NJUOS-7-真实世界的并发编程
本文最后更新于:2 年前
前面的各种东西都学过了,这里其实我们就可以有写一个完整的并发程序的能力了。真实世界中,并发&并行编程的实现与应用。
高性能计算中的并发编程
什么是高性能计算
“A technology that harnesses the power of supercomputers or computer clusters to solve complex problems requiring massive computation.” (IBM)
- Calculating & Simulating
- 以计算为中心
- 系统模拟:天气预报,分子、能源生物学。
- 人工智能:神经网络训练
- 矿场:纯粹的hash计算
- HPC-China 100
- Block Chain
主要挑战
计算任务如何分解
- 计算图需要容易并行化
- 机器-线程两级任务分解
- 生产者-消费者解决一切
线程间如何通信:通信不仅发生在节点/线程之间,还发生在任何共享内存访问。
并发直观感受
mandelbrot.c
1 | |
数据中心里的并发编程
“A network of computing and storage resources that enable the delivery of shared applications and data.” (CISCO)
- Storing & Analysing
以数据(存储为中心)
以数据 (存储) 为中心
- 从互联网搜索 (Google)、社交网络 (Facebook/Twitter) 起家
- 支撑各类互联网应用:微信/QQ/支付宝/游戏/网盘/……
算法/系统对HPC和数据中心的意义
- 你有 1,000,000 台服务器
- 如果一个算法/实现能快 1%,就能省 10,000 台服务器
- 参考:对面一套房 ≈ 50 台服务器 (不计运维成本)
主要挑战
多副本情况下的高可靠、低延迟数据访问(CAP)
- 在服务海量地理分布请求的前提下
- 数据要保持一致 (Consistency)
- 服务时刻保持可用 (Availability)
- 容忍机器离线 (Partition tolerance)

本门课的问题:如何用好一台计算机
如何用一台 (可靠的) 计算机尽可能多地服务并行的请求
- 关键指标:QPS, tail latency, …
我们有的工具:
- 线程 (threads)
1 | |
线程的切换需要代价的,切换的时候的代价:
- 寄存器(ALL)
- CPU重新调度
- 新的线程的寄存器装入CPU中
- 协程 (coroutines)
- 多个可以保存/恢复的执行流 (M2 - libco)
- 比线程更轻量 (完全没有系统调用,也就没有操作系统状态)
黑科技(小实验)
M2 - libco:可以自己在C语言里面创建多个状态机,并通过co_yield()的方式,主动放弃CPU使用权,让另外的任务使用。
为什么协程开销比线程小很多呢?
- 协程切换 -> co_yield() …. call co_yield -> 函数调用遵循x86-64的calling conventions
在函数里面,CPU不能随便把寄存器摧毁的,CPU不是切换哈,是通过调用函数的方式,实现切换的!!!这个时候,不是所有计算器里面的内容,都要保存的。
- 调用co_yield的时候,该保存的东西,都应该保存好了。
co_yield的切换:
- 寄存器
- 栈
不需要进操作系统兜一圈,有很多好处。
协程和线程
数据中心
- 同一时间有数千/数万个请求到达服务器
- 计算部分
- 需要利用好多处理器
- 线程 → 这就是我擅长的 (Mandelbrot Set)
- 协程 → 一人出力,他人摸鱼
- 需要利用好多处理器
- I/O 部分
- 会在系统调用上 block (例如请求另一个服务或读磁盘)
- 协程 → 一人干等,他人围观
- 线程 → 每个线程都占用可观的操作系统资源
- 会在系统调用上 block (例如请求另一个服务或读磁盘)
- (这个问题比你想象的复杂,例如虚拟机)
线程&协程对比
- 线程:每个线程都占用可观的操作系统资源,内存+寄存器,可能就要8KB…,占用资源好大,比协程大的多。
- 协程:
- 协程不受操作系统调度,调度逻辑由用户的co_yield()主动进行。一个线程里面一次只能运行一个协程。
- 如果协程发起了远程RPC调用,协程可能会等RPC结果,从而造成CPU空转。由于操作系统不感知协程,分配给线程对应的时间片就是线程执行任务的,这样导致。如果我们的协程不好好干活,我们的CPU就在公转。
在我看来,线程是“运行的主体”。由于线程与线程的切换开销很大。我们可能的做法是,减少线程切换的次数,用户不断的,在一个运行的线程上,切换协程(任务序列)。
- 自己的感受:
- 协程其实就是一个一个用户任务的实体,放在操作系统提供的线程上去进行执行,由用户控制任务的进度和切换。
- 还会遇到的问题:协程(当前执行的任务序列),如果执行到了read()指令,那么协程就会把线程阻塞。协程如果等数据,那么CPU就被浪费掉了,其他携程执行不了。
协程解决方案(Go&Goroutine)
Go: 小孩子才做选择,多处理器并行和轻量级并发我全都要!
每个 CPU 上有一个 Go Worker,自由调度 goroutines
执行到 blocking API 时 (例如 sleep, read)
- Go Worker 偷偷改成 non-blocking 的版本
- 成功 → 立即继续执行
- 失败 → 立即 yield 到另一个需要 CPU 的 goroutine
- 太巧妙了!CPU 和操作系统全部用到 100%
- Go Worker 偷偷改成 non-blocking 的版本
自己的理解:Golang在每个CPU/核心上,绑定一个Go Worker线程 -> 协程在进行操作系统耗时的调用的时候,就会迅速进行切换调度昂!
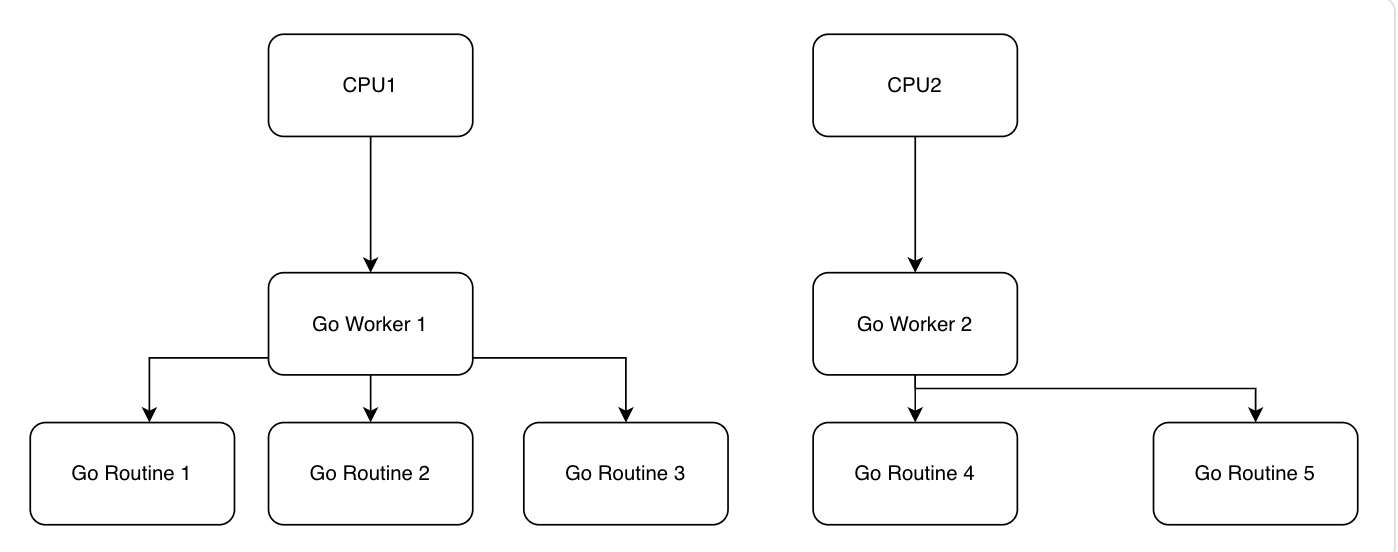
- 比如现在Go Routine 1现在要执行一个read(),Go Routine 1里面这个,是会阻塞系统的这种系统调用。调用的是
- Go Worker 1偷偷把这个read-blocking()版本的系统调用,改成read-non-blocking()的版本,再去帮我们去进行系统调用。(例如非同步非阻塞版本)
- Go Worker 1发现 Go Routine 1的数据没有到…
- Go Worker 1调度另外的Go Routine 2/Go Routine 3执行。
- Go Routine 1的数据来了,Go Worker 1可能会重新调度Go Routine 1进行执行。
- Go能够轻易的调度,创建几百万个Goroutine也就轻轻松松。。。Go的调度器能够帮我们管理好这些Goroutine。 -> 其实最多能够并行执行的数量,也就是核数(如果一个CPU一个核,也就是CPU的数量)
- Go已经把开销降到最低了,操作系统甚至都不会在两个Go线程之间切换。同一个Go Worker管理的,所有的Goroutine,都是挂载在这个Go Worker上执行的。Goroutine概念上是线程,实际上是协程。
现代编程语言上的系统编程Golang
学的难,但是我们平常写是不用写的昂!!!
- 实现汇编最底下的东西,真正要写某些内容的时候 -> 技术选型可能不会采用这些底层的,上层的Java or Golang之类的。
Do not communicate by sharing memory; instead, share memory by communicating. ——Effective Go
共享内存 = 万恶之源
- 在奇怪调度下发生的各种并发 bugs
- 条件变量:broadcast 性能低,不 broadcast 容易错
- 信号量:在管理多种资源时就没那么好用了
既然生产者-消费者能解决绝大部分问题,提供一个 API 不就好了?-> Channel的诞生,对于上面的东西,提供了抽象。不要尝试用共享内存(条件变量,信号量)来实现同步,用Golang提供的Channel来实现,简单安全!!!
- producer-consumer.go
- 缓存为 0 的 channel 可以用来同步 (先到者等待)
1 | |
channel这种东西,本质上就是对于生产者消费者模式的封装。Go底层保证了管道的安全,就很简单实用。
- Go解决的两个大问题:
- Goroutine的模型,线程+协程,解决了高并发IO的问题。
- 语言内建的机制,解决了并发编程的问题。
我们身边的编程
2000年之前的互联网:只能看,交互性很弱。
Web 2.0 时代 (1999)
人与人之间联系更加紧密的互联网
“Users were encouraged to provide content, rather than just viewing it.”
你甚至可以找到一些 “Web 3.0”/Metaverse/Decentralization 的线索 -> 交互性,互动性进一步增强!!!
是什么成就了今天的 Web 2.0?
浏览器中的并发编程:Ajax (Asynchronous JavaScript + XML)
HTML (DOM Tree) + CSS 代表了你能看见的一切
- 通过 JavaScript 可以改变它
- 通过 JavaScript 可以建立连接本地和服务器
- 你就拥有了全世界!
人机交互程序:特点和主要挑战
特点:不太复杂
既没有太多计算(和上面的数据中心和高性能计算相比)
- DOM Tree 也不至于太大 (大了人也看不过来)
- DOM Tree 怎么画浏览器全帮我们搞定了
也没有太多 I/O
- 就是一些网络请求
挑战:程序员多
零基础的人你让他整共享内存上的多线程
恐怕我们现在用的到处都是 bug 吧???
解决问题的模型:
单线程+事件模型
尽可能少但又足够的并发
- 一个线程、全局的事件队列、按序执行 (run-to-complete)
- 耗时的 API (Timer, Ajax, …) 调用会立即返回
- 条件满足时向队列里增加一个事件
1 | |
一个事件:一旦开始执行,它就要执行到结束(单线程,避免了并发的bug)
- 网络请求很久,事件太长了不好!!!因此搭配事件,出现了ajax,发起请求,同时根据异步的不同结果,注册处理的函数。 -> 单线程的模型!!!也就是异步事件模型。
异步事件模型
好处
并发模型简单了很多
- 函数的执行是原子的 (不能并行,减少了并发 bug 的可能性)
API 依然可以并行
- 适合网页这种 “大部分时间花在渲染和网络请求” 的场景
- JavaScript 代码只负责 “描述” DOM Tree
- 适合网页这种 “大部分时间花在渲染和网络请求” 的场景
坏处
- Callback hell (祖传屎山)
- 刚才的代码嵌套 5 层,可维护性已经接近于零了
- Callback hell (祖传屎山)
异步事件模型,减少了bug的可能性。API依然可以并行,但浏览器会帮我们全部处理好。非常适合网页!!!
- 解决Callback Hell这种问题,还有更好的模型:异步编程模型
异步编程:Promise
导致 callback hell 的本质:人类脑袋里想的是 “流程图”,看到的是 “回调”。
The Promise object represents the eventual completion (or failure) of an asynchronous operation and its resulting value.
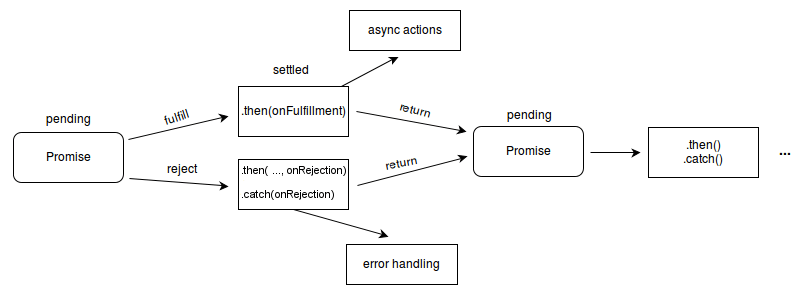
Promise: 流程图的构造方法 (Mozilla-MDN Docs)

- 可以用语言来描述上面的流程图关系!
Async-Await: Even Better
async function
- 总是返回一个
Promiseobject async_func()- fork
await promise
await promise- join
1 | |
比上面那种疯狂嵌套,看起来舒服多了…

Golang的GPM模型补充
References
- video link: https://www.bilibili.com/video/BV1cS4y1r7gw/?spm_id_from=333.999.0.0&vd_source=ff957cd8fbaeb55d52afc75fbcc87dfd
- PPT: http://jyywiki.cn/OS/2022/slides/7.slides#/
- 并发编程相关教材,这本读完就够啦:Parallel and Distributed Computation: Numerical Methods
- M2-libco: http://jyywiki.cn/OS/2022/labs/M2
- go语言GPM模型:https://zhuanlan.zhihu.com/p/261807834