prompt = f""" Provide the data in JSON format with the following keys: book_id, title, author, genre. """
检查是否满足某些条件,满足才执行任务
1 2 3 4 5 6 7 8 9 10 11 12 13
prompt=f""" You will be provided with text delimited by triple quotes.If it contains a sequence of instructions, re-write those instructions in the following format:
Step1 - ... step2 - ... ... step N - ...
If the text does not contain a sequence of instructions , then simply write "No steps provided. " \"\"\" (text_ 1)\"\"\" """
只有含有固定的条件,才会执行对应的处理和输出。
少量训练提示
要求模型执行任务之前,提示成功执行任务的示例。
1 2 3 4 5 6 7 8 9 10 11 12
prompt = f""" Your task is to answer in a consistent style .
<child>: Teach me about patience.
<grandparent>: The river that carves the deepest \ valley flows from a modest spring; the \ grandest symphony originates from a single note; \ the most intricate tapestry begins with a solitary thread.
<child>: Teach me about resilience. """
Principle 2
Principle 2: Give model time to think. 上下文逻辑链要足够GPT模型去学习和思考。
# example 1 prompt_1 = f""" Perform the following actions: 1 - Summarize the following text delimited by triple \ backticks with 1 sentence . 2 - Translate the summary into French. 3 - List each name in the French summary . 4 - Output a json object that contains the following \ keys: french summary, num_names.
Separate your answers with line breaks.
Text: ```{text}``` """
# example 2, asking for output in a specified format prompt_2 = f""" Your task is to perform the following actions : 1 - Summarize the following text delimited by <> with 1 sentence . 2 - Translate the surmary into French. 3 - List each name in the French summary. 4 - Output a json object that contains the following keys: french summary, num names.
Use the following format: Text: <text to summarize> Summary: <summary> Translation: <summary translation> Names: <list of names in Italian sumumary> Output JSON: <json with summary and num names>
prompt=""" Your task is determine if the student's solution is correct or not . To solve the problem do the following: - First, work out your own solution to the problem. - Then compare your solution to the student's solution and evaluate if the student's solution is correct or not.Don't decide if the student's solution is correct unti1 you have done the problem yourself.
Use the following format: Question: ``` question here ``` Student's solution: ``` student' s solution here ``` Actual solution: ``` steps to work out the solution and your solution here ``` Is the student's solution the same as actual solution just calculated : ``` yes or no ``` Student grade : ``` correct or incorrect ```
Question: ``` I'm building a solar power installation and I need help working out the financials. - Land costs $100 / square foot - I can buy solar panels for $250 / square foot - I negotiated a contract for maintenance that will cost me a flat $l00k per year, and an additional $10 \ square foot What is the total cost for the first year of operations as a function of the number of square feet. ``` Student's solution: ``` Let x be the size of the installation in square feet. Costs: 1. Land cost: 100x 2. Solar panel cost: 250x 3. Maintenance cost: 100,000 + 100x Total cost: 100x + 250x + 100,000 + 100x = 450x + 100, 000 ``` Actual solution: """
Model Limitations
模型没有记住它所看到的所有信息,不了解知识边界。这意味着它可能会尝试回答关于晦涩主题的问题,并编造听起来合理但是不正确的答案。(幻觉) -> Hallucination: Make statements that sound plausible but are not true.
Analyze where the result does not give what you want
Clarify instructions, give more time to think
Refine prompts with a batch of examples
Text Summarization
一份简单的Summary
1 2 3 4 5 6 7 8 9
prompt = f""" Your task is to generate a short summary of a product review from an ecommerce site .
Summarize the review below, delimited by triple backticks, in at most 30 words.
Review: ```{prod_ review}``` """
针对某个部分的Summary
1 2 3 4 5 6 7 8 9
prompt = f""" Your task is to generate a short summary of a product review from an ecommerce site .
Summarize the review below, delimited by triple backticks, in at most 30 words, and focusing on any aspects that mention shipping and delivery of the product.
大模型all in one,只需要一个大模型,就可以解决所有的问题。只需要编写正确的提示词,就能够实现对应的功能。Fast!!!
判断句子的情绪:
1 2 3 4 5 6 7 8
prompt = """ What is the sentiment of the following product review, which is delimited with triple backticks?
Give your answer as a single word, either "positive" or "negative".
Review text: """(review)""" """
提取情绪关键词:
1 2 3 4 5 6 7 8
prompt = f""" Identify a list of emotions that the writer of the \ following review is expressing. Include no more than \ five items in the list.Format your answer as a list of \ lower-case words separated by commas.
Review text: '''{review}''' """
判断用户是否愤怒:
1 2 3 4 5 6 7 8
prompt = """ Is the writer of the following review expressing anger? The review is delimited with triple backticks.
Give your answer as either yes or no.
Review text: """(review)""" """
提取文本中的重要内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
prompt = f""" Identify the following items from the review text: - Item purchased by reviewer - Company that made the item
The review is delimited with triple backticks. \ Format your response as a JSON object with \ "Item" and "Brand" as the keys. If the information isn't present, use "unknown" \ as the value. Make your response as short as possible.
Review text: '''{lamp_ review}''' """
感觉就类似,输入,处理,输出的思想。指定输入是啥,处理逻辑是啥,然后输出要表达成怎样的格式。
All in one:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
prompt = f""" Identify the following items from the review text: - Sentiment (positive or negative) - Is the reviewer expressing anger? (true or false) - Item purchased by reviewer - Company that made the item
The review is delimited with triple backticks. \ Format your response as a JSON object with \ "Sentiment", "Anger", "Item" and "Brand" as the keys. If the information isn't present, use "unknown" \ as the value.
Make your response as short as possible . Format the Anger value as a boolean . Review text: '''{review}''' """
提取文章主题
1 2 3 4 5 6 7 8 9
prompt = f""" Determine five topics that are being discussed in the following text, which is delimited by triple backticks.
Make each item one or two words long.
Format your response as a list of items separated by commas.
Text sample: '''{story}''' """
验证某篇文章,是否拥有哪些主题
1 2 3 4 5 6 7 8
prompt = f""" Determine whether each item in the following list of topics is a topic in the text below, which is delimited with triple backticks.
Give your answer as list with 0 or 1 for each topic.
List of topics: {", ".join(topic_list)} Text sample: '''{story}''' """
Zero-shot Learning
Transforming
Translation
1 2 3 4 5 6 7 8 9 10 11 12 13 14
prompt_1 = f""" Trans1ate the following English text to Spanish: \ ```Hi, I would like to order a blender``` """
prompt_2 = f""" Tell me which language this is: \ ```Hi, I would like to order a blender``` """
prompt_3 = f""" Trans1ate the following English text to Spanish and Chinese: \ ```Hi, I would like to order a blender``` """
面向不同受众
1 2 3 4 5
prompt = f""" Trans1ate the following English text to Spanish in both the \ formal and informal forms: ```Hi, I would like to order a blender``` """
Universal Translator
1 2 3 4 5 6 7 8 9 10
for issue in user_ messages: prompt = f"Tell me what language this is: ```{issue}``` lang.get_completion(prompt) print(f"Original message ({lang}): {issue}") prompt = f""" Translate the following text to English 1 and Korean: ```{issue}``` """ response = get_completion(prompt) print(response, "\n")
tone translation
1 2 3 4
prompt = f""" Translate the following from slang to a business letter: 'Dude, This is Joe, check out this' """
Translation between formats
1 2 3 4
prompt = f""" Translate the following Python dictionary from JSON to HTML table with column headers and title: {data_json} """
Spell checking & Grammer checking
1 2 3 4 5 6 7
text = [ "I working hardly", "I wake up late" ]
for t in text: prompt = f"Proofread and correct: ```{t}```"
1 2 3 4 5
prompt = f"""Proofread and correct the following text and rewrite the corrected version. If you don't find any errors, just say "No errors found": ```{t}``` """
Find difference between the old and the new one:
1 2 3
from readlines import Redlines diff = Redlines(text, response) display(Markdown(diff.output_markdown))
Advanced output
1 2 3 4 5 6
prompt = f""" proofread and correct this review. Make it more compelling. Ensure it follows APA style guide and targets an advanced reader. Output in markdown format. Text: ```{text}``` """
Expanding
根据用户情感,对于用户评论做出回复:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
prompt = """ You are a customer service AI assistant. Your task is to send an emai1 and reply to a valued customer . Given the customer email delimited by ```, \ Generate a reply to thank the customer for their review . If the sentiment is positive or neutral, thank them for \ their review. If the sentiment is negative, apologize and suggest that \ they can reach out to customer service . Make sure to use specific details from the review, Write in a concise and professional tone. Sign the email as `AI customer agent`. Customer review: ```{review}``` """
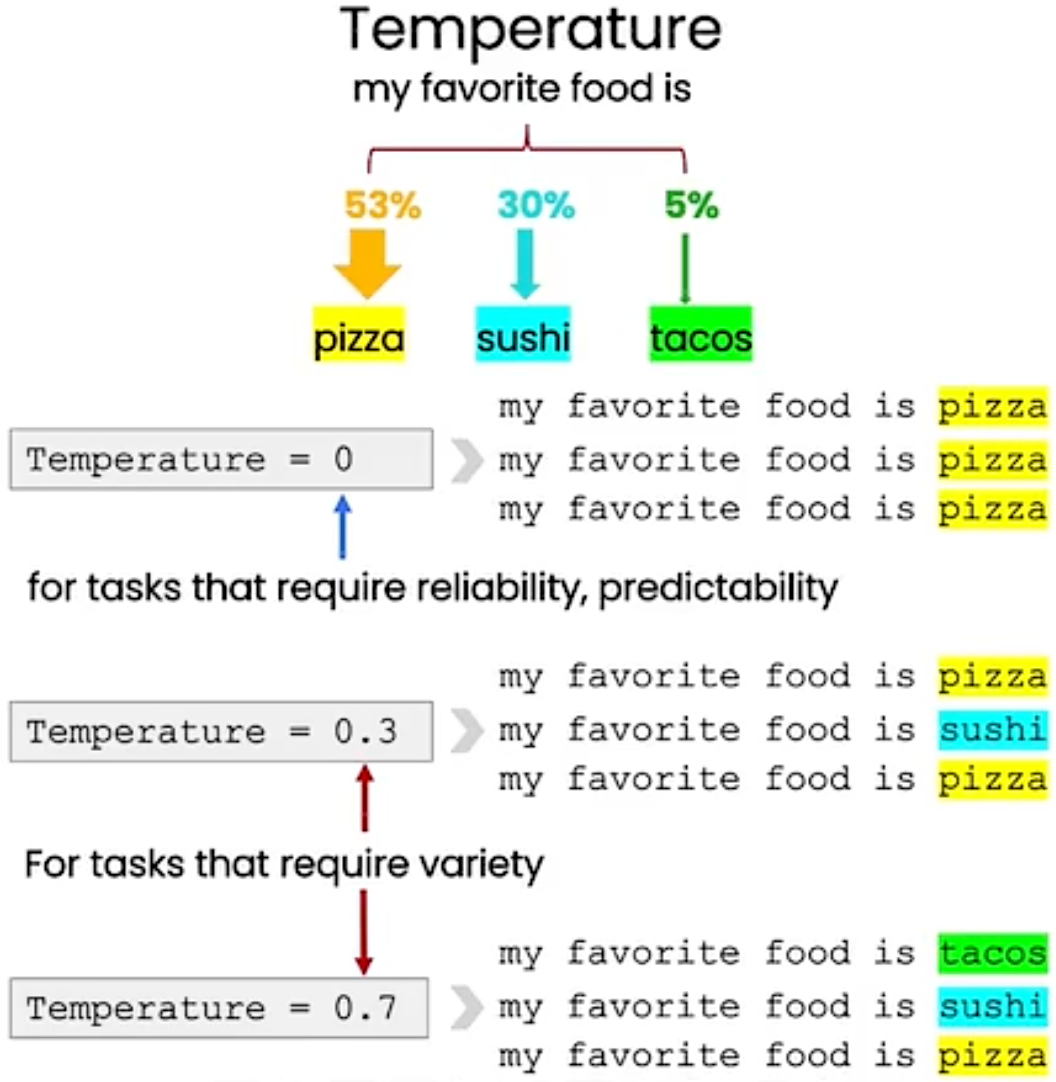
Temparature: an parameter in ChatGPT which we can pass through the APIs.
允许我们改变模型响应的多样性,可以将温度看作模型的搜索程度或者随机性。
For tasks require reliability, predictability, Temperature = 0.
For tasks require variety, Temperature can be higher.
ChatBot
角色扮演
1 2 3 4
messages = [ {'role':'system', 'content': 'You are a friendly chatbot.'}, {'role':"user", 'content': "Yes can you remind me, what is my name?"} ]
context = [ {'role': "system', 'content' :""" You are OrderBot, an automated service to collect orders for a pizza restaurant.You first greet the customer, then collects the order, and then asks if it's a pickup or delivery. You wait to collect the entire order, then summarize it and check for a final time if the customer wants to add anything else. If it's a delivery, you ask for an address. Finaily you collect the payment. Make sure to clarify all options, extras and sizes to uniquely identify the item from the menu. You respond in a short, very conversational friendly style. The menu includes: pepperoni pizza 12.95, 10.00, 7.00 cheese pizza 10.95, 9.25, 6.501 eggplant pizza 11.95, 9.75, 6.75 fries 4.50, 3.501 greek salad 7.25 Toppings: extra cheese 2.00, mushrooms 1.50, sausage 3.00, canadian bacon 3.50, AI sauce 1.50, peppers 1.00, Drinks: coke 3.00, 2.00, 1.00 sprite 3.00, 2.00, 1.00 bottled water 5.00 """}] # accumulate messages
customer_review = """ This leaf blower is pretty amazing. It has four settings: candle blower, gentle breeze, windy city, and tornado. It arrived in two days, just in time for my wife's anniversary present. I think my wife liked it so much she was speechless. So far I've been the only one using it, and I've been using it every other morning to clear the leaves on our 1awn. It's slightly more expensive than the other leaf blowers out there, but I think it's worth it for the extra features. """
review_template = """ For the following text, extract the following information:
gift: Was the item purchased as a gift for someone else? delivery_days: How many days did it take for the product to deliver? price_value: Extract any sentences about the value or price.
Format the output as JSON with the following keys: gift delivery days price value
text: {text} """
Use Parser:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
from langchain.prompts import ChatPromptTemplate from langchain.output_parsers import ResponseSchema from langchain.output_parsers import StructuredOutputParser
prompt_template = ChatPromptTemplate.from_template(review_template) messages = prompt_template.format_messages(text=customer_review) response = chat(messages) type(response) # string print(response.content) # a json like str
# Parser help us analyse the response gift_schema = ResponseSchema(name="gift", "Was the item purchased as a gift for someone else? Answer True if yes, False if not or unknown") delivery_days_schema = ResponseSchema(name="delivery_days", "How many days did it take for the product to deliver? If this information is not found, output -1") price_value_schema = ResponseSchema(name="price_value", "Extract any sentences about the value or price, and output them as a comma separated Python list.")
review_template_2 = """ For the following text, extract the following information:
gift: Was the item purchased as a gift for someone else? delivery_days: How many days did it take for the product to deliver? price_value: Extract any sentences about the value or price.
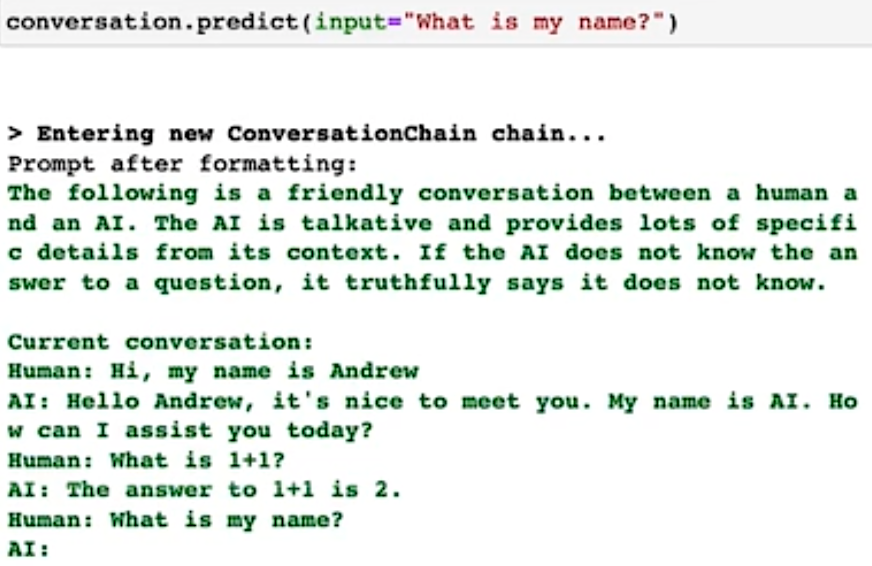
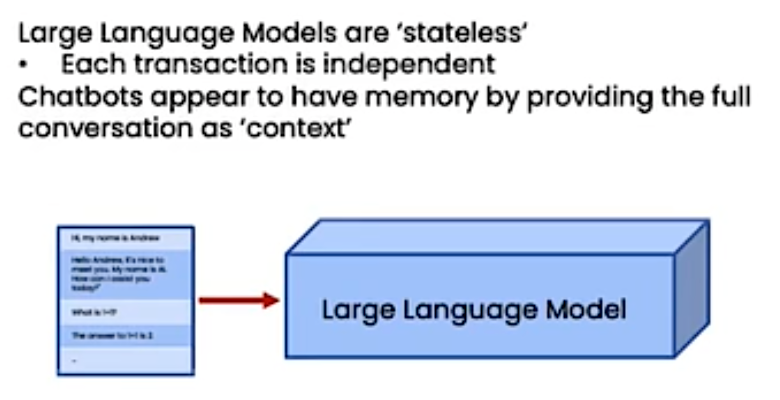
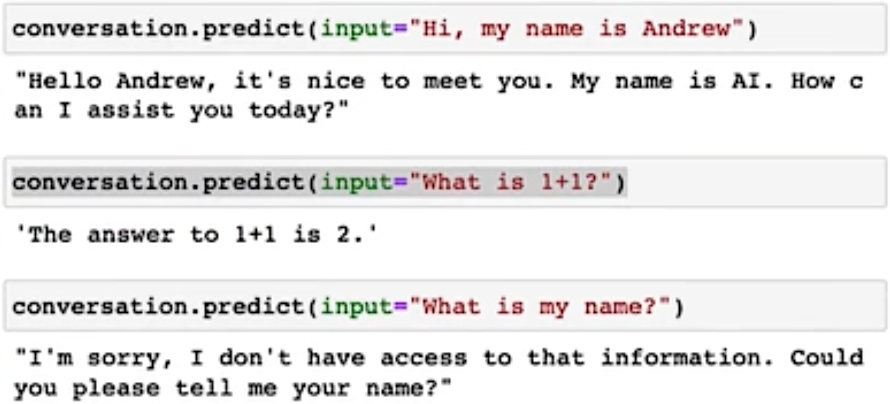
LangChain provides several kinds of ‘memory’ to store and accumulate the conversation, memory如果特别长,开销很大,因为模型是根据memory的context里面的token数量来计费的捏!所以太长了不好,LangChain会帮助你做优化捏!!!
ConversationBufferwindowMemory
1 2
from langchain.memory import ConversationBufferwindowMemory memory = ConversationBufferwindowMemory(k=1)
ConversationBufferwindowMemory, k=1 means just keeping one conversation(the newest). By adjusting k, you can just track the recent few conversations.
ConversationBufferMemory: This memory allows for storing of messages and then extracts the messages in a variable.
ConversationBufferWindowMemory: This memory keeps a list of the interactions of the conversation over time.It only uses the last K interactions.
ConversationTokenBufferMemory: This memory keeps a buffer of recent interactions in memory,and uses token length rather than number of interactions to determine when to flush interactions.
ConversationSummaryMemory: This memory creates a summary of the conversation over time.
Vector data memory: Stores text(from conversation or elsewhere)in a vector database and retrieves the most relevant blocks of text.
Entity memories: Using an LLM,it remembers details about specific entities.
You can also use multiple memories at one time. E.g.,Conversation memory Entity memory to recall individuals.
You can also store the conversation in a conventional database (such as key-value store or SQL)
Chains
类似于拼积木的感觉
1 2 3 4 5 6 7 8 9 10 11 12 13
from langchain.chat models import ChatopenAI from langchain.prompts import ChatpromptTemplate from langchain.chains import LLMChain
llm = ChatOpenAI(temperature=0.9) prompt = ChatpromptTemplate.from_template( "What is the best name to describe a company that makes the {product}?" )
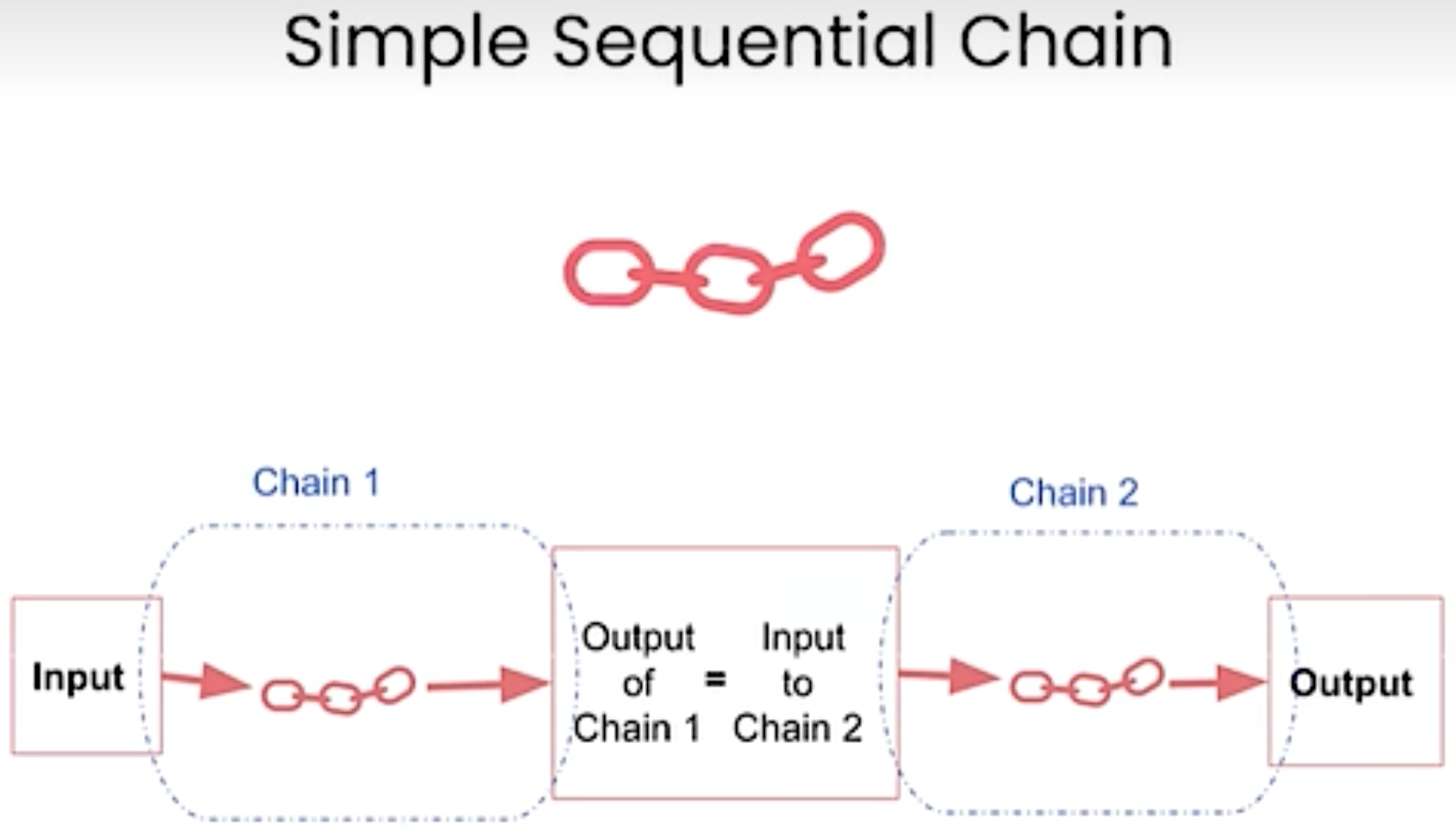
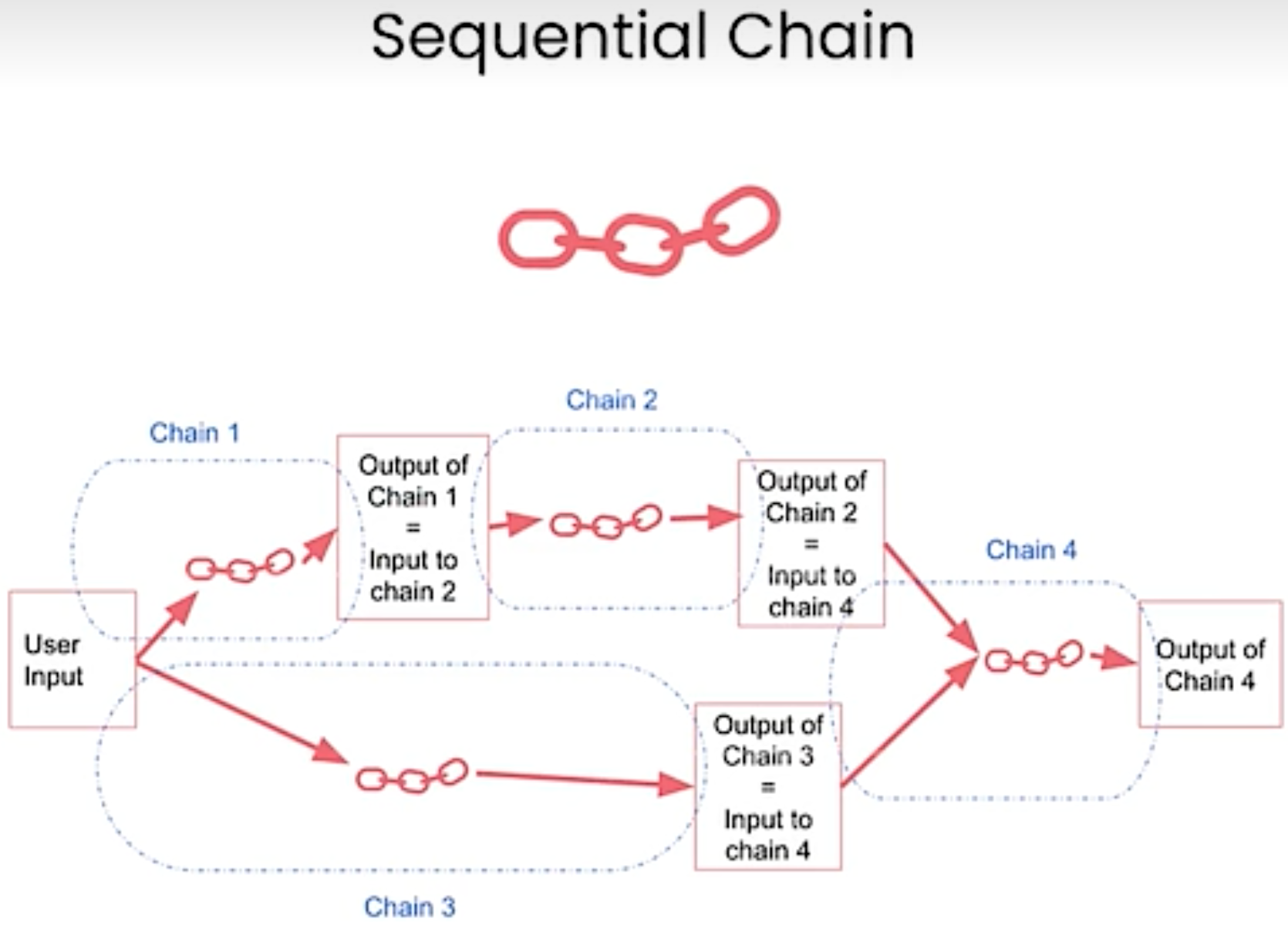
Sequential Chains. Sequential chain is another type of chains. The idea is to combine multiple chains where the output of the one chain is the input of the next chain.
There is two type of sequential chains:
SimpleSequentialChain:Single input/output
SequentialChain:multiple inputs/outputs
SimpleSequentialChain
1 2 3 4 5 6 7 8 9 10 11 12 13 14
from langchain.prompts import SimpleSequentialChain
first_prompt = ChatpromptTemplate.from_template( "What is the best name to describe a company that makes the {product}?" ) chain_one = LLMChain(llm=llm, prompt=first_prompt)
second_prompt = ChatpromptTemplate.from_template( "Write a 20 words description for the following company: {company_name}" ) chain_two = LLMChain(llm=llm, prompt=second_prompt)
first_prompt = ChatpromptTemplate.from_template( "What is the best name to describe a company that makes the {product}?" ) chain_one = LLMChain(llm=llm, prompt=first_prompt, output_key = "key_one")
prompt_two = "Tell me anything about {key_one}" chain_two = LLMChain(llm=llm, prompt=first_prompt, output_key = "key_two")
prompt_three = "Tell me the differnce between {key_one} and {key_two}" chain_three = LLMChain(llm=llm, prompt=first_prompt, output_key = "key_three")
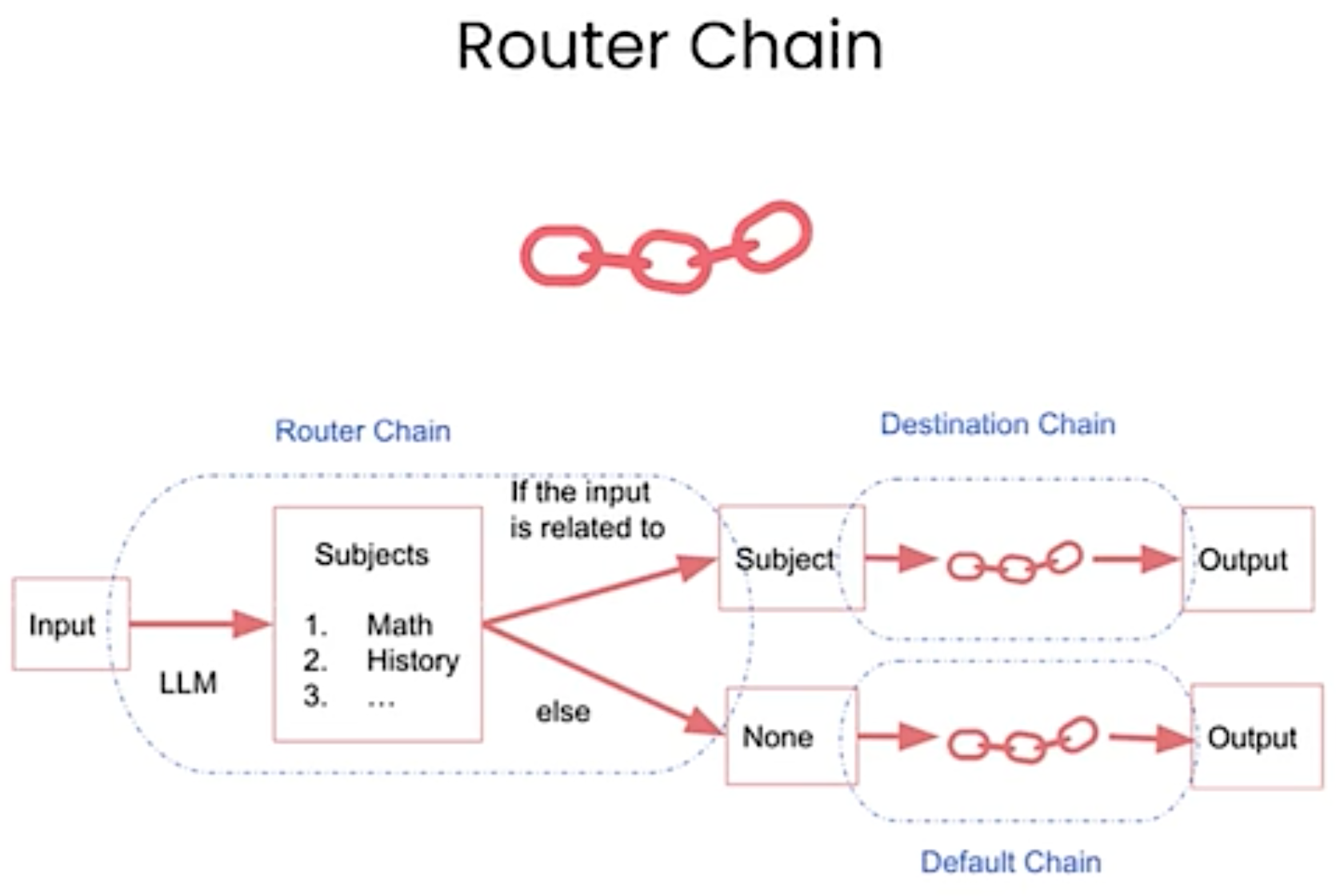
physics_template = """You are a very smart physics professor. \ You are great at answering questions about physics in a concise and easy to understand manner. \ When you don't know the answer to a question you admit that you don't know.
Here is a question: {input}""" physics_prompt = PromptTemplate.from_template(physics_template)
math_template = """You are a very good mathematician. You are great at answering math questions. \ You are so good because you are able to break down hard problems into their component parts, \ answer the component parts, and then put them together to answer the broader question.
Here is a question: {input}""" math_prompt = PromptTemplate.from_template(math_template)
prompt_infos = [ { "name": "physics", "description": "Good for answering questions about physics", "prompt_template": physics_template, }, { "name": "math", "description": "Good for answering math questions", "prompt_template": math_template, }, ]
from langchain.chains.router import MultiPromptChain from langchain.prompts import PromptTemplate from langchain.chains.router.llm_router import LLMRouterChain, RouterOutputParser from langchain.chains.router.multi_prompt_prompt import MULTI_PROMPT_ROUTER_TEMPLATE
llm = ChatOpenAI(temperature = 0)
destination_chains = {} for p_info in prompt_infos: name = p_info["name"] prompt_template = p_info["prompt_template"] prompt = PromptTemplate(template=prompt_template, input_variables=["input"]) chain = LLMChain(llm=llm, prompt=prompt) destination_chains[name] = chain default_chain = ConversationChain(llm=llm, output_key="text")
from langchain.chains import RetrievalQA from langchain.chat models import ChatopenAI from langchain.document loaders import CSVLoader from langchain.vectorstores import DocArrayInMemorySearch from IPython.display import display,Markdown
import os from dotenv import load_dotenv,find dot_env _ = load_dotenv(find_dotenv()) # read local .env file from langchain.chains import RetrievalQA from langchain.chat models import ChatopenAI from langchain.document_loaders import CSVLoader from langchain.vectorstores import DocArrayInMemorysearch from IPython.display import display,Markdown
from langchain.indexes import VectorstoreIndexCreator index = VectorstoreIndexCreator( vectorstore_cls=DocArrayInMemorySearch ).from_loaders([loader])
query ="Please list all your shirts with sun protection in a table in markdown and summarize each one." response = index.query(query) display(Markdown(response))
背后:LLM已经学习的知识和没有学习过的文档结合。但是LLM一次交互,有固定的Context限制(例如tokens),那么一个文档如果很大,上面这种效果是怎么实现的呢?(LLM can only inspect a few thousand words at a time.)
实现:Embeddings and Vector Storage,Embeddings可以讲文档抽象成向量,然后放入Vector Storage之后,本质上起到了“压缩”的作用,可以以更少或者更精炼的方式,和LLM进行交互。
交互方式评估:
Stuffing is the simplest method.You simply stuff all data into the prompt as context to pass to the language model.
Pros:It makes a single call to the LLM.The LLM has access to all the data at once.
Cons: LLMs have a context length, and for large documents or many documents this will not work as it will result in a prompt larger than the context length.
import os from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv())#read local .env file
from langchain.chains import RetrievalQA from langchain.chat models import ChatopenAI from langchain.document_loaders import CSVLoader from langchain.indexes import VectorstoreIndexCreator from langchain.vectorstores import DocArrayInMemorySearch
file 'Outdoorclothingcatalog_1000.csv' loader = CSVLoader(file_path=file) data = loader.1oad() index = VectorstoreIndexcreator( vectorstore_cls=DocArrayInMemorySearch ).from_loaders([loader])
for i, eg inenumerate(examples): print(f"Example (i):") print("Question:"predictions[i]['query']) print("Real Answer:"predictions[i]['answer'] print("Predicted Arlswer:"predictions[i]['result'] print("Predicted Grade:"graded_outputs[i]['text'] print()
Agents
LangChain的框架,可以帮你实现Agent
Math Example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
fros langchain.agents.agent toolkits import create_python_agent from langchain.agents import load_tools,initialize_agent from langchain.agents import AgentType from langehain.tools.python.tool import PythonREPLTool from langchain.python import PythonREPL from langchain.chat_models import ChatOpenAPI
customer_1ist=[["Harrison","Chase"], ["Lang","Chain"]] agent.run(f"""Sort these customers by last name and then first name and print the output:{customer_list}""")
Use Langchain debug to track,可以让你对于Agent底层的交互和执行流程有更深入的了解。
1 2 3 4 5 6
langchain.debug = True
agent.run(f"""Sort these customers by last name and then first name and print the output:{customer_list}""")
from langchain.agents import tool from datetime import date
@tool deftime(text:str)->str: """Returns todays date,use this for any questions related to knowing todays date.\ The input should always be an empty string, and this function will always return todays date any date mathmatics should occur outside this function.""" returnstr(date.today())