NJUOS-5-并发控制:互斥
本文最后更新于:2 年前
JYY第五课,并发+互斥,保证多线程正确性昂!!!好多锁,自旋锁啊之类的,好好学学!!! -> 多处理器互斥
共享内存上的互斥
- 思考模式:
- 上一个Peterson:
- 假设先贴字条后举旗子,会不会有问题。
- 假设先看字条,再看旗子,会不会有问题。
- 上一个Peterson:


- 这个Load和Store的形容非常形象!!!相当于另外世界的生存法则???
互斥问题解决
硬件是否可以为我们提供一条“瞬间完成”的读+写的指令 -> 所看即所得(软件不够,硬件来凑!)
- 厕所门口有个锁,原子的,一次只有一个人能去拿到厕所的钥匙!!!
硬件就是yyds!!!
自旋锁

1 | |
1 | |

处理器的Lock指令会保证:
- 无论多少个线程,所有lock,也就是临界区,一定能排出一个先后顺序。
- 所有前面的Lock已经发生的事情,在当前这个Lock中,是一定能看到结果的!!!
- 原子指令的模型:
- 保证之前的store都写入内存
- 保证load/store不与原子指令乱序
计算机系统硬件实现缓存一致性
486时代
两核共享一个Memory,给内存加个锁。多核竞争,由总线判定锁给谁。 -> 实现锁的方式,就是硬件来保证的
现代处理器时代
X86:
多核共享一个Memory,同时每个核还有自己的Cache -> how to guarantee cache coherence?
- 如果同一个变量同时出现在两个CPU缓存中,怎么办?Lock如何实现呢?把缓存从另外一个CPU里面踢掉!!!
所有CPU的L1 Cache都是用一根总线连起来的!!!-> Intel x86还有很大的包袱 -> L1-Cache能和别的L1-Cache连起来,导致MESI协议其实方便实现的昂!!!不用走内存总线,再去判断某些状态啦,和内存并行的应该是,CPU之间通过MESI就保证了缓存的一致性昂!!!(我猜想就是这样设计的昂!!!)
- 硬件上的锁就是用总线来保证的昂!!!
RISC-V:
- 另外一种原子设计:

本质就是三步:load -> exec -> store
- Load-Reserved/Store-Conditional(LR/SC)

类似于CAS!!!这个像是乐观锁了!!!就是自旋锁昂!!!

Store-conditional是有失败的可能性的昂!!!
我看到了等于我的版本号,我才能存进去,中间这个版本好是不能变动的。不能做“瞎子”,因此这里,Compare-And-Swap应该是原子操作昂!!!
使用场景
- 临界区几乎不“拥堵”(队列?大伙儿不要都抢,抢的少或者排队嘛!!!排队上厕所…)
- 持有自旋锁时禁止执行流切换(可别在厕所里面睡着了)
使用场景:操作系统内核的并发数据结构(短临界区)
- 操作系统可以关闭中断和抢占
- 保证锁的持有者在很短的时间内可以释放锁
- (如果是虚拟机呢…😂)
- PAUSE 指令会触发 VM Exit
- 但依旧很难做好
互斥锁
实现线程 + 长临界区的互斥,如果想要实现长临界区的互斥,加一个系统调用就行。既然没有拿到锁,那我就执行别的呗,C语言能够把CPU让给别人,这个“让”的动作,也是通过操作系统的API来实现的昂! -> 互斥锁(Mutex)

- 自旋锁缺陷:
自旋(就是一个原子指令)-> 锁不拥堵的时候,性能比较好,但是如果争抢的话
- (比如两个线程)。只有一个CPU能够正常执行,又一个CPU就一直在自旋(空转),那如果有128个线程呢…一人做事,其他围观。一个人待在厕所里,剩下的127个人不断在敲门……浪费了很多的CPU cycles
- 如果只有一个CPU,分时系统导致CPU可以同时运行多个线程。-> 有钥匙的线程在厕所里睡觉…别的线程还在那儿敲门呢…
- 对不对是一码事 -> 性能好不好是另外一码事
1 | |
1 | |
同样多的工作量,线程越多,效率越低:
- 自旋回触发缓存同步,延迟增加。
- 除了临界区的线程,其他都在空转。争抢锁的处理器增多,利用率降低。
- 获得自旋锁的线程可能被OS换出去,因为操作系统不“感知”线程在做什么(但是是可以感知的!!! -> 例如OS去检查锁的情况)。实现了100%的资源浪费。
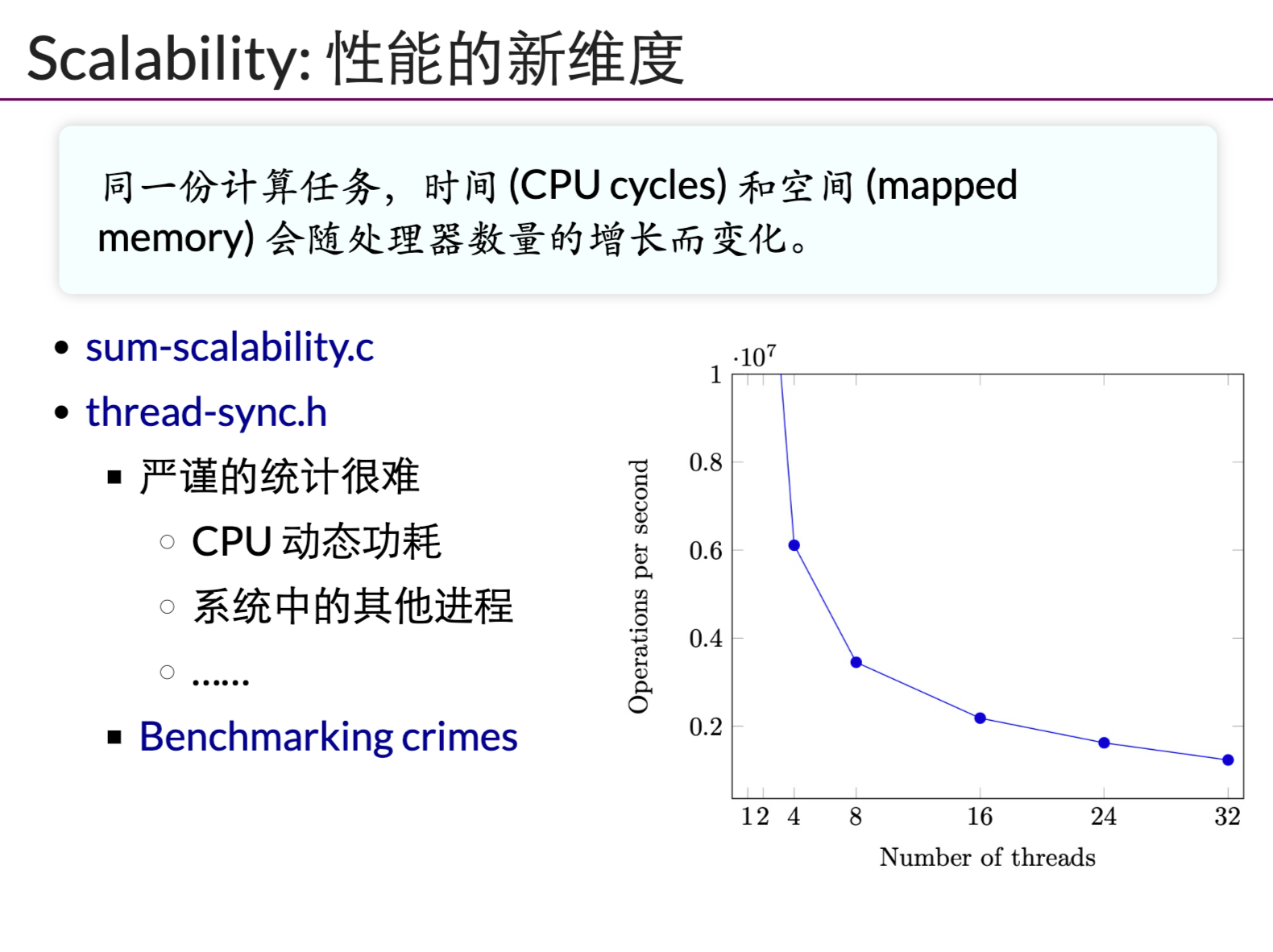
为啥有的时候,第一次试验结果好,后面越来越差。。。 -> 第一次试验的时候,CPU很猛,性能好,后面越来越热,CPU很烫,自然功率就下来了昂!
- Benchmarking很重要!!!
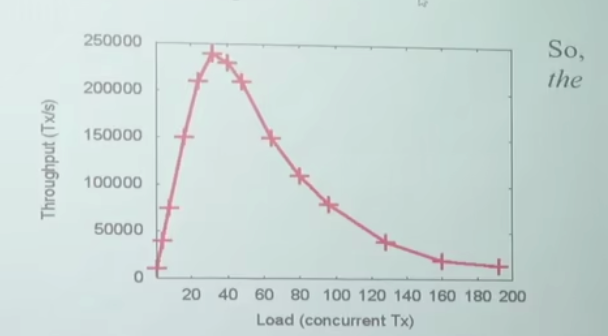
像上面这种情况,在多处理器中就经常发生昂!!!
Futex
Futex = Spin + Mutex


思想转换:worst case -> average case(二八定律)
通过运行时观察,我们发现。Futex(Fast Userspace muTexes)。
- 线程库里面的锁,在绝大多数情况下,都不会触发系统调用,原子指令可以直接解决。
- 少部分争抢的情况下,才会触发系统调用。
简答的实现:

成功直接进临界区,不成功直接进内核。 -> Spin就是用户态解决,Mutex就是内核态解决。
References
原子指令手册:https://en.cppreference.com/w/cpp/header/stdatomic.h -> 这里有好多原子指令!!!
Benchmarking-crimes: https://gernot-heiser.org/benchmarking-crimes.html
自旋锁的使用有多大:An analysis of Linux scalability to many cores (OSDI’10)
Futexes are tricky: http://jyywiki.cn/pages/OS/manuals/futexes-are-tricky.pdf