NJUOS-4-理解并发程序执行
本文最后更新于:2 年前
JYY第四课:理解并发程序执行,承接上一话多处理器编程的内容。让我们对于程序并发执行有更加深入的理解。这里自己补充了一些CPU中缓存一致性的东西(也算是和并发沾边?)
理解并发程序执行
- 并发模型:
多处理器,编译器,内存都是阻碍。状态机非常重要!!!
理解并发程序执行:无非就是画状态机嘛!把所有可能状态花清楚,考虑清楚,并发就没有问题昂!!!
互斥:保证两个程序不能同时执行一段代码。

假设内存的读/写,可以保证顺序,原子完成。对于内存就是write/read(store/load),如何保证程序互斥呢?
手动实现互斥
第一种方式实现(类似于手动自旋锁):
1 | |
现代处理器默认不保证load + store的原子性
第二种方式实现(Peterson算法)
Peterson算法其实提出了一种协议,基于共享内存之上的。
- Store: 改变状态
- Load: 查看状态
核心问题:从Load到实际处理过程中,Load其实看到的是“过去的”状态。没有人能够保证,Load和业务代码的执行过程中,看到的那个“过去的”状态,不会被其他人改变。


证明:
- 暴力写程序(实践证明,但是不规范,万一一直执行都没有碰上特殊情况呢?)
- 画出所有的状态机(理论证明,规范) -> 本质就是通过暴力穷举所有的情况来证明昂!!!
- 程序是对的,但是发现 -> 当程序没有加上内存屏障的时候,依旧会发生问题 -> CPU会对于指令进行重排序,导致结果出现问题,算法没有问题哈!!!
画状态机(自动)

model checker: 遍历所有可能的模型(并发程序)的顺序
- 看看视频吧… -> visualize.py好高级…… -> 自动完成状态机的遍历,对于状态进行判断并可视化绘图…好厉害…
Model Checker
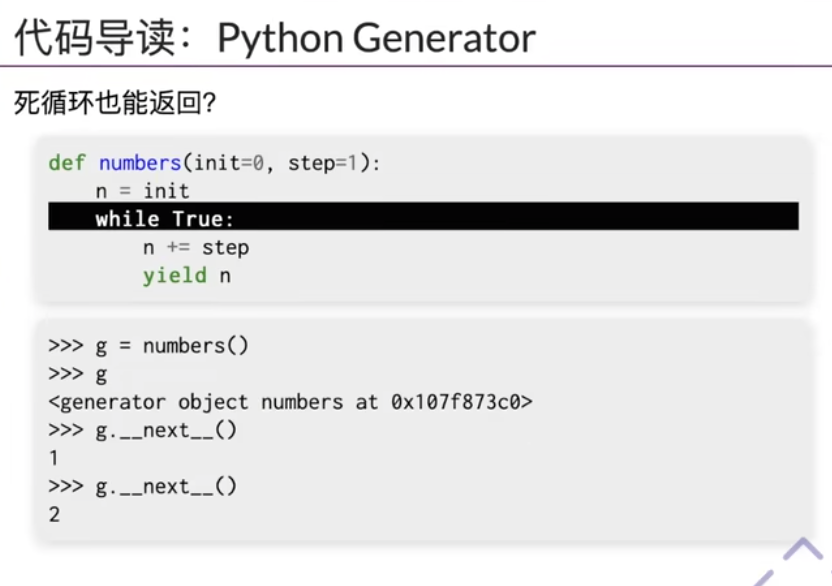
用python的特性(例如yield),可以在死循环中保存函数的状态 -> 状态机很高级,在程序中间,保存程序的状态昂!!!Model Checker可以把每一行当成一个原子操作,然后在操作完成后,返回程序执行到这一行的时候的状态!!!
- 在python中,可以创建和保存任意的状态机(不同的generator),可以认为是不同的线程。 -> 所有创建的状态机,都是共享内存的,就可以完成各种状态的遍历哇!!!
每一个yield就能保存状态机当前的状态checkpoint,我们就可以在外面接收到状态,并进行暴力搜索遍历(BFS)!!! -> 就很方便!!!python就是yyds!!! -> 把结果画成图图昂!!!
- 核心想法(十分有价值):

Model-checking: 只要建立合理的模型,就可以采用prove by brute-force的方式证明正确/找到问题。分布式系统就类似于我们的并发系统,可能会遇到各种各样并发的问题。这个时候就可以枚举所有的状态,找到问题。
程序正确性问题 -> 状态机抽象 -> 图论问题,这就是抽象一个很牛的地方,可以通过状态机的遍历,来check程序可能经历的每一个状态以及其正确性。
- e.g. 是否从任何地方出发,经过有限步,能否走到某些特殊状态。 -> 图论的问题,联通图之类的东西… (算法和实际应用的结合)

减少状态(类似于剪枝) -> 从而快速找得到答案
- 工具 is important

References
- https://www.bilibili.com/video/BV15T4y1Q76V/?spm_id_from=333.999.0.0&vd_source=ff957cd8fbaeb55d52afc75fbcc87dfd
- http://jyywiki.cn/OS/2022/ -> http://jyywiki.cn/OS/2022/slides/4.slides#/
自学内容补充
MESI协议 & 缓存体系结构
参考:
- https://xiaolincoding.com/os/1_hardware/cpu_mesi.html#cpu-cache-%E7%9A%84%E6%95%B0%E6%8D%AE%E5%86%99%E5%85%A5
- https://mp.weixin.qq.com/s/-uhAhBD2zGl_h19E4fNJzQ
- https://mp.weixin.qq.com/s?__biz=MzUxODAzNDg4NQ==&mid=2247485960&idx=1&sn=476d40b3e272149ba6c7370340e9768f&scene=21#wechat_redirect
- https://mp.weixin.qq.com/s?__biz=MzUxODAzNDg4NQ==&mid=2247485918&idx=1&sn=f7fa3aa2a7cc362eeebad09d4d6fa03a&scene=21#wechat_redirect
- https://alexanderliu-creator.github.io/2022/12/05/cpu-cache-xue-xi/
小林coding相关内容如上
缓存体系结构:
架构介绍
- CPU Cache 就是上面这一整块儿,通常分为三级缓存:L1 Cache、L2 Cache、L3 Cache,级别越低的离 CPU 核心越近,访问速度也快,但是存储容量相对就会越小。其中,在多核心的 CPU 里,每个核心都有各自的 L1/L2 Cache,而 L3 Cache 是所有核心共享使用的。L1 Cache又可以分为L1数据缓存和L1指令缓存,整体架构如下图所示:
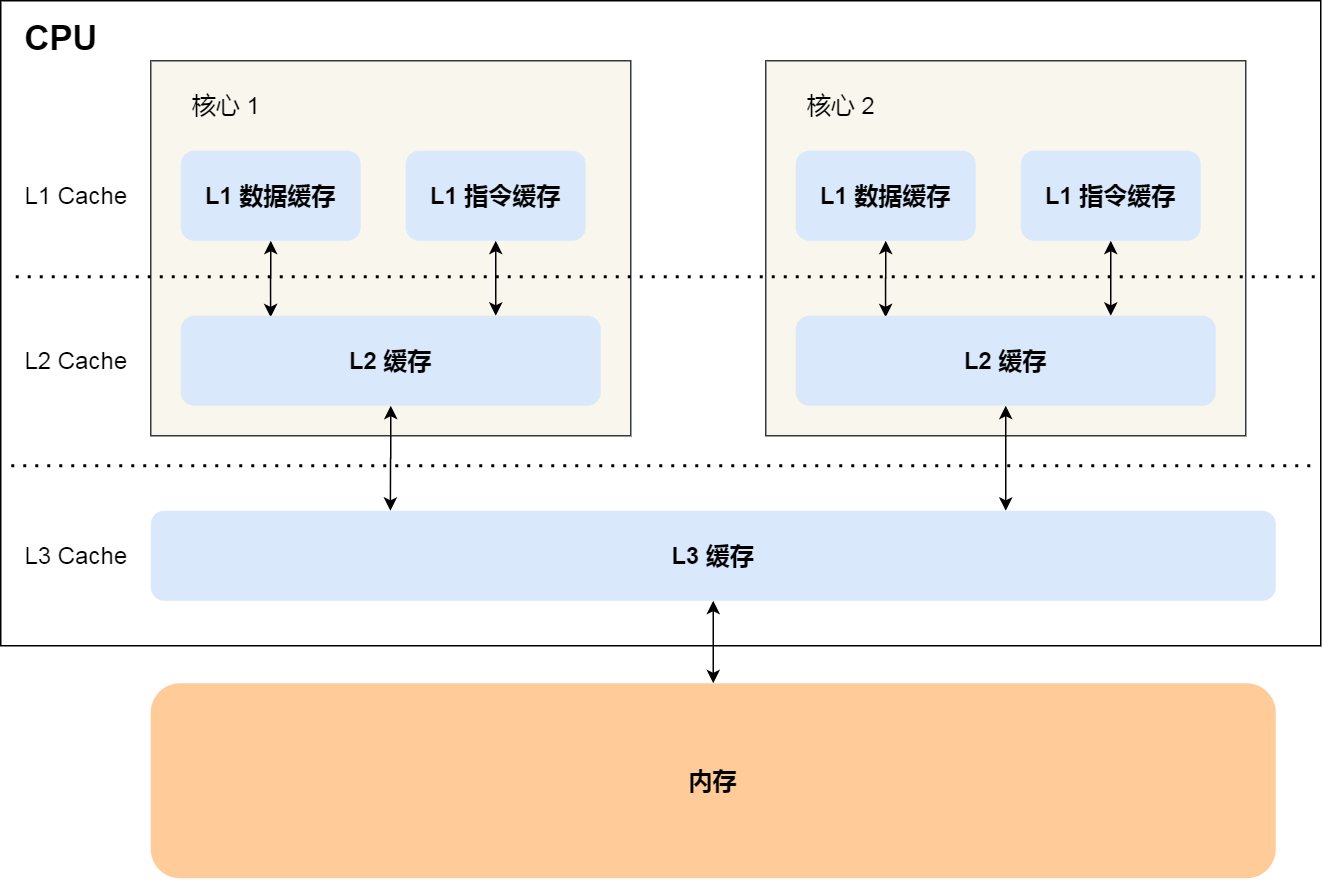
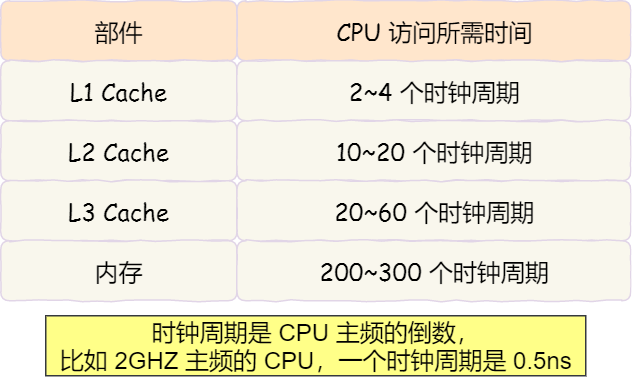
L1 Cache比内存快了100多倍orz
Cache Line介绍
- CPU Cache 是由很多个 Cache Line 组成的,CPU Line 是 CPU 从内存读取数据的基本单位,而 CPU Line 是由各种标志(Tag)+ 数据块(Data Block)组成。换句话说,Cache Line就是CPU Cache到基本单位,由多个Cache Line组成,Cache Line的结构:
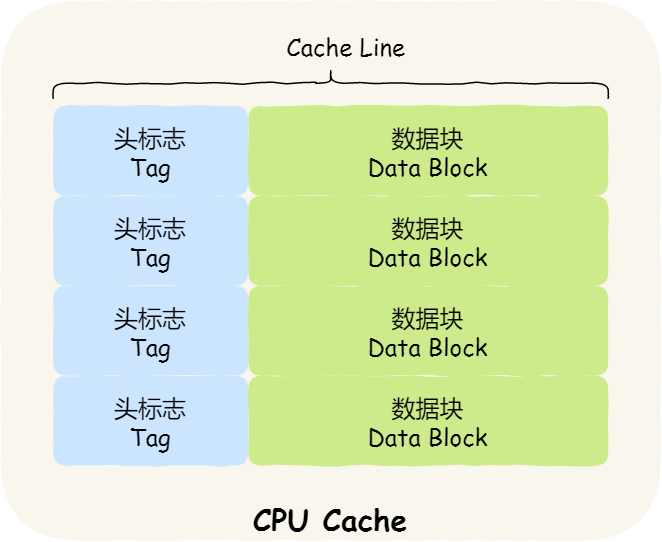
- 那Cache Line的大小怎么查看?Cache Line的工作原理呢?
Linux中可以通过sys/devices等方式查看缓存大小,缓存行的大小coherency_line_size,可以康康这个指标昂!!!
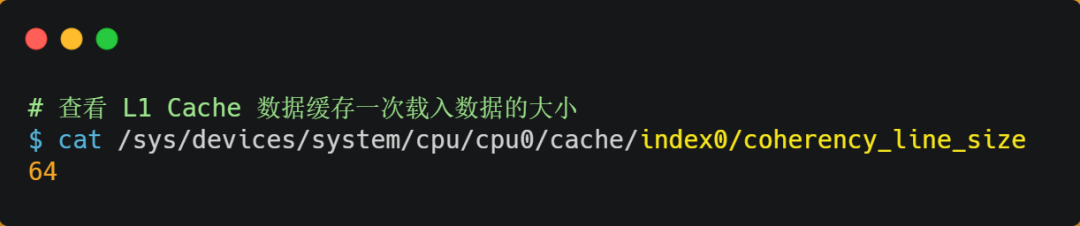
上面这台机器,我们就看到,缓存行(缓存基本单位)的大小是64个字节。有一个
int array[100]的数组,当载入array[0]时,由于这个数组元素的大小在内存只占 4 字节,不足 64 字节,CPU 就会顺序加载数组元素到array[15],意味着array[0]~array[15]数组元素都会被缓存在 CPU Cache 中了,因此当下次访问这些数组元素时,会直接从 CPU Cache 读取,而不用再从内存中读取,大大提高了 CPU 读取数据的性能。
Cache Line和内存的映射
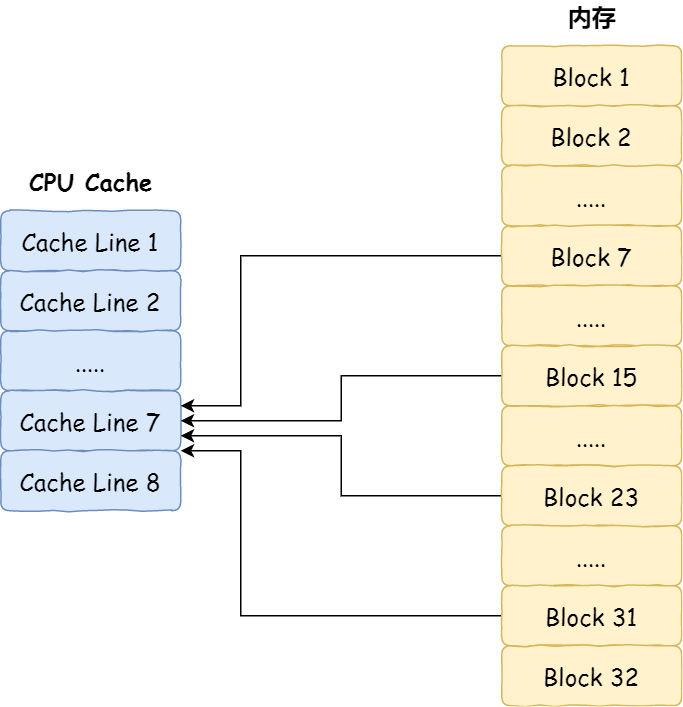
- CPU的Cache小,而内存非常大,怎样映射的呢?
直接映射
- 最简单、基础的直接映射 Cache(Direct Mapped Cache) 说起,来看看整个 CPU Cache 的数据结构和访问逻辑。前面,我们提到 CPU 访问内存数据时,是一小块一小块数据读取的,具体这一小块数据的大小,取决于 coherency_line_size的值,一般 64 字节。在内存中,这一块的数据我们称为内存块(Bock),读取的时候我们要拿到数据所在内存块的地址。
直接映射 Cache 采用的策略,就是把内存块的地址始终「映射」在一个 CPU Line(缓存块) 的地址,至于映射关系实现方式,则是使用「取模运算」,取模运算的结果就是内存块地址对应的 CPU Line(缓存块) 的地址。
- 举个例子,内存共被划分为 32 个内存块,CPU Cache 共有 8 个 CPU Line,假设 CPU 想要访问第 15 号内存块,如果 15 号内存块中的数据已经缓存在 CPU Line 中的话,则是一定映射在 7 号 CPU Line 中,因为
15 % 8的值是 7。
全相连
组相连
Cache Line的非数据部分组成
但是问题也来了,映射进来之后,如何标记是哪里映射的呢?以及如何标记数据过期啊之类的?
Cache Line的非数据部分组成:
- 为了区别不同的内存块,在对应的 CPU Line 中我们还会存储一个组标记(Tag)。这个组标记会记录当前 CPU Line 中存储的数据对应的内存块,我们可以用这个组标记来区分不同的内存块:
- 一个是,从内存加载过来的实际存放数据(Data)。
- 另一个是,有效位(Valid bit),它是用来标记对应的 CPU Line 中的数据是否是有效的,如果有效位是 0,无论 CPU Line 中是否有数据,CPU 都会直接访问内存,重新加载数据。
CPU从CPU Cache中读取数据规则:CPU 在从 CPU Cache 读取数据的时候,并不是读取 CPU Line 中的整个数据块,而是读取 CPU 所需要的一个数据片段,这样的数据统称为一个字(Word)。那怎么在对应的 CPU Line 中数据块中找到所需的字呢?答案是,需要一个偏移量(Offset)。CPU从CPU Cache中读取数据规则:
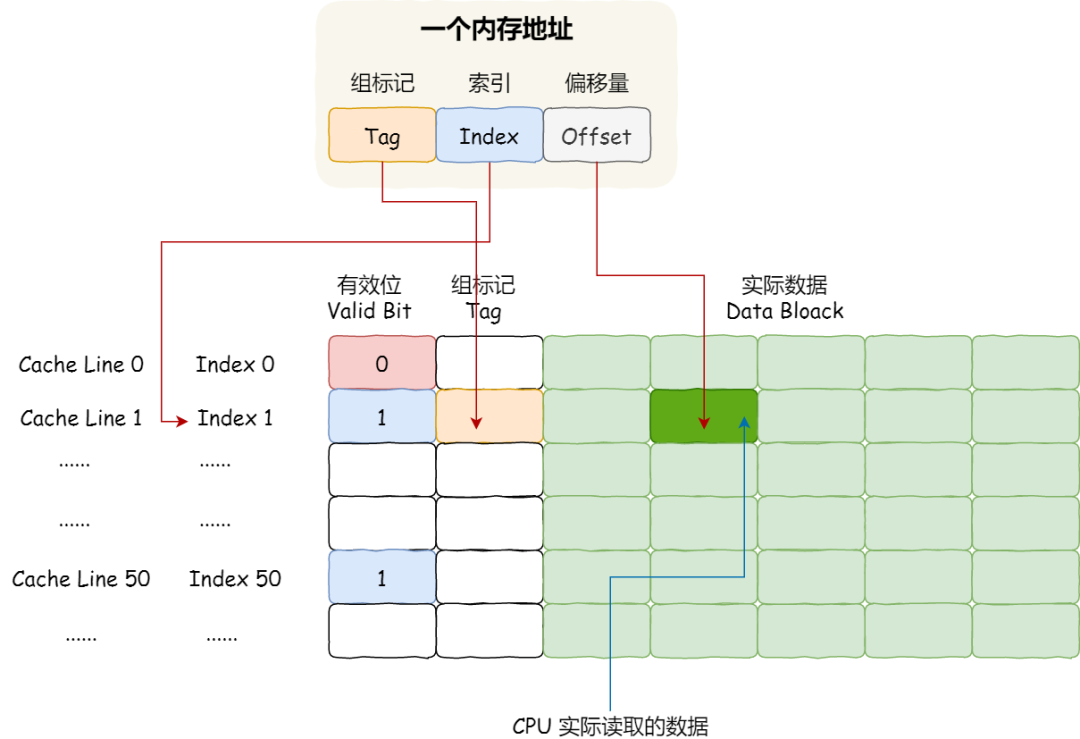
CPU访问缓存步骤
- 根据内存地址中索引信息,计算在 CPU Cahe 中的索引,也就是找出对应的 CPU Line 的地址;
- 找到对应 CPU Line 后,判断 CPU Line 中的有效位,确认 CPU Line 中数据是否是有效的,如果是无效的,CPU 就会直接访问内存,并重新加载数据,如果数据有效,则往下执行;
- 找到对应 CPU Line 后,判断 CPU Line 中的有效位,确认 CPU Line 中数据是否是有效的,如果是无效的,CPU 就会直接访问内存,并重新加载数据,如果数据有效,则往下执行;
- 根据内存地址中偏移量信息,从 CPU Line 的数据块中,读取对应的字。
CPUs run faster
CPU 访问内存的速度,比访问 CPU Cache 的速度慢了 100 多倍,所以如果 CPU 所要操作的数据在 CPU Cache 中的话,这样将会带来很大的性能提升。访问的数据在 CPU Cache 中的话,意味着缓存命中,缓存命中率越高的话,代码的性能就会越好,CPU 也就跑的越快。
如何写出让 CPU 跑得更快的代码? -> 如何写出 CPU 缓存命中率高的代码?
- L1 Cache 通常分为「数据缓存」和「指令缓存」,这是因为 CPU 会别处理数据和指令,比如
1+1=2这个运算,+就是指令,会被放在「指令缓存」中,而输入数字1则会被放在「数据缓存」里。因此,我们要分开来看「数据缓存」和「指令缓存」的缓存命中率。
经典例子
1 | |
第一种比第二种快好几倍。假设N=2,因为在内存中,数据的存储是array[0][0], array[0][1], array[1][0], array[1][1]。
- 用
array[i][j]访问数组元素的顺序,正是和内存中数组元素存放的顺序一致。当 CPU 访问array[0][0]时,由于该数据不在 Cache 中,于是会「顺序」把跟随其后的 3 个元素从内存中加载到 CPU Cache,这样当 CPU 访问后面的 3 个数组元素时,就能在 CPU Cache 中成功地找到数据,这意味着缓存命中率很高,缓存命中的数据不需要访问内存,这便大大提高了代码的性能。- 用
array[j][i]方式跳跃式的,而不是顺序的,那么如果 N 的数值很大,那么操作array[j][i]时,是没办法把array[j+1][i]也读入到 CPU Cache 中的,既然array[j+1][i]没有读取到 CPU Cache,那么就需要从内存读取该数据元素了。很明显,这种不连续性、跳跃式访问数据元素的方式,可能不能充分利用到了 CPU Cache 的特性,从而代码的性能不高。
array[0][0]元素时,CPU 具体会一次从内存中加载多少元素到 CPU Cache 呢?这个问题,在前面我们也提到过,这跟 CPU Cache Line 有关,它表示 CPU Cache 一次性能加载数据的大小,可以在 Linux 里通过coherency_line_size配置查看 它的大小,通常是 64 个字节。-> int 就是说,会一次取16个,当访问array[0][0]时,由于该元素不足 64 字节,于是就会往后顺序读取array[0][0]~array[0][15]到 CPU Cache 中。顺序访问的array[i][j]因为利用了这一特点,所以就会比跳跃式访问的array[j][i]要快。
因此,遇到这种遍历数组的情况时,按照内存布局顺序访问,将可以有效的利用 CPU Cache 带来的好处,这样我们代码的性能就会得到很大的提升。
如何提升指令缓存的命中率
1 | |
- 先遍历再排序速度快,还是先排序再遍历速度快呢?
我们先了解 CPU 的分支预测器。对于 if 条件语句,意味着此时至少可以选择跳转到两段不同的指令执行,也就是 if 还是 else 中的指令。那么,如果分支预测可以预测到接下来要执行 if 里的指令,还是 else 指令的话,就可以「提前」把这些指令放在指令缓存中,这样 CPU 可以直接从 Cache 读取到指令,于是执行速度就会很快。
当数组中的元素是随机的,分支预测就无法有效工作,而当数组元素都是顺序的,分支预测器会动态地根据历史命中数据对未来进行预测,这样命中率就会很高。
因此,先排序再遍历速度会更快,这是因为排序之后,数字是从小到大的,那么前几次循环命中
if < 50的次数会比较多,于是分支预测就会缓存if里的array[i] = 0指令到 Cache 中,后续 CPU 执行该指令就只需要从 Cache 读取就好了。如果你肯定代码中的
if中的表达式判断为true的概率比较高,我们可以使用显示分支预测工具,比如在 C/C++ 语言中编译器提供了likely和unlikely这两种宏,如果if条件为ture的概率大,则可以用likely宏把if里的表达式包裹起来,反之用unlikely宏。

CPU 自身的动态分支预测已经是比较准的了,所以只有当非常确信 CPU 预测的不准,且能够知道实际的概率情况时,才建议使用这两种宏。
提升多核CPU的缓存命中率
- 在单核 CPU,虽然只能执行一个进程,但是操作系统给每个进程分配了一个时间片,时间片用完了,就调度下一个进程,于是各个进程就按时间片交替地占用 CPU,从宏观上看起来各个进程同时在执行。而现代 CPU 都是多核心的,进程可能在不同 CPU 核心来回切换执行,这对 CPU Cache 不是有利的,虽然 L3 Cache 是多核心之间共享的,但是 L1 和 L2 Cache 都是每个核心独有的,如果一个进程在不同核心来回切换,各个核心的缓存命中率就会受到影响,相反如果进程都在同一个核心上执行,那么其数据的 L1 和 L2 Cache 的缓存命中率可以得到有效提高,缓存命中率高就意味着 CPU 可以减少访问内存的频率。
- 当有多个同时执行「计算密集型」的线程,为了防止因为切换到不同的核心,而导致缓存命中率下降的问题,我们可以把线程绑定在某一个 CPU 核心上,这样性能可以得到非常可观的提升。在 Linux 上提供了
sched_setaffinity方法,来实现将线程绑定到某个 CPU 核心这一功能。
MESI协议:
数据不光是只有读操作,还有写操作,那么如果数据写入 Cache 之后,内存与 Cache 相对应的数据将会不同,这种情况下 Cache 和内存数据都不一致了,于是我们肯定是要把 Cache 中的数据同步到内存里的。什么时机才把 Cache 中的数据写回到内存呢?为了应对这个问题,下面介绍两种针对写入数据的方法:
- 写直达(Write Through)
- 写回(Write Back)
写直达
保持内存与 Cache 一致性最简单的方式是,把数据同时写入内存和 Cache 中,这种方法称为写直达
写入前会先判断数据是否已经在 CPU Cache 里面了:
- 如果数据已经在 Cache 里面,先将数据更新到 Cache 里面,再写入到内存里面;
- 如果数据没有在 Cache 里面,就直接把数据更新到内存里面。
写直达法很直观,也很简单,但是问题明显,无论数据在不在 Cache 里面,每次写操作都会写回到内存,这样写操作将会花费大量的时间,无疑性能会受到很大的影响。
写回
写直达由于每次写操作都会把数据写回到内存,而导致影响性能,于是为了要减少数据写回内存的频率,就出现了写回(Write Back)的方法。写回机制中,当发生写操作时,新的数据仅仅被写入 Cache Block 里,只有当修改过的 Cache Block「被替换」时才需要写到内存中,减少了数据写回内存的频率,这样便可以提高系统的性能。
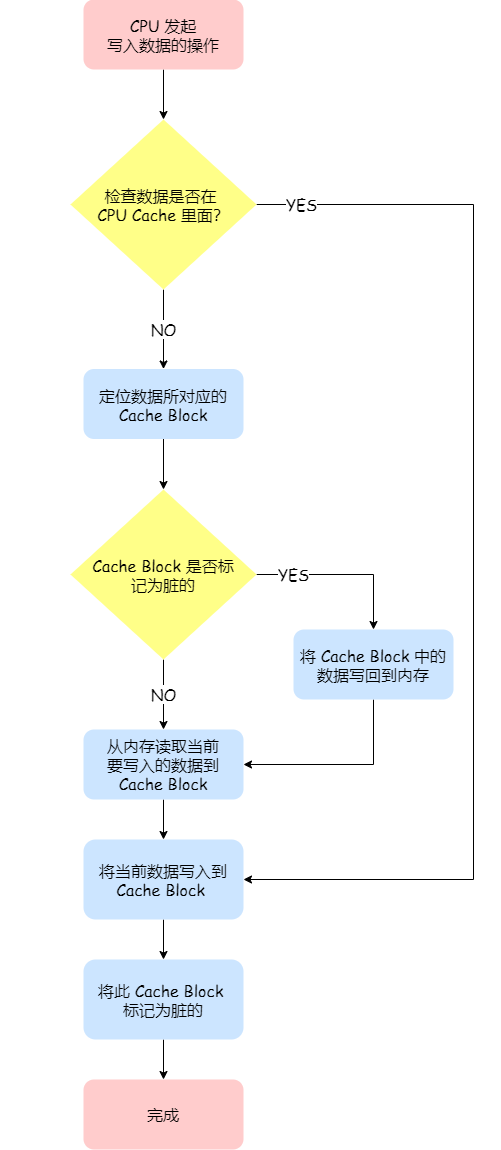
如果当发生写操作时,数据已经在 CPU Cache 里的话,则把数据更新到 CPU Cache 里,同时标记 CPU Cache 里的这个 Cache Block 为脏(Dirty)的,这个脏的标记代表这个时候,我们 CPU Cache 里面的这个 Cache Block 的数据和内存是不一致的,这种情况是不用把数据写到内存里的;
如果当发生写操作时,数据所对应的 Cache Block 里存放的是「别的内存地址的数据」的话,就要检查这个 Cache Block 里的数据有没有被标记为脏的:
- 如果是脏的话,我们就要把这个 Cache Block 里的数据写回到内存,然后再把当前要写入的数据,先从内存读入到 Cache Block 里(注意,这一步不是没用的,具体为什么要这一步,可以看这个「回答」),然后再把当前要写入的数据写入到 Cache Block,最后也把它标记为脏的;
- 如果不是脏的话,把当前要写入的数据先从内存读入到 Cache Block 里,接着将数据写入到这个 Cache Block 里,然后再把这个 Cache Block 标记为脏的就好了。
写回在把数据写入到 Cache 的时候,只有在缓存不命中,同时数据对应的 Cache 中的 Cache Block 为脏标记的情况下,才会将数据写到内存中,而在缓存命中的情况下,则在写入后 Cache 后,只需把该数据对应的 Cache Block 标记为脏即可,而不用写到内存里。 -> 这样的好处是,如果我们大量的操作都能够命中缓存,那么大部分时间里 CPU 都不需要读写内存,自然性能相比写直达会高很多。
为什么缓存没命中时,还要定位 Cache Block?这是因为此时是要判断数据即将写入到 cache block 里的位置,是否被「其他数据」占用了此位置,如果这个「其他数据」是脏数据,那么就要帮忙把它写回到内存。
- 整体流程图:
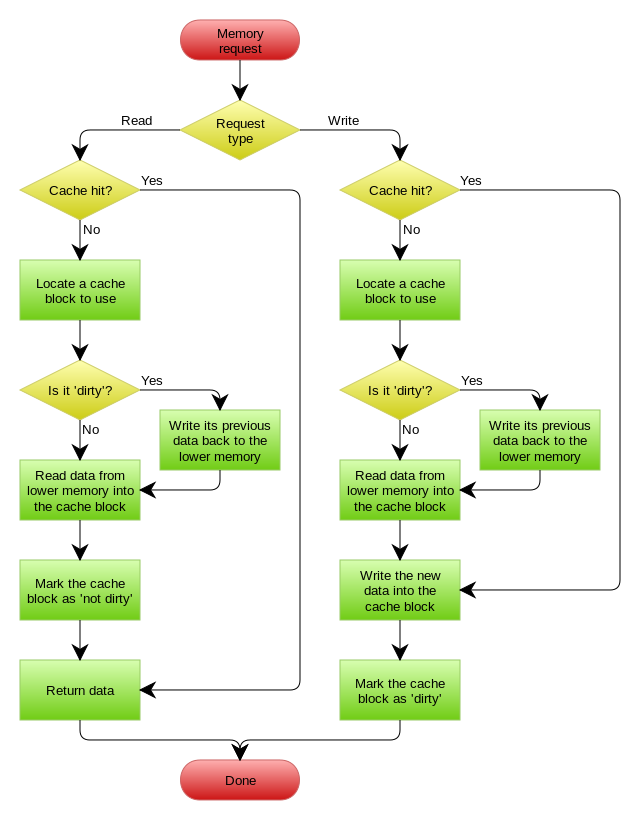
缓存一致性
CPU 都是多核的,由于 L1/L2 Cache 是多个核心各自独有的,那么会带来多核心的缓存一致性(Cache Coherence) 的问题,如果不能保证缓存一致性的问题,就可能造成结果错误。
- 类似于上面这里,我们使用写回操作(类似于惰性修改),会导致不同CPU中,某一时刻,同一个变量的数据可能不一致:
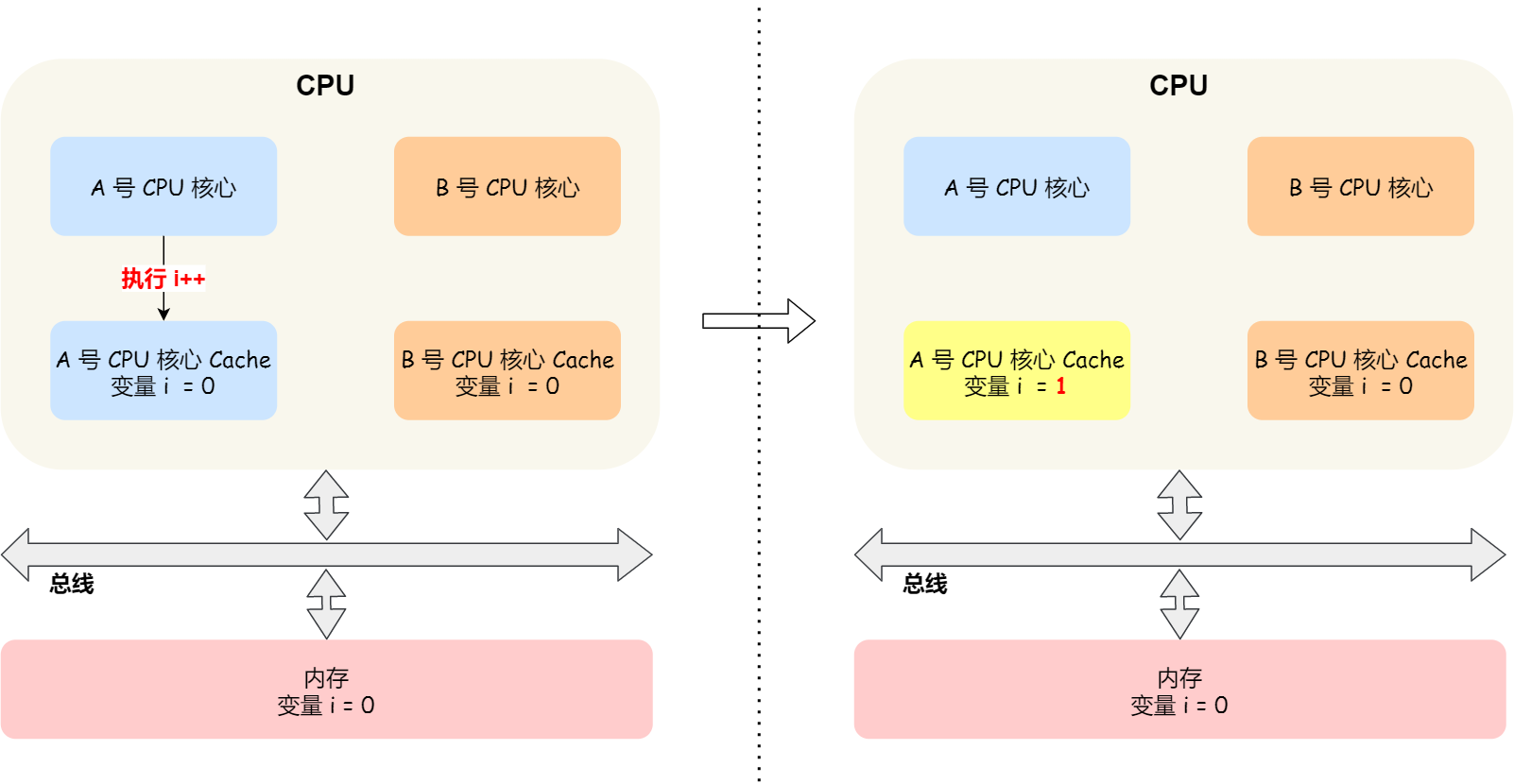
- 需要一种机制,来同步两个不同核心里面的缓存数据。要实现的这个机制的话,要保证做到下面这 2 点:
- 第一点,某个 CPU 核心里的 Cache 数据更新时,必须要传播到其他核心的 Cache,这个称为写传播(Write Propagation);
- 第二点,某个 CPU 核心里对数据的操作顺序,必须在其他核心看起来顺序是一样的,这个称为事务的串行化(Transaction Serialization)。
上面的第二点这里,举个例子:
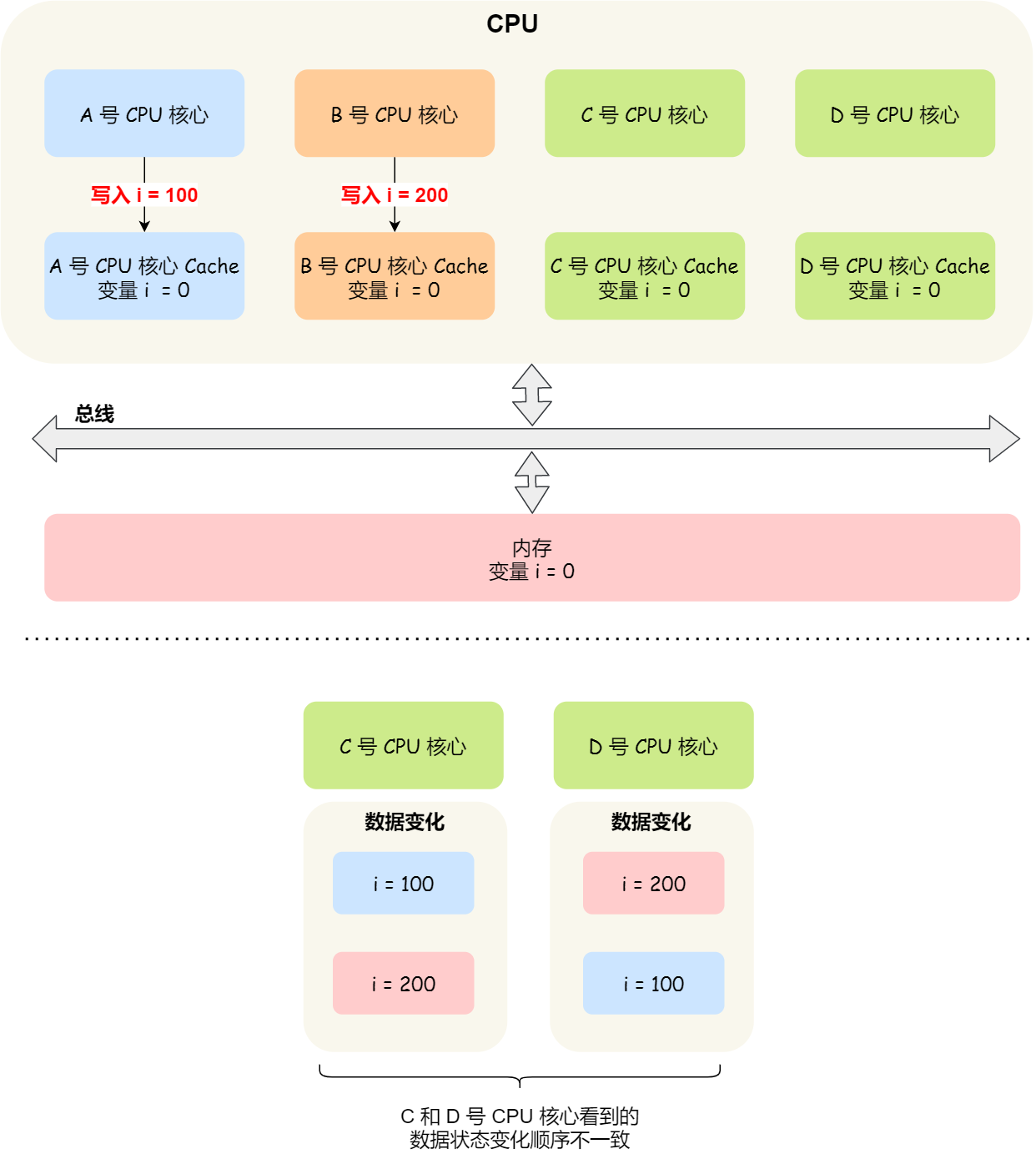
A和B可能都Propogation了,但是明显,看到的A, B操作的顺序不一致,就不符合第二条规则了。
- 事物的串行化的实现:
- CPU 核心对于 Cache 中数据的操作,需要同步给其他 CPU 核心;
- 要引入「锁」的概念,如果两个 CPU 核心里有相同数据的 Cache,那么对于这个 Cache 数据的更新,只有拿到了「锁」,才能进行对应的数据更新。
缓存一致性的保证
总线嗅探(Bus Snooping)
当 A 号 CPU 核心修改了 L1 Cache 中 i 变量的值,通过总线把这个事件广播通知给其他所有的核心,然后每个 CPU 核心都会监听总线上的广播事件,并检查是否有相同的数据在自己的 L1 Cache 里面,如果 B 号 CPU 核心的 L1 Cache 中有该数据,那么也需要把该数据更新到自己的 L1 Cache。
- 总线嗅探方法很简单, CPU 需要每时每刻监听总线上的一切活动,但是不管别的核心的 Cache 是否缓存相同的数据,都需要发出一个广播事件,这无疑会加重总线的负载。
- 总线嗅探只是保证了某个 CPU 核心的 Cache 更新数据这个事件能被其他 CPU 核心知道,但是并不能保证事务串行化。 -> MESI
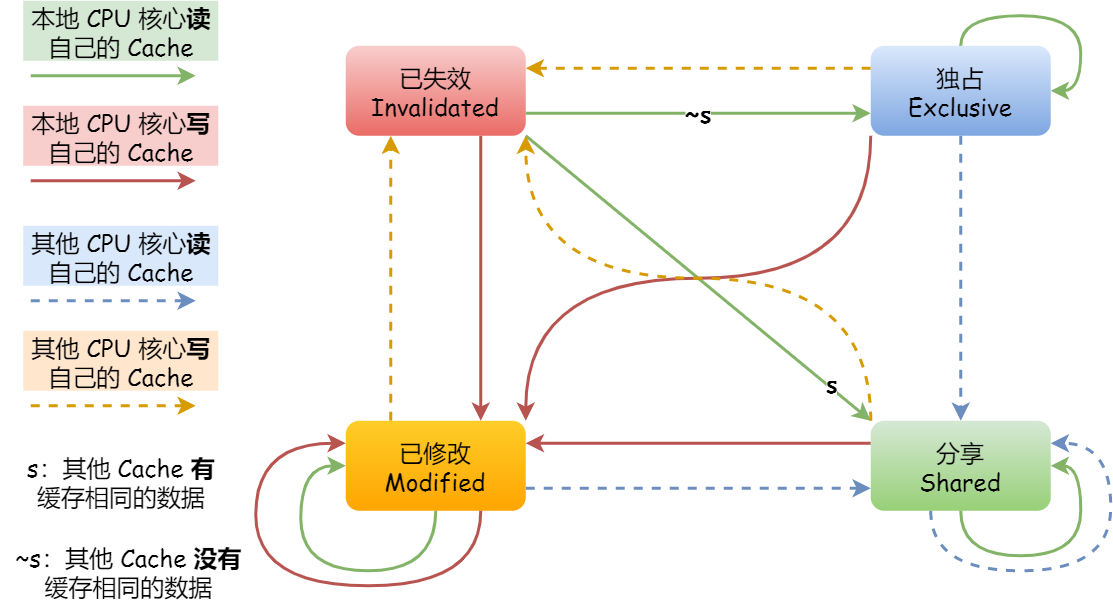
MESI协议
MESI 协议其实是 4 个状态单词的开头字母缩写,分别是:
Modified,已修改:我们前面提到的脏标记,代表该 Cache Block 上的数据已经被更新过,但是还没有写到内存里。
Exclusive,独占:Cache Block 里的数据是干净的(和内存一致),数据只存储在一个 CPU 核心的 Cache 里。写回的时候很自由,不需要通知其他 CPU 核心。如果有其他核心从内存读取了相同的数据到各自的 Cache ,那么这个时候,独占状态下的数据就会变成共享状态。
Shared,共享:Cache Block 里的数据是干净的(和内存一致),相同的数据在多个 CPU 核心的 Cache 里都有,所以当我们要更新 Cache 里面的数据的时候,不能直接修改,而是要先向所有的其他 CPU 核心广播一个请求,要求先把其他核心的 Cache 中对应的 Cache Line 标记为「无效」状态,然后再更新当前 Cache 里面的数据。
Invalidated,已失效:这个 Cache Block 里的数据已经失效了,不可以读取该状态的数据。
具体例子:
- 当 A 号 CPU 核心从内存读取变量 i 的值,数据被缓存在 A 号 CPU 核心自己的 Cache 里面,此时其他 CPU 核心的 Cache 没有缓存该数据,于是标记 Cache Line 状态为「独占」,此时其 Cache 中的数据与内存是一致的;
- 然后 B 号 CPU 核心也从内存读取了变量 i 的值,此时会发送消息给其他 CPU 核心,由于 A 号 CPU 核心已经缓存了该数据,所以会把数据返回给 B 号 CPU 核心。在这个时候, A 和 B 核心缓存了相同的数据,Cache Line 的状态就会变成「共享」,并且其 Cache 中的数据与内存也是一致的;
- 当 A 号 CPU 核心要修改 Cache 中 i 变量的值,发现数据对应的 Cache Line 的状态是共享状态,则要向所有的其他 CPU 核心广播一个请求,要求先把其他核心的 Cache 中对应的 Cache Line 标记为「无效」状态,然后 A 号 CPU 核心才更新 Cache 里面的数据,同时标记 Cache Line 为「已修改」状态,此时 Cache 中的数据就与内存不一致了。
- 如果 A 号 CPU 核心「继续」修改 Cache 中 i 变量的值,由于此时的 Cache Line 是「已修改」状态,因此不需要给其他 CPU 核心发送消息,直接更新数据即可。
- 如果 A 号 CPU 核心的 Cache 里的 i 变量对应的 Cache Line 要被「替换」,发现 Cache Line 状态是「已修改」状态,就会在替换前先把数据同步到内存。
可以发现当 Cache Line 状态是「已修改」或者「独占」状态时,修改更新其数据不需要发送广播给其他 CPU 核心,这在一定程度上减少了总线带宽压力。
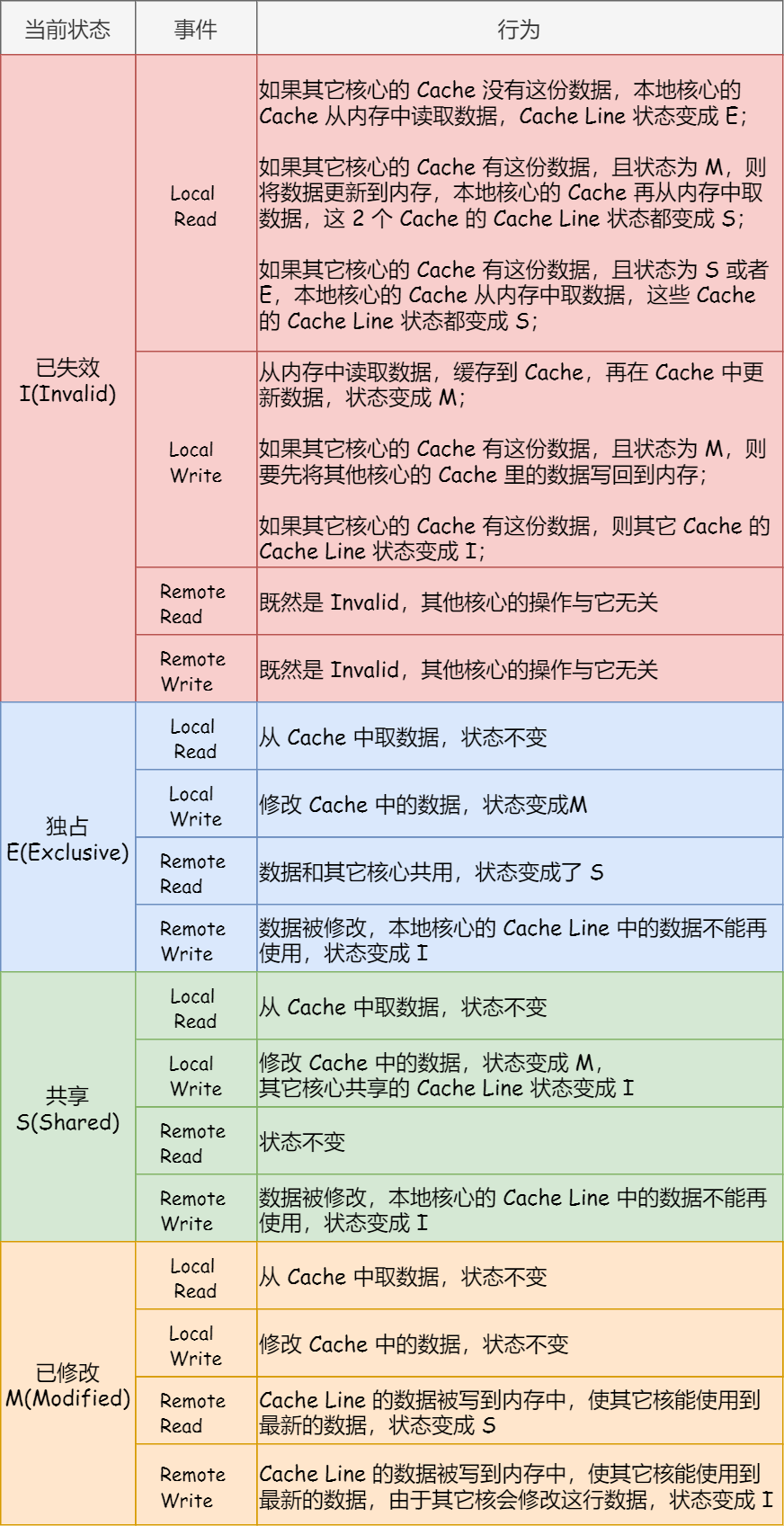
- 状态机 & 状态汇总: