Stanford Pratical Machine Learning-网络架构搜索
本文最后更新于:1 年前
这一章主要介绍网络架构搜索,也就是我们反复提到的NAS
Neural Architecture Search (NAS)
- A neural network has different types of hyperparameters:
- Topological structure: resnet-ish, mobilenet-ish, #layers
- Individual layers: kernel_size, #channels in convolutional layer, #hidden_outputs in dense/recurrent layers
- NAS automates the design of neural network
- How to specify the search space of NN
- How to explore the search space
- Performance estimation
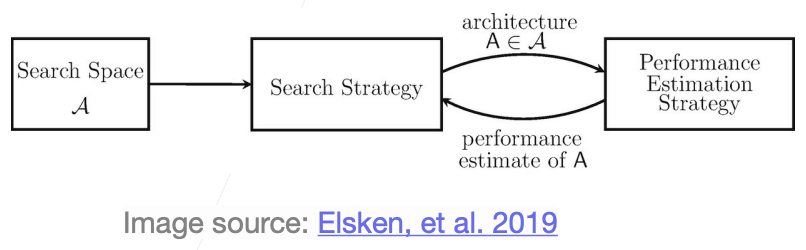
https://arxiv.org/abs/1808.05377,Image source,show how NAS work
NAS with Reinforcement Learning
- Zoph & Le 2017
- A RL-based controller (REINFORCE) for proposing architecture.
- RNN controller outputs a sequence of tokens to config the model architecture.
- Reward is the accuracy of a sampled model at convergence
- Naive approach is expensive and sample inefficient (~2000 GPU days). To speed up NAS:
- Estimate performance
- Parameter sharing (e.g. EAS, ENAS)
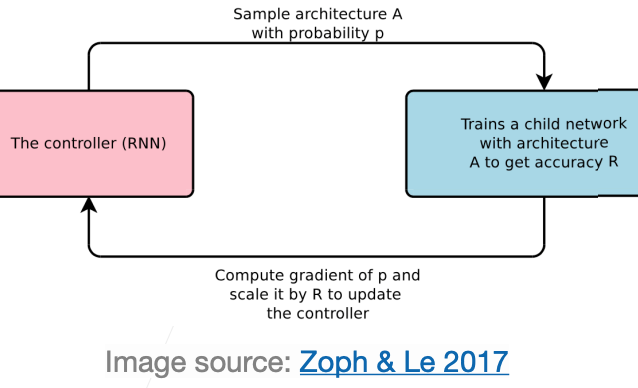
https://arxiv.org/abs/1611.01578,Image source,show how NAS work
The One-shot Approach
- Combines the learning of architecture and model params
- Construct and train a single model presents a wide variety of architectures
- Evaluate candidate architectures
- Only care about the candidate ranking
- Use a proxy metric: the accuracy after a few epochs
- Re-train the most promising candidate from scratch
Differentiable Architecture Search
- Relax the categorical choice to a softmax over possible operations:
- Multiple candidates for each layer
- Output of i-th candidate at layer l is $o_i^l$
- Learn mixing weights $a^l$. The input for i+1-the layer is $\sum_i a_i^l i_i^l$ with $a^l = softmax(a^l)$
- Choose candidate $argmax_ia_i$
- Jointly learn $a^l$ and network parameters
- A more sophisticated version (DARTS) achieves SOTA and reduces the search time to ~3 GPU days
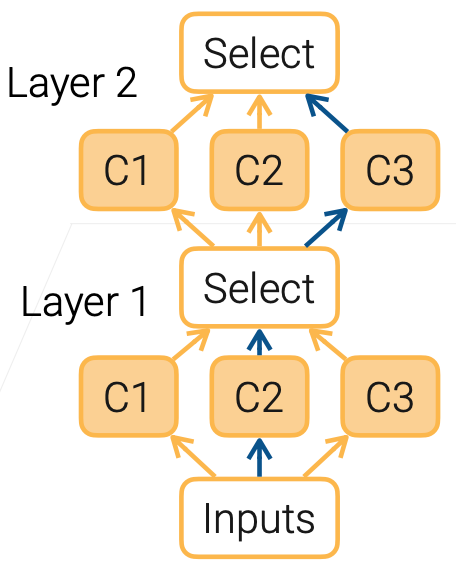
Select本质就是选择某一层的模型,通过权重的方式,完成“选择”。
Scaling CNNs
- A CNN can be scaled by 3 ways:
- Deeper: more layers
- Wider: more output channels
- Larger inputs: increase input image resolutions
- EfficientNet proposes a compound scaling
- Scale depth by $\alpha^{\phi}$, width by $\beta^{\phi}$, resolution by $\gamma^{\phi}$
- $\alpha \beta^{2}\gamma^{2} \approx 2$ so increase FLOP by 2x if $\phi = 1$
- Tune $\alpha, \beta, \gamma, \phi$
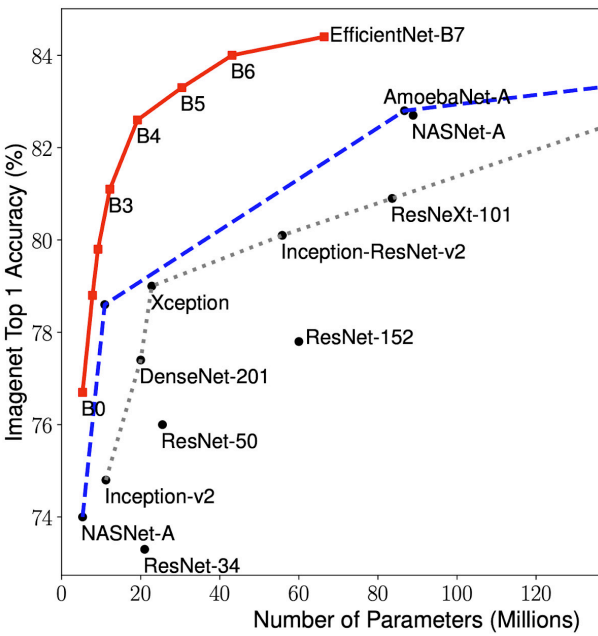
三个参数进行联动!然后进行搜索!找到合适的网络架构!我们一般只要调整$\phi$,别的都会选好,主要代表的意义就是,我们要把图片按照等高宽比拉伸多少?
Research directions
- Explainability of NAS result
- Search architecture to fit into edge devices
- Edge devices are more and more powerful, data privacy concerns
- But they are very diverse (CPU/GPU/DSP, 100x performance difference) and have power constraints
- Minimize both model loss and hardware latency
- E.g. minimize loss x $log(latency)^{\beta}$
- To what extend can we automates the entire ML workflow?
Summary
- NAS searches a NN architecture for a customizable goal
- Maximize accuracy or meet latency constraints on particular hardware
- NAS is practical to use now:
- Compound depth, width, resolution scaling
- Differentiable one-shot neural network
Stanford Pratical Machine Learning-网络架构搜索
https://alexanderliu-creator.github.io/2023/08/27/stanford-pratical-machine-learning-wang-luo-jia-gou-sou-suo/