CPU Cache 进阶学习
本文最后更新于:2 年前
补充一下,之前对于CPU Cache很多认知都还不到位。其实MESI还没有到尽头,
MESI协议补充
Write Invalidate & Write Broadcast
- MESI是一种写失效(Write Invalidate)协议
- 当一个CPU写入数据时
- 在这个CPU核心写入Cache之后,它会去广播一个“失效”请求告诉所有其他的CPU核心。
- 其他的CPU核心,只是去判断自己是否也有一个“失效”版本的Cache line,然后把这个也标记成失效
- 相对的,也有一种写广播(Write Broadcast)协议:一个写入请求广播到所有的CPU核心,同时更新各个核心里的Cache line
- 写失效只需要告诉其他的CPU核心,哪一个地址失效了
- 但是写广播还需要把对应的数据传输给其他CPU核心,而写广播需要占用更多的总线带宽
总线嗅探机制
Snoopy 协议,帮助实现MESI协议,这种协议更像是一种数据通知技术,CPU和内存通过总线(BUS)互通消息。
CPU感知其他CPU的行为(比如读、写某个缓存行)就是是通过嗅探(Snoop)其他CPU发出的请求消息完成的。
CPU Cache 通过这个协议可以识别其它Cache上的数据状态。有时CPU也需要针对总线中的某些请求消息进行响应,如果有数据共享的话,可以通过广播机制将共享数据的状态通知给其它 CPU Cache。这个协议要求每个 CPU Cache 都可以窥探数据事件的通知并做出相应的反应。
缓存一致性
代价
每个内核都有自己所需的cache line的副本,取值运算都在副本中进行。这就是为什么多线程应用中内存的变化会造成性能噩梦。
当并行的多个线程正在访问相同的数据值,甚至是相邻的数据值时,它们将访问同一cache line上的数据。
为了提高写的性能,主流的 CPU采用的是 Write Back 的策略:写操作先在 cache 上,然后再 flush 到内存上
- 如果某个核心上的一个线程对其cache line的副本进行了更改,那么根据总线MESI协议,同一cache line的所有其他副本都必须标记为失效。当线程尝试对dirty cache line进行读写访问时,需要放弃此次cache line访问,转而向主存访问(大约 100 到 300 个时钟周期)来获得cache line的新副本,以保证数据的一致性。
- 也许在一个 2 核处理器上这不是什么大问题,但是如果一个 32 核处理器在同一cache line上同时运行 32 个线程来访问和改变数据,那会发生什么?处理器到处理器的通信延迟更大。应用程序将会在主存中周转,性能将会大幅下降。
可见性
- 从性能角度考虑,没有必要在修改后就立即flush修改的值——如果多次修改后才使用,那么只需要最后一次同步即可,在这之前的同步都是性能浪费。因此,可见性的定义要弱一些,只需要保证:当一个线程修改了线程共享变量的值,其它线程在使用前,能够得到最新的修改值。
可见性可以认为是最弱的“一致性”(弱一致),只保证用户见到的数据是一致的,但不保证任意时刻,存储的数据都是一致的(强一致)。
- 各种高级语言(包括Java)的多线程内存模型中,在线程栈内自己维护一份缓存是常见的优化措施,但显然在CPU级别的缓存一致性问题面前,一切都失效了。
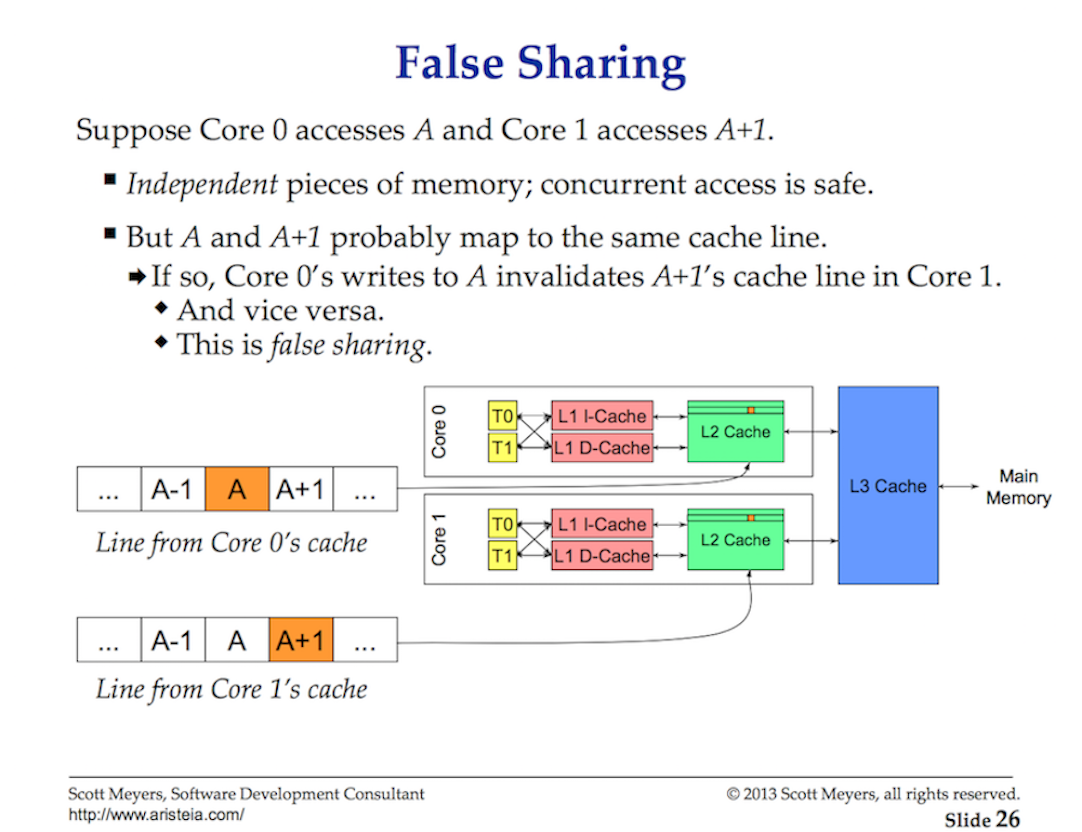
伪共享问题
当一个处理器改变了属于它自己缓存中的一个值,其它处理器就再也无法使用它自己原来的值,因为其对应的内存位置将被刷新(invalidate)到所有缓存。而且由于缓存操作是以缓存行而不是字节为粒度,所有缓存中整个缓存行将被刷新!
举个例子
- 如果线程A要对变量a进行操作,于是以64bit的大小将a和其附近的所有变量都装入cache line
- 此时B要对b进行操作,于是也以64bit的大小将b和其附近的所有变量都装入cache line
- 如果a紧邻b,根据局部性原理,这两个变量共享共享了缓存行
- 线程A对a进行修改后,将a写回主存,那么B的缓存行就失效了(B:我还没操作呢,怎么就失效了)
- B就只能乖乖从主存再加载数据,大大影响了性能,这就出现了伪共享问题
1 | |
解决思路:以空间换时间,让不同线程操作的不相干变量加载到不同缓存行,避免相互影响
变量 value 前后分别填充了 7 个 long 类型的变量,这样不论在什么情况下,都可以保证在多线程访问 value 变量时,value 与其他不相关的变量处于不同的 Cache Line。
重排序
重排序总体上可以分为两种
- 真重排序:编译器、底层硬件(CPU等)出于“优化”的目的,按照某种规则将指令重新排序(尽管有时候看起来像乱序)
- 伪重排序:由于缓存同步顺序等问题,看起来指令被重排序了
- CPU也算是一个编译器,NJU的OS上讲过,CPU会对于汇编 -> uOps微指令进行翻译并重排(底层维护了一个DAG)
真重排序
处理器层面的乱序优化节省了大量等待时间,提高了处理器的性能。
所谓“乱序”只是被叫做“乱序”,实际上也遵循着一定规则:只要两个指令之间不存在数据依赖,就可以对这两个指令乱序。不必关心数据的精准性
简而言之:只要不影响程序单线程、顺序执行的结果,就可以对两个指令重排序。
不进行乱序优化时,处理器的指令执行过程如下:
- 指令获取。
- 如果输入的运算对象是可以获取的(比如已经存在于寄存器中),这条指令会被发送到功能单元。如果运算对象在当前的时间片中是不可获取的(通常需要从主内存获取),处理器会开始等待直到它们是可以获取的。
- 指令在功能单元中被执行
- 功能单元将运算结果写回寄存器
乱序优化下的执行过程如下:
- 指令获取。
- 指令被发送到一个指令序列(也称执行缓冲区或者保留站)中。
- 指令将在序列中等待,直到它的数据运算对象是可以获取的。然后,指令被允许在先进入的旧指令之前离开序列缓冲区。(此处表现为乱序)
- 指令被分配给功能单元并执行。
- 将结果放到一个序列中。
- 仅当所有该指令之前的指令都将他们的结果写入寄存器后,这条指令的结果才会被写入寄存器中。
总结:使用指令序列实现乱序执行,先执行可获取运算对象的指令。再使用序列让结果按顺序写入寄存器,重新整理乱序结果。当然,为了实现乱序优化,还需要很多技术的支持,如寄存器重命名、分枝预测等,但大致了解到这里就足够
- 编译器提供的优化:
JVM自己维护的内存模型中也有可见性问题,使用volatile做标记,就解决了JVM层面的可见性问题。编译器产生的重排序也采用了同样的思路。
编译器为什么要重排序呢?和处理器乱序执行的目的是一样的:与其等待阻塞指令(如等待缓存刷入)完成,不如先去执行其他指令。与处理器乱序执行相比,编译器重排序能够完成更大范围、效果更好的乱序优化。
幸运的是,编译器层面的重排序,自然可以由编译器控制。使用volatile做标记,就可以禁用编译器层面的重排序。
这里提一嘴NJU OS课程上,在C语言里面通过asm加入compiler barrier,只能完成编译器层面的禁止指令重排序,CPU还是重排序了。如果要CPU禁止重排,要使用mfence作为memory barrier才可以昂!!!
伪重排序
假定一种场景
- Core0先更新缓存中的v1,再更新缓存中的v2(位于两个缓存行,这样淘汰缓存行时不会一起写回内存)。
- Core0读取v1(使用LRU淘汰缓存),然后长时间并未读取v2
- Core0的缓存满,此时将最久未使用的v2写回内存。
- Core1的缓存中本来存有v1,现在将v2加载入缓存。
Core1中v1是老v1,但是v2是新v2。但是更新顺序是新v1,再新v2,因此产生了不同!!!
此时,尽管“更新v1”早于“更新v2”发生,但Core1只看到了v2的最新值,却看不到v1的最新值。
这属于可见性导致的伪重排序:虽然没有实际上没有重排序,但看起来发生了重排序。
所以缓存可见性不仅仅导致可见性问题,还会导致伪重排序。
- 就是在这里,我向森洋提出了我的问题,为什么MESI的保证下,还会出现这种情况呢? -> 我的提问:
- Core1里面的v1对应的值是invalidate,在Core0执行完更新操作,所有其他CPU,只要缓存中,含有v1,全部会被置为Invalidate,这个时候,v1的值不是最新的值,在Core1需要读取或者写入(也就是用到V1)的时候,它会重新从内存中取最新的V1,我就感觉,这里讲的有点牵强……虽然顺序不一样,但是其实老的v1压根也用不上,始终会用最新的v1呀。
- 对哦,既然现有的CPU实现好的MESI就能保证这些的,那还要Memory Barrier,干什么呢?
Memory Barrier
好的总结(摘抄):CPU 从单核发展为多核,增加缓存,导致出现了多个核间的缓存一致性问题 –> 为了解决缓存一致性问题,提出了 MESI 协议 –> 完全遵守 MESI 又会给 CPU 带来性能问题 –> CPU 设计者又增加 store buffer 和 invalid queue –> 又导致了缓存的顺序一致性变为了弱缓存一致性 –> 需要缓存的顺序一致性的,就需要软件工程师自己在合适的地方添加内存屏障
Why Memory Barriers?
到底是什么原因导致CPU的设计者把memory barrier这样的大招强加给可怜的,不知情的SMP软件设计者?
一言以蔽之,性能,因为对内存访问顺序的重排可以获取更好的性能,如果某些场合下,程序的逻辑正确性需要内存访问顺序和program order一致,例如:同步原语,那么SMP软件工程师可以使用memory barrier这样的工具阻止CPU对内存访问的优化。
如果你想了解更多,需要充分理解CPU cache是如何工作的以及如何让CPU cache更好的工作,本文的主要内容包括:
- 描述cache的结构
- 描述cache-coherency protocol如何保证cache一致性
- 描述store buffers和invalidate queues如何获取更好的性能
1. Cache结构
Read Cache
- CPU cache和memory系统使用固定大小的数据块来进行交互,这个数据块被称为cache line,cache line的size一般是2的整数次幂,根据设计的不同,从16B到256B不等。当CPU首次访问某个数据的时候,它没有在cpu cache中,我们称之为cache miss(更准确的说法是startup或者warmup cache miss)。在这种情况下,cpu需要花费几百个cycle去把该数据对应的cacheline从memory中加载到cpu cache中,而在这个过程中,cpu只能是等待那个耗时内存操作完成。一旦完成了cpu cache数据的加载,随后的访问会由于数据在cache中而使得cpu全速运行。
- 运行一段时间之后,cpu cache的所有cacheline都会被填充有效的数据,这时候的,要加载新的数据到cache中必须将其他原来有效的cache数据“强制驱离”(一般选择最近最少使用的那些cacheline)。这种cache miss被称为capacity miss,因为CPU cache的容量有限,必须为新数据找到空闲的cacheline。有的时候,即便是cache中还有idle的cacheline,旧的cache数据也会被“强制驱离”,以便为新的数据加载到cacheline中做准备。当然,这是和cache的组织有关。size比较大的cache往往实现成hash table(为了硬件性能),所有的cache line被分成了若干个固定大小的hash buckets(更专业的术语叫做set),这些hash buckets之间不是形成链表,而是类似阵列,具体如下图所示:
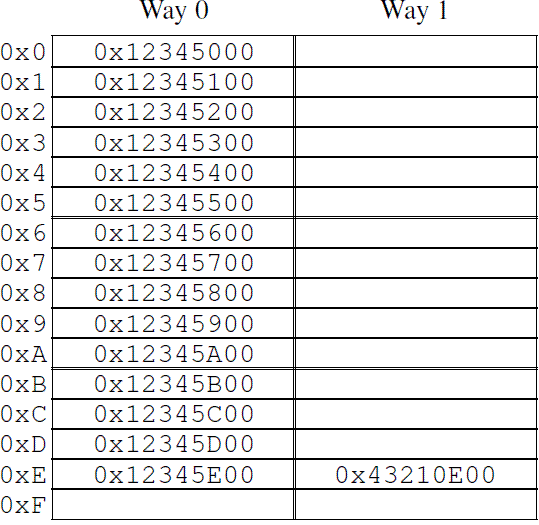
- 图中的cache一共有32个cacheline,被组织成16个set,每个set有2个可选的cacheline,分别称之为way 0和way 1。每个cacheline有256个Byte,在cache和memory交互cacheline的时候,要求cache line中数据地址对齐在256个字节上。256B的cacheline size稍显大了一点,主要是为了16进制的算法简单一些,实际中,level 0的cpu cache一般没有这么大。如果用专业术语来说的话,上面的这种cache被称为two-way set-associative cache。这种cache的组织类似软件中的有16个buckets的hash table,每个buckets(注意,这里是复数)中有两个bucket,最多可以放两个数据元素。total cache size(32个cache line)以及associativity(2 way)被称为cache的几何结构。由于是硬件实现,因此hash function(选择哪一个buckets)非常简单:从memory address中选择4个bit即可。
在上图中,每一个cell表示一个cache line,保存256B数据,空的cell表示该cacheline中没有数据,是idle状态的,缓存数据的cacheline标记了其保存数据对应的memory address。由于有256B对齐的要求,因此地址的低8位都是0,而8~11这四个bit用来选择set。高位基本一致,冲突严重,2^4 = 16,刚好映射到16个Set中,每个Set有两个Way,可以存两个Cache Line,通过这种方式。Memory -> Cache Set -> Cache Line。
- 当程序顺序访问了0x12345000 到0x12345EFF之间的数据的时候,cache中的前15个set的way 0 cacheline被加载了数据。随后对0x43210E00 到0x43210EFF数据的访问,导致cache的第15个set的way 1 cacheline也被加载的数据。OK,上图中的cache的状态就是这样的。这时候,我们一起看看后续cache的操作情况。如果程序访问0x1233000地址的数据,那么set 0被选中,由于way 0已经是保存了数据,因此way 1被用来缓存本次数据访问的内容。如果程序访问0x12345F00地址的数据,那么set 15被选中,由于way 0和way 1都是idle的,因此way 0被用来缓存本次数据访问的内容。但是,如果访问0x1233E00这个地址开始的256B数据块的时候,问题来了,这时候,set 14(0xE)已经满了,way 0和way 1这两个cacheline都加载了数据,怎么办?当然是把其中之一赶出去,为新来的数据让出地方。如果被赶出去的数据随后又被访问,这时候的cache miss被称为associativity miss。
Write Cache
到目前为止,我们只考虑了CPU读取数据的情况,如果写入数据会怎样呢?在某个CPU写入数据之前,有一点很重要,即所有的CPU需要对该数据的内容达成共识。因此,A cpu写入之前,需要先将其他cpu cache中的数据设定为无效。只有这个操作完成之后,A cpu才能安全的写入数据,而不会造成一致性的问题。如果该数据已经在A cpu的cache中,但是是read only的,这时候,该cpu不能直接操作cacheline中的对应的数据(因为是read only的),这种cache miss被叫做write miss。一旦A cpu完成了invalidate其他cpu cache中的数据,该cpu可以不断的写或者读取其cache中的数据。(注意:为了表述方便,我这里给指定cpu命名为A)
稍后,如果其他cpu也要访问该数据,由于其他CPU的cache数据已经被设置为无效,因此,其他cpu的访问会导致cache miss。之所以如此,是因为前面A CPU在写入数据的时候,将其他CPU的cache数据设置为无效,这种cache miss被称为communication miss。之所以称为communication miss,是因为这种cache miss的发生是由于多个CPU使用共享内存进行通信(例如:互斥算法中的lock)。
毫无疑问,系统中的各个CPU在进行数据访问的时候有自己的视角(通过自己的cpu cache),因此小心的维持数据的一致性变得非常重要。如果不仔细的进行设计,有可能在各个cpu这对自己特定的CPU cache进行加载cacheline、设置cacheline无效、将数据写入cacheline等动作中,把事情搞糟糕,例如数据丢失,或者更糟糕一些,不同的cpu在各自cache中看到不同的值。这些问题可以通过cachecoherency protocols来保证,也就是下一节的内容。
2. Cache Coherency Protocols
这篇论文讲的好,我再啰嗦摘抄一下
MESI状态
- MESI协议:
- M: 处于modified状态的cacheline说明近期有过来自对应cpu的写操作,同时也说明该该数据不会存在其他cpu对应的cache中。因此,处于modified状态的cacheline也可以说是被该CPU独占。而又因为只有该CPU的cache保存了最新的数据(最终的memory中都没有更新),所以,该cache需要对该数据负责到底。例如根据请求,该cache将数据及其控制权传递到其他cache中,或者cache需要负责将数据写回到memory中,而这些操作都需要在reuse该cache line之前完成。
- E: exclusive状态和modified状态非常类似,唯一的区别是对应CPU还没有修改cacheline中的数据,也正因为还没有修改数据,因此memory中对应的data也是最新的。在exclusive状态下,cpu也可以不通知其他CPU cache而直接对cacheline进行操作,因此,exclusive状态也可以被认为是被该CPU独占。由于memory中的数据和cacheline中的数据都是最新的,因此,cpu不需对exclusive状态的cacheline执行写回的操作或者将数据以及归属权转交其他cpu cache,而直接reuse该cacheline(将cacheine中的数据丢弃,用作他用)。
- S: 处于share状态的cacheline,其数据可能在一个或者多个CPU cache中,因此,处于这种状态的cache line,CPU不能直接修改cacheline的数据,而是需要首先和其他CPU cache进行沟通。和exclusive状态类似,处于share状态的cacheline对应的memory中的数据也是最新的,因此,cpu也可以直接丢弃cacheline中的数据而不必将其转交给其他CPU cache或者写回到memory中。
- I: 处于invalid状态的cacheline是空的,没有数据。当新的数据要进入cache的时候,优选状态是invalid的cacheline,之所以如此是因为如果选中其他状态的cacheline,则说明需要替换cacheline数据,而未来如果再次访问这个被替换掉的cacheline数据的时候将遇到开销非常大的cache miss。
由于所有的CPU需要通过其cache看到一致性的数据,因此cache-coherence协议被用来协调cacheline数据在系统中的移动。
MESI Protocol Messages
- MESI Protocol Messages(在上节中描述的各种状态的迁移需要CPU之间的通信,如果所有CPU都是在一个共享的总线上的时候,下面的message就足够了):
- Read,read message用于获取指定物理地址上的cacheline数据。
- Read Response,该消息携带了read message请求的数据。read response可能来自memory,也可能来自其他的cache。例如:如果一个cache有read message请求的数据并且该cacheline的状态是modified,那么该cache必须以read response回应这个read message,因为该cache中保存了最新的数据。(modified的数据,不一定及时刷回memory昂!)
- Invalidate,该命令用来将其他cpu cache中的数据设定为无效。该命令携带物理地址的参数,其他CPU cache在收到该命令后,必须进行匹配,发现自己的cacheline中有该物理地址的数据,那么就将其移除并用Invalidate Acknowledge回应。
- Invalidate Acknowledge。收到invalidate message的cpu cache,在移除了其cache line中的特定数据之后,必须发送invalidate acknowledge消息。
- Read Invalidate。该message中也包括了物理地址这个参数,以便说明其想要读取哪一个cacheline数据。此外,该message还同时有invalidate message的功效,即其他的cache在收到该命令后,移除自己cacheline中的数据。因此,Read Invalidate message实际上就是read + invalidate。发送Read Invalidate之后,cache期望收到一个read response以及多个invalidate acknowledge。
- Writeback。该message包括两个参数,一个是地址,另外一个是写回的数据。该消息用在modified状态的cacheline被驱逐出境(给其他数据腾出地方)的时候发出,该命名用来将最新的数据写回到memory(或者其他的CPU cache中)。
有意思的是基于共享内存的多核系统其底层是基于消息传递的计算机系统。这也就意味着由多个SMP机器组成的共享内存的cluster系统在两个不同的level上使用了消息传递机制,一个是SMP内部的message passing,另外一个是SMP机器之间的。
MESI State Diagram
单条总线的好处:状态只能一步一步转换,不会出现冲突。同一时刻,只有一个CPU能使用总线,并对全局的状态做出改变。
根据protocol message的发送和接收情况,cacheline会在“modified”, “exclusive”, “shared”, 和 “invalid”这四个状态之间迁移,具体如下图所示:
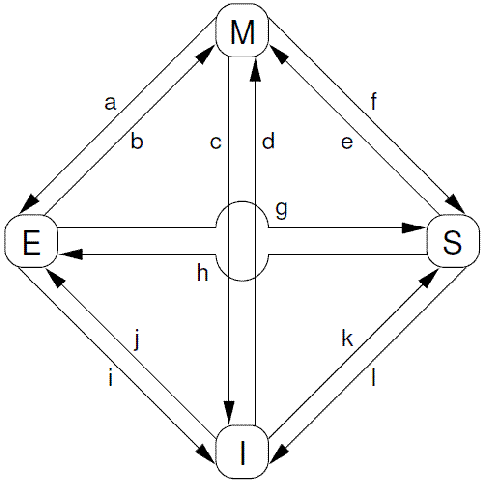
- Transition (a):cache可以通过writeback transaction将一个cacheline的数据写回到memory中(或者下一级cache中),这时候,该cacheline的状态从Modified迁移到Exclusive状态。对于cpu而言,cacheline中的数据仍然是最新的,而且是该cpu独占的,因此可以不通知其他cpu cache而直接修改之。
- Transition (b):在Exclusive状态下,cpu可以直接将数据写入cacheline,不需要其他操作。相应的,该cacheline状态从Exclusive状态迁移到Modified状态。这个状态迁移过程不涉及bus上的Transaction(即无需MESI Protocol Messages的交互)。
- Transition (c):CPU 在总线上收到一个read invalidate的请求,同时,该请求是针对一个处于modified状态的cacheline,在这种情况下,CPU必须该cacheline状态设置为无效,并且用read response和invalidate acknowledge来回应收到的read invalidate的请求,完成整个bus transaction。一旦完成这个transaction,数据被送往其他cpu cache中,本地的copy已经不存在了。
- Transition (d):CPU需要执行一个原子的readmodify-write操作,并且其cache中没有缓存数据,这时候,CPU就会在总线上发送一个read invalidate用来请求数据,同时想独自霸占对该数据的所有权。该CPU的cache可以通过read response获取数据并加载cacheline,同时,为了确保其独占的权利,必须收集所有其他cpu发来的invalidate acknowledge之后(其他cpu没有local copy),完成整个bus transaction。
- Transition (e):CPU需要执行一个原子的readmodify-write操作,并且其local cache中有read only的缓存数据(cacheline处于shared状态),这时候,CPU就会在总线上发送一个invalidate请求其他cpu清空自己的local copy,以便完成其独自霸占对该数据的所有权的梦想。同样的,该cpu必须收集所有其他cpu发来的invalidate acknowledge之后,才算完成整个bus transaction。
- Transition (f):在本cpu独自享受独占数据的时候,其他的cpu发起read请求,希望获取数据,这时候,本cpu必须以其local cacheline的数据回应,并以read response回应之前总线上的read请求。这时候,本cpu失去了独占权,该cacheline状态从Modified状态变成shared状态(有可能也会进行写回的动作)。
- Transition (g):这个迁移和f类似,只不过开始cacheline的状态是exclusive,cacheline和memory的数据都是最新的,不存在写回的问题。总线上的操作也是在收到read请求之后,以read response回应。
- Transition (h):如果cpu认为自己很快就会启动对处于shared状态的cacheline进行write操作,因此想提前先霸占上该数据。因此,该cpu会发送invalidate敦促其他cpu清空自己的local copy,当收到全部其他cpu的invalidate acknowledge之后,transaction完成,本cpu上对应的cacheline从shared状态切换exclusive状态。还有另外一种方法也可以完成这个状态切换:当所有其他的cpu对其local copy的cacheline进行写回操作,同时将cacheline中的数据设为无效(主要是为了为新的数据腾些地方),这时候,本cpu坐享其成,直接获得了对该数据的独占权。
- Transition (i):其他的CPU进行一个原子的read-modify-write操作,但是,数据在本cpu的cacheline中,因此,其他的那个CPU会发送read invalidate,请求对该数据以及独占权。本cpu回送read response”和“invalidate acknowledge”,一方面把数据转移到其他cpu的cache中,另外一方面,清空自己的cacheline。
- Transition (j):cpu想要进行write的操作但是数据不在local cache中,因此,该cpu首先发送了read invalidate启动了一次总线transaction。在收到read response回应拿到数据,并且收集所有其他cpu发来的invalidate acknowledge之后(确保其他cpu没有local copy),完成整个bus transaction。当write操作完成之后,该cacheline的状态会从Exclusive状态迁移到Modified状态。
- Transition (k):本CPU执行读操作,发现local cache没有数据,因此通过read发起一次bus transaction,来自其他的cpu local cache或者memory会通过read response回应,从而将该cacheline从Invalid状态迁移到shared状态。
- Transition (l):当cacheline处于shared状态的时候,说明在多个cpu的local cache中存在副本,因此,这些cacheline中的数据都是read only的,一旦其中一个cpu想要执行数据写入的动作,必须先通过invalidate获取该数据的独占权,而其他的CPU会以invalidate acknowledge回应,清空数据并将其cacheline从shared状态修改成invalid状态。
MESI Protocol Example
在理解了各种cacheline状态、各种MESI协议消息以及状态迁移的描述之后,我们从cache line数据的角度来看看MESI协议是如何运作的。开始,数据保存在memory的0地址中,随后,该数据会穿行在四个CPU的local cache中。为了方便起见,我们让CPU local cache使用最简单的Direct-mapped的组织形式。具体的过程可以参考下面的图片:
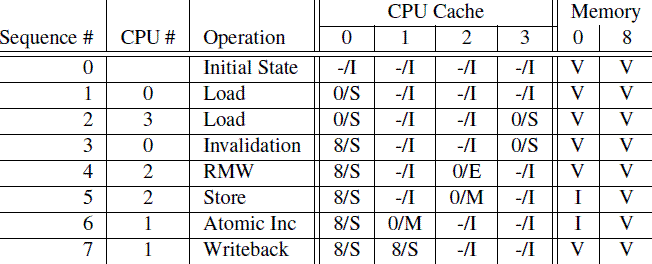
第一列是操作序列号,第二列是执行操作的CPU,第三列是具体执行哪一种操作,第四列描述了各个cpu local cache中的cacheline的状态(用meory address/状态表示),最后一列描述了内存在0地址和8地址的数据内容的状态:V表示是最新的,和cache一致,I表示不是最新的内容,最新的内容保存在cache中。
最开始的时候(sequence 0),各个cpu cache中的cacheline都是Invalid状态,而Memory中的数据都保存了最新的数据。随后(sequence 1),CPU 0执行了load操作,将address 0的数据加载到寄存器,这个操作使得保存0地址数据的那个cacheline从invalid状态迁移到shared状态。随后(sequence 2),CPU3也对0地址执行了load操作,导致其local cache上对应的cacheline也切换到shared状态。当然,这时候,memory仍然是最新的。在sequence 3中,CPU 0执行了对地址8的load操作,由于地址0和地址8都是选择同一个cache set,而且,我们之前已经说过,该cache是direct-mapped的(即每个set只有一个cacheline),因此需要首先清空该cacheline中的数据(该操作被称为Invalidation),由于cacheline的状态是shared,因此,不需要通知其他CPU。Invalidation local cache上的cacheline之后,cpu 0的load操作将该cacheline状态修改成Shared状态(保存地址8的数据)。CPU 2也开始执行load操作了(sequence 4),虽然是load操作,但是CPU知道程序随后会修改该值(不是原子操作的read-modify-write,否就是迁移到Modified状态了,也不是单纯的load操作,否则会迁移到shared状态),因此向总线发送了read invalidate命令,一方面获取该数据(自己的local cache中没有地址0的数据),另外,CPU 2想独占该数据(因为随后要write)。这个操作导致CPU 3的cacheline迁移到invalid状态。当然,这时候,memory仍然是最新的有效数据。CPU 2的store操作很快到来(Sequence 5),由于准备工作做的比较充分(Exclusive状态,独占该数据),cpu直接修改cacheline中的数据(对应地址0),从而将其状态迁移到modified状态,同时要注意的是:memory中的数据已经失效,不是最新的数据了,任何其他CPU发起对地址0的load操作都不能从memory中读取,而是通过嗅探(snoop)的方式从CPU 2的local cache中获取。在sequence 6中,CPU 1对地址0的数据执行原子的加1操作,这时候CPU 1会发出read invalidate命令,将地址0的数据从CPU 2的cacheline中嗅探得到,同时通过invalidate其他CPU local cache的内容而获得独占性的数据访问权。这时候,CPU 2中的cacheline状态变成invalid状态,而CPU 1将从invalid状态迁移到modified状态。最后(sequence 7),CPU 1对地址8进行load操作,由于cacheline被地址0占据,因此需要首先将其驱逐出cache,于是执行write back操作将地址0的数据写回到memory,同时发送read命名,从CPU 0的cache中获得数据加载其cacheline,最后,CPU1的cache变成shared状态(保存地址8的数据)。由于执行了write back操作,memory中地址0的数据又变成最新的有效数据了。
3. Stores Result in Unnecessary Stalls
我们可以看出,针对某些特定地址的数据(在一个cacheline中)重复的进行读写,这种结构可以获得很好的性能,不过,对于第一次写,其性能非常差。下面的这个图可以展示为何写性能差:
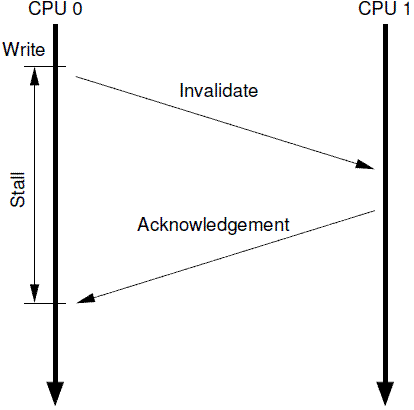
cpu 0发起一次对某个地址的写操作,但是local cache没有数据,该数据在CPU 1的local cache中,因此,为了完成写操作,CPU 0发出invalidate的命令,invalidate其他CPU的cache数据。只有完成了这些总线上的transaction之后,CPU 0才能正在发起写的操作,这是一个漫长的等待过程。
但是,其实没必要等待这么长的时间,毕竟,物理CPU 1中的cacheline保存有什么样子的数据,其实都没有意义,这个值都会被CPU 0新写入的值覆盖的。
Store Buffers
有一种可以阻止cpu进入无聊等待状态的方法就是在CPU和cache之间增加store buffer这个HW block,如下图所示:
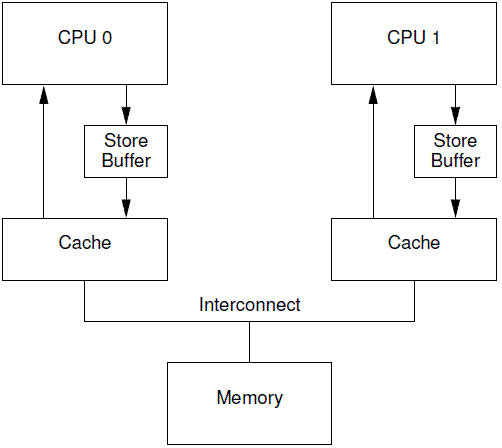
一旦增加了store buffer,那么cpu0无需等待其他CPU的相应,只需要将要修改的内容放入store buffer,然后继续执行就OK了。当cacheline完成了bus transaction,并更新了cacheline的状态后,要修改的数据将从store buffer进入cacheline。(核心思想:老子不管,你慢慢给我通知和MESI,我反正改完了,先放在buffer里,你方便了我再刷进Cache)
这些store buffer对于cpu而言是local的,如果系统是硬件多线程, 那么每一个cpu core拥有自己私有的stroe buffer,一个cpu只能访问自己私有的那个store buffer。在上图中,cpu 0不能访问cpu1的store buffer,反之亦然。之所以做这样的限制是为了模块划分(各个cpu core模块关心自己的事情,让cache系统维护自己的操作),让硬件设计变得简单一些。store buffer增加了CPU连续写的性能,同时把各个CPU之间的通信的任务交给维护cache一致性的协议。即便给每个CPU分配私有的store buffer,仍然引入了一些复杂性,我们会在下面两个小节中描述。
Store Forwarding
上文提到store buffer引入了复杂性,我们先看第一个例子:本地数据不一致的问题。我们先看看下面的代码:
1 | |
a和b都是初始化为0,并且变量a在CPU 1的cacheline中,变量b在CPU 0的cacheline中。如果cpu执行上述代码,那么第三行的assert不应该失败,不过,如果CPU设计者使用上图中的那个非常简单的store buffer结构,那么你应该会遇到“惊喜”(assert失败了)。具体的执行过程是这样的:
- CPU 0执行a=1的赋值操作
- CPU 0遇到cache miss
- CPU 0发送read invalidate消息以便从CPU 1那里获得数据,并invalid其他cpu保存a数据的local cacheline。
- CPU 0把要写入的数据“1”放入store buffer
- CPU 1收到read invalidate后回应,把本地cacheline的数据发送给CPU 0并清空本地cache中a的数据
- CPU 0执行b = a + 1
- CPU 0 收到来自CPU 1的数据,该数据是“0”
- CPU 0从cacheline中加载a,获得0值
- CPU 0将store buffer中的值写入cacheline,这时候cache中的a值是“1”
- CPU 0执行a+1,得到1并将该值写入b
- OMG,你期望b等于2,但是实际上b等于了1
由于a = 1,被缓存在store buffer里面了。导致CPU 0拿到CPU 1的,a = 0的值的时候,先去做了b = a + 1的计算。然后才去执行的b = a + 1,又相当于乱序了。。。导致这个问题的根本原因是我们有两个a值,一个在cacheline中,一个在store buffer中。
- 上面这个出错的例子之所以发生是因为它违背了一个基本的原则,即每个CPU按照其视角来观察自己的行为的时候必须是符合program order的。一旦违背这个原则,会导致一些非常不直观的软件行为,对软件工程师而言就是灾难。还好,有”好心“的硬件工程师帮助我们,修改了CPU的设计如下:
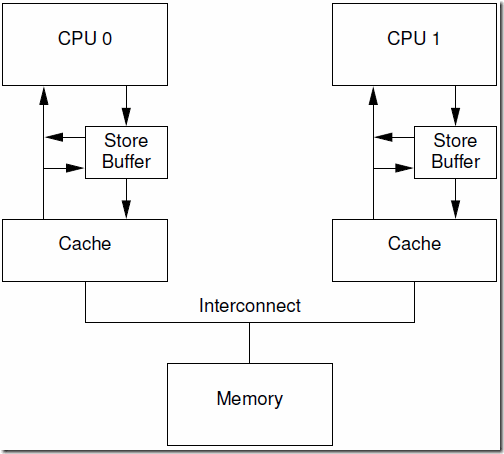
这种设计叫做store forwarding,当CPU执行load操作的时候,不但要看cache,还有看store buffer是否有内容,如果store buffer有该数据,那么就采用store buffer中的值。因此,即便是store操作还没有写入cacheline,store forwarding的效果看起来就好象cpu的store操作被向前传递了一样(后面的load的指令可以感知到这个store操作) 。
- 有了store forwarding的设计,上面的步骤(8)中就可以在store buffer获取正确的a值是”1“而不是”0“,因此计算得到的b的结果就是2,和我们预期的一致了。
Store Buffers and Memory Barriers
关于store buffer引入的复杂性,我们再来看看第二个例子:
1 | |
同样的,a和b都是初始化成0。我们假设CPU 0执行foo函数,CPU 1执行bar函数。我们再进一步假设a变量在CPU 1的cache中,b在CPU 0 cache中,执行的操作序列如下:
- CPU 0执行a=1的赋值操作,由于a不在local cache中,因此,CPU 0将a值放到store buffer中之后,发送了read invalidate命令到总线上去。
- CPU 1执行 while (b == 0) 循环,由于b不在CPU 1的cache中,因此,CPU发送一个read message到总线上,看看是否可以从其他cpu的local cache中或者memory中获取数据。
- CPU 0继续执行b=1的赋值语句,由于b就在自己的local cache中(cacheline处于modified状态或者exclusive状态),因此CPU0可以直接操作将新的值1写入cache line。
- CPU 0收到了read message,将最新的b值”1“回送给CPU 1,同时将b cacheline的状态设定为shared。
- CPU 1收到了来自CPU 0的read response消息,将b变量的最新值”1“值写入自己的cacheline,状态修改为shared。
- 由于b值等于1了,因此CPU 1跳出while (b == 0)的循环,继续前行。
- 这时候CPU 1的local cache中还是旧的a值,因此assert(a == 1)失败。
- CPU 1收到了来自CPU 0的read invalidate消息,以a变量的值进行回应,同时清空自己的cacheline,但是这已经太晚了。
- CPU 0收到了read response和invalidate ack的消息之后,将store buffer中的a的最新值”1“数据写入cacheline,然并卵,CPU 1已经assertion fail了。
- 遇到这样的问题,CPU设计者也不能直接帮什么忙,毕竟CPU并不知道哪些变量有相关性,这些变量是如何相关的。不过CPU设计者可以间接提供一些工具让软件工程师来控制这些相关性。这些工具就是memory-barrier指令。要想程序正常运行,必须增加一些memory barrier的操作,具体如下:
1 | |
- smp_mb() 这个内存屏障的操作会在执行后续的store操作之前,首先flush store buffer(也就是将之前的值写入到cacheline中)。smp_mb() 操作主要是为了让数据在local cache中的操作顺序是符合program order的顺序的,为了达到这个目标有两种方法:
方法一就是让CPU stall,直到完成了清空了store buffer(也就是把store buffer中的数据写入cacheline了)。
方法二是让CPU可以继续运行,不过需要在store buffer中做些文章,也就是要记录store buffer中数据的顺序,在将store buffer的数据更新到cacheline的操作中,严格按照顺序执行,即便是后来的store buffer数据对应的cacheline已经ready,也不能执行操作,要等前面的store buffer值写到cacheline之后才操作。增加smp_mb() 之后,操作顺序如下:
- CPU 0执行a=1的赋值操作,由于a不在local cache中,因此,CPU 0将a值放到store buffer中之后,发送了read invalidate命令到总线上去。
- CPU 1执行 while (b == 0) 循环,由于b不在CPU 1的cache中,因此,CPU发送一个read message到总线上,看看是否可以从其他cpu的local cache中或者memory中获取数据
- CPU 0执行smp_mb()函数,给目前store buffer中的所有项做一个标记(后面我们称之marked entries)。当然,针对我们这个例子,store buffer中只有一个marked entry就是“a=1”。
- CPU 0继续执行b=1的赋值语句,虽然b就在自己的local cache中(cacheline处于modified状态或者exclusive状态),不过在store buffer中有marked entry,因此CPU0并没有直接操作将新的值1写入cache line,取而代之是b的新值”1“被写入store buffer,当然是unmarked状态。
- CPU 0收到了read message,将b值”0“(新值”1“还在store buffer中)回送给CPU 1,同时将b cacheline的状态设定为shared。
- CPU 1收到了来自CPU 0的read response消息,将b变量的值(”0“)写入自己的cacheline,状态修改为shared。
- 完成了bus transaction之后,CPU 1可以load b到寄存器中了(local cacheline中已经有b值了),当然,这时候b仍然等于0,因此循环不断的loop。虽然b值在CPU 0上已经赋值等于1,但是那个新值被安全的隐藏在CPU 0的store buffer中。
- CPU 1收到了来自CPU 0的read invalidate消息,以a变量的值进行回应,同时清空自己的cacheline。
- CPU 0将store buffer中的a值写入cacheline,并且将cacheline状态修改为modified状态。
- 由于store buffer只有一项marked entry(对应a=1),因此,完成step 9之后,store buffer的b也可以进入cacheline了。不过需要注意的是,当前b对应的cacheline的状态是shared。
- CPU 0发送invalidate消息,请求b数据的独占权
- CPU 1收到invalidate消息,清空自己的b cacheline,并回送acknowledgement给CPU 0。
- CPU 1继续执行while (b == 0),由于b不在自己的local cache中,因此 CPU 1发送read消息,请求获取b的数据。
- CPU 0收到acknowledgement消息,将b对应的cacheline修改成exclusive状态,这时候,CPU 0终于可以将b的新值1写入cacheline。
- CPU 0收到read消息,将b的新值1回送给CPU 1,同时将其local cache中b对应的cacheline状态修改为shared。
- CPU 1获取来自CPU 0的b的新值,将其放入cacheline中
- 由于b值等于1了,因此CPU 1跳出while (b == 0)的循环,继续前行。
- CPU 1执行assert(a == 1),不过这时候a值没有在自己的cacheline中,因此需要通过cache一致性协议从CPU 0那里获得,这时候获取的是a的最新值,也就是1值,因此assert成功。
- 通过上面的描述,我们可以看到,一个直观上很简单的给a变量赋值的操作,都需要那么长的执行过程,而且每一步都需要芯片参与,最终完成整个复杂的赋值操作过程。
4. Store Sequences Result in Unnecessary Stalls
不幸的是:每个cpu的store buffer不能实现的太大,其entry的数目不会太多。当cpu以中等的频率执行store操作的时候(假设所有的store操作导致了cache miss),store buffer会很快的被填满。在这种状况下,CPU只能又进入等待状态,直到cache line完成invalidation和ack的交互之后,可以将store buffer的entry写入cacheline,从而为新的store让出空间之后,CPU才可以继续执行。这种状况也可能发生在调用了memory barrier指令之后,因为一旦store buffer中的某个entry被标记了,那么随后的store都必须等待invalidation完成,因此不管是否cache miss,这些store都必须进入store buffer。
- 引入invalidate queues可以缓解这个状况。store buffer之所以很容易被填充满,主要是其他CPU回应invalidate acknowledge比较慢,如果能够加快这个过程,让store buffer尽快进入cacheline,那么也就不会那么容易填满了。
Invalidate Queues
invalidate acknowledge不能尽快回复的主要原因是invalidate cacheline的操作没有那么快完成,特别是cache比较繁忙的时候,这时,CPU往往进行密集的loading和storing的操作,而来自其他CPU的,对本CPU local cacheline的操作需要和本CPU的密集的cache操作进行竞争,只要完成了invalidate操作之后,本CPU才会发生invalidate acknowledge。此外,如果短时间内收到大量的invalidate消息,CPU有可能跟不上处理,从而导致其他CPU不断的等待。
然而,CPU其实不需要完成invalidate操作就可以回送acknowledgement消息,这样,就不会阻止发生invalidate请求的那个CPU进入无聊的等待状态。CPU可以buffer这些invalidate message(放入Invalidate Queues),然后直接回应acknowledgement,表示自己已经收到请求,随后会慢慢处理。当然,再慢也要有一个度,例如对a变量cacheline的invalidate处理必须在该CPU发送任何关于a变量对应cacheline的操作到bus之前完成。
Invalidate Queues and Invalidate Acknowledge
有invalidate queue的系统结构如下图所示:
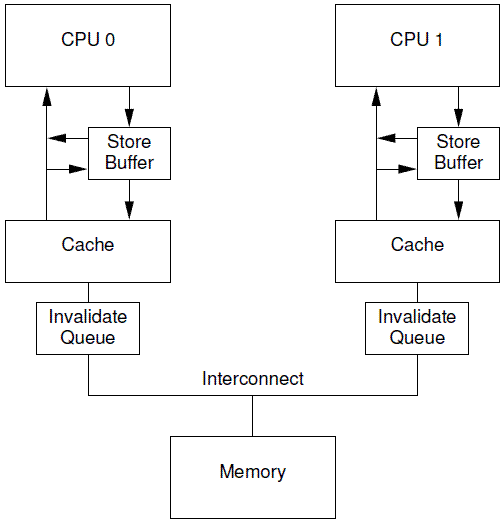
有了Invalidate Queue的CPU,在收到invalidate消息的时候首先把它放入Invalidate Queue,同时立刻回送acknowledge 消息,无需等到该cacheline被真正invalidate之后再回应。当然,如果本CPU想要针对某个cacheline向总线发送invalidate消息的时候,那么CPU必须首先去Invalidate Queue中看看是否有相关的cacheline,如果有,那么不能立刻发送,需要等到Invalidate Queue中的cacheline被处理完之后再发送。
一旦将一个invalidate(例如针对变量a的cacheline)消息放入CPU的Invalidate Queue,实际上该CPU就等于作出这样的承诺:在处理完该invalidate消息之前,不会发送任何相关(即针对变量a的cacheline)的MESI协议消息。只要是对该cacheline的竞争不是那么剧烈,CPU还是对这样的承诺很有信心的。
然而,缓存了invalidate消息也会引入一些其他的memory order的问题,我们在下一节讨论。
Invalidate Queues and Memory Barriers
我们假设CPU缓存invalidation消息,在操作cacheline之前直接回应该invalidation消息。这样的机制对于发送invalidation的CPU侧是非常好的事,该CPU的store性能会非常高,但是会使内存屏障指令失效,我们来看看下面的例子:
1 | |
- CPU 0执行a=1的赋值操作,由于a在CPU 0 local cache中的cacheline处于shared状态,因此,CPU 0将a的新值“1”放入store buffer,并且发送了invalidate消息去清空CPU 1对应的cacheline。
- CPU 1执行while (b == 0)的循环操作,但是b没有在local cache,因此发送read消息试图获取该值。
- CPU 1收到了CPU 0的invalidate消息,放入Invalidate Queue,并立刻回送Ack。
- CPU 0收到了CPU 1的invalidate ACK之后,即可以越过程序设定内存屏障(第四行代码的smp_mb() ),这样a的新值从store buffer进入cacheline,状态变成Modified。
- CPU 0 越过memory barrier后继续执行b=1的赋值操作,由于b值在CPU 0的local cache中,因此store操作完成并进入cache line。
- CPU 0收到了read消息后将b的最新值“1”回送给CPU 1,并修正该cacheline为shared状态。
- CPU 1收到read response,将b的最新值“1”加载到local cacheline。
- 对于CPU 1而言,b已经等于1了,因此跳出while (b == 0)的循环,继续执行后续代码
- CPU 1执行assert(a == 1),但是由于这时候CPU 1 cache的a值仍然是旧值0,因此assertion 失败
- 该来总会来,Invalidate Queue中针对a cacheline的invalidate消息最终会被CPU 1执行,将a设定为无效,但素,大错已经酿成。
很明显,在上文中的场景中,加速Invalidation response导致foo函数中的memory barrier失效了,因此,这时候对Invalidation response已经没有意义了,毕竟程序逻辑都错了。怎么办?其实我们可以让memory barrier指令和Invalidate Queue进行交互来保证确定的memory order。具体做法是这样的:当CPU执行memory barrier指令的时候,对当前Invalidate Queue中的所有的entry进行标注,这些被标注的项次被称为marked entries,而随后CPU执行的任何的load操作都需要等到Invalidate Queue中所有marked entries完成对cacheline的操作之后才能进行。因此,要想保证程序逻辑正确,我们需要给bar函数增加内存屏障的操作,具体如下:
1 | |
- 程序修改之后,我们再来看看CPU的执行序列:
- CPU 0执行a=1的赋值操作,由于a在CPU 0 local cache中的cacheline处于shared状态(read only),因此,CPU 0将a的新值“1”放入store buffer,并且发送了invalidate消息去清空CPU 1对应的cacheline。
- CPU 1执行while (b == 0)的循环操作,但是b没有在local cache,因此发送read消息试图获取该值。
- CPU 1收到了CPU 0的invalidate消息,放入Invalidate Queue,并立刻回送Ack。
- CPU 0收到了CPU 1的invalidate ACK之后,即可以越过程序设定内存屏障(第四行代码的smp_mb() ),这样a的新值从store buffer进入cacheline,状态变成Modified。
- CPU 0 越过memory barrier后继续执行b=1的赋值操作(这时候该cacheline或者处于modified状态,或者处于exclusive状态),由于b值在CPU 0的local cache中,因此store操作完成并进入cache line。
- CPU 0收到了read消息后将b的最新值“1”回送给CPU 1,并修正该cacheline为shared状态。
- CPU 1收到read response,将b的最新值“1”加载到local cacheline。
- 对于CPU 1而言,b已经等于1了,因此跳出while (b == 0)的循环,继续执行memory barrier的代码。
- CPU 1现在不能继续执行代码,只能等待,直到Invalidate Queue中的message被处理完成
- CPU 1处理队列中缓存的Invalidate消息,将a对应的cacheline设置为无效。
- 由于a变量在local cache中无效,因此CPU 1在执行assert(a == 1)的时候需要发送一个read消息去获取a值。
- CPU 0用a的新值1回应来自CPU 1的请求。
- CPU 1获得了a的新值,并放入cacheline,这时候assert(a == 1)不会失败了。
虽然多了很多MESI协议的交互,但是最终CPU的执行符合了预期的结果。这一节也说明了为什么CPU designer一定会非常小心的处理Cache一致性的问题。
5. Read and Write Memory Barriers
在我们上面的例子中,memory barrier指令对store buffer和invalidate queue都进行了标注,不过,在实际的代码片段中,foo函数不需要mark invalidate queue,bar函数不需要mark store buffer。因此,许多CPU architecture提供了弱一点的memory barrier指令只mark其中之一。如果只mark invalidate queue,那么这种memory barrier被称为read memory barrier。相应的,write memory barrier只mark store buffer。一个全功能的memory barrier会同时mark store buffer和invalidate queue。
我们一起来看看读写内存屏障的执行效果:对于read memory barrier指令,它只是约束执行CPU上的load操作的顺序,具体的效果就是CPU一定是完成read memory barrier之前的load操作之后,才开始执行read memory barrier之后的load操作。read memory barrier指令象一道栅栏,严格区分了之前和之后的load操作。同样的,write memory barrier指令,它只是约束执行CPU上的store操作的顺序,具体的效果就是CPU一定是完成write memory barrier之前的store操作之后,才开始执行write memory barrier之后的store操作。全功能的memory barrier会同时约束load和store操作,当然只是对执行memory barrier的CPU有效。
我们可以改一个用读写内存屏障的版本了,具体如下:
1 | |
有些CPU有更多种类的memory barrier操作,不过read mb,write mb和全功能的mb是应用普遍的指令,理解了这三个之后再学习其他的就比较简单了。
其他补充内容
Compiler Barrier & Memory Barrier
如何解决伪重排序问题:在Core0修改了数据v后,让Core1在使用v前,能得到v最新的修改值
- Core0修改v1后,发送一个信号,将Core1缓存的v1标记为失效,并将修改值写回内存。
- Core0可能会多次修改v1,每次修改都只发送一个信号(发信号时会锁住缓存间的总线),Core1缓存的v1保持着失效标记。
- Core1使用v1前,发现缓存中的v1已经失效了,得知v1已经被修改了,于是重新从其他缓存或内存中加载v1。
内存屏障是硬件之上、操作系统或JVM之下,对并发作出的最后一层支持。
再向下是是硬件提供的支持;向上是操作系统或JVM对内存屏障作出的各种封装。内存屏障是一种标准,各厂商可能采用不同的实现。
通过volatile,可以解决编译器层面的可见性与重排序问题。而内存屏障则解决了硬件层面的可见性与重排序问题。
具体标准
- Store:将处理器缓存的数据flush到内存中。
- Load:将内存的数据拷贝到处理器的缓存中。
| 屏障类型 | 指令示例 | 说明 |
|---|---|---|
| LoadLoad | Load1;LoadLoad;Load2 | 该屏障确保Load1数据装载先于Load2及其之后所有的装载操作 |
| StoreStore | Store1;StoreStore;Store2 | 该屏障确保Store1刷新数据到内存先于Store2及其之后所有的内存刷新操作,即保证对其他处理器可见 |
| LoadStore | Load1;LoadStore;Store2 | 该屏障确保Load1数据装载先于Store2及其之后所有的内存刷新操作 |
| StoreLoad | Store1;StoreLoad;Load2 | 该屏障确保Store1刷新数据到内存先于Load2及其之后所有的装载操作。StoreLoad会使该屏障之前的所有内存访问指令(存储指令和访问指令)完成之后,才执行该屏障之后的内存访问指令 |
StoreLoad同时具备其他三个屏障的效果,因此也称之为全能屏障(mfence),但是相对其他屏障,该屏障的开销相对昂贵。含义就是,之前的改的,后面一定都能读得到!!!这就是较强的一致性的(顺序一致性)
x86的实现
除了mfence,不同的CPU架构对内存屏障的实现方式与实现程都度非常不一样。Intel CPU的强内存模型比DEC Alpha的弱复杂内存模型(缓存不仅分层了,还分区了)更简单。x86架构是在多线程编程中最常见的,下面讨论x86架构中内存屏障的实现。不过不管是哪种方案,内存屏障的实现都要针对乱序执行的过程来设计,前文已经有写过。内存屏障可以通过使用类似MESI协议的思路实现。
Store Barrier
sfence指令实现了Store Barrier,相当于StoreStore Barriers(之前的修改,会对于后面的修改产生影响)
强制所有在sfence指令之前的store指令,都在该sfence指令执行之前被执行,发送缓存失效信号,并把store buffer中的数据刷新到CPU的L1 Cache中,所有在sfence指令之后的store指令,都在该sfence指令执行之后被执行。禁止对sfence指令前后store指令的重排序跨越sfence指令
所有Store Barrier之前发生的内存更新都是可见的。
前文说的乱序优化说基于寄存器和内存,而在内存屏障的标准中,讨论的是缓存与内存间的相干性,实际上,这同样适用于寄存器与缓存、甚至寄存器与内存间等多级缓存之间。x86架构使用了MESI协议的一个变种,由协议保证三层缓存与内存间的相关性,则内存屏障只需要保证store buffer(可以认为是寄存器与L1 Cache间的一层缓存)与L1 Cache间的相干性。
Load Barrier
lfence指令实现了Load Barrier,相当于LoadLoad Barriers(之前读的结果,对后面可见)
强制所有在lfence指令之后的load指令,都在该lfence指令执行之后被执行,并且一直等到load buffer被该CPU读完才能执行之后的load指令(发现缓存失效后发起的刷入)。禁止对lfence指令前后load指令的重排序跨越lfence指令。
配合Store Barrier,使所有Store Barrier之前发生的内存更新,对Load Barrier之后的load操作都是可见的。
这里的“可见”,指修改值可见(内存可见性)且操作结果可见(禁用重排序)
Full Barrier
mfence指令实现了Full Barrier,相当于StoreLoad Barriers。
mfence指令综合了sfence指令与lfence指令的作用
强制所有在mfence指令之前的store/load指令,都在该mfence指令执行之前被执行;
所有在mfence指令之后的store/load指令,都在该mfence指令执行之后被执行。
禁止对mfence指令前后store/load指令的重排序跨越mfence指令,使所有Full Barrier之前发生的操作,对所有Full Barrier之后的操作都是可见的。
Java中的volatile如何解决内存可见性与处理器重排序问题
既然有了内存屏障,是不是就不需要volatile了?当然不是,还有三个问题:
- 并不是所有的硬件架构都提供了相同的一致性保证,JVM需要volatile统一语义
- 可见性问题不仅仅局限于CPU缓存内,JVM自己维护的内存模型中也有可见性问题。使用volatile做标记,可以解决JVM层面的可见性问题。
- 如果不考虑真重排序,MESI确实解决了CPU缓存层面的可见性问题;然而,真重排序也会导致可见性问题。
在编译器层面,仅将volatile作为标记使用,取消编译层面的缓存和重排序。
如果硬件架构本身已经保证了内存可见性(单核处理器、一致性足够的内存模型等),那么volatile就是一个空标记,不会插入内存屏障
如果不保证,以x86架构为例,JVM对volatile变量的处理如下:
- 在写volatile变量v之后,插入一个sfence。这样,sfence之前的所有store(包括写)不会被重排序到sfence之后,sfence之后的所有store不会被重排序到sfence之前,禁用跨sfence的store重排序;sfence之前修改的值都会被立刻写回缓存,并标记其他CPU中的缓存失效。
- 在读volatile变量v之前,插入一个lfence。这样,lfence之后的load(包括读v)不会被重排序到lfence之前,lfence之前的load不会被重排序到lfence之后,禁用跨lfence的load重排序;且lfence之后,会首先刷新掉无效缓存,从而得到最新的修改值,与sfence配合保证内存可见性。
- 在另外一些平台上,JVM使用mfence代替sfence与lfence,实现更强的语义。
volatile修饰的变量,写之后,读之前,插入对应的屏障 -> 保证每次修改完了都能被读到,每次读到的,也一定是最新的!!!
Java和C++的volatile不一样
笑死:JYY就喜欢问这个昂!!!
Java
- Java上面说了哈:
- 1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
- 2)禁止进行指令重排序。
volatile 主要用来解决多线程环境中内存不可见问题。对于一写多读,是可以解决变量同步问题,但是如果多写,就无法解决线程安全问题。
- 特点:
- (1)volatile 变量具有 synchronized 的可见性特性,及如果一个字段被声明为volatile,java线程内存模型确保所有的线程看到这个变量的值是一致的
- (2)禁止进行指令重排序
- (3)不保证原子性
C++
- C++中的volatile:
对于程序员来说,程序本身的任何行为都必须是可预期的。那么,在程序当中,什么才叫 volatile 呢?这个问题的答案也很简单:程序可能受到程序之外的因素影响。应该避免错误的写法,而这个错误就在于误用了 volatile 关键字,volatile 可以避免优化、强制内存读取的顺序,但是 volatile 并没有线程同步的语义,C++ 标准并不能保证它在多线程情况的正确性。只保证可见性,内存栅栏可使用std::atomic_thread_fence,或者使用锁语义,不要滥用volatile。
1 | |
若忽略
volatile,那么p就只是一个「指向int类型的指针」。这样一来,a = *p;和b = *p;两句,就只需要从内存中读取一次就够了。因为从内存中读取一次之后,CPU 的寄存器中就已经有了这个值;把这个值直接复用就可以了。这样一来,编译器就会做优化,把两次访存的操作优化成一次。这样做是基于一个假设:我们在代码里没有改变p指向内存地址的值,那么这个值就一定不会发生改变。此处说的「读取内存」,包括了读取 CPU 缓存和读取计算机主存。
然而,由于 MMIP(Memory mapped I/O)的存在,这个假设不一定是真的。例如说,假设
p指向的内存是一个硬件设备。这样一来,从p指向的内存读取数据可能伴随着可观测的副作用:硬件状态的修改。此时,代码的原意可能是将硬件设备返回的连续两个int分别保存在a和b当中。这种情况下,编译器的优化就会导致程序行为不符合预期了。总结来说,被
volatile修饰的变量,在对其进行读写操作时,会引发一些可观测的副作用。而这些可观测的副作用,是由程序之外的因素决定的。
volatile不能解决多线程中的问题。按照 Hans Boehm & Nick Maclaren 的总结,
volatile只在三种场合下是合适的。- 和信号处理(signal handler)相关的场合;
- 和内存映射硬件(memory mapped hardware)相关的场合;
- 和非本地跳转(
setjmp和longjmp)相关的场合。
CAS
在x86架构上,CAS被翻译为”lock cmpxchg“。cmpxchg是CAS的汇编指令。
在CPU架构中依靠lock信号保证可见性并禁止重排序。
lock前缀是一个特殊的信号,执行过程如下:
- 对总线和缓存上锁。
- 强制所有lock信号之前的指令,都在此之前被执行,并同步相关缓存。
- 执行lock后的指令(如cmpxchg)。
- 释放对总线和缓存上的锁。
- 强制所有lock信号之后的指令,都在此之后被执行,并同步相关缓存。
因此,lock信号虽然不是内存屏障,但具有mfence的语义 -> CAS在x86,保证交换的都是最新的值,并且会将交换后的最新的值,写回内训。
CPU现代架构补充
核 != CPU,21世纪了都,Computer早都是多CPU多核多线程啦。摘抄自:https://wxler.github.io/2021/02/15/200435/
- 何为多核CPU?所谓的多核CPU就是CPU有多个核心,CPU运作时,每个核心各自处理各自任务,互不干扰。
- 线程又是什么?线程是指一个CPU分离出来的一个任务,本质就是一个核心通过CPU不断的切换同时进行的任务工作,因为CPU速度非常快,让你感觉不到有切换,但本身是只有一核心在工作。
多核多线程的意义:多核数决定了你运作程序时最多能有多少程序独占一个核心工作互不干扰,多线程决定了CPU一个核心下同时处理多少任务互不干扰,当然带来的就是性能上的折扣。
CPU架构演进
- 多个物理CPU,各个CPU通过总线进行通信,效率比较低
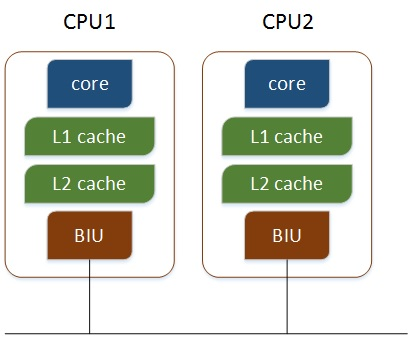
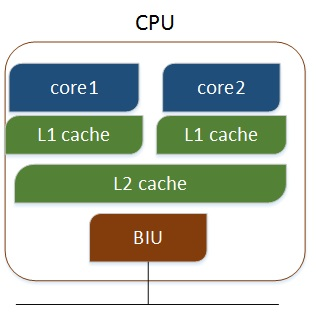
- 多核CPU,不同的核通过L2 cache进行通信,存储和外设通过总线与CPU通信
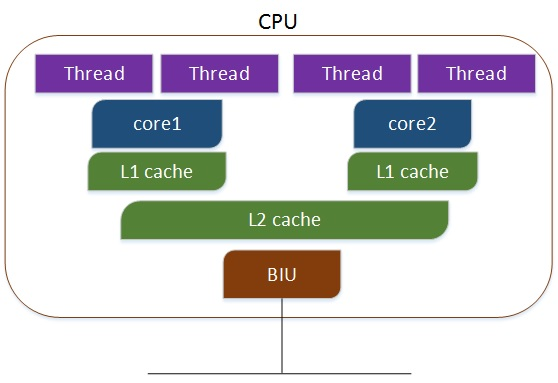
- 多核多线程,每个核有两个逻辑的处理单元,两个线程共同分享一个核的资源
最后这种,也就是,我们之前看到过的:
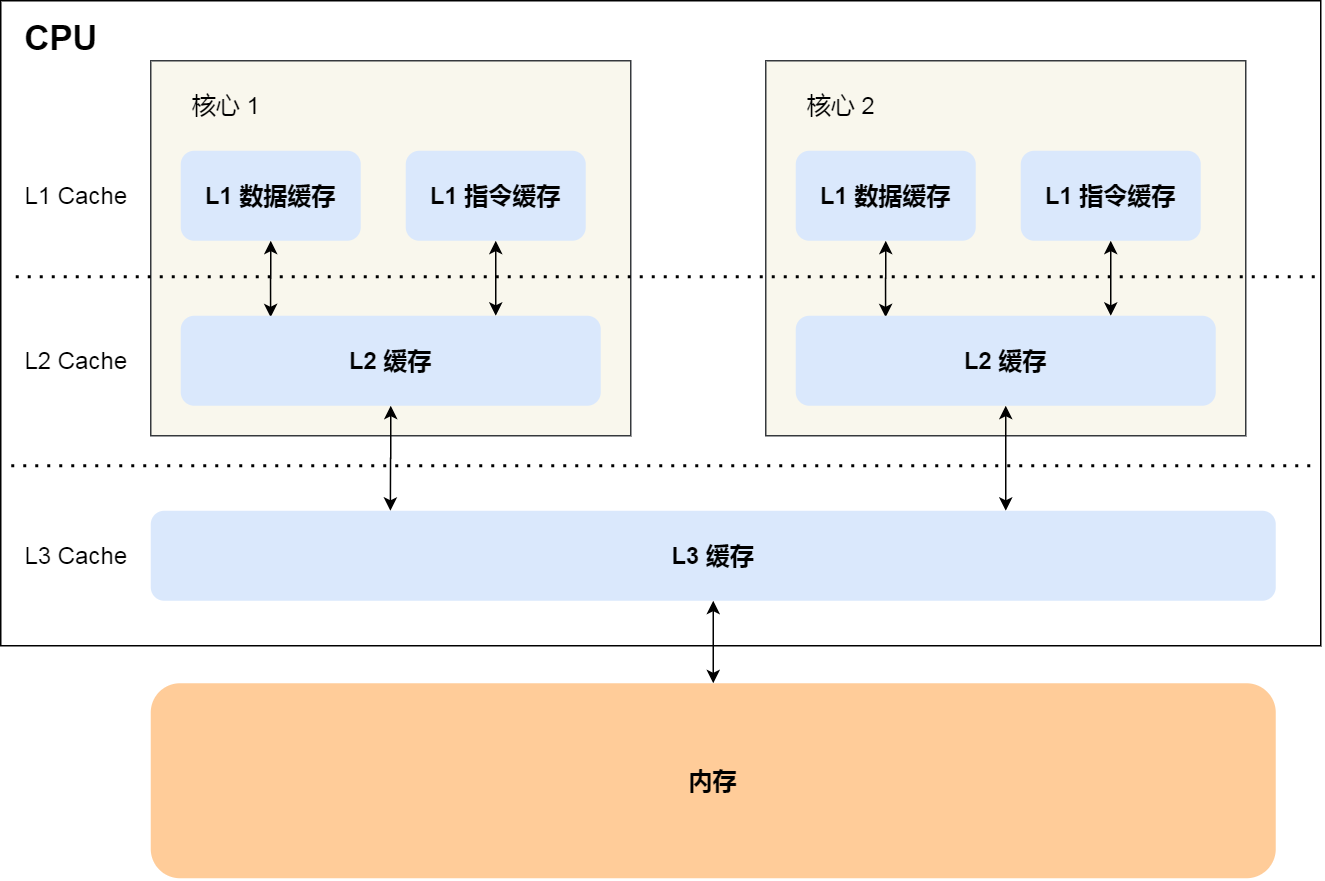
总核数 = 物理CPU个数 X 每颗物理CPU的核数
总逻辑CPU数(也即线程数) = 物理CPU个数 X 每颗物理CPU的核数 X 线程数
如何查看电脑CPU核心数量与线程数量?打开命令提示符(即cmd),输入wmic回车,再输入cpu get回车即可获取到CPU详情,往后拖动滑块找到两个值,一个是NumberOfCores表示是核心数,另一个是NumberOfLogicalProcessors表示线程数。
References
- Samuel’s Blog: https://krustykr2b.github.io/post/%E5%85%B3%E4%BA%8ECPU-Cache.html
- 有了MESI为什么还需要内存屏障?https://time.geekbang.org/column/article/462113
- 内存屏障相关论文(上)http://www.wowotech.net/kernel_synchronization/Why-Memory-Barriers.html
- 内存屏障相关论文(下)http://www.wowotech.net/kernel_synchronization/perfbook-memory-barrier-2.html
- 兔子上一次的小补充:https://alexanderliu-creator.github.io/2022/12/11/njuos-4-li-jie-bing-fa-cheng-xu-zhi-xing/#%E8%87%AA%E5%AD%A6%E5%86%85%E5%AE%B9%E8%A1%A5%E5%85%85
- CPU现代架构:https://wxler.github.io/2021/02/15/200435/
- Java和C中的volatile不一致:https://cloud.tencent.com/developer/article/1637791
- as-if-serial规则和happens-before规则的区别:https://blog.csdn.net/ThinkWon/article/details/102074107