NJUOS-27-操作系统的实现
本文最后更新于:1 年前
复习:文件系统 API
目录 (索引)
- “图书馆” - mkdir, rmdir, link, unlink, open, …
文件 (虚拟磁盘)
- “图书” - read, write, mmap, …
文件描述符 (偏移量)
- “书签” - lseek
本次课回答的问题
- Q: 如何实现这些 API?
本次课主要内容
- FAT 和 ext2/UNIX 文件系统
本质就是,我们磁盘上是一个一个的block,我们需要在最底层的物理结构之上,一层一层堆叠数据结构的设计和逻辑,最终实现文件、目录等具体的逻辑结构捏!!!
回到数据结构课
什么是文件系统实现?
在一个 I/O 设备 (block device) 上实现所有文件系统 API
bread(int id, char *buf);bwrite(int id, const char *buf);1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
- 假设所有操作排队同步完成
- (可以在 block I/O 层用队列实现)
- 目录/文件 API
- `mkdir`, `rmdir`, `link`, `unlink`
- `open`, `read`, `write`, `stat`
## 回到数据结构课……
> 数据结构课中很多的假设,例如RAM之类的,和我们平常的使用场景可能是有很多不同的。
- 文件系统就是一个数据结构 (抽象数据类型;ADT)
- 只是和数据结构课上的假设稍有不同
- 数据结构课程的假设
- 冯诺依曼计算机
- Random Access Memory (RAM)
- Word Addressing (例如 32/64-bit load/store)
- 每条指令执行的代价是*O*(1)
- Memory Hierarchy 在苦苦支撑这个假设 (cache-unfriendly 代码也会引起性能问题)
- 文件系统的假设
- 按块 (例如 4KB) 访问,在磁盘上构建 RAM 模型完全不切实际
> 我们认为的数据结构,和我们底层的Block的结构,还有巨大的差距,File System可以帮助我们,在某些程度上,完成这个层面的抽象。
## 数据结构的实现
Block device 提供的设备抽象
```c
struct block blocks[NBLK]; // 磁盘
void bread(int id, struct block *buf) {
memcpy(buf, &blocks[id], sizeof(struct block));
}
void bwrite(int id, const struct block *buf) {
memcpy(&blocks[id], buf, sizeof(struct block));
}
在 bread/bwrite 上实现块的分配与回收 (与 pmm 类似)
1 | |
数据结构的实现 (cont’d)
在balloc/bfree上实现磁盘的虚拟化
文件 = vector<char>
- 用链表/索引/任何数据结构维护
- 支持任意位置修改和 resize 两种操作
在文件基础上实现目录
- “目录文件”
- 把
vector<char>解读成vector<dir_entry> - 连续的字节存储一个目录项 (directory entry)
- 把
- “目录文件”
File Allocation Table (FAT)
让时间回到 1980 年
5.25” 软盘:单面 180 KiB
- 360 个 512B 扇区 (sectors)
- 在这样的设备上实现文件系统,应该选用怎样的数据结构?

FAT 文件系统中的文件
1 | |
注意到这是相当小的文件系统(历史原因限制)
树状的目录结构
系统中以小文件为主 (几个 block 以内)
文件的实现方式
- struct block * 的链表
- 任何复杂的高级数据结构都显得浪费
- struct block * 的链表
用链表存储数据:两种设计
- 在每个数据块后放置指针
- 优点:实现简单、无须单独开辟存储空间
- 缺点:数据的大小不是$2^k$; 单纯的 lseek 需要读整块数据
- 将指针集中存放在文件系统的某个区域(例如前面)
- 优点:局部性好;lseek 更快
- 缺点:集中存放的数据损坏将导致数据丢失
哪种方式的缺陷是致命、难以解决的?
- 第一种感觉更加危险,链表中,但凡有一个节点出了问题,直接全部都寄了,后面的再也找不到了就。第二种方法虽然集中,但是更加稳定!!!而且没有缓存!!!找最后一个节点也太慢啦!!!
- 第二种也很危险,集中存放,鸡蛋放在一个篮子里面,可能直接一起寄了!而且最容易出问题的地方,也是读写最频繁的地方,也最容易寄!!!
集中保存所有指针
集中存储的指针容易损坏?存n份就行!
- FAT-12/16/32 (FAT entry,即 “next 指针” 的大小)
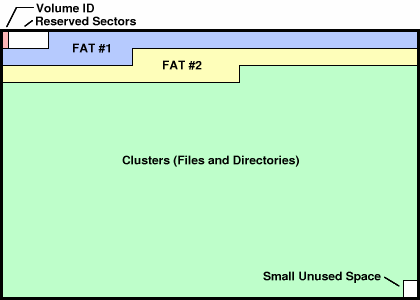
采用方法二!备份来指数提高可靠性!!!
“File Allocation Table” 文件系统

RTFM 得到必要的细节
诸如 tutorial、博客都不可靠
还会丢失很多重要的细节
1 | |
读手册很重要!!!!!!Not afraid,需要敢于探索&入门昂!!!
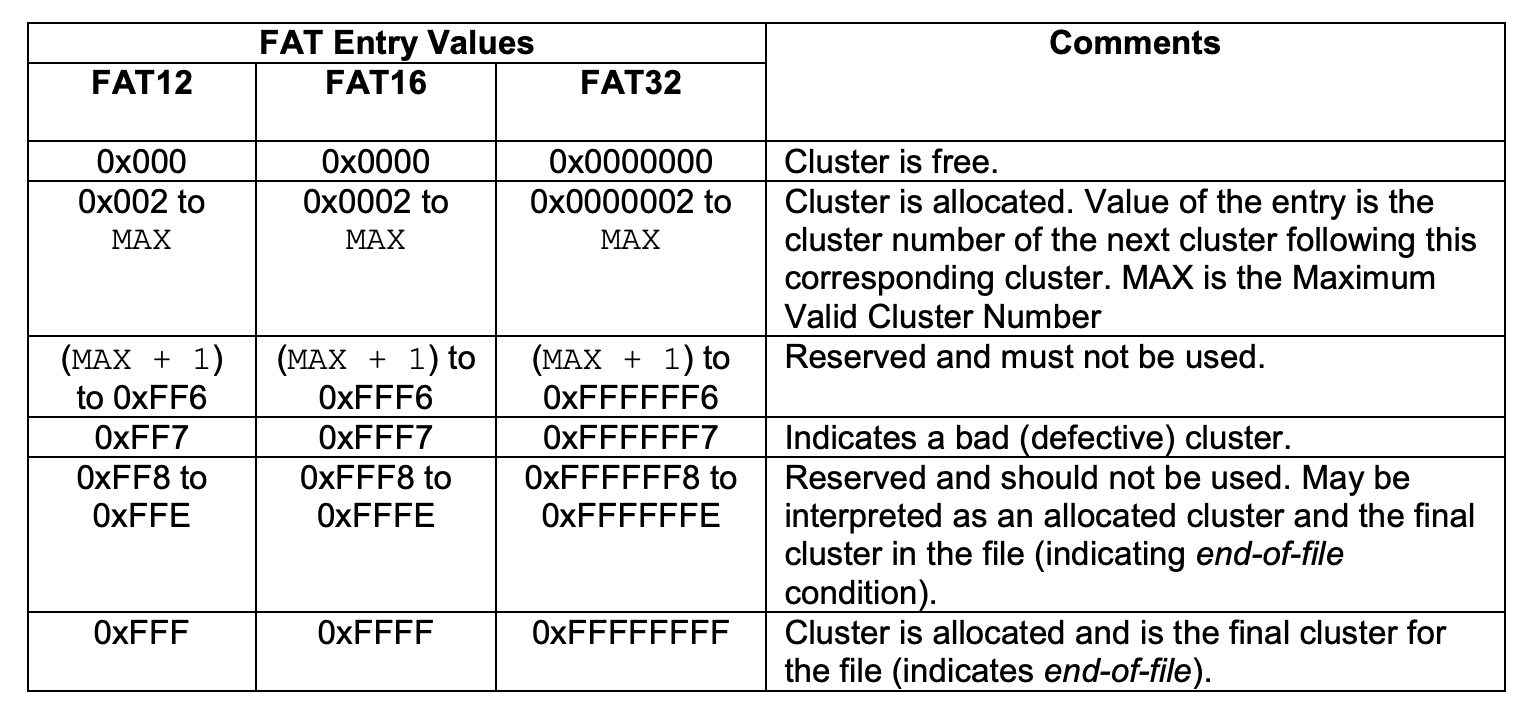
FAT: 链接存储的文件
“FAT” 的 “next” 数组
0: free;2...MAX: allocated;ffffff7: bad cluster;ffffff8-ffffffe,-1: end-of-file
目录树实现:目录文件
以普通文件的方式存储 “目录” 这个数据结构
- FAT: 目录 = 32-byte 定长目录项的集合
- 操作系统在解析时把标记为目录的目录项 “当做” 目录即可
- 可以用连续的若干个目录项存储 “长文件名”
- 思考题:为什么不把元数据 (大小、文件名、……) 保存在
vector<struct block *> file的头部?

Talk is Cheap, Show Me the Code!
首先,观察 “快速格式化” (
mkfs.fat) 是如何工作的- 老朋友:strace
然后,把整个磁盘镜像 mmap 进内存
- 照抄手册,遍历目录树:fatree.c
另一个有趣的问题 (M5 - frecov)
快速格式化 = FAT 表丢失
- 所有的文件内容 (包括目录文件) 都还在
- 只是在数据结构眼里看起来都是 “free block”
首先需要猜出文件系统的参数 (
SecPerClus,BytsPerSec,FATSz32,BPB_RootClus, …)本质上是 cluster 的分类和建立 “可能后继关系”
FAT: 性能与可靠性
性能
+ 小文件简直太合适了
- 但大文件的随机访问就不行了
- 4 GB 的文件跳到末尾 (4 KB cluster) 有 220220 次链表 next 操作
- 缓存能部分解决这个问题
在 FAT 时代,磁盘连续访问性能更佳
- 使用时间久的磁盘会产生碎片 (fragmentation)
- malloc 也会产生碎片,不过对性能影响不太大
- 使用时间久的磁盘会产生碎片 (fragmentation)
可靠性
维护若干个 FAT 的副本防止元数据损坏
- 额外的同步开销
损坏的 cluster 在 FAT 中标记
ext2/UNIX 文件系统
更好的文件系统:需要做到什么?
不能 “尽善尽美”,但可以在 “实际 workload” 下尽可能好
| Summary | Findings |
|---|---|
| Most files are small | Roughly 2K is the most common size |
| Average file size is growing | Almost 200K is the average |
| Most bytes are stored in large files | A few big files use most of the space |
| File systems contains lots of files | Almost 100K on average |
| File systems are roughly half full | Even as disks grow, file systems remain ~50% full |
| Directories are typically small | Many have few entries; most have 20 or fewer |
ext2/UNIX 文件系统
按对象方式集中存储文件/目录元数据
增强局部性 (更易于缓存)
支持链接
为大小文件区分 fast/slow path
小的时候应该用数组
- 连链表遍历都省了
大的时候应该用树 (B-Tree; Radix-Tree; …)
- 快速的随机访问
ext2: 磁盘镜像格式
- 对磁盘进行分组
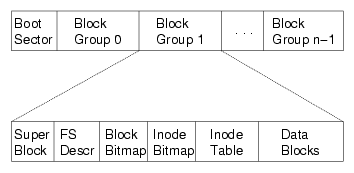
“superblock”:文件系统元数据
文件 (inode) 数量
block group 信息
- ext2.h 里有你需要知道的一切
ext2 inode
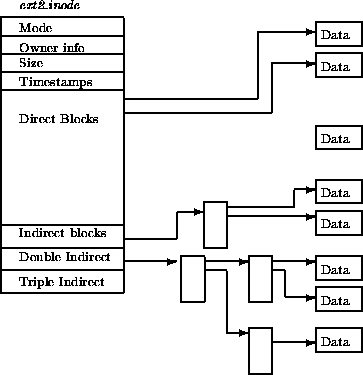
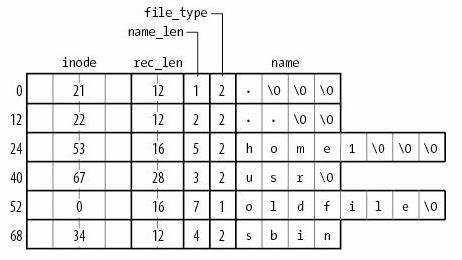
ext2 目录文件
与 FAT 本质相同:在文件上建立目录的数据结构
- 注意到 inode 统一存储
- 目录文件中存储文件名到 inode 编号的 key-value mapping
ext2: 性能与可靠性
大文件的随机读写性能提升明显O(1)
支持链接 (一定程度减少空间浪费)
inode 在磁盘上连续存储,便于缓存/预取
依然有碎片的问题
但可靠性依然是个很大的问题
- 存储 inode 的数据块损坏是很严重的
总结
总结
本次课回答的问题
- Q: 如何在磁盘上实现文件系统 API?
- “图书馆” - mkdir, rmdir, link, unlink, open, …
- “图书/书签” - read, write, mmap, lseek, …
- Q: 如何在磁盘上实现文件系统 API?
Takeaway messages
- 文件系统实现 = 自底向上设计实现数据结构
- balloc/bfree
- FAT/inode/…
- 文件和目录文件
- 文件系统实现 = 自底向上设计实现数据结构