Stanford Pratical Machine Learning-数据科学家的日常
本文最后更新于:1 年前
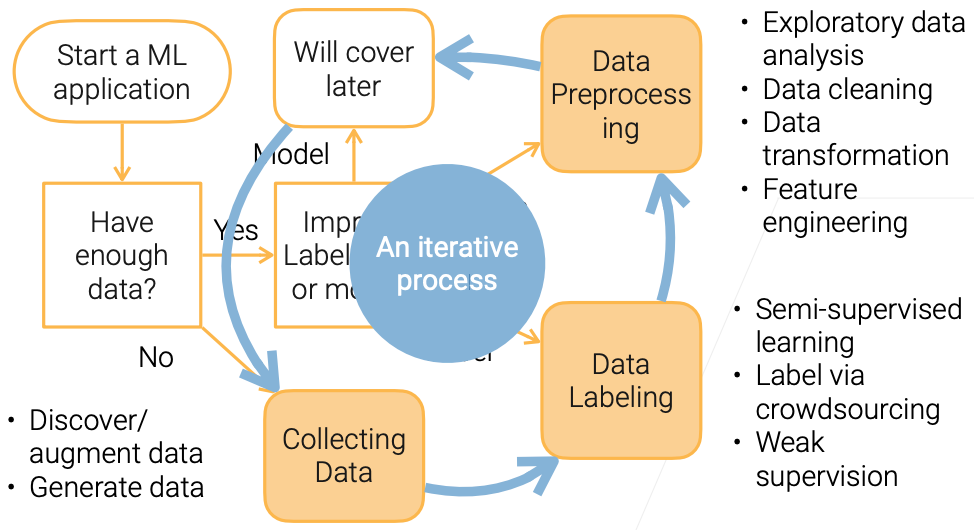
这一章主要介绍数据科学家的日常,主要是一个总结篇,对于前几章的数据预处理做一个大大的总结。
流程
- 是否有数据?
- 没有 -> 找数据,增强数据,生成数据
啥都没有,这个任务可能不适合机器学习昂。
- 有数据,如何提升任务精度?
- Improve label, data, model
- Data -> Data Preprocessing
- Lable -> Data Labeling
- Model -> Model Improvement
- Improve label, data, model
Chanllenges
- Trade-off between label quality vs data volume
- Data quality:
- diversity: all relevant aspects are represented
- unbiased: no biased on a particular side
- Faireness: non discriminating treatment of data and people
- Large-scale data management: storage, process, versioning, security
References
Stanford Pratical Machine Learning-数据科学家的日常
https://alexanderliu-creator.github.io/2023/08/24/stanford-pratical-machine-learning-shu-ju-ke-xue-jia-de-ri-chang/