Stanford Pratical Machine Learning-特征工程
本文最后更新于:1 年前
这一章主要介绍特征工程,上一章是如何将数据转换为我们需要的格式。这一章更进一步,从处理好的数据中,提取出模型用的特征。
Feature Engineering
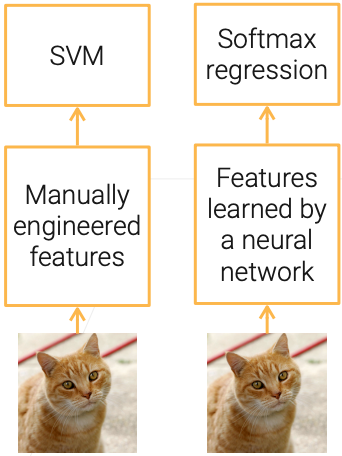
- Before deep learning (DL), feature engineering (FE) was critical to using ML models
- Traditional CV: detect corners / interest points..
- DL train deep neural networks to automatically extract features
- Train CNN to replace feature extractor
- Features are more relevant to the final task
- Limitation: data hungry, computation heavy
Tabular Data Features
- Tabular data are in the form of a table, feature columns of numeric / categorical / string type
- Int/float: directly use or or bin to unique n int values
- Categorical data: one-hot encoding
- Map rare categories into “Unknown”
- Date-time: a feature list such as
- [year, month, day, day_of_year, week_of_year, day_of_week]
- Feature combination: Cartesian product of two feature groups
- [cat, dog] x [male, female] -> [(cat, male), (cat, female), (dog, male), (dog, female)]
其实本质就是把数据 -> 特征,让后面的模型学习更加方便
Text Features
- Represent text as token features
- Bag of words (BoW) model
- Limitations: needs careful vocabulary design, losing context for individual words
- Word Embeddings (e.g. Word2vec):
- Vectorizing words such that similar words are placed close together
- Trained by predicting target word from context words
- Bag of words (BoW) model
- Pre-trained universal language models (e.g. universal sentence encoder, BERT, GPT-3)
- Giant transformer models
- Trained with large amount of unannotated data
- Usage: Text embedding; fine-tuning for downstream tasks
Image/Video Features
- Traditionally extract images by hand-craft features such as SIFT
- Now pre-trained deep neural networks are common used as feature extractor
- ResNet: trained with ImageNet (image classification)
- I3D: trained with Kinetics (action classification)
- Many off-the-shelf models available
References
Stanford Pratical Machine Learning-特征工程
https://alexanderliu-creator.github.io/2023/08/24/stanford-pratical-machine-learning-te-zheng-gong-cheng/