Stanford Pratical Machine Learning-Boosting
本文最后更新于:1 年前
这一章主要介绍Boosting,也是另外一种模型组合方案。本质就是一种训练多个弱模型,组合成强模型。主要目的是通过多个模型的决策结果来减少偏差。弱模型 -> 强模型。
Boosting
注意和之前的Bagging不一样!这里的模型是顺序训练的!特定训练预测不好的结果!不好并行,大模型比较吃亏。
- Learn n weak learners sequentially, combine to reduce model bias
- At step t, repeat:
- Evaluate the existing learners’ errors $\epsilon_t$
- Train a weak learner $\hat{f}_p$, focus on wrongly predicted examples
- AdaBoost: Re-sample data according to $\epsilon_t$
- Gradient boosting: Train learner to predict $\epsilon_t$
- Additively combining existing weak learners with $\hat{f}_t$
Gradient Boosting
相当于整体的模型,每轮迭代添加了一个新的模型!!!
- Supports arbitrary differentiable loss
- $H_t(x)$: output of combined model at timestep t, with $H_l(x) = 0$
- For each step t, repeat:
- Train a new learner $\hat{f}t$ on residuals: ${(x_i, y_i - H_i(x_i)}{i = 1,\dots,m}$
- Combine $H_{t+1}(x) = H_t(x) + \eta \hat{f}_t(x)$
- The learning rate $\eta$ is the shrinkage parameter for regularization
- MSE $L = \frac{1}{2}(H(x) - y) ^ 2$, , residual equals negative gradient $y - H(x) = -\frac{\part{L}}{\part{H}}$
- Other boosting algorithms (e.g. AdaBoost) can also be replaced in the gradient descent in the function space
Gradient Boosting Code
1 | |
Gradient Boosting Decision Trees (GBDT)
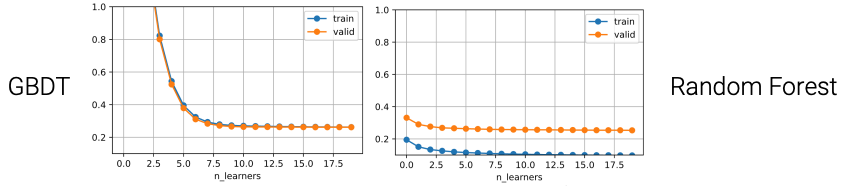
注意,Boosting一定是弱模型哈,强的一下拟合住了就没得玩了嘛!怎么弱?比如层数小的决策树,如果不限制层数,决策树本身是强模型昂!!!
- Use decision tree as the weak learner
- Regularize by a small max_depth and randomly sampling features
- Sequentially constructing trees runs slow
- Popular libraries use accelerated algorithms, e.g. XGBoost, lightGBM
References
Stanford Pratical Machine Learning-Boosting
https://alexanderliu-creator.github.io/2023/08/26/stanford-pratical-machine-learning-boosting/