NJUOS-8-并发bug和应对
本文最后更新于:2 年前
This is a very important lesson which teaches you how to find the bugs in your concurrent program!
应对Bug的方法
基本思路:否定你自己。虽然不太愿意承认,但始终假设自己的代码是错的。(先假设,自己的程序是错的)
然后呢?
做好测试
检查哪里错了
再检查哪里错了
再再检查哪里错了
- (把任何你认为 “不对” 的情况都检查一遍)
Bug多的根本原因:编程语言的缺陷
- 编程语言在表达物理世界的时候,是“有损”的,例如金额为负…这就难顶orz…。编译器只管 “翻译” 代码,不管和实际需求 (规约) 是否匹配,程序员匹配就容易出问题噻!
三十年后的编程语言和编程方法?
更实在的方法:防御性编程
把程序需要满足的条件用 assert 表达出来。
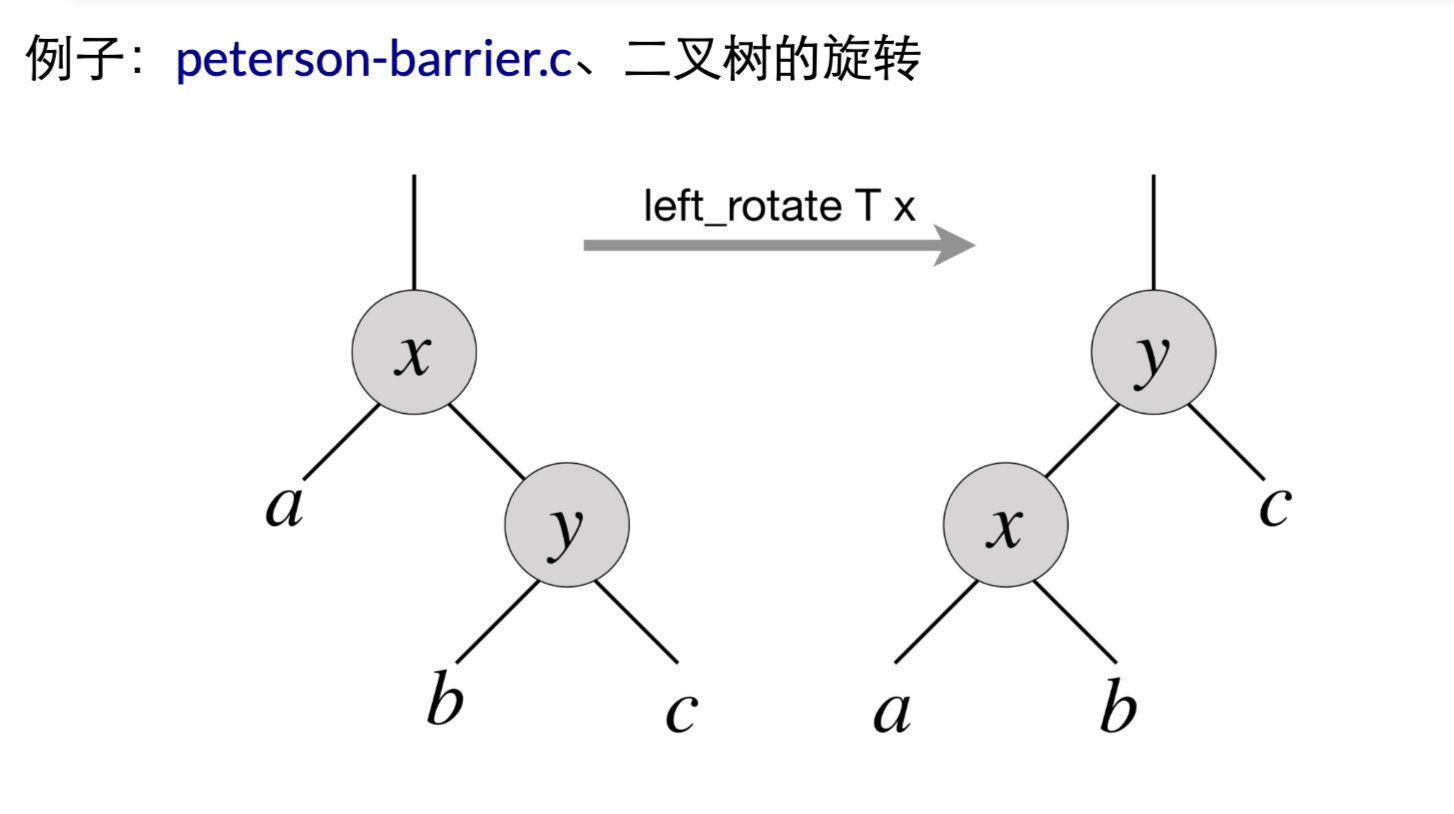
- peterson-barrier.c: 例如在临界区里,对应的逻辑位置,加上assert,进行判断和处理嘛!!!
- 二叉树的旋转: 不管代码是什么,可以对旋转后的结果进行验证的昂。e.g. Assert(y.left == x && y.right == c && …..)
小技巧,防御性编程,实习面试展现一下这个想法,都很好用昂!!!
防御性编程和规约给我们的启发
你知道很多变量的含义
1 | |
变量有 “typed annotation”
CHECK_INT(waitlist->count, >= 0);CHECK_INT(pid, < MAX_PROCS);CHECK_HEAP(ctx->rip); CHECK_HEAP(ctx->cr3);- 变量含义改变 → 发生奇怪问题 (overflow, memory error, …)
- 不要小看这些检查,它们在底层编程 (M2, L1, …) 时非常常见
- 在虚拟机神秘重启/卡住/…前发出警报
- 不一定能考虑周全,但是能够帮助我们,快速找到某种类型的bug捏!比如说,在“指针飞了”的情况下,帮助我们及时找到问题昂(CHECK_HEAP)!!!
并发Bug: Deadlock
A deadlock is a state in which each member of a group is waiting for another member, including itself, to take action.
Deadlock 1: AA
假设你的 spinlock 不小心发生了中断
- 在不该打开中断的时候开了中断
- 在不该切换的时候执行了
yield()
1 | |
lock的时候关中断,unlock的时候开中断,只有一个线程,出现的问题:
- 上了Lock A -> 关中断
- 上了Lock B -> 关中断
- 释放了Lock B -> 开中断???(不行,这里要个计数器,全部释放了才能开,不然手上有锁不释放,就有可能死锁!!!)
- 开了中断之后,如果中断处理程序也要这把锁A,才能正常执行。。。不能成功。。。A要释放,就要等中断返回。但是中断程序要继续执行,需要A的释放。自己等自己?????
- 操作系统内核,甚至一个线程就能把自己锁死。。。
Deadlock 2: ABBA
1 | |
上锁的顺序很重要……
swap本身看起来没有问题:swap(1, 2);swap(2, 3),swap(3, 1)→ 死锁- 上面这个就和哲学家吃饭一样的问题……
避免死锁
死锁产生的四个必要条件
四个条件:
互斥:一个资源每次只能被一个进程使用
请求与保持:一个进程请求资阻塞时,不释放已获得的资源
不可剥夺:进程已获得的资源不能强行剥夺
循环等待:若干进程之间形成头尾相接的循环等待资源关系
“理解了死锁的原因,尤其是产生死锁的四个必要条件,就可以最大可能地避免、预防和解除死锁。所以,在系统设计、进程调度等方面注意如何不让这四个必要条件成立,如何确定资源的合理分配算法,避免进程永久占据系统资源。此外,也要防止进程在处于等待状态的情况下占用资源。因此,对资源的分配要给予合理的规划。” ——Bullshit.
- 实际上,这四个条件想要破除,是相当困难的orz -> 每个条件破除会有很多影响…
AA-Deadlock
- AA 型的死锁容易检测,及早报告,及早修复
- spinlock-xv6.c中的各种防御性编程
if (holding(lk)) panic();
ABBA-Deadlock
- 任意时刻系统中的锁都是有限的
- 严格按照固定的顺序获得所有锁 (lock ordering; 消除 “循环等待”)
- 遇事不决可视化:lock-ordering.py
- 进而证明 T1: A -> B -> C; T2: B -> C是安全的
- 在任意时刻,总有获得“最靠后”锁的可以继续执行
最常用!!!破除“循环等待”!!!按照同一个顺序来获得锁!!!
1 | |
python3 model-checker.py lock-ordering.py | python3 visualize.py > tmp/a.html
- 红边和蓝边,如果没有一个指向自己的,就是对的昂!上面这种方式,不会死锁!!!
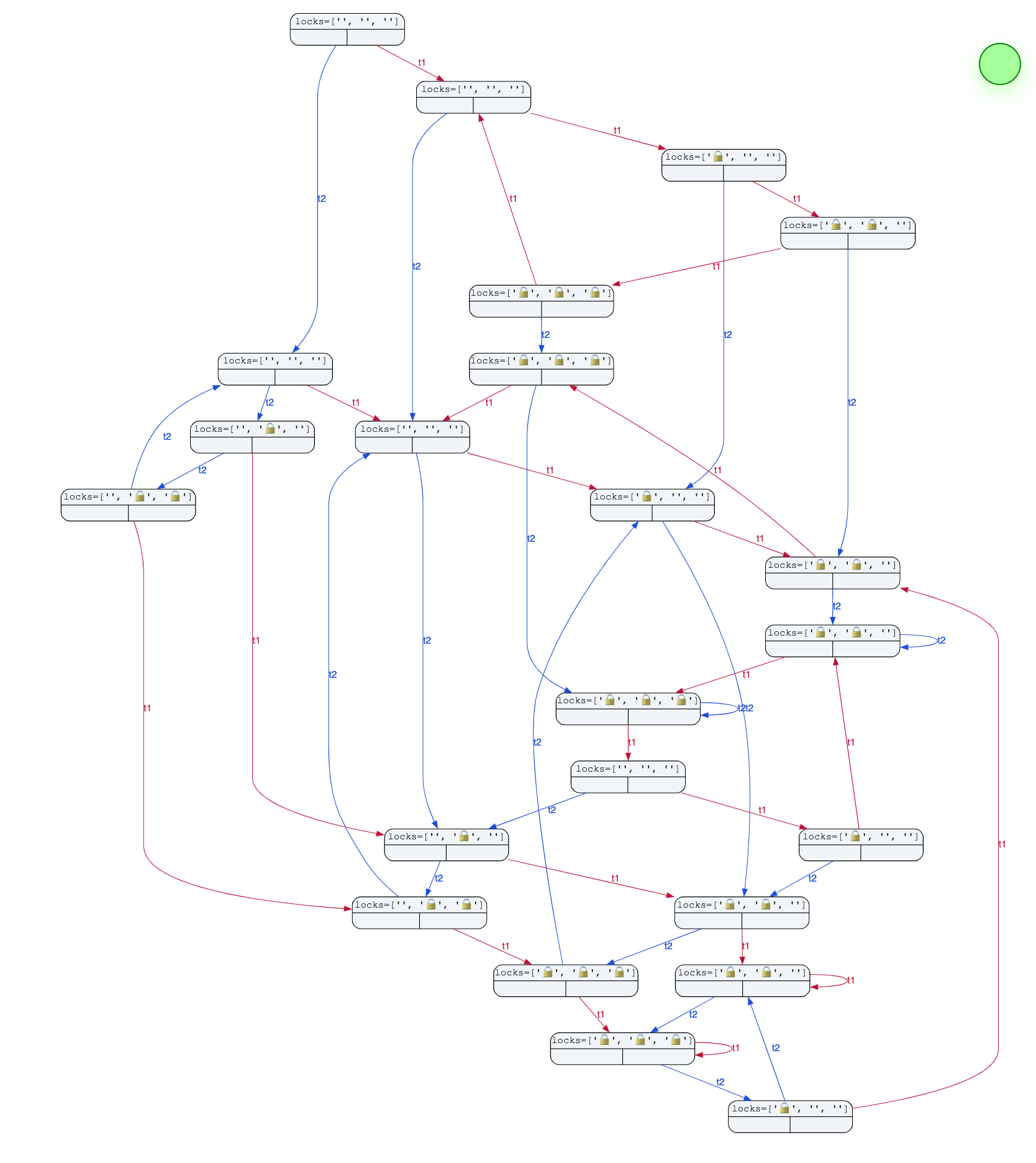
visualize.py和model-checker.py的下载方式放在References里面啦。自己配置一下是真的好用和震撼!!!
死锁也是并发最容易找到的bug,很显然,程序不会再继续执行下去了,就是死锁了呀!!!
Naive
Textbooks will tell you that if you always lock in the same order, you will never get this kind of deadlock. Practice will tell you that this approach doesn’t scale: when I create a new lock, I don’t understand enough of the kernel to figure out where in the 5000 lock hierarchy it will fit.
The best locks are encapsulated: they never get exposed in headers, and are never held around calls to non-trivial functions outside the same file. You can read through this code and see that it will never deadlock, because it never tries to grab another lock while it has that one. People using your code don’t even need to know you are using a lock.
并发Bug: 数据竞争
不同的线程同时访问同一段内存,且至少有一个是写。两个内存访问在 “赛跑”,“跑赢” 的操作先执行。(不确定性)
Peterson 算法告诉大家:
你们写不对无锁的并发程序
所以事情反而简单了
用互斥锁保护好共享数据,消灭一切数据竞争。
以下代码概括了你们遇到数据竞争的大部分情况
- 不要笑,你们的 bug 几乎都是这两种情况的变种
1 | |
1 | |
很多内存访问,每一处内存竞争写的地方,上把锁就行哇!!! -> 总能消除数据竞争的昂!!!
但是终极问题没有解决:人的思维还是单线程,而不是多线程!
更多类型的并发Bug
回顾我们实现并发控制的工具
- 互斥锁 (lock/unlock) - 原子性
- 条件变量 (wait/signal) - 同步
忘记上锁——原子性违反 (Atomicity Violation, AV)
忘记同步——顺序违反 (Order Violation, OV)
Empirical study: 在 105 个并发 bug 中 (non-deadlock/deadlock)
- MySQL (14/9), Apache (13/4), Mozilla (41/16), OpenOffice (6/2)
- 97% 的非死锁并发 bug 都是 AV 或 OV。
原子性的违反
- “ABA”:我以为一段代码没啥事呢,但被人强势插入了
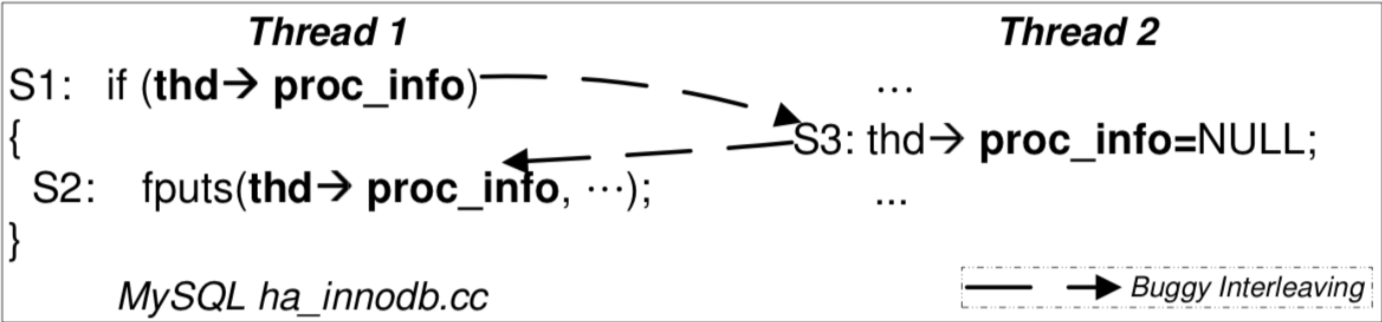
- 有时候上锁也不解决问题:
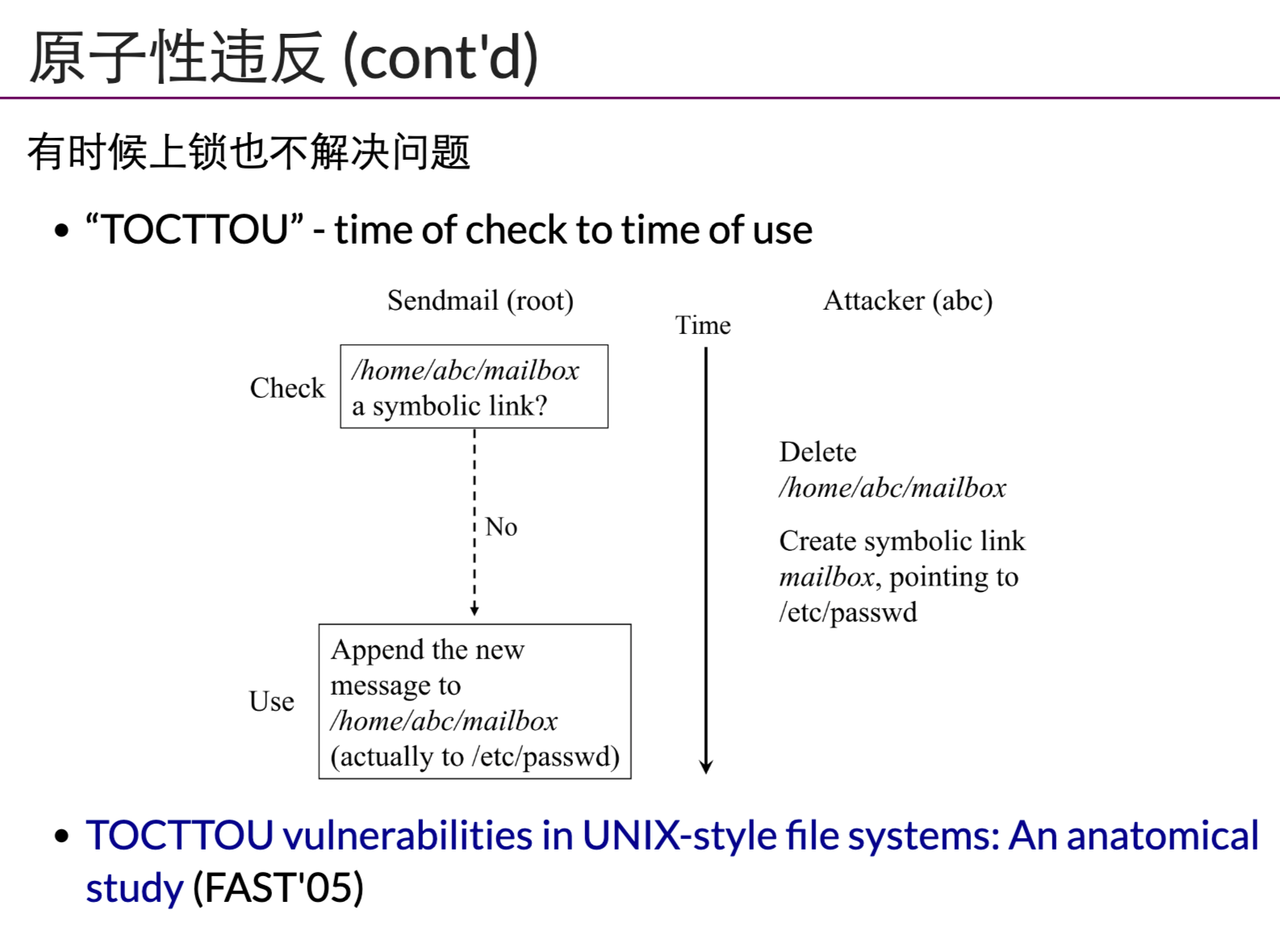
顺序违反
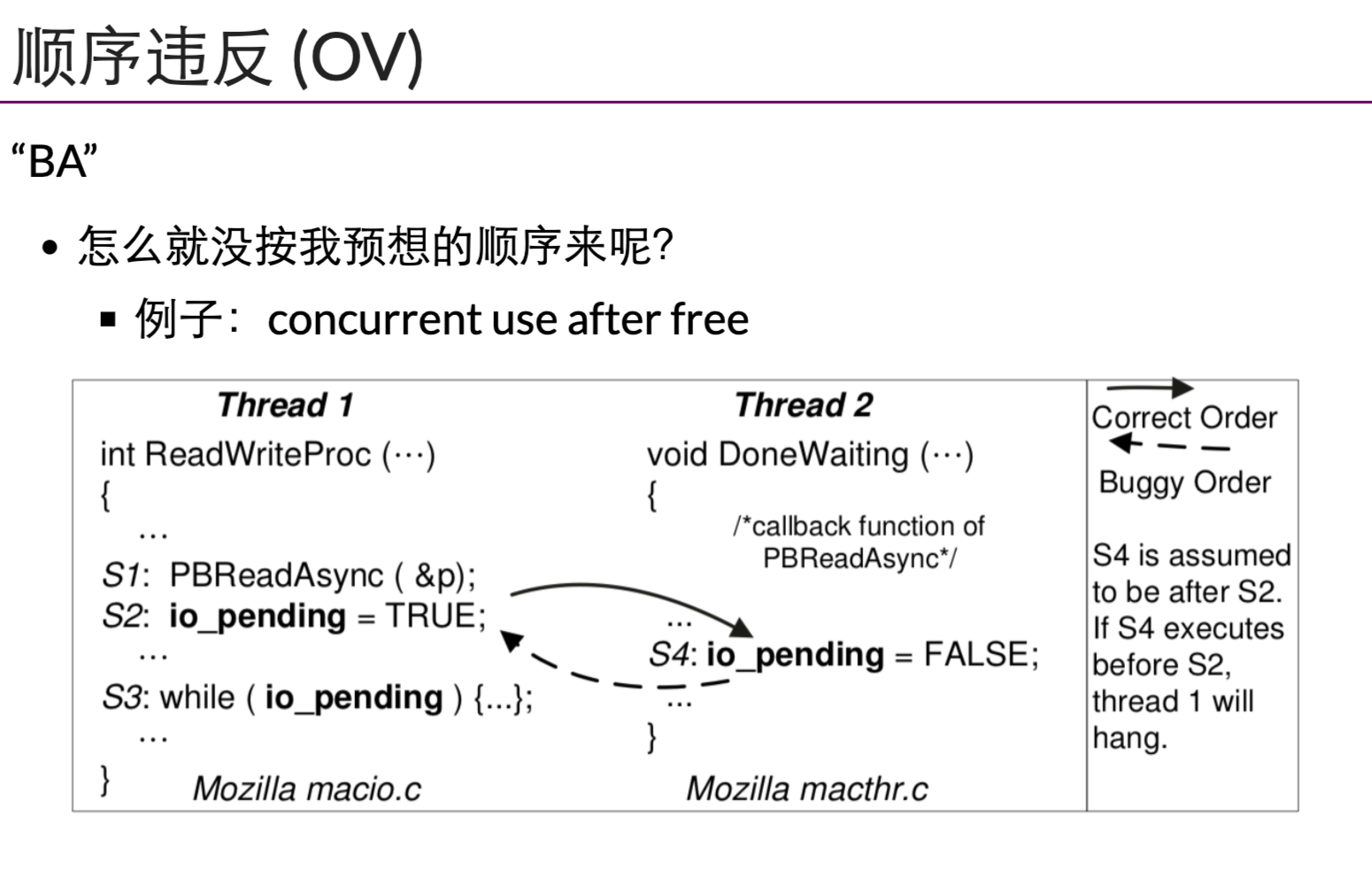
应对并发Bug的方法
还是得始终假设自己的代码是错的。
然后呢?
做好测试
检查哪里错了
再检查哪里错了
再再检查哪里错了
- (把任何你认为 “不对” 的情况都检查一遍)
例如:用 lock ordering 彻底避免死锁?
- 你想多了:并发那么复杂,程序员哪能充分测试啊
Lockdep: 运行时的死锁检查

1 | |
把所有可能的上锁和解锁顺序都可以打印出来呀!!!甚至可以对于lock-ordering进行检查!!!必须x -> y -> z,x一定要在y, z左边,我们实际在动态维护一个图昂,x -> y -> z,然后再x -> z,就有个这个图,不应该存在环!!!
ThreadSanitizer: 运行时的数据竞争检查
同一把锁有先后顺序的昂!!!
为所有事件建立 happens-before 关系图
Program-order + release-acquire
对于发生在不同线程且至少有一个是写的 x,yx,y 检查

- 上锁之间的happens-before,可以建立线程之间的happens-before。
- 同一个线程内的执行,也有happens-before。
- 然后整体做一个传递闭包,可以找到事件的顺序先后关系。可以按照图的方式,来解决相关的问题。 -> 一个点到另外一个点之间,是否存在路径:有路径就是没有数据竞争,没有路径就是数据竞争!!!
更多的检查:动态程序分析
上面两种都是动态程序分析下的工具
在事件发生时记录
Lockdep: lock/unlock
ThreadSanitizer: 内存访问 + lock/unlock
- 解析记录检查问题
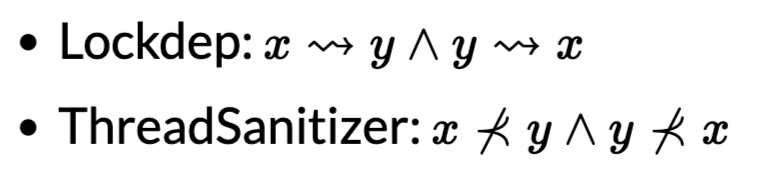
付出的代价和权衡
程序执行变慢
但更容易找到 bug (因此在测试环境中常用)
动态分析工具:Santilizers
编译选项,设置成默认,就非常方便我们找到Bug之类的昂!!!
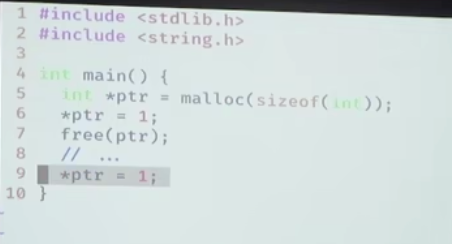
找到上面这种Bug,就可以加一些默认的编译选项
e.g. gcc -g uaf.c -fsanitize=address(可以找到地址的不正常使用) || gcc -g uaf.c -fsanitize=address(可以找到date race等)
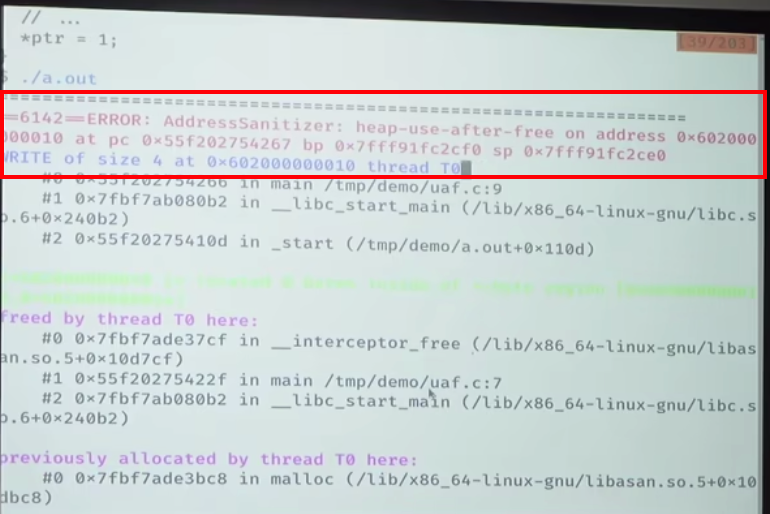
上面这些工具都很好用!!!可以通过不同的fsanitize,帮助我们找到不同的并发bug。
没用过 lint/sanitizers?
- AddressSanitizer(asan);(paper): 非法内存访问
- ThreadSanitizer(tsan): 数据竞争
- Demo: fish.c, sum.c, peterson-barrier.c; ktsan
- MemorySanitizer (msan): 未初始化的读取
- UBSanitizer(ubsan): undefined behavior
- Misaligned pointer, signed integer overflow, …
- Kernel 会带着
-fwrapv编译
很方便的使用哇!!!编译带上选项就好啦!!!本质无非就是:防御性编程,悄悄帮我们把检查都做了昂!!!
DIY Santilizers

- 田忌赛马?舍一保一是吧。。。Canary的例子:
1 | |
手动在栈顶和栈底预留了一些空间,快要发生栈溢出的时候,就能够帮助我们及时报错。(防御性编程)
- 类似于上面这样的Canary or 防御性编程实际例子:
VSSutdio,如果缓冲区没做好,可能会报烫烫烫烫烫烫之类的。编译器自动会根据堆之类的状态,为其在使用之前 or 使用之后之类的情况,分配一些初始值!方便检查 & 保护!
- 低配版Lockdep
死锁的特征?一直不停的尝试上锁 -> 上锁给个正常不可能的限制,设置一个边界,超过就报错。

很多种实现方式啊,不一定就一种,找到特点定制化就行。把他们的思想收纳到防御性编程中,而且,收益极大!!!
- 其他的东西:

往前走一小步,做一点点,就会有巨大的收益。
- Malloc分配的时候,分配的内存可以全部都刷上一个颜色(红色)。free回收的时候,全部刷上另外一个颜色(蓝色)。
- 如果在分配的时候,发现了红色,就会出问题。把别人的东西,拿来用了。或者free的时候,已经是蓝色了。 -> 设置了好的边界,方便我们进行防御性编程和bug的找寻。

上面这些所有的动态分析工具,我们都可以做出低配版来!!!做简单的检查昂!!!
References
笑死,JYY名言警句:懂System的人的编程,到处都是防御性的代码哈哈哈哈。
课件上的文件怎么下载,例如visualization.py
以及model-checker.py:https://blog.csdn.net/weixin_44310435/article/details/125132791
wget http://jyywiki.cn/pages/OS/2022/demos/model-checker.py wget http://jyywiki.cn/pages/OS/2022/demos/visualize.py wget http://jyywiki.cn/pages/OS/2022/demos/lock-ordering.py还要下一些依赖和环境,自己配置好了,是真爽呐~好用好用好用!!!
类似的,其他的文件和课件,也可以通过上面这种方式,把最后的文件名改一下,通过wget拉下来昂!!!
视频链接: