D2L-Kaggle-目标检测(牛仔穿戴)
本文最后更新于:1 年前
这个Competition中,我们遇到的主要问题,是数据的不平衡。数据不平衡使得某些类别的样本过少,我们需要处理这个问题。
实战Kaggle比赛
- This is an object detection competition with imbalanced data challenge. You will need to train a model to detect cowboy outfits in wild images.
- 任务回顾:
- 检测牛仔夹克、墨镜、靴子、牛仔帽、腰带6937张训练图片,12660标注框
- 数据使用MS-COCO格式,评测使用mAP
- 均可直接调用pycocotools
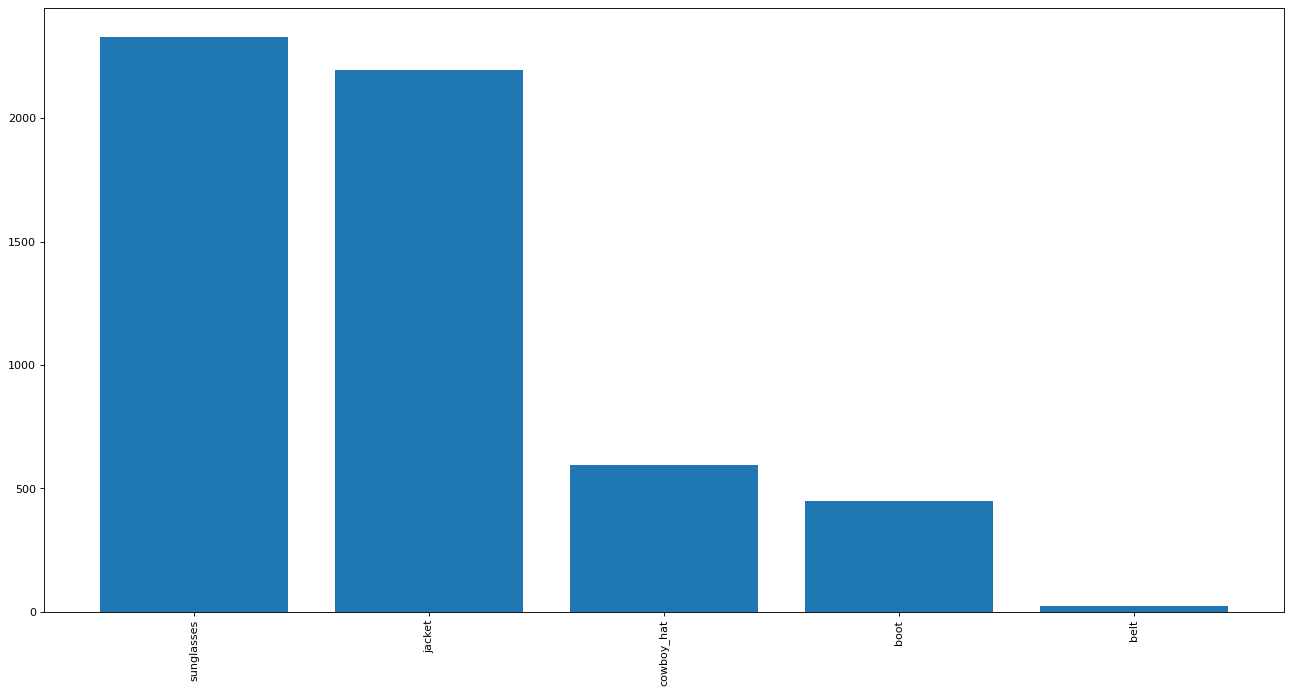
Challenge: 类别不平衡
类别失衡问题解决方案
- 当有类别样本严重不足时,可以人工干预提升它们对模型的影响力
- 最简答将不足的类别样本复制多次(手动将样本多复制,提高稀少样本的数量)
- 在随机采样小批量时对每个类使用不同采样频率(偏少的样本采样概率更高,能够使模型看到的样本更加均衡)
- 在计算损失时增大不足类别样本的权重(计算损失的时候,给偏少的样本更多的权重,使得模型看到偏少的样本的时候,能够让梯度“偏向”偏少的样本,从而进行学习)
随机采样,损失计算,样本重复等操作,可以独立使用,也可以组合使用。要注意不要过了哈!!!
- 有同学使用了SMOTE
- 在不足类样本的中选择相近对做差值
想法类似:两个非常类似的样本,我把这两个样本中间的所有点,都认为是合法的样本。相当于无中生有!多了很多样本!!!
模型
- YOLOX: YOLOv3 + anchor free :
- YOLOv5: YOLOv3 Pytorch版本的改进版
- YOLOv4和YOLOv5均是社区改迸版,命名有争以
- Detectron2: Faster RCNN
- 大都采用了多模型、k则融合
总结
- 目标检测代码实现复杂,训练代价大,上手仍以找到容易上手的库为主。
- 因为超参数多,一般需要较长时间探索
References
D2L-Kaggle-目标检测(牛仔穿戴)
https://alexanderliu-creator.github.io/2023/08/18/d2l-kaggle-mu-biao-jian-ce-niu-zi-chuan-dai/