Stanford Pratical Machine Learning-模型调参
本文最后更新于:1 年前
这一章主要介绍模型调参,model tuning
Manual Hyperparameter Tuning
Start with a good baseline, e.g. default settings in high-quality toolkits, values reported in papers
Tune a value, retrain the model to see the changes
Repeat multiple times to gain insights about
- Which hyperparameters are important
- How sensitive the model to hyperparameters
- What are the good ranges
Needs careful experiment management
Save your training logs and hyperparameters to compare, share and reproduce later
- The simplest way is saving logs in text and put key metrics in Excel
- Better options exist, e.g. tenesorboard and weights & bias
Weights & Biases在这里,是一款用来服务器存储参数,结果和可视化的工具捏!!!
- Reproducing is hard, it relates to
- Environment (hardware & library)
- Code
- Randomness (seed)
Randomness这种问题最好解决一下,随机性其实代表着模型不是特别稳定捏,可以使用更稳定的实现 or 多个模型Ensemble。
- Summary
- 选取一个好的超参数得到一个好的结果是比较花时间的过程
- 一般会从一个好的基线开始。
- 基线是什么?
- 选一个质量比较高的工具包,其中设了不错的参数,虽然可能对我们的问题不算是最好的,但是是一个不错的开始点;
- 如果要做的东西是跟某些论文相关,可以看看该论文里面的超参数是什么(有些超参数跟特定的数据集有关),这些超参数在一般的情况下都不错
- 有了比较好的起始点之后,调整超参数后再重新训练模型,再去看看验证集上的结果(精度、损失)
- 一次调一个值,多个值同时调可能会不知道谁在起贡献
- 看看模型对超参数的敏感度是什么样子【没调好一个超参数模型可能会比较差,但是调好了也只是到了还不错的范围】
- 想对超参数没那么敏感的话,可以使用比较好的模型【在优化算法中使用Adam(对有些超参数没那么敏感,调参会简单很多)而不是SGD(在比较小的区域比较好)】
- 每次调参一定要做好笔记【任何调过的东西,最好将这些实验管理好】(训练日志、超参数记录下来,这样可以与之前的实验做比较,也好做分享,与自己重复自己的实验)
- 最简单的做法是将log记录到txt上,把超参数和关键性指标(训练误差)放在excel中【适合实验没有那么多的参数】
- Tensorboard,tensorflow开发的一个可视化工具
- weight&bias:允许在训练的时候用他们的API,然后把实验记录下来后上传到他们的网页上,就可以进行比较
- 重复一个实验是非常难的
- 开发的环境:用的硬件是什么、新旧GPU可能会有点不一样;用的库的版本(Python本身也要去注意)
- 代码开发要做好版本控制(可以将每个版本的代码放在同一个地方 需求的库也放在这里)
- 要注意随机性(改变了随机种子,模型抖动比较大的话,说明代码的稳定性不是很好)【要避免换了个随机种子后,结果浮动比较大。这样的话,尝试能不能将不稳定的地方修改一下,实在不行就将多个模型做ensemble】
Automated Hyperparameter Tuning
- Computation costs decrease exponentially, while human costs increase
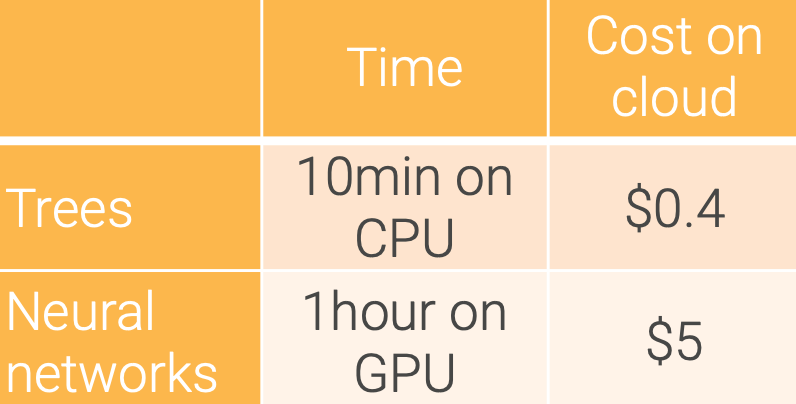
- Cost per training for a typical ML task:
- E.g. 1M user logs, 10K images
- Cost of a data scientist per day >$500
- Use algorithms if it outperforms human after 1000 trials
- Typically beat 90% data scientists
Automated Machine Learning (AutoML)
机器学习问题去解决实际问题的时候,所有的东西都想自动化!!!
- Automate every step in applying ML to solve real-world problems: data cleaning, feature extraction, model selection…
- Hyperparameter optimization (HPO): find a good set of hyperparameters through search algorithms
- Neural architecture search (NAS): construct a good neural network model
Summary
- Hyperparameter tuning aims to find a set of good values
- It’s time consuming as data preprocessing
- There is a trend to use algorithm for tuning
References
- slides
- Weights & Biases
- 笔记,文章中很多Summary的部分,搬了笔记,确实笔记写的很清楚,相见恨晚!!!
Stanford Pratical Machine Learning-模型调参
https://alexanderliu-creator.github.io/2023/08/26/stanford-pratical-machine-learning-mo-xing-diao-can/