Stanford Pratical Machine Learning-过拟合和欠拟合
本文最后更新于:1 年前
这一章主要介绍过拟合和欠拟合,Overfitting和Underfitting。
Who will Repay Their Loans?
- A lender hires you to investigate who will repay their loans
- You are given all information about the 100 applicants
- 5 defaulted within 3 years
- A Surprising Finding?!
- All 5 people who defaulted wore blue shirts during interviews
- Your model leverages this strong signal as well
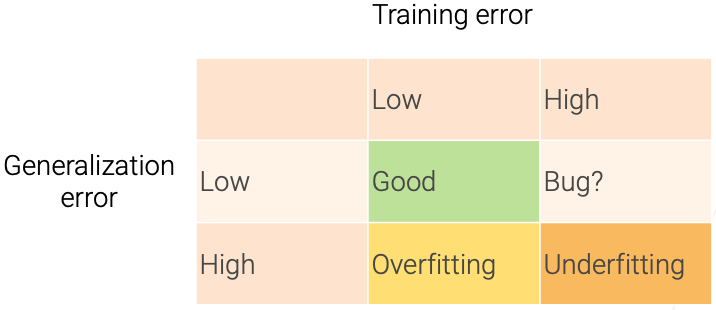
Underfitting and Overfitting
- Training error: model error on the training data
- Generalization error: model error on new data
Data and Model Complexity
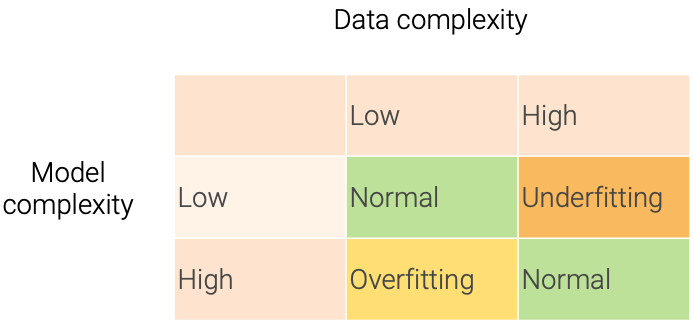
数据和模型复杂度一致的时候,效果比较好。模型的复杂度,是模型拟合复杂数据的能力。
Model Complexity
- The capacity of a set of function to fit data points
- In ML, model complexity usually refers to:
- The number of learnable parameters
- The value range for those parameters
- It’s hard to compare between different types of ML models
- E.g. trees vs neural network
- More precisely measure of complexity: VC dimension
- VC dim for classification model: the maximum number of examples the model can shatter
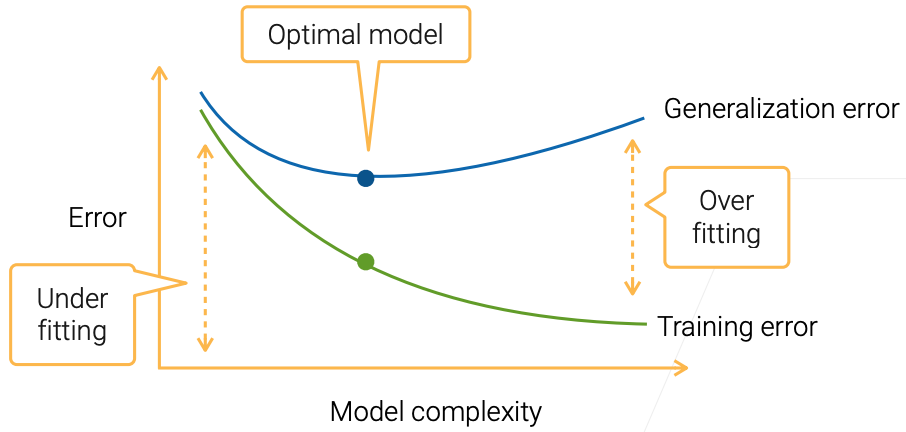
- Influence of Model Complexity
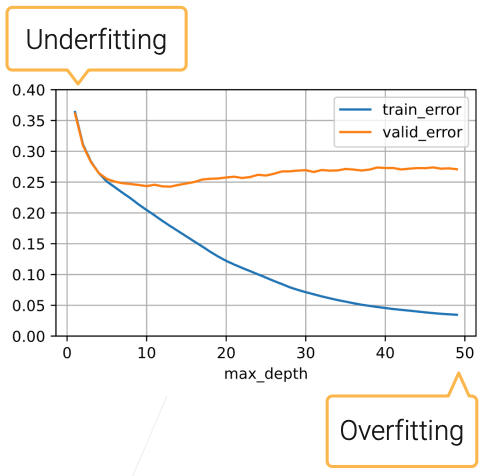
Model Complexity Example: Decision Tree
- The tree size can be controlled by the number of levels
- Use scikit-learn DecisionTreeRegressor(max_depth = n) on house sales data
Data Complexity
- Multiple factors matters
- #of examples
- #of features in each example
- Time/space structure
- Diversity
- the separability of the classes
- Again, hard to compare among very different data
- E.g a char vs a pixel
- More precisely, Kolmogorov complexity
- A data is simple if it can be generated by a short program
Model Complexity vs Data Complexity
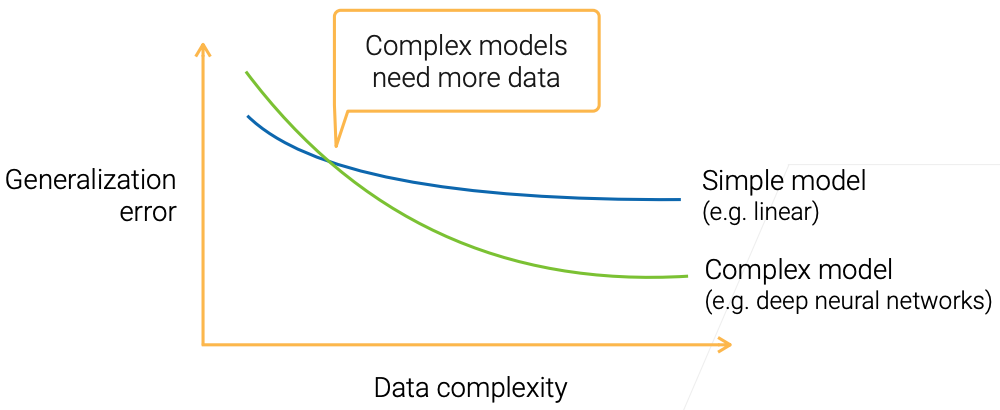
Model Selection
- Pick a model with a proper complexity for your data
- Minimize the generalization error
- Also consider business metrics
- Pick up a model family, then select proper hyper-parameters
- Trees: #trees, maximal depths
- Neural networks: architecture, depth (#layers), width (#hidden units), regularizations
Summary
- We care about generalization error
- Model complexity: the ability to fit various functions
- Data complexity: the richness of information
- Model selection: match model and data complexities
References
Stanford Pratical Machine Learning-过拟合和欠拟合
https://alexanderliu-creator.github.io/2023/08/25/stanford-pratical-machine-learning-guo-ni-he-he-qian-ni-he/