UESTC数据库系统期末复习
本文最后更新于:2 年前
数据库考前磨枪嗷!!!
第一章:数据库系统
数据库系统及其概念
- 组织和存储数据的系统容器被称为数据库。
- 数据库具有以下特点:
- 数据一般不重复存储。(减少冗余度)
- 可以支持多个应用程序并发访问。(实现数据共享)
- 数据结构独立于使用它的应用程序。(与应用程序分离)
- 数据的增删改查都有数据库系统软件进行管理和控制。(数据库起到统一的控制作用)
- 数据库其中一个定义:
- 使用某种存储模型组织起来并且放在存储器中的数据集合。
数据模型:
对象数据特征及其结构的形式化体现:
- 数据结构
- 数据操作
- 数据约束
数据结构:
- 事务对象的静态特征
数据操作:
- 事务对象的动态特征
数据约束:
- 描述事务对象之间语义的联系,取值范围等。
- 目的:
- 确保数据的完整性,一致性,有效性。
数据库使用的数据模型:
- 层次数据模型
- 网状数据模型
- 关系数据模型
层次数据模型:
- 数据结构层次清晰,更新和拓展容器。
- 局限于层次结构,缺乏灵活性,数据冗余大。拓扑空间数据不适用。
网状数据模型:
- 扩展了层次数据模型,数据处理更加方便,可以表示复杂关系,冗余小
- 结构复杂,数据查询定位困难,数据存储存储量大,更新不方便嗷!
关系数据模型:
- 特点:
- 关系代数的理论。
- 通过二维表来表示数据记录之间联系的数据模型。
- 优点:
- 结构简单,操作灵活。
- 支持关系与集合的运算操作
- 支持广泛使用的sql语句
- 容易实现与应用程序的数据独立性
- 缺点:
- 局限于结构化数据
- 支持数据类型较简单
- 不能支持非结构化的数据
- 特点:
数据库系统:
- 组成部分:
- 用户(实体)
- 应用程序(用户用的玩意儿)
- 数据库管理系统(DBMS)
- 数据库(DB)
- 用户:
- 分类:
- 最终用户
- DBA
- 最终用户:
- 通过操作数据库应用程序处理业务,利用程序存取数据库信息。
- 还是哟啊通过DBMS
- DBA:
- 还是通过DBMS,数据库是摸不到的嗷!!!
- 分类:
- 数据库应用程序:
- 在DBMS支持下对于数据库访问和处理的应用程序。
- 使用DBMS , OBMS提供的标准接口,连接操作数据库。
- 数据库管理系统:
- 功能:
- create db
- select , insert , update , delete
- 维护数据库结构
- 执行数据库数据访问规则
- 提供数据库并发访问控制和安全控制
- 执行数据库备份与恢复
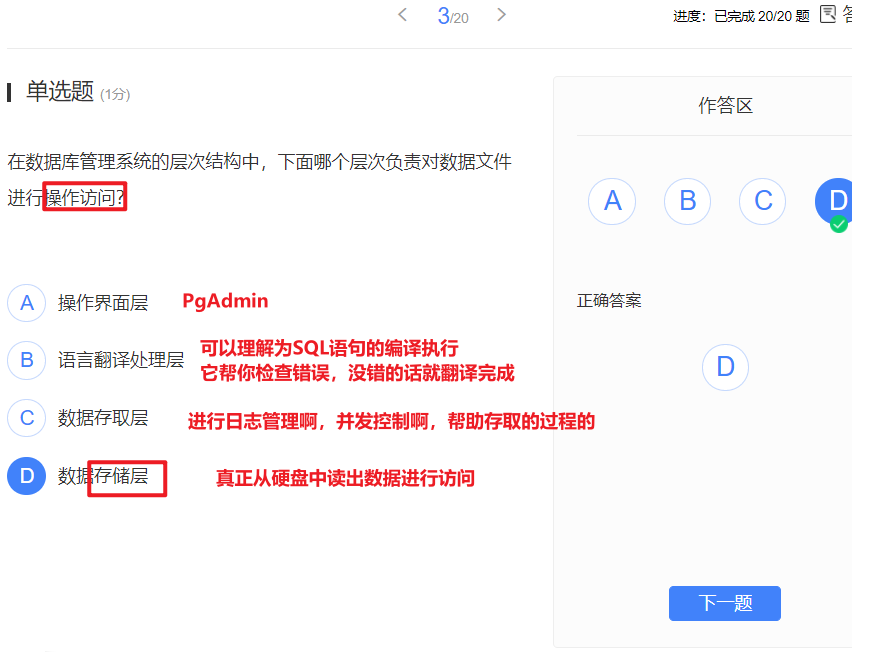
- 层次结构:
- 操作界面层
- 语言翻译处理层
- 数据存取层
- 数据存储层
- 操作界面层:由管理工具和
api组成,为应用程序和用户提供接口界面 - 语言翻译层:对于数据库操作语句 -> 语法分析,视图转换,授权检查,完整性检查,查询优化等处理。(针对语句)
- 数据存取层:将上层集合关系操作转换为数据记录操作,对于数据进行存取,事务管理,日志记录,并发控制等。(针对数据库操作)
- 数据存储层:实实在在对于数据进行读写,数据页,内外存交换等。
- 功能:
- 数据库:
- 真正存放数据的容器,按照一定的数据模型组织和存储数据。
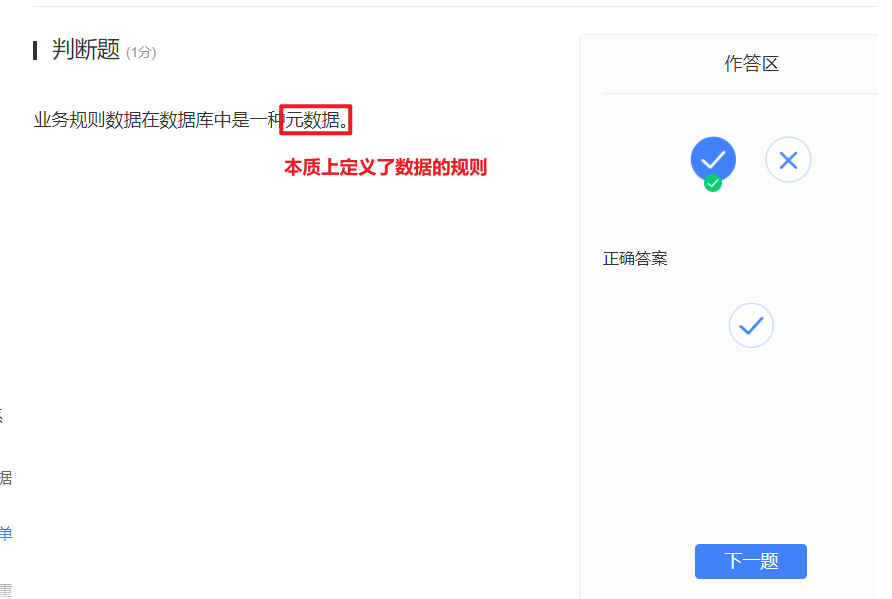
- 数据库中除了要存放用户数据外,还要存放描述数据库结构的元数据。
- 关系数据库中存储:
- 用户数据
- 元数据
- 索引数据
- 其他数据
数据库管理技术的演化
数据库管理技术的演化:
- 不同阶段:
- 人工数据管理阶段(不能数据共享)
- 文件系统管理阶段(不怎么能共享)
- 数据库管理阶段(真正实现共享):
- 程序与数据隔离
- 使用标准语言操作
- 数据组织结构化,共享性高,冗余小
- 提供了数据的安全访问,保证了完整性,一致性,正确性。
数据库技术的发展阶段:
- 第一代数据库技术:层次和网状
- 第二代数据库技术:关系型数据库系统(MySQL)
- 第三代数据库技术:面向对象的数据库应用,(对象-关系型数据库产品PostgreSQL)
- 第四代数据库技术:非结构化数据技术,分布式技术。
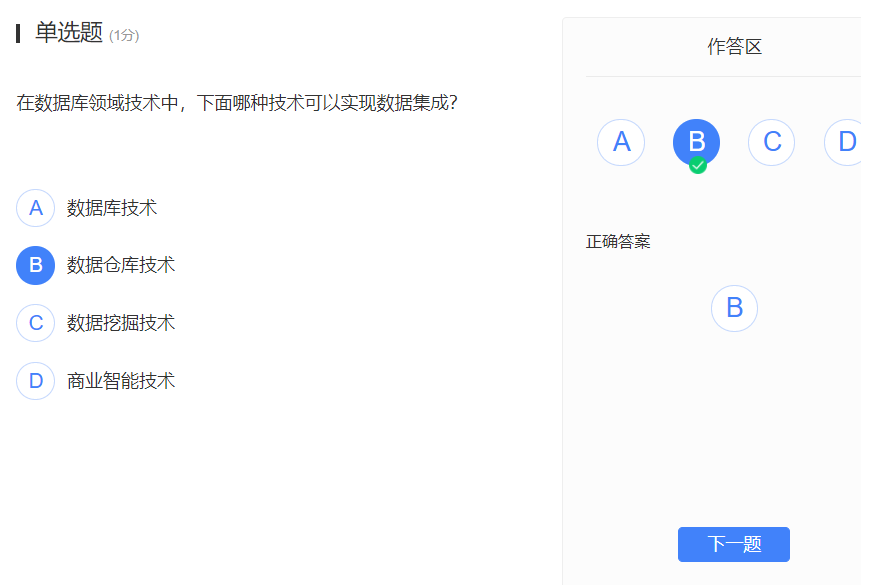
数据库领域新技术:
- NoSQL数据库
- NewSQL数据库
- 领域数据库
- 数据仓库与数据挖掘
- 商业智能
- 大数据分析处理技术
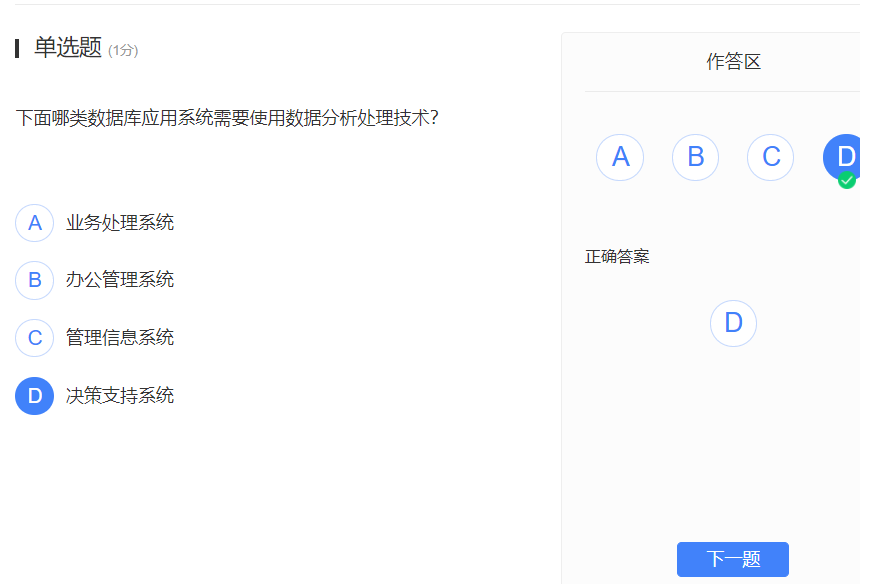
数据库应用系统
- 类型:
- 业务处理系统:对于机构日常业务活动的统计和操作。
- 管理信息系统:达到规范管理和提高机构工作效率。
- 决策支持系统:帮助管理者进行明确决策目标和进行问题的识别。
- 结构:
- 单用户结构:
- 数据库对象为单个用户,应用系统软件和数据库都安装在一个计算机中运行。
- 简单易用易维护,但是只适用于单用户,不能实现用户间数据共享。
- 集中式结构:
- 所有对于DB的操作都由服务器来完成,客户机啥也不干,所有操作集中到服务器中。
- 服务器响应客户机的请求访问会成为瓶颈,系统性能降低
- C/S架构:
- 和上面差不多,不过这个时候C端有客户端,可以帮忙干点活,其他没啥区别
- 客户机多的时候网络和服务器都有可能成为瓶颈
- 分布式架构:
- 大规模跨地区的机构信息系统中,都用的是这个。
- 优缺点:
- 适应跨地区的大型机构及企业等组织对于数据库应用的要求。
- 处理性能强,但是数据库的分布处理和维护有一定的开销和技术难度。
- 单用户结构:
数据库应用系统的生命周期:
- 系统需求分析:
- 需求信息收集
- 需求信息分析
- 需求规格说明
- 系统设计:
- CDM , LDM , PDM
- 我们平常做作业就是根据上面的来先进行系统设计
- CDM -> LDM -> PDM
- 系统实现:
- 软件程序编写
- DBMS安装部署
- 数据库创建和数据对象实现
- 系统测试:
- 根据系统规格要求来设计测试用例,使用测试用例对于系统进行功能测试,性能测试,集成测试等。
- 系统运行和维护:
- 维护数据库系统的安全性和完整性
- 监控和优化数据库系统运行性能
- 拓展数据库系统处理能力
典型数据库管理系统
- SQL Server:
- 适合大型机构的数据库管理和数据分析,之前的版本适合用于中小规模机构使用。
- 适用于任何独特的商业环境中嗷!!!
- Oracle DataBase:
- 企业级关系数据库管理系统
- 功能最强大的企业级数据库产品
- MySQL
- 开源关系型数据库
- 支持多用户,多线程的数据库关系系统
- 体积小,速度快,适应性强,免费使用
- PostgreSQL
- 对象-关系数据库管理系统
- 支持面向对象数据管理
第一章学堂在线习题:
- 回去看书上P10-11,这一页没有细心好好看哦!!!
- 回去看书上P12,这一页没有细心好好看哦!!!
- 书上P21 , 阿sir , 这都能考???
- 书上P23 , 阿sir , 这都能考???
第一章补充学习
各种新技术的应用:
- NoSQL:针对大量互联网应用的非结构化数据 -> 分布式非关系数据库技术
- NewSQL:NoSQL + SQL
- 领域数据库:更多领域将会出现数据库技术
- 数据仓库:对于历史数据进行有效存储和整合集成,以便实现决策分析所需要的联机分析和数据挖掘处理
- 特征:
- 面向主题
- 集成性
- 稳定性
- 时变性
- 数据抽取,数据清理,系统加工,汇总,整理得到的主题将被存放到特定的数据库中以备联机分析所使用。
- 特征:
- 数据挖掘:数据仓库 + 模式识别/规律挖掘,发现有价值的信息。
- 基础:
- 人工智能
- 机器学习
- 模式识别
- 统计学
- 数据库
- 可视化技术
- 作用:
- 帮助决策者进行策略分析,防范或者减少风险,做出正确决策。
- 步骤:
- 数据预处理
- 规律寻找
- 结果可视化
- 基础:
- 商业智能:
- 数据仓库+联机分析+数据挖掘
- 数据分析以实现商业价值的技术
- 为决策者的决策过程提供辅助支持
- 大数据分析处理技术:
- 解决传统数据分析技术难以在规定时间完成大规模复杂数据分析的技术。
- 快速提取有价值的信息
数据库系统应用:
- 决策支持系统需要用到数据分析,预测信息,决策方案的信息
PostgreSQL的特性:
服务端程序提供数据库的访问(DBMS的功能),并且可以服务多种不同的客户端,以及创建服务进程服务每一个客户端连接请求。
客户端程序:
- clusterdb 建立一个PostgreSQL集群
- createdb
- createlang 安装一个过程语言
- createuser
- dropdb
- droplang
- dropuser
- ecpg 嵌入的SQL C预处理器
- pg_basevackup 做一个集群的基础备份
- pg_config 检索版本细腻
- pg_dump 导出数据库到脚本程序中
- pg_dumpall 导出集群到脚本程序中
- pg_isready 是否连接好了
- pg_receivexlog 流事务日志
- pg_restore 从pg_dump的备份文件中恢复PostgreSQL
- psql 交互终端
- reindexdb 重建数据库索引
- vacuumdb 收集垃圾分析数据库
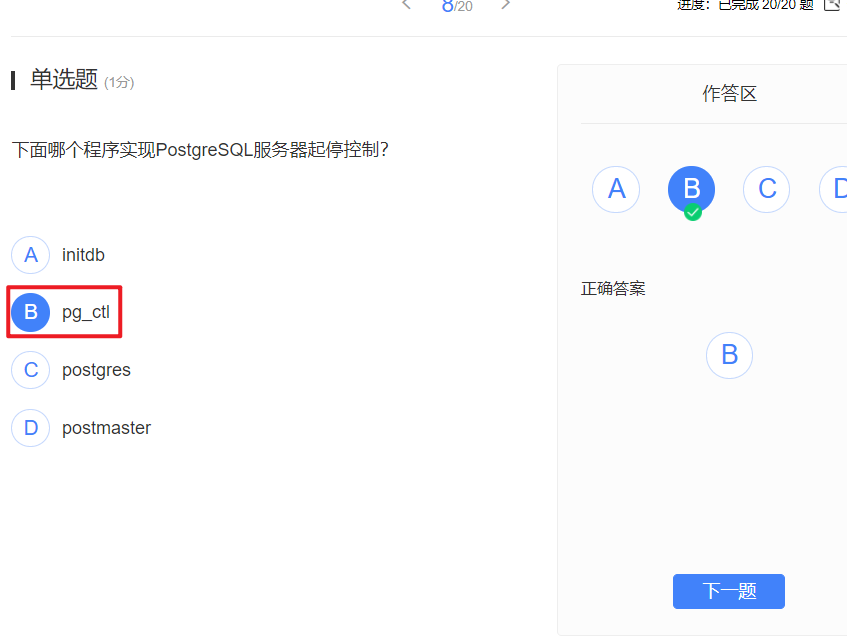
服务端程序:
- initdb 创建新的Cluster
- pg_controldata 显示集群的控制信息
- pg_ctl 初始化,启动,停止控制PostgreSQL服务器
- pg_resetxlog 重置一个数据库集群的预写日志及其他控制内容
- postgres:数据库服务器服务进程
- postmaster:数据库服务器守护进程
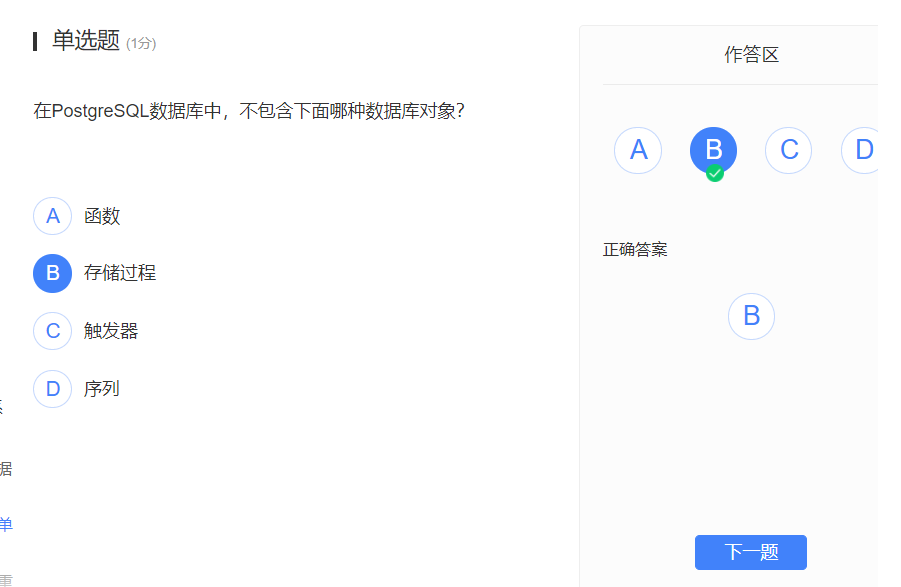
PostgreSQL数据库对象
- 类型:
- schema
- 表
- 视图
- 序列
- 函数
- 触发器
- schema:
- 数据库下级的逻辑对象(数据库是房子,schema是房间)
- 用于用户分类组织其他对象(更下层的,如表啊之类的)
- 系统会自动创建一个名为public的schema对象
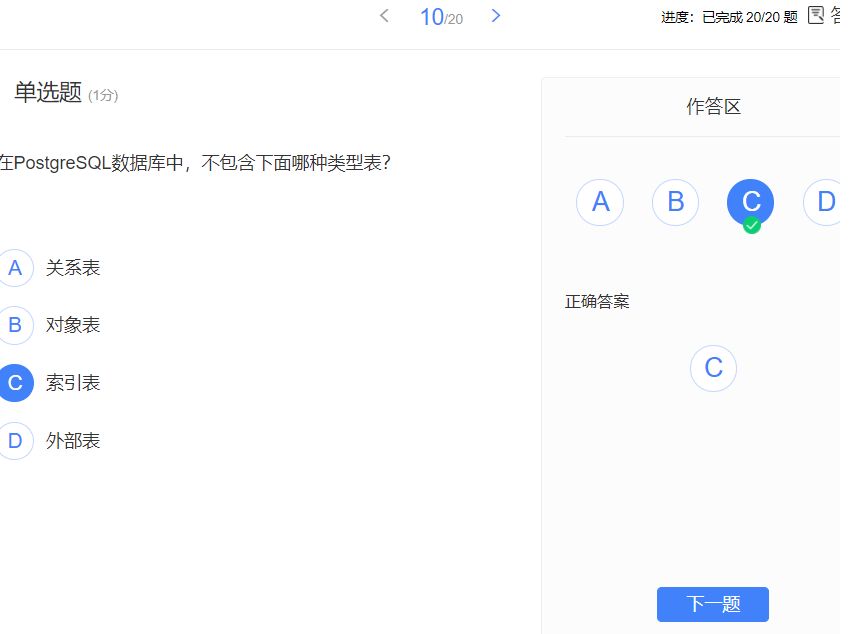
- 表:
- 用户组织存储数据的数据库对象
- db > schema > table
- 表的类型:
- 关系表
- 继承表
- 外部表
- 视图:
- 基于虚拟表的操作数据的数据库对象
- 用于简化查询逻辑,更新基本表中的数据
- 序列:
- 为代理键列提供自动增量序列值的数据库对象
- 可以多表共享
- 可以自定义初始值,增量值,序列范围等
- 函数:
- 内置编程语言编写数据库访问操作功能程序的数据库对象
- PostgreSQL没有单独的存储过程对象,而是通过函数来实现存储过程。
- 触发器:
- 支持多种类型:
- 语句级
- 行级
- 触发时机:
- 修改前
- 修改后
- 支持多种类型:
第二章:数据关系模型
关系以及其相关概念
- 实体:表示系统内在的数据对象
- 实体联系:数据对象的关系
- 关系模型是采用关系二维表的数据结构形式存储实体以及实体间联系的数据模型
- 关系 -> 具有关系特征的二维表(本质上就是由行和列组成的,用于组织存储实体数据的二维表)
- 特点 :
- 每行一个实例数据
- 每列一个属性
- 每格单个值
- 行和列不能够重复
- 行和列可以无序
- 术语:
- 关系表 = 关系
- 元组 = 二维表的一行
- 属性 = 二维表的一列
- 域 = 属性列的取值范围
- 基数 = 值域的取值个数
- 实体 = 包含数据特征的事务抽象
- 数学定义:
- 域:
- 一组具有相同数据类型的值和集合,用于表示实体属性的取值范围。(列的取值范围)
- 例如学号 , 姓名等,可以表示为一个集合。
- 基数:
- 集合中元素的个数。
- 笛卡尔积:
- 所有属性的值域的全排列,值构成一个大的集合
- 所以笛卡尔积的基数等于每一个分量基数的乘积!!!
- 关系:(实际的表)
- 笛卡尔元组集合中有特定意义的子集合。
R(D1 x D2 ... x Dn),n表示属性的个数,成为元数或者度数。- 例如学生表中有(学号,姓名,性别)三个属性,那么度数为3,称为3元关系
- 关系类型:
- 基本关系 = 基本表(存储关系的二维表)
- 视图关系 = 基本表或者其他视图基础上定义的关系(虚拟表,并不实际存储数据)
- 关系特性:
- 有限元组
- 给不同列不同列名,满足关系交换律,消除元组有序性
- 特性如下:
- 单元格必须是原子值
- 每个列定义同一个数据类型或者同一域
- 任意两个元组不能够完全相同(冗余数据打咩)
- 不同属性列定义不同列名
- 行和列的顺序可以任意交换
- 关系模式:
- STUDENT(StudentNum , StudentName , Sex)
- 关系键的定义:
- key:唯一标识不同元组的属性或属性组。
- 复合键:
- 两个或多个属性的组合以标识不同的元组
- 候选键:
- 每个键都称为候选键
- 主键:
- 最合适的键作为主键
- 主键作用:
- 标识关系表的不同行(元组)
- 多表关联,主键可以作为表之间的关联属性
- DBMS产品使用主键列索引来组织表的数据块存储
- 主键列的索引值可以快速检索关系表中的行数据
- 域:
关系模型的原理
- 组成:
- 数据结构:
- 具有关系特征的二维表数据结构
- 若干关系表组成,表之间存在一定的联系
- 操作方式:
- 选择
- 投影
- 连接
- 除
- 并
- 交
- 差
- CRUD
- 数据约束:
- 实体完整性约束
- 参照完整性约束
- 用户自定义完整性约束(结合具体的应用场景和应用规则!!!)
- 数据结构:
关系模型的操作:
传统的集合运算:
前提条件,两个关系都有n个属性并且属性列相同。
并运算:
- 操作:元组合并并消除重复元组。
差运算:
- 属于R并且不属于S的元组组成。
交运算:
- 既属于R,又属于S的元组组成。
广义笛卡尔积:
- R有n个属性,S有m个属性,R和S的广义笛卡尔积为一个(n+m)列的元组集合。
- 说白了就是列拼在一起,里面的元组就是R中所有元组和S中所有元组的全排列。
专门的关系运算:
传统仅仅考虑了对于行的处理,列的处理没了orz
一些定义:
- 元组中的列定义为它的一个分量
- 部分列(少了一些列后剩余分量的集合)
- …
选择运算:
- 挑出符合条件的行
投影运算:
- 挑出符合条件的列
连接运算:
- theta 连接:
- theta本质上表示比较运算符,因此其作用于可以比较的属性组。
- 表的连接,要给一些条件,比如某些属性值之间的大小关系
- 当theta为 = 的时候,又称为等值连接运算。
- 从行的角度运算
- 自然连接:
- 特殊的等值连接,比较的分量必须是相同的属性组,并且在结果中要把重复的列去掉。
- 从行和列的角度进行运算
- 外连接:
- 内连接的拓展,可以在内连接的结果集上,拓展关系中未匹配的属性值
- 分类:
- 左
- 右
- 全
- 左外连接:
- 左边全部保留,右边找不到的就为Null
- 右外连接:
- 右边全部保留,左边找不到的就为Null
- 全外连接:
- 左右不匹配的都用null填上,然后构造最后的表
- 可以看为,先内连接,再把左表(或右表)中不匹配的行通过null加入查询结果中嗷!!!
- 除运算:
- ????
- theta 连接:
数据完整性约束
实体完整性:
- 主键取值约束,保证每个元组可标识
- 规则:
- 每个主键属性列不允许为Null
- 取值应该唯一
- 检查:
- 主键值是否唯一
- 主键的各个属性是否为空,一个都不能为空!!!
参照完整性:
- 外键取值约束,重点在于关系之间的联系的约束
- 外键的取值必须在关联主键的取值范围内嗷!!!
- 外键斜体(关系模式中)来表示。
- 可能引发参照完整性问题的:
- 修改主表主键,子表不管了orz
- 删除主表元素,子表不管了orz
- 子表插入新元素,主表没有???
- 修改子表外键值,主表没有???
自定义完整性:
- 例如表格中分数这一栏只能为0~100
- 保证满足业务要求或者约束条件。
- 提供如下完整性功能:
- 域的数据类型与取值范围
- 属性的数据类型和取值范围
- 默认值
- 是否允许为空
- 取值的唯一性
- 数据依赖性
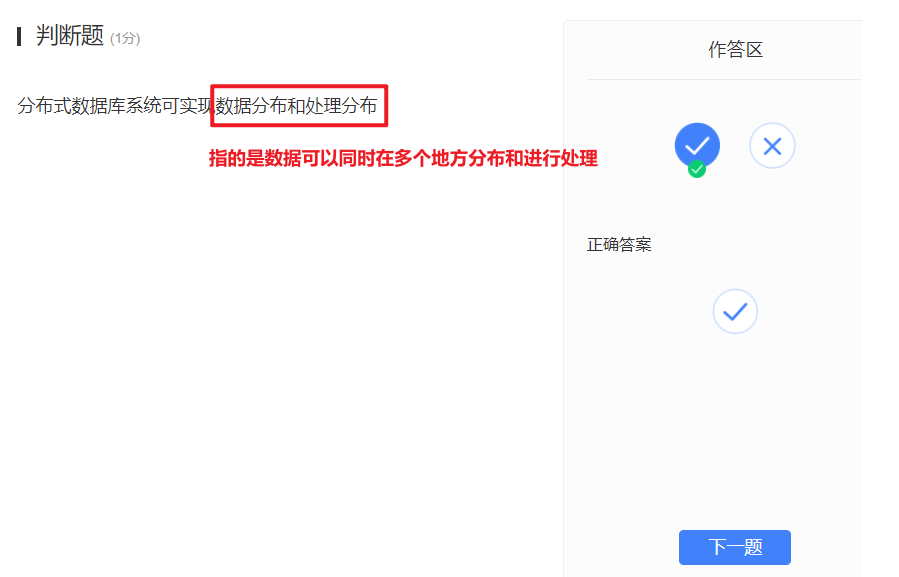
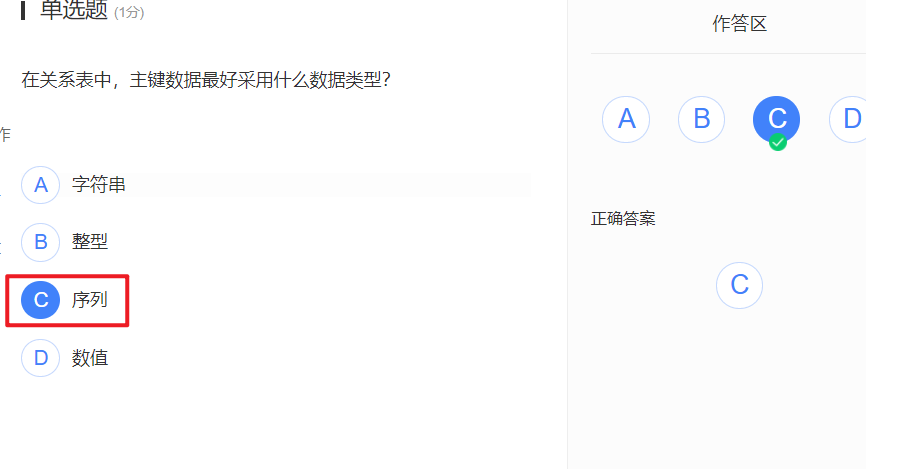
第二章学堂在线习题:
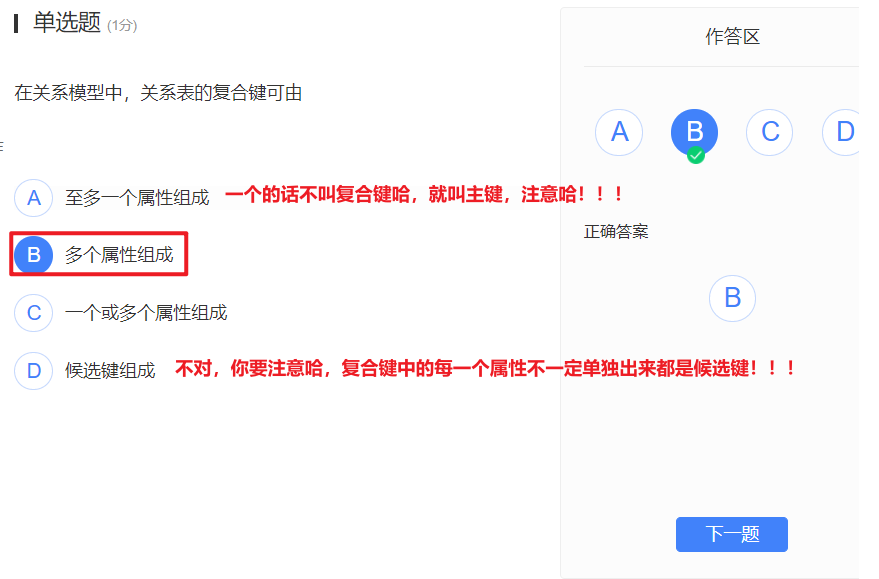
 ‘
‘
- 自增快乐,直接serial,DBMS都帮你处理好,自己插入主键处理还要考虑这考虑那,这样处理不香咩???
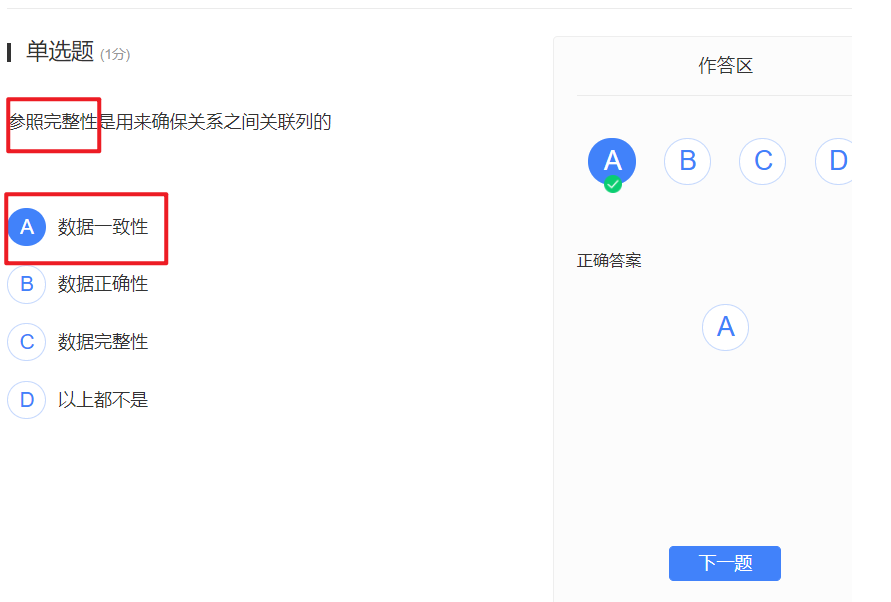
- 关系是满足一定限制条件的更为严苛的二维表
第二章补充学习
数据完整性约束
- 目的是为了确保关系数据的正确性和一致性。
- 参照完整性约束就是为了保证关系之间属性列的数据一致性。
- 专门的关系运算:选择,投影,连接
- 传统的集合运算:并,差,交,笛卡尔积
第三章:数据库操作语言SQL
SQL概述:
- SQL的特点:
- 一体化:
- SQL可以完成所有操作,数据定义,数据操作,数据查询,数据库控制,数据库管理等
- 使用方式灵活:
- 可以直接交互方式操作数据库,也可以嵌入到程序中操作数据库
- 非过程化:
- SQL直接将命令交给DBMS执行
- 语法简单容易:
- SQL的操作语句不多,语法语义简单,操作方便
- 一体化:
- SQL的类型:
- DDL(数据定义语言):创建和维护数据库对象,类似于表,视图,索引,触发器,存储过程等。
- DML(数据操作语言):CRUD,中的插入,删除,更新,对于表中数据来说的。
- DQL(数据查询语言):专门的select语句,因为select最复杂嘛orz。
- DCL(数据控制语言):GRANT , REVOKE , DENY。DBA对于DB的存储权限的管理。
- TPL(事务处理语言):用于数据库的事务的编程处理
- CCL(游标控制语言):用于数据库游标结构的使用。
- SQL数据类型:
- varchar , char , text
- int , smallint , bigint
- **numeric(p,s)**:定点数,p为定点数总位数,s为定点数小数位数
- real(单精度浮点数), double(n,d)双精度浮点数
- money,专门的货币数据表示
- bit(逻辑型),只能为0或者1
- date , datetime,日期型
DDL:
DB创建,修改,删除:
- CREATE DATABASE <DBName> :
- some options:
- ENCODING
- OWNER
- CONNECTION LIMIT (并发连接数)
- some options:
- ALTER DATABASE <DBName> [ [ WITH ] option […] ]:
- ALTER DATABASE demoDB RENAME TO MyDemoDB
- DROP DATABASE <DBName>
数据库表对象的定义:
CREATE TABLE <TableName>( Column1 数据类型 完整性约束, Column2 数据类型 完整性约束, Column3 数据类型,完整性约束 );注意哈,上面最后一行没有逗号
列约束关键词:
- PRIMARY KEY
- NOT NULL
- UNIQUE
- CHECK
- DEFAULT
CHECK(CourseType IN('基础课','专业','选修'))可以添加表级约束,定义后面加上
CONSTRAINT 表级约束名 表级约束:constraint couser_pk Primary Key(CouserID,TeacherID)constraint couser_fk Foreign Key(CourseID) references Course(CourseID) on delete cascade- 推荐使用这种形式,清晰明了与定义分开来了哦!!!
修改表的结构:
Alter tabel <TN> add <newColumn> <dataType> <Constraint>alter table <TN> drop column <columnName>alter table <TN> rename to <TN2>alter table <TN> alter column <columnName> type<newDataType>alter table <TN> rename <columnName> to <newColumnName>
DROP table <tableName>
数据库索引对象的定义:
create index <indexName> on <TN><CN>create unique index <indexName> on <TN><CN>alter index <indexName> rename to <newIndexName>drop index <indexName>
DML:
- insert:
- insert into Student Values(), 这里Values里面根据列的顺序逐个赋值就好。
- insert into Student(Column01, …) values(…) 这里的Values根据Student后面的顺序来赋值嗷。
- 多行插入写多个并列的加上;就好嗷!!!
- update:
- update Student set name=’tuzi’ where studentID = 001
- update Student set name=’tuzi’ , email=‘tuzi@163.com‘ where studentID = 001
- 多值更新就在后面加上就好嗷!!!
- delete:
- delete from student where studentName=’tuzi’
DQL:
- 子句:
- SELECT
- INTO
- WHERE
- FROM
- GROUP BY
- ORDER BY:
- desc : 降序
- asc:升序
- 通配符:
- _表示一个未指定的字符
- %表示一个或多个未指定字符
- 例子:
- select * from student;
- select StudentID , StudentName from student where StudentAge > 19;
- select DISTINCT Major from student,注意,这个可以从 结果集中去掉相同的元素嗷!!!
- select * from student where birthday between ‘2021-01-01’ and ‘2021-12-30’
- between ‘2021-01-01’ and ‘2021-12-30’ 等价于 birthday >= ‘2021-01-01’ and birthday <= ‘2021-12-30’
- Major like ‘计算机%’ , Name not like ‘林_’
- order by major ASC , birthday DESC;
- select coursename , round(grade , 0) as grade from grade
- 内置函数:
- avg
- count
- min
- max
- sum
- 这些内置函数要么直接使用,要么和分组函数一起使用。
- 算数函数:
- SIN()等
- ABS()取绝对值
- EXP()
- LOG()
- SQRT()
- FLOOR()
- CEILING()
- ROUND()
- 字符串函数:
- CHR()
- LOWER / UPPER()
- LENGTH()
- LTRIM()
- RTRIM()
- OVERLAY()
- REVERSE()
- REPLACE()
- 日期函数:
- CURRENT_DATE
- CURRENT_TIME
- AGE(timestamp , timestamp)
- 数据类型转换函数:
- TO_CHAR
- TO_DATE()
- …
- 分组处理:
- GROUP BY Major
- select major from student group by major having count(*) > 3
- having是分组统计的条件
- 子表查询
- JOIN…ON…查询多表嗷!!!
- 多表连接查询:
- from 后面多张表,可以AS这样重命名。
- 书上说是基本思想为主键值与外键值进行匹配对比orz
- join … on …:
- 和前面一样的嗷!!!
- select … from … join … on … join … on …
- 内外连接orz,见的多了嗷,看下面的例子,语句执行的顺序非常非常重要!!!
DCL:
- grant all on <DBName> to <Role or User>
- deny all on <DBName> to <Role or User>
- revoke all on <DBName> from <Role or User>
视图:
- 建立在查询结果集上的虚拟表
- 自己本身没有数据,使用了存储在基础表中的数据
- 与基础表双向互通
创建:
- create view <viewName>[列名1,列名2,…] as <select查询>
- 上面这里列名不取的话就为默认的列名嗷!!!
- 视图的操作和正常的表是一样样的嗷!!!
删除:
drop view <viewName>
视图的作用:
- 简化SQL查询操作,封装好一定的查询语句
- 提高数据的安全性
- 提供一定程度的数据独立性。(有的时候表改了视图不用改嗷!!!)
- 集中展示用户感兴趣的特定数据嗷!!!
第三章学堂在线习题:
- 下去康康这个内容嗷,这个是PostgreSQL里面新加上的嗷!!!
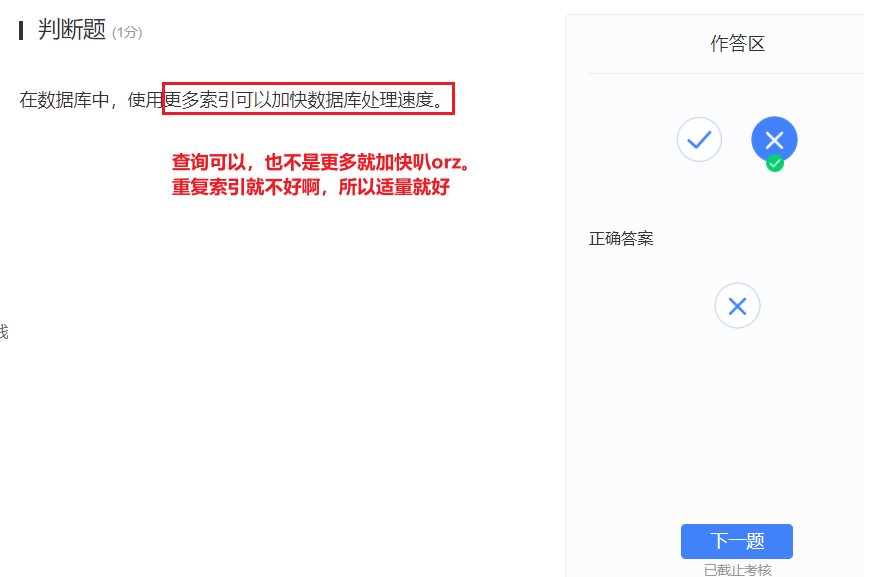

- 我觉着这里的更多索引就是在隐含,每一列加索引orz。
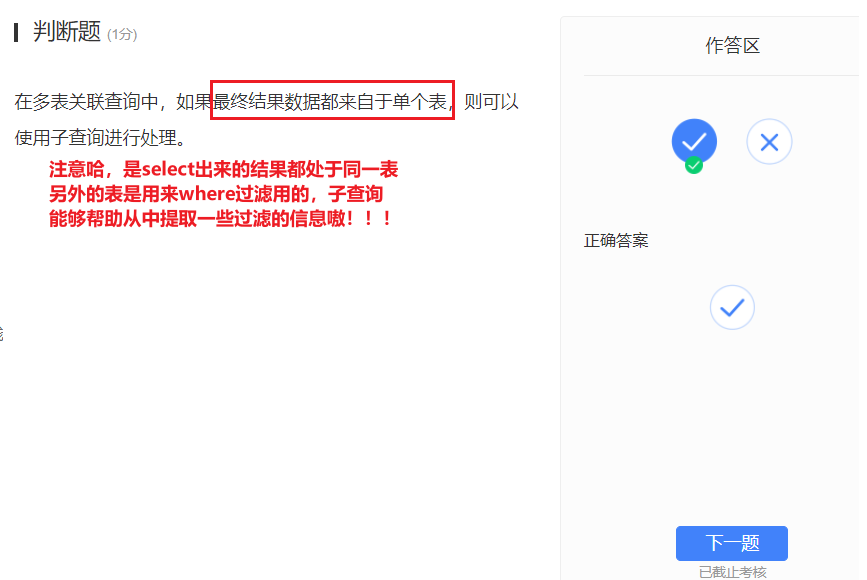
- 展示多张表的数据不得不多表连接查询,不然怎么展示多张表中的数据啊???
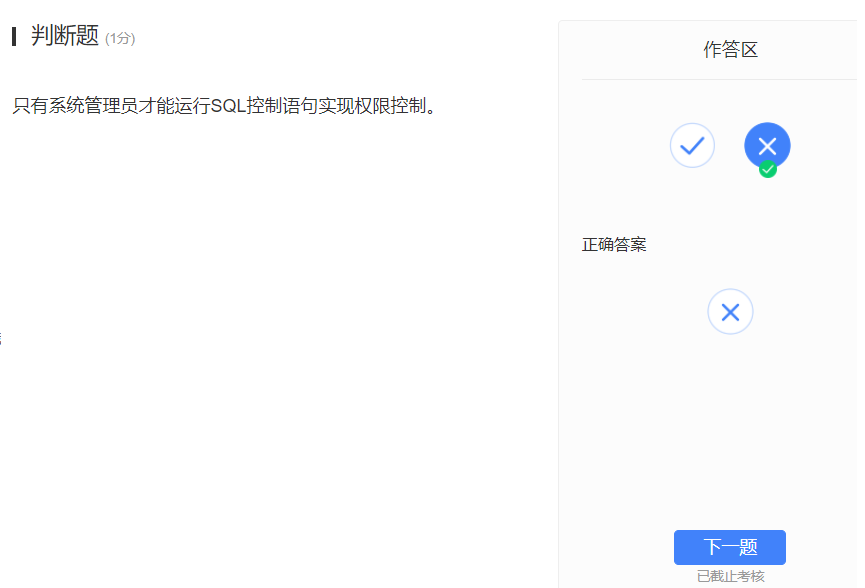
- 赋予了相应的权限的人也可以使用DCL来控制权限,你想想哈,一个用户赋予了它的子用户权限,它肯定可以收回来啊!!!
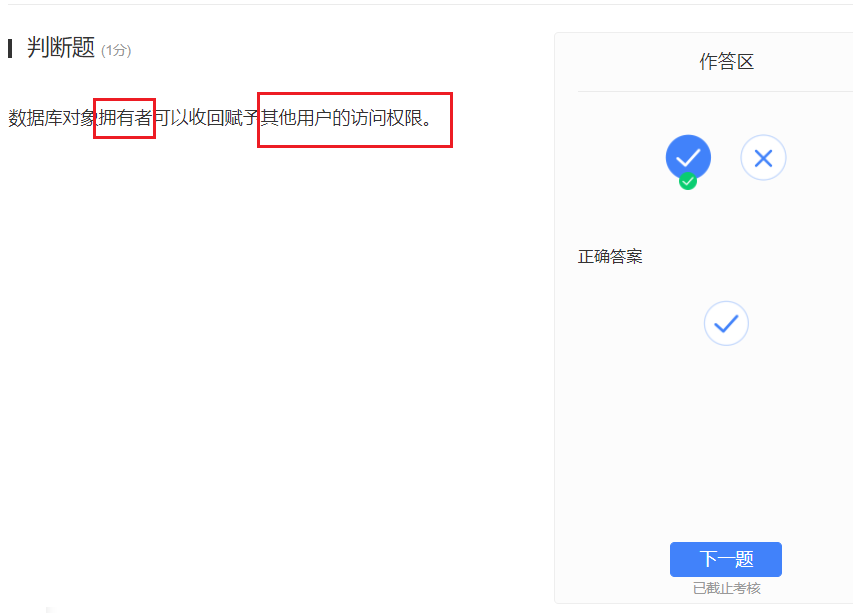
- 拥有者拥有“拥有者上帝权限”,还是猛一点,这个没办法嗷orz
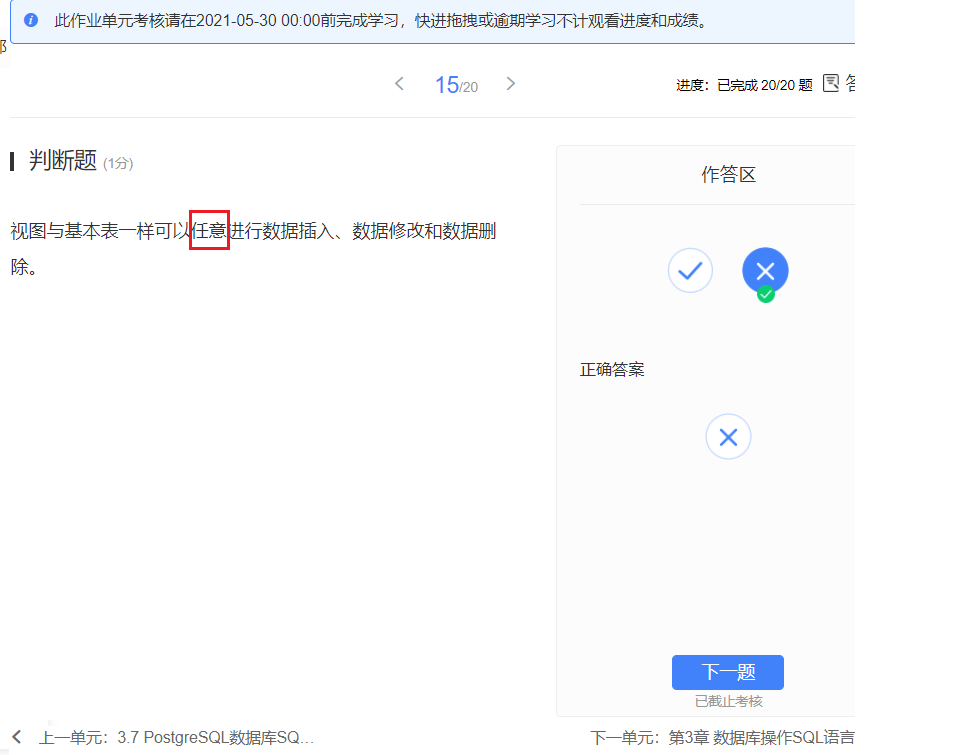
- 基本表也不可以任意啊orz,都是有一定约束的修改和删除好吧,有外键约束呢不能这么玩orz,外键约束被你视图突破了还得了???
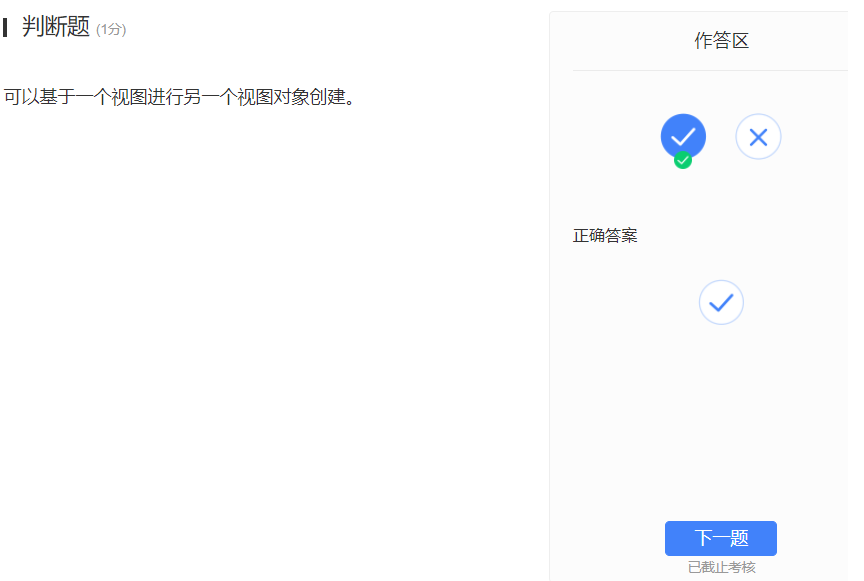
- 上面这个是可以的嗷!!!
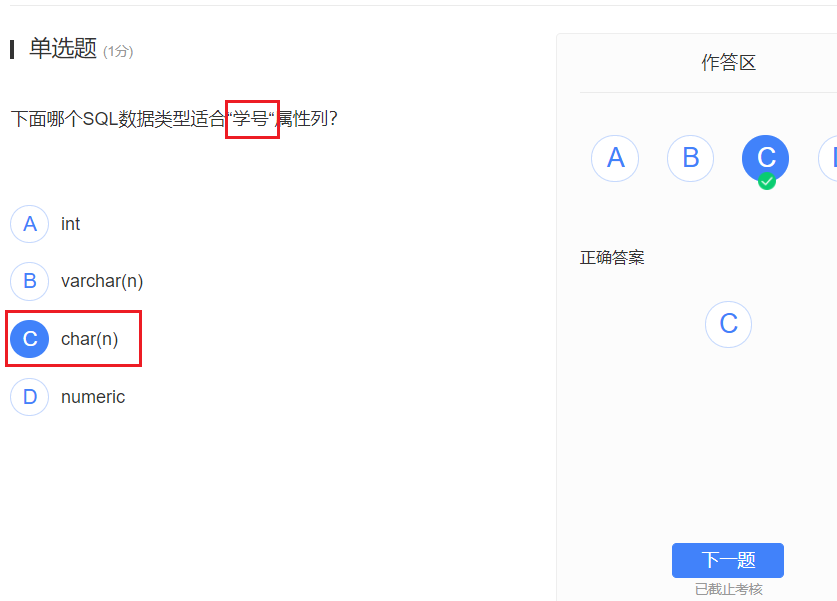
- 学号更加偏向于字符串,例如我们日常的学号都有一些类似于年份啊之类的存储,学号又都是同位数的,char刚刚好,拿int之类的存有点emmm,怎么说呢,没啥用,查那么大一个数字就很浪费诶orz。
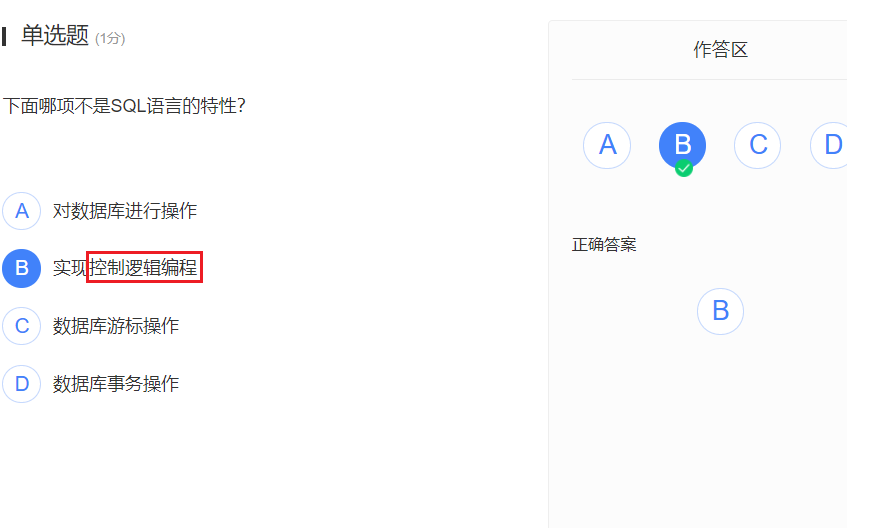
- 上面这个反正第二个我没见过:

第三章补充学习:
- 这里的图片主要为三个部分:
- 数据库的操作
- 事务的操作
- 游标的操作
- 没有出现过什么类似于控制逻辑操作等奇奇怪怪的东西嗷!!!
SQL广泛支持的数据类型(基本数据类型):
- varchar , char
- int , smallint
- numeric
- real , double
- money
- bit
- date
第四章:数据库设计和实现
数据库设计概述
数据库设计方案主要体现为:
- 数据库设计报告
- 数据库设计模型
本质上就是文档+产品嘛!!!
报告中:
- 数据库任务目标
- 数据库设计思路
- 数据库设计约束
- 数据库命名规则
- 数据库应用架构
- 数据库应用访问模式
- 数据库设计模型等
核心:
- 各种设计模型:
- CDM
- LDM
- PDM
- 各种设计模型:
系统架构可以由CDM , LDM , PDM组成。
典型数据库设计框架:
- 应用访问方式
- 结构模型
- 应用结构
CDM:
- 概念上,和系统无关
- 内在数据模型到信息系统数据实体联系的顶层抽象。
- 用于设计人员与用户交流的载体。
- 确保模型满足用户数据需求。
LDM:
- 概念设计模型的完善。
- 依然关系表示为实体与联系,使得实体联系更加完善和规范,但不依赖于DBMS产品。
- 此时是从系统设计角度描述对象与结构的关系,考虑逻辑表示。
PDM:
- 系统设计角度描述数据模型在特定DBMS中的具体设计实现方案。
- 满足数据库设计模型的三个基本原则:
- 真实模拟
- 容易被用户理解
- 便于在计算机实现
数据库设计过程:
- 需求分析,系统设计。
- CDM
- LDM
- PDM
- 数据库实现
中间的三步统称为数据库建模设计
需求分析:需要分析人员从业务分析中获取数据处理请求,抽象出数据实体。
数据库设计:从业务领域,进行概念设计。软件设计角度,逻辑设计。DBMS,具体实现设计。
数据库设计策略:
- 为了适应组织机构的信息数据处理需求与支持业务数据管理而设计的数据库方案与其数据模型的过程。
- 自底向上:
- 不断概括,分类与最终建立反应整个组织全局数据模型。
- 适用于较小规模,业务数据关系较为简单的数据库设计
- 自顶向下:
- 规划设计组织机构顶层的数据模型,然后对于各个部门所涉及的业务数据进行实体联系建模。
- 适用于规模较大,业务关系复杂。
- 设计难度大,初始阶段全局规划设计数据模型困难。
- 由内而外:
- 设计核心业务,逐步向外拓展。
- 由内而外是自底向上的特列。
- 实体冲突,实体冗余,实体共享的问题
- 混合设计:
- 避免单一模式的局限
- 适用于大型组织机构的复杂数据建模设计
- 过程:
- 自顶向下分割业务范围
- 自底向上建立数据模型
- 解决实体冲突等问题
E-R模型
基本元素:
- 实体
- 属性
- 联系
- 实体:
- 两层方框表示
- 实体名:大写字母开头的具有特定含义的英文名词表示
- 属性:
- 上栏实体名称,下栏实体属性
- 被用于唯一标识不同实体的属性或属性集被称为标识符
- 联系:
- 一元联系:
- 又被称为递归联系
- 一个实体集内部实体之间的联系
- 二元联系:
- 两个实体间的联系
- 三元联系:
- 三个实体之间的联系,比较少用嗷!!!
- 例如继承的联系,例如商品可以分类为图书和计算机。
- 一元联系:
实体联系类型:
针对于二元实体联系分析,因为二元用到的最多嗷!!!
多重性联系:
一对一联系:
- 实体A在实体B中至多有一个实体有联系。- 一对多联系:
- 实体A在实体B中至少有一个实体有联系。
- 多对多联系:
- A中至少有一个实体与N中至少有一个实体有联系
- 一对多联系:
参与性联系:
- 可选和强制的联系
- 有的时候还要确定基数范围,用[]来表示
继承性联系:
- 互斥继承和非互斥继承
- 互斥:父实体一个实例只能属于某个子实体
- 非互斥:父实体一个实例可以属于多个子实体
完整性联系:
- 完整:父实体的实例被子实体完整继承
- 非完整:和上面不符合
强弱实体:
- 某些实体必须依赖另外的实体存在
- 某些实体为弱实体,另外的实体为强实体
- 给出一个弱实体的时候,也要给出它所依赖的强实体,才能完整反应组成结构嗷!!!
- 一个实体既可以是弱实体,也可以为强实体。在不同关系中扮演角色不同哈!!!
- 强弱实体区分是为了确定实体之间的依赖关系,同时也在系统模型设计的时候确保完整性!!!
标识符依赖实体:
- 标识符依赖弱实体:
- 弱实体的标识符中含有强实体的标识符,就被称为标识符依赖弱实体。
- 非标识符依赖弱实体:
- 本质上就是代理主键嘛!!!其实全部都是Id依赖的,一般情况下只要外键为其他的主键,都为id依赖,只是有时候定义了代理键而已嗷!!!
E-R模型图:
- 书上P115
数据库建模设计
概念数据模型设计
抽取实体与标识实体
分析与标识实体联系
定义实体属性和标识符
检查和完善概念数据模型
一些注意点:
- 实体名称必须唯一,且有明确的意义。
- 属性名称不一定要唯一哈
- 联系名称必须唯一,且有明确的意义。
逻辑数据模型设计
- 系统设计角度,使得E-R模型体现数据库模型的针对性(如使用对象数据库还是关系-对象数据库啊之类的),但是不确定使用这类模型中的哪一种具体的DBMS。
- LDM与CDM的区别:
- LDM更加具体,可能还会新增便于信息化处理的数据实体。
- 多对多打咩,转换为一对多。
- 进一步细化,区分主键标识符和外键标识符,以便规范化处理。
- 步骤:
- CDM / LDM的转换
- 规范化和完善逻辑数据模型设计:
- 通常需要各个实体符合数据库设计规范的3NF范式
物理数据模型设计
- 对于选定的具体的DBMS,设计人员对于其及逆行物理数据模型设计,系统设计中主要讲实体转换为对应的数据库表,参照完整性约束,并进行存储过程等的设计。
- 步骤:
- 实体到关系表的转换:
- 属性的具体设计
- 标识符标识为主键
- 代理键设置
- 列特性设置
- 数据约束等
- 弱实体到关系表的转换:
- 外键 -> 非标识符依赖
- 主键+外键 -> 标识符依赖
- 实体联系的转换:
- 一对一联系 -> 外键(双向外键都可行)
- 一对多联系 -> 外键(一作为外键放入多)
- 多对多联系 -> 再来一张表,两个外键解决。
- 实体继承关系 -> 父表属性作为子表外键(父表的属性是公有的嘛!!!)
- 实体递归联系 -> 本表中接入一个外键来表示本类另一个实体,一对多一样的,多对多多一张表就舒服了嗷!!!
- 实体到关系表的转换:
数据库规范化设计
- 规范化数据库是为了减少数据冗余,减少一致性维护成本
- 好处:
- 冗余数据减少到最低程度,同一数据在数据库中只保存一份,降低数据一致性的工作量
- 设计合理的标表间依赖关系和约束关系
- 设计合理的数据库表结构
非规范化表的问题
- 可能遇见的异常:
- 插入异常
- 删除异常
- 修改异常
- 上述问题出现的原因是,一张表存储了多个主题的信息数据。
函数依赖理论
- 本质:
- 分析属性之间的依赖关系
- 使用一定的规则确定属性组合,减少冗余数据。
- 函数依赖是为了表示属性之间在语义上的联系。
- 函数依赖的定义:
- X —> Y这样的形式就是函数依赖。
- 左部为决定因子,右部为函数依赖。任意可能值都要满足才能叫函数依赖。
- X,Y都为函数的属性嗷!!!
- 平常所指的函数依赖一般都是指非平凡函数依赖。
- 部分函数依赖:
- 顾名思义,只依赖一部分,例如一个表的复合主键有两个元素,而仅仅通过其中一个元素就能够确定其他的某些元素,那其他的元素就部分依赖于这个主键呀!
- 传递函数依赖:
- 主键X可以确定N , N不能确定主键X,但是N可以确定O那这个时候肯定X可以确定O呀,就类似于,X与N是一对一的关系,N与O是一对一的关系,那X与O肯定一对一啊!!!
- 多值依赖:
- 有属性相互独立的!!!
- 看书上P131
规范化设计范式
- 高级范式包含了低级范式的全部要求。
- 数据库中第三范式或者巴斯-科德范式就足够了。
第一范式:
属性列不能重复并且不可分割
对于关系表的基本要求
第一范式都不满足就不是关系orz。
属性列不能重复并且不可分割,这都是关系的最基本的要求,要是关系一定要第一范式。
解决方法:对于关系进行分解处理,分解后的每个属性都满足规范化为止。
第二范式:
消除部分依赖,拆成完全依赖。
一范式+消除属性列部分依赖 = 二范式
数据表中的数据对于主键要完全依赖,不可以出现部分依赖。
部分依赖的话,就要把复合主键拆开来,把部分依赖的放在一起构成完全依赖嗷!!!
第三范式:
消除传递依赖
二范式+消除属性列传递依赖 = 三范式
拆,有传递依赖就拆成表用外键,总可以拆分的。
巴斯-科德范式:
所有函数依赖因子必须是候选键
又被称为BCNF范式
要是不是候选键的话又可以拆了我的天啊!!!
第四范式:
BCNF + 多值依赖 = 第四范式
离谱
第五范式:
为了消除连接依赖进行投影分解嗷!!!
离谱。。。
逆规范化处理
- 牺牲空间,提高性能,减少多表连接查询以省时间嗷!!!
- 逆规范化处理方案:
- 关系表的合并:
- 1 : 1实体联系,常被一起访问的,可以合并。
- 冗余列的增加:
- 1 : N实体联系,减少连接。M : N也可以嗷!!!
- 抽取表的创建:
- 时效性不高的可以放入独立创建的表中。
- 关系表分区的创建:
- 可以大幅缩短时间嗷!!!
- 关系表的合并:
- 带来的问题:
- 数据存在冗余,耦合度高,不利于日后的升级和维护。
- 数据完整性降低。
- 降低数据库更新操作的性能。
- 设计原则:
- OLTP情况下,第三范式或者巴斯科德足够了,别花里胡哨的嗷!!!
- 局部优化,不要把规范化和逆规范化对应起来。
- OLAP,低程度规范化处理。OLTP,较高程度的规范化处理。
第四章学堂在线习题:
- E - R模型实体,属性,联系:标识符的话本质上也是属性嗷,所以题目可能会变着法考你嗷!!!

- 结合特定DBMS添砖加瓦。
- 标识符分为主键标识符和外键标识符,分别转换为主键和外键嗷!!!标识符类型的转换在CDM转为LDM的时候,就已经确定了嗷,转的时候要注意嗷!!!
- 可以看出来,标识符不是那么严格的哦!!!(标识符弱实体不一定需要)
- 所有表的设计,与表相关的存储过程的设计都是在PDM阶段解决的!!!
- 没错哈,这就对应了我们从Power Designer中导出SQL脚本的过程嗷!!!
第五章:数据库管理
概述
- 内容:
- 运行维护
- 事务管理
- 性能调优
- 安全管理
- 故障恢复
- 定义:为了保证数据库系统正常的运行和服务质量,相关人员必须进行的系统管理,管理人员被称为DBA
- 目标:
- 正常稳定运行
- 充分发挥数据库的软硬件处理能力
- 确保数据库安全和用户数据的隐私性
- 有效管理数据库系统用户及其权限
- 解决数据库性能优化,系统故障与数据损坏等问题
- 充分发挥数据库对其所属机构的作用
- 总之数据库相关的管理,权限的设置,备份和故障等特殊权限的应对都是DBA来管嗷!!!
- pgAdmin本质上就是一个数据库管理工具。
- DBMS的功能如下:
- 数据库定义:
- 提供DBA数据库及其对象进行创建和修改功能。
- 数据库对象创建和修改功能。
- 数据库运行管理:
- 提供DBA对于数据库运行控制管理功能。
- 操作完整性检查,系统运行日志管理,系统运行性能监控
- 数据组织与存储:
- 实现数据库的数据组织与存储管理
- 数据库文件组织,数据分区存储,数据存储管理,缓冲区管理等
- 数据库维护:
- 为DBA提供数据库维护的功能
- 数据的载入,数据的转换,数据导出,数据库重构,数据库备份,数据库恢复等。
- 数据库通信:
- 为DBA提供数据库通信管理功能
- 不同数据库之间的复制,不同分区之间的数据同步等功能。
- 数据库定义:
- DBMS的结构:
- 语言翻译处理层:
- SQL语句的编译
- 视图转换
- 授权检查
- 完整性检查
- 事务命令解释等
- 数据存取控制层:
- 上层翻译的SQL命令的执行。
- 对于各种数据库对象进行逻辑存取操作访问。
- 实现多用户环境事务并发访问控制。
- 多用户环境并发控制访问
- 数据库事务管理
- 执行引擎操作
- 权限控制
- 系统给日志管理
- 数据库恢复管理
- 性能监控
- 数据存储管理层:
- 对于物理存取操作访问。
- 对于缓冲区进行管理
- 调用系统接口物理意义上对于数据库文件进行I / O 操作。
- 语言翻译处理层:
事务管理:
事务的概念:
- 事务指的是由构成单个逻辑处理单元的一组数据库访问操作。
- 要么都被执行,要么都不执行。
- 确保数据库处于正常状态与数据一致性。
一些有意思的定义:
- 事务是DBMS执行的最小任务单元
- 事务也是DBMS最小故障恢复任务单元和并发控制任务单元。
一个事务可以由一组SQL组成,也可以由一条SQL组成。一个应用程序可以包含一个SQL或者一组SQL。
事务状态:
- 事务初始状态:
- 事务被DBMS调度之后
- 事务正常状态:
- SQL语句成功执行
- 事务失败状态:
- SQL语句操作失败
- 事务提交状态:
- 所有SQL执行之后都是事务正常状态
- 事务回滚状态:
- 但凡一条SQL操作失败处于事务失败状态之后
- 事务初始状态:
即使进入了事务正常状态,也有可能接下来遇到意外失败而进入失败状态。
提交状态和回滚状态之后,就是结束
总共五个状态嗷:初始,正常,失败,提交,回滚。
事务的特性:
- 原子性:
- 要么全被执行,要么全不执行,最小工作单元
- 一致性:
- 事务执行结果使得数据库从一种正确状态变迁到另一种正确状态
- 事务保证了数据库数据的正确性。
- 隔离性:
- 多个事务并发执行的时候,一个事务的执行不能够被其他事务干扰。
- 持久性:
- 事务一旦提交数据就持久化了。
事务的并发执行:
- 提高系统的吞吐量和资源利用率
- 减少事务执行的平均等待时间
- 语句:
- begin / start transaction
- rollback
- commit
- savepoint
- postgres里面是使用begin开始事务的嗷!!!
- 不是所有的操作都能够放在事务里面执行的嗷:
- 数据库的创建,修改,删除
- 数据库的恢复和加载
- 备份日志文件
- 授权操作
- 说白了就是对于数据库表的数据进行具体操作才能够使用事务嗷!!!
- 默认设置:每条SQL一个事务。
并发控制:
并发控制问题:
- 脏读:
- 多个事务并发执行,操作访问共享数据,其中一个事务读取了另一个事务修改后的共享数据,但是另外一个事务出问题了,你读到了有问题的数据嗷!!!
- 这个时候你就读到了一个垃圾数据,脏数据。读取了脏数据,可能导致使用数据错误嗷!!!
- 脏读:读了实际不存在的数据
- 不可重复读:
- 对于共享数据先后两次读取的值是不一样的orz
- 你在读,别人在改嗷!!!
- 幻像读:
- 前后两次读,发现后一次读的数据变多了???
- 你在读,别人在添加嗷!!!
- 丢失更新:
- 一个事务更新了某个值,再次访问的时候,这个值它又变了???
- 前三个是自己读的除问题,最后一个是自己的更新出问题。
- 脏读是读到中间数据。不可重复度读是执行相同的读操作,但是原有数据改变或者丢失了。幻像读是执行相同的读操作,但是原有数据增多了。。。脏读只读了一次,不可重复读和幻像读读了两次。
并发事务调度:
- DBMS并发调度器通过安排各个事务的读写顺序来实现调度。
- 结论:事务并发执行的过程中,当事务调度顺序的执行结果和事务串行执行数据结果一样的时候,并发事务调度才能够保证数据库的一致性(这被称为:可串行化调度)。
数据库锁机制:
- 对于共享数据的访问需要加锁!!!这种方式叫做资源锁定嗷!!!
- 锁定资源的类型:
- 排他锁定:
- 封锁其他事务对于共享锁定的任何加锁操作。Lock-X
- 共享锁定:
- 封锁修改或者删除操作,只能够读取嗷!!!Lock-S
- 排他锁定:
- 锁定粒度越大,DBMS管理就越容易,但是性能越差。反之,粒度越小,DBMS管理越复杂,但是性能越好。
锁的并发执行协议
- 排他锁排斥一切的锁,兼容无锁。
- 共享锁排斥排他锁,但是兼容共享锁和无锁。
- 无锁和所有都兼容嗷!!!
- 如果共享数据没有被锁定,则可以添加任意加锁协议嗷!!!!
加锁协议:
- 一级加锁协议:
- 修改变量(更新和删除)之前,要加排他锁。
- 我改的时候,任何人都不准改,不准读。保证了自己事务执行过程中,死死抓着数据不给别人操作,自己的更新就不会和别人的更新冲突啦!!!
- 注意脏读没有解决哦,因为没有对于“读”进行限制,读操作还不受锁的限制。
- 解决了丢失更新的问题。
- 二级加锁协议:
- 一级基础上+读数据的时候要加共享锁,读完就可以释放锁了。
- 别人改的时候我读不了了!!!
- 解决了脏读的问题。
- 三级加锁协议:
- 一级基础上+读数据的时候要加共享锁,事务执行完成之后才可以释放锁。
- 保证了我读的数据,在我事务执行的过程中,没人能改!!!
- 解决了不可重复读的问题。
- 三级的协议,排他锁都是全程要加的,二级协议的时候是开始的时候加锁,读完就可以释放。三级协议的共享锁是全程加锁!!!分别解决了,丢失更新,脏读,不可重复读。
- 老师上课讲过,幻像读比较特殊哈,幻像读的话需要对于表加锁哦,我们一般用不上。
两阶段加锁协议:
- 增长阶段只能够申请锁,缩减阶段只能够释放锁。
- 满足两阶段加锁协议就可以实现可串行化调度嗷!!!
并发事务死锁解决:
- 加锁加着加着可能会出现死锁的情况嗷!!!
- 死锁的必要条件:
- 互斥条件
- 请求和保持条件
- 不可剥夺条件
- 环路等待条件
- 解决策略:
- 预防死锁!!!
- 死锁出现后破坏死锁必要条件嗷!!!
事务隔离级别:
- 读取未提交:
- 四种情况都有可能发生。
- 读取已提交:
- 脏读gg了
- 可重复读:
- 不可重复读和脏读gg了
- 可串行化:
- 四种都gg了。
- 级别越高越猛嗷,越能保持数据的一致性和完整性,但是对于并发性能的影响也就越大嗷!!!
安全管理:
- 采用安全保护措施,防止数据库系统及其数据遭到破坏。
- 存取控制安全模型:
- 每个数据库对象被定义若干访问操作权限,用户和角色可以多对多的嗷!
- 用户和角色均可以被赋予若干数据库对象的操作访问权限,DBMS可以限制和检查他们的访问嗷!
用户管理:
- 要访问数据库,先要创建账号,成为数据库的用户。
- 合法用户才能够进入系统。DBA为其赋予权限并创建初始账号和密码嗷!
- 一些语句:
- SQL语句创建用户
- 用户修改
- 用户删除
- 权限管理:
- 权限类别:
- 数据库对象访问权限:
- 某张表的CRUD权限
- 数据库对象定义权限:
- 数据库对象的创建修改,删除等权限
- 数据库对象访问权限:
- 数据库中,超级用户(admin)拥有系统最高权限,可以对于其他用户和角色进行管理。数据库拥有者(DBO)则拥有其所拥有的对象的全部权限,普通user只是具有被赋予的数据库访问操作权限嗷!!!
- 权限类别:
- 角色管理:
- 和用户管理差不多嗷,没啥两样。
- 角色代表的是不同权限集合的用户集合。
- 可以在创建用户的时候同通过指定角色的方式来达到授权的目的嗷!!!
- 角色分类:
- 系统角色
- 自定义角色
备份与恢复:
- 用户数据库和系统数据库都要备份,出现故障后才能完全恢复。
- 备份方式:
- 完整数据库备份:
- 被封整个数据库
- 花费很多时间和空间,一般一周一次
- 差异数据库备份:
- 只备份上次数据库备份以来发生变化的数据,耗费促成农户空间少。
- 适用于变化频繁的数据库,减少数据丢失的风险。
- 事务日志备份:
- 只备份上一次日志备份已来的食物日志数据。
- 文件备份:
- 通过复制数据库文件的方式来是实现数据库备份,通常和日志事务备份结合使用。
- 冷备份:
- 数据库关闭备份
- 热备份:
- 实例运行情况下的数据库备份,实时备份。但会有点复杂,影响系统性能。
- 备份设备:
- 磁盘阵列
- 磁带库
- 光盘库
- 完整数据库备份:
PostgreSQL备份:
- pg_dump [options]<dbName>并且按照数据库名称来备份。可以对于选定的数据库进行数据被封,也可以对schema备份。
pg_dump -h localhost -p 5432 -U postgres -n public –f g:\ProjectDB-public.sql ProjectDB就是一种示例。- pg_dumpall用于整个数据库的数据备份,默认存在SQL文件中:
pg_dumpall -h localhost -p 5432 -U postgres –f g:\PostgreAllDB.sql
PostgreSQL数据库恢复:
psql [options] -d 恢复的数据库 -f 备份文件psql -h localhost -p 5432 -U postgres –d ProjectDB –f g:\ProjectDB.sql- 若数据库备份以自定义压缩格式、TAR包格式或目录格式存储数据备份文件,则需要使用pg_restore实用程序工具进行数据备份恢复处理。
pg_restore -h localhost -p 5432 -U postgres –d ProjectDB -c g:\ProjectDB.bak- 在Windows下的CMD中就可以运行嗷!!
第五章学堂在线习题:
别问,问就是记住orz。
注意一下这里哈,这里是DBMS自动恢复。存储设备损坏了的话,需要重新人工手动导入,其他的都是。但是事务故障的话,数据库会自动撤销事务恢复数据嗷!!!
不得行,完整+差异+事务才能够恢复嗷!!!
第六章:数据库应用编程
- 提供数据库接口的中间件有:
- ODBC
- JDBC
- ADO.NET
- PDO
- ODBC提供了:
- CLI
- DLL
- ODBC驱动程序相当于中介,屏蔽了不同的DBMS接口,为上层ODBC应用程序的编写提供了同一的接口。
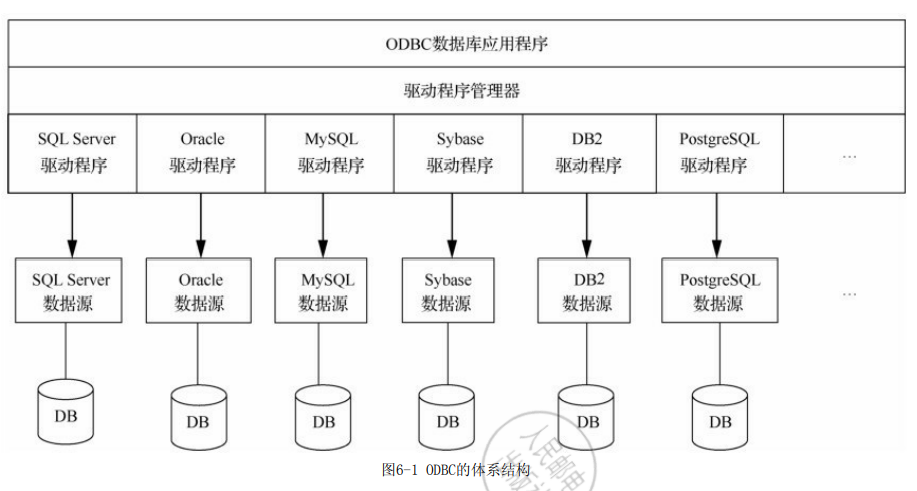
- ODBC由四个部分构成:
- ODBC数据库应用程序
- 驱动程序管理器(最重要,负责管理ODBC驱动程序的加载,管理不同数据库的驱动程序,向上提供统一的接口!!!)
- DBMS驱动程序
- 数据源
JDBC技术:
- JDBC驱动程序的类型:
- JDBC-ODBC Bridge Driver
- Native-API partly-Java Driver
- JDBC-Net All-Java Driver
- Native-protocol All-Java Driver(最常用的嗷!!!,由数据库厂商直接提供的嗷!)
- JDBC核心类和接口:
- java.sql.DriverManager是JDBC的管理类,静态方法有getConnection等,getDriver()等
- java.sql.Connection提供的的Connection对象代表连接嗷!getConnection对象的返回值。有createStatement , close , preparedStatement等方法嗷!!!
- java.sql.Statement,这个是执行静态SQL并且返回的生成的结果对象,有:Statement , PreparedStatement和CallableStatement三种对象。
- java.sql.ResultSet接口表示结果集合。通过next()和get()方法取到结果。
- 运行步骤:
- Class.forName(“”),加载驱动
- Connection conn = DriverManager.getConnection(url,username,passwd) , 获取数据库连接。
- Statement stmt = conn.createStatement(),建立会话
- int temp = stmt.executeUpdate(sql语句) , ResultSet rs = stmt.executeQuery(sql语句)。通过会话执行SQL语句。
Java Web技术:
- Tomcat
- Servlet技术:
- Servlet优点:
- 持久的,只需要Web加载一次
- 平台无关
- 可拓展
- 安全
- 适配多种客户机
- Servlet优点:
- JSP技术:
- Servlet + JSP
- JSP本质就是弱化版的Servlet
- 特点:
- 平台无关
- 跨平台组件
- 标签化页面开发
- 多层企业应用架构支持
- JSP语法:
- JSP中的脚本程序的格式为 <% 脚本程序;(’;’必须加)%>
- JSP中的变量、方法声明的格式为 <%! 变量、方法声明;(’;’必须加)%>
- JSP中的表达式的格式为 <%= 表达式(不能加’;’)%>
- JSP编译指令:
- page指令:为容器提供说明
- taglib指令:引入自定义标签集合的定义
- include指令:通过include指令来包含其他文件,可以包含JSP,HTML文件或者文本文件。
- JavaBean技术
- MyBatis访问数据库技术:
- API接口层
- 数据处理层
- 基础支撑层
- 核心部件:
- SqlSession
- Executor
- StatementHandler
- ParameterHandler
- ResultSetHandler
- TypeHandler
- ……
- MyBatis访问数据库的基本过程:
- SqlMapConfig.xml
- mapper.xml
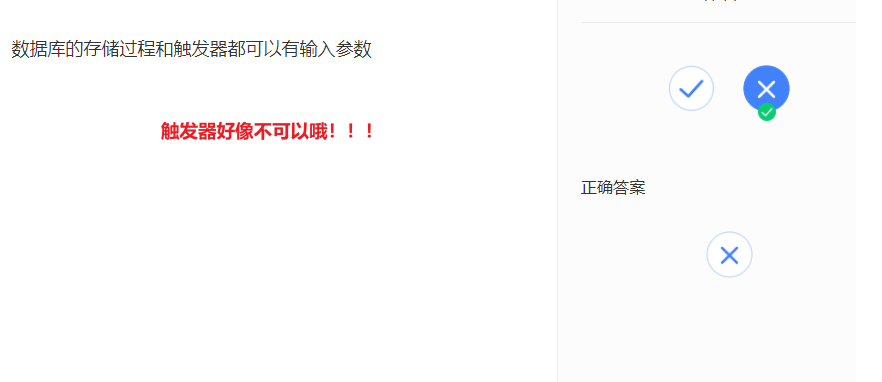
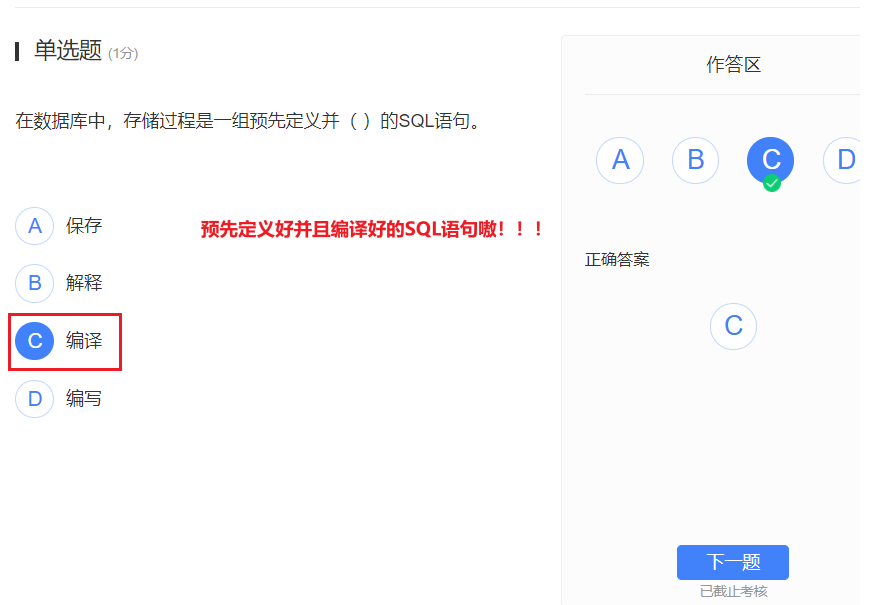
存储过程编程:
经编译后,存储在数据库服务器端,当被再次调用时,不需要再次编译;当客户端连接到数据库时,用户通过指定存储过程的名称并给出参数,数据库就可以找到相应的存储过程并予以调用
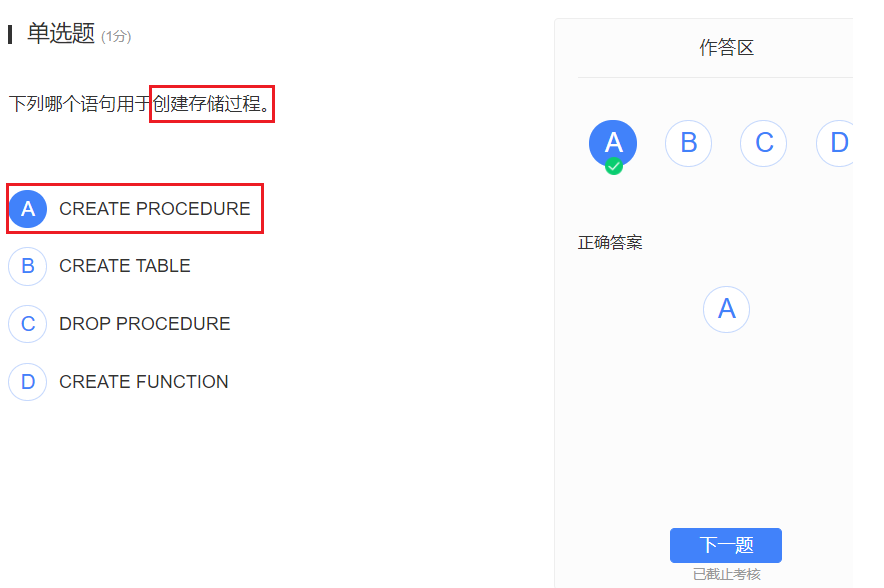
创建:
- create function
- select … into 可以将值存入变量中
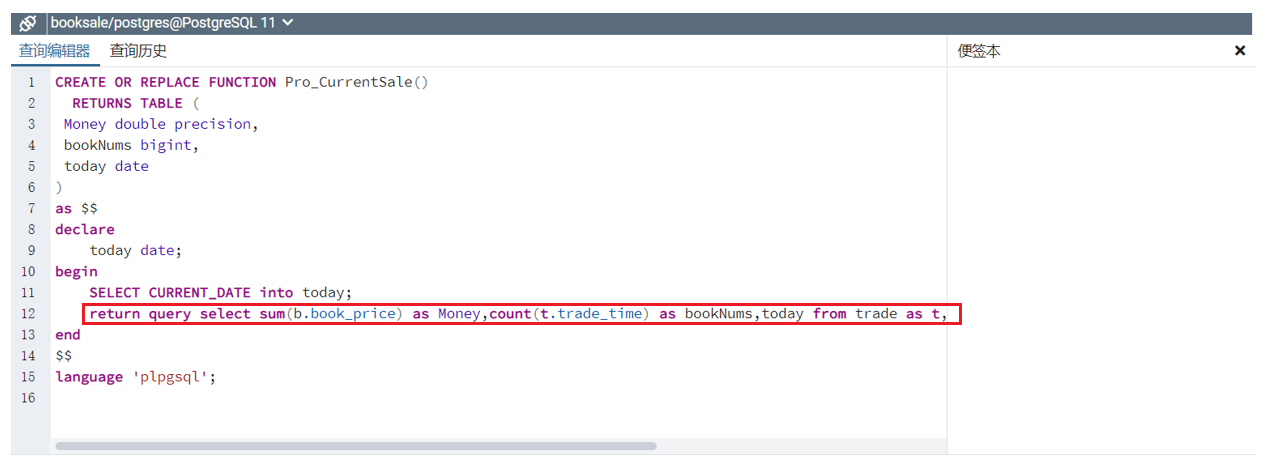
- 或者这里直接用return query语句,也可以将查询结果封装成表然后返回嗷!!!

- out表示输出参数嗷!!!
- 用户只有具备该存储过程(函数)的所有权,才能修改存储过程。如果要修改存储过程的模式,用户还必 须在新模式上拥有 CREATE 权限。如果存储要改变外部表的所有者,用户必须是新角色的直接或间接成员,并且这个 新角色必须在该函数的模式上具有CREATE 权限。超级用户可以用任何方法任意更改函数的所有者。
- 存储过程优缺点:
- 优点:
- 减少网络通信量
- 执行速度更快
- 适应性更强
- 降低了业务与应用程序的耦合
- 降低了开发的复杂性
- 保护了数据库的元信息
- 增加了安全性
- 缺点:
- SQL本身是结构化语言,存储过程是过程化的程序。SQL优势难以体现。
- 存储过程代码的更新同时还需要更新主程序调用存储过程的代码。
- 开发调试复杂。
- 可移植性较差。
- 优点:
触发器编程:
- 触发器和存储过程不同,存储过程通过其他程序来启动运行,而触发器由时间触发启动运行。
- 触发器可以作用域:
- 表
- 特殊的视图
- 外部表定义上
- 触发器用于定义逻辑比较复杂的完整性约束。
- 触发时间:
- BEFORE
- AFTER
- INSTEAD OF
- 例如,往视图插入数据可以通过INSTEAD OF转换为向基表插入数据嗷!!!

- 特殊变量:
- NEW,新保存的数据,DELETE中这个变量没有值
- OLD,老的数据,INSERT中这个变量没有值
- TG_NAME:数据类型是name;该变量包含实际触发的触发器名称。
- TG_WHEN:数据类型是text;是值为BEFORE、AFTER或INSTEAD OF的一个字符串,取决于触发器的定 义。
- TG_LEVEL:数据类型是text;是值为ROW或STATEMENT的一个字符串,取决于触发器的定义。
- TG_OP:数据类型是text;是值为INSERT、UPDATE、DELETE或TRUNCATE的一个字符串,它说明触发 器由哪个操作引发。
- TG_RELID:数据类型是oid;是引发触发器调用的表的对象ID。
- TG_TABLE_NAME:数据类型是name;是导致触发器调用的表的名称。
- TG_ARGV[]:数据类型是text数组;来自CREATE TRIGGER语句的参数。索引从0开始记数。非法索引(小于 0 或者大于等于TG_NARGS)会导致返回一个空值。
- TG_NARGS:数据类型是integer;在CREATE TRIGGER语句中给触发器过程的参数数量。
- TG_TABLE_SCHEMA:数据类型是name;是导致触发器调用的表所在的模式名称。
- 绑定触发器函数与表:
CREATE TRIGGER score_audit_trigger AFTER INSERT OR UPDATE OR DELETE ON Stu_score FOR EACH ROW EXECUTE PROCEDURE score_audit();
- 修改触发器:
ALTER TRIGGER name ON table_name RENAME TO new_name
- 删除触发器:
DROP TRIGGER [ IF EXISTS ] name ON table_name [ CASCADE | RESTRICT ],由于触发器和对应的表相互绑定,因此要删除对应某张表中的某个触发器QAQ!
事件触发器:
当指定的事件发生时,事件触发器就会被触发。事件触发器定义在数据库级,权限相对较大,所以只有超级用户 才能创建和修改触发器。当预定的事件发生时,事件触发器就会被触发。
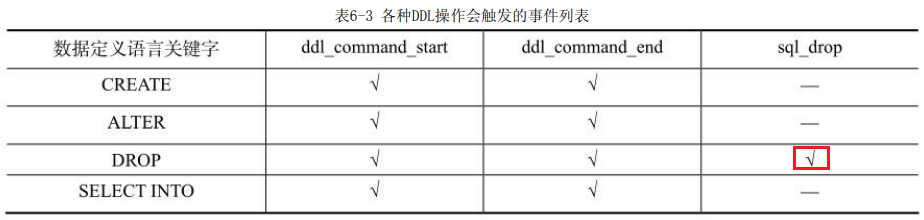
事件触发器支持的事件分3类:ddl_command_start, ddl_command_end 和 sql_drop。
(1)ddl_command_start:在DDL开始前触发。
(2)ddl_command_end:在DDL结束后触发。
(3)sql_drop:删除一个数据库对象前被触发,其中删除的数据库对象详细信息,可以通过 pg_event_trigger_dropped_objects()函数记录下来。该函数返回的结果集见表6-2。
SELECT INTO 从一个查询中创建一个 新表,并且将查询到的数据插入到新表中,数据并不返回给客户端,新表的字段具有和SELECT 的输出字段相同的名称 和数据类型,所以执行SELECT INTO会触发事件。表6-3给出PostgreSQL的CREATE、ALTER、DROP、SELECT INTO 关键字相关命令执行时所触发的事件。
创建事件触发器:
触发器函数没有参数,返回event_trigger类型。
(1)tg_event:为ddl_command_start、ddl_command_end、sql_drop之一。
(2)tg_tag:实际执行的DDL操作,如CREATE TABLE、DROP TABLE等。
绑定触发器到表上:
CREATE EVENT TRIGGER NoCreateDrop ON ddl_command_start WHEN TAG IN ('CREATE TABLE', 'DROP TABLE') EXECUTE PROCEDURE abort();
- 应用:
- 检查输入数据的完整性
- 完成特殊的业务规则
- 保证数据一致性
- 追踪数据库操作。
- 优点:
- 提高开发速度。
- 全局执行业务逻辑规则,触发器的业务处理可以被数据库应用程序共享。
- 更加容易维护,如果业务发生变化,只需要改触发器,应用程序可以不动。
- 实现较为复杂的数据完整性约束。
游标编程
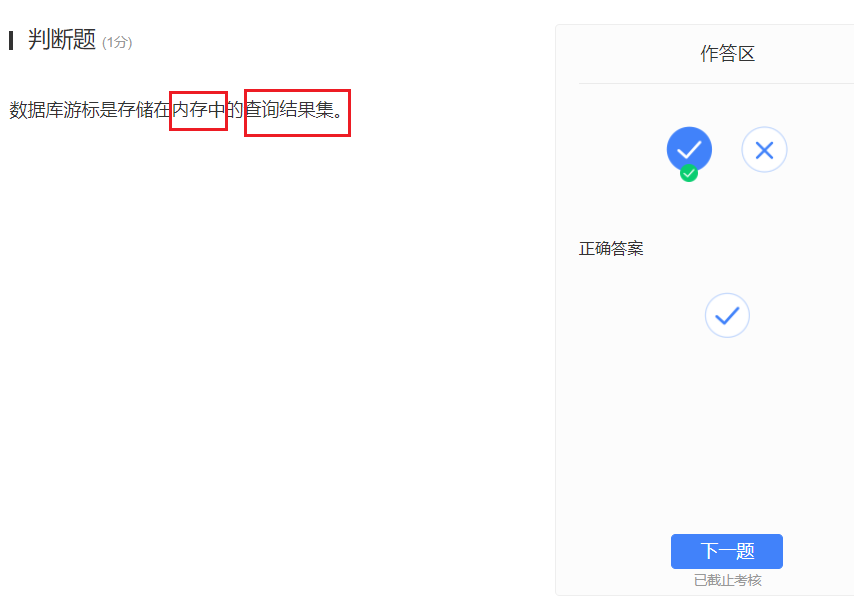
- 游标是临时的数据库对象,存储查询返回的数据行的副本。当存储过程或函数对于查询结果处理,声明指向结果集的游标变量。
- 步骤:
- 声明游标:
curStudent CURSOR FOR SELECT * FROM Student; curStudentOne CURSOR (key integer) IS SELECT * FROM Student WHERE SID = key;
- 打开游标:
OPEN unbound_cursor FOR query;
- 声明游标:
- 游标应用编程:
- 略
第六章学堂在线习题:
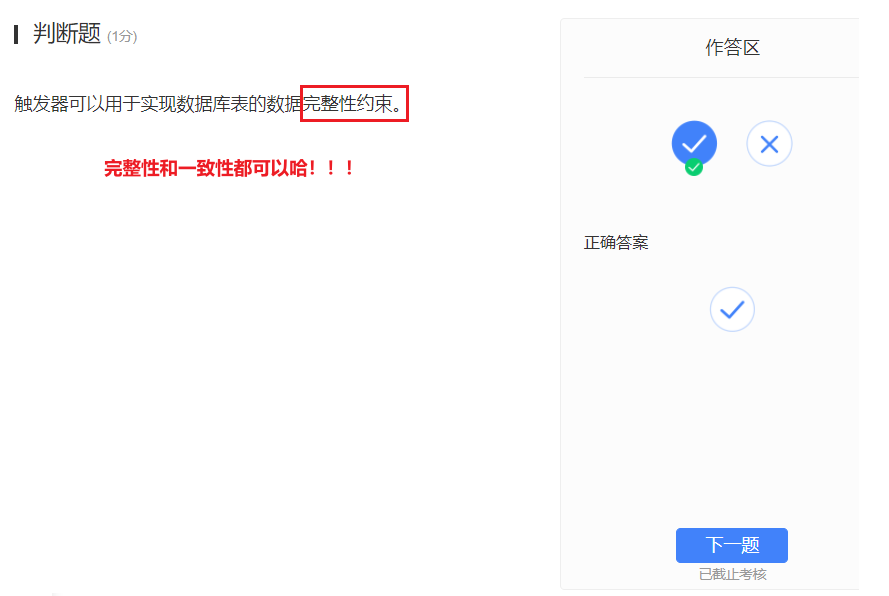
数据完整性约束指的是为了防止不符合规范的数据进入数据库,在用户对数据进行插入、修改、删除等操作时,DBMS自动按照一定的约束条件对数据进行监测,使不符合规范的数据不能进入数据库,以确保数据库中存储的数据正确、有效、相容。所以我可以拿到你的NEW判断你数据合法不!!!
第七章:NoSQL数据库技术
- 关系数据库的优势:
- 外模式
- 模式
- 内模式
- 事务处理机制保证了ACID
- 缺点:不擅长大量数据的写入处理,表结构变更,字段不固定等问题处理不了嗷!!!
- 关系数据库的挑战:
- 数据库高并发的读写需求
- 海量数据的高效存储和管理
- 数据库高拓展性和高可用性
- 数据库在大数据处理方面的要求
- 大数据的5V特征:
- 超量
- 高速
- 异构
- 真实
- 价值
- 海量数据关键技术:
- 数据划分
- 数据一致性
- 可用性
- 负载均衡
- 容错机制
- 虚拟存储环境
- 云存储技术
NoSQL理论基础:
正对于分布式的CAP理论:
- Consistency , 一致性。
- 所有结点在同一事件具有相同的数据,具有一致性。
- Availability , 可用性
- 不管操作如何,系统都要及时返回结果。
- Partition Tolerance , 分区容忍性
- 网络被分割为若个个独立的区域时,系统仍然可以接收服务请求。
- 三个同时满足不太显示,最多同时满足两个。由此出现了CA , CP , AP。
- 原则讲解:
- CA , 一致可用,单点集群,拓展性不强。
- CP , 一致可拓展,可用性不强,性能不是特别高orz。
- AP , 一致性要求不那么高,但是可以分布式部署,可以使用。
- Consistency , 一致性。
BASE:
- Basically Available:基本可用,系统可以基本运行,一直提供服务。
- Soft State:软状态(无连接),而硬状态就是面向连接的,系统不要求强一致的状态
- Eventually Consistence:最终一致性,在某个时候达到最终一致性
- S是实现BASE模型的方法,BA和E是实现BASE的目标。
一致性理论:
- 强一致性:所有的读操作都要获取到最新的数据。
- 弱一致性:读到某一操作对系统特定数据的更新需要一段时间,这段时间被称为“不一致窗口”
- 最终一致性:弱一致性的特例,保证用户最终能够读取到某个操作对于系统特定数据的更新。
最终一致性最常用,进一步细分:
- 因果一致性:无因果关系的数据不保证一致性
- 读一致性:用户自己总能够读到更新后的数据,别人不一定
- 会话一致性:存储过程进程限制在会话范围内,会话存在就读一致性
- 单调读一致性:数据被读取,后续操作都不会返回给数据之前的值。
- 单调写一致性:同一个进程的更新操作按照时间顺序执行,时间轴一致性。
NoSQL的特征:
- 简单类型记录
- 元数据和应用数据分离
- 弱一致性(减少同步开销,最终一致性和时间一致性来满足一致性要求嗷!!!)
NoSQL的普遍存在的特征:
- 不用预定义模式
- 无共享架构
- 弹性可拓展
- 分区(解决了单点失效的问题)
- 异步复制
- BASE:保证事务的最终一致性和软事务(一般都是这种,满足AP嗷!!!C可以缓缓orz)
处理的数据类型简单,其中使用元数据来定义系统处理的数据格式。
NoSQL处理的数据类型简单,可以避免不必要的复杂性,以提供较少的功能来提高系统的性能,避免昂贵的对象-关系映射。
NoSQL分类:
- 列存储数据库
- 键值对数据库
- 文档数据库
- 图形数据库
列存储:
- 只定义列族
- 键存在但是指向了多个列,列可以随着应用变化。
- 可以存储结构化和半结构化的数据
- 典型例子:
- HBase
- Cassandra
- Hypertable
键值对存储:
- 用一个哈希表存储数据。
- 模型简单容易部署。
- 一个键和一个指向特定数据的指针。
- 典型例子:
- Redis
- Tokyo Cabinet/Tyrant Berkeley DB
- MemcacheDB
文档存储:
- 数据模型是版本化的文档,半结构的方式来存储的。
- 内容是文档型的,可以用格式化文件:
- JSON
- XML
- 典型的例子有:
- MongoDB
- CouchDB
图形存储:
- 数据以有向加权图的方式进行存储。
- 社交关系,推荐系统,关系图谱的存储以图形存储方式最佳。
NoSQL的优点:
- 高拓展性
- 分布式计算
- 低成本
- 架构的灵活性
- 半结构化数据
- 没有复杂的关系
NoSQL的缺点:
- 没有标准化
- 有限的查询功能
- 最终一致不直观
NoSQL整体架构:
- 接口层(不同的接口):
- REST
- MapReduce
- Thrift
- …
- 数据逻辑模型层:
- Key-Value
- Column Family
- Document
- Graph
- 数据分布层:
- CAP支持
- 支持多数据中心
- 动态部署
- 数据持久层:
- 基于内存
- 接口层(不同的接口):
上下四层:不同接口,数据存储方式,数据存储要满足的特点,数据存在什么上。
列存储数据库:
- 不支持完整的关系数据模型
- 把一列中的数据值串在一起存储,然后再存储下一列。原来是按照元组,现在是按照列。
- 存储的基本单元是页,页是进行数据读取的基本单位,一次读取一次I/O操作。
键值对数据库:
- 快啊,但是只能通过键的完全一致来查询结果。
- 数据模型的体现:
- 数据结构
- 数据操作
- 数据完整性
文档数据库:
- 没有强制架构,以键值对方式的存储,支持嵌套结构
- MongoDB的数据模型:
- 文档
- 集合
- 数据库
- 文档是基本单元,集合是一组文档,数据库是一组集合。
图形数据库:
- 存储连接数据,将每个配置文件数据作为结点存储。
- 以图形的结构来存储和查询数据。
- 图形的算法有:
- 最短路径
- 可达集
- 最小生成树
- 深度优先搜索
- 广度优先搜索
- 各种搜索算法
第七章学堂在线习题:
- MongoDB分片的基本思想就是将集合切分成小块.这些块分散到若干片里面,每个片只负责总数据的一部分.应用程序不必知道
HBase , Cursor , MongoDB , Redis等补充
NoSQL:
NoSQL的重点在于分布式数据存储上嗷!!!
分布式数据库的不一致原因:
- 数据项的多个副本
- 单点网络故障
- 通信网络的故障
- 分布式提交等
在网络或其他原因,通过牺牲一定的一致性C来获得更好的性能与扩展性 -> 这就有了我们的BASE。
最终一致性是弱一致性的一种特例。
一致性的两个角度:
- 客户端关注的多并发更新过的数据如何获取
- 服务端关注如何分发罪行的数据。
NoSQL采用的技术:
- 简单数据类型
- 元数据与应用数据分离
- 弱一致性
列存储数据库:
- 列数据库则是把一列中的数据库串在一起存储起来,再存储下一列的数据,以此类推。
- 查询中的选择规则是列来定义的,列式存储数据库是自动索引化的。数据压缩比高,查询速度快!
HBASE数据库
基于列的方式对于数据进行组织嗷!!!
开源的非关系型分布式数据库,Java实现的嗷!!!
HBase的表能够作为不同任务的输入和输出,用API来存取数据
HBase建立在DFS上,提供很多性能。
列族是表的模式的一部分,列则不是,列是不需要定义的嗷!!!定义表的时候只需要指定一个表名和至少一个列族名。
区域是HBase中存储和负载均衡的最小单元,空列不占存储空间嗷!!!表中的所有行都是按照键的字典排序嗷!!!
数据模型:
- 逻辑视图是基于行键,列族,列限定符,时间版本等构成

- 表
- 行键
- 列族
- 列
- 单元:行+列族+列限定符+值+代表值版本+时间戳。单元里面的数据为单元值,行和列的交叉点为单元格,内容是列的值,二进制存储。
- 时间版本:类型为64位Long,每隔cell把偶才能多个版本
表中多有行按照行键的字典序排列(行键的重要性)
Table在行上被分为多个区域。
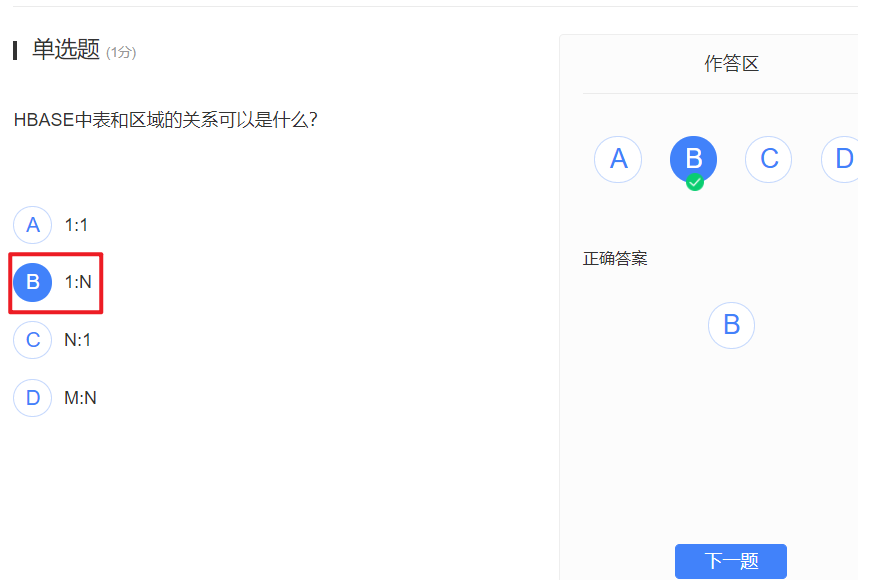
Region大小分割,Region达到阈值就会分为两个新的region
Region是HBase中分布式存储和负载均衡的最小单元,不同的Region分布在不同的RegionServer上。
Table在行上分割为多个Region , 每隔Region存储着若干行,Region中以列族为单位的单元,Store由MemStore和0至多个StoreFile组成。
StoreFile的重点关系:
- table和Region的关系:一对多
- Region和Store的关系:一对多
- Store和HFile的关系:一对多
键值对数据库:
- key-value存储模型是NoSQL中最基本的数据存库模型。
Redis数据库
- 数据模型:
- 数据结构:字典模型
- 数据操作:Get , Set , Delete
- 数据完整性,单个键才区别一致性
- Redis:
- 内存数据库。
- Key-Value键值对,存储模型是NoSQL中最基本的数据存储模型,KV类似于哈希表,在键和值之间可以建立映射关系。
- 支持的数据类型:
- 字符串类型
- 哈希表类型
- 链表类型
- 集合类型
- 有序集合类型
- 缺点是数据库容量受到物理内存的限制,单个值的最大限制是1GB。
- List是用来做FIFO双向链表可实现的轻量级的高性能信息队列服务。
- Redis的每个数据库中的所有数据都是Key-Value对,底层都是二进制字节数组的格式存放。空字符串对于Redis也是有效的key值。
- String:
- String是二进制安全的,可以包含任何数据。
- 具有定时持久化等功能。
- List:
- 列表是数组的简单的字符串列表,有lpush , rpush , lpop , rpop , lrange等。
- 双端都有prev , next指针,获取前置和后置的算法复杂度都为O(1)。
- 无环
- 带链表长度计数器
- 多态
- Hash:
- String类型的field和value的映射表,常用命令有hget , set , hgetall等
- 将用户ID作为查找key , 其他信息封装为对象以虚拟化的方式存储。用户信息对象中所有成员都存成单个的key-value对,来使用。
- Set:
- Redis中的集合是string类型一个无序,去重的集合。元素是字符串类型
- set自动重拍,数据不重复
- 内部是value永远为null的Hash
- zset:
- 类似于Set集合,有序的,去重的,元素是字符串类型,不允许重复的成员。
- 数据库数组:
- Redis中本质上是一个字典dict,又称为符号表或者映射,这样来找数据。
- Rehash过程:
- 创建一个新的哈希表,大小是当前的2的幂次,然后把所有的key重新散列到新的哈希表中。
- 内部默认16个数据库,用select命令来切换数据库。
- 简化数据结构和算法的实现,通过异步IO和pipelining等机制来实现高速的并发访问。
- Redis复制主要包括RDB复制和AOF复制,RDB快照方式,AOF通过将发送到服务器的写操作命令记录下来,形成AOF文件。
文档型数据库:
- 文档可以很长很复杂无结构
- 文档进行自我描述,如XML , HTML和JSON
- 嵌入式文档
- 每个文档的id就是它唯一的键,检索排序的ID性能好,ID在一个数据库集合中。
MongoDB数据库
- 基本的概念是文档,集合,数据库
- 文档是MongoDB中的基本单元
- 层次关系:
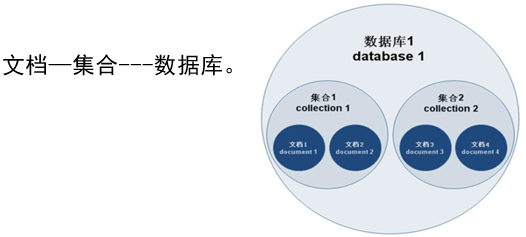
多个键及其关联的值有序放在一起就是文档,文档是一组键值对。文档不需要设置相同的字段,相同的字段不需要相同的数据类型。
文档中的值可以多种多样,甚至是嵌入整个文档。
MongoDB文档不能有重复的键,文档的键是字符串,值可以是多种多样的。
Collection:
- 一组相关文档放在一起
- system是一个集合,不是数据库哈,是每个数据库中自带的存放元数据的集合。
- 元数据的集合collection,<dbname>.system.*是包含多种系统信息的特殊集合。
- 包含:
- system.namespace
- system.indexes
- system.profile
- system.users
- local.sources
数据库database:
- 多个文档组成的集合,数据库由多个集合组成。
- 数据库之间相互独立。
- 同一种业务类型的数据放在同一个数据库中。磁盘上,不同数据库存放在不同文件中。
- 系统数据库:
- admin
- local
- config
文档是MongoDB中数据的基本单元,集合可以被看作是没有模式的表。MongoDB每个实例可以容纳多个独立的数据库,每个数据库由自己独立的权限。
Document -> Collection -> Database -> 一个实例支持多个DB
Mongo应用场景:
- 网站数据
- 缓存
- 大尺寸,低机制的数据
- 高伸缩场景
- 用于对象以及JSON数据的存储。
不适用于:
- 高度事务性的系统
- ACID
- 需要SQL的问题
图形数据库:
- 起源于欧拉和图理论,面向于图的数据库
- 图数据库可处理大量的、复杂的、互联的、多变的网状数据,适用于社交网络、实时推荐、银行交易环路、金融征信系统等广泛的领域。
- 图模型:
- 邻接表
- 邻接矩阵
- 如果实体间有多种关系,就需要创建多个关联表。
Neo4J图形数据库
将结构化的数据存储到网络上,可以提供完全的事务特性嗷!!!
Neo4J图形数据库是开源的使用Java实现的图数据库,运行方式有:
- 服务的方式,对外提供REST接口
- 嵌入式模式,数据以文件的形式存放在本地,直接对本地文件进行操作。
Neo4J是一个高性能的NoSQL属性数据库,结构化数据存储在网络中。高性能图引擎。
查询语言名字为Cypher , 不适用schema,可以满足任何形式的需求。
数据模型:
- 实体
- 关系
- 标签:用于结点进行分组,相当于结点的类型。拥有相同标签的节点属于同一个分组。
- 属性:一个键值对,用于为节点或关系提供信息,每个结点都由name属性,用于属性节点。
- 遍历
存储结构核心概念:
- Nodes(节点)图的基本单位节点和关系,都可以包含属性。
- Relationships(关系)组织和连接节点,一个开始节点和一个结束节点,关系有方向进和出。
- Properties(属性),某个节点的一些属性啊之类啊,可以有一个或者多个。
- Labels(标签),一个节点可以有多个类型,给属性建立索引和约束的时候也会用到。(约束)
- Traversal(遍历),找路径用的嗷!!!一个开始节点,遍历相关路径上的节点和关系,得到最终结果。
- Paths(路径),一个或者多个节点通过关系连接起来的产物。
结构化的数据存储在网络上而不是表格中。基本数据类型:Nodes(结点),Relationships(关系),包含键值对属性,Nodes通过Relationships和所定义的关系相连。
实体指的是结点和关系嗷!!!实体有唯一一个ID , 有0到多个属性,属性键是唯一的嗷。每个结点都有0个,1个或者多个标签。
标签用于给节点分类,一个结点可以有多个标签嗷!!!
Neo4j使用的时候不需要定义任何的模式嗷!索引很重要,因为图的读写很多嗷!约束是定义在某个字段上的,限制字段值为唯一值。创建约束会自动创建索引!!!
图形物理存储结构(5种文件):
- 存储结点文件
- 存储关系文件
- 存储标签文件
- 存储属性文件
- 其他文件
Neo4j中四类使用数组的典型的存储结构:
- 四类结点,属性,关系等文件。数组作为核心存储结构,对于结点,属性,关系等类型的每个数据项都会分配一个唯一的id。
- 一个结点9个字节,一个关系(双向链表)33个字节,一个属性41个字节(固定大小,最多容纳四个属性)。
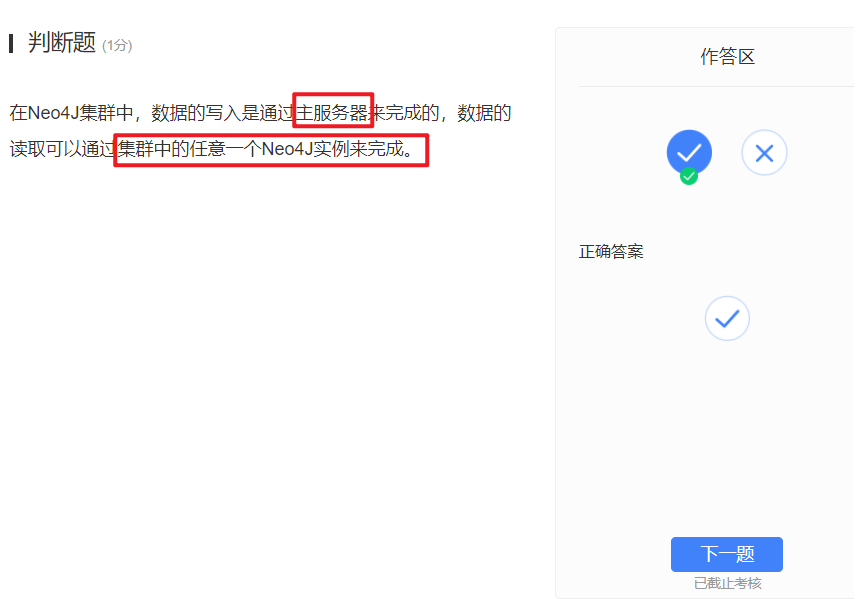
一主多从,主一般负责写,写完就同步到所有从服务器。从服务器处理只读操作,不写嗷!!!主写完之后,同步到所有的从,主也可以负载读嗷!!!每一个服务器都有所有的数据!!!写的过程和异步更新的过程,都是事务执行的过程嗷!!!
Neo4j内有一个写队列,用于缓存数据库的写入操作。
数据的读取可以通过集群中的任意一个Neo4j实例来完成嗷!!!
组成集群管理原则:
- 负责同步各个实例的状态
- 失效的结点少于集群结点个数的一半,则该集群只接收读取操作!!!
Summary:
- DBMS是爹,谁都要用DBMS才能操作DB
- 我们学的这几个里面只有Oracle,Sybase,DB2是企业级数据库嗷!!!
- 关系模式本质上就是后面这个标准表示关系用的,TUZI(TuziName , TuziAge) ,如果是主键下面还要加上横线嗷!!!表名如果多个值,那就是 RELATION_NAME(Column01 , Column02 , … , LastColumn)。如果是外键的话,关系模式语句中必须采用斜体表示。
- 传统集合运算不是乱运算,是给了背景条件的嗷!!!
- theta连接的theta本质上表示的是数值比较的运算符!!!
- 主键的任意一个属性都不能为空!!!!!
- PostgreSQL中,单引号表示字符串,双引号表示变量嗷QAQ!!!
- 见书上P64!!!
- update和set一起使用嗷!!!
- 升序就是从小到大的排列的意思,降序就是从大到小的排列的意思。
- DQL那里好好去看下哈,有些不清楚的嗷!!!
- 注意哈,group by的结果一般是要在select里面出现的嗷,你想想嘛,group by的出现就是为了“分组”,而查询中一般都会出现所谓的“组别”,这样才能体现你分组的作用嘛。一般先分组再进行统计,所以分组的组别一般需要嗷!!!
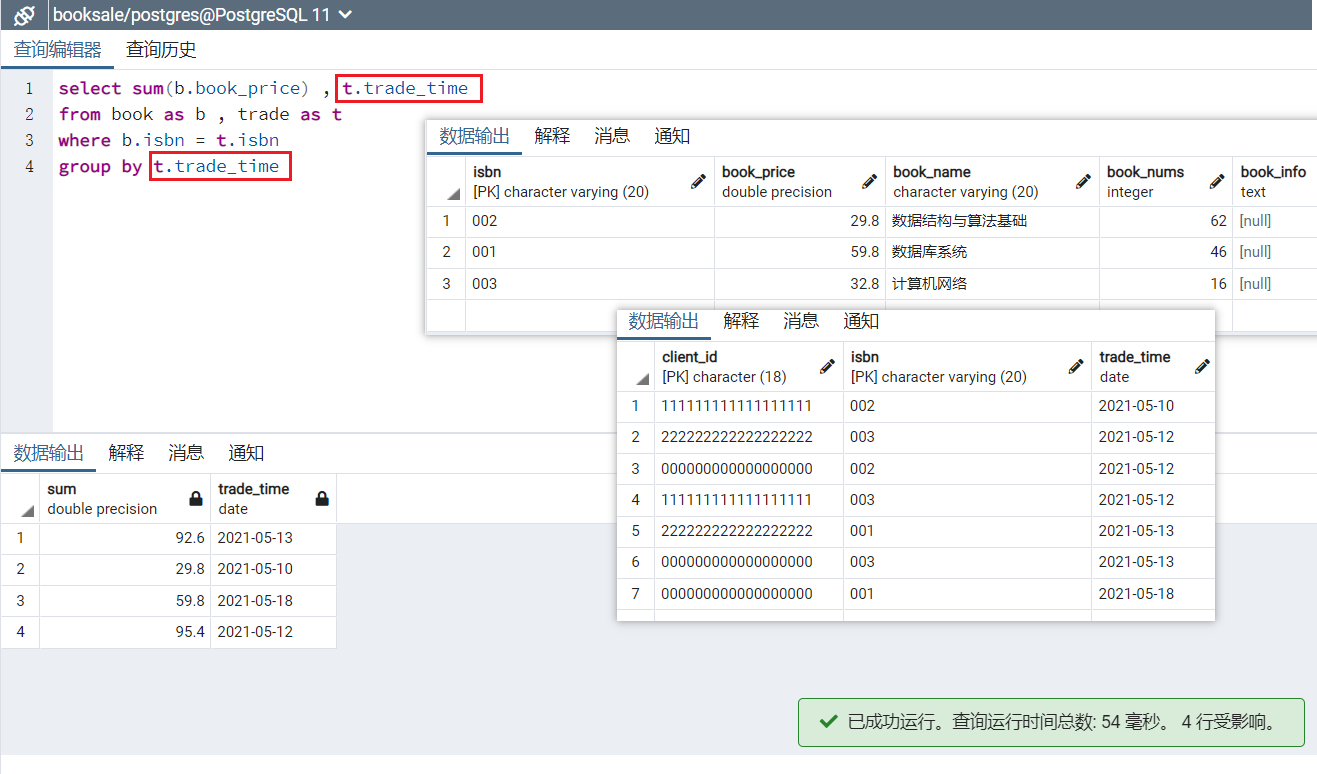
上面这个,查询不同日期的销售额。多表连接查询,两张表连接的条件为b.isbn = t.isbn。 from -> where -> group by -> 聚合函数的使用 -> select -> order by
一对一:至多有一个,多对多:至少有一个。
P113完整非完整,互斥非互斥的表示嗷!!!
函数依赖理论P131
高级范式包含了低级范式的全部要求
凡是类似于表啊,存储过程啊,存储方案啊,这些和数据库DBMS实现相关的,统统都在PDM实现。
注意哈,范式的升级一定要前一个范式+本范式的条件,单独一个不得行的嗷!!!
DBMS的架构和DB的架构比起来少了一个操作界面层,DBMS架构 + 操作界面层 = DB架构
并发控制问题和问题解决有点麻烦哈,记得下去看一看嗷!!!
加锁和事务隔离级别都要康康嗷!!!
数据库中,超级用户(admin)拥有系统最高权限,可以对于其他用户和角色进行管理。数据库拥有者(DBO)则拥有其所拥有的对象的全部权限,普通user只是具有被赋予的数据库访问操作权限嗷!!!
完全备份一周一次,差异备份一天一次,事务备份一直都在。所以,完全备份+差异备份+事务备份才能完全恢复数据库嗷!!!
PostgreSQL数据库没有为创建存储过程提供专用命令,而是通过创建数据库函数来实现存储过程的功能,后面将PostgreSQL的函数和存储过程统称为存储过程。但是如果问如何创建存储过程而不指定数据库的话,create procedure才是对的嗷!!!
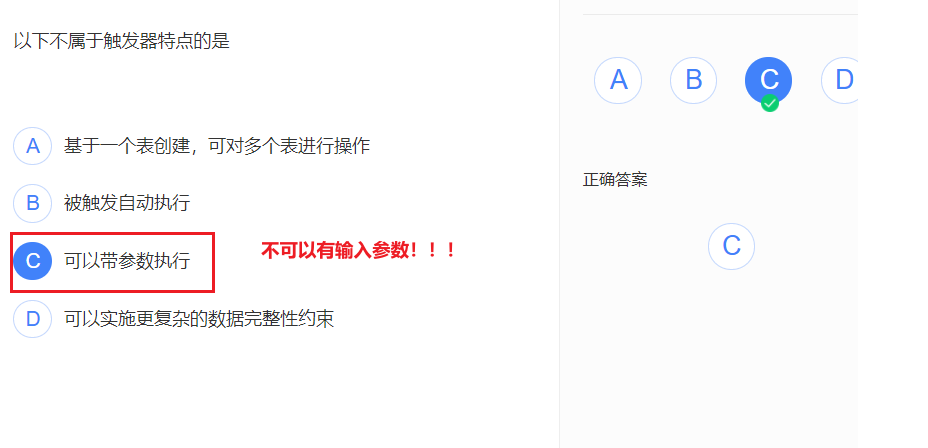
触发器不可以有输入的参数,存储过程可以有嗷!!!
NoSQL理论基础还是要康康的嗷!!!
最后一章给我去看看书嗷!!!!!!
企业级DBMS——适用于中大型的企业级应用,如DB2、ORACLE Database、Sybase ASE等
数据库 -> 数据模型 : 数据结构,数据操作,数据约束 -> 有哪些?层次,网状,关系等
数据库系统由用户、数据库应用程序、数据库管理系统和数据库四个部分组成。
关系(relation)——是指具有关系特征、用于存放实体数据的二维表。
关系是指在集合域 D1、…、Dn 上运算笛卡儿积的有意义子集。
代理键可替代复合主键,以便获得更高性能的数据访问操作处理。它的值对用户没有任何意义,通常需要在表单或报表中隐藏它们。
关系模型(Relation Model)——是一种基于二维表结构存储数据实体及实体间联系的数据模型。
专门的关系运算:选择,投影,连接,除运算。
参照完整性约束来说的话,一般就是外键要对应另外一张表中的主键嗷!!!
SQL语言非过程化,它是结构化的语言,而不是过程化的语言嗷!!!
SQL语言基本数据类型:
字符:CHAR、VARCHAR、TEXT
整数:SMALLINT、INTEGER
浮点数:NUMBER(n,d)、FLOAT(n,d)
日期:DATE、DATETIME
货币:MONEY
between … and … , like(%和_)

CourseType varchar(10) NULL CHECK(CourseType IN('基础课','专业课','选修课')),SQL聚合函数可以单独使用,与之对应的,select后面的属性必须要和group by成对出现使用嗷!!!


- 除了GROUP BY语句外,列的名称是不允许和聚合函数一起混合使用,DBMS产品在使用聚合函数的方式也不一样。一般来说,聚合函数是不能用于WHERE子句中的。
- 三种模型出发点:
- 概念数据模型(Concept Data Model,CDM)是一种面向用户的系统数据模型。用户角度
- 逻辑数据模型 (Logic Data Model,LDM)是在概念数据模型基础上,从系统设计角度描述系统的数据对象组成及其关联结构,并考虑这些数据对象符合数据库对象的逻辑表示。系统分析员角度
- 物理数据模型(Physical Data Model,PDM)是在逻辑数据模型基础上,针对具体DBMS所设计的数据模型。系统设计人员角度
- E-R模型中的主键对应的属性下面要加上下划线嗷!!!
- CDM / LDM -> PDM:
- 将实体之间的联系转化为关系表之间的参照完整性约束
- 事务例子:

二级加锁协议:在一级加锁协议基础上,针对并发事务的共享数据读操作,必须对该数据执行共享锁定指令,读完数据后即刻释放共享锁定。
在一级加锁协议基础上,针对并发事务对共享数据进行读操作,必须对该数据执行共享锁定指令,直到该事务处理结束才释放共享锁定。
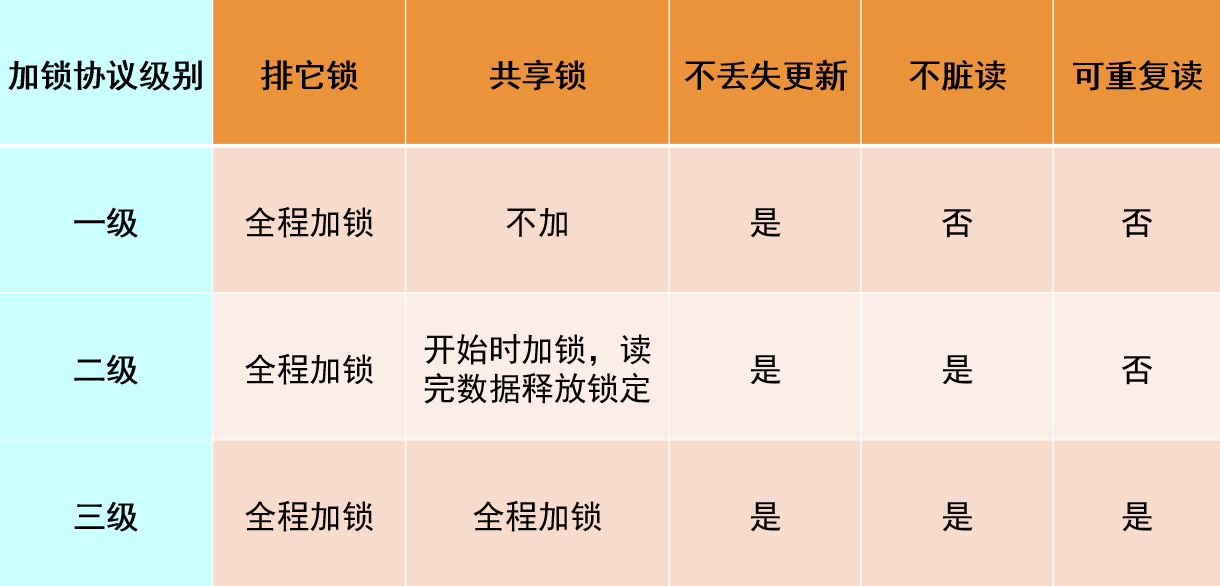
注意上表,幻像读不在里面哈,幻想表对应的表级的锁,其他的对应的则是行级锁嗷!!!
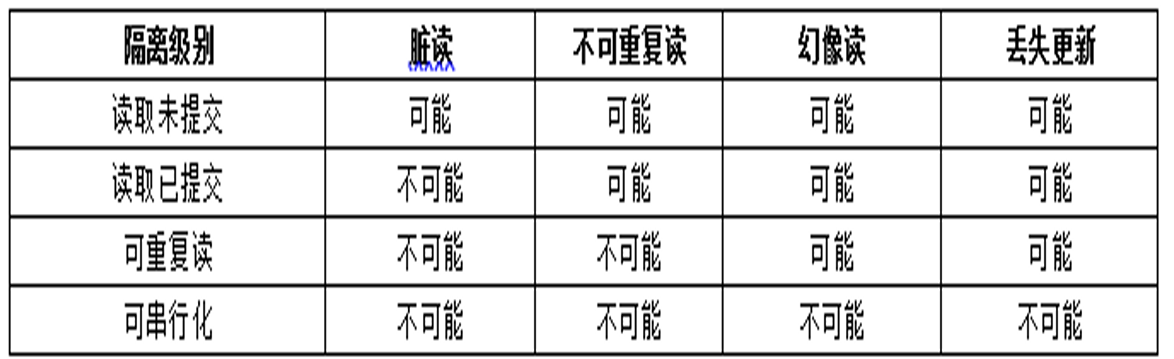
注意康康嗷!!!
备份角色——可以是服务器管理员(sysadmin)、数据库所有者(db_owner)、数据库备份员(db_backupoperator)角色之一。
应用程序使用ODBC访问数据库的步骤:
①首先必须用ODBC管理器注册一个数据源;(有点像Java中的.Driver,就是保存响应驱动的信息的)
②管理器根据数据源提供的数据库位置、数据库类型及ODBC驱动程序等信息,建立起ODBC与具体数据库的联系;
③应用程序只需将数据源名提供给ODBC,ODBC就能建立起与相应数据库的连接;
④这样,应用程序就可以通过驱动程序管理器与数据库交换信息;
⑤驱动程序管理器负责将应用程序对ODBC API的调用传递给正确的驱动程序;
⑥驱动程序在执行完相应的SQL操作后,将结果通过驱动程序管理器返回给应用程序

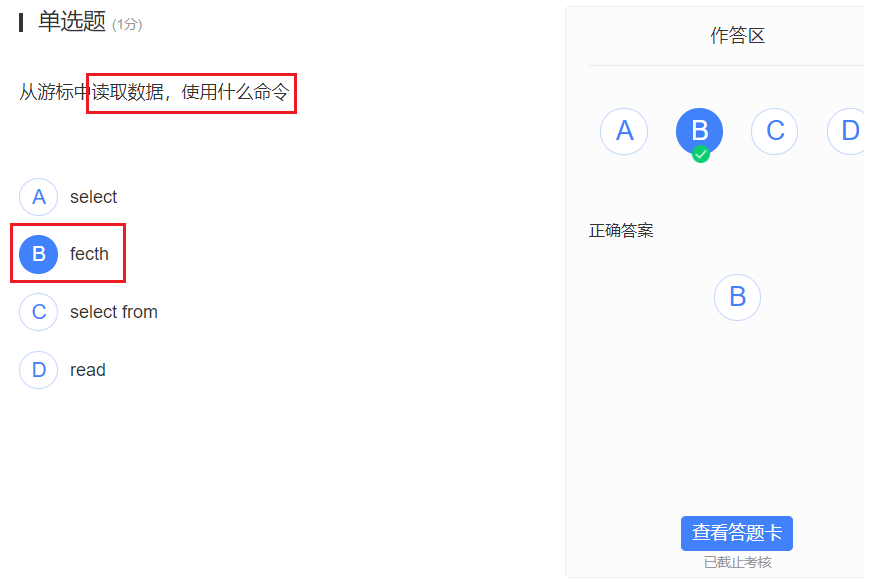
如果不关心countRecords()的返回值,则可用**PERFORM **countRecords() 代替
RECORD不是真正的数据类型,只是一个占位符
存储过程中:


值的初始化:
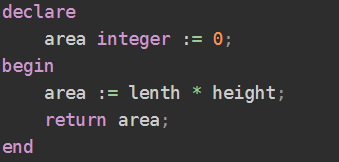
- 触发器是事务的一部分,不能直接调用,也不能传递或接受参数。
- FOR EACH STATEMENT,一个事务就执行一次,就算没有改表中的数据也会执行。FOR EACH ROW,每变化一行就会执行一次触发器。
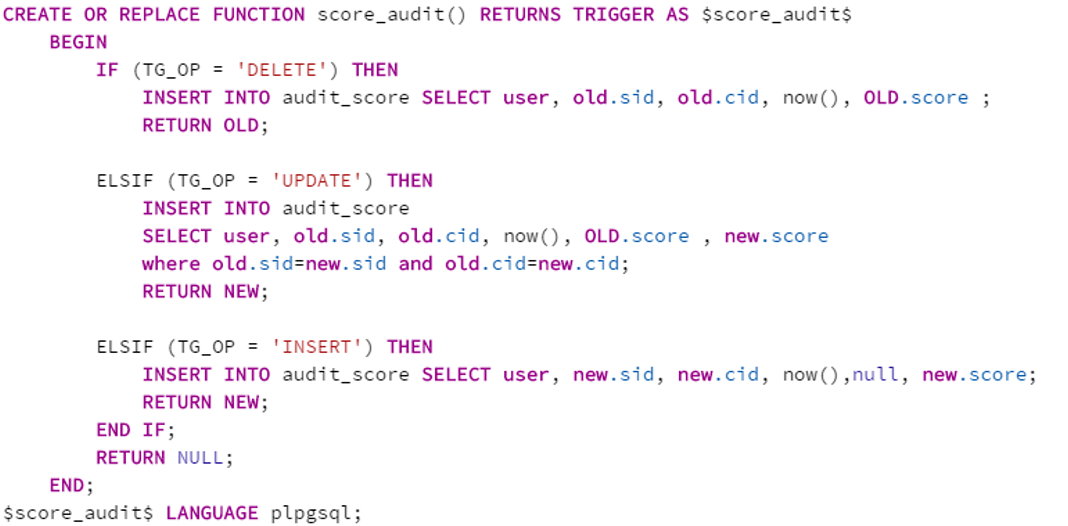

- 游标就离谱:

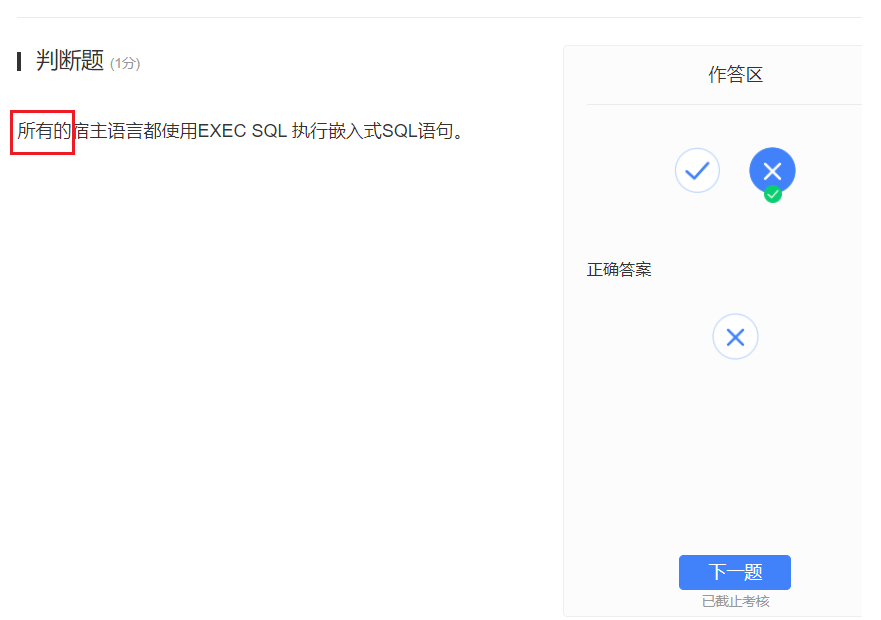
为了使程序语言同时具有它的优点,在JAVA、C/C++等高级语言中嵌入SQL语句,称高级语言为宿主语言。说白了就是SQL在高级语言中的使用而已嘛orz。
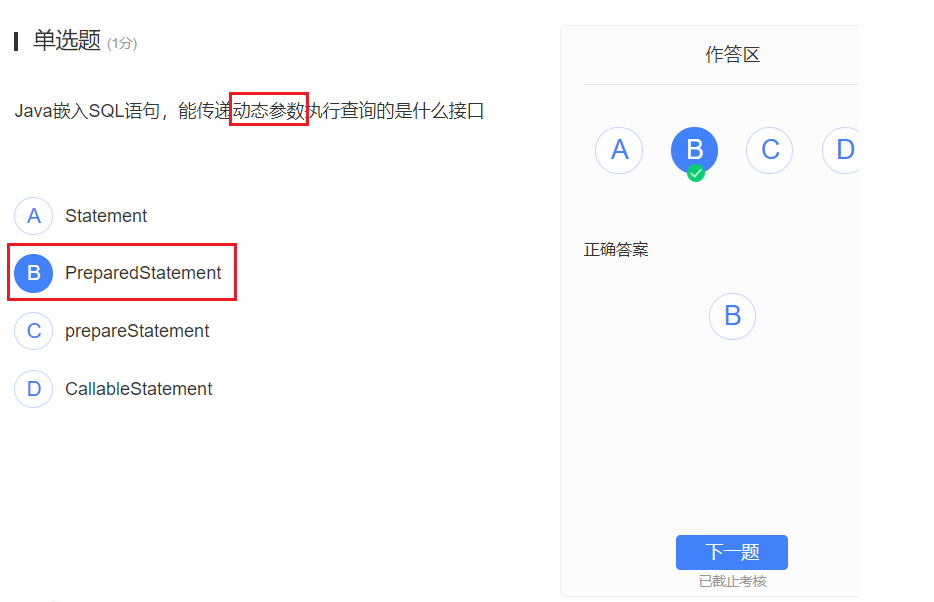
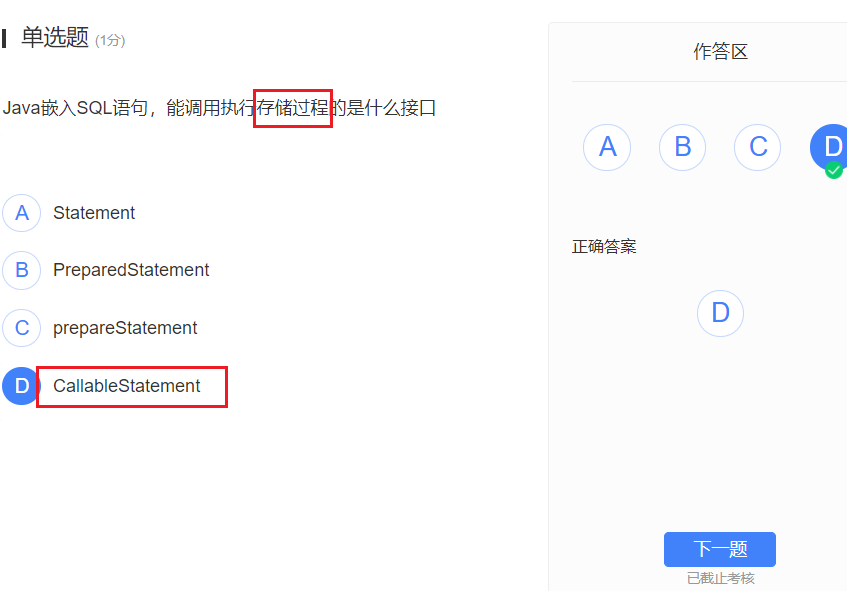
Java语言嵌入式SQL:
Class.forName(“org.postgresql.Driver”)
DriverManager.getConnection(String url, String user, String pwd)
Connection:
- createStatement()
- prepareStatement(sql)
- prepareCall(sql)
execute:
- execute()
- executeQuery()
- executeUpdate()
ResultSet():
- next()
- getString()
addBatch() , executeBatch()
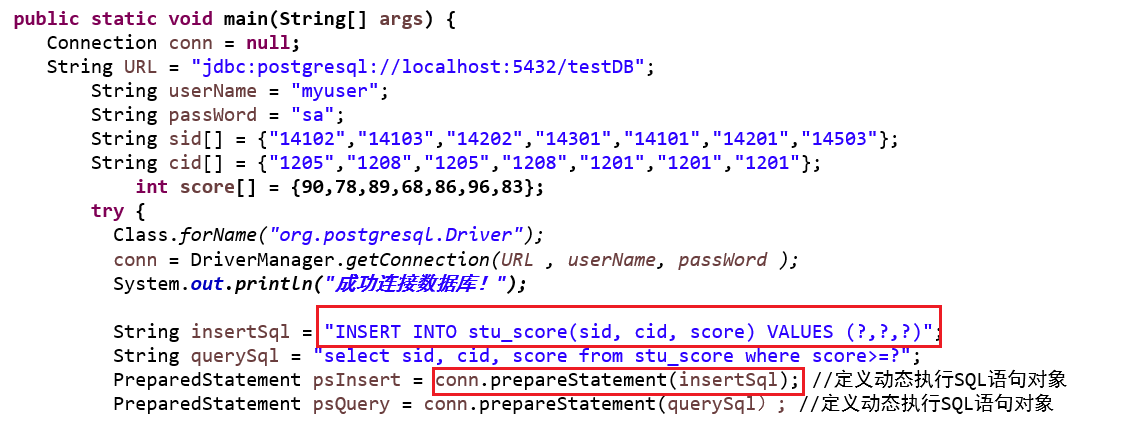



三级加锁协议能解决幻象读????好像不可以嗷!!!
Redis使用内存提供主存储支持。Redis是内存数据库嗷!!!
MongoDB文档不能有重复的键。文档的键是字符串。文档中的值不仅可以是字符串,也可以是其他数据类型(或者嵌入其他文档)
LDM才有fi嗷,CDM只有pi,记得要写一下嗷QAQ!!!