Stanford Pratical Machine Learning-Stacking
本文最后更新于:1 年前
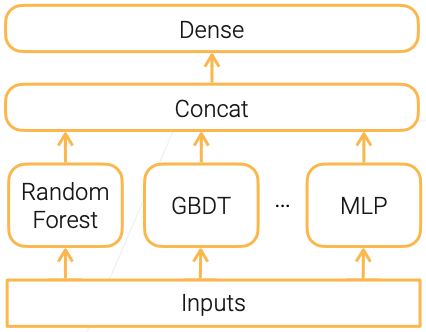
这一章主要介绍Stacking,刷榜利器!和Bagging有点像,组合多个base learner。不同点在于,Bagging是在不同的采样数据上,训练同一个模型。Stacking是在同样的数据上,训练不一样的模型。
Stacking
- Combine multiple base learners to reduce variance
- Base learners can be different model types
- Linearly combine base learners outputs by learned parameters
- Widely used in competitions
- bagging VS stacking
- Bagging: bootstrap samples to get diversity
- Stacking: different types of models extract different features
- Code
1 | |
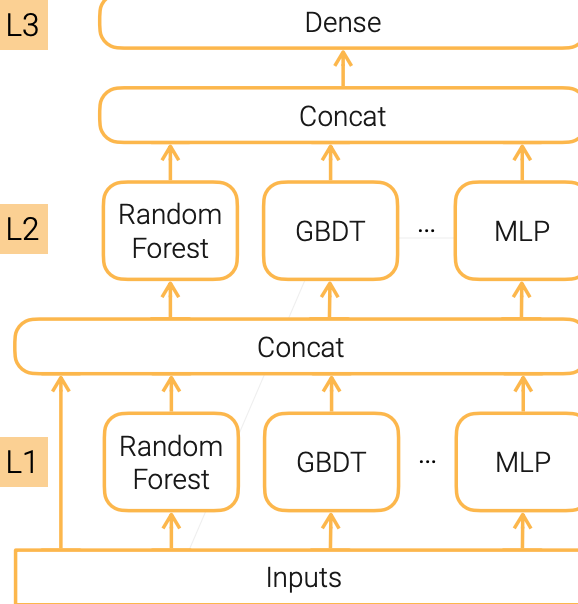
Multi-layer Stacking
- Stacking base learners in multiple levels to reduce bias
- Can use a different set of base learners at each level
- Upper levels (e.g. L2) are trained on the outputs of the level below (e.g. L1)
- Concatenating original inputs helps
- Code
1 | |
Overfitting in Multi-layer Stacking
- Train leaners from different levels on different data to alleviate overfitting
- Split training data into A and B, train L1 learners on A, run inference on B to generate training data for L2 learners
- Repeated k-fold bagging:
- Train k models as in k-fold cross validation
- Combine predictions of each model on out-of-fold data
- Repeat step 1,2 by n times, average the n predictions of each example for the next level training
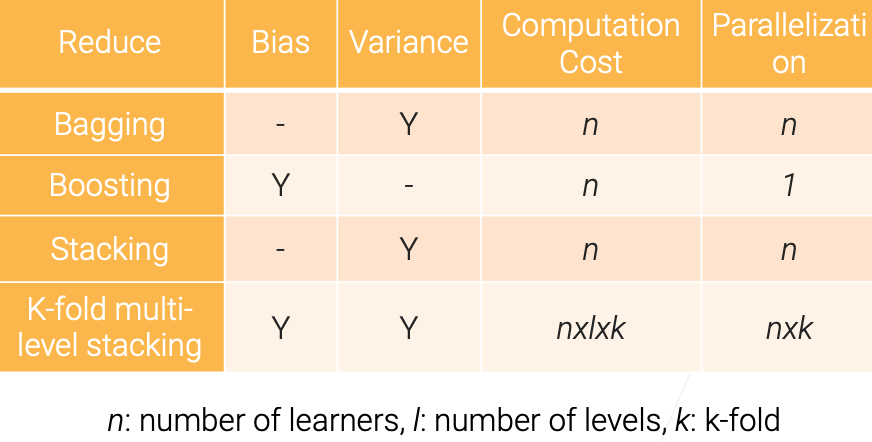
Model Combination Summary
References
Stanford Pratical Machine Learning-Stacking
https://alexanderliu-creator.github.io/2023/08/26/stanford-pratical-machine-learning-stacking/