李宏毅深度学习课程
本文最后更新于:10 个月前
李沐老师的课程看完了!再来看看李宏毅老师的课程!温故而知新!多学习!
Machine Learning
Machine Learning 约等于 Looking for Function
cases: Audio2txt, img2txt, ….
Different types of IO
- Input: vector, matrix, sequence(speech, text)
- Output: scalar(regression), choice(classification), text
有很多种方法去教机器学!
- Classification -> Supervised Learning(监督学习)
- 但是监督学习需要的人工太多了,Self-supervised Learning(自监督学习), unlabeled images —Pre-train—> Develop general propose knowledge, Fine-tune可以在下游任务上表现出好的结果!!!Pre-trained Model又被称为Foundation Model.
- Generative Adversarial Network(GAN) -> 不需要手动标注太多!只需要找到x集合和y集合,不用标注(unpaired),机器就能够自动学习。
- 还有Unsupervised,无监督。也是类似的,不用找材料的对应关系,只要有足量的x和y,机器就能够学的很好。
- Reinforcement Learning(RL),你不知道具体是怎么样的,但是你知道“是好是坏”,这就是RL,你能够给予一些反馈给机器,而不是具体的x -> y的关系。
ML不只是追求正确率,还关注:
- Anomaly Detection: 机器在分类问题上,回答“我不知道”的能力。
- Explainable AI: 可解释性
- Model Attack: 模型攻击
- Domain Adaptation: 测试资料和训练资料分布很不一样,模型准确率暴跌
- Network Compression: 模型太大,压缩一把
- Life-long Learning: all-in-one ML,学习所有的东西!
- Meta Learning: Learn to Learn, Few-shot learning 和 meta-learning强相关. 机器自己会写算法???教会机器如何去学习,就可以做到few shots,很多人甚至会画上等号,few-shot就要用到meta-learning的技术。
Introduction of Machine/Deep Learning
ML
Introduction
ML: Find a function
Different types of functions
- Regression: The function outputs a scalar
- Classification: Give options(classes), the function outputs the correct one.
- Structure Learning -> create something with structure(image, document)
……
How to find the function?
- Function with Unknown Parameters, e.g. $y = wx + b$
- Define Loss From Training Data. (Loss is a function of parameters).
- Loss is a function of parameters, $L(b, w)$
- Loss: how good a set of values is.
- MAE, MSE, Cross-Entropy, …
- Optimization -> decrease loss
- Gradient Descent, …
- hyperparameters: learning rate, …
Sigmoid & Epoch
Linear Models are too simple… we need more sophisticated modes. Linear models have server limitation. Model Bias. We need a more flexible model!
- Approximate continuous curve by a piecewise linear curve
- Sigmoid Function
- New Model: More Features, consisting of sigmoid functions to approximate real function.
Some hyperparameters
- Batch: All the training data are too much, we don’t use all the data to do gradient descent, that costs too much. We divide data into batches, and use each “Batch” to do the gradient descent. 1 Update = update parameters once = 1 batch training.
- 1 Epoch = see all the batches once.
- e.g. Q: 10,000 examples(N = 10,000), Batch size is 10(B = 10), how many updates in 1 epoch? -> A: 1000 updates
Why Sigmoid? ReLU -> ReLU(Rectified Linear Unit) is “hard sigmoid”, and others. They’re called activated functions.
Neuron -> Neural Network, 可以一层有多个Neuron,也可以多层嵌套,组成复杂的神经网络结构,拟合复杂的函数和情况。
一些思考:Why we want “Deep” instead of “Fat” network? Fat也可以拟合很复杂的Functions啊!
Better on training data, worse on unseen data -> Overfitting
DL Concept
- Deep = Many Hidden Layers
- Just a new name, deep neural network too.
Pytorch
DL
- Ups and downs of Deep Learning
- 1958: Perceptron(linear model)
- 1969: Perceptron has limitation
- 1980s: Multi-layer perceptron -> Do not have significant difference from DNN today
- 1986: Backpropagation
- 1989: 1 hidder layer is “good enough”, why deep?
- 2006: RBM(Restricted Boltzmann Machine) initialization(breakthrough)
- 2009: GPU
- 2011: Better and better
- Three Steps for deep learning:
- Neural Network -> Given network structure, we define a function set. Define a good network structure is really important. Use Gradient Descent to find a good function.
- Goodness of function -> Loss function
- Pick the best function -> Minimize total loss(Gradient Descent)
- Deep = Many hidden layers, How many layers? How many neurons for each layer? Trial and Error + Intuition.
- DL的出现转换了问题,如何抽取features -> 如何定义一个好的neural network.
- 越多的参数,可以覆盖的function set越大,找到越好的function的可能性也就越大,效果越好也就是在预料之中啊。Why deeper is better, why not fat?
Backpropagation
- Chain Rule is core of back propagation
- 建议全部看看哈,这里的计算讲的非常清楚昂!!!
- Backpropagation需要Forward pass和Backward pass两步,综合起来才能够完成。
- Forward pass: 从前往后,每一个的神经元的输入,就是当前神经元对于上一个神经元的Forward pass
- Backward pass: 从后往前,和上面类似,反推。
- 这么看来,就是前往后,后往前,计算量其实是一样的。通过前往后 + 后往前,就能够算的出来某一层的偏微分,就能够更新了哈!
- Backpropagation需要Forward pass和Backward pass两步,综合起来才能够完成。
Regression Prediction Problem
Pokemon Regression Task
Loss function: Input is a function, output is a value telling how bad the function is. $L(f) = L(w,b)$
More complex model doen’t always lead to better performance on testing data -> Overfitting -> Select suitable model
缓解overfitting的技巧
- 删掉一些没用的features,防止过拟合。
- 损失函数加上一个正则项,Regularization
Regularization,正则项的系数$\lambda$是我们手动调整的。让$w$尽可能的小,越小越平滑!模型越平滑,对于输入越不敏感,输入的噪声也对于函数的影响小,模型拟合效果就越好!We prefer smooth function, but don’t be too smooth. 做正则化的过程中,也不需要考虑$b$,因为它对于模型的平滑程度是没有影响的。
Classification: Probabilistic Generative Model
Plz see the lession vedio,涉及到了好多概率论相关的知识,贝叶斯,高斯分布,极大似然估计等,很有意思!但是要有概率论的部分基础哈,还要有线性代数和微积分的昂!x -> Function -> Class n
贝叶斯本质上就是一个Generative Model哇!
Linear Regression可以用在Classification的问题上吗?可以,但是不好! -> Penalize to the examples that are “too correct”,会惩罚那些离分界线远的点,但是那些点正确性强!导致预测的分解会有偏移昂!
Linear Regression不太适用于分类问题哈
Logistic Regression
- 专门用来处理二分类问题
Probabilistic Generative Model -> Logistic Regression
MSE没有交叉熵好的理由:使用MSE算出来的梯度,离目标很近,微分是0,离目标很远,微分也是0,几乎学不动orz。很难找到结果,但是Cross-Entropy,距离目标越远,梯度越大,就很容易能够找到很好的结果昂!Changing the loss function can change the difficulty of optimization.
Dicriminative vs Generative
- Logistic Regression: Dicriminative
- Gauss Probability: Generative(当二分类两个变量共享covariance matrix时候,这两者是一致的)
本质表达的是同一个model,同样的function set,去寻找$w$和$b$。因为假设不一样,所以找出来的结果也会不一样,但是都make sense。The same model(function set), but different function is selected by the same training data. Discriminative的效果,看起来比Generative Model要好一些昂!!!
数据少的时候,Generative Model的效果可能就会更好(脑补),它做的一些假设(例如Naive Bayes),就适用于数据量少的情况(或者数据里有噪音的时候)。但是Logistic是看数据说话,数据少的时候,就不太好,数据量大的时候,Logistic就work。
Multi-class Classification
二分类使用了Sigmoid,多分类使用了Softmax,使用的损失函数是Cross-entropy。Minimizing cross-entropy is equivalent to maximizing likelihood.
Cross-entropy相较于MSE是更加常用于Classfication问题上的,常用到在pytorch里面,Cross-entropy和Softmax是绑定在一起的。只要call Cross-entropy,内部就自动内建了Softmax。
One-hot编码?不用one-hot编码可能会造成歧义,例如0,1,2三类,0和2两类的区别从数字层面上来看,会“比较大”。
Limitation of Logistic Regression:
- Logistic Regression本质上是一个线性分类器,两个class之间的boundary就是一条直线,对于一些特殊的分类情况做不到哈。
- 如果你非要想用怎么办?Feature Transformation,按照处理后的feature,把不同的类尽量放在空间中不同的部分,使其使用Logistic Regression可以很好的“线性分类”。Not always easy to find a good transformation to use logistic regression.
怎么办?把很多Logistic Regression Cascade起来,然后自己去学!找一个好的Transformation!
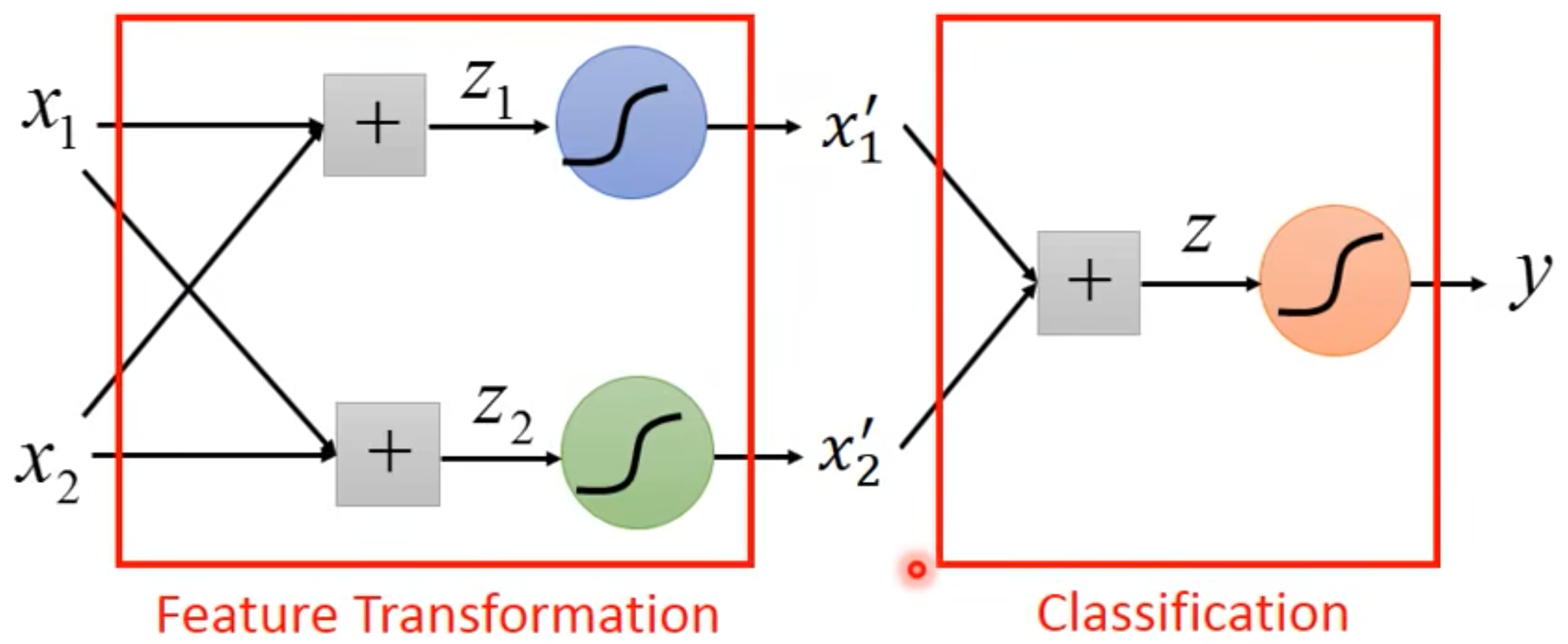
叠加逻辑回归层,使得x特征不断进行Transformation,使其明显易分类。
- 为什么二分类用Sigmoid函数,多分类用Softmax函数呢? -> 本质是一模一样的!
Machine Learning Strategy - General Guide
Framework of ML: Input -> Function -> Output
- Function with unknown
- Define loss from training data
- Optimization
loss on training data
- large(训练资料没有学好)
- model bias -> 模型太简单,function set里面就没有包含好的function,那没办法找到好的function哇。Redesign your model to make it more flexible.
- optimization -> Gradient Descent有许多问题,例如被限制在local minima,没办法在一个包含较好结果的function set上,找到一个好的function。
- 怎么判断是哪种呢?可以通过比较不同模型,来比较function set够不够大捏!**Gaining the insights from comparison.**(例如56-layer和20-layer的模型对比效果)
- Start from shallower networks(or other models), which are easier to optimize. If deeper networks do not obtain smaller loss on training data,then there is optimization issue.
- Solution:More powerful optimization technology (next lecture)
- small
- loss on testing data
- small -> done
- large
- overfitting -> more training data/data augmentation/make your model simpler
- mismatch: 和overfitting不一样,测试资料和训练资料不一样昂!
- loss on testing data
- large(训练资料没有学好)
Overfitting: Small loss on training data,large loss on testing
data. Why? -> “Freestyle”- More training data
- Data Augmentation(agument要有道理,你拿一只猫猫照片反过来喂给model是不是就有点抽象???)
- Less “Freestyle” -> 更简单的模型或者是更多的限制,function set就有限啦!
- Less parameters, sharing parameters
- Less features
- Early stopping
- Regularization
- Dropout
- 如果模型限制太多,例如一个二次模型,给了一个一次函数,死活都拟合不好哇。Back to model bias……
Bias-Complexity Trade-off -> 你应该如何找一个比较合适的model呢?
- 去Kaggle上,对着public testing set刷分数,看看哪个模型好。但是这个是不make sense的,低效,并且有次数限制,而且!也不一定是准确的,public上好,private也不一定好哇。
- Training Set -> Training Set(90%) + Validation Set(10%),根据你自己本地的Validation Set的结果,去挑选好的模型,然后再上传到Kaggle上康康捏!
- Using the results of public testing data to select your model. You are making public set better than private set. 所以从这个角度来看,我们完全在看Trainging Data,而不是Testing data的结果(不管是Public还是Private)。这样能够消除,我们“偏袒于” public tesing training set.
这里的结构其实是:
- Trainging Data
- Training set
- Validation set
- Testing Data
- Public testing set
- Private testing set
- Trainging Data
如果我的Validation Set选的不好怎么办呢? -> N-fold Cross Validation.
- 把Training Data切分为n份,把一份儿当作Validation Set,其他当作Training Set。
- 这种操作,重复n次。每次把第n份当作Validation set,其他都当作Training set.
- 把所有的模型,对于n组不同的Training Set和Validation Set,分别跑n次,然后算个Avg或者别的指标也好,看看哪个model的效果最好。然后再交上去,用到testing set上!
Mismatch: Your training and testing data have different distributions.
类神经网络Train不起来怎么办
When gradient is small
- Trainging loss. Gradient is close to zero, result is not well:
- 一开始loss就不往下走
- loss往下走了,但是收敛后发现。Not small enough
例如:卡住的点叫做critical point: local minima/maxima, saddle point等。注意!卡住的点不一定就是local minima昂!!!
- critical point如何辨别local minima还是saddle point呢?-> 利用泰勒展开,判断这个点周围的值和它的关系。(这里用到了Hessian矩阵)
- H is positive definite = All eigen values are positive -> Local minima
- H is negative definite = All eigen values are negative -> Local maxima
- Some eigen values are positive, and some are negative. -> Saddle point
- 如果是Saddle point,那么还好!可以解决!H may tell us parameter update direction!, 找到负的eigen value,算出eigen vector,这就是此时梯度可以继续减小的方向。You can escape the saddle point and decrease the loss. -> This method is seldom used in practice, 运算量太大了。那有什么别的方法,如何逃离saddle point?
微积分 + 线性代数
- Saddle Point v.s. Local Minima -> Saddle Point的数量比local minima常见的多!因为feature太多了,导致paddle point非常常见,反而local minima不好找昂!
Tips for training: Batch and Momentum
Batch
$\theta^{*} = argmin_{\theta}L$,我们只会拿一个Batch的资料,算一个Loss,然后更新一次Parameter。1 epoch = see all the batches once -> shuffle after each epoch
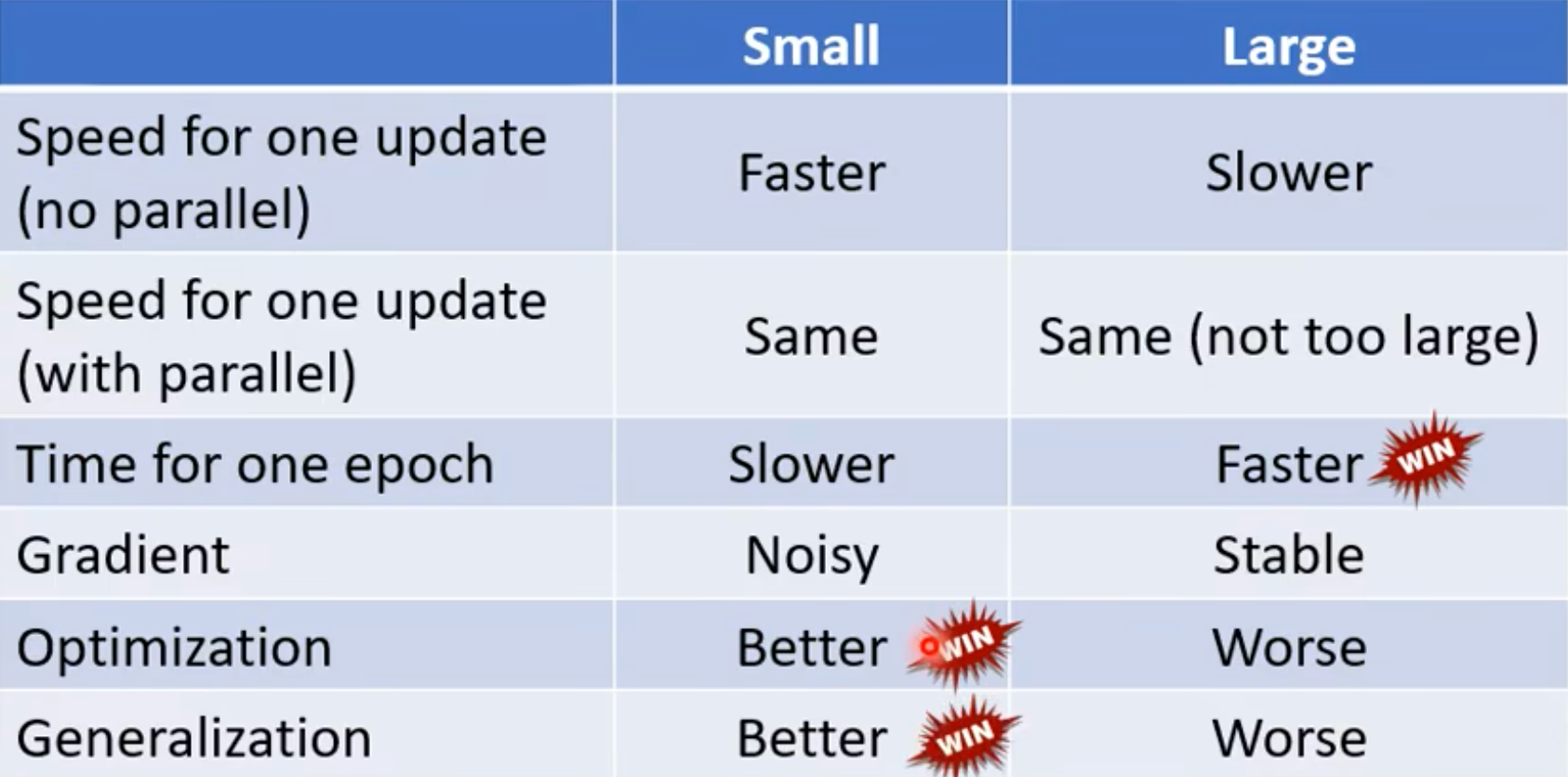
为什么需要Batch, Small Batch v.s. Large Batch
- Batch size = N (Full Batch) -> Update after seeing all the examples. ->
Long time for cooldown, but powerful. - Batch size = 1 -> Update for each example. ->
Short time for cooldown, but noisy. - Noisy反而可能会更加有利于Training. Smaller batch size has better performance, What’s wrong with large batch size? Optimization Fails. 小的batch带来的噪音,可能有利于“越过”local minima。
- Small batch is better on testing data? 小的batch比大的batch好,overfitting!Why? -> 好的和坏的local minima,越平滑的local minima越好,平滑才可以困住small batch,big batch很容易就被尖锐的local minima困住了,导致如果测试和训练数据有一定的偏差,效果就不好昂!
- Batch size = N (Full Batch) -> Update after seeing all the examples. ->
Momentum
- 这一步的梯度,加上上一步的方向,加权矢量叠加,然后往后走!
- Movement:movement of last step minus gradient at present. 也有别的说法,例如之前走的所有的加权 + 现在的梯度合起来!但是不管怎么说呢,都是一定程度上保留过去的影响!
Tips for training: Adaptive Learning Rate
本质上就是一条公式:$\theta_{i}^{t + 1} \leftarrow \theta_{i}^{t} - \frac{\eta^{t}}{\sigma_{i}^{t}}m_{i}^{t}$,每次更新迭代的时候,会根据一些策略,算出具体的本次学习率。
Training stuck不一定等于Small gradient,Training Loss不动了,但是可能梯度依然很大!
Learning rate can not be one-size-fits-all
常见方法,本质是去更新$\sigma_{i}^{t}$,本质是在根据之前的Gradient Descend,对于目前的Learning Rate,进行放缩。
- Root Mean Square -> Used in Adagrad,每个gradient有同等的重要性!
- RMSProp -> Learning rate adapts dynamically: smaller learning rate, larger gradient. Larger learning rate, smaller gradient. 加权现在的gradient和之前的影响!
Leaning Rate Scheduling,这个是去更新$\eta^{t}$,
- Learning Rate Decay: As the training goes,we are closer to the destination,so we reduce the learning rate.
- Warm Up: Increase and then decrease? At the beginning, the estimate of $\sigma^{t}_{i}$ has large variance.
Adam: RMSProp + Momentum,Pytorch里面预设的参数就够好了,可能不需要你再去手动调整了昂!
momentum和adaptive learning rate的对比,$\theta_{i}^{t + 1} \leftarrow \theta_{i}^{t} - \frac{\eta^{t}}{\sigma_{i}^{t}}m_{i}^{t}$:
$m_{i}^{t}$,Gradient + Momentum: weighted sum of the previous gradients. Consider direction,你的小球往哪儿滚!
$\sigma_{i}^{t}$: root mean square of the gradients. Only magnitude,只考虑learning rate的大小!
$\eta^{t}$: Learning rate sheduling,随着时间的变化进行调整!
Pokemon demo带给我们的别的启示
Pokemon Demo Plus,看看这个哈!
Result
- The following discussion is model-agnostic.
- In the following discussion, we don’t have assumption about data distribution.
- In the following discussion, we can use any loss function.
这里有一个抽取到好的训练资料和坏的训练资料的计算比例公式,可以详细看看昂!衡量有限数据集上,得到的模型效果和真实世界中的模型效果的Balance。抽取到的数据集,抽取数据集的大小,全部数据的大小和期望的误差等,都会对于这个计算造成影响!
Model Complexity -> The number of possible functions you can select
- Answer1: Everything that happens in a computer is discrete.
- Answer2: VC-dimension (not this course)
Tradeoff of Model Complexity -> Gradient Descent
New Optimizers for Deep Learning
- Now learned
- SGD: Gradient直接反方向走就ok了
- SGD with momentum(SGDM): 用到momentum,算gradient,然后叠加gradient和momentum,更新momentum的值!
- Adagrad: SGD的学习率,加个分母。Root Mean Square
- RMSProp: 唯一的区别在于,分母的算法不太一样,不是Root Mean Square,而是加权了之前的gradient和当前的gradient。
- Adam: SGDM + RMSProp,综合Momentum和学习率的调整。还采用了类似于de-biasing的技术,保证Momentum的值随着上面加权的变化,不会变的太多,相对稳定!
Adaptive learning rate: Adagrad, RMSProp and Adam.
Adam vs SGDM
- Adam fast training,large generalization gap, unstable
- SGDM stable,little generalization gap,better convergence
- Combinition: Begin with Adam(fast), end with SGDM -> SWATS. Start Training –Adam–> Meet some criteria(Learning rate initialization) –SGDM–> Convergence
In the final stage of training,most gradients are small and non-informative,while some mini-batches provide large informative gradient rarely.
Towards Improving Adam
- In the final stage of training,most gradients are small and non-informative,while some mini-batches provide large informative gradient rarely.
- Non-informative gradients contribute more than informative gradients
- AMSGrad:
- Reduce the influence of non-informative gradients
- Remove de-biasing due to the max operation
- Monotonically decreasing learning rate
- Remember Adagrad vs RMSProp?
- AMSGrad only handles large learning rates
- AdaBound -> Handle large and small at the same time.
Towards Improving SGDM…
- Adaptive learning rate algorithms dynamically
adjust learning rate over time - SGD-type algorithms fix learning rate for all updates…too slow for small learning rates and bad result for large learning rates
There might be a “best” learning rate
- LR Range Test
- Cyclical LR
- learning rate decide by LR range test
- stepsize several epochs
- avoid local minimum by varying learning rate
- SGDR
- One-cycle LR: warm-up + annealing + find-tuning
- Adaptive learning rate algorithms dynamically
Does Adam need warm-up?
- Experiments show that the gradient distribution distorted in the first 10 steps
- Distorted gradient -> distorted EMA squared gradients -> Bad learning rate
- Keep your step size small at the beginning of training helps to reduce the variance of the gradients -> Too big:overshoot and even diverge
- Adam:
- effective memory size of EMA
- max memory size
RAdam vs SWATS

k step forward, 1 step back. Lookahead: universal wrapper for all optimizers.
Nesterov accelerated gradient(NAG)
AdamW & SGDW with momentum(重要的会被使用的),AdamW在BERT中经常被使用!L2 regurization or weight decay?
Something helps optimization…
- Shuffling
- Dropout
- Gradient noise
The more exploration, the better!
- Warm-up
- Curriculum learning (Train your model with easy data(e.g.clean voice) first, then difficult data. Perhaps helps to improve generalization)
- Fine-tuning
Teach your model patiently!
- Normalization
- Regularization
What we learn, SGD & Adam Improvement
- Team SGD
- SGD
- SGDM
- Learning rate scheduling
- NAG
- SGDWM
- Team Adam
- Adagrad
- RMSProp
- Adam
- AMSGrad, AdaBound(Extreme values of learning rate)
- Learning rate scheduling
- RAdam
- Nadam
- AdamW
- Combination
- SWATS
- 万能方法
- Lookahead
- Team SGD
What we learn, SGD & Adam Comparison
- SGDM
- Slow
- Better convergence
- Stable
- Smaller generalization gap
- Adam
- Fast
- Possibly non-convergence
- Unstable
- Larger generalization gap
- SGDM
Advices
- SGDM
- Computer vision
- image classification
- segmentation
- object detection
- Computer vision
- Adam
- NLP
- QA
- machine translation
- summary
- Speech synthesis
- GAN
- Reinforcement learning
- NLP
- SGDM
Universal Optimizer? No Way!!!
Why Deep Learning
- Activation Function
- Hard Sigmoid -> ReLU
- Sigmoid
Piecewise linear = constant + sum of a set of Sigmoid/Hard Sigmoid function
- Why “Deep”, not “Fat”? Deeper is Better! -> 实验看出来确实,原理呢?One hidden layer can represent any function. However, using deep structure is more effective. Deep只需要较少的参数 or 较少的训练参数,就能够达到比较好的效果。
Analogy: Logic Circuits, parity check就是这个样子的昂!
Analogy: Programming. Don’t put everything in your main function.
- Comparison
- Deep: k layers, 2k neurons, $2^k$ pieces.
- Shallow: 1 layer, $2^k$ neurons, $2^k$ pieces.
复杂模型,大量资料和Overfitting之间是有取舍的昂!!!
- Deep networks outperforms shallow ones when the required functions are complex ard regular. (Image, speech, etc. have the characteristics)
Network Architecture
CNN
Fully connected —> too many parameters.
Simplification Way
- 看一小部分的图片就足够啦!不一定每个neruon要去看全部的图片昂!Receptive Field我们自己安排!但是有一些Typical Setting
- 一般要看就看全部的channel哈。
- Kernel size就是我们看的区域的大小,一般都是3x3,7x7或者9x9就算比较大的啦!
- Each receptive field has a set of neurons
- stride用来移动kernel的昂!一般都是1或者2,不希望太大哈。太大不利于检测一些特征。
- 如果超出范围了怎么办呢?Padding,补充为0!
- 按照上面的配置,整张扫过去!
- The Same patterns appear in different regions.
- 不同的receptive field可以共享参数!虽然看到的receptive field可能是不一样的,但是参数是一模一样的!输入不同,所以输出不同!
- Two neurons with the same receptive field would not share parameters.
- Each receptive field has a set of neurons (e.g.,64 neurons). Each receptive field has the neurons with the same set of parameters. 同组的参数就叫做filter!
- Pooling
- 主要是做Subsampling,减少运算量,Subsampling the pixels will not change the object. 例如可以在一个pixel小矩阵中,拿掉一些信息,表达的还是同一个物体,但是会小!
- Max Pooling,没有要Learn的东西。相当于特征压缩一样?可能对于图片有损害,对于图片非常微细的东西。
- Convolution之后往往就要接上Pooling,这两者往往交替使用。
- 近些年用的也少了,因为算力在不断增加捏!有很多压根不用Pooling捏!
- 看一小部分的图片就足够啦!不一定每个neruon要去看全部的图片昂!Receptive Field我们自己安排!但是有一些Typical Setting
Receptive Field + Parameter Sharing = Convolutional Layer, Some patterns are much smaller than the whole image. The same patterns appear in different regions.
图片通过filter,产出的结果就是feature map。channels的数量是由filter的数量决定的啦!通过不同层之间,filter层之间的叠加,相当于一张图片,在不断的进行”Transformation”,生成新的图像,最终拿到结果 -> Each filter convolves over the input image. Filter就相当于是Neruon!
常见方法:Convolution + Pooling + Flatten + Fully Connected Layers(Softmax) -> Classification
Alpha Go就是可以用CNN来做!下围棋其实也可以当作一个19 x 19的分类问题!或者说看作一个图片也可以哇!而且!下围棋和图片也有点类似,局部就可以做出很多决策!像围棋这种场景,Pooling来进行Subsampling就不适用,围棋很精细,不能丢失哪怕一点点信息哈!
More Applications: Speech, NLP. 如果这么使用的话,CNN的特性是不是符合你的应用场景,不能硬用哈。可以改一改,或者用别的,总之要符合!
CNN is not invariant to scaling and rotation(we need data augmentation). 放大后的图像,向量输入进去之后,CNN看起来可能就和原来完全不一样,这就是为啥我们要使用data augumentation. 那有没有能处理的呢?还真有!Spatial Transformer Layer
Spatial Transformer
- 这个layer就可以专门做scaling and rotation, 本质也是一个NN,End-to-end learn的昂!就放在CNN前面,和CNN一起训练就行!
- Image Transformation: Expansion, Compression, Translation. 6 parameters to describe the affine transformation. 本质是线性代数那一套,乘法和加法嘛!对于原始pixel的每一个(x, y),乘上一个2 x 2matrix,再加上一个2 x 1的matrix,六个参数,就可以完成一个矩阵的转换!
- 但是上面的转换,不一定work,如果算出来是一个处于“中间”的点呢?Interpolation,这样才能用Gradient Descent去解哈!
- Spatial Transformer可以混合使用,不同的conv之间也可以,不同的conv之间,甚至用多个Spatial Transformer都可以的昂!
Self-Attention
Input is a vector -> Input is a set of vectors
如何用向量表示词汇:
- One-hot Encoding: 有问题,忽视了不同词汇之间的关系!One-hot就是假设词汇之间没有任何关系的!
- Word Embedding: 给每一个词汇一个向量,近义词之间可能是有一定向量关系的!
Output
- Each vector has a label
- The whole sentence has a label
- Seq2seq
Each vector has a label -> Sequence Labeling
- Is it possible to consider the context? -> 一次不要只丢进去一个值,应该是一个值带上前后context,把一个”window”里面的东西都丢进去昂!
- 但是仍然不够好,How to consider the whole sequence? -> Self-attention
Self-attention作为一个中间层,所有的输入都过这个层,然后拿到输出昂!Self-attention就可以考虑整个sequence昂!Self-Attention的使用也可以叠加,例如和Fully Connected Network交替使用。
Graph
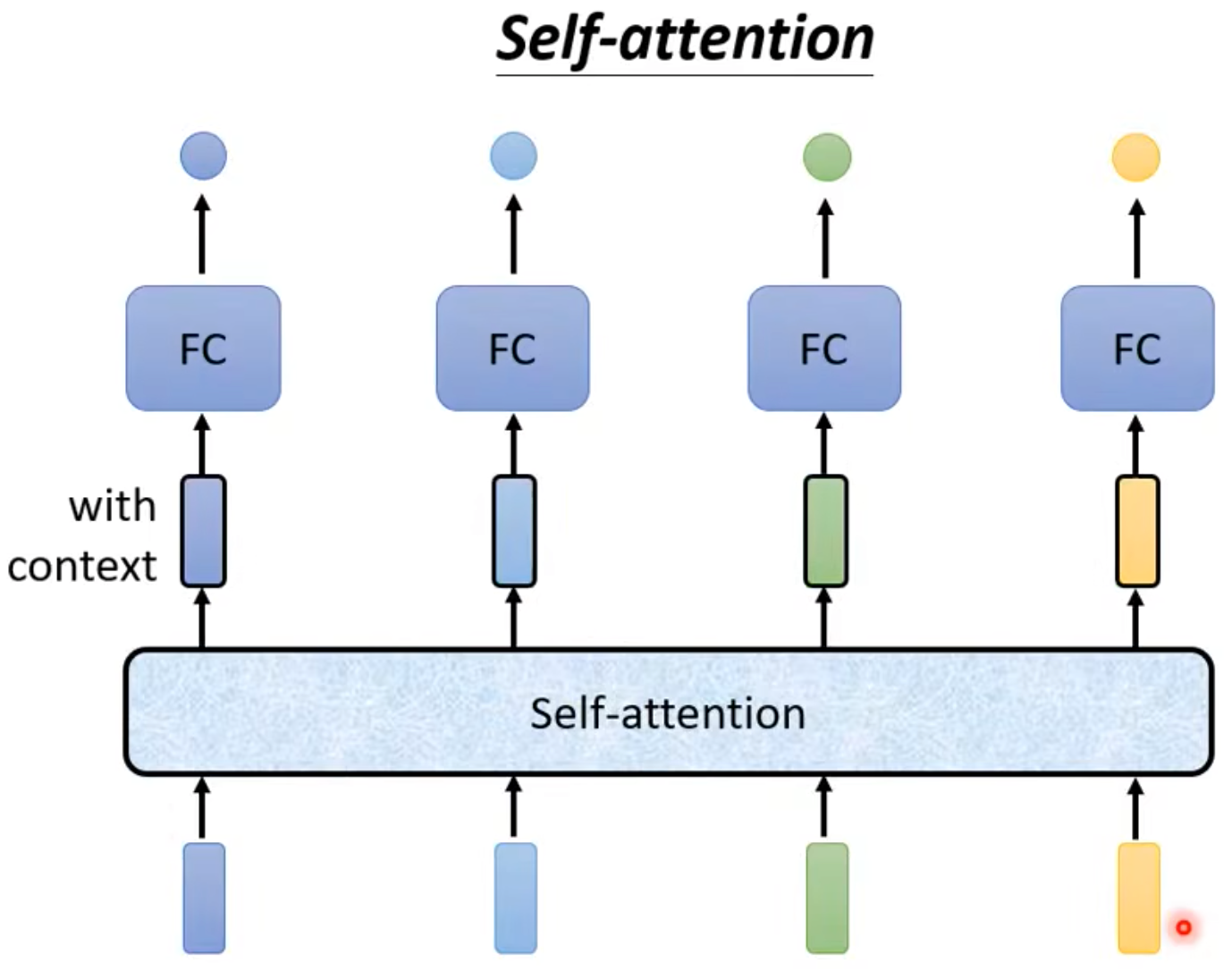
Self-attention details:
Input could be either input or a hidden layer.
Each output takes all the inputs into consideration.
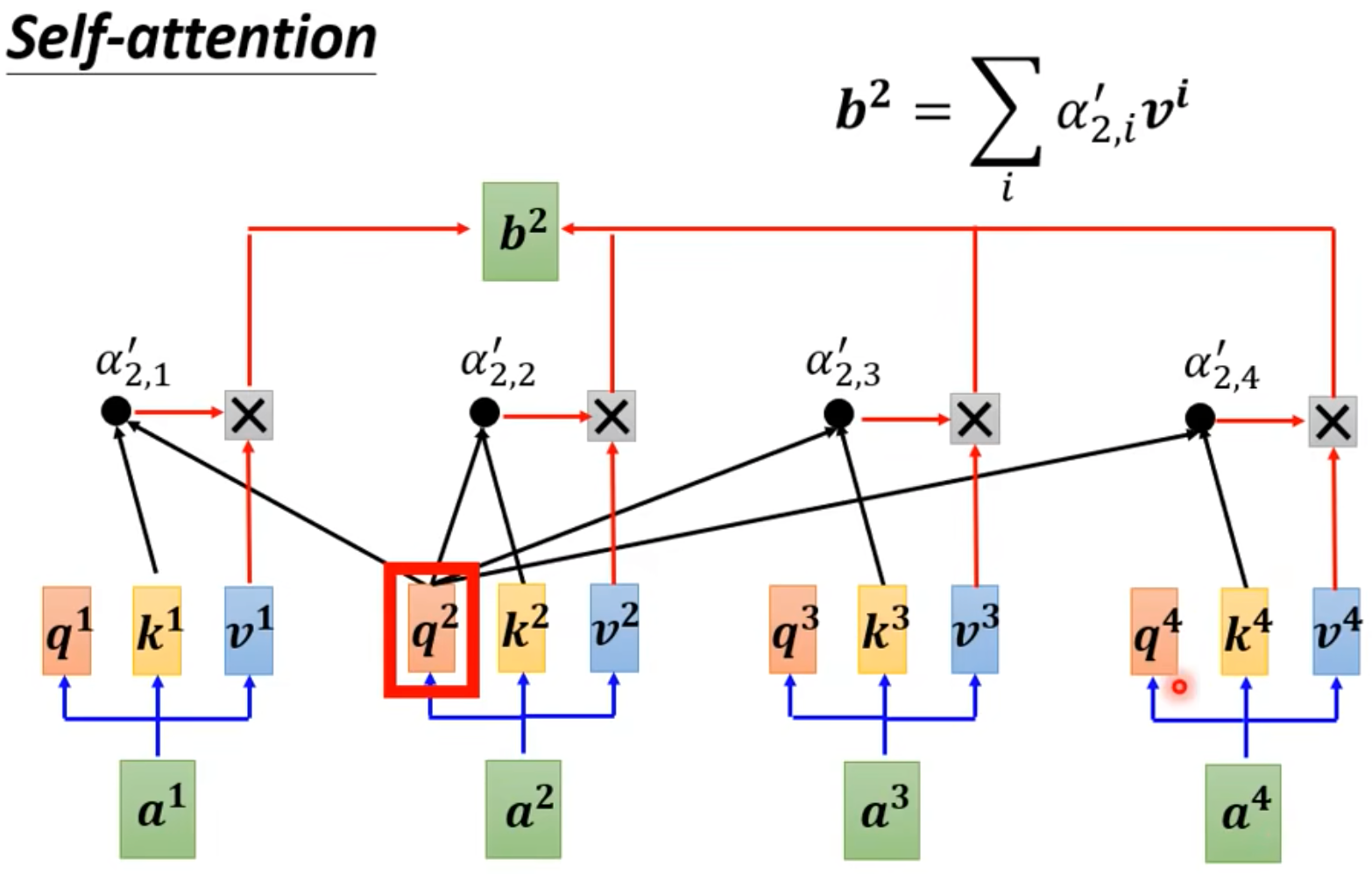
Steps:
- 根据Input,算出来其他的向量和当前向量的relevance。如何计算这个relevance呢?-> Dot-product/Additive等等!Dot-product是最常用的昂!
- 当前输入和其他所有的输入(包括自己),算一个关联性,然后塞进Softmax里面(也可以是别的)。
- 然后根据上面拿到的关联性,从每个Input抽取重要的咨询(乘上attention的分数),然后加起来。谁的attention的值更大,谁的值就被多抽出来一些捏!
计算过程中,所有的Output的向量是可以并行计算的哈,可以一次就被计算出来哈!
线性代数!
$$
I\ is \ input\ matrix \
Q = W^q I \
K = W^k I \
V = W^v I \
\
A = K^T Q \
A^{‘} = softmax(A),这个就是我们传说中的Attention Matrix \
O = VA^{‘} \
O\ is\ output\ matrix
$$- Q, W, V是未知的,需要我们找出来的,其他都不需要学习哈!
If input sequence is length L, attention matrix size is L x L,L很大的话,计算量就很大,就不容易处理或者处理! -> Truncated Self-attention,可能只看一部分,就有足够的效果!
Self-attention for image
- 一张图片的一个pixel,由RGB,可以看作是一个三维的vector,其实也是一个vector set呀,那就可以用self-attention啦!
Self-attention v.s. CNN
- Self-attention考虑全局整个图片。Self-attention is the complex version of CNN. 而且这个Attention,是模型自动学出来的昂!
- CNN是考虑receptive field,self-attention that can only attends in a receptive field. CNN is simplified self-attention.
- Paper “On the Replationship between Self-Attention and Convolutional Layers”, CNN是一种特殊的Self-attention, Self-attention可以做到和CNN一样的效果。子集!
- 这也就意味着,Self-Attention更加复杂!更多的训练资料,效果会比CNN更好!能表达的function set更大。
Self-attention for Graph:
- Consider edge: only attention to connected nodes
- edge本身就是attention的一种体现形式啊,也许你可以直接用edge来实现attention对不,没有连接的节点我们就认为它没有attention呗!Attention Matrix
- This is one type of Graph Neural Network(GNN).
Papers:
- Long Range Arena: A Benchmark for Efficient Transformers
- Efficient Transformers: A Survey
- 有时候广义的Transformer,讲的就是Self-attention。如何减少Self-attention的运算量,也是将来的一个重点!
Multi-head Self-Attetion
Different types of relevance
- Q就是用来找Attention的捏!不同的Q,可以找到不同的Attention信息!所以Multi-head,可以有多个不同的Q,找到不同的相关性!Q, W, V是配套的哈,多个Q,意味着对应计算的W, V也都多个!
- 计算的时候,Multi-head分别计算哈,并行!
Positional Encoding
- No position information in self-attention.
- Each position has a unique positional vector $e^i$,用这个$e^i$加上原先的输入$a^{i}$,就ok啦!
- hand-crafted是可能有很多问题的,例如:sin, cos。没有定数,甚至可以是learned from data的捏!
RNN
RNN的角色可以用Self-attention取代哈,不细讲!
- RNN也是适用于Input Sequence的情况,有一个类似于Memory的Matrix,记录记忆信息!
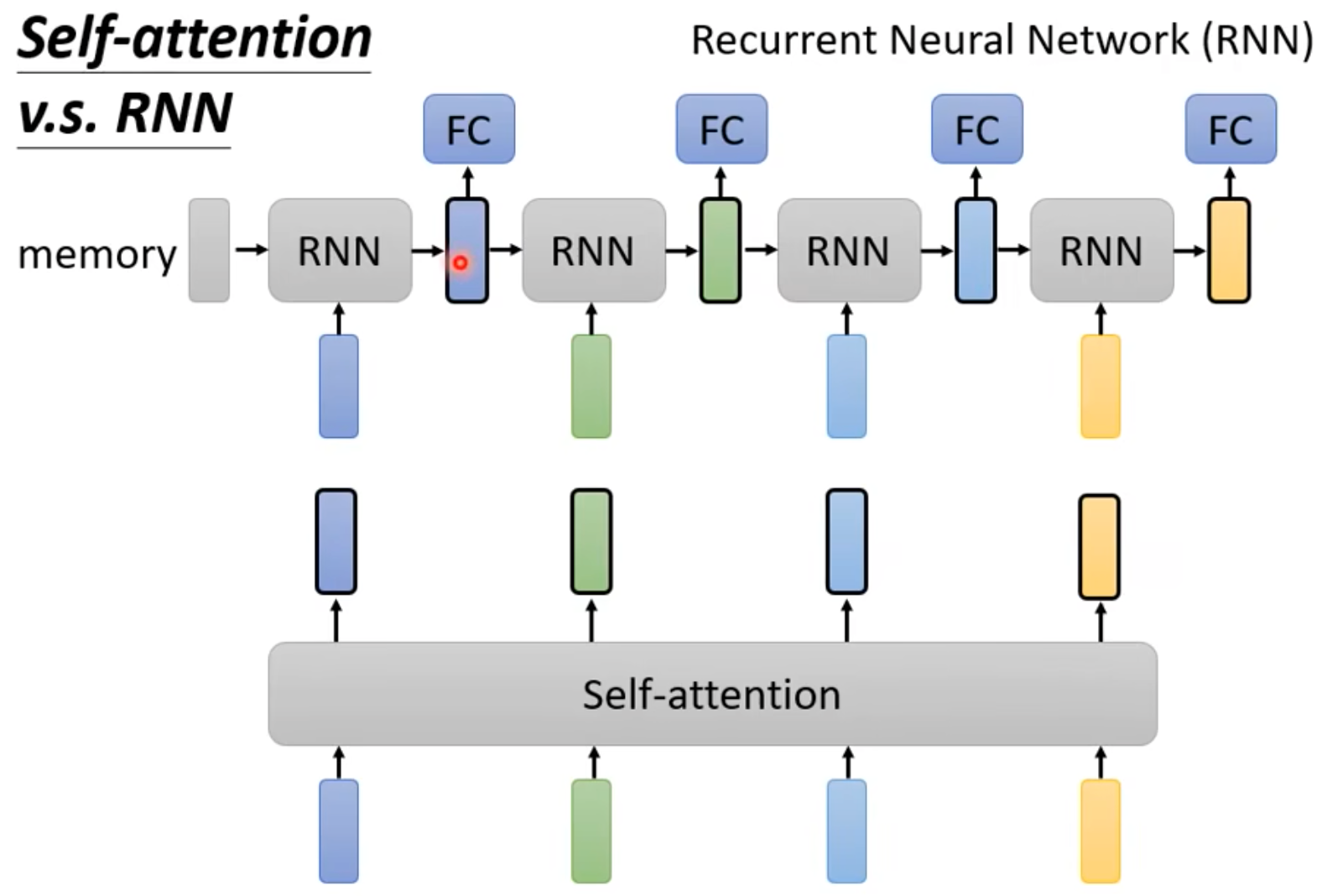
- RNN也可以是双向的哈,从某种程度上来说,双向RNN也和Self-attention一样,考虑了整个sequence的信息!
- RNN vs. Self-attention
- 如果前后的Input隔的比较远,信息要存在memory里面,逐步从前传递到后面,可能还会遗忘,就不好考虑哈!
- Self-attention没有这个问题,不管多远的前后input,直接一把算,都一样,天涯若比邻!
- RNN没办法并行哈,前后顺序,没办法平行处理!但是Self-attention是可以的哈!并行运算,嘎嘎快!
- 很多research都逐步把RNN改为self-attention了哈!
Paper: “Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention”
- Recurrent Neural Network,输入sequence是有先后顺序的哈!不是简简单单,就能够调换顺序的,和图像识别之类的不一样的昂!
- Network also can be deep! 中间存的”memory”可以很多昂!
- Elman Network & Jordan Network
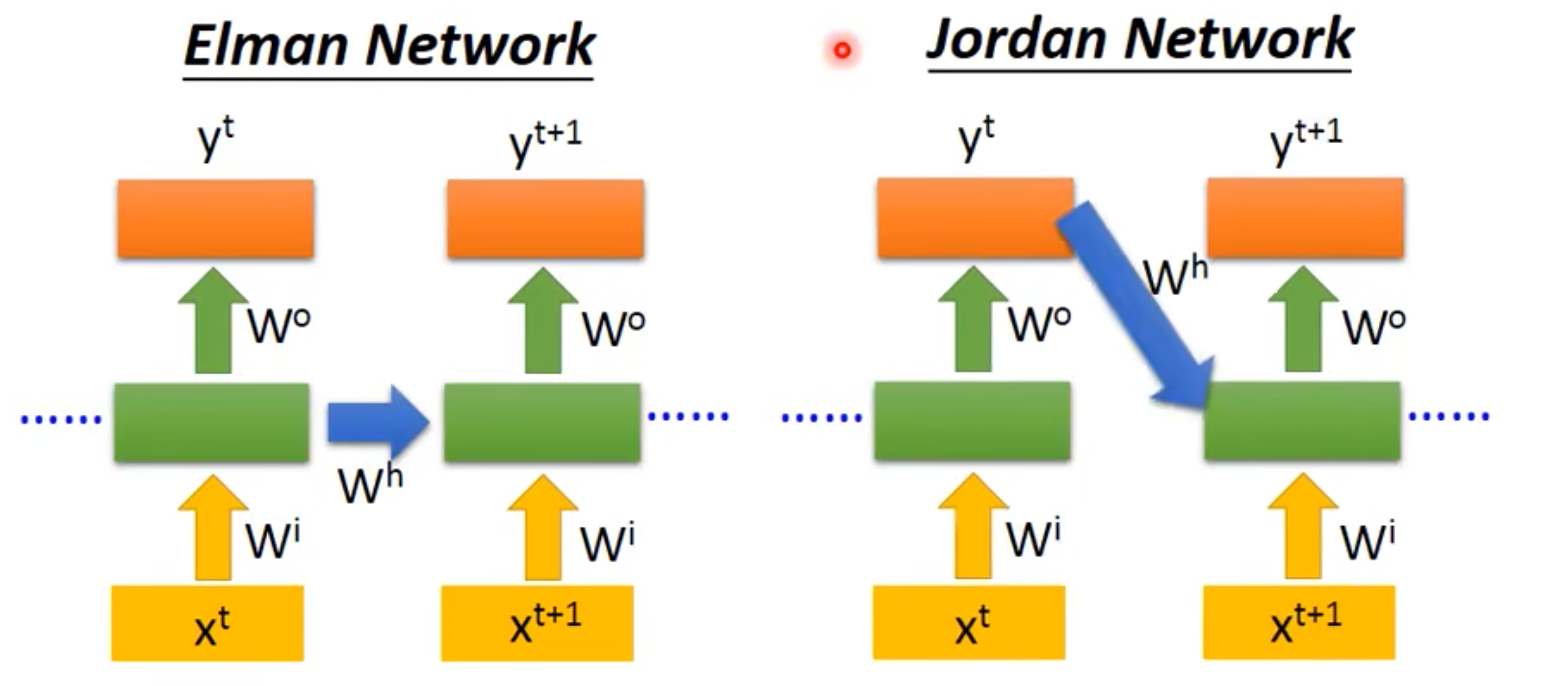
Jordan Network传说可以得到较好的结果,因为Jordan可以看到存的是输出,输出是有target的,存的东西相对清楚。但是Elman在中间,难控制学到了什么。
Bidirectional RNN
- Bidirectional RNN: 双向去train!双向可以同时看到前面和后面的内容!
LSTM
Long Short-term Memory
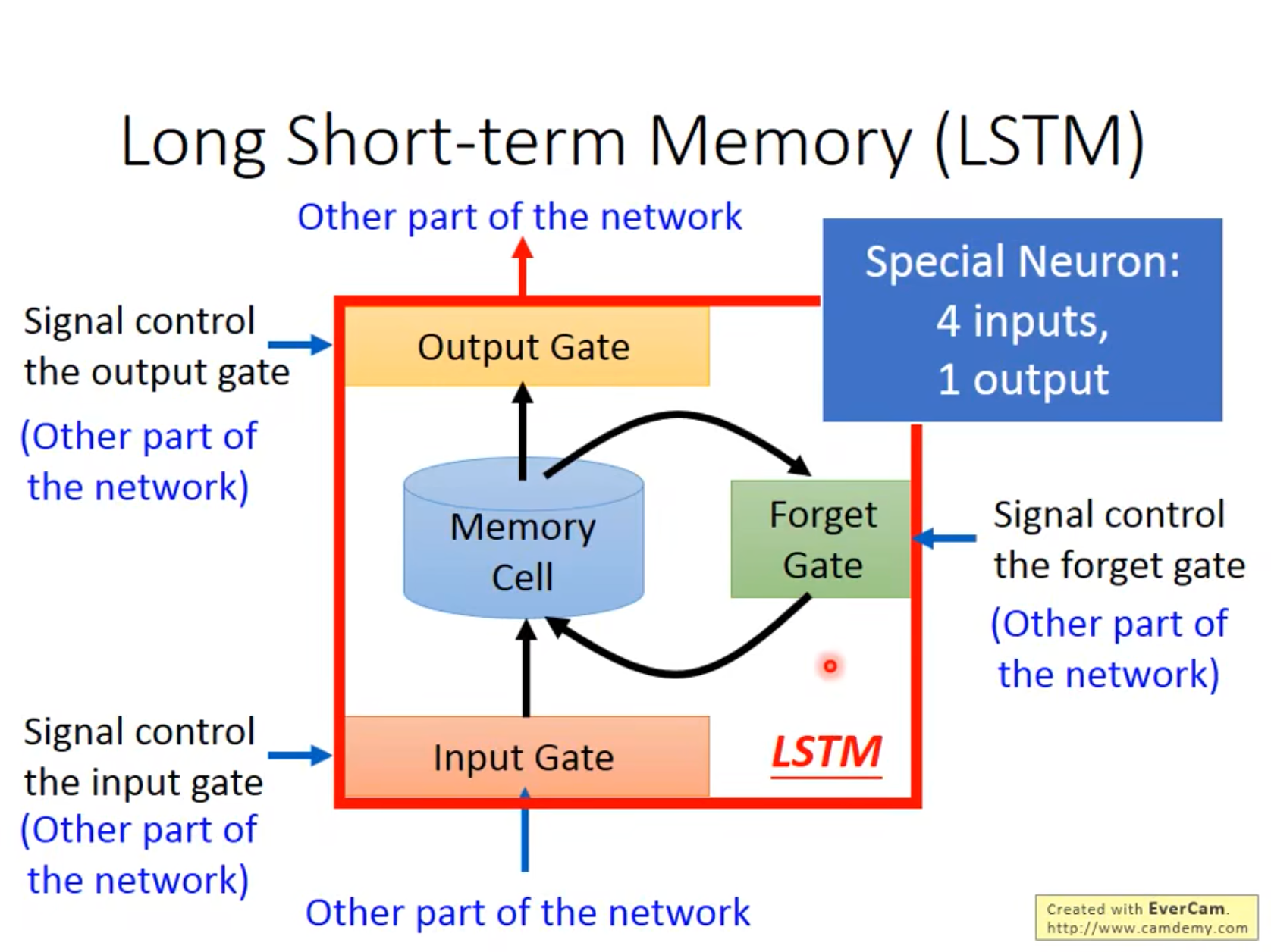
- 4个input: Original Input + 3 Signals to control different gates,这几个Signal对应的f是sigmoid function,好处是从0到1,代表“门被打开的程度”。
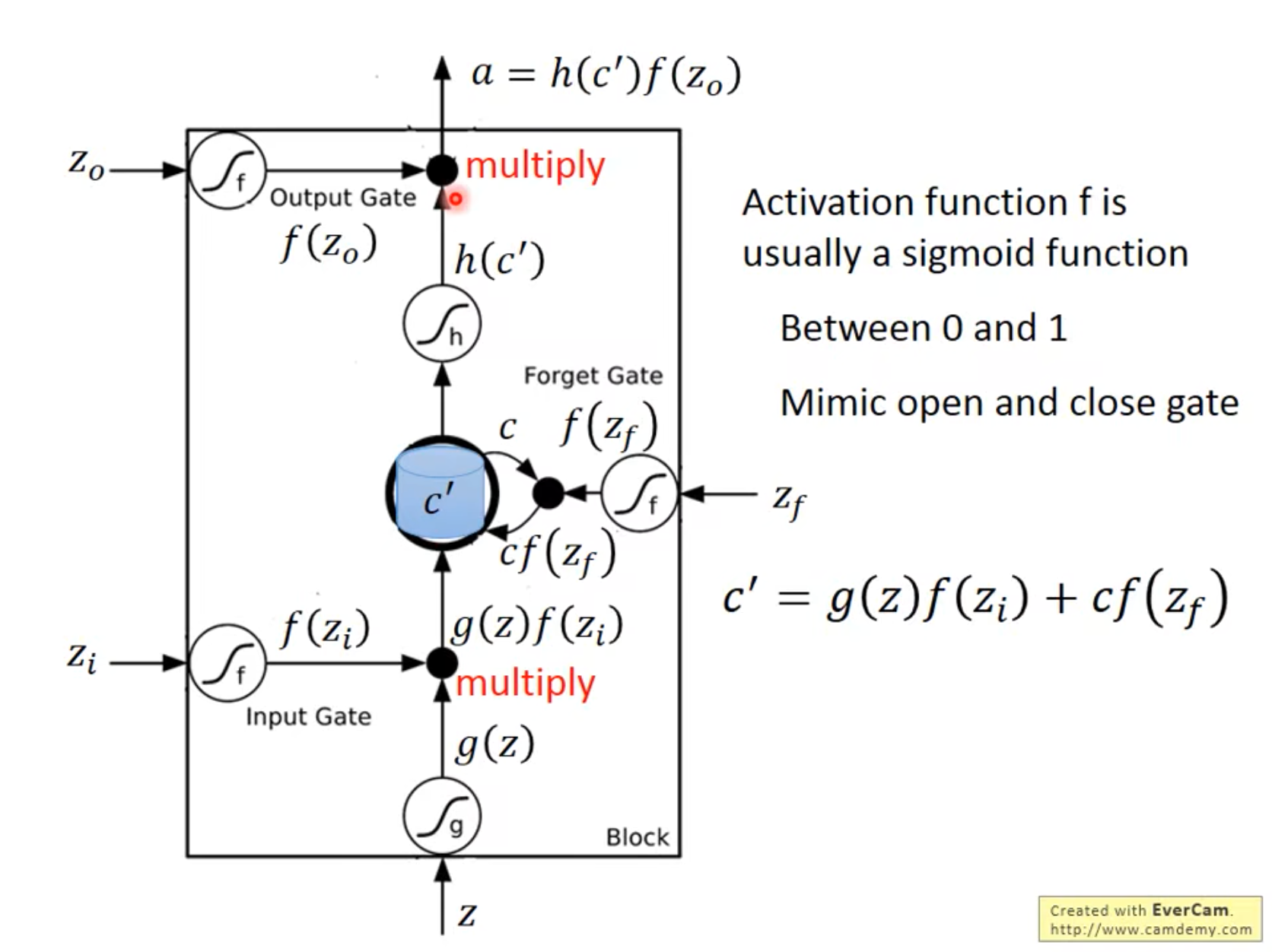
forget gate在打开的时候,代表是记得。在关闭的时候,代表的是遗忘。可以看看视频昂,原教程这个部分后面会有很多的计算例子捏!
- LSTM有点像是,把普通的NN里面的神经元,都换成了上面提到的这种结构(LSTM Cell)。同一个Input,接入LSTM cell的时候,需要四组参数,才能接的进去!所以LSTM需要的参数量是四倍昂!!!
- Multi-layer LSTM
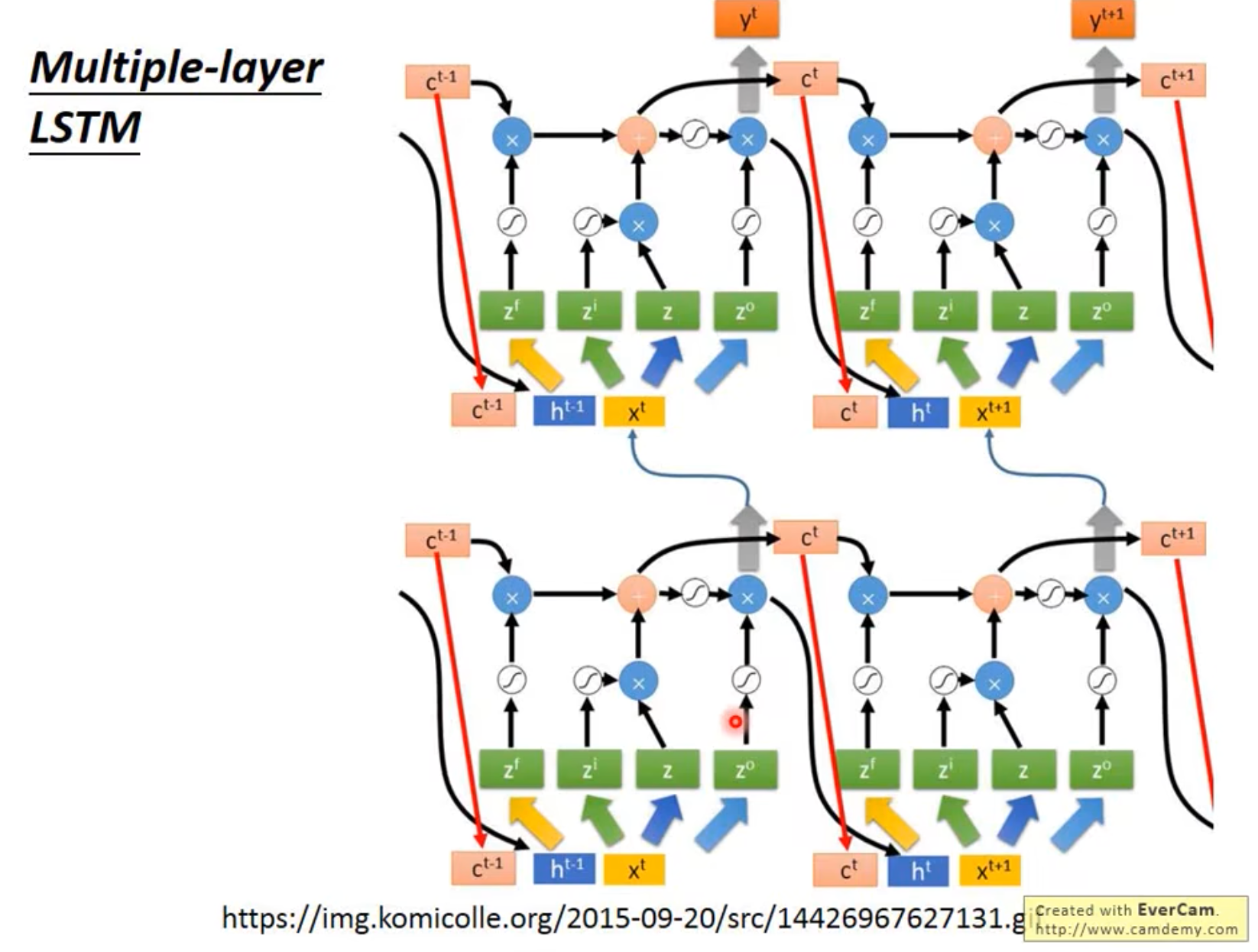
LSTM vs RNN: 其实就是一种RNN。类似,拿Input算了很多东西,更新留存的Memory内容!
如何训练呢?
- Loss function: arrive(other) Taipei(dest) on(other) November(time) 2nd(time),丢入每个词,就和对应的reference vector算一个cross entropy作为loss就行。注意,按照顺序丢,不能打散昂,前后顺序很重要!
- Learning: Backpropagation through time(BPTT), BPTT considers time information. Gradient Descent去training。
- Unfortunately, RNN-based network is not always easy to learn. RNN error surface is really rough, the error surface is either very flat or very steep. -> Clipping, 当gradient太大的时候,就截断!不要太大啦!
- Why the problem happens? -> 随着输入sequence变长(time sequence),memory对于后续的单元的作用是“叠加”的,同一个参数$w$,经过了多次传递(累乘),例如1000次,就变成了$w^{1000}$,导致在Gradient Descent的过程中,梯度变化特别大。
- LSTM -> Can deal with gradient vanishing(not gradient explode),LSTM更新Memory的时候,不是“每次覆盖”,而是“累加更新”。
- Memory and input are added.
- The influence never disappears unless forget gate is closed. -> No Gradient vanishing(If forget gate is opened.),传言:确保forget gate绝大多数情况下,都是open,只有少数才是close去遗忘。只要记得就是add,只要忘记就是multiply。
- Gated Recurrent Unit (GRU): 只有两个gate,参数少,不容易overfitting,更加robust。simpler than LSTM,input gate和forget gate联动。精神:旧的不去,新的不来!不遗忘,新的就进不来!
- Helpful Techniques handling gradient vanishing
- Clockwise RNN
- Structurally Constrained Recurrent Network(SCRN)
- Vanilla RNN Initialized with Identity matrix ReLU activation
function [Quoc V.Le,arXiv’15]
RNN applications
- One2one: slot label
- Many2one:
- Sentiment Analysis
- Key Term Extraction
- Many2many:
- Both input and output are both sequences,but the output
is shorter.(Speech Recognition). Tricks: Trimming, extra “null”, CTC. - Machine Translation(No Limitation)
- Machine translation alignment
- Speech translation alignment
- Both input and output are both sequences with different
lengths -> Sequence to sequence learning
- Both input and output are both sequences,but the output
- Beyond Sequence
- Syntactic parsing
- Sequence-to-sequence Auto-encoder Text: To understand the meaning of a word sequence, the order of the words can not be ignored.
- Sequence-to-sequence Auto-encoder Speech: Dimension reduction for a sequence with variable length
- Sequence-to-sequence Auto-encoder: The RNN encoder and decoder are jointly trained. Input -> RNN Encoder -> RNN Decoder -> Output(Compared with Input)
Attention-based Model
Reading Comprehension
- Machine’s Head Controller -> Neural Turing Machine
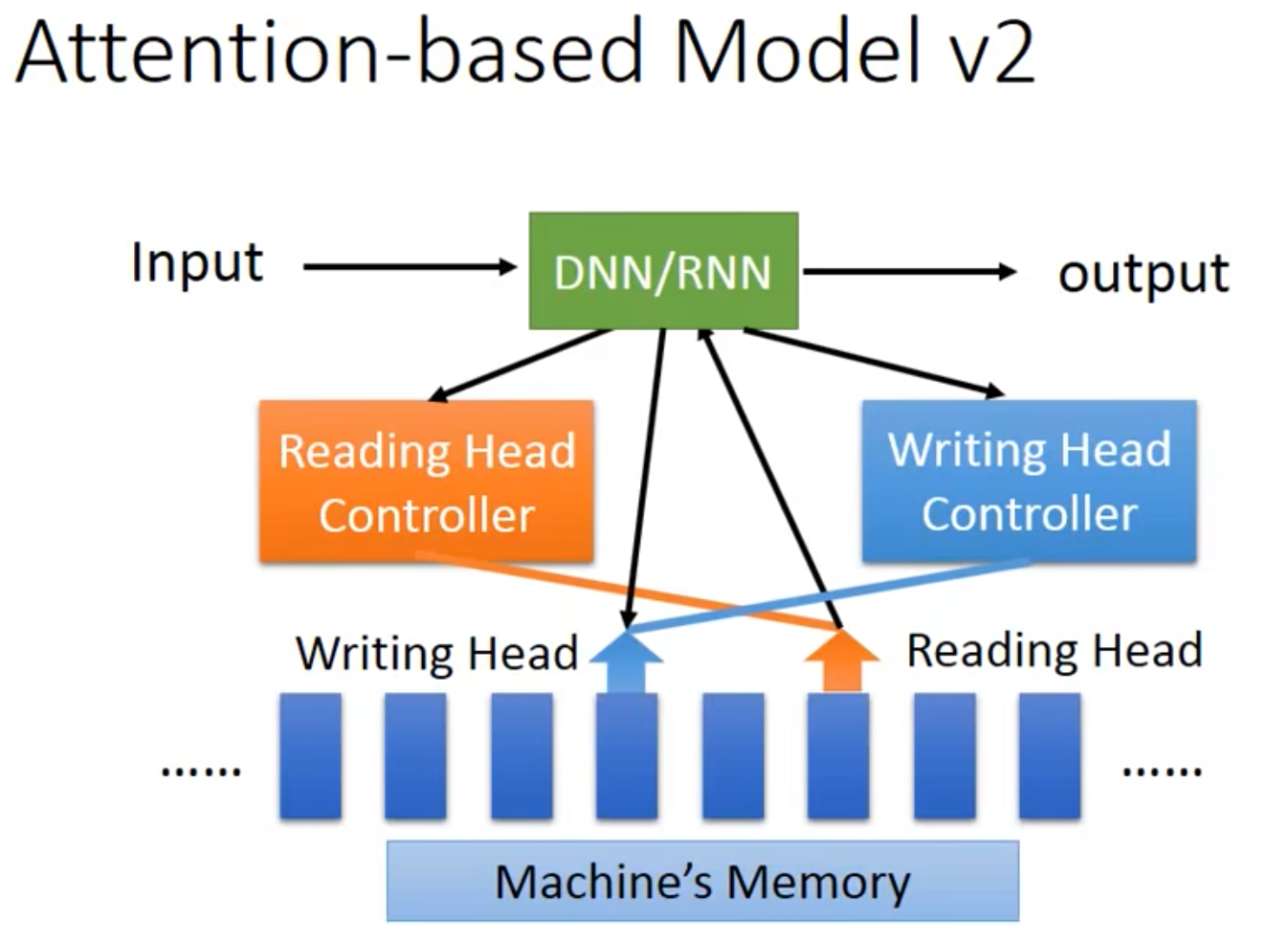
- 甚至可以结合CNN一起用,CNN把一个图片分成若干个region,每个region有一个vector,然后DNN/RNN有一个Reading Head Controller,可以来做特征的读取与处理。
- 其他问题:Speech Question Answering(TOFEL),Architecture
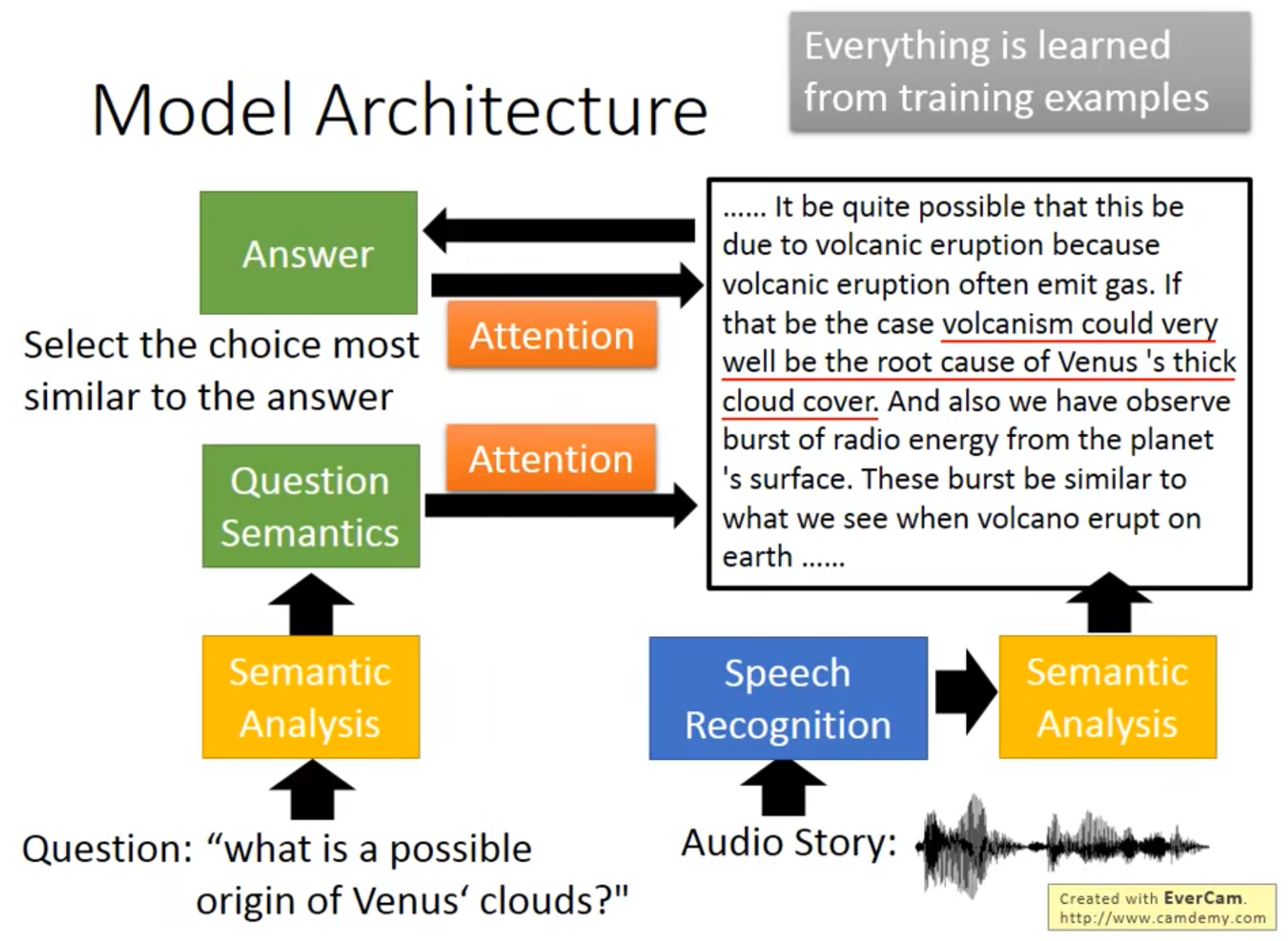
The Unreasonable Effectiveness of Recurrent Neural Networks: http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Understanding LSTM Networks: http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Deep & Structured
- RNN,LSTM
- Unidirectional RNN does not consider the whole sequence
- Cost and error not always related
- Deep
- HMM, CRF, Structured Perceptron/SVM
- Using Viterbi, so consider the whole sequence?
- Can explicitly consider the label dependency: Cost is the upper bound of error.
- 也可以二者混合使用,先过RNN/DNN/LSTM -> 再去HMM, CRF, Structured Perceptron/SVM,结合二者的优势!Semantic Tagging: Bi-directional LSTM CRF/Structured SVM
GNN
应用场景:
- 分类
- 药物研发 -> Generation的工作
- 很多不像是graph的,也可以用GNN来做。例如人际关系图!
Problems
- How do we utilize the structures and relationship to help our model?
- What if the graph is larger,like 20k nodes?
- What if we don’t have the all the labels?
How to embed node into a feature space using convolution?(想用类CNN的想法,来处理GNN,“扫描Graph”)
- Solution 1:Generalize the concept of convolution(corelation)to
graph -> Spatial-based convolution - Solution 2: Back to the definition of convolution in signal processing -> Spectral-based convolution
- Solution 1:Generalize the concept of convolution(corelation)to
Tasks,Dataset,and Benchmark
- Tasks
- Semi-supervised node classification
- Regression
- Graph classification
- Graph representation learning
- Link prediction
- Common dataset
- CORA:citation network.2.7k nodes and 5.4k links
- TU-MUTAG:188 molecules with 18 nodes on average
- Tasks
Spatial-based GNN
- Terminology:
- Aggregate:用neighbor feature update下一層的hidden state(类似于CNN的kernel,用周围的值更新中间的值,也有点Pagerank的意思在里面。)
- Readout:把所有nodes的feature集合起來代表整個graph
- Terminology:
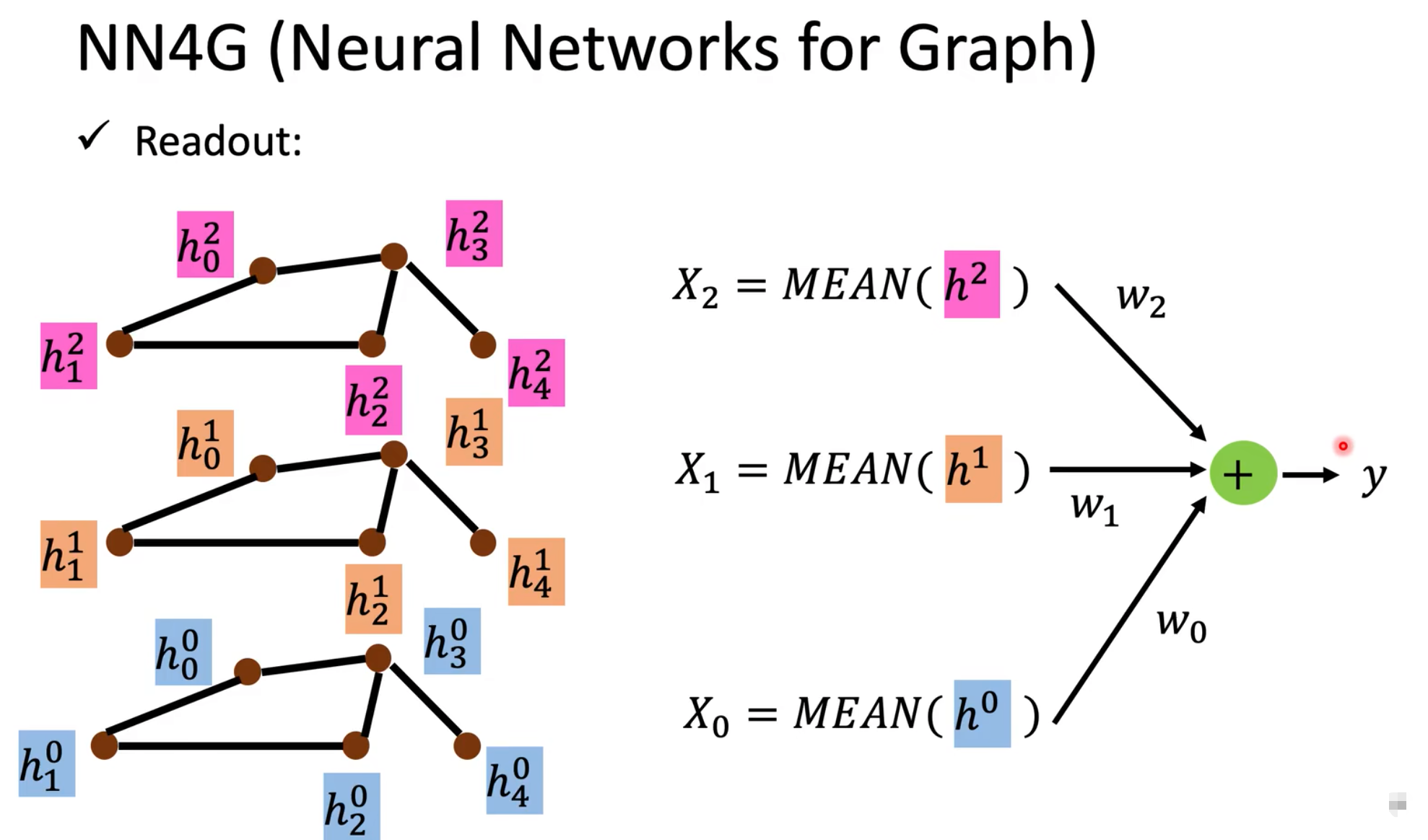
NN4G
Aggregate: 将节点周围的value相加,乘上一个矩阵,再加上自己原本的值乘上一个矩阵,来进行学习和更新。
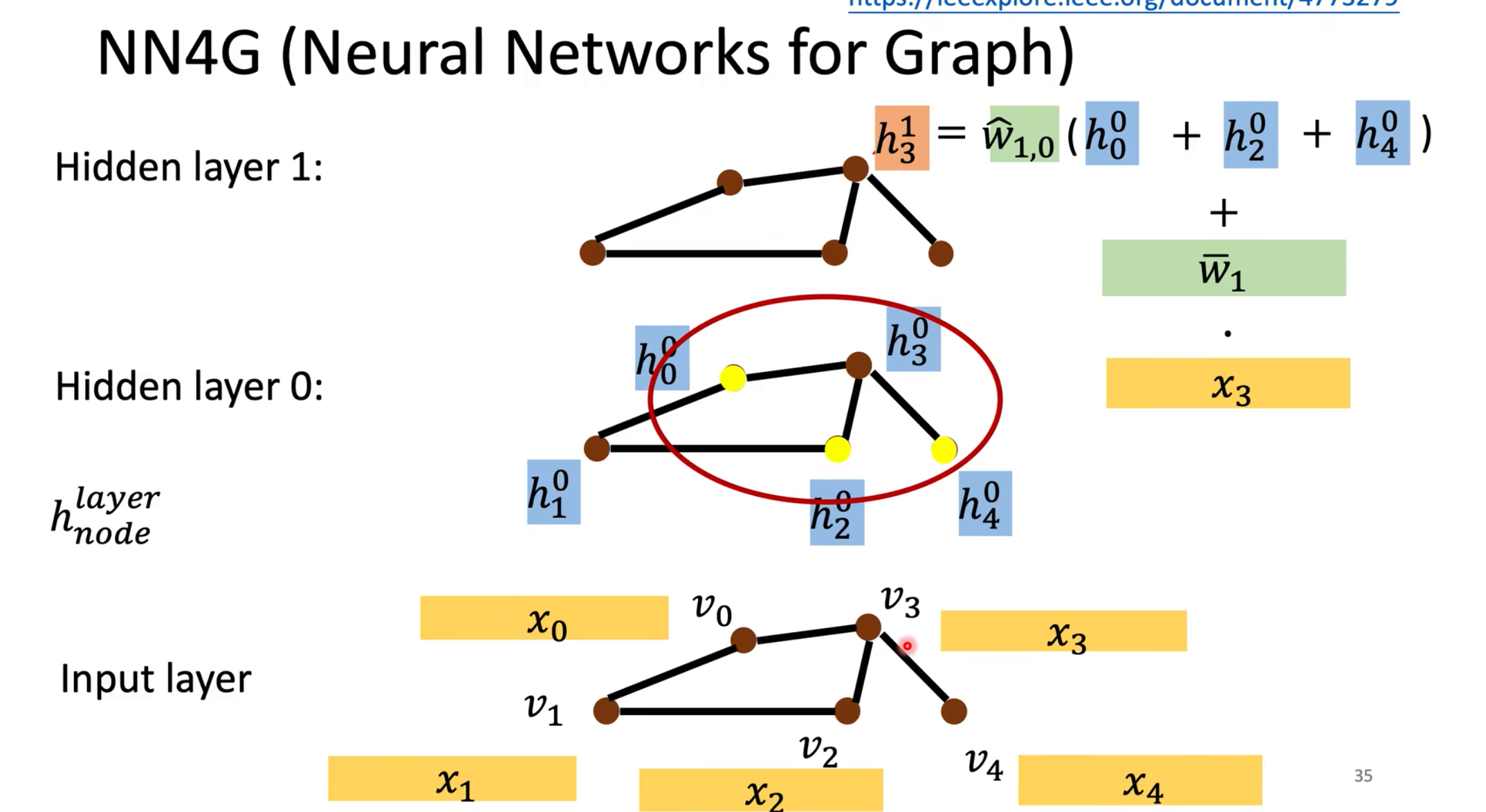
Readout: 每一层相加,再乘上一个矩阵,得到一个输出。代表整个Graph的一个feature。
DCNN: 把距离为$d$的节点,和当前节点的值加起来(按照距离,比如距离为1,距离为2之类的)。每一层叠起来,然后乘上一个矩阵,就拿到feature了!
DGC: 和上面类似,但是拿到数据之后,不是叠起来,而是加起来昂!
MoNET (Mixture Model Networks)
- Define a measure on node distances
- Use weighted sum(mean)instead of simply summing up (averaging) neighbor features.
点和点之间的距离,不一定是边数啊!我们定义一把!
GraphSAGE: AGGREGATION:mean,max-pooling,or LSTM
GAT: Graph Attention Networks,Attention是当前节点,给它的周围邻居的attention,然后算出来结果昂!
GIN:Graph Isomorphism Network
Resources: DEEP GRAPH LIBRARY
Transformer
Seq2seq的model, Input a sequence,output a sequence. The output length is determined by model.
- application
- speech recognition
- machine translation
- speech translation
- Seq2seq is really powerful.
Encoder
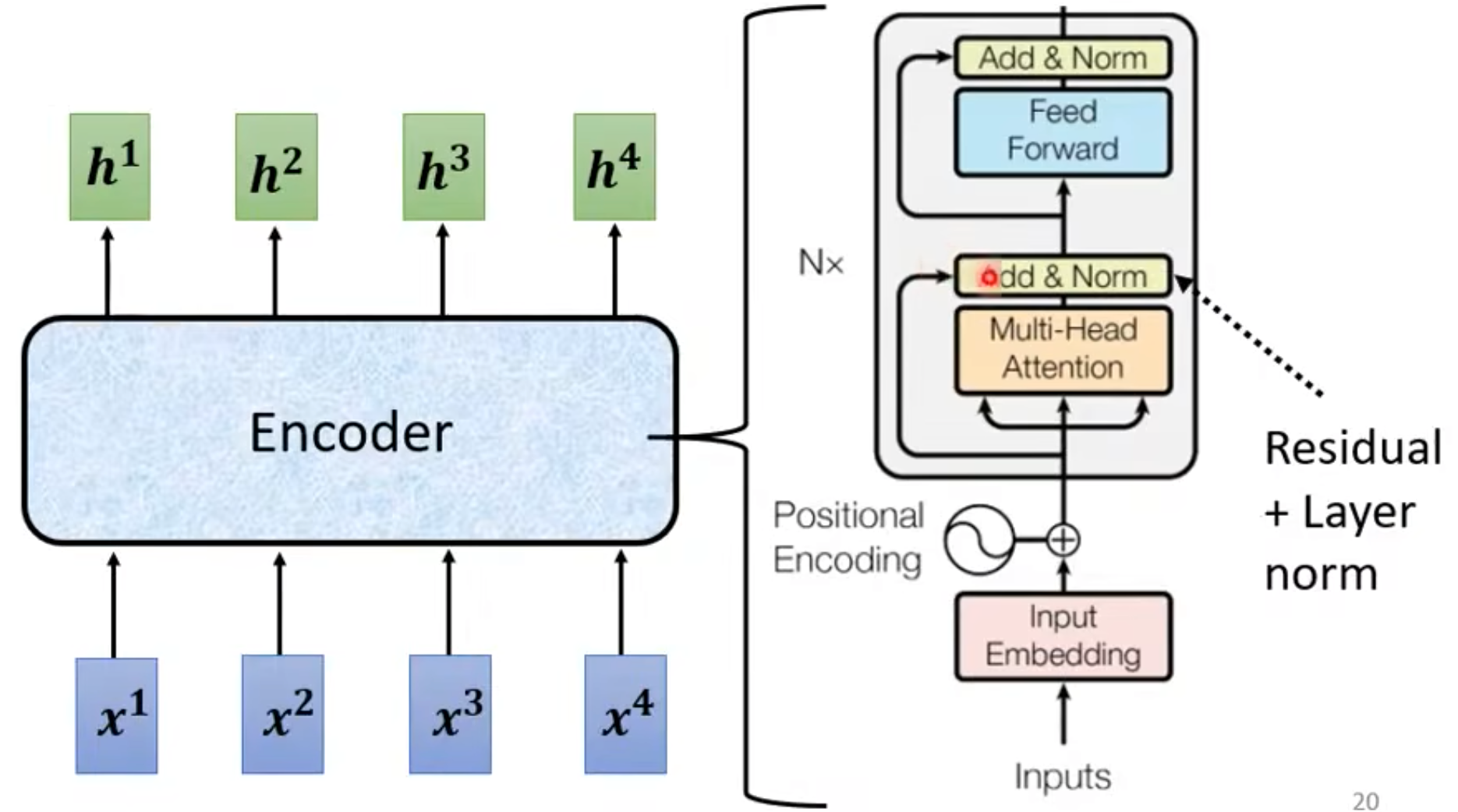
- Transfomer Encoder Block:
Inputs -> Input Embedding -> Add Positional Encoding -> (Multi-Head Attention -> Add & Norm -> Feed Forward Network -> Add & Norm) x N -> Output
- “Add” is just the same “residual” concept in residual network.
- Some papers
- on Layer Normalization in the Transformer Architecture, https://arxiv.org/abs/2002.04745
- PowerNorm:Rethinking BatchNormalization in Transformers, https://arxiv.org/abs/2003.07845
Decoder
Encoder Output + Input -> Decoder Blocker -> Softmax -> Output(max possiblity word in distribution)
- First input is a special token(BOS, begin of sentence), next input is the output of this input.(问题:一步错,步步错)
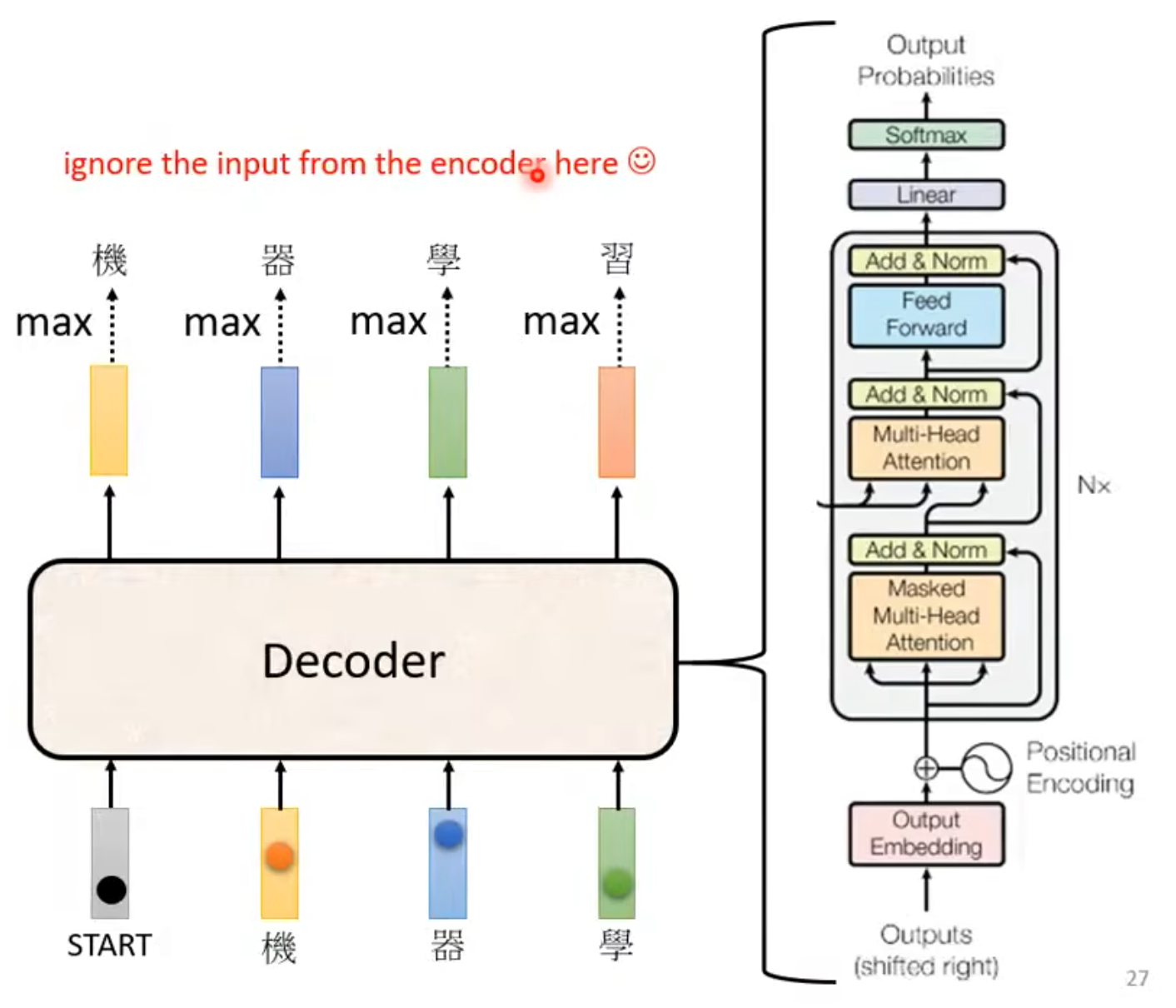
Self-attention -> Masked Self-attention, 当前位置的输入,看不到之后的输入,没办法计算后面的attention,只能和前面的位置算attention。很直觉感觉很对哇!Decoder的输出是一个一个产生的,看不到后面的内容很正常啊!!!
Autoregressive Decoder: 必须自己知道,输出的长度是多少捏!怎么解决?用一个特殊的输出当作结束(EOS, end of sentence)!也就解决了这个问题!!!
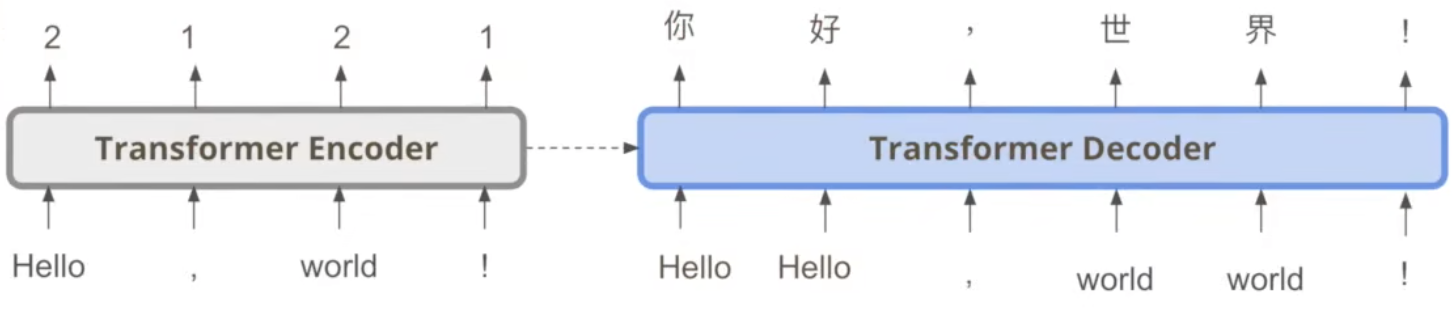
Decoder Non-autoregressive(NAT),Autoregressive model也缩写为(AT),AT产生是one by one。NAT产生是一次就是一句话,每次吃一排input,然后产生一排output。那咋知道长度呢?How to decide the output length for NAT decoder?
- Another predictor for output length
- Output a very long sequence,ignore tokens after END
NAT’s Advantage: parallel, controllable output length
NAT’s Disadvantage: usually worse than AT(Why? Multi-modality)
Encoder + Decoder
- Cross-Attention: Encoder提供了两个箭头,Decoder提供了一个箭头。Decoder利用Cross-Attention,用到了Encoder的输出!
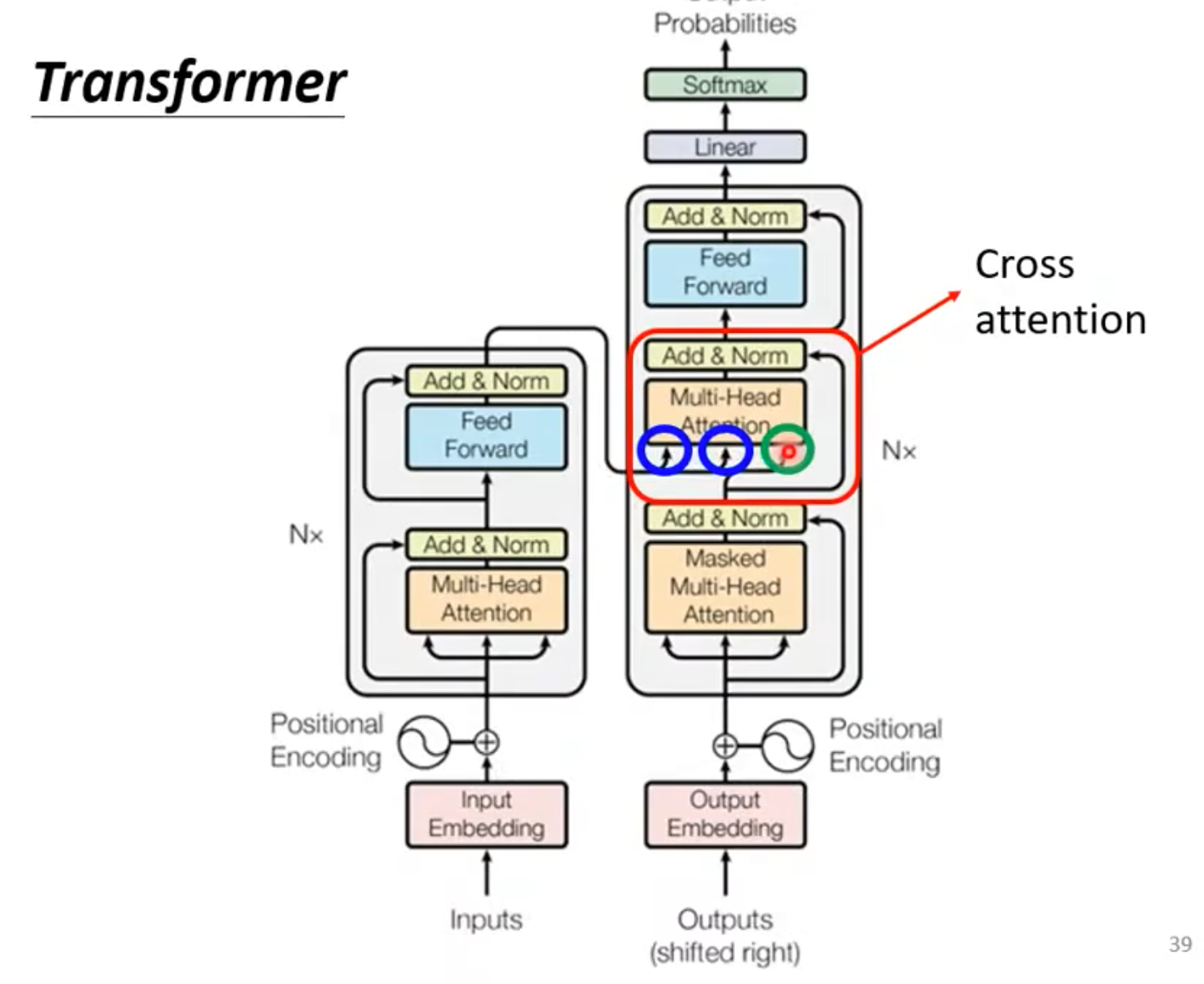
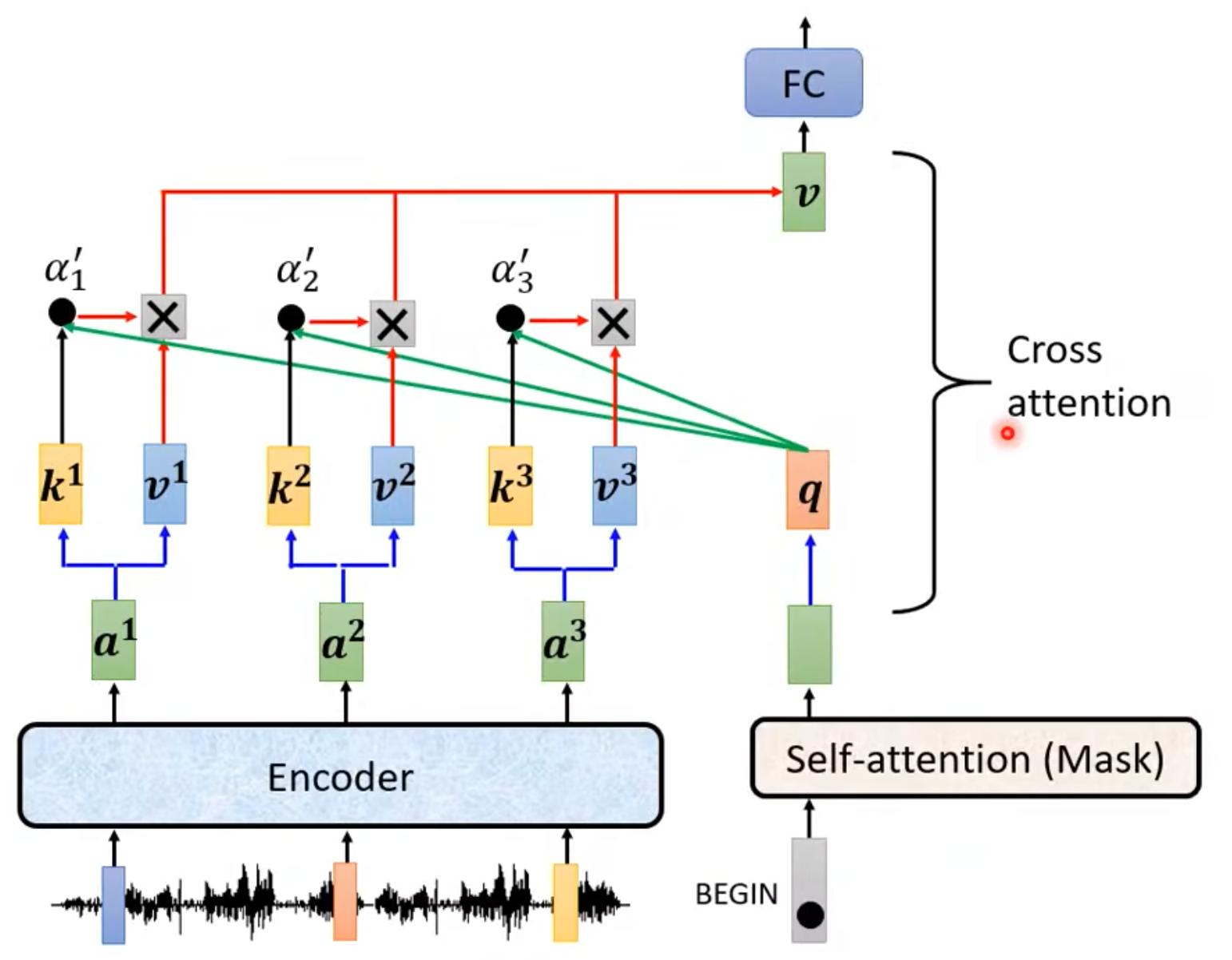
q来自于Decoder,k和v来自于Encoder,这个步骤就叫做cross-attention
- Cross-Attention can do many things,也不一定就要和这一层Cross啊,可以一个Decoder和很多Encoder做cross,也可以所有的Decoder和所有的Encoder做cross。总之就是,技巧和idea很多!
Training
- 模型的输出本质是一个distribution,正确的输出可以表示为一个one-hot,loss就是cross-entropy,感觉就和分类很像啊!minimize cross entropy就好!(注意,这里还有个BOS和EOS,EOS也是作为正确答案做cross entropy的昂)
- Decoder的输入是正确答案昂!会不断从正确答案的输入,进行输出,并且和正确的输出做对比算loss。
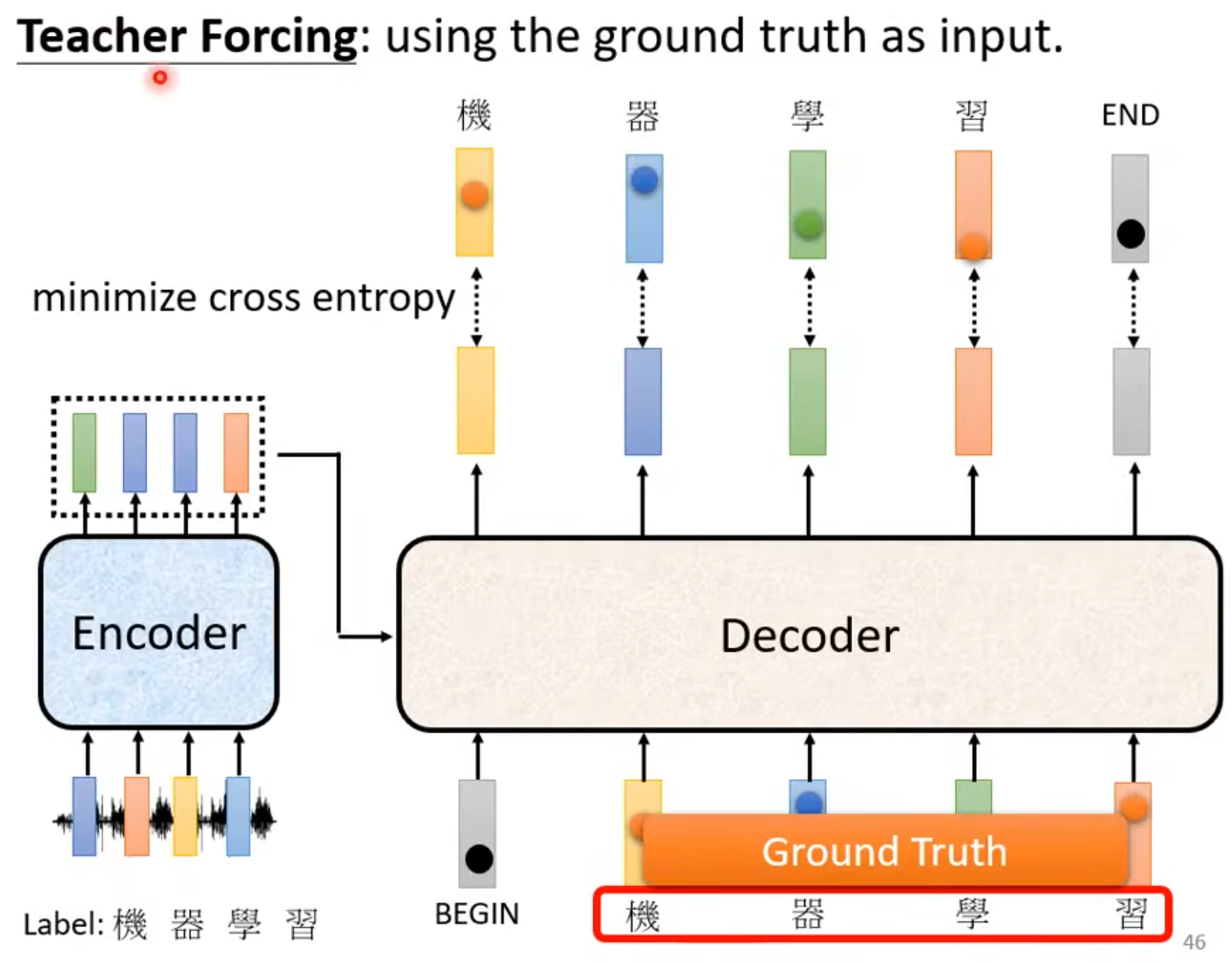
Teacher Forcing: using the ground truth as input.
- 训练的时候,Decoder偷看到正确答案了,Inference的时候不行啊,mismatch!
- Tips:
- Copy Mechanism: 有些任务也许不一定是需要自己输出,从输入里面复制内容出来就行,机器不需要创造,只是Copy就可以。例如Chat-bot,复制摘要等。Pointer Network 和 Incorporating Copying Mechanism in Sequence-to-Sequence Learning
- Guided Attention: 输入有些东西可能没有看到,我想要它一定要看到,或者按照什么顺序去看,引导注意力!!In some tasks,input and output are monotonically aligned. For example, speech recognition,TTS,etc. (Monotonic Attention, Location-aware Attention)
- Beam Search: 束搜索!不要老贪心,多看看!有时候有用,有时候没有用(可以多增加一些随机性!)Randomness is needed for decoder when generating sequence in some tasks (e.g.,sentence completion,TTS)。确定任务就不要,创造性的就要!Accept that nothing is perfect. True beauty lies in the cracks of imperfection.
- Optimizing Evaluation Metrics? BLEU score v.s. Cross-Entropy, BLEU Score来作为loss不好,因为不好微分,但是助教拿这个看效果怎么办捏?How to do the optimization? When you don’t know how to optimize,just use reinforcement learning (RL)!https://arxiv.org/abs/1511.06732
- 测试看到的是自己的输出,训练看到的是完全正确的,This is a mismatch called exposure bias. 一步错,步步错怎么办?训练的时候,输入加一些错误的东西,学的时候就知道错的该怎么处理!Scheduled Sampling,会伤害到Transformer并行化的能力!
- Original Scheduled Sampling https://arxiv.org/abs/1506.03099
- Scheduled Sampling for Transformer https://arxiv.org/abs/1906.07651
- Parallel Scheduled Sampling https://arxiv.org/abs/1906.04331
Attention Variant
Each input has a q,k,v. If sequence length is N, there will be an N x N attention matrix. How to make self-attention efficient?
Notice
- Self-attention is only a module in a larger network.
- Self-attention dominates computation when N is large.
- Usually developed for image processing. 只有在input sequence长的时候才有用。短的话,其实和Transformer(或者其他应用self-attention的模型等)其他计算部分相比,self-attention部分计算的开销没有那么大,效果也就不太显著啦!
Efficient
Skip Some Calculations with Human Knowledge. Can we fill in some values with human knowledge?
- Local Attention/Truncated Attention
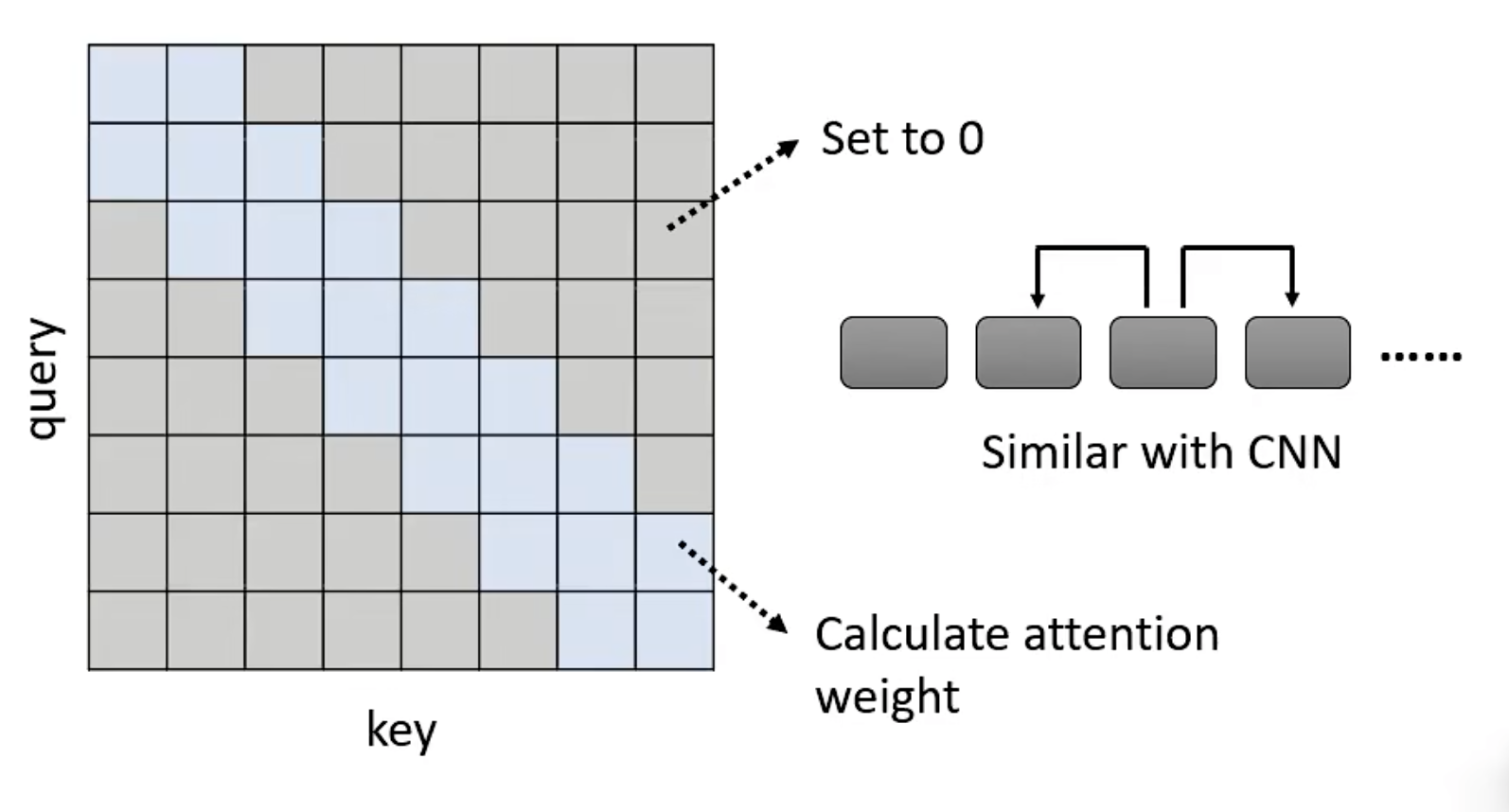
Attention在很小的范围内,不就和CNN一样了吗?可以啊,可能效果不那么好,但是效率高了呀!
- Stride Attention
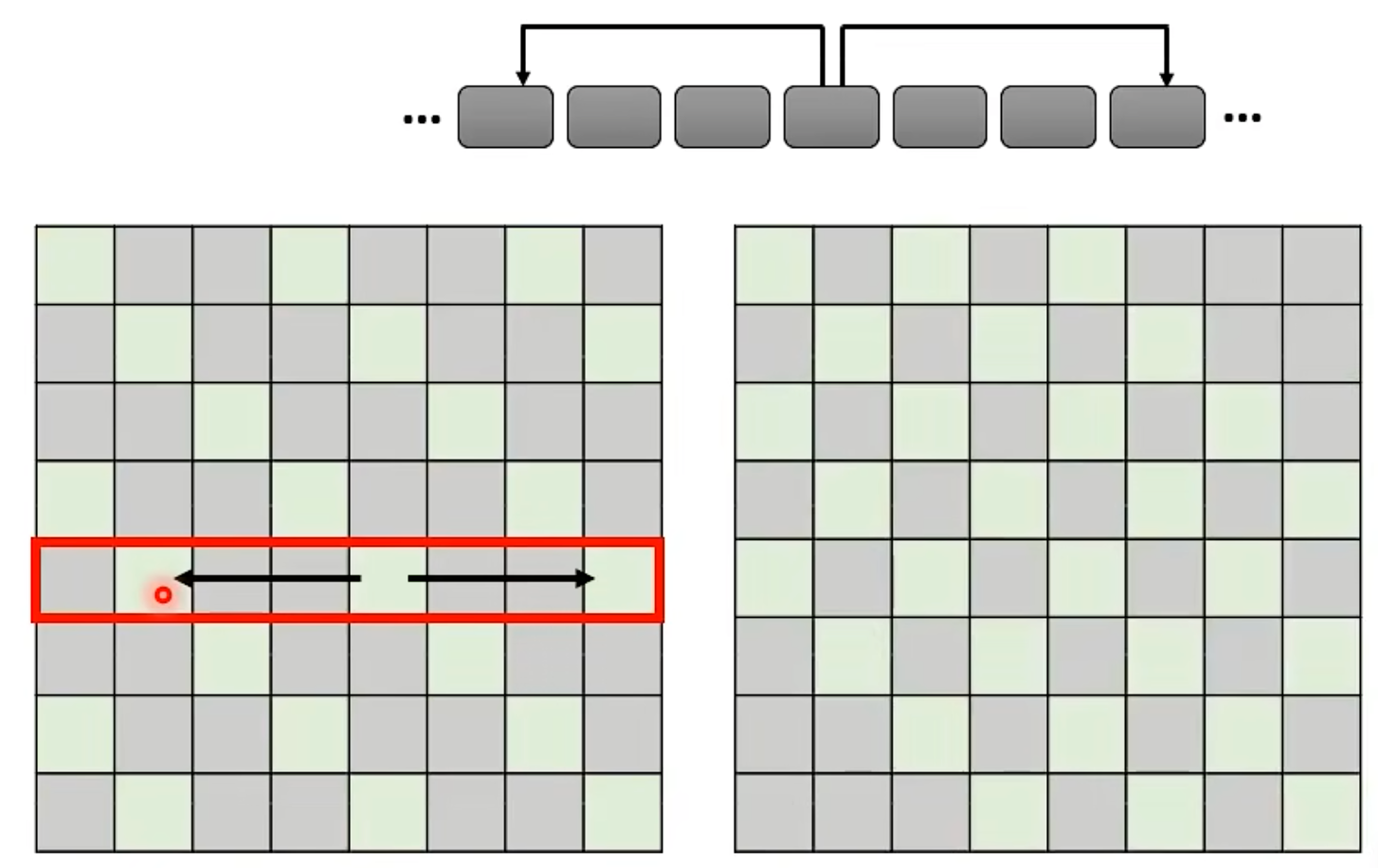
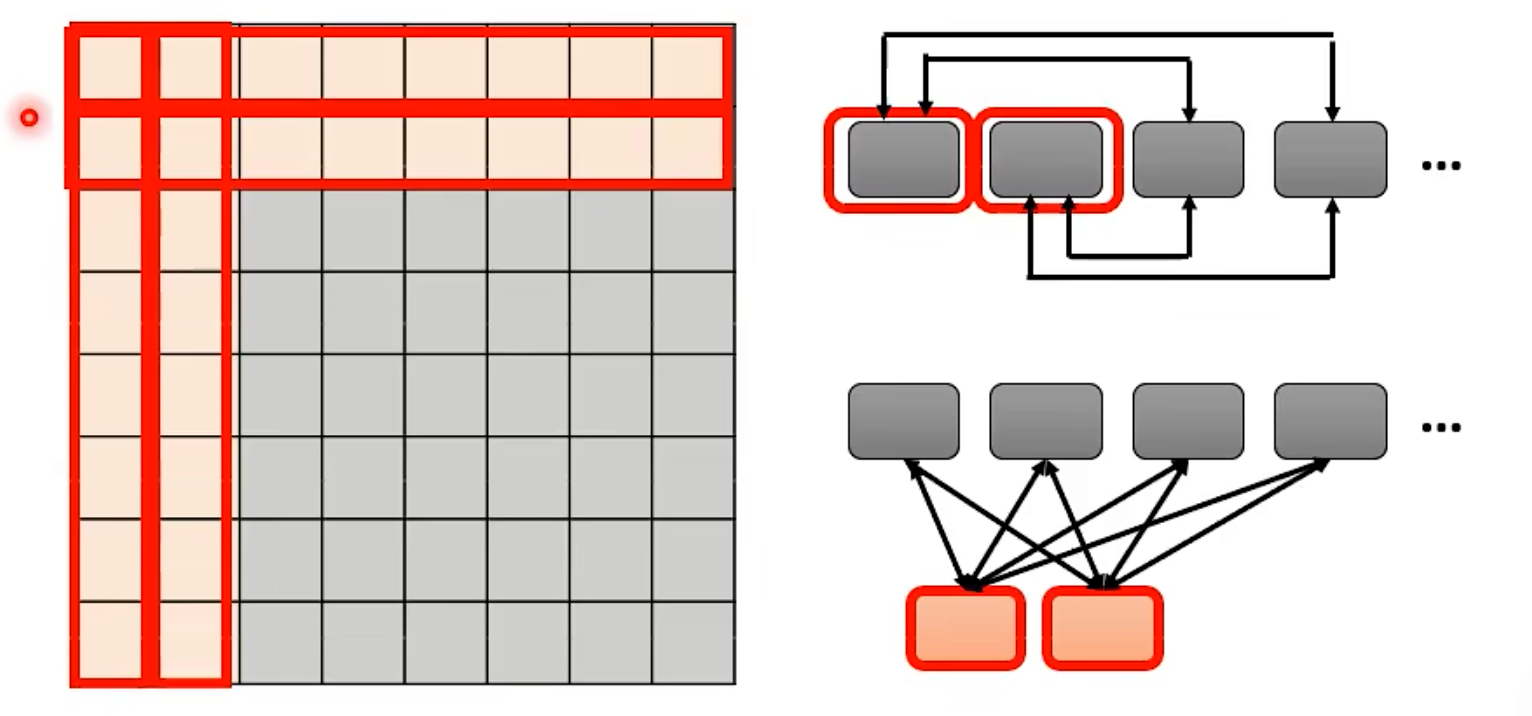
- Global Attention: Add special token into original sequence
- Attend to every token -> collect global information
- Attended by every token -> it knows global information
- Can be done by: assign some tokens as “special tokens” / add some extra tokens as “special tokens”
- 使用场景?选哪个呢?小孩子才做选择,全都用!Different heads use different patterns.可以在multi-head self-attention里面,都综合使用,不同的head有不同的attention的模式和方式!综合不同的pattern!
- Famous way: Longformer, Big Bird.
Can we only focus on Critical Parts? ->
- Data-driven methods help you find the large values and set the small values directly to 0. How to quickly estimate the portion with small attention weights?
- Reformer: https://openreview.net/forum?id=rkgNKkHtvB
- Routing Transformer: https://arxiv.org/abs/2003.05997
- Clustering(based on similarity) on query and key -> approximate&fast, clustering可以加速!简单的clustering可能效果就太差了,达不到我们的目的!
- Belong to the same cluster, then calculate attention weight. Not the same cluster, set to 0.
- Learnable Patterns,直接学出来!
- Sinkhorn Sorting Network. A grid should be skipped or not is decided by another learned module.
- Input sequence -> NN -> Sequence Array v.s. Attention Matrix). Learning ! ! !
- Data-driven methods help you find the large values and set the small values directly to 0. How to quickly estimate the portion with small attention weights?
Do we need full attention matrix?
- Many redundant columns. Linformer https://arxiv.org/abs/2006.04768. Many columns are Low Rank.
- Keys -> Get K Representative Keys
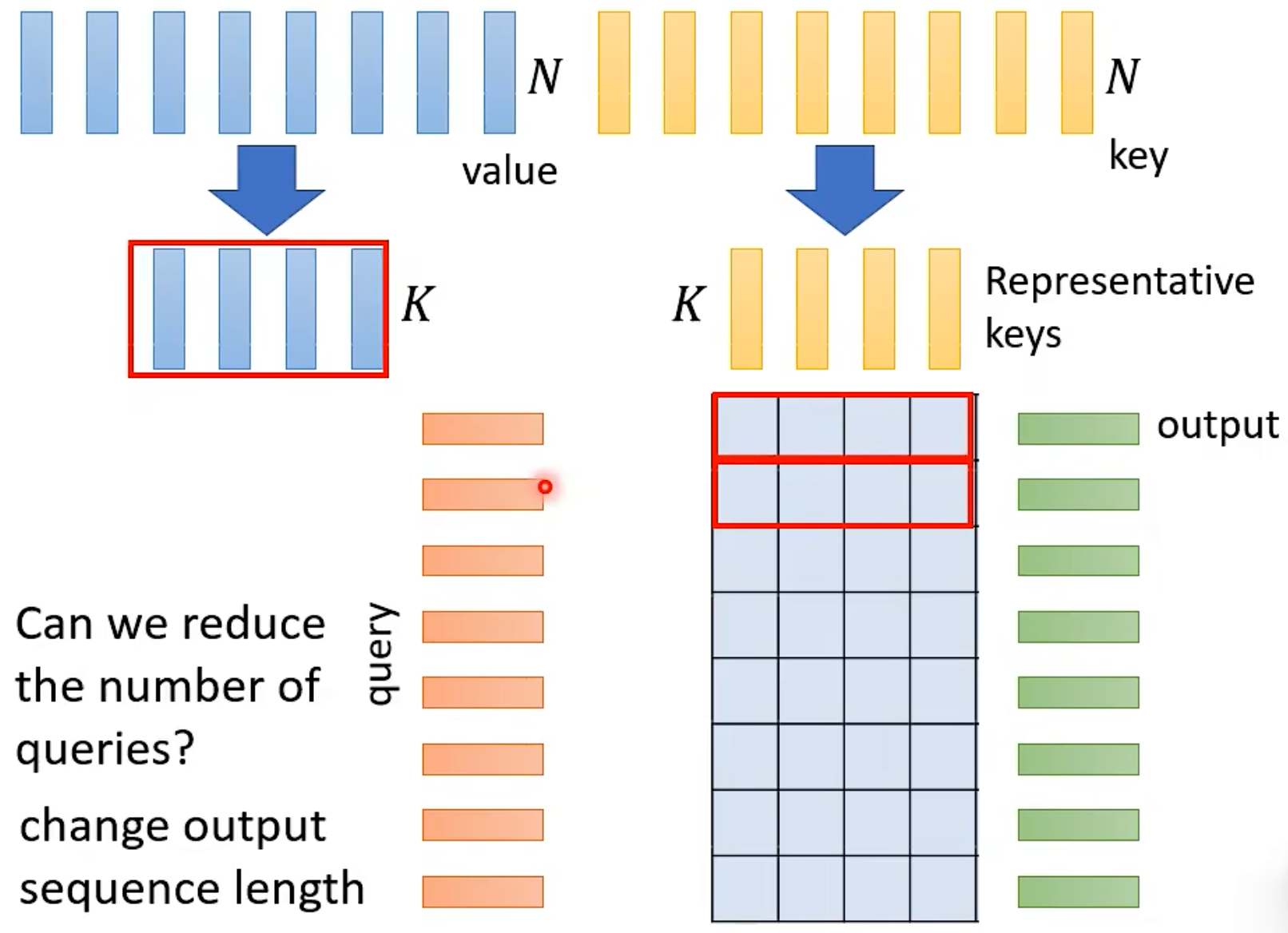
- Reduce number of keys:
- Compressed Attention, https://arxiv.org/abs/1801.10198, CNN conv attentions
- Linformer: https://arxiv.org/abs/2006.04768, Matrix multiply to get fewer attentions. (Linear combination of N vectors)
Attention Mechanism is three-matrix Multiplication,
- Origin: $(d + d^{‘}) * N^{2}$, Now: $2d{‘}dN$,本质是$O = V * K^{T} * Q$, $(d + d^{‘}) * N^{2}$往往 >> $2d{‘}dN$,因为$N$往往远大于$d$,改变矩阵乘法的顺序!(去掉中间的Softmax才能work)
- 放回Softmax应该怎么做呢?Realization: Efficient attention, https://arxiv.org/pdf/1812.01243.pdf. Linear Transformer, https://linear-transformers.com/. Random Feature Attention, https://arxiv.org/pdf/2103.02143.pdf. Performer, https://arxiv.org/pdf/2009.14794.pdf
Do we need g and k to compute attention? Synthesizer!
Attention-free?
Non-Autoregressive Sequence Generation
Autoregressive model太慢了!
Non-autoregressive model(mostly by Transformer), predict output length & feed position embedding
- 一个input可能对应多个output,导致输出出错,multi-modality problem!
Vanilla NAT(Non-Autoregressive Translation)
- Predict fertility as latent variable & Copy input words
- Represents sentence-level “plan” before writing Y
每个输入测一下“影响的输出有几个”,然后直接copy对应的次数,放到输出Decoder的Input位置
Fertility
- Labels comes from external aligner
- Observing attention weights in auto-regressive models
Fine-tune (after NAT model converges): Updating fertility classifier with REINFORCE
Sequence-level knowledge distillation
- Process
- Input -> 小的model -> 学习learning target
- Input -> 大的model -> Output(Learning target)
- Teacher:Autoregressive model,Student:Non-autoregressive model
- Construct new corpus by autoregressive teacher model
- Teacher’s greedy decode output as student’s training target
- Process
Noisy Parallel Decoding (NPD)
- Sample several fertilitie sequences
- Generate sequences
- Score by a autoregressive model
Evolution of NAT
- Vanilla NAT
- Iterative Refinement
- Insertion-based
- Insert + Delete
- CTC-based
NAT with Iterative Refinement: Encoder -> Decoder_1 -> Decoder_2,每一步都进行一些设计,不断促进model的学习
Mask-Predict: 每次把预测的不是很好的位置的word(概率低),给MASK住,塞进网络再来看结果。效果好不好,可能可以用另外一个比较强大的model来判断昂!
Insertion Transformer: 判断要不要插入一个字,插入什么字?Training -> shuffled
Multiple target words to predict
KERMIT
Pointer Network
解决硬train一发的问题
- Seq2seq做不了!
- Pointer Network可以让输出从输入中copy一部分的词汇过来!
PixelRNN(Optional)
Generative Model
- To create an image, generating a pixel each time
VAE(Optional)
Generative Model
- Auto-encoder: Input -> NN Encoder -> Coder -> NN Decoder -> Output
- VAE: Input -> NN Encoder(From a normal distribution, $c_i = exp(\delta_i) \times\ e_i + m_i$) -> NN Decoder -> Output, Minimize reconstruction error.
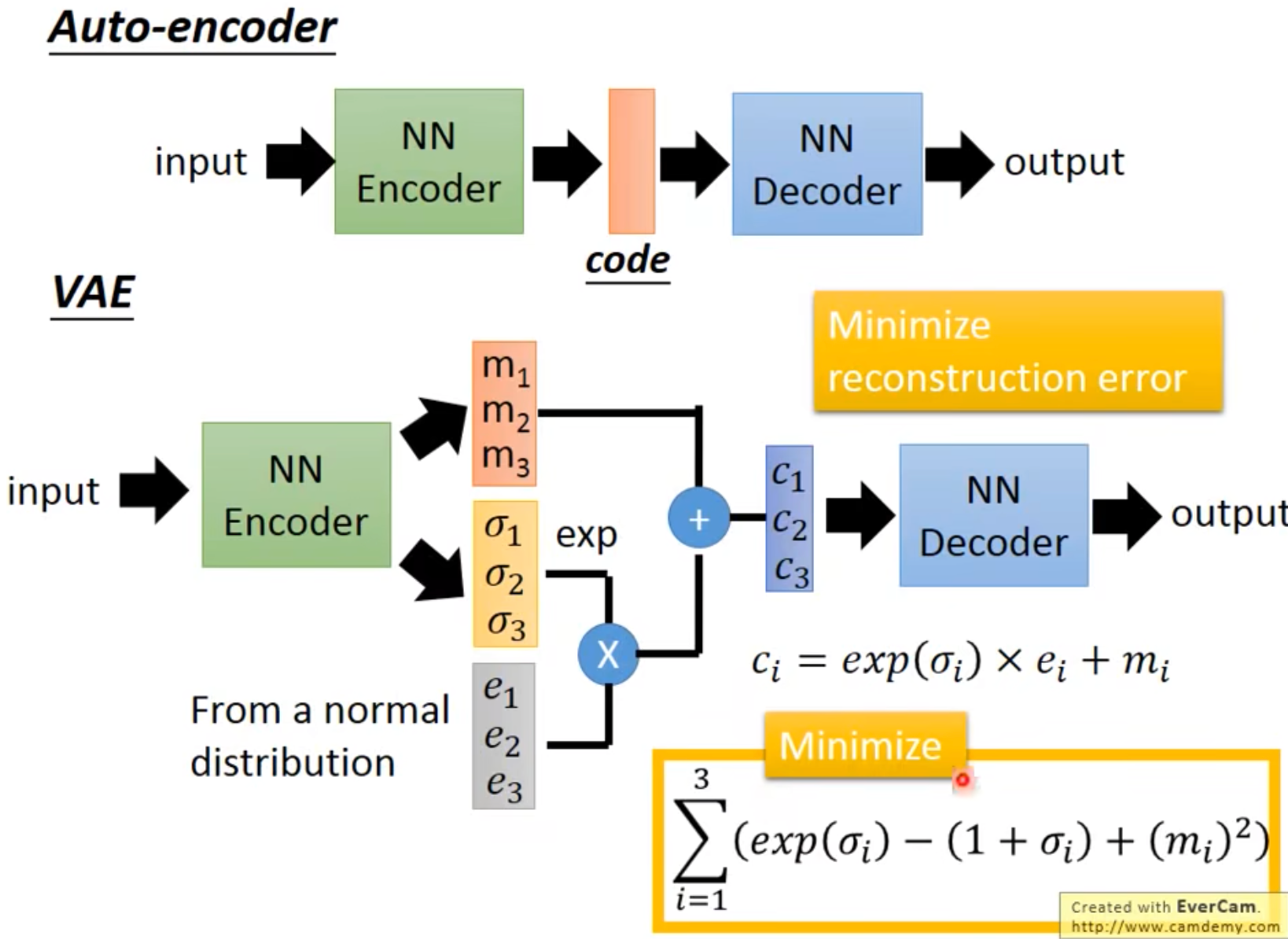
Writing Poetry: sentence -> NN Encoder -> code -> NN Decoder -> sentence
- Why VAE? Intuitive Reason. Back to what we want to do -> Estimate the probability distribution.(Gaussian Mixture Model)
- Conditonal VAE: Generate style similar results
- Problem of VAE: 没有学习怎样产生。VAE may just memorize the existing images,instead of
generating new images. 它能做的只有模仿!
GAN
GAN Training
Generative Adversarial Network
Vector -> NN Generator -> NN Discriminator -> Scalar(打分)
- Especially for the tasks needs “creativity’(The same input has different outputs.)
- Unconditional generation: simple distribution(Low-dim vector sample) -> Generator -> Complex Distribution,generator本质就是从一个低纬的向量,生成一个高纬的向量。
- 我们要训练的东西:
- Generator: 一个nn,生成图片。
- Discriminator: It is a neural network(that is,a function). Image -> Discriminator -> Scalar(Larger means real smaller value fake)
- 这俩架构都可以自己设计捏!例如Discriminator用CNN就挺好!
- Basic Idea of GAN: This is where the term “adversarial”comes from. 对抗!Algorithm:
- Initialize generator and discriminator
- In each training iteration:
- Step 1: Fix generator G,and update discriminator D. Discriminator learns to assign high scores to real objects
and low scores to generated objects. D会拿到G的输出,然后对比真实的数据进行训练,要能区分G生成的数据。 - Step 2: Fix discriminator D,and update generator G. Generator learns to “fool” the discriminator. G会把自己的输入塞进D中,让D的打分越高越好,这样来训练G。
- Step 1: Fix generator G,and update discriminator D. Discriminator learns to assign high scores to real objects
反复交替训练D和G,就可以一直做的越来越好!
- 除了Anime之外,Photorealistic也是work的昂!例如Progressive GAN
Theory behind GAN
- Normal Distribution -> Generator -> Output,希望这个output和真实data的output越接近越好!$G^* = argmin_G Div(P_G, P_{data})$,这两个之间的divergence应该怎么算呢?怎么判断两张图是不是类似呢?怎么去计算呢?
Although we do not know the distributions of $P_G$ and $P_{data}$, we can sample from them. GAN告诉我们,只要你知道怎么sample,就有办法算divergence。
- Discriminator就是做这个事儿的,从$P_G$和$P_{data}$里面,把数据抽出来,然后打分做判断。
$$
Training: D^* = arg max_D V(D,G) \
Objective\ Function\ for\ D:\ V(G,D) = E_{y-P_{data}}[logD(y)] + E_{y-P_G}[log(1-D(y))]
$$
希望V越大越好捏!其实感觉这个loss,就是binary classifier的想法,negative cross entry! 希望把分对的分数提高,把分错的分数降低!感觉就像是那个Training classifier: minimize cross entropy.
- Small divergence -> hard to discriminate, small $max_DV(D,G)$. Large divergence -> easy to discriminate. 不知道怎么计算Divergence,没事儿!$max_DV(D,G)$就可以看作和$Div(P_G, P_{data})$相关!因此问题又转换为了$G^* = argmin_G max_DV(G,D))$。GAN的训练过程,就是在做这件事儿昂!!!
GAN很难Train,还有CycleGAN,就是既然两个分布不好train,那么:
- 转两次,判断原来的分布和预测的分布的相似程度。然后去算一把loss(类似cycle GAN),然后对中间状态加以限制。类似于形式,Discriminator之类的,来限制我们所需要的Output的形式和内容。
- 先用现有的数据,pre-train一发,尽量把两个分布拉近。等到”warm up”之后,再来KL散度!就可以train起来了!
- Tips for GAN Training:
- JS divergence is not suitable, $P_G$和$P_{data}$是有很大的overlap的,JS divergence is always log2 if two distributions do not overlap. 所以起不到什么实际的作用。有点像,距离最低点远的时候,算出来的loss都是一样的,就没有用!
- Intuition: If two distributions do not overlap,binary classifier achieves 100% accuracy. The accuracy (or loss) means nothing during GAN training.
- Wasserstein distance
- Considering one distribution P as a pile of earth, and another distribution Q as the target.
- The average distance the earth mover has to move the earth.
- There are many possible “moving plans”. Using the “moving plan”with the smallest average distance to define the Wasserstein distance.
- WGAN
- Original WGAN -> Weight
- Improved WGAN -> Gradient Penalty
- Spectral Normalization(SNGAN) -> Keep gradient norm smaller than 1 everywhere
- GAN is still chanllenging, G and D needs to match each other. Hard to train,其中一个寄了,另外一个就寄了!GAN for sequence Generation也难,Discriminator更新对于G可能会没啥影响,求啥导啊?
- Quality of Image
- Human evaluation is expensive (and sometimes unfair/unstable).
- How to evaluate the quality of the generated images automatically?(用一些神经网络或者别的技术处理,例如vgg看看效果之类的)
- Diversity — Model Collapse / Model Dropping. Inception Score(IS): Good quality, large diversity -> Large IS.
- Fréchet Inception Distance(FID): red points:real images, blue points:generated images. FID = Frechet distance between the two Gaussians. Smaller is better.
Conditional Generator
Supervised Learning
Text-to-image, Supervised Learning, 你要告诉NN,什么样的IO是对的!
- Condition x(Prompt) + z(Normal Distribution)
- 如何训练呢?需要paired的data,Condition + Picture都要看!只有图片好 + 图片和文字相匹配,才会给高分昂!!!故意配一些错的,让GAN学学!
- 不只txt2img,也可以image translation(pix2pix),sound2img
- Talking head generation
Unsupervised Learning
Unlabeled资料如何使用?Still need some paired data.
- 例如Image Style Transfer,Photo -> Anime,没有任何成对的资料。Can we learn the mapping without any paired data?
Unsupervised Conditional Generation - 直接从X和Y直接Sample,然后进行训练就好,但是这里有个问题,就是我生成的图片可以和Y很像,如何和X建立联系呢?如何强化输入和输出的关系呢(参考txt2img)
- Cycle GAN -> Train两个generator,一个是x到y,一个是y还原回x。要求还原回来的,和原始的输入,as close as possible, Cycle consistency. “Related” to input, so possible to construct.
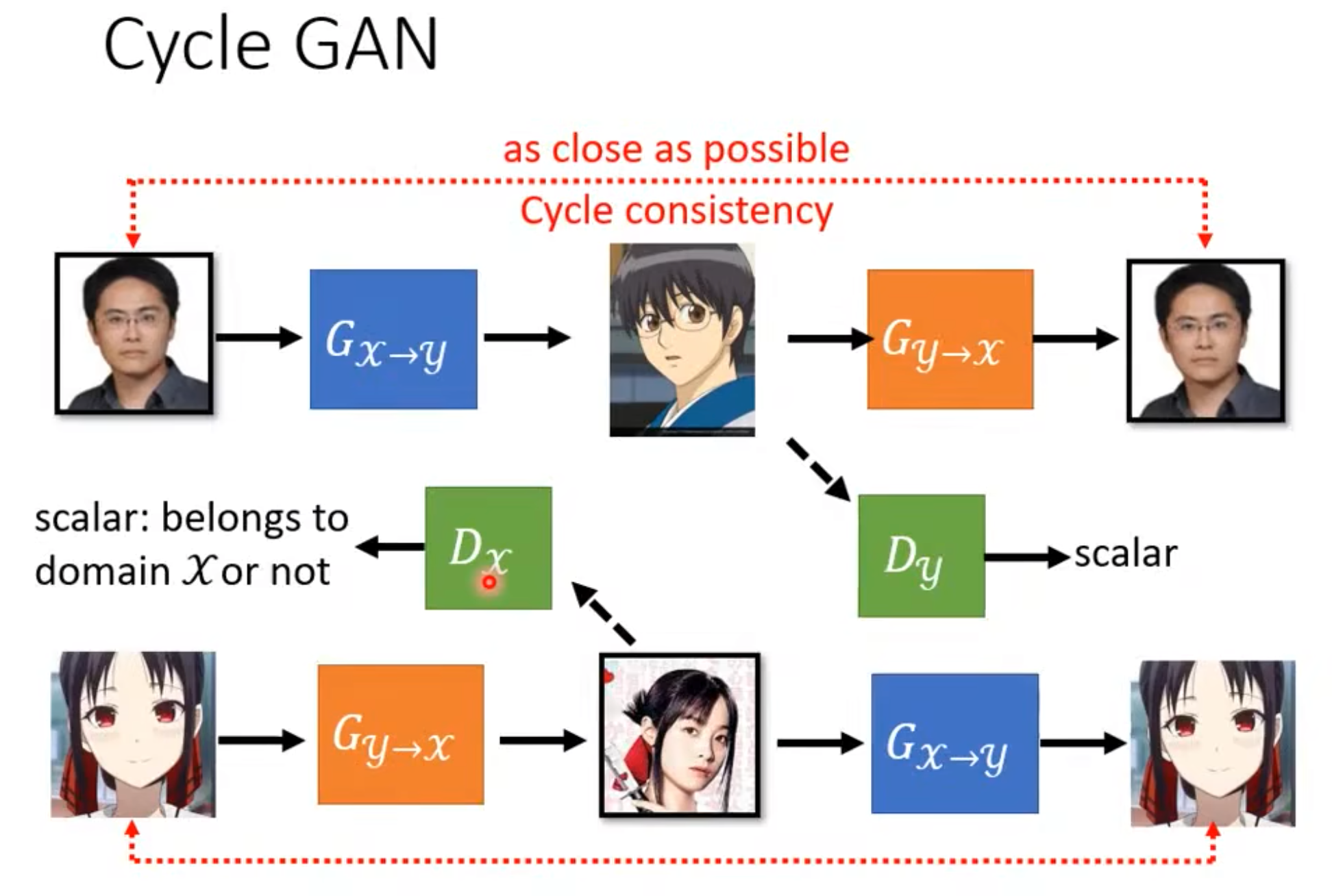
类似的,Cycle GAN也可以用于Text Style Transfer. minimize the reconstruction error
Theory behind GAN(optional)
Flow-based Generative Models
- Autoregressive model
- Component-by-component(Autoregressive model)
- Autoencoder
- Generative Adversarial Network(GAN)
- Generative Models
- Component-by-component(Auto-regressive Model)
- What is the best order for the components?
- Slow generation
- Variational Auto-encoder
- Optimizing a lower bound
- Generative Adversarial Network
- Unstable training
- Component-by-component(Auto-regressive Model)
- A generator G is a network. The network defines a probability distribution $p_G$。Normal Distribution $\pi(z)$ -> Generator G -> $p_G(x)$,什么样的G是好的呢?我们想$p_G(x)$的效果和$p_{data}(x)$越近越好。Maximize这俩的likelihood,等同于minimize $p_G$和$p_{data}$的KL散度。Flow-based model directly optimizes the objective function.
- Math background: Jacobian,Determinant,Change of Variable Theorem.
Self-supervised Learning
- GPT和Bert的能力不同,Bert是Encoder,侧重于理解。GPT是Decoder,侧重是生成。Bert是客观题,GPT是主观题!
Bert
Training & Tasks
Self-supervised,不用主动去进行标注,例如数据集,想办法让模型自己做supervised learning。从没有用到label这个角度上讲,这也是unsupervised learning。
Bert本质上就是一个Transformer的Encoder,一般用在NLP上,输入就是一个Sequence,输出也是一个sequence。
Bert的训练:
- Masked token prediction:训练的时候,Masking Input, Random. Randomly masking some tokens. 本质还是在做一个分类的问题,预测mask的词(类别)!
- Next sentence prediction: 这也是Bert可以执行的,[CLS] Sentence 1 [SEP] Sentence 2,输出是True/False,判断这两句话是不是连在一起的。This approach is not helpful, RoBERTa & SOP, 都是更加有用的任务!
训练完之后,可以很神奇用在不同的downstream tasks上:
- The tasks we care
- We have a little bit labeled data
- 把Bert拿过来,再训练一下,就可以用来做不同的任务。这件事儿就叫做fine-tune. Fine-tune之前,产生Bert的过程,就叫做Pre-train(这个就类似于胚胎干细胞)。Pre-train是Self-supervised,Fine-tune是Supervised,所以合起来就是semi-supervised(半监督学习)。
How to use BERT:
- Case 1: Input: sequence, output: class. Example: Sentiment analysis. [CLS] sentence -> [CLS]对应位置加上Linear,单个的Output。
- Case 2: Input\output are sequence, length same as input. Example: POS tagging,主打一个一对一。
- Case 3: Input: two sequences, output: class. Example: Natural Language Inference(NLI),两个句子,一个是premise,一个是hypothesis。从premise -> hypothesis,吐出这两个句子之间的关系。
- Case 4: Extraction-based QA, 答案一定出现在文章里面。Input: Document和Query,Output: two integers(start, end),这个Output就是一个字符串的范围,这里面的就是答案![CLS] question [SEP] document,fine-tune的时候,就可以不动Bert模型的主体参数了捏!
Pre-training a seq2seq model: 成对的sequence,把sequence“弄坏”,再还原回来,就可以train起来,让encoder -> decoder学到东西。
Why does BERT work
- The tokens with similar meaning have similar embedding.
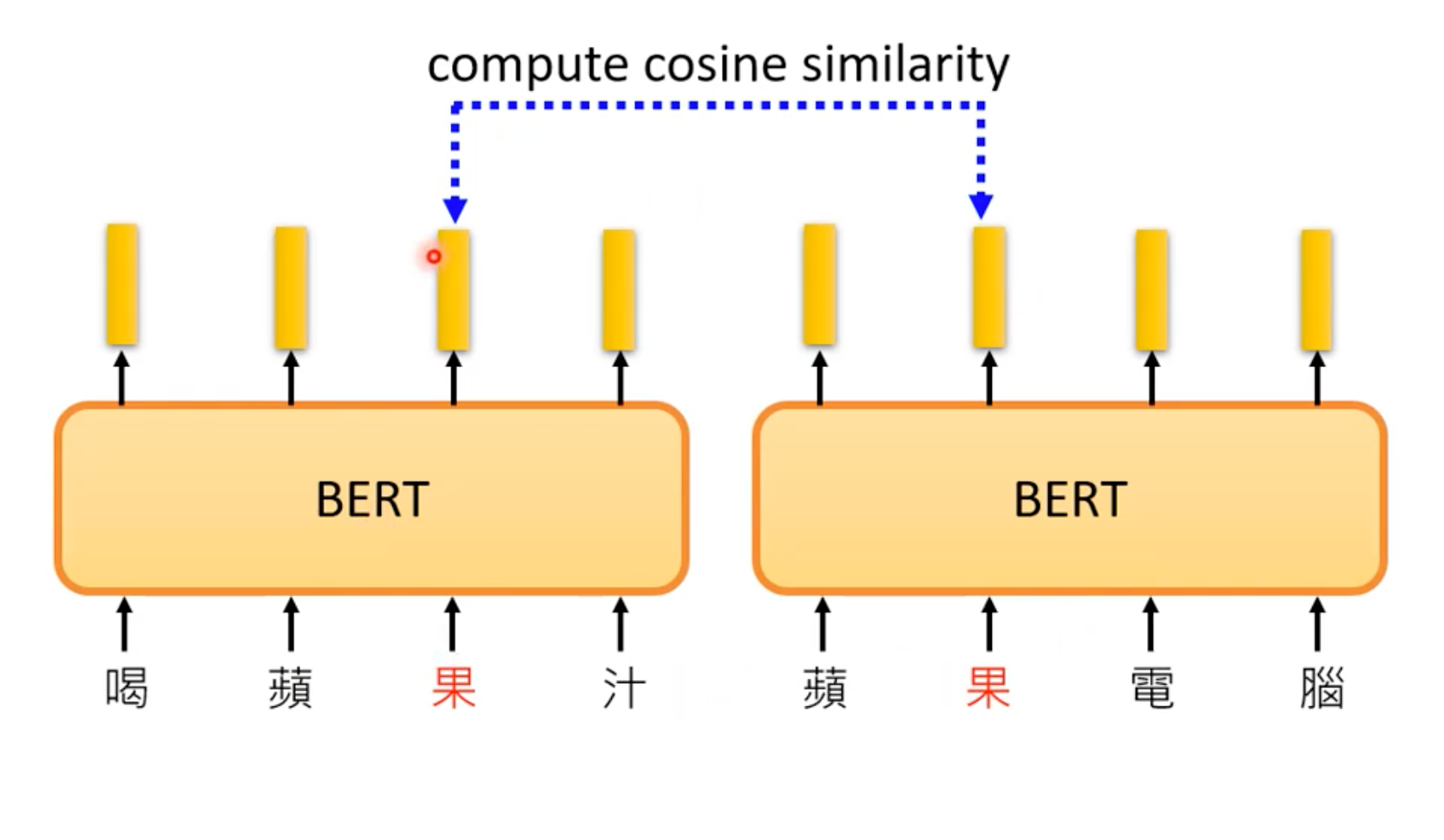
由于BERT里面的Self-Attention的存在,Embedding考虑了上下文的信息,是不一样的!”You shall know a word by the company it keeps”
- 在word之前,这种想法早就有了。Word Embedding技术!CBOW!CBOW很简单,就是简单几层Transform!Contextualized word embedding!
Multi-lingual BERT
- Training a BERT model by many different languages. 神奇!拿英文的QA做Fine-tune,它可以学到中文的东西????
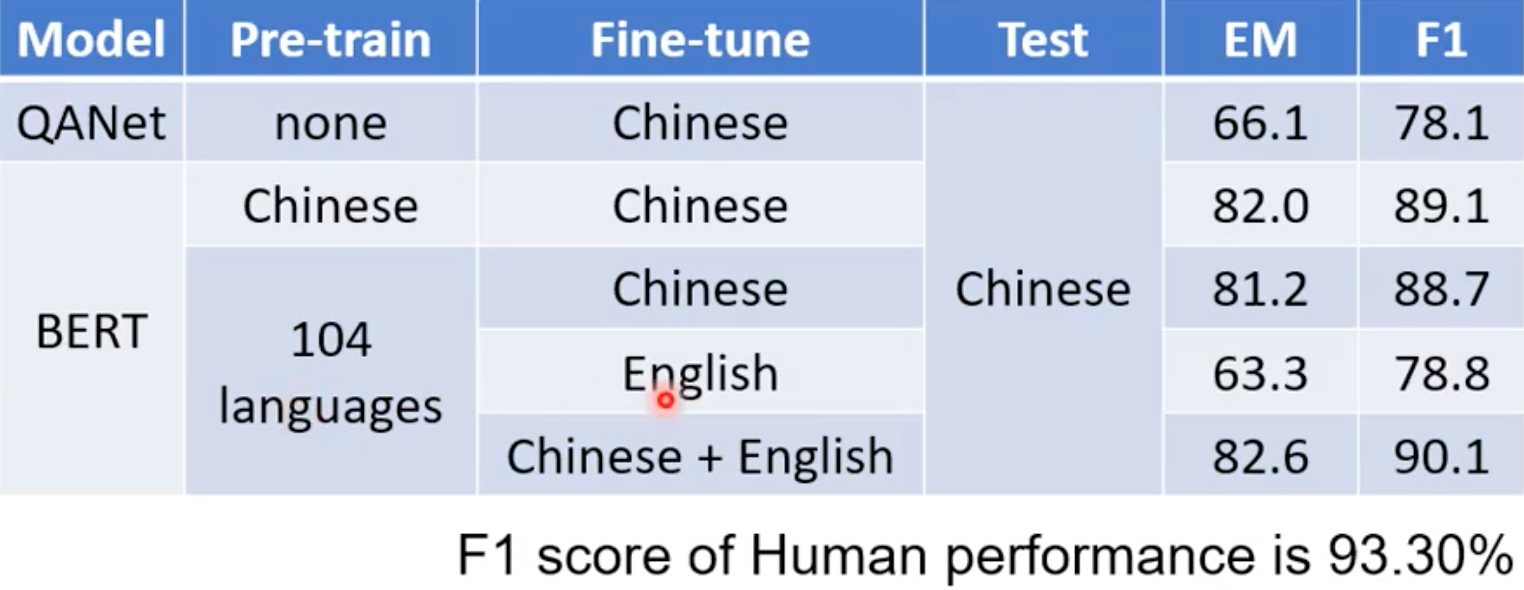
Cross-lingual alignment? 不同语言的embedding,相似含义的,可能是类似的!数据量变大,效果更好!!!
- 太强了,很震惊!!!甚至可以跨语言,算出difference的vector,把英文加上中英的这个differnce vector,Bert甚至可以输出中文???语言之间的差异,还是“藏”在了Bert里面!这种difference可能就是不同向量之间的距离。
GPT
- Transformer的Decoder,Predict Next Token,预测接下来要出现的内容是什么。就训练就完了!Decoder用的是那个Mask的Attention,看不到后面的,可以看到前面的。
- How to use GPT? 也可以和Bert一样,接一个简单的classifier。GPT有一个更狂的想法,seq2seq!”Few-shot”/“One-shot”/“Zero-shot” Learning(no gradient learning), “In-context” Learning。
- Beyond Text
- Image - SimCLR
- Image - BYOL
- Speech - Bert
- Benchmark: GLUE/Speech GLUE
Smaller Model
- Network Compression
- Network Pruning
- Knowledge Distillation
- Parameter Quantization
- Architecture Design
Excellent reference: http://mitchgordon.me/machine/learning/2019/11/18/all-the-ways-to-compress-BERT.html
- Transformer-XL:Segment-Level Recurrence with State Reuse
- Reformer
- Longformer
Reduce the complexity of self-attention
Fine-tune
Input:
- One sentence
- Multiple sentences
Output:
- one class
- class for each token
- copy from input
- general sequence
在当前的model上,再接上一层NN,根据不同的Output,接上不同的NN,来实现不同的功能!接上NN的时候,例如seq2seq,如果一个纯空白的task-specific decoder,效果可能就不好,都有pre-train就好了。用pre-train的model,当作decoder,auto-regressive one-by-one gen,好像就可以不用Encoder -> task-specific Decoder(v1),而是可以直接Encoder当成Decoder来用(v2)!!!
How to fine-tune
- Pre-trained Model训练完就不动了,Model当作Feature Extractor来用,就fix住就行。
- Task-specific和Pre-trained Model接起来,一起Fine-tune,当作一个巨大的Model. A gigantic model for down-stream tasks.
2的效果,往往比1好哦!
针对不同的下游任务,每个模型fine-tune,都要存一份,那太大,太浪费了!!! -> Adapter,我不调整个模型,就调整一部分!其他不动!存就存Adapter就可以,不用存一个完整的Model。
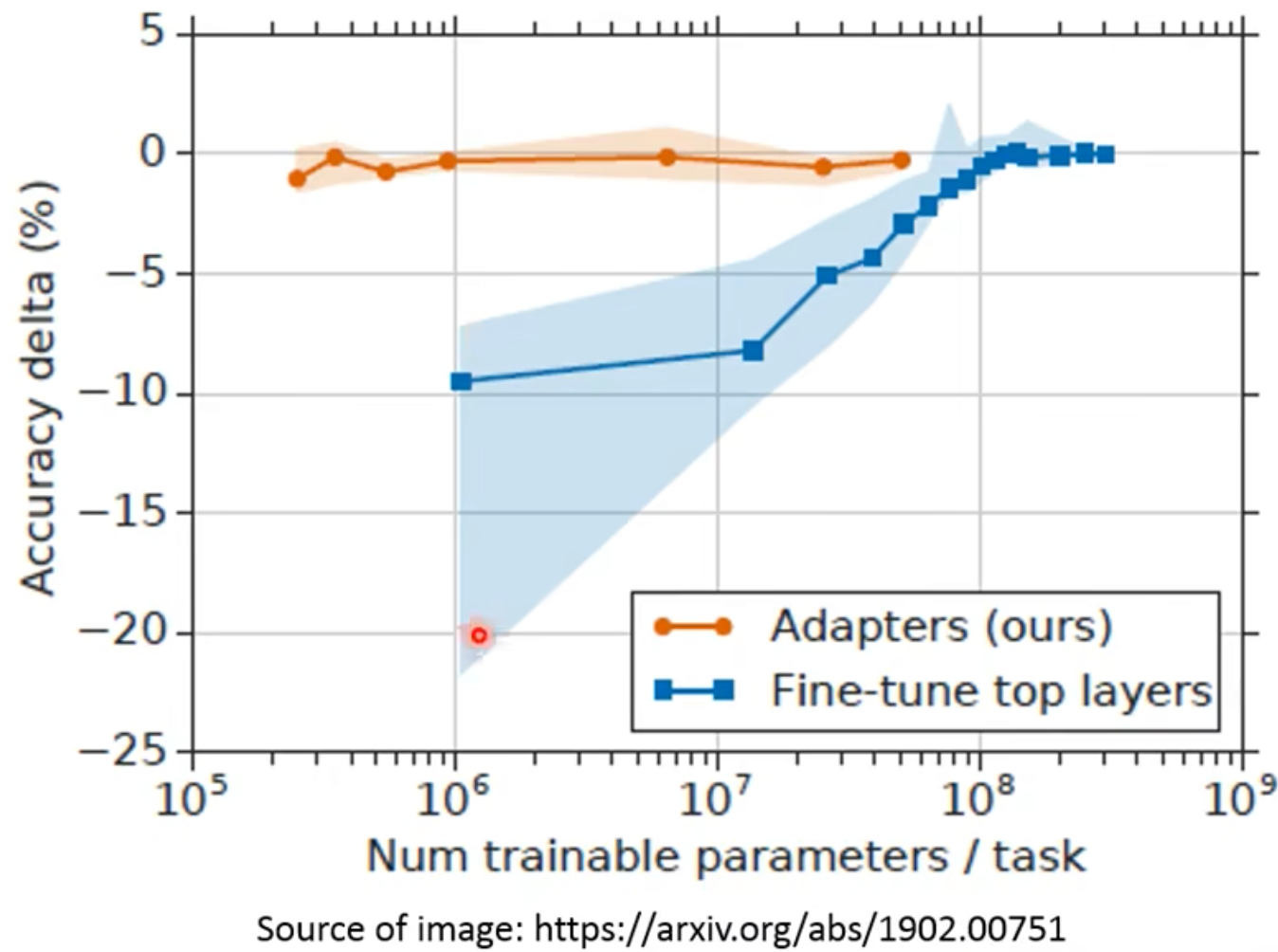
- Weighted Features: 联合不同层的参数!用不同层抽取出来的不同参数,做一个组合的特征!这都可以学!
- Why Pre-train Models? 这些models带给我们比较好的performance。而且Training loss也是比较快的下降!
Pre-train
Pre-train过程中,Attention都很多种玩法
- Context Vector(CoVe),Pre-training by Translation, 是一个Encoder-Decoder的架构,sentence pair的Input, output,就可以end2end训练出模型。sentence pair难搞, supervised-learning -> self-supervised learning
- ElMo是双向的,考虑两边的context - Predict Next Token(Bidirectional),但是用的是LSTM,并且“不会交汇”。单独拿两边的值的LSTM结果出来,汇总下,吐个result出来!
- Bert不是predict next token,而是把某些token给mask掉,然后预测这个mask是啥。Bert用attention的时候,是没有限制的,可以同时attention到前面和后面的内容。—> 和CBOW的思想一模一样好吧!拿某个点周围的数据,然后算个output出来。只不过CBOW过于简单罢了,通常左右20个,预测中间昂!(Using context to predict the missing token)
Bert pre-train过程中要masking input,怎么mask呢?
- Original Bert Input: 一次盖住一个token
- Whole Word Masking(WWM): 一次盖住一整个word所有的token
- Phrase-level & Entity-level: 一次盖住好几个Word,一次盖住一个Entity
- SpanBert: 每次随机盖住一排token,盖住几个呢?给了个概率分布,赌呗!
- SpanBert-Span Boundary Objective(SBO): 根据被盖住的tokens左右两边的embedding,去预测被盖住范围内的东西。SBO还有个Input是数字,代表预测被masked的tokens中,第几个位置的token。
Other Networks
XLNet
- Transformer-XL,Attention随机选取一些前后文的token,然后预测Mask的word。
Bert cannot talk? —> Given partial sequence,predict the next token. Limited to autoregressive model. MASS/BART: The pre-train model is a typical seg2seg model.
- MAsked Sequence to Sequence pre-training (MASS)
- Bidirectional and Auto-Regressive Transformers (BART)
UniLM: 同时又是Encoder、Decoder和Seq2seq LM.
ELECTRA: 改一些token,ELECTRA去判断哪些是有问题的!这个token最好是语法没错,语意有点点差别的感觉。生成数据?Bert可以生成这种数据!(有GAN那味儿了!)
Sentence整个可以做一个embedding吗?”You shall know a sentence by the company it keeps?” Skip Thought -> Quick Thought. NSP:Next sentence prediction
Robustly optimized BERT approach (RoBERTa), SOP:Sentence order prediction.
T5-Comparison
- Transfer Text-to-Text Transformer(T5)
- Colossal Clean Crawled Corpus(C4)
试了各种Pretraining的方法!
- Knowledge: Bert + External Knowledge(Knowledge Graph) —> ERNIE
- Audio Graph
Auto-encoder
很早了,其实也类似Self-supervised Learning, Pre-train! 感觉SD那边用的多!!!
Basic Idea of Auto-encoder
Input -> NN Encoder -> vector -> NN Decoder -> Output,让Output和Input越接近越好!GAN!这个思路好CycleGAN!
不需要标注资料,unsupervised learning的方法。
这个vector被称为Embedding, Representation, Code。vector可以当作是 new feature for downstream tasks!图片 -> vector,可以看作压缩!我就说我见过。。。这个玩意儿在Stable Diffusion里面,Pixel Space -> Latent Space用的就是AutoEncoder。。。High dim -> Low dim
More Dimension Reduction: PCA, t-SNE
De-noising Auto-encoder: Input -> Add noise -> NN Encoder -> vector -> NN Decoder -> Output(As close as possible to Input)
Bert也可以这样看啊!Bert就是de-noising auto-encoder,然后Noise就是Input(with masked token),Bert的输出就是Embedding,接一个NN(Decoder),Recontruction,还原被盖住的地方,拿到Output,要求这个Output和masked token尽可能的像!
Feature Disentanglement:
- 可以用来把不同模态的数据提取出来!Encoder就可以抽取!!!对于这个vector,就有很多操作可以做啦!
- Application: Voice Conversion
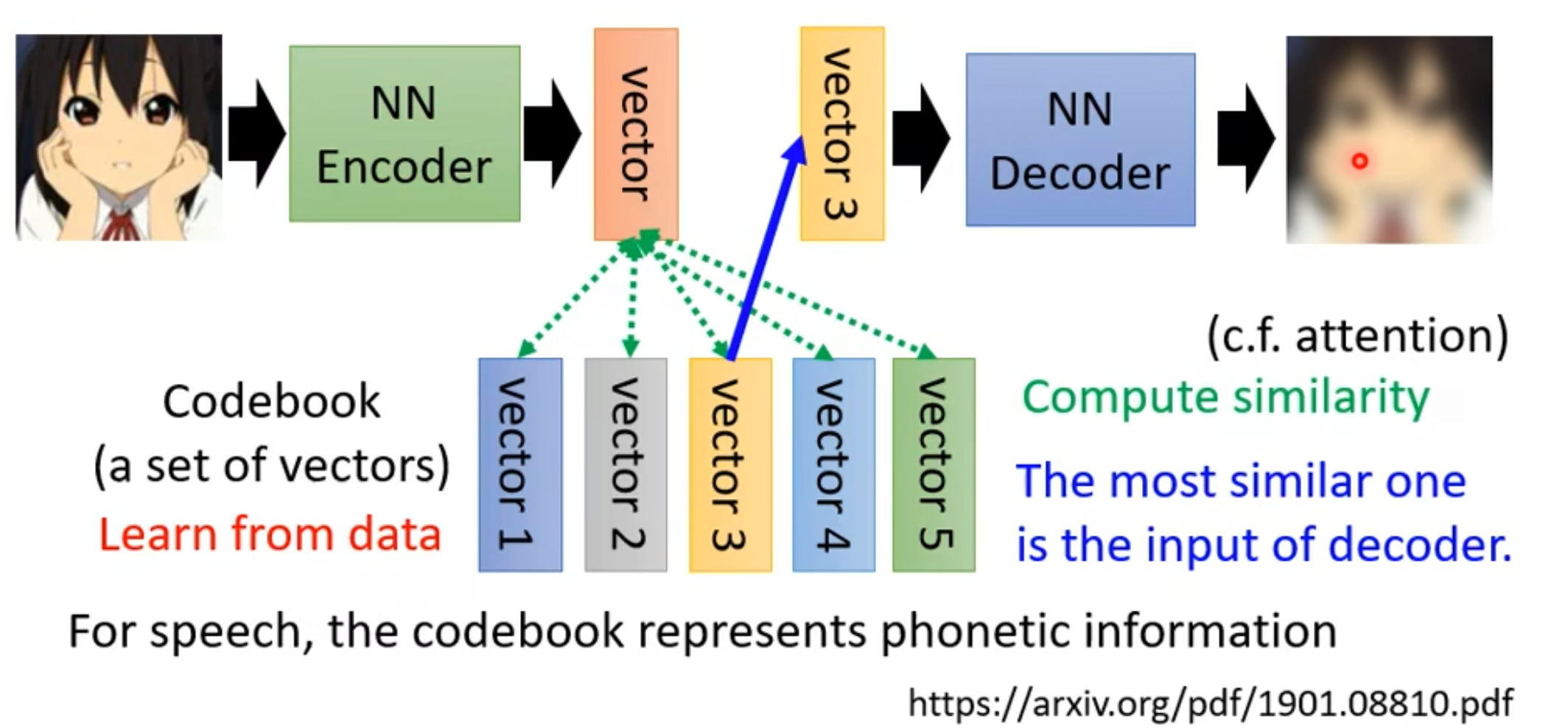
Discrete Latent Representation
- vector可以是Real numbers,也可以是Binary(可以代表某种特征的有或者没有),也可能是one-hot,可以作为分类问题哇,unsupervised分类,例如MNIST!
- Vector Quantized Variational Auto-encoder (VQVAE),类似self-attention,让vector去“选” codebook中的向量,作为塞入NN Decoder的输入!
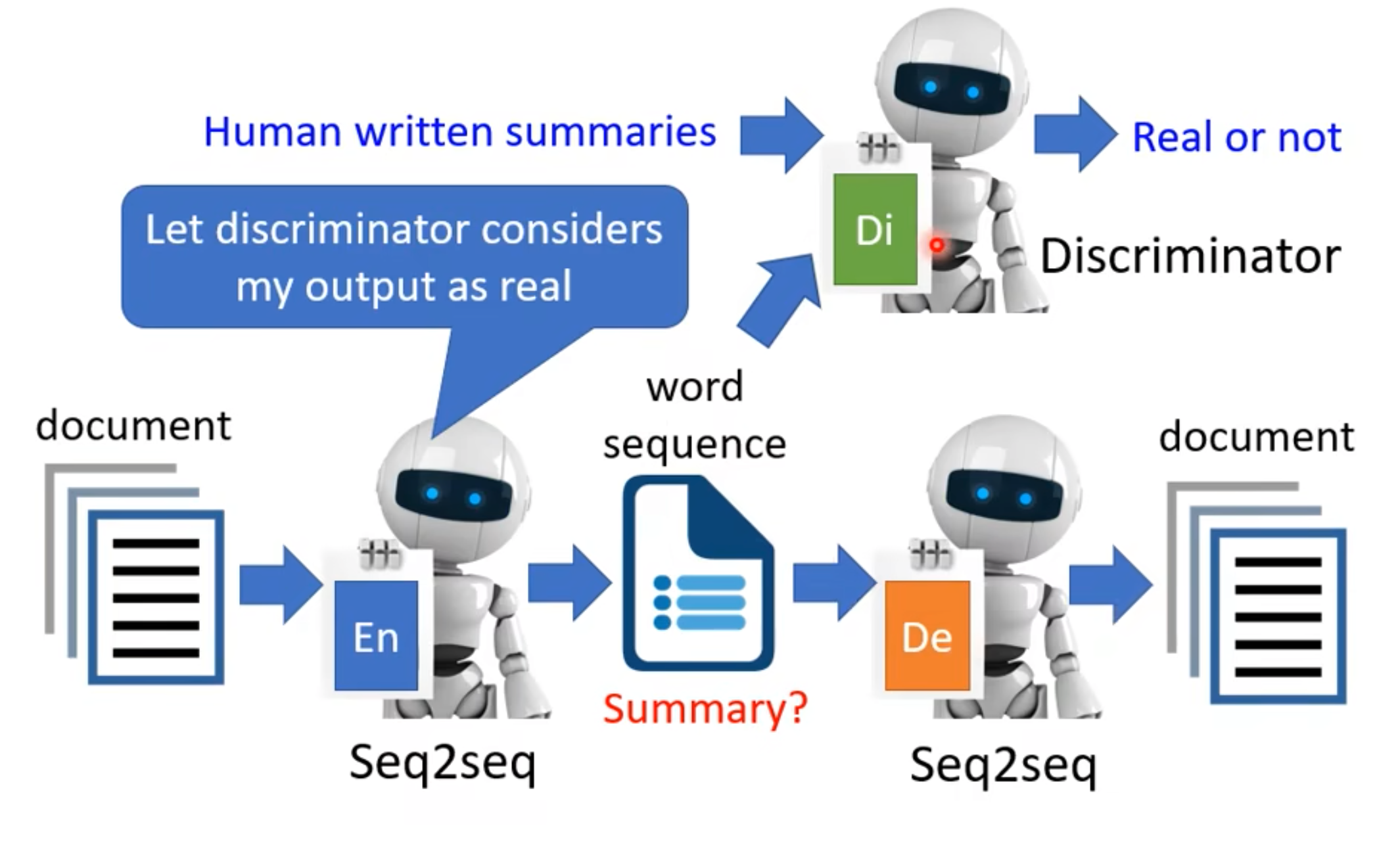
- Representation有多种,Text也可以作为Representation哇!Encoder -> Decoder中间的vector看不懂啊?咋办!Discriminator!
- Tree as Embedding
More Applications
With some modification,we have variational auto-encoder(VAE).
Encoder可以当作Compression来用,Decoder可以当作Generator来用。
Anomaly Detection
- Fraud Detection
- Training data:credit card transactions,x:fraud or not
- Ref: https://www.kaggle.com/ntnu-testimon/paysim1/home
- Ref: https://www.kaggle.com/mlg-ulb/creditcardfraud/home
- Network Intrusion Detection
- Training data:connection, x:attack or not
- Ref: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html
- Cancer Detection
- Training data:normal cells, x:cancer or not?
- Ref: https://www.kaggle.com/uciml/breast-cancer-wisconsin-data/home
- Binary Classification?
- We only have one class.
- Training auto-encoder
- Fraud Detection
More about Anomaly Detection
- Part 1: https://youtu.be/gDp2LXGnVLQ
- Part 2: https://youtu.be/cYrNjLxkoXs
- Part 3: https://youtu.be/ueDlm2FkCnw
- Part 4: https://youtu.be/XwkHOUPbcOQ
- Part 5: https://youtu.be/Fh1xFBktRLQ
- Part 6: https://youtu.be/LmFWzmn2rFY
- Part 7: https://youtu.be/6W8FqUGYyDo
Unsupervised Learning
Clustering & Dimension Reduction
Clustering
Pre: How many clusters?
- k-means
- Hierarchical Agglomerative Clustering(HAC): Build a tree due to similarity and pick a threshold
Distributed Representation
- Clustering: an object must belong to one cluster
- Distributed representation(Dimension Reduction)
Dimension Reduction
- Feature Selection
- Principle component analysis
这两节课主要在讲
- PCA
- t-SNE(Neighbor Embedding)
Explainable Machine Learning
Tradeoff between Interpretable and Powerful.
Goal of Explainable ML: Reasons that make people comforatble.
- Local Explanation: Why do you think this image is a cat?
- Global Explanation: What does a “cat”look like? (not referred to a specific image)
Local Explanation
- Noisy Gradient
- Gradient Saturation
- Integrated Gradient
How a network processes the input data?
- Visualization(PCA, t-SNE等等) -> Plot on figure
- 某个层拿出来,看看效果
- Attention看看
- Probing(探针看看!!!)
- Visualization(PCA, t-SNE等等) -> Plot on figure
Global Explanation
Outlook:
- Using an interpretable model to mimic the behavior of an uninterpretable model.
- Local Interpretable Model-Agnostic Explanations(LIME)
Adversial Attack
Attack & Approach
Motivation: Are networks robust to the inputs that are built to fool them? -> Useful for spam classification, malware detection,network intrusion detection,etc.
Example Attack
- Non-targeted: 让输出不是正确的输出就行 -> 对应的Input,离output越大越好。(input改动也越小越好)
- Targeted: 输出指定的Output => 对应的Input,离output越大越好的同时,离对应的target越小越好。(input改动也越小越好)
Non-perceivable如何实现?
- Need to consider human perception
- 上面说的,两个图片之间的区别,本质上就是X’ - X,算一个”Distance”。L2和L-Infinity都可以算,但是为了让“人眼”看起来更像,L-Infinity看起来会更好!这个就是loss的一部分昂!
综合上面的说法,除了我们的Loss Function之外,Non-perceivable是这个Loss Function的另外一个Constraint条件,限制我们的Input的取值范围!
- Attack approach
- Update input, not parameters
- Gradient Descent
- Start from original image $x^0$
- For t 1 to T,
- $x^t = x^{t-1} - \eta\times gradient$
- if $d(x^0, x) > \epsilon$ (符合human non-perceivable的最小范围),$x^t = fix(x^t)$,只要超出了“方框”,就找一个最近的,把这个点拉回来!(这个就叫做fix昂!)
- 常见的Attack approach都差不多,但是要么是optimization method不一样,要么是constraints不一样。e.g. Fast Gradient Sign Method(FGSM), Iterative FGSM
White Box & Black Box
White Box v.s. Black Box
- White Box: 知道模型参数后再进行攻击。(和上面的一样,知道模型参数之后,就可以算Gradient来更新我们自己的Input了!)
- Black Box: You cannot obtain model parameters in most online APl.
Black Box Attack method:
- We have training data: If you have the training data of the target network. Train a proxy network yourself. -> 用proxy network来模仿Network Black的行为,这两者会有一定程度相似,只要对proxy network攻击就相当于对Black Box进行攻击。
- What if we do not know the training data? 用Black Network来“造”数据集,丢一堆进去,拿出来结果。然后再重复上面“We have training data”的做法就好。好好好,这么玩儿是吧orz
- Non-targeted在黑箱场景中比较容易成功,而targeted不太容易成功。
Why the attack is so easy! Why? -> Adversarial Examples Are Not Bugs. They Are Features.
More:
- One pixel attack
- Universal Adversarial Attack
More attacks
Beyond Images
- Speech processing (Detect synthesized speech)
- Natural language processing
Attack in the physical world
- An attacker would need to find perturbations that generalize beyond a single image.
- Extreme differences between adjacent pixels in the perturbation are unlikely to be accurately captured by cameras.
- It is desirable to craft perturbations that are comprised mostly of colors reproducible by the printer.
Adversarial Reprogramming: “寄生”,我可以通过植入特定的pixel之类的,强迫模型输出特定的值,做一些“不太合法”的工作。
- “Backdoor” in Model: 训练的时候就展开攻击!数据甚至都是对的,但是能够影响对于别的一些特定资料,输出特定的输出。留下“后门”。Be careful of unknown dataset ……
Defensive
- Passive Defense
- 在模型前面加一个filter,让攻击图片less harmful。这个Filter可能很简单可能就有用喔,比如让图片轻微模糊一点!(但是可能会有一点副作用昂!)
- Image Compression: https://arxiv.org/abs/1704.01155, https://arxiv.org/abs/1802.06816
- Generator: https://arxiv.org/abs/1805.06605
- Randomization: https://arxiv.org/abs/1711.01991。问题:一旦别人知道了,模糊化这个Filter也可以看作是网络的一层啊,重新再训练就行!一旦被发现,很快就没用了捏!随机防御,会比上面的好!别人知道了你的随机的分布,其实也会有一些危险昂!
- Proactive Defense
- Adversarial Training: 训练的时候,就进行攻击。把攻击的图片,标成正确的label,训练就够猛!Find the problem -> Fix it! 可以看作是Data Augmentation,也可以用这样的方法,产生更多的资料,让模型更加robust捏!
- 问题:
- 很难deal with new algorithm,如果考虑不到新的algorithm,可能就没有Augmented那种攻击的情况哇!
- 吃运算资源,数据集大就不太好做。。。有一些研究就是: Adversarial Training for Free!
https://arxiv.org/abs/1904.12843