本文最后更新于:1 年前
Self Attention & Transformer 李宏毅 ,Self-supervised Learing BERT GPT 李宏毅 。先看这些!这个对于原理讲的非常清楚,了解了这个,再去学李沐的课程,就十分清晰了昂!!!
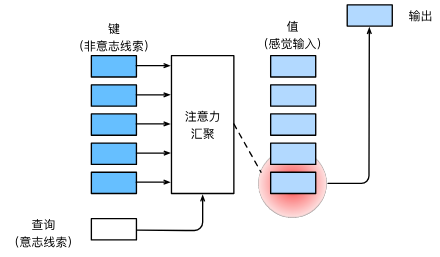
注意力机制 查询、键和值
卷积、全连接和池化层都只考虑不随意线索。
注意力机制则显示地考虑随意线索
随意线索被称之为查询(Query)
每个输入是一个值(Value)和不随意线索(Key)的对
通过注意力池化层来偏向性地选择某些输入
给定任何查询,注意力机制通过注意力汇聚 (attention pooling) 将选择引导至感官输入 (sensory inputs,例如中间特征表示)。 在注意力机制中,这些感官输入被称为值 (value)。 更通俗的解释,每个值都与一个键 (key)配对, 这可以想象为感官输入的非自主提示。 如 图10.1.3 所示,可以通过设计注意力汇聚的方式, 便于给定的查询(自主性提示)与键(非自主性提示)进行匹配, 这将引导得出最匹配的值(感官输入)。
非参注意力池化层
给定数据$(x_i, y_i)$
平均池化层 $$
最简单的估计器,这个估计器确实不够聪明。 真实函数f(“Truth”)和预测函数(“Pred”)相差很大。
Nadaraya-Watson核回归
$$
K是Kernel昂!!!上述估计器被称为 Nadaraya-Watson核回归 (Nadaraya-Watson kernel regression),我们可以从 图10.1.3 中的注意力机制框架的角度 重写 (10.2.3) , 成为一个更加通用的注意力汇聚 (attention pooling)公式:
$$
$x$是查询,$(x_i, y_i)$是key-value对,注意力汇聚是$y_i$的加权平均。将查询$x$和键$x_i$之间的关系建模为 注意力权重 (attention weight)$\alpha(x, x_i)$, 如 (10.2.4) 所示, 这个权重将被分配给每一个对应值$y_i$。 对于任何查询,模型在所有键值对注意力权重都是一个有效的概率分布: 它们是非负的,并且总和为1。
下面考虑一个高斯核 (Gaussian kernel),其定义为:
$$
将高斯核代入 (10.2.4) 和 (10.2.3) 可以得到:
$$
参数化的注意力机制
在之前的基础上,可以引入可以学习的$\omega$,有:
$$
代码 Dependencies 1 2 3 import torchfrom torch import nnfrom d2l import torch as d2l
生成数据集 1 2 3 4 5 6 7 8 9 10 11 n_train = 50 5 )def f (x ):return 2 * torch.sin(x) + x**0.8 0.0 , 0.5 , (n_train,))0 , 5 , 0.1 )len (x_test)
绘图 1 2 3 4 5 6 7 def plot_kernel_reg (y_hat ):'x' , 'y' , legend=['Truth' , 'Pred' ],0 , 5 ], ylim=[-1 , 5 ])'o' , alpha=0.5 );
非参数注意力汇聚 1 2 3 4 X_repeat = x_test.repeat_interleave(n_train).reshape((-1 , n_train))2 / 2 , dim=1 )
非参的好处,类似于knn,不需要学习捏!
热力图康康注意力权重 1 2 3 d2l.show_heatmaps(0 ).unsqueeze(0 ),'Sorted training inputs' , ylabel='Sorted testing inputs' )
带参数注意力汇聚假定两个张量的形状分别是 (𝑛,𝑎,𝑏)和 (𝑛,𝑏,𝑐),它们的批量矩阵乘法输出的形状为 (𝑛,𝑎,𝑐)
1 2 3 X = torch.ones((2 , 1 , 4 ))2 , 4 , 6 ))
使用小批量矩阵乘法来计算小批量数据中的加权平均值
1 2 3 weights = torch.ones((2 , 10 )) * 0.1 20.0 ).reshape((2 , 10 ))1 ), values.unsqueeze(-1 ))
带参数的注意力汇聚 1 2 3 4 5 6 7 8 9 10 11 12 class NWKernelRegression (nn.Module):def __init__ (self, **kwargs ):super ().__init__(**kwargs)self .w = nn.Parameter(torch.rand((1 ,), requires_grad=True ))def forward (self, queries, keys, values ):1 ]).reshape(1 , keys.shape[1 ]))self .attention_weights = nn.functional.softmax(self .w)**2 / 2 , dim=1 )return torch.bmm(self .attention_weights.unsqueeze(1 ),1 )).reshape(-1 )
将训练数据集转换为键和值 1 2 3 4 5 6 X_tile = x_train.repeat((n_train, 1 ))1 ))1 - torch.eye(n_train)).type (torch.bool )].reshape(1 ))1 - torch.eye(n_train)).type (torch.bool )].reshape(1 ))
训练带参数的注意力汇聚模型 1 2 3 4 5 6 7 8 9 10 11 12 net = NWKernelRegression()'none' )0.5 )'epoch' , ylabel='loss' , xlim=[1 , 5 ])for epoch in range (5 ):2 sum ().backward()print (f'epoch {epoch + 1 } , loss {float (l.sum ()):.6 f} ' )1 , float (l.sum ()))
预测结果绘制 1 2 3 4 keys = x_train.repeat((n_test, 1 ))1 ))1 ).detach()
1 2 3 d2l.show_heatmaps(0 ).unsqueeze(0 ),'Sorted training inputs' , ylabel='Sorted testing inputs' )
总结
心理学认为人通过随意线索和不随意线索选择注意点
注意力机制中,通过query (随意线索)和key (不随意线索)来有偏向性的选择输入
可以一般的写作$f(x) = \sum_{i=1} \alpha(x, x_i)y_i$这里$\alpha(x, x_i)$是注意力权重
早在60年代就有非参数的注意力机制
接下来我们会介绍多个不同的权重设计
注意力分数 注意力评分函数
由于注意力权重是概率分布, 因此加权和其本质上是加权平均值。
假设有一个查询$\mathbf{q} \in \mathbb{R}^q$和$m$个“键-值”对$(\mathbf{k}_1, \mathbf{v}_1), \ldots, (\mathbf{k}_m, \mathbf{v}_m)$, 其中$\mathbf{k}_i \in \mathbb{R}^k, \mathbf{v}_i \in \mathbb{R}^v$。 注意力汇聚函数f就被表示成值的加权和:
$$m)) = \sum {i=1}^m \alpha(\mathbf{q}, \mathbf{k}_i) \mathbf{v}_i \in \mathbb{R}^v,
其中查询$q$和键$\mathbf{k}_i$的注意力权重(标量) 是通过注意力评分函数$\alpha$将两个向量映射成标量, 再经过softmax运算得到的:
$$i))}{\sum {j=1}^m \exp(a(\mathbf{q}, \mathbf{k}_j))} \in \mathbb{R}.
加性注意力
当查询和键是不同长度的矢量时,可以使用加性注意力作为评分函数。 给定查询$\mathbf{q} \in \mathbb{R}^q$和键$\mathbf{k} \in \mathbb{R}^k$, 加性注意力 (additive attention)的评分函数为:
$$
其中可学习的参数是$\mathbf W_q\in\mathbb R^{h\times q}$、$\mathbf W_k\in\mathbb R^{h\times k}$和$\mathbf w_v\in\mathbb R^{h}$。 如 (10.3.3) 所示, 将查询和键连结起来后输入到一个多层感知机(MLP)中, 感知机包含一个隐藏层,其隐藏单元数是一个超参数h。 通过使用tanh作为激活函数,并且禁用偏置项。
等价于将key和value合并起来,放入到一个隐藏大小为h,输出为1的单隐藏层MLP
缩放点积注意力
使用点积可以得到计算效率更高的评分函数, 但是点积操作要求查询和键具有相同的长度d。 假设查询和键的所有元素都是独立的随机变量, 并且都满足零均值和单位方差, 那么两个向量的点积的均值为0,方差为d。 为确保无论向量长度如何, 点积的方差在不考虑向量长度的情况下仍然是1, 我们再将点积除以$\sqrt{d}$, 则缩放点积注意力 (scaled dot-product attention)评分函数为:
$$
由于q和k的shape一致,本质上就是做个内积!很方便昂!
在实践中,我们通常从小批量的角度来考虑提高效率, 例如基于n个查询和m个键-值对计算注意力, 其中查询和键的长度为d,值的长度为v。 查询$\mathbf Q\in\mathbb R^{n\times d}$、 键$\mathbf K\in\mathbb R^{m\times d}$和值$\mathbf V\in\mathbb R^{m\times v}$的缩放点积注意力是:
$$
总结
注意力分数是query和key的相似度,注意力权重是分数的softmax结果。
两种常见的分数计算:
将query和key合并起来进入一个单输出单隐藏层的MLP
直接将query和key做内积
代码 Dependencies 1 2 3 4 import mathimport torchfrom torch import nnfrom d2l import torch as d2l
掩蔽softmax操作
softmax操作用于输出一个概率分布作为注意力权重。 在某些情况下,并非所有的值都应该被纳入到注意力汇聚中。 例如,为了在 9.5节 中高效处理小批量数据集, 某些文本序列被填充了没有意义的特殊词元。 为了仅将有意义的词元作为值来获取注意力汇聚, 可以指定一个有效序列长度(即词元的个数), 以便在计算softmax时过滤掉超出指定范围的位置。 下面的masked_softmax函数 实现了这样的掩蔽softmax操作 (masked softmax operation), 其中任何超出有效长度的位置都被掩蔽并置为0。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def masked_softmax (X, valid_lens ):"""通过在最后一个轴上掩蔽元素来执行softmax操作""" if valid_lens is None :return nn.functional.softmax(X, dim=-1 )else :if valid_lens.dim() == 1 :1 ])else :1 )1 , shape[-1 ]), valid_lens,1e6 )return nn.functional.softmax(X.reshape(shape), dim=-1 )
为了演示此函数是如何工作的, 考虑由两个2×4矩阵表示的样本, 这两个样本的有效长度分别为2和3。 经过掩蔽softmax操作,超出有效长度的值都被掩蔽为0。
1 masked_softmax(torch.rand(2 , 2 , 4 ), torch.tensor([2 , 3 ]))
也可以使用二维张量,为矩阵样本中的每一行指定有效长度。
1 masked_softmax(torch.rand(2 , 2 , 4 ), torch.tensor([[1 , 3 ], [2 , 4 ]]))
加性注意力 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class AdditiveAttention (nn.Module):"""加性注意力""" def __init__ (self, key_size, query_size, num_hiddens, dropout, **kwargs ):super (AdditiveAttention, self ).__init__(**kwargs)self .W_k = nn.Linear(key_size, num_hiddens, bias=False )self .W_q = nn.Linear(query_size, num_hiddens, bias=False )self .w_v = nn.Linear(num_hiddens, 1 , bias=False )self .dropout = nn.Dropout(dropout)def forward (self, queries, keys, values, valid_lens ):self .W_q(queries), self .W_k(keys)2 ) + keys.unsqueeze(1 )self .w_v(features).squeeze(-1 )self .attention_weights = masked_softmax(scores, valid_lens)return torch.bmm(self .dropout(self .attention_weights), values)
forward里面有点复杂:
queries的形状:(batch_size,查询的个数,1,num_hidden)
features的形状:(batch_size,查询的个数,“键-值”对的个数,num_hidden)
scores的形状:(batch_size,查询的个数,“键-值”对的个数)
1 2 3 4 5 6 7 8 9 10 queries, keys = torch.normal(0 , 1 , (2 , 1 , 20 )), torch.ones((2 , 10 , 2 ))40 , dtype=torch.float32).reshape(1 , 10 , 4 ).repeat(2 , 1 , 1 )2 , 6 ])2 , query_size=20 , num_hiddens=8 ,0.1 )eval ()
1 2 d2l.show_heatmaps(attention.attention_weights.reshape((1 , 1 , 2 , 10 )),'Keys' , ylabel='Queries' )
缩放点积注意力 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class DotProductAttention (nn.Module):"""缩放点积注意力""" def __init__ (self, dropout, **kwargs ):super (DotProductAttention, self ).__init__(**kwargs)self .dropout = nn.Dropout(dropout)def forward (self, queries, keys, values, valid_lens=None ):1 ]1 ,2 )) / math.sqrt(d)self .attention_weights = masked_softmax(scores, valid_lens)return torch.bmm(self .dropout(self .attention_weights), values)
1 2 3 4 queries = torch.normal(0 , 1 , (2 , 1 , 2 ))0.5 )eval ()
1 2 d2l.show_heatmaps(attention.attention_weights.reshape((1 , 1 , 2 , 10 )),'Keys' , ylabel='Queries' )
Bahdanau 注意力
在为给定文本序列生成手写的挑战中, Graves设计了一种可微注意力模型, 将文本字符与更长的笔迹对齐, 其中对齐方式仅向一个方向移动。 受学习对齐想法的启发,Bahdanau等人提出了一个没有严格单向对齐限制的 可微注意力模型 (Bahdanau et al. , 2014 )。 在预测词元时,如果不是所有输入词元都相关,模型将仅对齐(或参与)输入序列中与当前预测相关的部分。这是通过将上下文变量视为注意力集中的输出来实现的。
模型
编码器每次的输出作为key和value
解码器RNN对于上一个词的输出是query
注意力的输出和下一个词的词嵌入合并进入解码器
总结
Seq2Seq中通过隐状态在编码器和解码器中传递信息。
注意力机制可以根据解码器RNN的输出来匹配到合适的编码器RNN的输出来更有效的传递信息。
代码 Dependencies 1 2 3 import torchfrom torch import nnfrom d2l import torch as d2l
注意力机制解码器
1 2 3 4 5 6 7 8 9 class AttentionDecoder (d2l.Decoder):"""带有注意力机制解码器的基本接口""" def __init__ (self, **kwargs ):super (AttentionDecoder, self ).__init__(**kwargs) @property def attention_weights (self ):raise NotImplementedError
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 class Seq2SeqAttentionDecoder (AttentionDecoder ):def __init__ (self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0 , **kwargs ):super (Seq2SeqAttentionDecoder, self ).__init__(**kwargs)self .attention = d2l.AdditiveAttention(self .embedding = nn.Embedding(vocab_size, embed_size)self .rnn = nn.GRU(self .dense = nn.Linear(num_hiddens, vocab_size)def init_state (self, enc_outputs, enc_valid_lens, *args ):return (outputs.permute(1 , 0 , 2 ), hidden_state, enc_valid_lens)def forward (self, X, state ):self .embedding(X).permute(1 , 0 , 2 )self ._attention_weights = [], []for x in X:1 ], dim=1 )self .attention(1 )), dim=-1 )self .rnn(x.permute(1 , 0 , 2 ), hidden_state)self ._attention_weights.append(self .attention.attention_weights)self .dense(torch.cat(outputs, dim=0 ))return outputs.permute(1 , 0 , 2 ), [enc_outputs, hidden_state, @property def attention_weights (self ):return self ._attention_weights
使用包含7个时间步的4个序列输入的小批量测试Bahdanau注意力解码器。
1 2 3 4 5 6 7 8 9 10 encoder = d2l.Seq2SeqEncoder(vocab_size=10 , embed_size=8 , num_hiddens=16 ,2 )eval ()10 , embed_size=8 , num_hiddens=16 ,2 )eval ()4 , 7 ), dtype=torch.long) None )len (state), state[0 ].shape, len (state[1 ]), state[1 ][0 ].shape
训练 1 2 3 4 5 6 7 8 9 10 11 embed_size, num_hiddens, num_layers, dropout = 32 , 32 , 2 , 0.1 64 , 10 0.005 , 250 , d2l.try_gpu()len (src_vocab), embed_size, num_hiddens, num_layers, dropout)len (tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
模型训练后,我们用它将几个英语句子翻译成法语并计算它们的BLEU分数。
1 2 3 4 5 6 7 engs = ['go .' , "i lost ." , 'he\'s calm .' , 'i\'m home .' ]'va !' , 'j\'ai perdu .' , 'il est calme .' , 'je suis chez moi .' ]for eng, fra in zip (engs, fras):True )print (f'{eng} => {translation} , ' ,f'bleu {d2l.bleu(translation, fra, k=2 ):.3 f} ' )
1 2 attention_weights = torch.cat([step[0 ][0 ][0 ] for step in dec_attention_weight_seq], 0 ).reshape((1 , 1 , -1 , num_steps))
训练结束后,下面通过可视化注意力权重 会发现,每个查询都会在键值对上分配不同的权重,这说明 在每个解码步中,输入序列的不同部分被选择性地聚集在注意力池中。
1 2 3 4 len (engs[-1 ].split()) + 1 ].cpu(),'Key positions' , ylabel='Query positions' )
自注意力和位置编码 自注意力
给定一个由词元组成的输入序列$\mathbf{x}_1, \ldots, \mathbf{x}_n$, 其中任意$\mathbf{x}_i \in \mathbb{R}^d\ (1 \leq i \leq n)$。 该序列的自注意力输出为一个长度相同的序列 $\mathbf{y}_1, \ldots, \mathbf{y}_n$,其中:
$$
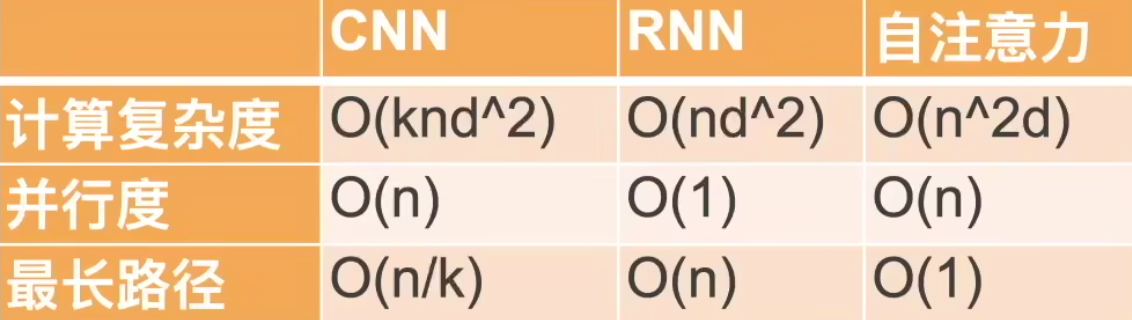
RNN的并行度是这里最差的昂!
位置编码
在处理词元序列时,循环神经网络是逐个的重复地处理词元的, 而自注意力则因为并行计算而放弃了顺序操作。 为了使用序列的顺序信息,通过在输入表示中添加 位置编码 (positional encoding)来注入绝对的或相对的位置信息。 位置编码可以通过学习得到也可以直接固定得到。
假设输入表示$\mathbf{X} \in \mathbb{R}^{n \times d}$包含一个序列中n个词元的d维嵌入表示。 位置编码使用相同形状的位置嵌入矩阵$\mathbf{P} \in \mathbb{R}^{n \times d}$输出$\mathbf{X} + \mathbf{P}$, 矩阵第i行、第2j列和2j+1列上的元素为:
$$
在位置嵌入矩阵$P$中, 行代表词元在序列中的位置,列代表位置编码的不同维度。 从下面的例子中可以看到位置嵌入矩阵的第6列和第7列的频率高于第8列和第9列。 第6列和第7列之间的偏移量(第8列和第9列相同)是由于正弦函数和余弦函数的交替。
直接把位置编码放入数据,而不是在模型进行修改 or 多加一个位置的维度再concat原始数据。
绝对位置信息
在二进制表示中,较高比特位的交替频率低于较低比特位(例如00, 01, 10, 11,高位交替一次,低位交替了两次), 与下面的热图所示相似,只是位置编码通过使用三角函数在编码维度上降低频率。 由于输出是浮点数,因此此类连续表示比二进制表示法更节省空间。
相对位置信息
除了捕获绝对位置信息之外,上述的位置编码还允许模型学习得到输入序列中相对位置信息。 这是因为对于任何确定的位置偏移$\delta$,位置$i + \delta$处 的位置编码可以线性投影位置$i$处的位置编码来表示。这种投影的数学解释是,令$\omega_j = 1/10000^{2j/d}$, 对于任何确定的位置偏移$\delta$, (10.6.2) 中的任何一对$(p_{i, 2j}, p_{i, 2j+1})$都可以线性投影到$(p_{i+\delta, 2j}, p_{i+\delta, 2j+1})$:
$$
2×2投影矩阵不依赖于任何位置的索引i。
代码实现 Dependencies 1 2 3 4 import mathimport torchfrom torch import nnfrom d2l import torch as d2l
位置编码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class PositionalEncoding (nn.Module):"""位置编码""" def __init__ (self, num_hiddens, dropout, max_len=1000 ):super (PositionalEncoding, self ).__init__()self .dropout = nn.Dropout(dropout)self .P = torch.zeros((1 , max_len, num_hiddens))1 , 1 ) / torch.pow (10000 , torch.arange(0 , num_hiddens, 2 , dtype=torch.float32) / num_hiddens)self .P[:, :, 0 ::2 ] = torch.sin(X)self .P[:, :, 1 ::2 ] = torch.cos(X)def forward (self, X ):self .P[:, :X.shape[1 ], :].to(X.device)return self .dropout(X)
绘制位置编码示意图
行代表标记在序列中的位置,列代表位置编码的不同维度
1 2 3 4 5 6 7 encoding_dim, num_steps = 32 , 60 0 )eval ()1 , num_steps, encoding_dim)))1 ], :]0 , :, 6 :10 ].T, xlabel='Row (position)' ,6 , 2.5 ), legend=["Col %d" % d for d in torch.arange(6 , 10 )])
二进制表示 1 2 for i in range (8 ):print (f'{i} in binary is {i:>03b} ' )
在编码维度上降低频率 1 2 3 P = P[0 , :, :].unsqueeze(0 ).unsqueeze(0 )'Column (encoding dimension)' ,'Row (position)' , figsize=(3.5 , 4 ), cmap='Blues' )
多头注意力
在实践中,当给定相同的查询、键和值的集合时, 我们希望模型可以基于相同的注意力机制学习到不同的行为, 然后将不同的行为作为知识组合起来, 捕获序列内各种范围的依赖关系 (例如,短距离依赖和长距离依赖关系)。 因此,允许注意力机制组合使用查询、键和值的不同子空间表示 (representation subspaces)可能是有益的。
为此,与其只使用单独一个注意力汇聚, 我们可以用独立学习得到的h组不同的 线性投影 (linear projections)来变换查询、键和值。 然后,这h组变换后的查询、键和值将并行地送到注意力汇聚中。 最后,将这h个注意力汇聚的输出拼接在一起, 并且通过另一个可以学习的线性投影进行变换, 以产生最终输出。 这种设计被称为多头注意力 (multihead attention) (Vaswani et al. , 2017 )。 对于h个注意力汇聚输出,每一个注意力汇聚都被称作一个头 (head)。 图10.5.1 展示了使用全连接层来实现可学习的线性变换的多头注意力。
说白了就是想抽取不同的特征,学到更多的东西。对同一个key, value, query抽取不同的信息,例如短距离和长距离关系。多头注意力使用h个独立的注意力池化,合并各个头并得到最终输出。
模型
给定查询$\mathbf{q} \in \mathbb{R}^{d_q}$、 键$\mathbf{k} \in \mathbb{R}^{d_k}$和值$\mathbf{v} \in \mathbb{R}^{d_v}$, 每个注意力头$i = 1, \ldots, h$的计算方法为:
$$
其中,可学习的参数包括$\mathbf W_i^{(q)}\in\mathbb R^{p_q\times d_q}$、 $\mathbf W_i^{(k)}\in\mathbb R^{p_k\times d_k}$和$\mathbf W_i^{(v)}\in\mathbb R^{p_v\times d_v}$, 以及代表注意力汇聚的函数$f$。$f$可以是 10.3节 中的 加性注意力和缩放点积注意力。 多头注意力的输出需要经过另一个线性转换, 它对应着ℎ个头连结后的结果,因此其可学习参数是 $\mathbf W_o\in\mathbb R^{p_o\times h p_v}$:
$$
基于这种设计,每个头都可能会关注输入的不同部分, 可以表示比简单加权平均值更复杂的函数。
有掩码的多头注意力
解码器在对于序列中的元素输出时,只考虑之前的元素,不考虑之后的元素。
可以通过掩码来实现:计算$x_i$的时候,假装当前的序列长度为i
从宏观角度来看,Transformer的编码器是由多个相同的层叠加而成的,每个层都有两个子层(子层表示为sublayer)。第一个子层是多头自注意力 (multi-head self-attention)汇聚;第二个子层是基于位置的前馈网络 (positionwise feed-forward network)。具体来说,在计算编码器的自注意力时,查询、键和值都来自前一个编码器层的输出。受 7.6节 中残差网络的启发,每个子层都采用了残差连接 (residual connection)。在Transformer中,对于序列中任何位置的任何输入$\mathbf{x} \in \mathbb{R}^d$,都要求满足$\mathrm{sublayer}(\mathbf{x}) \in \mathbb{R}^d$,以便残差连接满足$\mathbf{x} + \mathrm{sublayer}(\mathbf{x}) \in \mathbb{R}^d$。在残差连接的加法计算之后,紧接着应用层规范化 (layer normalization) (Ba et al. , 2016 )。因此,输入序列对应的每个位置,Transformer编码器都将输出一个d维表示向量。
Transformer解码器也是由多个相同的层叠加而成的,并且层中使用了残差连接和层规范化。除了编码器中描述的两个子层之外,解码器还在这两个子层之间插入了第三个子层,称为编码器-解码器注意力 (encoder-decoder attention)层。在编码器-解码器注意力中,查询来自前一个解码器层的输出,而键和值来自整个编码器的输出。在解码器自注意力中,查询、键和值都来自上一个解码器层的输出。但是,解码器中的每个位置只能考虑该位置之前的所有位置。这种掩蔽 (masked)注意力保留了自回归 (auto-regressive)属性,确保预测仅依赖于已生成的输出词元。
基于Encoder-Decoder架构来处理序列对
Transformer是纯基于注意力
基于位置的前馈网络
基于位置的前馈网络对序列中的所有位置的表示进行变换时使用的是同一个多层感知机(MLP),这就是称前馈网络是基于位置的 (positionwise)的原因。在下面的实现中,输入X的形状(批量大小,时间步数或序列长度,隐单元数或特征维度)将被一个两层的感知机转换成形状为(批量大小,时间步数,ffn_num_outputs)的输出张量。
将输入形状由(b, n, d)变换为(bn, d)
作用两个全连接层
将输出形状由(bn, d)变换为(b, n, d)
等价于两层核窗口为1的一维卷积层
FFN存在的原因是:FFN的输入,linear函数只能写 input_embed, 和output_embed这两个参数, 所以得切换成二维的形式输入。
残差连接和层规范化
加法和规范化 (add&norm)组件。正如在本节开头所述,这是由残差连接和紧随其后的层规范化组成的。两者都是构建有效的深度架构的关键。一个小批量的样本内基于批量规范化对数据进行重新中心化和重新缩放的调整。层规范化和批量规范化的目标相同,但层规范化是基于特征维度进行规范化。尽管批量规范化在计算机视觉中被广泛应用,但在自然语言处理任务中(输入通常是变长序列)批量规范化通常不如层规范化的效果好。
每个句子的长度不一样,不能用bn,得用ln。比方说一行是一项数据,那么batch norm就是对一列进行归一化,ln就是对所有数据项的某一列特征归一化。
每句话有len个词,每个词由d个特征表示,BN是对所有句子所有词的某一特征做归一化,LN是对某一句话的所有词所有特征做归一化
批量归一化对每个特征/通道里元素进行归一化,不适合序列长度会变的NLP应用。(预测序列的长短,可能直接影响归一化的效果,不稳定。对于每个样本来做的话,和长短无关,就稳定很多了昂。)
层归一化对每个样本里的元素进行归一化
信息传递
编码器中的输出$y_1, \dots, y_n$
将其作为解码器中第$i$个Transformer块中多头注意力的key和value,它的query来自目标序列。
意味着编码器和解码器中块的个数和输出维度都是一样的
预测
预测第$t+1$个输出时
解码器输入前t个预测值
在自注意力中,前t个预测值作为key和value,弟t个预测值还作为query
训练时,第一个mask-多头K,V来自本身的Q,第二个attention的K,V才是来自encoder。
总结
Transformer是一个纯使用注意力的Encoder-Decoder。
Encoder和Decoder都有n个Transformer块。
每个块里使用多头(自)注意力,基于位置的前馈网络,和层归一化。
代码实现 Dependencies 1 2 3 4 5 import mathimport pandas as pdimport torchfrom torch import nnfrom d2l import torch as d2l
多头注意力 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class MultiHeadAttention (nn.Module):"""多头注意力""" def __init__ (self, key_size, query_size, value_size, num_hiddens, num_heads, dropout, bias=False , **kwargs ):super (MultiHeadAttention, self ).__init__(**kwargs)self .num_heads = num_headsself .attention = d2l.DotProductAttention(dropout)self .W_q = nn.Linear(query_size, num_hiddens, bias=bias)self .W_k = nn.Linear(key_size, num_hiddens, bias=bias)self .W_v = nn.Linear(value_size, num_hiddens, bias=bias)self .W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)def forward (self, queries, keys, values, valid_lens ):self .W_q(queries), self .num_heads)self .W_k(keys), self .num_heads)self .W_v(values), self .num_heads)if valid_lens is not None :self .num_heads, dim=0 )self .attention(queries, keys, values, valid_lens)self .num_heads)return self .W_o(output_concat)
为了能够使多个头并行计算, 上面的MultiHeadAttention类将使用下面定义的两个转置函数。 具体来说,transpose_output函数反转了transpose_qkv函数的操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def transpose_qkv (X, num_heads ):"""为了多注意力头的并行计算而变换形状""" 0 ], X.shape[1 ], num_heads, -1 )0 , 2 , 1 , 3 )return X.reshape(-1 , X.shape[2 ], X.shape[3 ])def transpose_output (X, num_heads ):"""逆转transpose_qkv函数的操作""" 1 , num_heads, X.shape[1 ], X.shape[2 ])0 , 2 , 1 , 3 )return X.reshape(X.shape[0 ], X.shape[1 ], -1 )
下面使用键和值相同的小例子来测试我们编写的MultiHeadAttention类。 多头注意力输出的形状是(batch_size,num_queries,num_hiddens)。
1 2 3 4 num_hiddens, num_heads = 100 , 5 0.5 )eval ()
1 2 3 4 5 batch_size, num_queries = 2 , 4 6 , torch.tensor([3 , 2 ])
基于位置的前馈网络 1 2 3 4 5 6 7 8 9 10 class PositionWiseFFN (nn.Module):def __init__ (self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs, **kwargs ):super (PositionWiseFFN, self ).__init__(**kwargs)self .dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)self .relu = nn.ReLU()self .dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)def forward (self, X ):return self .dense2(self .relu(self .dense1(X)))
1 2 3 ffn = PositionWiseFFN(4 , 4 , 8 )eval ()2 , 3 , 4 )))[0 ]
1 2 3 4 ln = nn.LayerNorm(2 )2 )1 , 2 ], [2 , 3 ]], dtype=torch.float32)print ('layer norm:' , ln(X), '\nbatch norm:' , bn(X))
使用残差连接和层归一化 1 2 3 4 5 6 7 8 class AddNorm (nn.Module):def __init__ (self, normalized_shape, dropout, **kwargs ):super (AddNorm, self ).__init__(**kwargs)self .dropout = nn.Dropout(dropout)self .ln = nn.LayerNorm(normalized_shape)def forward (self, X, Y ):return self .ln(self .dropout(Y) + X)
1 2 3 add_norm = AddNorm([3 , 4 ], 0.5 )eval ()2 , 3 , 4 )), torch.ones((2 , 3 , 4 ))).shape
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class EncoderBlock (nn.Module):def __init__ (self, key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, dropout, use_bias=False , **kwargs ):super (EncoderBlock, self ).__init__(**kwargs)self .attention = d2l.MultiHeadAttention(key_size, query_size,self .addnorm1 = AddNorm(norm_shape, dropout)self .ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens,self .addnorm2 = AddNorm(norm_shape, dropout)def forward (self, X, valid_lens ):self .addnorm1(X, self .attention(X, X, X, valid_lens))return self .addnorm2(Y, self .ffn(Y))
Transformer编码器中的任何层都不会改变其输入的形状
1 2 3 4 5 X = torch.ones((2 , 100 , 24 ))3 , 2 ])24 , 24 , 24 , 24 , [100 , 24 ], 24 , 48 , 8 , 0.5 )eval ()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class TransformerEncoder (d2l.Encoder):def __init__ (self, vocab_size, key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout, use_bias=False , **kwargs ):super (TransformerEncoder, self ).__init__(**kwargs)self .num_hiddens = num_hiddensself .embedding = nn.Embedding(vocab_size, num_hiddens)self .pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)self .blks = nn.Sequential()for i in range (num_layers):self .blks.add_module("block" + str (i),def forward (self, X, valid_lens, *args ):self .pos_encoding(self .embedding(X) * math.sqrt(self .num_hiddens))self .attention_weights = [None ] * len (self .blks)for i, blk in enumerate (self .blks):self .attention_weights[return X
1 2 3 4 encoder = TransformerEncoder(200 , 24 , 24 , 24 , 24 , [100 , 24 ], 24 , 48 , 8 , 2 ,0.5 )eval ()2 , 100 ), dtype=torch.long), valid_lens).shape
Transformer解码器也是由多个相同的层组成:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 class DecoderBlock (nn.Module):"""解码器中第 i 个块""" def __init__ (self, key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, dropout, i, **kwargs ):super (DecoderBlock, self ).__init__(**kwargs)self .i = iself .attention1 = d2l.MultiHeadAttention(key_size, query_size,self .addnorm1 = AddNorm(norm_shape, dropout)self .attention2 = d2l.MultiHeadAttention(key_size, query_size,self .addnorm2 = AddNorm(norm_shape, dropout)self .ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens,self .addnorm3 = AddNorm(norm_shape, dropout)def forward (self, X, state ):0 ], state[1 ]if state[2 ][self .i] is None :else :2 ][self .i], X), axis=1 )2 ][self .i] = key_valuesif self .training:1 , num_steps + 1 ,1 )else :None self .attention1(X, key_values, key_values, dec_valid_lens)self .addnorm1(X, X2)self .attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)self .addnorm2(Y, Y2)return self .addnorm3(Z, self .ffn(Z)), state
训练 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 num_hiddens, num_layers, dropout, batch_size, num_steps = 32 , 2 , 0.1 , 64 , 10 0.005 , 200 , d2l.try_gpu()32 , 64 , 4 32 , 32 , 32 32 ]len (src_vocab), key_size, query_size, value_size,len (tgt_vocab), key_size, query_size, value_size,
预测
1 2 3 4 5 6 7 engs = ['go .' , "i lost ." , 'he\'s calm .' , 'i\'m home .' ]'va !' , 'j\'ai perdu .' , 'il est calme .' , 'je suis chez moi .' ]for eng, fra in zip (engs, fras):True )print (f'{eng} => {translation} , ' ,f'bleu {d2l.bleu(translation, fra, k=2 ):.3 f} ' )
可视化
1 2 3 enc_attention_weights = torch.cat(net.encoder.attention_weights, 0 ).reshape(1 , num_steps))
1 2 3 4 d2l.show_heatmaps(enc_attention_weights.cpu(), xlabel='Key positions' ,'Query positions' ,'Head %d' % ifor i in range (1 , 5 )], figsize=(7 , 3.5 ))
为了可视化解码器的自注意力权重和“编码器-解码器”的注意力权重,我们需要完成更多的数据操作工作
1 2 3 4 5 6 7 8 9 10 dec_attention_weights_2d = [0 ].tolist() for step in dec_attention_weight_seq for attn in stepfor blk in attn for head in blk]0.0 ).values)1 , 2 , num_layers, num_heads, num_steps))1 , 2 , 3 , 0 , 4 )
1 2 3 4 d2l.show_heatmaps(len (translation.split()) + 1 ],'Key positions' , ylabel='Query positions' ,'Head %d' % i for i in range (1 , 5 )], figsize=(7 , 3.5 ))
输出序列的查询不会与输入序列中填充位置的标记进行注意力计算
1 2 3 4 d2l.show_heatmaps(dec_inter_attention_weights, xlabel='Key positions' ,'Query positions' ,'Head %d' % ifor i in range (1 , 5 )], figsize=(7 , 3.5 ))
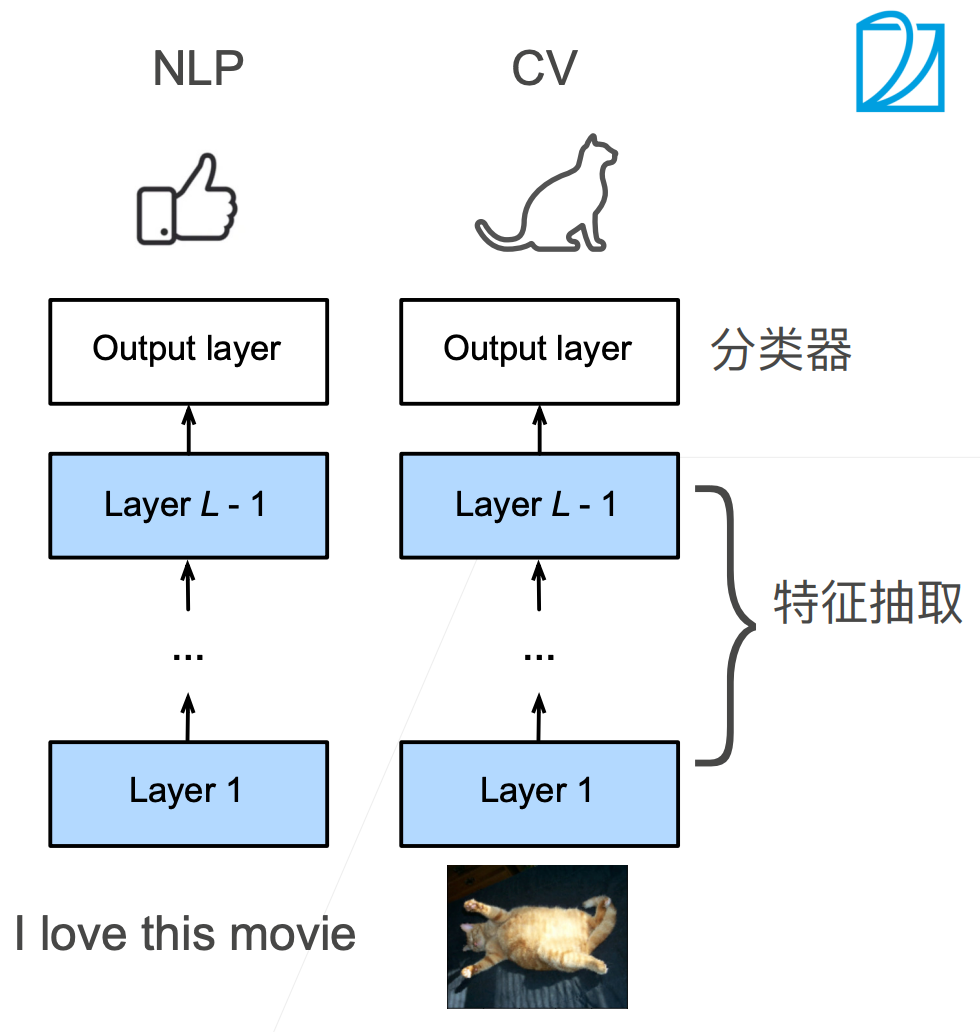
Bert Transfer Learning in NLP
使用预训练好的模型来抽取词、句子的特征
不更新预训练好的模型 需要构建新的网络来抓取新任务需要的信息
Word2vec忽略了时序信息,语言模型只看了一个方向
Bert的动机
基于fine tune的NLP模型
预训练的模型抽取了足够多的信息
新的任务只需要增加一个简单的输出层
Bert架构
只有编码器的Transformer
两个版本:
Base: #blocks= 12, hidden size= 768, #heads= 12, #parameters= 1 10M
Large: #blocks= 24, hidden size= 1024, #heads= 16, #parameter = 340M
在大规模数据上训练 > 3B 词
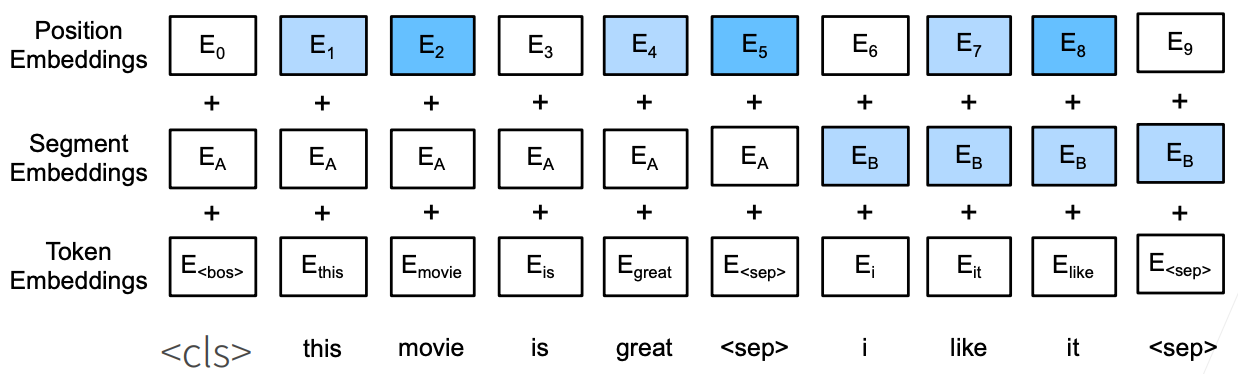
对输入的修改
每个样本是一个句子对
加入额外的片段嵌入
位置编码可学习
代码实现 Dependencies 1 2 3 import torchfrom torch import nnfrom d2l import torch as d2l
1 2 3 4 5 6 7 8 def get_tokens_and_segments (tokens_a, tokens_b=None ):"""Get tokens of the BERT input sequence and their segment IDs.""" '<cls>' ] + tokens_a + ['<sep>' ]0 ] * (len (tokens_a) + 2 )if tokens_b is not None :'<sep>' ]1 ] * (len (tokens_b) + 1 )return tokens, segments
BERTEncoder 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class BERTEncoder (nn.Module):"""BERT encoder.""" def __init__ (self, vocab_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout, max_len=1000 , key_size=768 , query_size=768 , value_size=768 , **kwargs ):super (BERTEncoder, self ).__init__(**kwargs)self .token_embedding = nn.Embedding(vocab_size, num_hiddens)self .segment_embedding = nn.Embedding(2 , num_hiddens)self .blks = nn.Sequential()for i in range (num_layers):self .blks.add_module(f"{i} " , d2l.EncoderBlock(True ))self .pos_embedding = nn.Parameter(torch.randn(1 , max_len,def forward (self, tokens, segments, valid_lens ):self .token_embedding(tokens) + self .segment_embedding(segments)self .pos_embedding.data[:, :X.shape[1 ], :]for blk in self .blks:return X
1 2 3 4 5 6 7 8 9 vocab_size, num_hiddens, ffn_num_hiddens, num_heads = 10000 , 768 , 1024 , 4 768 ], 768 , 2 , 0.2 0 , vocab_size, (2 , 8 ))0 , 0 , 0 , 0 , 1 , 1 , 1 , 1 ], [0 , 0 , 0 , 1 , 1 , 1 , 1 , 1 ]])None )
Masked Language Modeling 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class MaskLM (nn.Module):"""The masked language model task of BERT.""" def __init__ (self, vocab_size, num_hiddens, num_inputs=768 , **kwargs ):super (MaskLM, self ).__init__(**kwargs)self .mlp = nn.Sequential(nn.Linear(num_inputs, num_hiddens),def forward (self, X, pred_positions ):1 ]1 )0 ]0 , batch_size)1 ))self .mlp(masked_X)return mlm_Y_hat
The forward inference of MaskLM1 2 3 4 5 mlm = MaskLM(vocab_size, num_hiddens)1 , 5 , 2 ], [6 , 1 , 5 ]])
1 2 3 4 5 mlm_Y = torch.tensor([[7 , 8 , 9 ], [10 , 20 , 30 ]])'none' )1 , vocab_size)), mlm_Y.reshape(-1 ))
Next Sentence Prediction 1 2 3 4 5 6 7 8 class NextSentencePred (nn.Module):"""The next sentence prediction task of BERT.""" def __init__ (self, num_inputs, **kwargs ):super (NextSentencePred, self ).__init__(**kwargs)self .output = nn.Linear(num_inputs, 2 )def forward (self, X ):return self .output(X)
The forward inference of an NextSentencePred
1 2 3 4 5 encoded_X = torch.flatten(encoded_X, start_dim=1 )1 ])
1 2 3 4 5 nsp_y = torch.tensor([0 , 1 ])
Summary 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class BERTModel (nn.Module):"""The BERT model.""" def __init__ (self, vocab_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout, max_len=1000 , key_size=768 , query_size=768 , value_size=768 , hid_in_features=768 , mlm_in_features=768 , nsp_in_features=768 ):super (BERTModel, self ).__init__()self .encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape,self .hidden = nn.Sequential(nn.Linear(hid_in_features, num_hiddens),self .mlm = MaskLM(vocab_size, num_hiddens, mlm_in_features)self .nsp = NextSentencePred(nsp_in_features)def forward (self, tokens, segments, valid_lens=None , pred_positions=None ):self .encoder(tokens, segments, valid_lens)if pred_positions is not None :self .mlm(encoded_X, pred_positions)else :None self .nsp(self .hidden(encoded_X[:, 0 , :]))return encoded_X, mlm_Y_hat, nsp_Y_hat
The Dataset for Pretraining BERT
1 2 3 4 import osimport randomimport torchfrom d2l import torch as d2l
The WikiText-2 dataset:
1 2 3 4 5 6 7 8 9 10 11 12 d2l.DATA_HUB['wikitext-2' ] = ('https://s3.amazonaws.com/research.metamind.io/wikitext/' 'wikitext-2-v1.zip' , '3c914d17d80b1459be871a5039ac23e752a53cbe' )def _read_wiki (data_dir ):'wiki.train.tokens' )with open (file_name, 'r' ) as f:' . ' )for line in lines if len (line.split(' . ' )) >= 2 ]return paragraphs
Generating the Next Sentence Prediction Task:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def _get_next_sentence (sentence, next_sentence, paragraphs ):if random.random() < 0.5 :True else :False return sentence, next_sentence, is_nextdef _get_nsp_data_from_paragraph (paragraph, paragraphs, vocab, max_len ):for i in range (len (paragraph) - 1 ):1 ], paragraphs)if len (tokens_a) + len (tokens_b) + 3 > max_len:continue return nsp_data_from_paragraph
Generating the Masked Language Modeling Task
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 def _replace_mlm_tokens (tokens, candidate_pred_positions, num_mlm_preds, vocab ):for token in tokens]for mlm_pred_position in candidate_pred_positions:if len (pred_positions_and_labels) >= num_mlm_preds:break None if random.random() < 0.8 :'<mask>' else :if random.random() < 0.5 :else :0 , len (vocab) - 1 )return mlm_input_tokens, pred_positions_and_labelsdef _get_mlm_data_from_tokens (tokens, vocab ):for i, token in enumerate (tokens):if token in ['<cls>' , '<sep>' ]:continue max (1 , round (len (tokens) * 0.15 ))sorted (pred_positions_and_labels,lambda x: x[0 ])0 ] for v in pred_positions_and_labels]1 ] for v in pred_positions_and_labels]return vocab[mlm_input_tokens], pred_positions,vocab[mlm_pred_labels]
Append the special “” tokens to the inputs
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def _pad_bert_inputs (examples, max_len, vocab ):round (max_len * 0.15 )for (token_ids, pred_positions, mlm_pred_label_ids, segments,in examples:'<pad>' ]] * (len (token_ids)), dtype=torch.long))0 ] * (len (segments)), dtype=torch.long))len (token_ids), dtype=torch.float32))0 ] * (len (pred_positions)), dtype=torch.long))1.0 ] * len (mlm_pred_label_ids) + [0.0 ] * (len (pred_positions)),0 ] * (len (mlm_pred_label_ids)), dtype=torch.long))return (all_token_ids, all_segments, valid_lens, all_pred_positions,
The WikiText-2 dataset for pretraining BERT
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class _WikiTextDataset (torch.utils.data.Dataset):def __init__ (self, paragraphs, max_len ):'word' ) for paragraph in paragraphs]for paragraph in paragraphsfor sentence in paragraph]self .vocab = d2l.Vocab(sentences, min_freq=5 , reserved_tokens=['<pad>' , '<mask>' , '<cls>' , '<sep>' ])for paragraph in paragraphs:self .vocab, max_len))self .vocab)for tokens, segments, is_next in examples]self .all_token_ids, self .all_segments, self .valid_lens,self .all_pred_positions, self .all_mlm_weights,self .all_mlm_labels, self .nsp_labels) = _pad_bert_inputs(self .vocab)def __getitem__ (self, idx ):return (self .all_token_ids[idx], self .all_segments[idx],self .valid_lens[idx], self .all_pred_positions[idx],self .all_mlm_weights[idx], self .all_mlm_labels[idx],self .nsp_labels[idx])def __len__ (self ):return len (self .all_token_ids)
Download and WikiText-2 dataset and generate pretraining examples
1 2 3 4 5 6 7 8 9 def load_data_wiki (batch_size, max_len ):"""Load the WikiText-2 dataset.""" 'wikitext-2' , 'wikitext-2' )True , num_workers=num_workers)return train_iter, train_set.vocab
Print out the shapes of a minibatch of BERT pretraining examples
1 2 3 4 5 6 7 8 9 batch_size, max_len = 512 , 64 for (tokens_X, segments_X, valid_lens_x, pred_positions_X, mlm_weights_X,in train_iter:print (tokens_X.shape, segments_X.shape, valid_lens_x.shape,break
Pretraining BERT 1 2 3 4 5 6 import torchfrom torch import nnfrom d2l import torch as d2l512 , 64
A small BERT, using 2 layers, 128 hidden units, and 2 self-attention heads
1 2 3 4 5 6 7 net = d2l.BERTModel(len (vocab), num_hiddens=128 , norm_shape=[128 ],128 , ffn_num_hiddens=256 , num_heads=2 ,2 , dropout=0.2 , key_size=128 , query_size=128 ,128 , hid_in_features=128 , mlm_in_features=128 ,128 )
Computes the loss for both the masked language modeling and next sentence prediction tasks
1 2 3 4 5 6 7 8 9 10 11 12 13 def _get_batch_loss_bert (net, loss, vocab_size, tokens_X, segments_X, valid_lens_x, pred_positions_X, mlm_weights_X, mlm_Y, nsp_y ):1 ),1 , vocab_size), mlm_Y.reshape(-1 )) *\1 , 1 )sum () / (mlm_weights_X.sum () + 1e-8 )return mlm_l, nsp_l, l
Pretrain BERT (net) on the WikiText-2 (train_iter) dataset
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 def train_bert (train_iter, net, loss, vocab_size, devices, num_steps ):0 ])1e-3 )0 , d2l.Timer()'step' , ylabel='loss' ,1 , num_steps], legend=['mlm' , 'nsp' ])4 )False while step < num_steps and not num_steps_reached:for tokens_X, segments_X, valid_lens_x, pred_positions_X,\in train_iter:0 ])0 ])0 ])0 ])0 ])0 ]), nsp_y.to(devices[0 ])0 ], 1 )1 ,0 ] / metric[3 ], metric[1 ] / metric[3 ]))1 if step == num_steps:True break print (f'MLM loss {metric[0 ] / metric[3 ]:.3 f} , ' f'NSP loss {metric[1 ] / metric[3 ]:.3 f} ' )print (f'{metric[2 ] / timer.sum ():.1 f} sentence pairs/sec on ' f'{str (devices)} ' )len (vocab), devices, 50 )
Representing Text with BERT
1 2 3 4 5 6 7 def get_bert_encoding (net, tokens_a, tokens_b=None ):0 ]).unsqueeze(0 )0 ]).unsqueeze(0 )len (tokens), device=devices[0 ]).unsqueeze(0 )return encoded_X
Consider the sentence “a crane is flying”
1 2 3 4 5 tokens_a = ['a' , 'crane' , 'is' , 'flying' ]0 , :]2 , :]0 ][:3 ]
Now consider a sentence pair “a crane driver came” and “he just left”
1 2 3 4 5 tokens_a, tokens_b = ['a' , 'crane' , 'driver' , 'came' ], ['he' , 'just' , 'left' ]0 , :]2 , :]0 ][:3 ]
Bert Fine Tuning
上面的课程都是顺序在d2l的课程中,Bert Fine Tuning在一个新的位置:微调Bert D2L 教程 ,冲!
单文本分类
单文本分类 将单个文本序列作为输入,并输出其分类结果。 除了我们在这一章中探讨的情感分析之外,语言可接受性语料库(Corpus of Linguistic Acceptability,COLA)也是一个单文本分类的数据集,它的要求判断给定的句子在语法上是否可以接受。
BERT输入序列明确地表示单个文本和文本对,其中特殊分类标记“”用于序列分类,而特殊分类标记“”标记单个文本的结束或分隔成对文本。如 图15.6.1 所示,在单文本分类应用中,特殊分类标记“”的BERT表示对整个输入文本序列的信息进行编码。作为输入单个文本的表示,它将被送入到由全连接(稠密)层组成的小多层感知机中,以输出所有离散标签值的分布。
文本对分类或回归
文本对分类或回归应用的BERT微调,如自然语言推断和语义文本相似性(假设输入文本对分别有两个词元和三个词元)
以一对文本作为输入但输出连续值,语义文本相似度 是一个流行的“文本对回归”任务。 这项任务评估句子的语义相似度。例如,在语义文本相似度基准数据集(Semantic Textual Similarity Benchmark)中,句子对的相似度得分是从0(无语义重叠)到5(语义等价)的分数区间 (Cer et al. , 2017 )。
文本标注
文本标记应用的BERT微调,如词性标记。假设输入的单个文本有六个词元。
词元级任务,比如文本标注 (text tagging),其中每个词元都被分配了一个标签。在文本标注任务中,词性标注 为每个单词分配词性标记(例如,形容词和限定词)。
问答
为了微调BERT进行问答,在BERT的输入中,将问题和段落分别作为第一个和第二个文本序列。为了预测文本片段开始的位置,相同的额外的全连接层将把来自位置i的任何词元的BERT表示转换成标量分数$s_i$。文章中所有词元的分数还通过softmax转换成概率分布,从而为文章中的每个词元位置i分配作为文本片段开始的概率$p_i$。预测文本片段的结束与上面相同,只是其额外的全连接层中的参数与用于预测开始位置的参数无关。当预测结束时,位置i的词元由相同的全连接层变换成标量分数$e_i$。 图15.6.4 描述了用于问答的微调BERT。
对于问答,监督学习的训练目标就像最大化真实值的开始和结束位置的对数似然一样简单。当预测片段时,我们可以计算从位置i到位置j的有效片段的分数$s_i + e_j(i \leq j)$,并输出分数最高的跨度。
Summary
下游任务不同,使用Bert微调时,只需要增加输出层。
根据任务的不同,输入的表示和使用的Bert特征也会不一样。
自然语言推理数据集
1 2 3 4 5 6 7 8 9 10 11 import osimport reimport torchfrom torch import nnfrom d2l import torch as d2l'SNLI' ] = ('https://nlp.stanford.edu/projects/snli/snli_1.0.zip' ,'9fcde07509c7e87ec61c640c1b2753d9041758e4' )'SNLI' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def read_snli (data_dir, is_train ):"""Read the SNLI dataset into premises, hypotheses, and labels.""" def extract_text (s ):'\\(' , '' , s)'\\)' , '' , s)'\\s{2,}' , ' ' , s)return s.strip()'entailment' : 0 , 'contradiction' : 1 , 'neutral' : 2 }'snli_1.0_train.txt' if is_train else 'snli_1.0_test.txt' )with open (file_name, 'r' ) as f:'\t' ) for row in f.readlines()[1 :]]1 ]) for row in rows if row[0 ] in label_set]2 ]) for row in rows if row[0 ] in label_set]0 ]] for row in rows if row[0 ] in label_set]return premises, hypotheses, labels
1 2 3 4 5 train_data = read_snli(data_dir, is_train=True )for x0, x1, y in zip (train_data[0 ][:3 ], train_data[1 ][:3 ], train_data[2 ][:3 ]):print ('premise:' , x0)print ('hypothesis:' , x1)print ('label:' , y)
Labels “entailment”, “contradiction”, and “neutral” are balanced
1 2 3 test_data = read_snli(data_dir, is_train=False )for data in [train_data, test_data]:print ([[row for row in data[2 ]].count(i) for i in range (3 )])
Defining a Class for Loading the Dataset
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class SNLIDataset (torch.utils.data.Dataset):"""A customized dataset to load the SNLI dataset.""" def __init__ (self, dataset, num_steps, vocab=None ):self .num_steps = num_steps0 ])1 ])if vocab is None :self .vocab = d2l.Vocab(all_premise_tokens + all_hypothesis_tokens,5 , reserved_tokens=['<pad>' ])else :self .vocab = vocabself .premises = self ._pad(all_premise_tokens)self .hypotheses = self ._pad(all_hypothesis_tokens)self .labels = torch.tensor(dataset[2 ])print ('read ' + str (len (self .premises)) + ' examples' )def _pad (self, lines ):return torch.tensor([d2l.truncate_pad(self .vocab[line], self .num_steps, self .vocab['<pad>' ])for line in lines])def __getitem__ (self, idx ):return (self .premises[idx], self .hypotheses[idx]), self .labels[idx]def __len__ (self ):return len (self .premises)
Putting All Things Together
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def load_data_snli (batch_size, num_steps=50 ):"""Download the SNLI dataset and return data iterators and vocabulary.""" 'SNLI' )True )False )True ,False ,return train_iter, test_iter, train_set.vocab128 , 50 )len (vocab)
1 2 3 4 5 for X, Y in train_iter:print (X[0 ].shape)print (X[1 ].shape)print (Y.shape)break
Bert微调代码
1 2 3 4 5 6 import jsonimport multiprocessingimport osimport torchfrom torch import nnfrom d2l import torch as d2l
1 2 3 4 d2l.DATA_HUB['bert.base' ] = (d2l.DATA_URL + 'bert.base.torch.zip' ,'225d66f04cae318b841a13d32af3acc165f253ac' )'bert.small' ] = (d2l.DATA_URL + 'bert.small.torch.zip' ,'c72329e68a732bef0452e4b96a1c341c8910f81f' )
Load pretrained BERT parameters
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def load_pretrained_model (pretrained_model, num_hiddens, ffn_num_hiddens, num_heads, num_layers, dropout, max_len, devices ):open (os.path.join(data_dir, 'vocab.json' )))for idx, token in enumerate (len (vocab), num_hiddens, norm_shape=[256 ],256 , ffn_num_hiddens=ffn_num_hiddens,4 , num_layers=2 , dropout=0.2 ,256 , query_size=256 ,256 , hid_in_features=256 ,256 , nsp_in_features=256 )'pretrained.params' )))return bert, vocab'bert.small' , num_hiddens=256 , ffn_num_hiddens=512 , num_heads=4 ,2 , dropout=0.1 , max_len=512 , devices=devices)
The Dataset for Fine-Tuning BERT
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 class SNLIBERTDataset (torch.utils.data.Dataset):def __init__ (self, dataset, max_len, vocab=None ):for p_tokens, h_tokens in zip (for s in sentences])for sentences in dataset[:2 ]])]self .labels = torch.tensor(dataset[2 ])self .vocab = vocabself .max_len = max_lenself .all_token_ids, self .all_segments,self .valid_lens) = self ._preprocess(all_premise_hypothesis_tokens)print ('read ' + str (len (self .all_token_ids)) + ' examples' )def _preprocess (self, all_premise_hypothesis_tokens ):4 )map (self ._mp_worker, all_premise_hypothesis_tokens)for token_ids, segments, valid_len in out]for token_ids, segments, valid_len in out]for token_ids, segments, valid_len in out]return (torch.tensor(all_token_ids, dtype=torch.long),def _mp_worker (self, premise_hypothesis_tokens ):self ._truncate_pair_of_tokens(p_tokens, h_tokens)self .vocab[tokens] + [self .vocab['<pad>' ]] \self .max_len - len (tokens))0 ] * (self .max_len - len (segments))len (tokens)return token_ids, segments, valid_lendef _truncate_pair_of_tokens (self, p_tokens, h_tokens ):while len (p_tokens) + len (h_tokens) > self .max_len - 3 :if len (p_tokens) > len (h_tokens):else :def __getitem__ (self, idx ):return (self .all_token_ids[idx], self .all_segments[idx],self .valid_lens[idx]), self .labels[idx]def __len__ (self ):return len (self .all_token_ids)
1 2 3 4 lr, num_epochs = 1e-4 , 5 'none' )
References
Attention D2L Self Attention & Transformer 李宏毅 Self-supervised Learing BERT GPT 李宏毅 Attention Q&A Attention Seq2Seq Q&A Transformer Q&A Bert Q&A 微调Bert D2L 教程 Bert微调 Q&A