Stanford Pratical Machine Learning-机器学习简介
本文最后更新于:1 年前
这一章主要简单介绍一下机器学习,包括机器学习的类型之类的。
Types of ML Algorithms
Supervised:Train on labeled data to predict labels
- Self-supervised: Labels are generated from data. (E.g. word2vec, Bert)
Semi-supervised:Train on both labeled and unlabeled data, use models to infer labels for unlabeled data
- E.g. self-training
Unsupervised:Train on unlabeled data
- E.g. clustering, density estimation(GAN)
Reinforcement learning:Use observations from the interaction with the environment to take actions to maximize reward
Tips:
We can design supervised training tasks for unlabeled data:
- Self-supervised learning: generate labels from data. E.g. word2vec, BERT
- GAN: generating fake data with trivial label from unlabeled data
Training tasks can be different from how the model is evaluated / used.
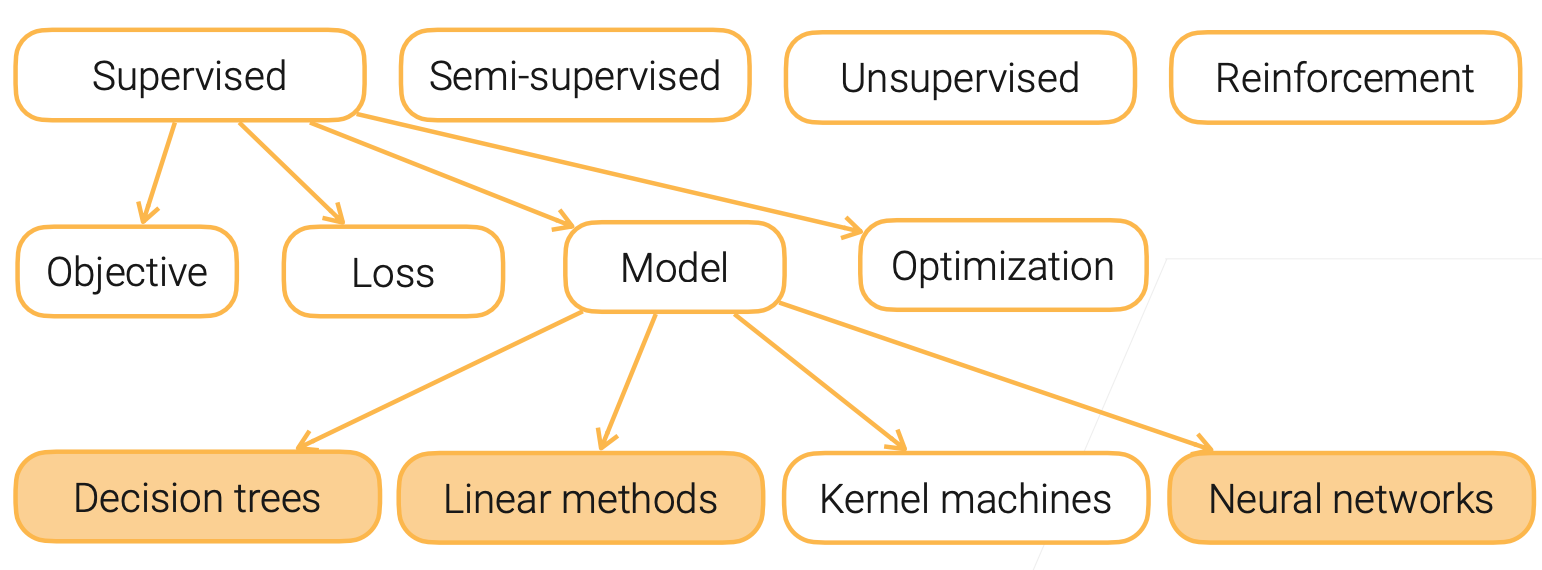
Components in Supervised Training
Model
- A parameterized function to map inputs to label
- Model parameters VS hyper parameters
- E.g. listing house -> sale price
- A parameterized function to map inputs to label
Loss
- The measure of how good the model does in terms of predicting the outcome
- E.g. classification / regression / contrastive / triplet / ranking
- E.g. $(predict_price - sale_price) ^ 2$
- The measure of how good the model does in terms of predicting the outcome
Objective
- The goal to optimize model params for
- E.g. minimize the sum of losses over examples
- The goal to optimize model params for
Optimization
- The algorithm for solving the objective
Types of Supervised Models
- Decision trees: Use trees to make decisions
- Linear methods: Decision is made from a linear combination of input features
- Kernel machines: Use kernel functions to compute feature similarities
- Neural Networks: Use neural networks to learn feature representations
Summary
References
Stanford Pratical Machine Learning-机器学习简介
https://alexanderliu-creator.github.io/2023/08/24/stanford-pratical-machine-learning-ji-qi-xue-xi-jian-jie/