HuggingFace-NLP-Course
本文最后更新于:5 个月前
新坑来自于自己的浅薄,在从洛阳回北京的动车上,李老师给我推荐了这个HuggingFace教程。尽量不大篇幅记录,记录笔记,对有感触和自己认为有价值的地方多驻足。这个项目从我的视角来看,和实践结合会更加紧密,对我来说有很多价值!
Environment Setup
- Anaconda
- Conda create一个环境,并且
pip install transformers。
Transformer Model
Introduction
- 主要内容:Transformers、Datasets、Tokenizers 和 Accelerate——以及 Hugging Face Hub 教你自然语言处理 (NLP)。
- 课程设置:
- 第 1 章到第 4 章介绍了 Transformers 库的主要概念。在本课程的这一部分结束时,您将熟悉 Transformer 模型的工作原理,并将了解如何使用 Hugging Face Hub 中的模型,在数据集上对其进行微调,并在 Hub 上分享您的结果。
- 第 5 章到第 8 章在深入研究经典 NLP 任务之前,教授 Datasets和 Tokenizers的基础知识。在本部分结束时,您将能够自己解决最常见的 NLP 问题。
- 第 9 章到第 12 章更加深入,探讨了如何使用 Transformer 模型处理语音处理和计算机视觉中的任务。在此过程中,您将学习如何构建和分享模型,并针对生产环境对其进行优化。在这部分结束时,您将准备好将 Transformers 应用于(几乎)任何机器学习问题!

Transformer Usage
常见NLP任务:对整个句子进行分类,对句子中的每个词进行分类,生成文本内容,从文本中提取答案,从输入文本生成新句子。NLP 不仅限于书面文本。它还解决了语音识别和计算机视觉中的复杂挑战,例如生成音频样本的转录或图像描述。Transformer就是广泛用于NLP领域的一个模型。Some of the currently available pipelines are:
Transformers 库中最基本的对象是 pipeline() 函数。它将模型与其必要的预处理和后处理步骤连接起来,使我们能够通过直接输入任何文本并获得最终的答案:
Single Sentence
1
2
3
4
5
6from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier("I've been waiting for a HuggingFace course my whole life.")
# Result: [{'label': 'POSITIVE', 'score': 0.9598047137260437}]Multi Sentences
1
2
3
4
5classifier(
["I've been waiting for a HuggingFace course my whole life.", "I hate this so much!"]
)
# Result: [{'label': 'POSITIVE', 'score': 0.9598047137260437},{'label': 'NEGATIVE', 'score': 0.9994558095932007}]默认情况下,此pipeline选择一个特定的预训练模型,该模型已针对英语情感分析进行了微调。创建classifier对象时,将下载并缓存模型。如果您重新运行该命令,则将使用缓存的模型,无需再次下载模型。
将一些文本传递到pipeline时涉及三个主要步骤:
- 文本被预处理为模型可以理解的格式。
- 预处理的输入被传递给模型。
- 模型处理后输出最终人类可以理解的结果。
Some of the currently available pipelines are:
feature-extraction(get the vector representation of a text)fill-maskner(named entity recognition)question-answeringsentiment-analysissummarizationtext-generationtranslationzero-shot-classification
下面是一些Demo
Zero-shot classification
我们将首先处理一项非常具挑战性的任务,我们需要对尚未标记的文本进行分类。zero-shot-classification pipeline非常强大:它允许您直接指定用于分类的标签,因此您不必依赖预训练模型的标签。下面的模型展示了如何使用这两个标签将句子分类为正面或负面——但也可以使用您喜欢的任何其他标签集对文本进行分类。
1
2
3
4
5
6
7
8
9from transformers import pipeline
classifier = pipeline("zero-shot-classification")
classifier(
"This is a course about the Transformers library",
candidate_labels=["education", "politics", "business"],
)
# Result: {'sequence': 'This is a course about the Transformers library', 'labels': ['education', 'business', 'politics'], 'scores': [0.8445963859558105, 0.111976258456707, 0.043427448719739914]}此pipeline称为zero-shot,因为您不需要对数据上的模型进行微调即可使用它。它可以直接返回您想要的任何标签列表的概率分数!
Text generation
主要使用方法是您提供一个提示,模型将通过生成剩余的文本来自动完成整段话。这类似于许多手机上的预测文本功能。文本生成涉及随机性,因此如果您没有得到相同的如下所示的结果,这是正常的。
1
2
3
4
5
6from transformers import pipeline
generator = pipeline("text-generation")
generator("In this course, we will teach you how to")
# Result: [{'generated_text': 'In this course, we will teach you how to understand and use data flow and data interchange when handling user data. We will be working with one or more of the most commonly used data flows — data flows of various types, as seen by the HTTP}]您可以使用参数 num_return_sequences 控制生成多少个不同的序列,并使用参数 max_length 控制输出文本的总长度。
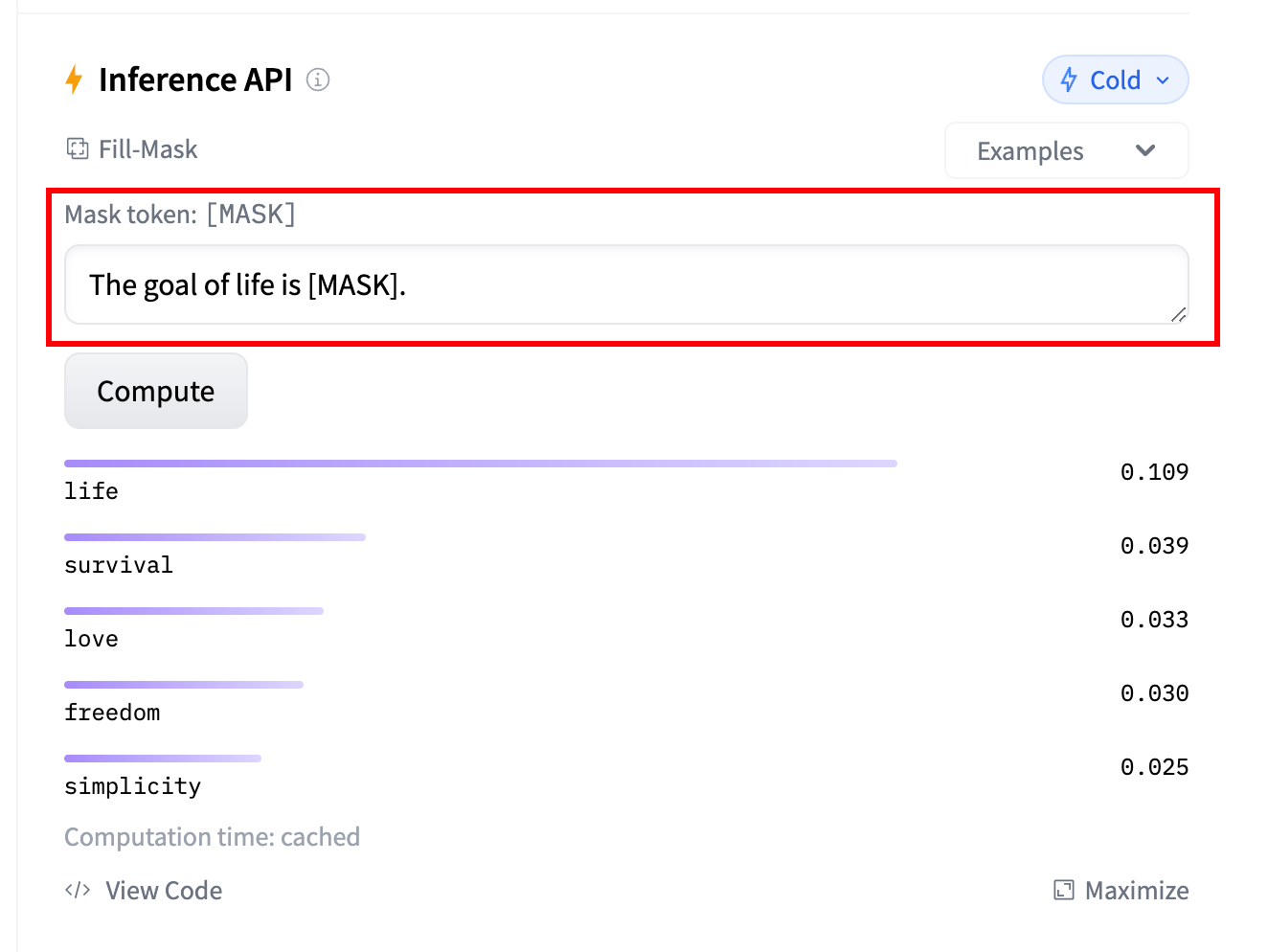
Mask filling
此任务的想法是填充给定文本中的空白,
1
2
3
4
5
6from transformers import pipeline
unmasker = pipeline("fill-mask")
unmasker("This course will teach you all about <mask> models.", top_k=2)
# Reuslt: [{'sequence': 'This course will teach you all about mathematical models.','score': 0.19619831442832947,'token': 30412,'token_str': ' mathematical'}, {'sequence': 'This course will teach you all about computational models.', 'score': 0.04052725434303284, 'token': 38163, 'token_str': ' computational'}]top_k 参数控制要显示的结果有多少种。请注意,这里模型填充了特殊的< **mask** >词,它通常被称为掩码标记。其他掩码填充模型可能有不同的掩码标记,因此在探索其他模型时要验证正确的掩码字是什么。检查它的一种方法是查看小组件中使用的掩码。
Named entity recognition
命名实体识别 (NER) 是一项任务,其中模型必须找到输入文本的哪些部分对应于诸如人员、位置或组织之类的实体。
1
2
3
4
5
6from transformers import pipeline
ner = pipeline("ner", grouped_entities=True)
ner("My name is Sylvain and I work at Hugging Face in Brooklyn.")
# result [{'entity_group': 'PER', 'score': 0.99816, 'word': 'Sylvain', 'start': 11, 'end': 18},{'entity_group': 'ORG', 'score': 0.97960, 'word': 'Hugging Face', 'start': 33, 'end': 45}, {'entity_group': 'LOC', 'score': 0.99321, 'word': 'Brooklyn', 'start': 49, 'end': 57}]pipeline创建函数中传递选项 grouped_entities=True 以告诉pipeline将对应于同一实体的句子部分重新组合在一起:这里模型正确地将“Hugging”和“Face”分组为一个组织,即使名称由多个词组成。事实上,正如我们即将在下一章看到的,预处理甚至会将一些单词分成更小的部分。例如,Sylvain 分割为了四部分:S、##yl、##va 和 ##in。在后处理步骤中,pipeline成功地重新组合了这些部分。
Question answering
问答pipeline使用来自给定上下文的信息回答问题:
1
2
3
4
5
6
7
8
9from transformers import pipeline
question_answerer = pipeline("question-answering")
question_answerer(
question="Where do I work?",
context="My name is Sylvain and I work at Hugging Face in Brooklyn",
)
# Result {'score': 0.6385916471481323, 'start': 33, 'end': 45, 'answer': 'Hugging Face'}此pipeline通过从提供的上下文中提取信息来工作;它不会凭空生成答案。
Summarization
文本摘要是将文本缩减为较短文本的任务,同时保留文本中的主要(重要)信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28from transformers import pipeline
summarizer = pipeline("summarization")
summarizer(
"""
America has changed dramatically during recent years. Not only has the number of
graduates in traditional engineering disciplines such as mechanical, civil,
electrical, chemical, and aeronautical engineering declined, but in most of
the premier American universities engineering curricula now concentrate on
and encourage largely the study of engineering science. As a result, there
are declining offerings in engineering subjects dealing with infrastructure,
the environment, and related issues, and greater concentration on high
technology subjects, largely supporting increasingly complex scientific
developments. While the latter is important, it should not be at the expense
of more traditional engineering.
Rapidly developing economies such as China and India, as well as other
industrial countries in Europe and Asia, continue to encourage and advance
the teaching of engineering. Both China and India, respectively, graduate
six and eight times as many traditional engineers as does the United States.
Other industrial countries at minimum maintain their output, while America
suffers an increasingly serious decline in the number of engineering graduates
and a lack of well-educated engineers.
"""
)
# Result [{'summary_text': ' America has changed dramatically during recent years . The number of engineering graduates in the U.S. has declined in traditional engineering disciplines such as mechanical, civil , electrical, chemical, and aeronautical engineering . Rapidly developing economies such as China and India, as well as other industrial countries in Europe and Asia, continue to encourage and advance engineering .'}]与文本生成一样,您指定结果的 max_length 或 min_length。
Translation
对于翻译,如果您在任务名称中提供语言对(例如“translation_en_to_fr”),则可以使用默认模型,但最简单的方法是在模型中心(hub)选择要使用的模型。
1
2
3
4
5
6from transformers import pipeline
translator = pipeline("translation", model="Helsinki-NLP/opus-mt-fr-en")
translator("Ce cours est produit par Hugging Face.")
# Result [{'translation_text': 'This course is produced by Hugging Face.'}]与文本生成和摘要一样,您可以指定结果的 max_length 或 min_length。
Using any model from the Hub in a pipeline
您也可以从 Hub 中选择特定模型以在特定任务的pipeline中使用 - 例如,文本生成。转到模型中心(hub)并单击左侧的相应标签将会只显示该任务支持的模型。 distilgpt2 模型为例子
1
2
3
4
5
6
7
8
9
10from transformers import pipeline
generator = pipeline("text-generation", model="distilgpt2")
generator(
"In this course, we will teach you how to",
max_length=30,
num_return_sequences=2,
)
# Result: [{'generated_text': 'In this course, we will teach you how to manipulate the world and move your mental and physical capabilities to your advantage.'}, {'generated_text': 'In this course, we will teach you how to become an expert and practice realtime, and with a hands on experience on both real time and real'}]可以从网站上找到对应的使用代码:
模型页面:
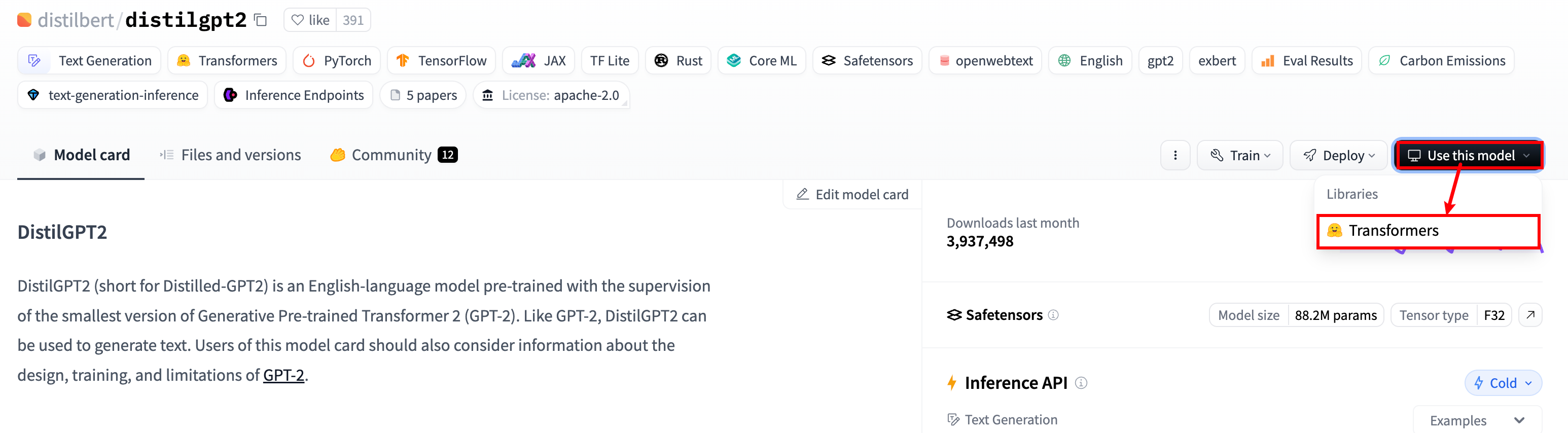
模型使用代码:
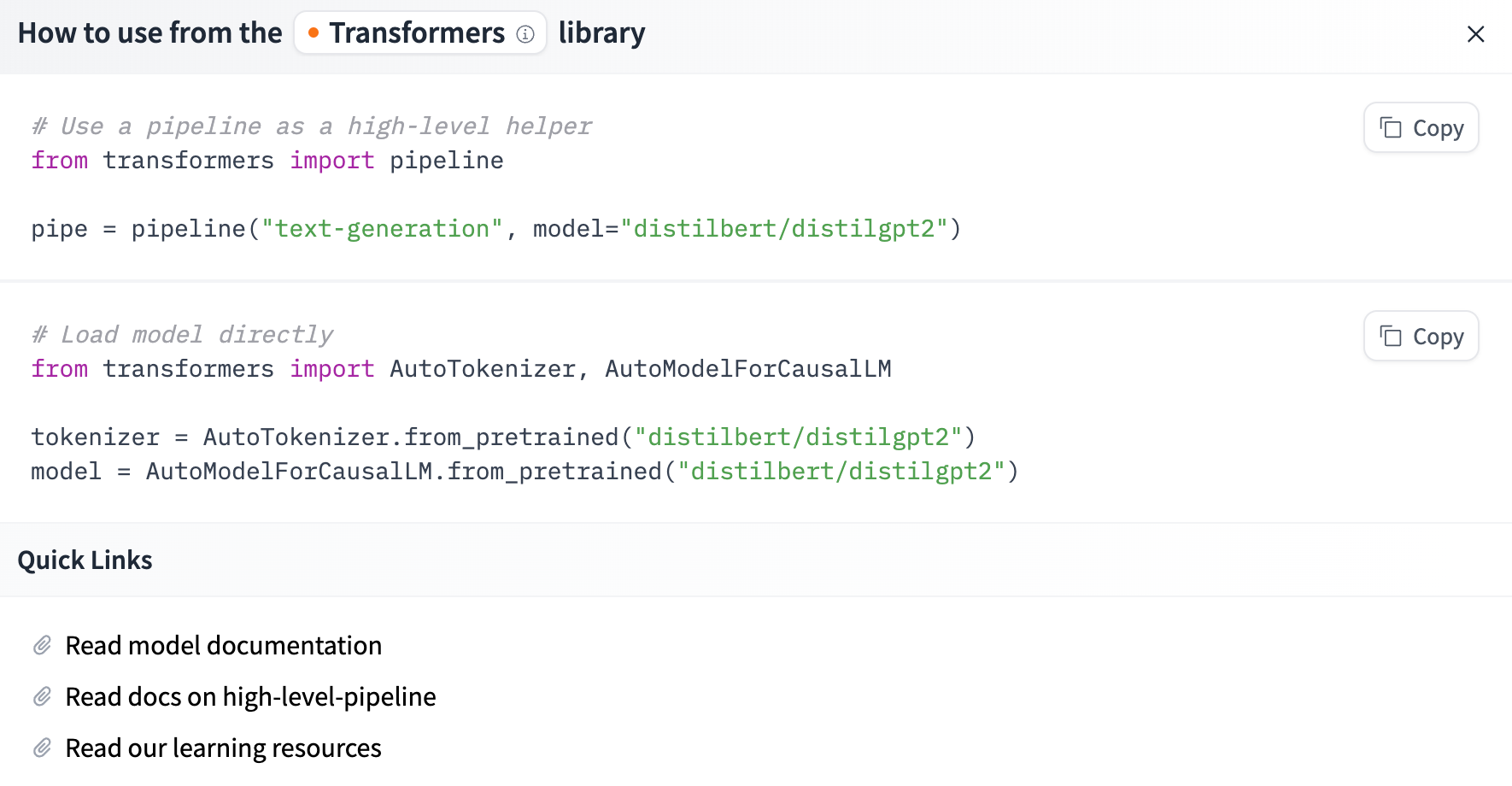
The Inference API:所有模型都可以使用 Inference API 直接通过浏览器进行测试,该 API 可在 Hugging Face 网站上找到。通过输入自定义文本并观察模型的输出,您可以直接在此页面上使用模型。小组件形式的推理 API 也可作为付费产品使用,如果您的工作流程需要它,它会派上用场。有关更多详细信息,请参阅定价页面。
How Transformer Work
以下是 Transformer 模型(简短)历史中的一些关键节点:
Development Graph for Transformer

Transformer 架构 于 2017 年 6 月推出。原本研究的重点是翻译任务。随后推出了几个有影响力的模型,包括
2018 年 6 月: GPT, 第一个预训练的 Transformer 模型,用于各种 NLP 任务并获得极好的结果
2018 年 10 月: BERT, 另一个大型预训练模型,该模型旨在生成更好的句子摘要(下一章将详细介绍!)
2019 年 2 月: GPT-2, GPT 的改进(并且更大)版本,由于道德问题没有立即公开发布
2019 年 10 月: DistilBERT, BERT 的提炼版本,速度提高 60%,内存减轻 40%,但仍保留 BERT 97% 的性能
2019 年 10 月: BART 和 T5, 两个使用与原始 Transformer 模型相同架构的大型预训练模型(第一个这样做)
2020 年 5 月, GPT-3, GPT-2 的更大版本,无需微调即可在各种任务上表现良好(称为零样本学习)
大体上,它们可以分为三类:
GPT-like (也被称作自回归Transformer模型, Decoder)
BERT-like (也被称作自动编码Transformer模型, Encoder)
BART/T5-like (也被称作序列到序列的 Transformer模型, Encoder + Decoder)
Transfer Learning


- 预训练通常是在非常大量的数据上进行的。因此,它需要大量的数据,而且训练可能需要几周的时间。 另一方面,微调是在模型经过预训练后完成的训练。要执行微调,首先需要获取一个经过预训练的语言模型,然后使用特定于任务的数据集执行额外的训练。等等,为什么不直接为最后的任务而训练呢?有几个原因:
- 预训练模型已经在与微调数据集有一些相似之处的数据集上进行了训练。因此,微调过程能够利用模型在预训练期间获得的知识(例如,对于NLP问题,预训练模型将对您在任务中使用的语言有某种统计规律上的理解)。
- 由于预训练模型已经在大量数据上进行了训练,因此微调需要更少的数据来获得不错的结果。
- 出于同样的原因,获得好结果所需的时间和资源要少得多
微调模型具有较低的时间、数据、财务和环境成本。迭代不同的微调方案也更快、更容易,因为与完整的预训练相比,训练的约束更少。这个过程也会比从头开始的训练(除非你有很多数据)取得更好的效果,这就是为什么你应该总是尝试利用一个预训练的模型—一个尽可能接近你手头的任务的模型—并对其进行微调。(大多数场景下,你其实都没有足够量的数据orz)
Architecture
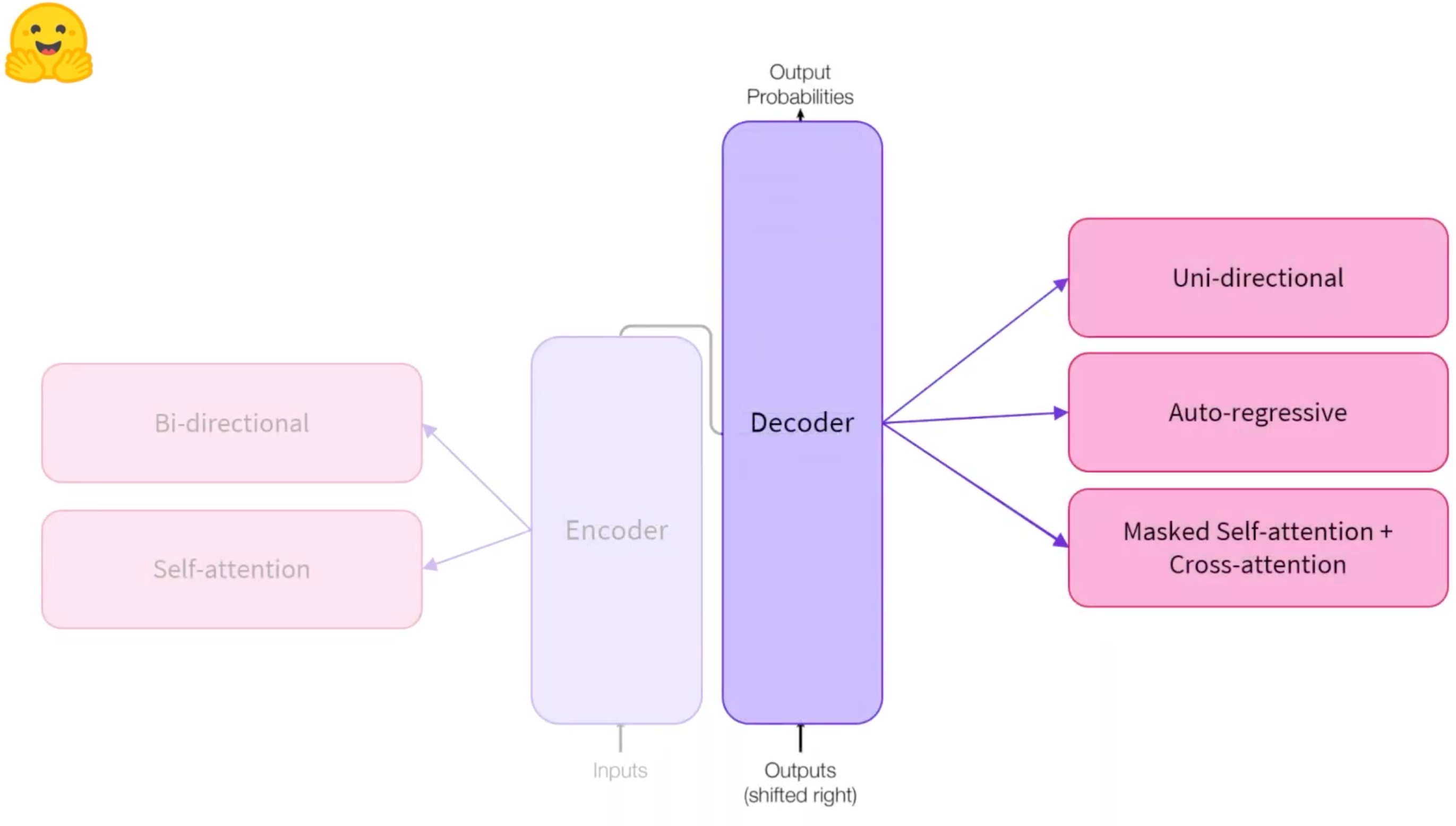
结构介绍
Encoder (左侧): 编码器接收输入并构建其表示(其特征)。这意味着对模型进行了优化,以从输入中获得理解。
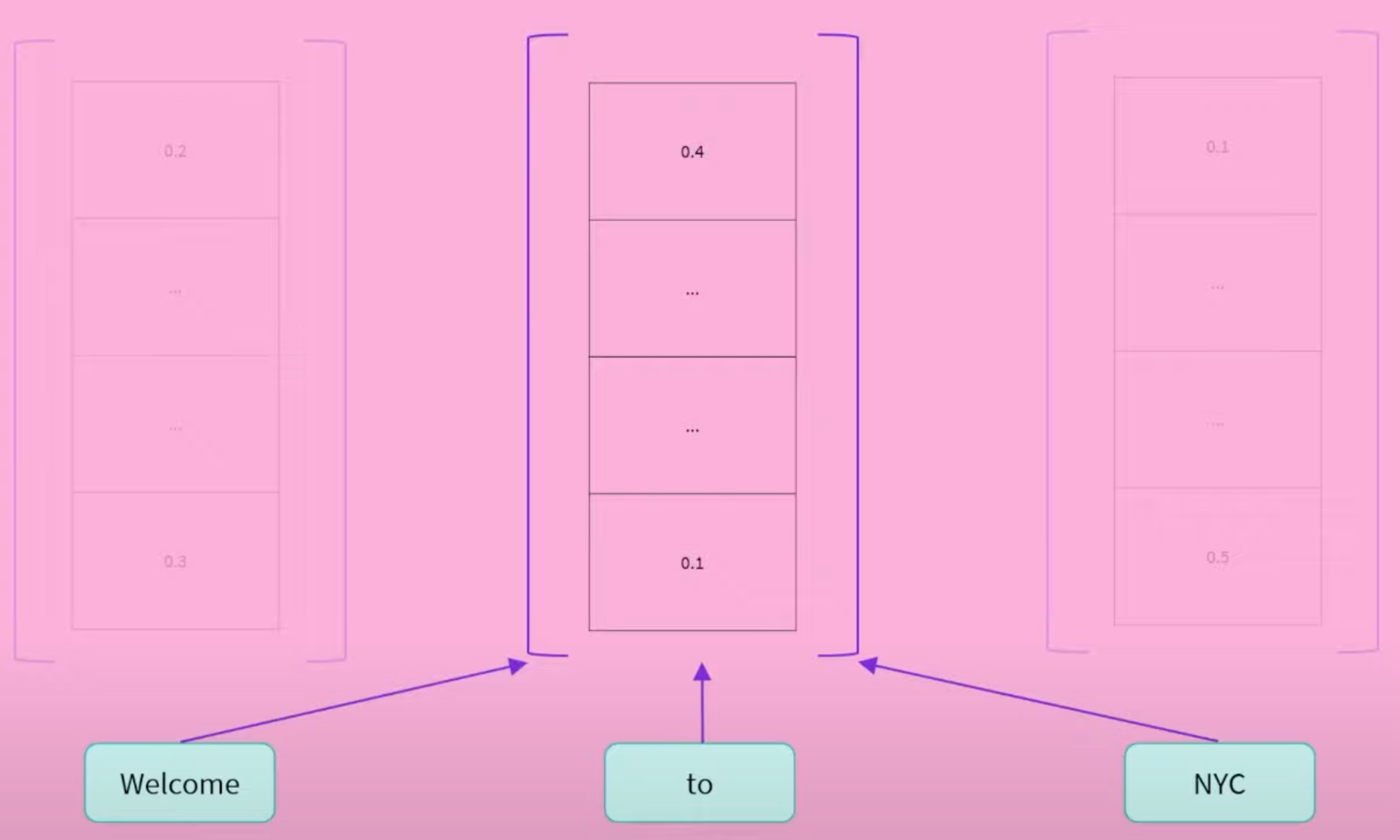
将Sentence中的每一个单词,通过self-attention提取它的context和它本身的含义,并转换为一个多维的向量(例如768纬),这个向量实际上就可以理解为,保存了当前词在当前上下文中的”语义“。因此这个语义vector后续就可以被用来实现更多的NLP任务。(例如加DNN,做情感分类之类的事儿)
Decoder (右侧): 解码器使用编码器的表示(特征)以及其他输入来生成目标序列。这意味着该模型已针对生成输出进行了优化。
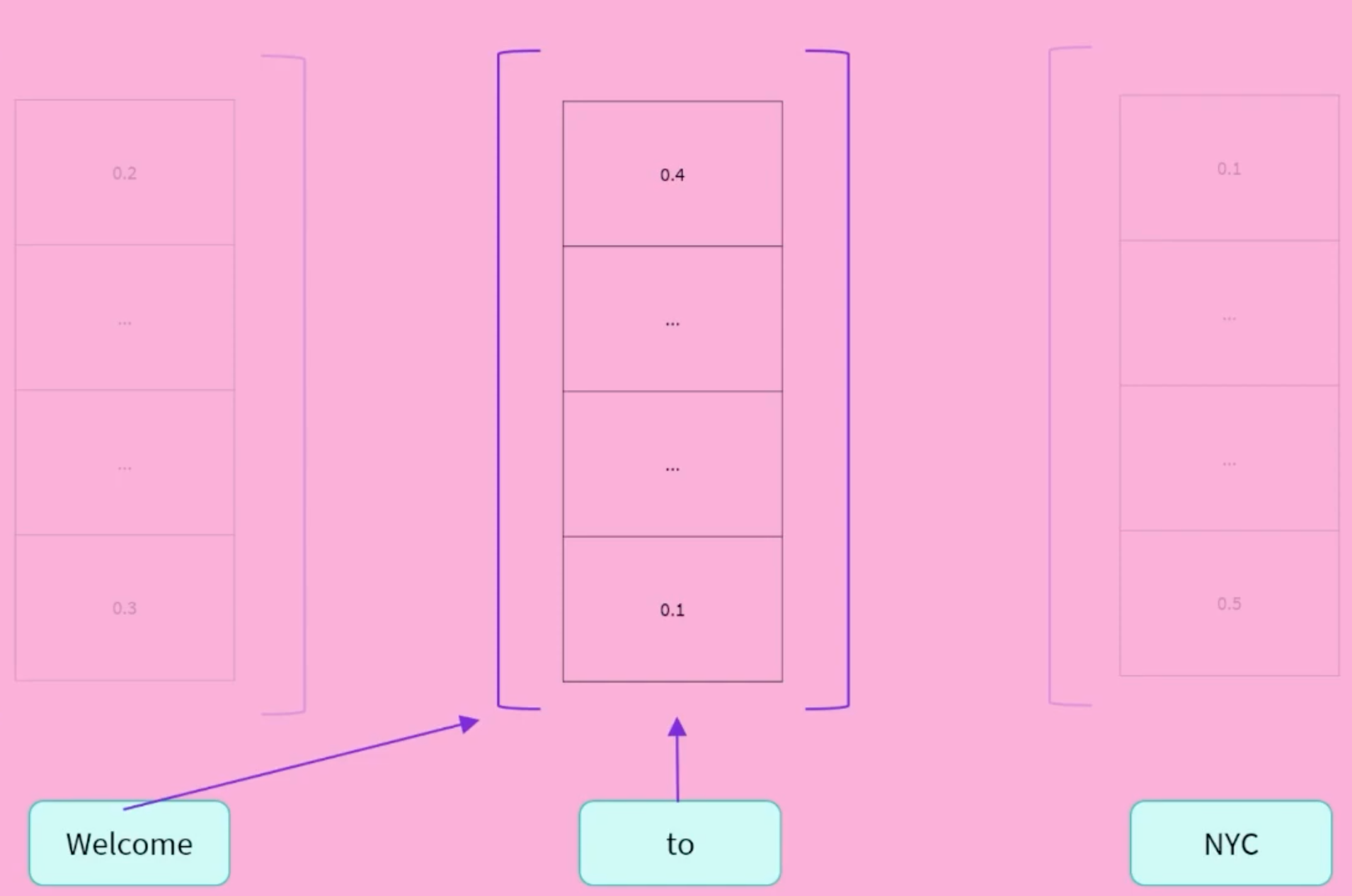
通过Masked Self-Attention,把右边遮住,只暴露左边给Decoder,并让其输出右边。Good at Causal Language Modeling(Guessing the next word in the sentence).
Seq2Seq: Encoder-Decoder接在一起。
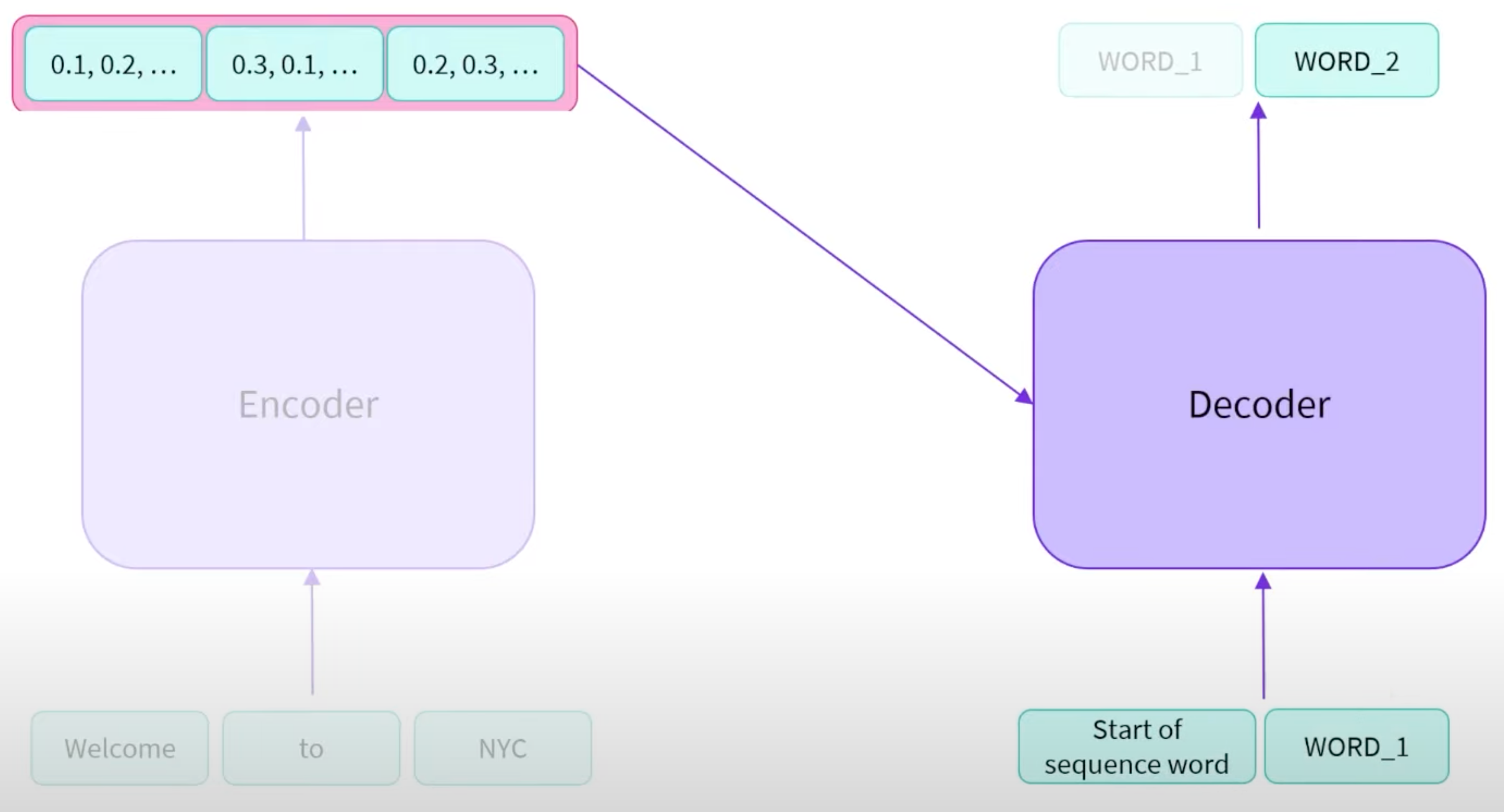
- Encoder将输入Sentence所表述的语义抽取出来,并且在Decoder生成期间使用(Encoder在输出了对应的语义后,便不在Decoder生成的过程中起别的作用了,Decoder生成本质上是拿着Encoder的输出作为自己的输入的一部分的。
- Decoder会接受一个特殊的Start token,和Encoder输出的语义,开始生成文本。每次生成的新的token,都会接在现有的token sequence最后,并成为一个新的token sequence重新输入Decoder,Decoder会一直输出,直到遇到某个特殊的End token为止。(Encoder就使用了一次,Decoder会被使用多次)
- Encoder和Decoder权重不一定是共享的,因此我们可以只使用其中的一部分,例如Encoder or Decoder only,去解决一些实际任务。
这些部件中的每一个都可以独立使用,具体取决于任务:
Encoder-only models: 适用于需要理解输入的任务,如句子分类和命名实体识别。
Decoder-only models: 适用于生成任务,如文本生成。
Encoder-decoder models 或者 sequence-to-sequence models: 适用于需要根据输入进行生成的任务,如翻译或摘要。
Attension Layer
- Transformer模型的一个关键特性是注意力层。事实上,介绍Transformer架构的文章的标题是“Attention Is All You Need”!这一层将告诉模型在处理每个单词的表示时,要特别重视您传递给它的句子中的某些单词(并且或多或少地忽略其他单词)。

- 原始的Transformer架构如下所示,编码器在左侧,解码器在右侧:请注意,解码器块中的第一个注意力层关注解码器的所有(过去的)输入,但第二个注意力层使用编码器的输出。因此,它可以访问整个输入句子,以最好地预测当前的词。这非常有用,因为不同的语言可能有将单词放在不同顺序的语法规则,或者句子后面的一些上下文可能有助于确定给定词的最佳翻译。注意力掩码也可以在编码器/解码器中使用,以防止模型关注一些特殊词——例如,用于使所有输入在批处理句子时具有相同长度的特殊填充词。
Summary
当我们深入探讨Transformers模型时,您将看到 架构、参数和模型。这些术语的含义略有不同:
Architecture: 这是模型的骨架 — 每个层的定义以及模型中发生的每个操作。
Checkpoints: 这些是将在给架构中结构中加载的权重。
Model: 这是一个笼统的术语,没有“架构”或“参数”那么精确:它可以指两者。为了避免歧义,本课程使用将使用架构和参数。
Bias and limitations: 其中最大的一个问题是,为了对大量数据进行预训练,研究人员通常会搜集所有他们能找到的内容,中间可能夹带一些意识形态或者价值观的刻板印象。 尽管一些大模型是使用经过筛选和清洗后,明显中立的数据集上建立的的Transformer模型,仍然会有这样的问题存在。当您使用这些工具时,您需要记住,使用的原始模型的时候,很容易生成性别歧视、种族主义或恐同内容。这种固有偏见不会随着微调模型而使消失。
Summary: 您可以使用完整的体系结构,也可以仅使用编码器或解码器,具体取决于您要解决的任务类型。下表总结了这一点:
模型 示例 任务 编码器 ALBERT, BERT, DistilBERT, ELECTRA, RoBERTa 句子分类、命名实体识别、从文本中提取答案 解码器 CTRL, GPT, GPT-2, Transformer XL 文本生成 编码器-解码器 BART, T5, Marian, mBART 文本摘要、翻译、生成问题的回答 Little test: https://huggingface.co/learn/nlp-course/en/chapter1/10?fw=pt
Using Transformers
Introduction
由于几乎每天都在发布新模型,而且每种模型都有自己的实现,因此尝试它们绝非易事。创建🤗 Transformers库就是为了解决这个问题。它的目标是提供一个API,通过它可以加载、训练和保存任何Transformer模型。这个库的主要特点是:
易于使用:下载、加载和使用最先进的NLP模型进行推理只需两行代码即可完成。
灵活:所有型号的核心都是简单的PyTorch nn.Module 或者 TensorFlow tf.kears.Model,可以像它们各自的机器学习(ML)框架中的任何其他模型一样进行处理。
简单:当前位置整个库几乎没有任何摘要。“都在一个文件中”是一个核心概念:模型的正向传递完全定义在一个文件中,因此代码本身是可以理解的,并且是可以破解的。
最后一个特性使🤗 Transformers与其他ML库截然不同。这些模型不是基于通过文件共享的模块构建的;相反,每一个模型都有自己的菜单。除了使模型更加容易接受和更容易理解,这还允许你轻松地在一个模型上实验,而且不影响其他模型。
How Pipeline Works
- Demo
1 | |
此管道将三个步骤组合在一起:预处理、通过模型传递输入和后处理:

Tokenizer
- 使用分词器进行预处理: 我们管道的第一步是将文本输入转换为模型能够理解的数字。 为此,我们使用tokenizer,负责:
- 将输入拆分为单词、子单词或符号(如标点符号),称为标记(token)
- 将每个标记(token)映射到一个整数
- 添加可能对模型有用的其他输入
- 所有这些预处理都需要以与模型预训练时完全相同的方式完成,因此我们首先需要从Model Hub中下载这些信息。为此,我们使用
AutoTokenizer类及其from_pretrained()方法。使用我们模型的检查点名称,它将自动获取与模型的标记器相关联的数据,并对其进行缓存(因此只有在您第一次运行下面的代码时才会下载)。
1 | |
一旦我们有了tokenizer,我们就可以直接将我们的句子传递给它,然后我们就会得到返回的dictionary,它可以提供给我们的模型!The only thing left to do is to convert the list of input IDs to tensors.
- 您可以使用Transformers,而不必担心使用的是哪个机器学习框架作为后端;它可能是PyTorch或TensorFlow,或者对于某些模型来说是Flax。然而,Transformer模型只接受张量作为输入。为了指定我们想要返回的张量类型(PyTorch、TensorFlow或普通的NumPy),我们使用
return_tensors参数:
1 | |
不要担心填充和截断的问题,我们稍后会解释这些。这里要记住的主要事项是您可以传递一个句子或一个句子列表,并且可以指定您想要返回的张量类型(如果没有传递类型,您将得到一个列表列表作为结果)。以下是PyTorch张量形式的结果示例:
1 | |
Going through the model
- 我们可以像使用标记器一样下载预训练模型。Transformers提供了一个
AutoModel类,该类还具有from_pretrained()方法:
1 | |
在这段代码片段中,我们下载了之前在管道中使用过的同一个检查点(实际上应该已经被缓存了),并用它实例化了一个模型。这个架构只包含基础的Transformer模块:给定一些输入,它输出我们称之为隐藏状态,也被称为特征的东西。对于每个模型输入,我们将检索到一个高维向量,代表Transformer模型对那个输入的上下文理解。虽然这些隐藏状态本身可能很有用,但它们通常是模型另一部分的输入。
- High dimension vector,Transformers模块的矢量输出通常较大。它通常有三个维度:
- Batch size: 一次处理的序列数(在我们的示例中为2)。
- Sequence length: 序列的数值表示的长度(在我们的示例中为16)。
- Hidden size: 每个模型输入的向量维度。
由于最后一个值,它被称为“高维”。隐藏的大小可能非常大(768通常用于较小的型号,而在较大的型号中,这可能达到3072或更大)。
1 | |
Model heads: Making sense out of numbers

模型头部接收高维隐藏状态向量作为输入,并将它们投影到不同的维度。它们通常由一个或几个线性层组成:Transformer模型的输出直接发送到模型头部进行处理。
模型由其嵌入层和随后的层表示。嵌入层将标记化输入中的每个输入ID转换为表示相关标记的向量。随后的层使用注意力机制操作这些向量,以产生句子的最终表示。
Transformers中有许多不同的体系结构,每种体系结构都是围绕处理特定任务而设计的。以下是一个非详尽的列表:
*Model(retrieve the hidden states)*ForCausalLM*ForMaskedLM*ForMultipleChoice*ForQuestionAnswering*ForSequenceClassification*ForTokenClassification以及其他
对于我们的示例,我们需要一个带有序列分类头的模型(能够将句子分类为肯定或否定)。因此,我们实际上不会使用
AutoModel类,而是使用AutoModelForSequenceClassification:
1 | |
现在,如果我们观察输出的形状,维度将低得多:模型头将我们之前看到的高维向量作为输入,并输出包含两个值的向量。因为我们只有两个句子和两个标签,所以我们从模型中得到的结果是2 x 2的形状。
1 | |
- 什么是模型的Head层? 一个附加组件,通常由一个或几个层组成,用于将Transformer的预测转换为特定于任务的输出。
Postprocessing the output
- 我们从模型中得到的输出值本身并不一定有意义,我们的模型预测第一句为
[-1.5607, 1.6123],第二句为[ 4.1692, -3.3464]。这些不是概率,而是logits,即模型最后一层输出的原始非标准化分数。要转换为概率,它们需要经过SoftMax层(所有Transformers模型输出logits,因为用于训练的损耗函数通常会将最后的激活函数(如SoftMax)与实际损耗函数(如交叉熵)融合):
1 | |
- 现在我们可以看到,模型预测第一句为
[0.0402, 0.9598],第二句为[0.9995, 0.0005]。这些是可识别的概率分数。为了获得每个位置对应的标签,我们可以检查模型配置的id2label属性(下一节将对此进行详细介绍):
1 | |
第一句:否定:0.0402,肯定:0.9598
第二句:否定:0.9995,肯定:0.0005
Summary
- 管道的三个步骤:
- 使用标记化器进行预处理(是将文本转换为单词或子词序列的过程。在自然语言处理中,文本通常是由一系列单词或子词组成的,而分词器的任务就是将这些单词或子词从文本中分离出来,并将它们转换为计算机可以处理的数字表示。)
- 通过模型传递输入(是将单词或子词转换为向量表示的过程。在自然语言处理中,单词或子词通常被表示为一个高维度的稀疏向量,其中每个维度对应一个单词或子词的特征。然后再把Embedding塞入模型中,拿到输出的Logits)
- 后处理(将Logits塞入Softmax中,拿到最后的概率结果)
Models
AutoModel类及其所有相关项实际上是对库中各种可用模型的简单包装。它是一个聪明的包装器,因为它可以自动猜测checkpoint的适当architecture,然后用该体系结构实例化模型。但是,如果您知道要使用的模型类型,则可以使用直接定义其体系结构的类。让我们看看这是如何与BERT模型一起工作的。
Create a Transformer
1
2
3
4
5
6
7
8
9from transformers import BertConfig, BertModel
# Building the config
config = BertConfig()
# Building the model from the config
model = BertModel(config)
# 从默认配置创建模型会使用随机值对其进行初始化。Model is randomly initialized!该模型可以在这种状态下使用,但会输出胡言乱语;首先需要对其进行训练。为了避免不必要的重复工作,必须能够共享和重用已经训练过的模型。
Load a Transformer
1
2
3from transformers import BertModel
model = BertModel.from_pretrained("bert-base-cased")我们可以将BertModel替换为等价的AutoModel类。我们将这样做,因为这会产生与checkpoint无关的代码;如果您的代码适用于一个checkpoint,它应该可以无缝地适用于另一个。即使架构不同,只要检查点是为类似任务(例如,情感分析任务)训练的,这也适用。
在上面的代码示例中,我们没有使用BertConfig,而是通过bert-base-cased标识符加载了一个预训练模型。这是一个由BERT的作者自己训练的模型检查点;您可以在其模型卡片中找到更多详细信息。
这个模型现在已用检查点的所有权重初始化。它可以直接用于它所训练的任务上的推理,也可以在新任务上进行微调。通过使用预训练权重而不是从头开始训练,我们可以快速取得良好的结果。
权重已经被下载并缓存(因此future calls to the from_pretrained()方法不会重新下载它们),缓存文件夹默认为~/.cache/huggingface/transformers。您可以通过设置HF_HOME环境变量来自定义您的缓存文件夹。
用于加载模型的标识符可以是模型中心上任何与BERT架构兼容的模型的标识符。完整的可用BERT检查点列表可以在这里找到。
Save methods
1
model.save_pretrained("directory_on_my_computer")1
2
3ls directory_on_my_computer
config.json pytorch_model.binconfig.json: 您将识别构建模型体系结构所需的属性。该文件还包含一些元数据,例如checkpoint的来源以及上次保存检查点时使用的Transformers版本。
pytorch_model.bin: state dictionary; 它包含模型的所有权重。
这两个文件齐头并进;配置是了解模型体系结构所必需的,而模型权重是模型的参数。
Using a Transformer model for inference
- Transformer模型只能处理数字—这些数字是由分词器生成的。分词器可以负责将输入转换为适当框架的张量。
1
2
3
4
5
6
7
8
9sequences = ["Hello!", "Cool.", "Nice!"]
=====================> Tokenizer
encoded_sequences = [
[101, 7592, 999, 102],
[101, 4658, 1012, 102],
[101, 3835, 999, 102],
]- 这是一系列编码序列:一个列表的列表。张量只接受矩形形状(想象矩阵)。这个“数组”已经是矩形形状,所以将其转换为张量很容易:
1
2
3import torch
model_inputs = torch.tensor(encoded_sequences)- 使用张量作为模型的输入
1
output = model(model_inputs)While the model accepts a lot of different arguments, only the input IDs are necessary.
Tokenizers
在 NLP 任务中,通常处理的数据是原始文本。 但是,模型只能处理数字,因此我们需要找到一种将原始文本转换为数字的方法。这就是标记器(tokenizer)所做的,并且有很多方法可以解决这个问题。目标是找到最有意义的表示——即对模型最有意义的表示——并且如果可能的话,找到最小的表示。
Tokenizers的示例:
Word-based:

它通常很容易设置和使用,只需几条规则,并且通常会产生不错的结果。例如,将原始文本拆分为单词,并为每个单词找到一个数字表示:
1
2
3
4tokenized_text = "Jim Henson was a puppeteer".split()
print(tokenized_text)
# Result: ['Jim', 'Henson', 'was', 'a', 'puppeteer']还有一些单词标记器的变体,它们具有额外的标点符号规则。使用这种标记器,我们最终可以得到一些非常大的“词汇表”,其中词汇表由我们在语料库中拥有的独立标记的总数定义。每个单词都分配了一个 ID,从 0 开始一直到词汇表的大小。该模型使用这些 ID 来识别每个单词。
如果我们想用基于单词的标记器(tokenizer)完全覆盖一种语言,我们需要为语言中的每个单词都有一个标识符,这将生成大量的标记。例如,英语中有超过 500,000 个单词,因此要构建从每个单词到输入 ID 的映射,我们需要跟踪这么多 ID。此外,像“dog”这样的词与“dogs”这样的词的表示方式不同,模型最初无法知道“dog”和“dogs”是相似的:它会将这两个词识别为不相关。这同样适用于其他相似的词,例如“run”和“running”,模型最初不会认为它们是相似的。
最后,我们需要一个自定义标记(token)来表示不在我们词汇表中的单词。这被称为“未知”标记(token),通常表示为“[UNK]”或”
“。如果你看到标记器产生了很多这样的标记,这通常是一个不好的迹象,因为它无法检索到一个词的合理表示,并且你会在这个过程中丢失信息。制作词汇表时的目标是以这样一种方式进行,即标记器将尽可能少的单词标记为未知标记。 减少未知标记数量的一种方法是使用更深一层的标记器(tokenizer),即基于字符的(character-based)标记器(tokenizer)。
Character-based:

- 基于字符的标记器(tokenizer)将文本拆分为字符,而不是单词。这有两个主要好处: 词汇量要小得多。 词汇外(未知)标记(token)要少得多,因为每个单词都可以从字符构建。
- 这种方法也不是完美的。由于现在表示是基于字符而不是单词,因此人们可能会争辩说,从直觉上讲,它的意义不大:每个字符本身并没有多大意义,而单词就是这种情况。然而,这又因语言而异;例如,在中文中,每个字符比拉丁语言中的字符包含更多的信息。另一个需要考虑的问题是,我们的模型最终将处理大量的标记:使用基于词的分词器时,一个词只会是一个单独的标记,但在转换为字符时,它很容易变成10个或更多的标记。
- 标点符号也是一个重要的问题和考量方面。
Subword tokenization

- 子词分词算法基于这样一个原则:常用词不应被拆分为更小子词,但罕见词应该被分解成有意义的子词。例如,“annoyingly”可能被视为一个罕见词,并可以被分解为“annoying”和“ly”。这两个子词作为独立的子词出现的可能性更大,同时“annoyingly”的含义通过“annoying”和“ly”的组合含义得以保留。
- 以下是一个示例,展示了子词分词算法如何对序列“Let’s do tokenization!”进行分词:
- “Let” -> “Let”
- “’s” -> “‘s” (可能被视为一个特殊字符或缩写)
- “do” -> “do”
- “token” -> “token”
- “ization” -> “ization”
- “!” -> “!”
Other tokenizers
- **字节级BPE (Byte-level BPE)**:在GPT-2中使用,它将文本分解为字节级别的子词,这允许模型处理Unicode字符,并且能够更好地处理未知词汇。
- WordPiece:在BERT中使用,这是一种基于子词的分词方法,它允许模型处理超出词汇表的词汇,通过将它们分解为已知的子词。
- SentencePiece或Unigram:在多种多语言模型中使用,这些技术通常用于处理多种语言的文本,并且能够很好地处理词汇表外的词汇。
How to use tokenizers?
Loading and saving
加载和保存标记器(tokenizer)就像使用模型一样简单。实际上,它基于相同的两种方法: from_pretrained() 和 save_pretrained() 。这些方法将加载或保存标记器(tokenizer)使用的算法加载和保存tokenizer,就像使用模型一样简单。实际上,它基于相同的两种方法: from_pretrained() 和 save_pretrained() 。这些方法将加载或保存tokenizer使用的算法(类似于architecture)以及它的词汇(类似于weights)。
加载方式:
1
2
3from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-cased")如同
AutoModel,AutoTokenizer类将根据检查点名称在库中获取正确的标记器(tokenizer)类,并且可以直接与任何检查点一起使用。使用方式:
1
2
3tokenizer("Using a Transformer network is simple")
# {'input_ids': [101, 7993, 170, 11303, 1200, 2443, 1110, 3014, 102], token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0], attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}保存方式:
1
tokenizer.save_pretrained("directory_on_my_computer")
编码
将文本翻译成数字被称为编码(encoding).编码分两步完成:标记化,然后转换为输入 ID。
- 第一步是将文本拆分为单词(或单词的一部分、标点符号等),通常称为*标记(token)*。有多个规则可以管理该过程,这就是为什么我们需要使用模型名称来实例化标记器(tokenizer),以确保我们使用模型预训练时使用的相同规则。
- 第二步是将这些标记转换为数字,这样我们就可以用它们构建一个张量并将它们提供给模型。为此,标记器(tokenizer)有一个*词汇(vocabulary)*,这是我们在实例化它时下载的部分
from_pretrained()方法。同样,我们需要使用模型预训练时使用的相同词汇。
我们将使用一些单独执行部分标记化管道的方法来向您展示这些步骤的中间结果,但实际上,您应该直接在您的输入上调用tokenizer
标记化过程由tokenizer的
tokenize()方法实现:1
2
3
4
5
6
7
8
9
10from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
sequence = "Using a Transformer network is simple"
tokens = tokenizer.tokenize(sequence)
print(tokens)
# Result ['Using', 'a', 'transform', '##er', 'network', 'is', 'simple']这个标记器(tokenizer)是一个子词标记器(tokenizer):它对词进行拆分,直到获得可以用其词汇表表示的标记(token)。
transformer就是这种情况,它分为两个标记:transform和##er。Tokens -> Input IDs
1
2
3
4
5ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)
# Result [7993, 170, 11303, 1200, 2443, 1110, 3014]这些输出(Input IDs)一旦转换为适当的框架张量(Tensor),就可以用作模型的输入
解码:
解码(Decoding) 正好相反:从词汇索引中,我们想要得到一个字符串。这可以通过
decode()方法实现,如下:1
2
3
4decoded_string = tokenizer.decode([7993, 170, 11303, 1200, 2443, 1110, 3014])
print(decoded_string)
# 'Using a Transformer network is simple'请注意,
decode方法不仅将索引转换回标记(token),还将属于相同单词的标记(token)组合在一起以生成可读的句子。当我们使用预测新文本的模型(根据提示生成的文本,或序列到序列问题(如翻译或摘要))时,这种行为将非常有用。
Handling multiple sequences
New questions:
- 我们如何处理多个序列?
- 我们如何处理不同长度的多个序列?
- 词汇索引是唯一能让模型良好工作的输入吗?
- 序列是否可能太长?
Models expect a batch of inputs:
批处理是将多个句子一次性通过模型发送的行为。如果您只有一个句子,您可以只构建一个包含单个序列的批次:
1
batched_ids = [ids, ids]批处理允许模型在您给它输入多个句子时工作。使用多个序列就像构建一个包含单个序列的批次一样简单。然而,还有第二个问题。当您尝试将两个(或更多)句子组合成一个批次时,它们可能长度不同。如果您以前使用过张量,您知道它们需要是矩形形状,所以您不能直接将输入ID列表转换为张量。为了解决这个问题,我们通常对输入进行填充。
Padding the inputs
为了解决这个问题,我们将使用填充使张量具有矩形。Padding通过在值较少的句子中添加一个名为Padding token的特殊单词来确保我们所有的句子长度相同。
Transformer模型的关键特性是关注层,它将每个标记上下文化。这些将考虑填充标记,因为它们涉及序列中的所有标记。为了在通过模型传递不同长度的单个句子时,或者在传递一批应用了相同句子和填充的句子时获得相同的结果,我们需要告诉这些注意层忽略填充标记。这是通过使用 attention mask来实现的。
1
2
3
4
5
6batched_ids = [
[200, 200, 200],
[200, 200, tokenizer.pad_token_id],
]
print(model(torch.tensor(batched_ids)).logits)
Attention masks
Attention masks是与输入ID张量形状完全相同的张量,用0和1填充:1s表示应注意相应的标记,0s表示不应注意相应的标记(即,模型的注意力层应忽略它们)。
1
2
3
4
5
6
7
8
9
10
11
12batched_ids = [
[200, 200, 200],
[200, 200, tokenizer.pad_token_id],
]
attention_mask = [
[1, 1, 1],
[1, 1, 0],
]
outputs = model(torch.tensor(batched_ids), attention_mask=torch.tensor(attention_mask))
print(outputs.logits)第二个序列的最后一个值是一个填充ID,它在attention mask中是一个0值。
Longer sequences
对于Transformers模型,我们可以通过模型的序列长度是有限的。大多数模型处理多达512或1024个令牌的序列,当要求处理更长的序列时,会崩溃。此问题有两种解决方案:
使用支持的序列长度较长的模型。
截断序列。
模型有不同的支持序列长度,有些模型专门处理很长的序列。 Longformer 这是一个例子,另一个是 LED . 如果您正在处理一项需要很长序列的任务,我们建议您查看这些模型。否则,我们建议您通过指定max_sequence_length参数:
1
sequence = sequence[:max_sequence_length]
Putting it all together
- Transformers API可以通过一个高级函数为我们处理所有这些
1 | |
model_inputs变量包含模型良好运行所需的一切。对于DistilBERT,它包括输入 ID和注意力掩码(attention mask)。其他接受额外输入的模型也会有tokenizer的输出。
- 一次处理多个序列:
1 | |
- 标记器对象可以处理到特定框架张量的转换,然后可以直接发送到模型。例如,在下面的代码示例中,我们提示标记器从不同的框架返回张量——
"pt"返回Py Torch张量,"tf"返回TensorFlow张量,"np"返回NumPy数组:
1 | |
Special tokens
我们看一下标记器返回的输入 ID,我们会发现它们与之前的略有不同:
1
2
3
4
5
6
7
8
9
10
11sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)
print(model_inputs["input_ids"])
tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)
print(tokenizer.decode(model_inputs["input_ids"]))
print(tokenizer.decode(ids))Result
1
2
3
4
5
6
7[101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102]
[1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012]
"[CLS] i've been waiting for a huggingface course my whole life. [SEP]"
"i've been waiting for a huggingface course my whole life."Tokenizer在开头添加了特殊单词
[CLS],在结尾添加了特殊单词[SEP]。这是因为模型是用这些数据预训练的,所以为了得到相同的推理结果,我们还需要添加它们。请注意,有些模型不添加特殊单词,或者添加不同的单词;模型也可能只在开头或结尾添加这些特殊单词。在任何情况下,Tokenizer都知道需要哪些词符,并将为您处理这些词符。
Wrapping up: From tokenizer to model
现在我们已经看到了标记器对象在应用于文本时使用的所有单独步骤,让我们最后一次看看它如何处理多个序列(填充!),非常长的序列(截断!),以及多种类型的张量及其主要API:
1 | |
- 填充(Padding):将较短的序列用特殊的填充值(通常是
<PAD>token)扩展到与最长序列相同的长度。这可以避免批处理中因为序列长度不一致而导致的张量维度不匹配的问题。- 截断(Truncation):对于过长的序列,截取到指定的最大长度,避免序列过长超过模型的最大处理能力。
padding=True和truncation=True一起使用,可以确保所有输入序列的长度一致,从而可以方便地进行批量处理。return_tensors="pt"则表示返回的是PyTorch张量。
Summary
学习的内容
学习了Transformers模型的基本构造块。
了解了标记化管道的组成。
了解了如何在实践中使用Transformers模型。
学习了如何利用分词器将文本转换为模型可以理解的张量。
将分词器和模型一起设置,以从文本到预测。
了解了inputs IDs的局限性,并了解了attention mask。
使用多功能和可配置的分词器方法。
Little test: https://huggingface.co/learn/nlp-course/en/chapter2/8?fw=pt
Fine-tuning a pretrained model
Introduction
- Table of contents
- 如何从模型中心(hub)准备大型数据集
- 如何使用高级
训练API微调一个模型 - 如何使用自定义训练过程
- 如何利用🤗 Accelerate库在任何分布式设备上轻松运行自定义训练过程
Processing the data
- Easy demo
1 | |
数据太少了,训练没有效果!
MRPC数据集Demo
该数据集由威廉·多兰和克里斯·布罗克特在这篇文章发布。该数据集由5801对句子组成,每个句子对带有一个标签,指示它们是否为同义(即,如果两个句子的意思相同)。我们在本章中选择了它,因为它是一个小数据集,所以很容易对它进行训练。
点击数据集的链接即可进行浏览,也可以学习:加载和处理新的数据集这篇文章。我们使用MRPC数据集中的GLUE 基准测试数据集,它是构成MRPC数据集的10个数据集之一,这是一个学术基准,用于衡量机器学习模型在10个不同文本分类任务中的性能。
Datasets库提供了一个非常便捷的命令,可以在模型中心(hub)上下载和缓存数据集。我们可以通过以下的代码下载MRPC数据集:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21from datasets import load_dataset
raw_datasets = load_dataset("glue", "mrpc")
raw_datasets
# 此命令在下载数据集并缓存到 ~/.cache/huggingface/datasets,您可以通过设置HF_HOME环境变量来自定义缓存的文件夹。
# Result
DatasetDict({
train: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
validation: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 408
})
test: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 1725
})
})我们获得了一个DatasetDict对象,其中包含训练集、验证集和测试集。每一个集合都包含几个列(sentence1, sentence2, label, and idx)以及一个代表行数的变量。
访问数据
1
2
3raw_train_dataset = raw_datasets["train"]
raw_train_dataset[0]
# 这个就是一条真真切切,含有各种feature的数据要知道哪个数字对应于哪个标签,我们可以查看raw_train_dataset的features.
1
raw_train_dataset.featuresLabel(标签) 是一种ClassLabel(分类标签),使用整数建立起到类别标签的映射关系。0对应于not_equivalent,1对应于equivalent。
预处理数据集
将文本转换为模型能够理解的数字
1
2inputs = tokenizer("This is the first sentence.", "This is the second one.")
inputs输入词id(input_ids) 和 注意力遮罩(attention_mask) ,**类型标记ID(token_type_ids)**的作用就是告诉模型输入的哪一部分是第一句,哪一部分是第二句。
1
2
3tokenizer.convert_ids_to_tokens(inputs["input_ids"])
# ['[CLS]', 'this', 'is', 'the', 'first', 'sentence', '.', '[SEP]', 'this', 'is', 'the', 'second', 'one', '.', '[SEP]'][CLS] sentence1 [SEP] sentence2 [SEP],输入中 [CLS] sentence1 [SEP] 它们的类型标记ID均为0,而其他部分,对应于sentence2 [SEP],所有的类型标记ID均为1。
如果选择其他的checkpoint,则不一定具有token_type_ids(例如,如果使用DistilBERT模型,就不会返回它们)。只有当它在预训练期间使用过这一层,模型在构建时依赖它们,才会返回它们。
使用第一章的遮罩语言模型,还有一个额外的应用类型,叫做下一句预测。
训练过程中,会给模型输入成对的句子(带有随机遮罩的标记),并被要求预测第二个句子是否紧跟第一个句子。为了提高模型的泛化能力,数据集中一半的两个句子在原始文档中挨在一起,另一半的两个句子来自两个不同的文档。
一般来说,不需要担心是否有token_type_ids。在您的标输入中:只要您对标记器和模型使用相同的检查点,一切都会很好,因为标记器知道向其模型提供什么。
我们可以给标记器提供一组句子,第一个参数是它第一个句子的列表,第二个参数是第二个句子的列表。
1
2
3
4
5
6tokenized_dataset = tokenizer(
raw_datasets["train"]["sentence1"],
raw_datasets["train"]["sentence2"],
padding=True,
truncation=True,
)它的缺点是返回字典(字典的键是输入词id(input_ids) , 注意力遮罩(attention_mask) 和 **类型标记ID(token_type_ids)**,字典的值是键所对应值的列表)。而且只有当您在转换过程中有足够的内存来存储整个数据集时才不会出错
Hugging face数据集库中的数据集是以Apache Arrow文件存储在磁盘上,因此您只需将接下来要用的数据加载在内存中,因此会对内存容量的需求要低一些。
为了将数据保存为数据集,我们将使用Dataset.map()方法,如果我们需要做更多的预处理而不仅仅是标记化,那么这也给了我们一些额外的自定义的方法。这个方法的工作原理是在数据集的每个元素上应用一个函数。
代码
1
2
3
4
5def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets- 输入是一个字典(与数据集的项类似),并返回一个包含输入词id(input_ids) , 注意力遮罩(attention_mask) 和 类型标记ID(token_type_ids) 键的新字典。
- 可以处理成对的句子列表 像上面的示例一样,如果键所对应的值包含多个句子(每个键作为一个句子列表),那么它依然可以工作。
- 我们可以在调用map()使用该选项 batched=True ,这将显著加快标记与标记的速度。这个标记器来自🤗 Tokenizers库由Rust编写而成。当我们一次给它大量的输入时,这个标记器可以非常快。
我们现在在标记函数中省略了padding参数。这是因为在标记的时候将所有样本填充到最大长度的效率不高。一个更好的做法:在构建批处理时填充样本更好,因为这样我们只需要填充到该批处理中的最大长度,而不是整个数据集的最大长度。当输入长度变化很大时,这可以节省大量时间和处理能力!
Datasets库应用这种处理的方式是向数据集添加新的字段,those three fields are added to all splits of our dataset.
1
2
3
4
5
6
7
8
9
10
11
12
13
14DatasetDict({
train: Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 3668
})
validation: Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 408
})
test: Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 1725
})
})You can even use multiprocessing when applying your preprocessing function with
map()by passing along anum_procargument. We didn’t do this here because the Tokenizers library already uses multiple threads to tokenize our samples faster, but if you are not using a fast tokenizer backed by this library, this could speed up your preprocessing.我们的tokenize_function返回一个包含input_ids、attention_mask和token_type_ids键的字典,因此这三个字段被添加到我们数据集的所有分割中。请注意,如果我们的预处理函数返回了数据集中现有键的新值,我们也可以改变现有字段,前提是我们对数据集应用了map()。
Dynamic padding
负责将样本组合成一个批次的函数称为collate函数。它是你在构建DataLoader时可以传递的一个参数,默认情况下是一个函数,它只会将你的样本转换为PyTorch张量并将它们连接起来(如果你的元素是列表、元组或字典,则递归连接)。在我们的案例中,这将是不可能的,因为我们的输入不会全部是相同的大小。我们故意推迟了填充,只在每个批次中按需应用它,以避免有过多填充的过长输入。这将通过相当多的方式加快训练速度,但请注意,如果你在TPU上训练,它可能会导致问题——TPU更喜欢固定的形状,即使这需要额外的填充。
collate函数,它将对数据集中我们想要组合成批次的项目应用正确的填充量。Transformers库通过DataCollatorWithPadding为我们提供了这样一个函数。当你实例化它时,它需要一个tokenizer(以知道使用哪个填充标记,以及模型是否期望填充在输入的左侧还是右侧),并且会做你需要做的一切:
1
2
3from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)从我们的训练集中抓取一些我们想要组合在一起的样本。在这里,我们移除了idx、sentence1和sentence2列,因为它们不需要,并且包含字符串。(Tensor中不能包含字符串),查看每个条目的长度:
1
2
3samples = tokenized_datasets["train"][:8]
samples = {k: v for k, v in samples.items() if k not in ["idx", "sentence1", "sentence2"]}
[len(x) for x in samples["input_ids"]]到了不同长度的样本,从32到67。动态填充意味着这个一次sample中,所有的样本都应该被填充到67的长度,即批次内的最大长度。如果没有动态填充,所有的样本都必须被填充到整个数据集中的最大长度,或者模型可以接受的最大长度。
动态填充效果
1
2batch = data_collator(samples)
{k: v.shape for k, v in batch.items()}Result
1
2
3
4{'attention_mask': torch.Size([8, 67]),
'input_ids': torch.Size([8, 67]),
'token_type_ids': torch.Size([8, 67]),
'labels': torch.Size([8])}
Fine-tuning a model with the Trainer API
Train
Transformers提供了一个 Trainer 类来帮助您在自己的数据集上微调任何预训练模型。预处理数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPadding
raw_datasets = load_dataset("glue", "mrpc")
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)第一步是定义一个 TrainingArguments 类,它将包含 Trainer用于训练和评估的所有超参数。您唯一必须提供的参数是保存训练模型的目录,以及训练过程中的checkpoint。
1
2
3from transformers import TrainingArguments
training_args = TrainingArguments("test-trainer")如果您想在训练期间自动将模型上传到 Hub,请将push_to_hub=True添加到TrainingArguments之中
第二步是定义我们的模型,我们将使用 AutoModelForSequenceClassification类,它有两个参数:
1
2
3from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)在实例化此预训练模型后会收到警告。这是因为 BERT 没有在句子对分类方面进行过预训练,所以预训练模型的头部已经被丢弃,而是添加了一个适合句子序列分类的新头部。警告表明一些权重没有使用(对应于丢弃的预训练头的那些),而其他一些权重被随机初始化(新头的那些)。最后鼓励您训练模型,这正是我们现在要做的。
第三步就可以定义一个 Trainer 通过将之前构造的所有对象传递给它
1
2
3
4
5
6
7
8
9
10from transformers import Trainer
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
)开始训练:
1
trainer.train()这将开始微调,并每500步报告一次训练损失。但是,它不会告诉您模型的性能如何(或质量如何)。这是因为:
- 我们没有通过将evaluation_strategy设置为“steps”(在每次更新参数的时候评估)或“epoch”(在每个epoch结束时评估)来告诉Trainer在训练期间进行评估。
- 我们没有为Trainer提供一个**compute_metrics()**函数来直接计算模型的好坏(否则评估将只输出loss,这不是一个非常直观的数字)。
Evaluate
构建一个有用的 compute_metrics() 函数并在我们下次训练时使用它。该函数必须采用 EvalPrediction 对象(带有 predictions 和 label_ids 字段的参数元组)并将返回一个字符串到浮点数的字典(字符串是返回的指标的名称,而浮点数是它们的值)。我们可以使用 Trainer.predict() 命令来使用我们的模型进行预测:
1
2
3
4
5predictions = trainer.predict(tokenized_datasets["validation"])
print(predictions.predictions.shape, predictions.label_ids.shape)
# Result
(408, 2) (408,)predict() 的输出结果是具有三个字段的命名元组: predictions , label_ids , 和 metrics .这 metrics 字段将只包含传递的数据集的loss,以及一些运行时间(预测所需的总时间和平均时间)。如果我们定义了自己的 compute_metrics() 函数并将其传递给 Trainer ,该字段还将包含**compute_metrics()**的结果。
predict() 方法是具有三个字段的命名元组: predictions , label_ids , 和 metrics .这 metrics 字段将只包含传递的数据集的loss,以及一些运行时间(预测所需的总时间和平均时间)。如果我们定义了自己的 compute_metrics() 函数并将其传递给 Trainer ,该字段还将包含compute_metrics() 的结果。如你看到的, predictions 是一个形状为 408 x 2 的二维数组(408 是我们使用的数据集中元素的数量)。这些是我们传递给**predict()**的数据集的每个元素的结果(logits)。
要将我们的预测的可以与真正的标签进行比较,我们需要在第二个轴上取最大值的索引:
1
2
3import numpy as np
preds = np.argmax(predictions.predictions, axis=-1)现在建立我们的 compute_metric() 函数来较为直观地评估模型的好坏,我们将使用 Evaluate 库中的指标。我们可以像加载数据集一样轻松加载与 MRPC 数据集关联的指标,这次使用 evaluate.load() 函数。返回的对象有一个 compute()方法我们可以用来进行度量计算的方法:
1
2
3
4
5
6import evaluate
metric = evaluate.load("glue", "mrpc")
metric.compute(predictions=preds, references=predictions.label_ids)
# Result {'accuracy': 0.8578431372549019, 'f1': 0.8996539792387542}将所有东西打包在一起,我们得到了我们的 compute_metrics() 函数:
1
2
3
4
5def compute_metrics(eval_preds):
metric = evaluate.load("glue", "mrpc")
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)为了查看模型在每个训练周期结束的好坏,下面是我们如何使用**compute_metrics()**函数定义一个新的 Trainer :
1
2
3
4
5
6
7
8
9
10
11
12training_args = TrainingArguments("test-trainer", evaluation_strategy="epoch")
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)它将在训练loss之外,还会输出每个 epoch 结束时的验证loss和指标。同样,由于模型的随机头部初始化,您达到的准确率/F1 分数可能与我们发现的略有不同,但它应该在同一范围内。
A Full Training
- 简单总结:
1 | |
我们需要对我们的
tokenized_datasets做一些处理,来处理Trainer自动为我们做的一些事情。具体来说,我们需要:- 删除与模型不期望的值相对应的列(如
sentence1和sentence2列)。 - 将列名
label重命名为labels(因为模型期望参数是labels)。 - 设置数据集的格式,使其返回 PyTorch 张量而不是列表。
1
2
3
4
5
6
7tokenized_datasets = tokenized_datasets.remove_columns(["sentence1", "sentence2", "idx"])
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format("torch")
tokenized_datasets["train"].column_names
# Result ["attention_mask", "input_ids", "labels", "token_type_ids"]- 删除与模型不期望的值相对应的列(如
定义Dataloader
1
2
3
4
5
6
7
8from torch.utils.data import DataLoader
train_dataloader = DataLoader(
tokenized_datasets["train"], shuffle=True, batch_size=8, collate_fn=data_collator
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], batch_size=8, collate_fn=data_collator
)为了快速检验数据处理中没有错误,我们可以这样检验其中的一个批次:
1
2
3for batch in train_dataloader:
break
{k: v.shape for k, v in batch.items()}实际的形状可能略有不同,因为我们为训练数据加载器设置了
shuffle=True,并且模型会将句子填充到batch中的最大长度。模型
1
2
3
4
5
6
7
8from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
outputs = model(**batch)
print(outputs.loss, outputs.logits.shape)
# Result tensor(0.5441, grad_fn=<NllLossBackward>) torch.Size([8, 2])当我们提供
labels时,Transformers 模型都将返回这个batch的loss,我们还得到了logits(batch中的每个输入有两个,所以张量大小为 8 x 2)。优化器和学习率调度器
1
2
3
4
5
6
7
8
9
10
11
12
13from transformers import AdamW
from transformers import get_scheduler
optimizer = AdamW(model.parameters(), lr=5e-5)
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
print(num_training_steps)循环训练:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import torch
from tqdm.auto import tqdm
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)添加评估:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import evaluate
metric = evaluate.load("glue", "mrpc")
model.eval()
for batch in eval_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
logits = outputs.logits
predictions = torch.argmax(logits, dim=-1)
metric.add_batch(predictions=predictions, references=batch["labels"])
metric.compute()
# Result: {'accuracy': 0.8431372549019608, 'f1': 0.8907849829351535}Evaluate 库提供的指标。我们已经了解了
metric.compute()方法,当我们使用add_batch()方法进行预测循环时,实际上该指标可以为我们累积所有batch的结果。一旦我们累积了所有batch,我们就可以使用metric.compute()得到最终结果 .以下是在评估循环中实现所有这些的方法。使用Accelerate加速
使用Accelerate库,只需进行一些调整,我们就可以在多个 GPU 或 TPU 上启用分布式训练。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)加入Accelerate
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34from accelerate import Accelerator
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
accelerator = Accelerator()
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
train_dl, eval_dl, model, optimizer = accelerator.prepare(
train_dataloader, eval_dataloader, model, optimizer
)
num_epochs = 3
num_training_steps = num_epochs * len(train_dl)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dl:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)要添加的第一行是导入
Accelerator。第二行实例化一个Accelerator对象 ,它将查看环境并初始化适当的分布式设置。 Accelerate 为您处理数据在设备间的传递,因此您可以删除将模型放在设备上的那行代码(或者,如果您愿意,可使用accelerator.device代替device)。大部分工作会在将数据加载器、模型和优化器发送到的
accelerator.prepare()中完成。这将会把这些对象包装在适当的容器中,以确保您的分布式训练按预期工作。要进行的其余更改是删除将batch放在device的那行代码(同样,如果您想保留它,您可以将其更改为使用accelerator.device) 并将loss.backward()替换为accelerator.backward(loss)。⚠️ 为了使云端 TPU 提供的加速发挥最大的效益,我们建议使用标记器(tokenizer)的
padding=max_length和max_length参数将您的样本填充到固定长度。要在分布式设置中试用它,请运行以下命令:
1
accelerate config这将询问您几个配置的问题并将您的回答转储到此命令使用的配置文件中。
启动分布式训练
1
accelerate launch train.py如果您想在 Notebook 中尝试此操作(例如,在 Colab 上使用 TPU 进行测试),只需将代码粘贴到
training_function()并使用以下命令运行最后一个单元格:1
2
3from accelerate import notebook_launcher
notebook_launcher(training_function)您可以在Accelerate repo找到更多的示例。
Summary
- 汇总:
- 了解了Hub中的数据集
- 学习了如何加载和预处理数据集,包括使用动态填充和整理器
- 实现您自己的模型微调和评估
- 实施了一个较为底层的训练循环
- 使用 Accelerate 调整您的训练循环,使其适用于多个 GPU 或 TPU
- Little test: https://huggingface.co/learn/nlp-course/en/chapter3/6?fw=pt
Sharing Models and Tokenizers(Optional)
Using pretrained models
- 你唯一需要注意的是所选检查点是否适合它将用于的任务。例如,这里我们正在将
camembert-base检查点加载在fill-mask管道,这完全没问题。但是如果我们在text-classification管道加载检查点,结果没有任何意义,因为camembert-base不适合这个任务!我们建议使用 Hugging Face Hub 界面中的任务选择器来选择合适的检查点:

- 用pipeline使用
1 | |
用model/tokenizer使用
直接使用
1
2
3
4from transformers import CamembertTokenizer, CamembertForMaskedLM
tokenizer = CamembertTokenizer.from_pretrained("camembert-base")
model = CamembertForMaskedLM.from_pretrained("camembert-base")使用Auto类(我们建议使用
Auto*类,因为Auto*类设计与架构无关。):1
2
3
4from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("camembert-base")
model = AutoModelForMaskedLM.from_pretrained("camembert-base")
Sharing pretrained models
创建新模型存储库的方法有以下三种:
使用 push_to_hub API 接口
使用 huggingface_hub Python 库
使用 web 界面
不是重点,其余请参考:https://huggingface.co/learn/nlp-course/zh-CN/chapter4/3?fw=pt
Building model cards
Summary
Datasets
Introduction
我们将找到以下问题的答案:
当数据集不在hub上时,您该怎么做?
如何对数据集进行切片?(如果你真正的特别需要使用pandas的时候该怎么办?)
当你的数据集很大,会撑爆你笔记本电脑的RAM时,你会怎么做?
“内存映射”和Apache Arrow到底是什么?
如何创建自己的数据集并将其推送到中心?
Dataset Loading
Local dataset
- 加载数据集的方法:
atasets 提供了加载脚本来加载本地和远程数据集。它支持几种常见的数据格式,例如:
| Data format | Loading script | Example |
|---|---|---|
| CSV & TSV | csv |
load_dataset("csv", data_files="my_file.csv") |
| Text files | text |
load_dataset("text", data_files="my_file.txt") |
| JSON & JSON Lines | json |
load_dataset("json", data_files="my_file.jsonl") |
| Pickled DataFrames | pandas |
load_dataset("pandas", data_files="my_dataframe.pkl") |
如表所示, 对于每种数据格式, 我们只需要使用 load_dataset() 函数, 使用 data_files 指定一个或多个文件的路径的参数。 让我们从本地文件加载数据集开始;稍后我们将看到如何对远程文件执行相同的操作。
一个Demo
下载解压数据集
1
2
3
4
5!wget https://github.com/crux82/squad-it/raw/master/SQuAD_it-train.json.gz
!wget https://github.com/crux82/squad-it/raw/master/SQuAD_it-test.json.gz
# 我们可以用Linux的解压命令 gzip
!gzip -dkv SQuAD_it-*.json.gz我们可以看到压缩文件已经被替换为SQuAD_it-train.json和SQuAD_it-test.json,并且数据以 JSON 格式存储。使用
load_dataset()函数来加载JSON文件, 我们只需要知道我们是在处理普通的 JSON(类似于嵌套字典)还是 JSON 行(行分隔的 JSON)。像许多问答数据集一样, SQuAD-it 使用嵌套格式,所有文本都存储在data文件中。这意味着我们可以通过指定参数field来加载数据集,如下所示:1
2
3from datasets import load_dataset
squad_it_dataset = load_dataset("json", data_files="SQuAD_it-train.json", field="data")默认情况下, 加载本地文件会创建一个带有
train的DatasetDict对象。 我们可以通过squad_it_dataset查看:1
squad_it_dataset1
2
3
4
5
6DatasetDict({
train: Dataset({
features: ['title', 'paragraphs'],
num_rows: 442
})
})我们可以通过索引到
train查看示例1
squad_it_dataset["train"][0]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17{
"title": "Terremoto del Sichuan del 2008",
"paragraphs": [
{
"context": "Il terremoto del Sichuan del 2008 o il terremoto...",
"qas": [
{
"answers": [{"answer_start": 29, "text": "2008"}],
"id": "56cdca7862d2951400fa6826",
"question": "In quale anno si è verificato il terremoto nel Sichuan?",
},
...
],
},
...
],
}我们真正想要的是包括
train和test的DatasetDict对象。这样的话就可以使用Dataset.map()函数同时处理训练集和测试集。 为此, 我们提供参数data_files的字典,将每个分割名称映射到与该分割相关联的文件:1
2
3data_files = {"train": "SQuAD_it-train.json", "test": "SQuAD_it-test.json"}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
squad_it_dataset1
2
3
4
5
6
7
8
9
10DatasetDict({
train: Dataset({
features: ['title', 'paragraphs'],
num_rows: 442
})
test: Dataset({
features: ['title', 'paragraphs'],
num_rows: 48
})
})load_dataset()函数的data_files参数非常灵活并且可以是单个文件路径、文件路径列表或将分割后的名称映射到文件路径的字典。您还可以根据Unix shell使用的规则对与指定模式匹配的文件进行全局定位(例如,您可以通过设置’data_files=“*.JSON”‘将目录中的所有JSON文件作为单个拆分进行全局定位)。有关更多详细信息,请参阅🤗Datasets 文档。
Datasets实际上支持输入文件的自动解压,所以我们可以跳过使用
gzip,直接设置data_files参数传递压缩文件:1
2data_files = {"train": "SQuAD_it-train.json.gz", "test": "SQuAD_it-test.json.gz"}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")如果您不想手动解压缩许多 GZIP 文件,这会很有用。自动解压也适用于其他常见格式,如 ZIP 和 TAR,因此您只需将
data_files设置为压缩文件所在的路径,你就可以开始了!
Remote dataset
我们没有提供本地文件的路径, 而是将load_dataset()的data_files参数指向存储远程文件的一个或多个URL。例如, 对于托管在 GitHub 上的 SQuAD-it 数据集, 我们可以将 data_files 指向 SQuAD_it-*.json.gz 的网址,如下所示:
1 | |
这将返回和上面的本地例子相同的 DatasetDict 对象, 但省去了我们手动下载和解压 SQuAD_it-*.json.gz 文件的步骤。
Slice and dice
Slicing and dicing our data
- Datasets 提供了几个函数来操作 Dataset 和 DatasetDict 对象。
这一节的数据Demo: 我们将使用托管在加州大学欧文分校机器学习存储库的药物审查数据集,其中包含患者对各种药物的评论,以及正在治疗的病情和患者满意度的 10 星评级。
- 加载数据
1 | |
1 | |
- 抽取一个小的随机样本,以快速了解您正在处理的数据类型(shuffle + select)
1 | |
1 | |
- Data特点:
- Unnamed: 0这列看起来很像每个患者的匿名 ID。
- condition 这列包含有描述健康状况的标签。
- 评论长短不一,混合有 Python 行分隔符 (\r\n) 以及 HTML 字符代码,如**’**。
- 为了验证Unnamed: 0 列存储的是患者 ID的猜想,我们可以使用 Dataset.unique() 函数来验证匿名ID 的数量是否与拆分后每部分中的行数匹配:
1 | |
- 我们可以使用 **DatasetDict.rename_column()**函数一次性重命名DatasetDict中共有的列:
1 | |
1 | |
- 使用 **Dataset.map()**标准化所有 condition 标签
1 | |
Creating new columns
1 | |
然后进行排序
1 | |
向数据集添加新列的另一种方法是使用函数Dataset.add_column() 。这允许您输入Python 列表或 NumPy,在不适合使用Dataset.map()情况下可以很方便。
- 一些评论只包含一个词,虽然这对于情感分析来说可能没问题,但如果我们想要预测病情,这些评论可能并不适合。我们使用 Dataset.filter() 功能来删除包含少于 30 个单词的评论。与我们对 condition 列的处理相似,我们可以通过选取评论的长度高于此阈值来过滤掉非常短的评论:
1 | |
这已经从我们的原始训练和测试集中删除了大约 15% 的评论。
- 评论中存在 HTML 字符代码,我们可以使用 Python 的html模块取消这些字符的转义
1 | |
Dataset.map() 方法对于处理数据非常有用
Map() method’s superpowers
- Dataset.map() 方法有一个 batched 参数,如果设置为 True , map 函数将会分批执行所需要进行的操作(批量大小是可配置的,但默认为 1,000)。 当您在使用 Dataset.map()函数时指定 batched=True。该函数会接收一个包含数据集字段的字典,每个值都是一个列表,而不仅仅是单个值。Dataset.map() 的返回值应该是相同的:一个包含我们想要更新或添加到数据集中的字段的字典,字典的键是要添加的字段,字典的值是结果的列表。
1 | |
列表推导式通常比在同一代码中用 for 循环执行相同的代码更快,并且我们还通过同时访问多个元素而不是一个一个来处理来提高处理的速度。使用 Dataset.map() 和 batched=True 是加速的关键。
- “快速”标记器
1 | |
- Dataset.map() 也有一些自己的并行化能力。由于它们不受 Rust 的支持,因此慢速分词器的速度赶不上快速分词器,但它们仍然会更快一些(尤其是当您使用没有快速版本的分词器时)。要启用多处理,请在**Dataset.map()**时使用 num_proc 参数并指定要在调用中使用的进程数 :
1 | |
Others
- 其他内容其实已经不是重点了(包括上面的Datasets,最主要的部分,是前面几节,由不同的层拼出来具体的处理逻辑和pipeline)。