Stable Diffusion and ComfyUI Tutorial
本文最后更新于:1 年前
最近做的一些内容偏向Stable Diffusion的应用,也用到了类似于WebUI和ComfyUI这样的UI工具。网上的教程多、杂、乱,就寻思的记录下自己摸索过程中的学习内容吧!这里很多东西都是参考网上的哈,只不过是摘抄+学习,具体用到的网站会放到References下面。另外,SD is the short of Stable Diffusion.
Summary
- 在我看来,Stable Diffusion能够执行的任务有很多种。但是无非是在几种不同的形式之间转换:txt, img, vedio
- 常见的转换与任务有:
- txt2img
- img2img
- Style Transfer
- Upscaling
- Inpainting
- img2vedio
- vedio2vedio
- Stable Diffusion能做的本质就是,把“模糊的东西变清楚”,这一点十分重要。可以本来是糊的,也可以是后来我们手动糊上去的。调参无非也就是,怎么糊?糊多少?怎么变清楚,引导或者参考?清楚成什么样子?
How to use Stable Diffusion
SD Introduction
This beginner’s guide is for newbies with zero experience with Stable Diffusion or other AI image generators. You will get an overview of Stable Diffusion and some basic useful tips. SD beginners-guide
SD是一种用于生成 AI 图像的潜在扩散模型。这些图像可以是逼真的,就像相机拍摄的图像一样,也可以是艺术风格的,就像由专业艺术家制作的一样。SD的好处有:
- 开源:许多爱好者创建了免费的工具和模型。
- 专为低功耗计算机设计:免费或运行成本低廉。
如何使用SD? Prompt!
SD能做什么?
- text2img
- img2img
- inpainting
- make vedioes
- text2vedio
- vedio2vedio(Stylize, …)
如何使用SD
- 在线生成器
- GUI
GUI能够带给你的好处:
- Advanced prompting techniques.
- Regenerate a small part of an image with Inpainting.
- Generate images based on an input image (Image-to-image)
- Edit an image by giving an instruction.
Prompt Matters
- 如何建立一个好的Prompt
- 一些Prompt的经验法则
- 详细且具体:街上的一个女人 -> 一位年轻的女士,棕色的眼睛,头发亮点,微笑,穿着时尚的商务休闲装,坐在外面,安静的城市街道,边缘照明
- 使用强大的关键词:有些关键字比其他关键字更强大。名人名字(例如艾玛·沃特森)、艺术家姓名(例如梵高)、艺术媒介(例如插图、绘画、照片)
- 您可以在构建提示的基础知识中了解有关提示构建和示例关键字的更多信息。想作弊吗?就像做作业一样,您可以使用ChatGPT来生成提示!
Picture Gen Params
- 生成图片的时候,一些参数和其作用:
强烈推荐,参阅其他设置的建议。
- 生成图像数量?我会一次生成 2-4 个图像,以便加快搜索速度。当进行小的更改以增加看到可用内容的机会时,我会一次生成 4 个。有些提示只能在一半或更少的时间内起作用。因此,不要根据一张图像就取消提示。
Picture Images Defects
当你看到社交媒体上分享的令人惊叹的人工智能图像时,它们很可能经过了一系列的后处理步骤。
- 面部修复:SD不擅长生成面部。很多时候,生成的面孔存在伪影。我们经常使用经过训练来恢复人脸的图像 AI 模型,例如CodeFormer,AUTOMATIC1111 GUI 具有内置支持。看看如何打开它。您知道 v1.4 和 v1.5 模型有修复眼睛的更新吗?查看如何安装VAE。
- 修复Inpainting小瑕疵: 第一次尝试很难获得您想要的图像。更好的方法是生成具有良好构图的图像。然后用修补法修复缺陷。
- 还有其他技术可以解决问题。阅读有关解决常见问题的更多信息。
Custom Models
模型介绍
使用哪种型号?
- 如果您刚开始,请坚持使用基本模型。有很多值得学习和玩耍的东西,可以让你忙上几个月。
- Stable Diffusion 的三个主要版本是 v1、v2 和 Stable Diffusion XL (SDXL)。
- v1 型号为 1.4 和 1.5。
- v2 型号为 2.0 和 2.1。
- SDXL 1.0
- 您可能认为应该从较新的 v2 型号开始。人们仍在试图弄清楚如何使用 v2 模型。v2 的图像不一定比 v1 的图像好。发布了一系列SDXL模型:SDXL beta、SDXL 0.9和最新的SDXL 1.0。如果您是稳定扩散的新手,我建议您使用v1.5和 SDXL 1.0 模型。
如何训练新模型
- 使用SD的优点是您可以完全控制模型。如果您愿意,您可以创建具有独特风格的自己的模型。训练模型的两种主要方法:(1)Dreambooth和(2)Embedding。
- Dreambooth被认为更强大,因为它微调了整个模型的重量。Embedding使模型保持不变,但找到描述新主题或风格的关键字。
- 您可以在dreambooth文章中尝试使用 Colab 笔记本。
Negative Prompts
您在提示中输入您想看到的内容。你把你不想看到的东西放在否定提示中。并非所有稳定扩散服务都支持负面提示。但它对于 v1 模型来说很有价值,对于 v2 模型来说是必须的。对于初学者来说,使用通用的否定提示并没有什么坏处。阅读有关负面提示的更多信息:
SD Make Large Prints
对于 v1 模型,稳定扩散的原始分辨率为 512×512 像素。您不应生成宽度和高度与 512 像素偏差太大的图像。使用以下尺寸设置生成初始图像。
- 横向图像:将高度设置为 512 像素。将宽度设置得更高,例如 768 像素(2:3 宽高比)
- 纵向图像:将宽度设置为 512 像素。将高度设置得更高,例如 768 像素(3:2 宽高比)
- 如果您将初始宽度和高度设置得太高,您将看到重复的主题。
下一步是放大图像。免费的 AUTOMATIC1111 GUI 附带一些流行的 AI 升级器。
Control Image Composition
- Image-to-image: 您可以要求稳定扩散在生成新图像时大致遵循输入图像。这称为图像到图像。下面是使用鹰的输入图像生成龙的示例。输出图像的组成遵循输入。
- ControlNet: ControlNet类似地使用输入图像来指导输出。但它可以提取特定信息,例如人体姿势。下面是使用 ControlNet 从输入图像复制人体姿势的示例。除了人体姿势之外,ControlNet 还可以提取其他信息,例如轮廓。
- Regional prompting: 您可以使用名为Regional Prompter 的扩展指定图像某些部分的提示。此技术对于仅在图像的某些部分绘制对象非常有帮助。阅读区域提示器教程以了解更多使用方法。
- Depth-to-image: 图像深度是通过输入图像控制构图的另一种方法。它可以检测输入图像的前景和背景。输出图像将遵循相同的前景和背景。下面是一个例子。
Generating Specific Subjects
- 现实的人:您可以使用稳定扩散来生成照片风格的逼真人物。是使用正确的提示和经过训练的特殊模型来产生照片风格的逼真人类。在生成真实人物的教程中了解更多信息。
- 动物:动物是SD用户中最受欢迎的主题。 阅读生成动物的教程以了解如何操作。
Good Prompts for SD
Prompt Guide
快速构建是任何SD用户都应该掌握的基本技能。通过了解如何构建清晰简洁的提示,您可以解锁 Stable Diffusion 提供的全部风格。为了擅长提示构建,您应该从一个特定的主题开始,并添加关键字以达到特定的效果。SD prompts
如果您想练习快速构建但尚未设置稳定扩散,您可以在线使用免费的稳定扩散生成器。如果您想自行设置,请阅读快速入门指南。使用提示生成器 以系统的方法来制作提示。这篇文章旨在成为您的第一门提示课程。请参阅此提示指南以了解高级技术。
这是一种经过验证的技术,可以生成高质量的特定图像。您的提示应该涵盖大部分(如果不是全部)这些区域。
- Subject (required)
- Medium
- Style
- Artist
- Website
- Resolution
- Additional details
- Color
- Lighting
Subject:
- 初学者的一个常见错误是没有足够详细地描述图像。她穿什么衣服?她的发型是什么?这些看似微不足道的元素可以对所传达的整体形象做出重大贡献。如果不指定这些详细信息,您就将它们留给 AI 生成器,您可能会对得到的结果感到失望。
- 包含通用的否定提示是一个好习惯。ugly, deform, disfigured。
Medium:
- 我们可以更具体。让我们添加一个Medium,即创作艺术品的材料。一些例子是digital painting, photography, and oil painting。Digital painting of a young woman with light blue dress sitting next to a wooden window reading a book
其余
- Artist– 指定创作艺术的艺术家来引导风格。 by Stanley Artgerm Lau
- Website– 网站名称可用于特定类型。 artstation
- Resolution– 这些是控制图像清晰度的关键字。8k
Additional details– 这些关键词更像是甜味剂,例如添加一些有趣的细节。extremely detailed, ornateLighting–控制光线对于获得良好的图像非常重要。cinematic lighting, rim lightingcolor– 图像的配色方案。vivid
Putting them all together, the prompt is: Digital painting of a young woman with light blue dress sitting next to a wooden window reading a book, by Stanley Artgerm Lau, artstation, 8k, extremely detailed, ornate, cinematic lighting, rim lighting, vivid.
我们可以通过在提示中添加特定的关键字来设计图像以获得我们想要的样式。
- Tips for good prompts
- 描述主题时要详细、具体。
- 使用多个括号 () 可以增加其强度,使用 [] 可以减少强度。
- 使用与艺术家一致的适当媒介类型。例如,照片不应该与梵高一起使用。
- 艺术家的名字是一个非常强烈的风格修饰符。明智地使用。
- 尝试混合风格。
- 前往Workflow section研究高质量的提示。如果您喜欢特定图像,请使用提示作为起点。
Good Prompt List
Some good keywords: You can find the full list in the prompt builder.
Medium: Medium defines a category of artwork.
| keyword | Note |
|---|---|
| Portrait | Very realistic drawings. Good to use with people. |
| Digital painting | Digital art style. |
| Concept art | Illustration style, 2D. |
| Ultra realistic illustration | Drawings that are very realistic. Good to use with people. |
| Underwater portrait | Use with people. Underwater. Hair floating. |
| Underwater steampunk | Very realistic drawings. Good to use with people. |
- Style: These keywords further refine the art style.
| keyword | Note |
|---|---|
| hyperrealistic | Increases details and resolution |
| pop-art | Pop-art style |
| Modernist | vibrant color, high contrast |
| art nouveau | Add ornaments and details, building style |
- Artist: Mentioning the artist in the prompt is a strong effect. Study their work and choose wisely.
| keyword | Note |
|---|---|
| John Collier | 19th century portrait painter. Add elegancy |
| Stanley Artgerm Lau | Good to use with woman portrait, generate 19th delicate clothing, some impressionism |
| Frida Kahlo | Quite strong effect following Kahlo’s portrait style. Sometimes result in picture frame |
| John Singer Sargent | Good to use with woman portraits, generate 19th delicate clothing, some impressionism |
| Alphonse Mucha | 2D portrait painting in style of Alphonse Mucha |
- Website: Mentioning an art or photo site is a strong effect, probably because each site has its niche genre.
| keyword | Note |
|---|---|
| pixiv | Japanese anime style |
| pixabay | Commercial stock photo style |
| artstation | Modern illustration, fantasy |
- Resolution
| keyword | Note |
|---|---|
| unreal engine | Very realistic and detailed 3D |
| sharp focus | Increase resolution |
| 8k | Increase resolution, though can lead to it looking more fake. Makes the image more camera like and realistic |
| vray | 3D rendering best for objects, landscape and building. |
- Lighting
| keyword | Note |
|---|---|
| rim lighting | light on edge of an object |
| cinematic lighting | A generic term to improve contrast by using light |
| crepuscular rays | sunlight breaking through the cloud |
- Additional details: Add specific details to your image.
| keyword | Note |
|---|---|
| dramatic | shot from a low angle |
| silk | Add silk to clothing |
| expansive | More open background, smaller subject |
| low angle shot | shot from low angle |
| god rays | sunlight breaking through the cloud |
| psychedelic | vivid color with distortion |
- Color: Add an additional color scheme to the image.
| keyword | Note |
|---|---|
| iridescent gold | Shinny gold |
| silver | Silver color |
| vintage | vintage effect |
We have gone through the basic structure of a good prompt. This should be used as a guide rather than rule. The Stable Diffusion model is very flexible. Let it surprise you with some creative combination of keywords!
How Stable Diffusion Works
Diffusion Model Introduction
Stable Diffusion is a latent diffusion model that generates AI images from text. Instead of operating in the high-dimensional image space, it first compresses the image into the latent space. How SD works
SD属于一类称为扩散模型的深度学习模型。它们是生成模型,这意味着它们旨在生成与训练中看到的类似的新数据。在SD的情况下,数据是图像。
扩散那些事儿
- 前向扩散:前向扩散将照片变成噪声。前向扩散过程向训练图像添加噪声,逐渐将其变成不典型的噪声图像。 就像一滴墨水落入一杯水中。墨滴在水中扩散。几分钟后,它随机分布在整个水中。您不再能够判断它最初是落在中心还是边缘附近。
- 反向扩散:如果我们可以逆转扩散呢?就像倒放视频一样。时间倒退。我们将看到墨滴最初添加的位置。 从嘈杂、无意义的图像开始,反向扩散恢复为原始的图像。这是主要思想。
- 从技术上讲,每个扩散过程都有两个部分:(1)漂移和(2)随机运动。反向扩散会偏向猫或狗图像,但不会偏向于两者之间。这就是为什么结果可以是猫或狗。
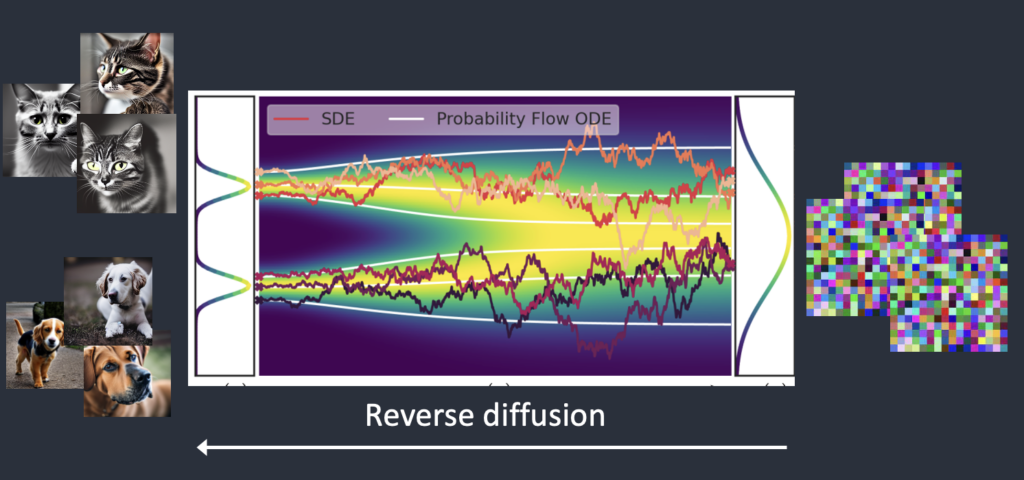
如何训练一个扩散模型呢?为了反转扩散,我们需要知道图像中添加了多少噪声。答案是训练神经网络模型来预测添加的噪声。它在稳定扩散中被称为噪声预测器。它是一个U-Net模型。
训练过程如下:
- 选择一张训练图像,例如猫的照片。
- 生成随机噪声图像。
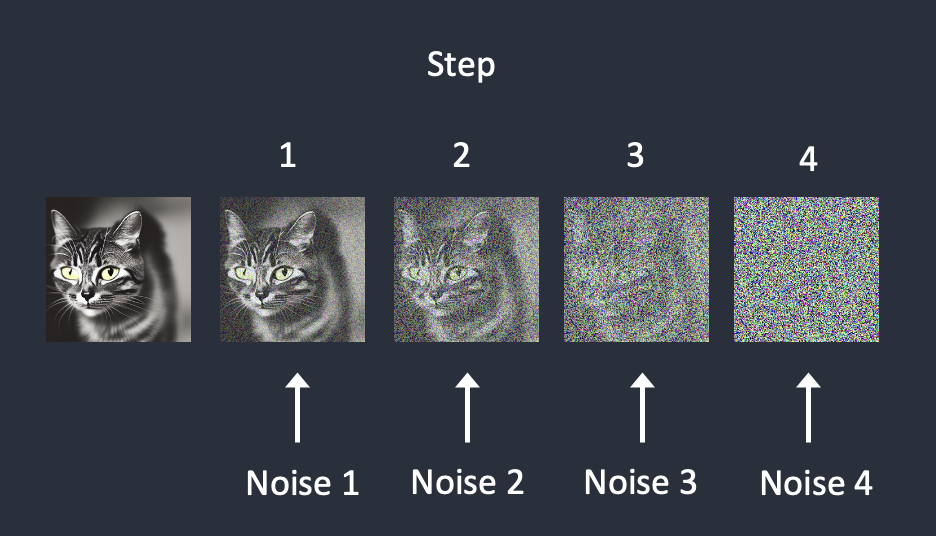
- 通过将噪声图像添加到一定数量的步骤,来破坏训练图像。
- 教噪声预测器告诉我们添加了多少噪声,这是通过调整其权重并向其显示正确答案来完成的。
在每个步骤中依次添加噪声。噪声预测器估计每一步添加的总噪声。添加噪声:
训练后,我们有了一个噪声预测器,能够估计添加到图像中的噪声。
反向扩散:我们首先生成一个完全随机的图像,并要求噪声预测器告诉我们噪声。然后我们从原始图像中减去估计的噪声。重复此过程几次。您将获得猫或狗的图像。

Stable Diffusion Model Introduction
上述扩散过程是在图像空间中进行的。它的计算速度非常非常慢。您将无法在任何单个 GPU 上运行,更不用说笔记本电脑上的蹩脚 GPU 了。 图像空间是巨大的。想想看:具有三个颜色通道(红、绿、蓝)的 512×512 图像是一个 786,432 维的空间!
Latent Space
- Latent Duffusion Model: Stable Diffusion Model旨在解决速度问题。 SD是一种潜在扩散模型。它不是在高维图像空间中操作,而是首先将图像压缩到潜在空间中。潜在空间小了 48 倍,因此它获得了处理更少数字的好处。这就是为什么它要快得多。
- 为什么潜在空间可能存在?您可能想知道为什么 VAE 可以将图像压缩到更小的潜在空间而不丢失信息。毫不奇怪,原因是自然图像不是随机的。它们具有高度的规律性:面部遵循眼睛、鼻子、脸颊和嘴巴之间的特定空间关系。图像的高维性是人为的。自然图像可以很容易地压缩到更小的潜在空间中,而不会丢失任何信息。这在机器学习中被称为Manifold hypothesis 流形假设
- Reverse diffusion in latent space, Here’s how latent reverse diffusion in Stable Diffusion works.
- 生成随机潜在空间矩阵。
- 噪声预测器估计潜在矩阵的噪声。
- 然后从潜在矩阵中减去估计的噪声。
- 重复步骤 2 和 3 直至达到特定的采样步骤。
- VAE 的解码器将潜在矩阵转换为最终图像。
VAE
- Variational Autoencoder(VAE): 可以做到图像在Pixel和Latent之间的转换,变分自动编码器 (VAE) 神经网络有两部分:(1) 编码器和 (2) 解码器。编码器将图像压缩为潜在空间中的较低维表示。解码器从潜在空间恢复图像。
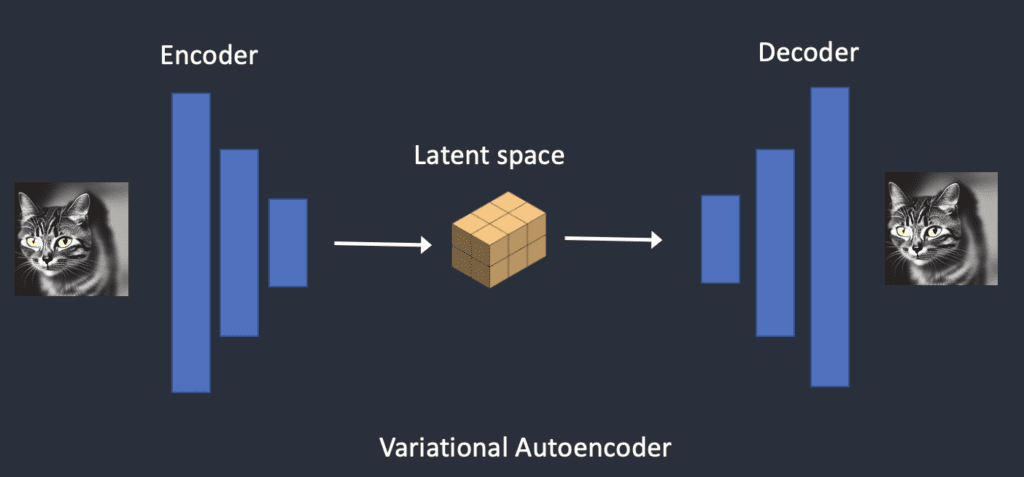
- SD的潜在空间为 4x64x64,比图像像素空间小 48 倍。我们谈到的所有前向和反向扩散实际上都是在潜在空间中完成的。
- 在训练过程中,它不会生成噪声图像,而是在潜在空间(潜在噪声)中生成随机张量。它不是用噪声破坏图像,而是用潜在噪声破坏图像在潜在空间中的表示。这样做的原因是它的速度要快得多,因为潜在空间更小。
- 什么是 .vae 文件?Stable Diffusion v1 中使用VAE 文件来改善眼睛和面部。它们就是我们刚才谈到的自动编码器的解码器。通过进一步微调解码器,模型可以绘制更精细的细节。您可能意识到我之前提到的并不完全正确。将图像压缩到潜在空间确实会丢失信息,因为原始 VAE 无法恢复精细细节。相反,VAE 解码器负责绘制精细细节。
Upscaling
图像分辨率
图像分辨率反映在潜像张量的大小上。仅对于 512×512 图像,潜在图像的大小为 4x64x64。768×512 肖像图像的尺寸为 4x96x64。这就是为什么需要更长、更多的 VRAM 才能生成更大的图像。
由于SD v1 在 512×512 图像上进行了微调,因此生成大于 512×512 的图像可能会导致重复的对象,例如臭名昭著的两个头。
图像放大: 要生成大打印,请将图像的至少一侧保持为 512 像素。使用AI 放大器或图像到图像功能进行图像放大。或者,使用SDXL型号。它的默认尺寸更大,为 1,024 x 1,024 像素。
Conditioning
我们的理解不完整:文字提示在哪里进入图片?没有它,稳定扩散就不是文本到图像的模型。您可能获得猫或狗的图像,而没有任何方法可以控制它。
这就是Conditioning作用的用武之地。条件作用的目的是引导噪声预测器,以便预测的噪声在从图像中减去后能够为我们提供我们想要的结果。
Text Conditioning: 下面概述了如何处理文本提示并将其输入噪声预测器。 Tokenizer首先将提示中的每个单词转换为一个称为token的数字。然后,每个标记都会转换为一个称为embedding的 768 个值向量。 嵌入随后由文本转换器进行处理,并准备好供噪声预测器使用。
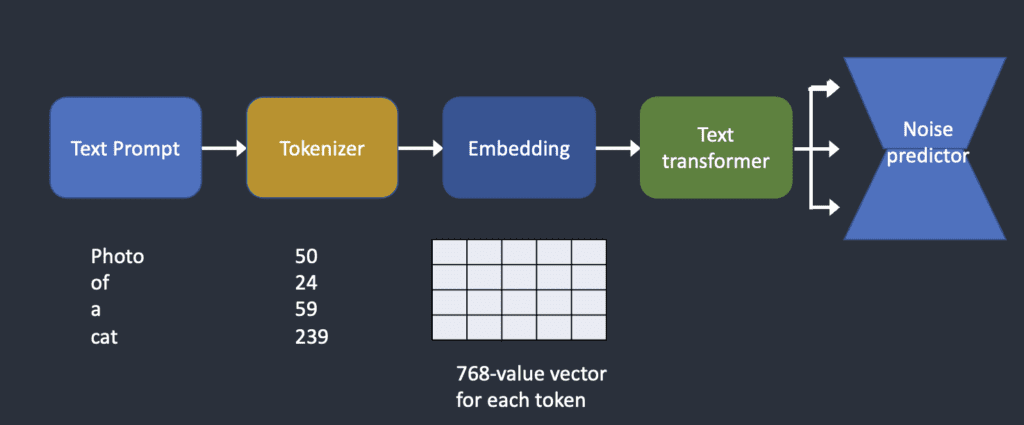
- Tokenizer: 文本提示首先由CLIP 标记器进行分词。 一个词并不总是意味着一个令牌!SD Model仅限于在提示中使用 75 个tokens。
- Embedding: SD v1 使用 Open AI 的ViT-L/14 Clip 模型。Embedding一个 768 值向量。每个标记都有自己独特的嵌入向量。嵌入由 CLIP 模型固定,CLIP是在训练过程中学习的。Embedding可以把Token嵌入到向量空间,更好表达每个Token之间的关系。
- Feeding embeddings to noise predictor(Text Transformer): 在输入噪声预测器之前,Embedding需要由Text Transformer进一步处理。Text Transformer就像一个用于调节的通用适配器。在这种情况下,它的输入是文本嵌入向量,但它也可以是其他东西,例如类标签、图像和Depth-to-image。转换器不仅进一步处理数据,而且还提供了一种包含不同调节模式的机制。
- Cross-attention(Noise Predictor):
- 整个 U-Net 中的噪声预测器****多次使用文本转换器的输出。U-Net 通过交叉注意力机制来消耗它。这就是提示与图像相遇的地方。
- Hypernetwork是一种微调稳定扩散模型的技术,它劫持交叉注意力网络来插入样式。LoRA模型修改交叉注意力模块的权重来改变风格。单独修改这个模块就可以微调 Stabe Diffusion 模型,这一事实告诉您这个模块有多么重要。
Other Conditionings:
- 文本提示并不是调节稳定扩散模型的唯一方法。 text conditioning和depth-to-image都用于conditioning模型。
- ControlNet使用检测到的轮廓、人体姿势等来调节噪声预测器,并实现对图像生成的出色控制。
Stable Diffusion Working Pipeline(txt2img)
- 稳定扩散在潜在空间中生成随机张量。您可以通过设置随机数生成器的种子来控制该张量。如果将种子设置为某个值,您将始终获得相同的随机张量。这是你在潜在空间中的影像。但目前这都是噪音。
- 第2步。噪声预测器 U-Net 将潜在噪声图像和文本提示作为输入,并在潜在空间(4x64x64 张量)中预测噪声。
- 步骤3。从潜在图像中减去潜在噪声。这成为你新的潜像。(重复步骤2和3一定数量的采样步骤,例如20次。)
- 步骤4。最后,VAE 的解码器将潜像转换回像素空间。这是运行稳定扩散后获得的图像。
Noise Schedule
- 图像从嘈杂变为干净。您是否想知道噪声预测器在最初的步骤中是否工作得不好?事实上,这只是部分正确。真正的原因是我们试图在每个采样步骤中获得预期的噪声。这称为噪声表。下面是一个例子。
- 噪声表是我们定义的。我们可以选择在每一步减去相同数量的噪声。或者我们可以在开始时减去更多,就像上面一样。采样器在每一步中减去足够的噪声,以达到下一步中的预期噪声。这就是您在分步图像中看到的内容。
Stable Diffusion Working Pipeline(img2img)
- 输入图像被编码到潜在空间。
- 噪声被添加到潜像中。**去噪强度**控制添加的噪声量。如果为0,则不添加噪声。如果为1,则添加最大量的噪声,使潜像成为完全随机的张量。
- 噪声预测器 U-Net 将潜在噪声图像和文本提示作为输入,并预测潜在空间(4x64x64 张量)中的噪声。
- 从潜在图像中减去潜在噪声。这成为你新的潜像。(重复步骤3和4一定数量的采样步骤,例如20次。)
- 最后,VAE 的解码器将潜像转换回像素空间。这是运行 image-to-image 后得到的图像。
图像到图像所做的就是设置带有一点噪声的初始潜在图像和输入图像。将去噪强度设置为 1 相当于文本到图像,因为初始潜在图像是完全随机的。
Inpainting
Inpainting实际上只是图像到图像的一种特殊情况。噪点会添加到您想要修复的图像部分。噪声量同样由降噪强度控制。
Depth-to-image
深度到图像是图像到图像的增强;它使用深度图生成带有附加条件的新图像。步骤如下:
- 输入图像被编码为潜在状态
- MiDaS(一种 AI 深度模型)根据输入图像估计深度图。
- 噪声被添加到潜像中。去噪强度控制添加的噪声量。如果去噪强度为0,则不添加噪声。如果去噪强度为1,则添加最大噪声,使得潜像变成随机张量。
- 噪声预测器估计潜在空间的噪声,以文本提示和深度图为条件。
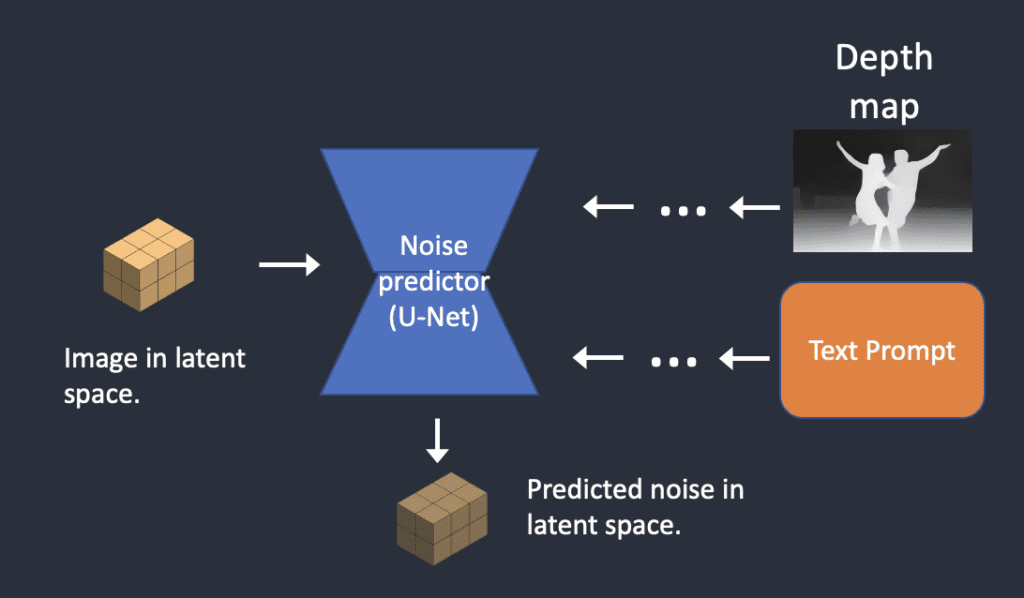
- 从潜在图像中减去潜在噪声。这成为你新的潜像。(重复步骤 4 和 5 的采样步骤数。)
- VAE的解码器对潜像进行解码。现在,您可以获得从深度到图像的最终图像。
CFG value
- Classifier guidance:
- 分类器引导是一种将图像标签合并到扩散模型中的方法。您可以使用标签来指导扩散过程。例如,标签“猫”引导反向扩散过程来生成猫的照片。分类器指导尺度是控制扩散过程遵循标签的程度的参数。
- 在高分类器指导下,扩散模型生成的图像将偏向极端或明确的示例。如果你向模型询问一只猫,它会返回一张明确是猫的图像,除此之外别无其他。
- Classifier-free guidance
- Classifier-free guidance scale: 无分类器引导尺度(CFG 尺度)是控制文本提示引导扩散过程的程度的值。当 CFG 比例设置为 0 时, AI 图像生成是无条件的(即忽略提示)。较高的 CFG 比例会引导扩散朝向提示。
SD v1.5 vs v2
…想看去原文看哈,这里简单概括下重要的
- 用户通常发现使用 Stable Diffusion v2 来控制风格和生成名人更困难。尽管 Stability AI 没有明确过滤掉艺术家和名人的名字,但它们的效果在 v2 中要弱得多。这可能是由于训练数据的差异造成的。Open AI 的专有数据可能有更多艺术品和名人照片。他们的数据可能经过高度过滤,因此一切和每个人看起来都很好。v2 和 v2.1 模型并不流行。人们只使用经过微调的 v1.5 和 SDXL 模型。
- SDXL型号是v1和v2型号的官方升级版。该模型作为开源软件发布。 这是一个更大的模型,SDXL模型的参数总数为66亿,而v1.5模型的参数总数为9.8亿。
Important Parameters in image gen
CFG Scale
- CFG Value是一个参数,用于控制模型应尊重您的提示的程度。
1 – 大多忽略您的提示。
3 – 更有创意。
7 – 遵循提示和自由之间的良好平衡。
15 – 坚持更多提示。
30 – 严格按照提示操作。
- 下面是使用相同随机种子增加 CFG 规模的几个示例。一般来说,您应该远离两个极端——1 和 30。
- 建议:从 7 开始。如果您希望它更多地遵循您的提示,请增加。
Sampling steps
- 质量随着采样步骤的增加而提高。通常,使用Euler采样器进行 20 个步骤 就足以获得高质量、清晰的图像。虽然当迈向更高的值时,图像会发生微妙的变化,但它会变得不同,但不一定具有更高的质量。
- 建议:20-30 步。如果您怀疑质量较低,请调整至较高值。
Sampling methods
- 您可以选择多种采样方法,具体取决于您使用的 GUI。它们只是求解扩散方程的不同方法。它们应该给出相同的结果,但由于数值偏差可能略有不同。但由于这里没有正确的答案——唯一的标准是图像看起来不错,因此该方法的准确性不应该是您关心的问题。
- 在线社区中有一些讨论声称某些采样方法往往会产生特定的风格。这是没有理论价值的。
Seed
- 随机种子决定了初始噪声模式,从而决定了最终图像。将其设置为 -1 意味着每次都使用随机的一个。当您想要生成新图像时它很有用。另一方面,固定Seed,将会在每一代中产生相同的图像。
- 如果使用随机种子,如何找到用于图像的种子?在对话框中,您应该看到类似以下内容:
步骤:20,采样器:Euler a,CFG规模:7, 种子:4239744034,大小:512×512,模型哈希:7460a6fa
- 将此种子值复制到种子输入框中。如果一次生成多张图像,则第二张图像的种子值会增加 1,依此类推。或者,单击回收按钮以重复使用上一代的种子。建议:Set to -1 to explore. Fix to a value for fine-tuning.
Image size
- 输出图像的大小。由于稳定扩散 v1 是使用 512×512 图像进行训练的,因此偏离太多可能会导致诸如重复对象之类的问题。尽可能将其保留为正方形。512×768(纵向)或768×512(横向)仍然可以。
- 建议:将图像尺寸设置为512×512。否则为 512×768 或 768×512。(适用于 v1 型号)
Batch size
- 批量大小是每次生成的图像数量。由于最终图像非常依赖于随机种子,因此一次生成一些图像始终是一个好主意。这样,您就可以很好地了解当前提示可以执行的操作。
- 建议:将批量大小设置为 4 或 8。
More
How to use ComfyUI
ComfyUI is a node-based GUI for Stable Diffusion. Beginner’s Guide to ComfyUI
Components in ComfyUI
- ComfyUI 是一个基于节点的Stable Diffusion GUI。您可以通过将不同的块(称为节点)链接在一起来构建图像生成工作流程。
- 一些常用的块包括加载检查点模型、输入提示、指定采样器等。ComfyUI 将工作流程分解为可重新排列的元素,以便您可以轻松创建自己的元素。您需要一个可用的 ComfyUI 才能遵循本指南。本地安装请参见安装指南。
- ComfyUI 的好与坏:
- 好处
- 轻量级:运行速度快。
- 灵活:非常可配置。
- 透明:数据流就在你的面前。
- 易于共享:每个文件都是一个可重复的工作流程。
- 适合原型设计:使用图形界面而不是编码进行原型设计。
- 坏处
- 界面不一致:每个工作流程可能会以不同的方式放置节点。你需要弄清楚要改变什么。
- 太多细节:普通用户不需要知道底层是如何连接的。(这难道不是使用 GUI 的全部意义吗?)
- 好处
具体的Demo可以看上的链接哈,这里就不详细展开了。
Workflow is made with two basic building blocks: Nodes and edges.
Nodes are the rectangular blocks, e.g., Load Checkpoint, Clip Text Encoder, etc. Each node executes some code. If you have some programming experience, you can think of them as functions. Each node needs three things
Inputs are the texts and dots on the left that the wires come in.
Outputs are the texts and dots on the right the wires go out.
Parameters are the fields at the center of the block.
Edges are the wires connecting the outputs and the inputs between nodes.
Stable Diffusion由三个主要部分组成:
- 模型:潜在空间中的噪声预测模型。
- CLIP:语言模型对正面和负面提示进行预处理。
- VAE:变分自动编码器在像素和潜在空间之间转换图像。
MODEL 输出连接到采样器,在采样器中完成反向扩散过程。
CLIP 输出连接到提示,因为提示需要经过 CLIP 模型处理才能有用。CLIP文本编码节点获取提示并将其输入 CLIP 语言模型。CLIP 是 OpenAI 的语言模型,将提示中的每个单词转换为Embedding。
在txt2img中,VAE仅用于最后一步:将图像从潜在空间转换到像素空间。换句话说,我们只使用自动编码器的解码器部分。
- Empty latent image: 文本到图像的过程从潜在空间中的随机图像开始。潜像的大小与像素空间中的实际图像成正比。因此,如果您想更改图像的大小,请更改潜在图像的大小。
- 您可以设置高度和权重来更改像素空间中的图像大小。
- 您还可以设置批量大小,即每次运行生成的图像数量。
- KSampler: KSampler 是稳定扩散图像生成的核心。采样器将随机图像去噪为与您的提示相匹配的图像。KSampler 指的是在此代码存储库中实现的采样器。
ComfyUI Manager
- Install:
1 | |
- Usage
- 安装/卸载custom nodes。
- 安装当前工作流程中缺少的节点。
- 安装checkpoint models, AI upscalers, VAEs, LoRA, ControlNet models, etc.
- 更新 ComfyUI UI
- 阅读社区手册。
The Install Missing Nodes function is especially useful for finding what custom nodes that are required in the current workflow.
The Install Custom Nodes menu lets you manage custom nodes. You can uninstall or disable an installed node or install a new one.
- 如何更新ComfyUI或者是某个custom node?
- 通过ComfyUI Manger的UI来更新
- 切到对应的目录,然后git pull
Upscaling
There are several ways to upscale in Stable Diffusion. For teaching purposes, let’s go through upscaling with: AI upscaler, Hi-res fix, Ultimate Upscale
AI upscale: AI upscaler是一种用于放大图像(Pixel)并填充细节的 AI 模型。它们不是Stable Diffusion Model,而是经过训练以放大图像的神经网络。Example
Upscaler Model Wiki, The Best Place To Find AI Upscaling Models
Hi-res fix: Example, 第一部分与文本到图像相同:您使用采样器对潜在图像进行去噪,并以正面和负面提示为条件。 然后,工作流程会放大潜在空间中的图像并执行一些额外的采样步骤。它给图像添加一些初始噪声,并以一定的去噪强度对其进行去噪。 然后,VAE 解码器对较大的潜在图像进行解码以生成放大的图像。
SD Ultimate upscale, Github Page of SD Ultimate upscale for ComfyUI
This is a good exercise for installing a custom node.
A good exercise is to start with the AI upscaler workflow. Add SD Ultimate Upscale and compare the result. Right-click on an empty space. Select Add Node > image > upscaling > Ultimate SD Upscale.
Parameters
image to VAE Decode’s IMAGE.
model to Load Checkpoint’s MODEL.
positive to CONDITIONING of the positive prompt box.
negative to CONDITIONING of the negative prompt box.
vae to Load Checkpoint’s VAE.
upscale_model to Load Upscale Model’s UPSCALE_MODEL.
Others
ComfyUI Inpainting: You can use ComfyUI for inpainting. It is a basic technique to regenerate a part of the image.
ComfyUI Impact Pack: ComfyUI Impact pack is a pack of free custom nodes that greatly enhance what ComfyUI can do. There are more custom nodes in the Impact Pact. See the official tutorials to learn them one by one. Read through the beginner tutorials if you want to use this set of nodes effectively.
Regenerate faces with Face Detailer (SDXL)
You can use this workflow in the Impact Pack to regenerate faces with the Face Detailer custom node and SDXL base and refiner models. Download and drop the JSON file into ComfyUI.
To use this workflow, you will need to set
- The initial image in the Load Image node.
- An SDXL base model in the upper Load Checkpoint node.
- An SDXL refiner model in the lower Load Checkpoint node.
- The prompt and negative prompt for the new images.
使用 Face Detailer (SDXL) 重新生成面部
使用 Face Detailer (SD v1.5) 重新生成面部
Embeddings: 要在 ComfyUI 中使用Embeddings(也称为文本反转
embedding:),请在肯定或否定提示框中键入。ComfyUI 将搜索文件夹ComfyUI > models > embeddings中具有相同文件名的Embeddings。Embedding with autocomplete: 查找文件名需要做很多工作。相反,您可以通过安装ComfyUI-Custom-Scripts自定义节点来启用嵌入名称的自动完成功能。 您可以使用 ComfyUI 管理器安装它。单击管理器 > 安装自定义节点。搜索“ComfyUI-Custom-Scripts”并安装它。重新启动 ComfyUI。 embedding:输入提示后,应该会出现可用嵌入的列表。选择您要使用的一个。
Lora: LoRA是一个修改检查点模型的小模型文件。它经常用于修改样式或将人物注入模型中。 LoRA模型改变了检查点模型的MODEL和CLIP,但保持VAE不变。下载简单的 LoRA 工作流程
- 选择检查点模型。
- 选择 LoRA。
- 修改提示和否定提示。
- 单击队列提示。
多个 LoRA: 您可以在同一文本到图像工作流程中使用两个 LoRA。 下载两个 LoRA 工作流程,用法与一个 LoRA 类似,但现在您必须选择两个,两个LoRA相继应用(one after the other)。
Joining two strings:
- To join two strings, you will use a node called String Function from the ComfyUI-Custom-Scripts custom node.
- You should have installed this custom node to enable autocomplete of the textual inversion. Install it in the ComfyUI Manager if not.
Stable Diffusion Workflow
A stunning Stable Diffusion artwork is not created by a simple prompt. The workflow is a multiple-step process. In this post, I will go through the workflow step-by-step. Stable Diffusion Workflow