Stanford Pratical Machine Learning-迁移学习
本文最后更新于:1 年前
这一章主要介绍迁移学习,Transfer Learning
Transfer learning
Motivation
- Exploit a model trained on one task for a related task
- Popular in deep learning as DNNs are data hungry and training cost is high
Approaches
- Feature extraction (e.g. Word2Vec, ResNet-50 feature, I3D feature)
- Train a model on a related task and reuse it
- Fine-tuning from a pertained model (focus of this lecture)
Related to
- Semi-supervised learning
- In the extreme, zero-shot / few-shot learning
- Multi-task learning, where some labeled data is available for each task
能在一个任务上学习一个模型,然后用其来解决相关的别的任务,这样我们在一个地方花的时间,学习的一些知识,研究的一些看法可以在另外一个地方被使用到;
迁移学习是在深度学习出圈的,因为在深度学习中需要训练很多的深层神经网络,需要很多的数据,代价也很高;
迁移学习的途径:
- 做好一个模型将其做成一个特征提取的模块(Word2Vec【在文本上做训练一个单层神经网络,在训练好之后,每一个词对应一个特征,然后用这个特征去别的事情】,ResNet【对图片做特征,然后用这个特征来对作为另一个模型的输入,这样假设效果非常好,那么就可以代替人工去抽取特征】,I3D【用来对视频做特征】);
- 在一个相关的任务上训练一个模型,然后在另一个任务上直接用它;(之后的单元会讲到)
- 训练好一个模型,然后在一个新的任务上对其做微调,使模型能更好的适应新的任务;
相关的领域:
- 半监督学习:利用没有标号的数据,让有标号的数据变得好
- 在极端的条件下,可以做zero-shot(一个任务有很多的类别但不会告诉你样本)或few-shot(一个任务就给你一些样本) learning。
- Multi-task learning(多任务学习):每一个任务都有它自己的数据,但是数据不是很够,可是任务之间相关,那么可以将所有的数据放在一起,然后同时训练多个任务出来,这样我们希望能从别的任务之中获益
CV Field
Transferring Knowledge
- 在CV中存在了很多大规模标好的数据集(特别是分类问题,因为标号容易);
- 在CV的迁移学习,我们是希望存在 很多数据的一些应用上比较好的模型,能将它的知识拓展到我们自己的任务上去;
- 通常你自己任务的数据集会比大的数据集(ImageNet)要小很多(一开始不会花太多钱去标注很多的数据,正常是,标好了一些看看模型效果怎么样,然后好的话再继续投入进去,这样是一个迭代的过程),然后我们想要快速的迭代,看看能不能用比较大的数据集来将一些学到的东西迁移到我们自己的任务上面去;
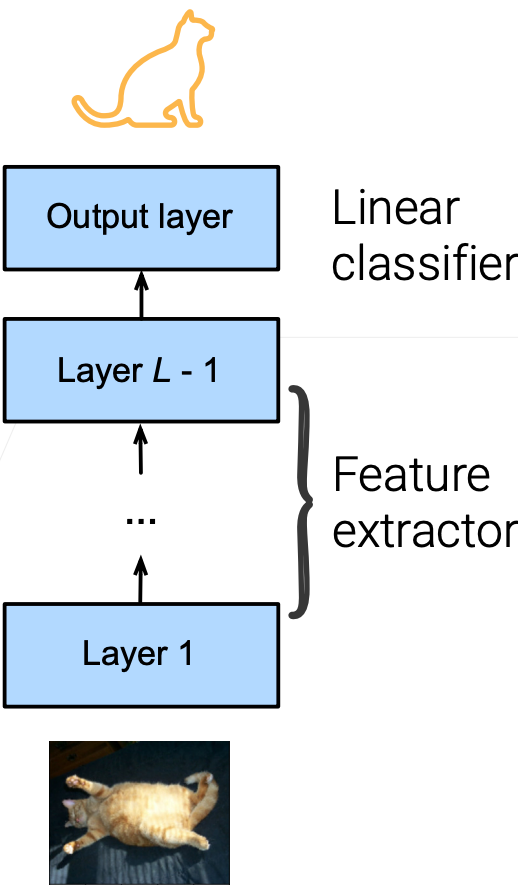
Pre-trained Models
Partition a neural network into:
- A feature extractor (encoder) maps raw pixels into linearly separable features
- A linear classifier (decode) makes decisions
Pre-trained model
- a neural network trained on a large-scale and general enough dataset
- The feature extractor may generalize well to
- other datasets (e.g. medical/satellite images)
- other tasks (e.g. object detection, segmentation)
可以将神经网络分成两块,一块编码器(特征提取器,将原始图片的原始像素转化在一个语义空间中可以线性可分的一些特征(浅表示或语义特征表示)),一块解码器(简单的线性分类器,将编码器的表示映射成想要的标号,或者做一些决策);
预训练模型(Pre-train):在一个比较大的数据上训练好的一个模型,会具有一定的泛化能力(放到新模型上或新的数据集上,这个模型还是有效果的)【虽然是用于图片分类但是也可以试试目标检测】;
Fine-Tuning techniques
Initialize the new model:
- Initialize the feature extractor with the feature extractor parameters of a pre-trained model
- Randomly initialize the output layer
- Start the parameter optimization near a local minimal
Train with a small learning rate with just a few epochs
- Regularize the search space
将预训练好的模型用在新任务上叫fine-tuning(微调)【通常在深度学习里面,微调能带来最好的效果,但是也有一定的开销】
微调是怎么做的:
- 在新的任务上构建一个新的模型,新的模型的架构要更预训练的模型的架构是一样的;
在找到合适的预训练模型之后要初始化我们的模型(将预训练模型的除了最后一层之外(特征提取器)的权重都复制给我们的模型,最后一层的解码器用的还是随机的权重【因为我们的标号和预训练模型的标号是不一样的】);
具体看例子
- 在初始化之后,就可以开始学习了,这步跟我们平常的学习没有什么不同的;
有一点点小做法是,限制fine-tune后的学习率。因为我们初始的结果已经比较好了,已经在想要解的附近了,限制学习率可以使得我们可以不会走太远【一般是用1e-3】;另外是说不要训练太长的时间;这些做法都是为了缩小搜索空间;
微调:不要改的太多!!!
- 限制搜索空间的原因:原来任务结果就已经很好的,只需要再略微调整,便可以得到最优解!
Freeze Bottom Layers
Neural networks learn hierarchical features
- Low-level features are universal, generalize well, e.g. curves /edges / blobs
- High-level features are more task and dataset specific, e.g. classification labels
Freeze bottom layers during fine tuning Train the top layers from scratch
- Keep low-level universal features intact
- Focus on learning task specific features
- A strong regularizer
神经网络通常有一个层次化的,最底层一般是学习了底层的特征,上层的更与语义相关,所以一般来说底层与上面层没有太多的关系,在换了数据集之后泛化性都很好;
最后一层还是随机初始化学习,然后只对某一些层进行改动,最下面那些层在微调时就不去动了(可以说是学习率为0);
固定住多少层是要根据应用来看的,假设应用与预训练模型差别比较大的话,可以多训练一些层;
Where to Find Pre-trained Models
- 首先要去找有没有我们想要的预训练模型,然后是看它是在什么样的数据集上训练好的;
- 可以去的途径(ModelHub、ModelZoom之类的):
- Tensorflow Hub: https://tfhub.dev/;(允许用户去提交模型)
- TIMM(把pytorch上能找到的各种代码实现弄过来): https://github.com/rwightman/pytorch-image-models;(ross 自己维护的一个包【文档不错,模型性能暂时一般般】)
- TIMM使用代码介绍:
1 | |
Applications
Fine-tuning pre-trained models (on ImageNet) is widely used in various CV applications:
- Detection/segmentation (similar images but different targets)
- Medical/satellite images (same task but very different images)
Fine-tuning accelerates convergence
Though not always improve accuracy
- Training from scratch could get a similar accuracy, especially when the target dataset is also large
在大的数据集上训练好模型再微调到自己的应用上在CV领域上广泛的应用;
- 新的任务包含 目标检测、语义分割等(图片类似但是目标不一样);
- 在医疗领域等(同样的任务但是图片大相径庭);
现在的观点是微调加速了收敛(微调让初始的点不再试一个随机的点而是一个离最终的目标比较近的点,使得损失比较平滑),但是不一定可以提升精度(一般不会让精度变低,因为它只是改变初始值而已,跟随机初始化没区别,只要走的足够远也能摆脱初始值的影响);
Summary
- 通常我们会在大数据上训练预训练好的模型,这种任务通常是图片分类;
- 然后在关心的任务上把模型的权重初始化成预训练好的模型的权重,当然最后一层也就是解码器是要随机初始化的;
- 微调一般用一个小一点的学习率进行细微的调整,这样通常会加速收敛,有时可以提升精度但通常不会变差;(所以通常在CV中是经常被推荐的做法)
NLP Field
Self-supervised pre-training
No large-scale labeled NLP dataset
Large quantities of unlabeled documents
- Wikipedia, ebooks, crawled webpages
Self-supervised pre-training
- Generate “pseudo label” and use supervised learning task
- Common tasks for NLP
- Language model (LM): predict next word. e.g. I like your hat
- Masked language model (MLM): random masked word prediction. e.g. I like your hat
NLP与CV在微调中有个不一样的地方是说:NLP里面不存在特别大的标好的数据集(CV中图片分类里,有使用特别大的标注好的数据集训练好的预训练模型),在NLP中机器翻译里面有大一点的,但是在NLP中更多是说有大量的没有标注的文档(如Wikipedia、网络的电子书、爬取网站中的文字等);
在NLP里面我们很容易得到大量的文档,但是比较难的是去给这些文档一个个去做标号。在早期,我们可以去分类这些文档,但是标注是非常非常难的。
在NLP中,我们一般会去做自监督的一个预训练(标号是由自己产生的,也就是伪标号。然后用这些伪标号来参与进 一个正常的可以监督学习的任务之中,用于完成预训练)
在NLP中有两个常见的应用来生成这样的伪标号
- 语言模型(Language Model,LM):给出前面的一些词,去预测下一个词;
- 带掩码的语言模型(Masked Language Model,MLM):在一个句子里面随机的扣掉一些字,然后让你去预测这个字,有点像是完型填空;
- 完型填空比预测下一个字容易些,因为完型填空能看到左右的信息,而预测比较开放;
Pre-trained Models
词嵌入(十几年前的模型):模型会学习两个向量$u_w$和$v_w$,然后对给定掩码的词Y,用其x1……xn去预测Y
具体来说,要预测的值用u来表示,上下文的词用v来表示,然后把v给加起来再与u做内积,这样就可以的到u与v之间的关系,这个算法叫CBOW;然后做预测时就从字典中选取一个y使得CBOW的值最大;
$$
argmax_yu_y^T \sum_i v_{x_i}
$$当然,也可以用中心词去预测周围的词。具体是说,对所有的词学到了两个向量,这两个词具有一定的语义关系(两个词如果差不多同时出现的话,那么存在相似度),如果说y与$x_i$出现在一起的话,内积比较大的话,意味着说有相似性;
基于Transformer的预训练模型(BERT):
- BERT就是一个Transformer的编码器,然后它使用的是带掩码的词预测(双向的),所以它适合一些带掩码的语言模型;
- GPT用的是它的一个解码器(从左到右的过程),可以用于预测下一个词;
- T5是一个基于编码器与解码器的架构
BERT
- 论文精讲BERT:https://www.bilibili.com/video/BV1PL411M7eQ
- BERT使用了两个预训练任务:一个是把一个词盖住去预测,另一个是为了处理NLP里多的任务,一个进去两个句子(可以是文档中确实是相连的(正例),没有相连的句子(负例));
- BERT原始的论文使用的是Wikipedia和一个书的数据集;
- 有许多的版本:Base/Large(大小不一样);English/Multilingual(在英语上训练还是在英语上训练的);cased/uncase(有没有大小写的区别);
- 看图看BERT在干什么事情
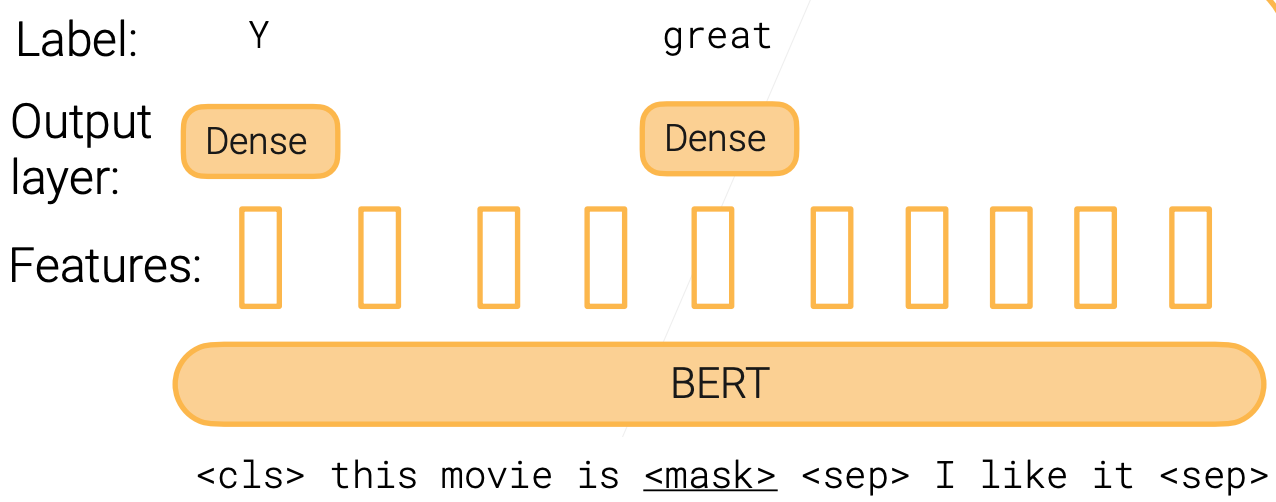
- BERT之后有很多变种,ALBERT,ELECTRA,RoBERTa;
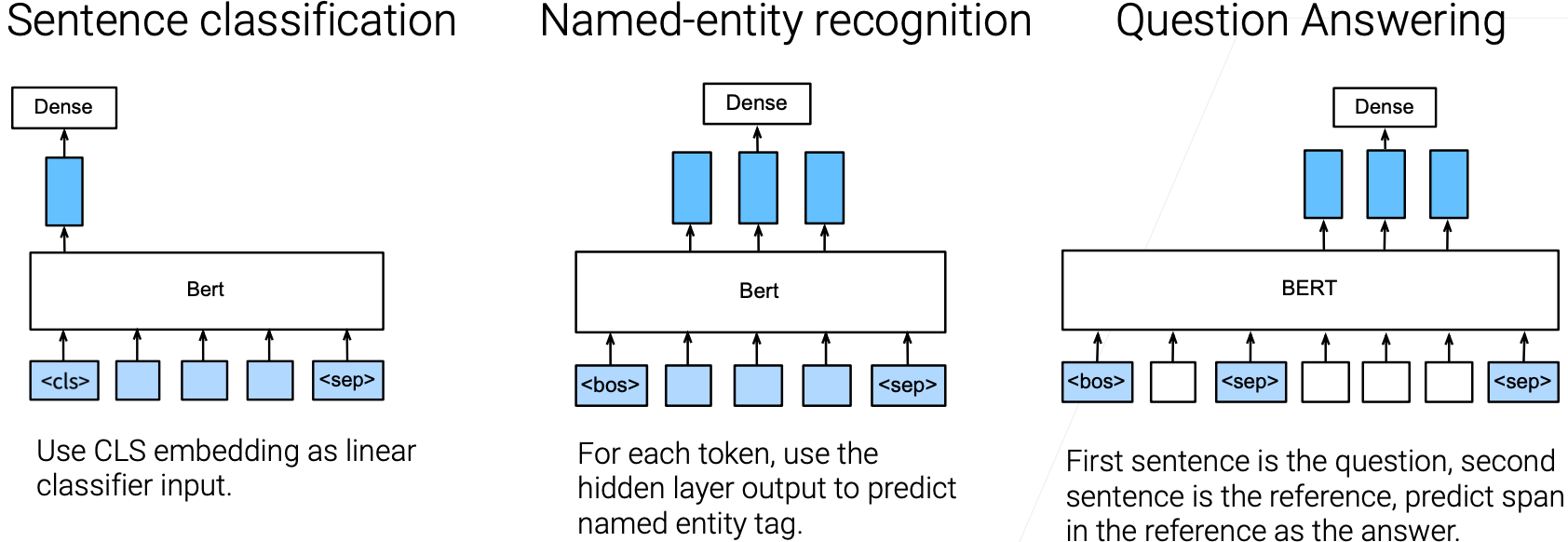
BERT Fine-tuning
Randomly initialize the last layer, train a few epochs with small lr
Downstream task examples
在训练好上面的模型之后就可以用BERT做fine-tuning了;
和CV很像,构造我们的任务的最后一层让它输出到我们想要的东西(BERT的最后一层要去掉,因为最后一层是输出两句子间是否相连),也就是最后一层随机初始化,训练一些epoch,用一个比较小的学习率;
当然这也取决于下游的任务:
- 对句子分类(判断句子的正面与负面):只需要把第一个词对应输出拿出来,然后加一个输出层就可以拿到标号了;
- 做词级别的任务(实体命名(人名街道名之类的)的识别):把整个那些词,每个词对应的输出的向量拿过去接上个全连接层做标号就行了;
- 做问答的话(给一个问题或给一段话,答案就在这一段话里面,模型需要把答案给找出来(给出答案的开始与结束的位置)),对第二个句子开始就要每个词的输出里面去看他是不是答案的开始,是不是答案的结束,
虽然在自然语言中任务有多种多样,但实际上可以通过构造输入(句子、词、一段话、甚至可以是一篇文章)使得能放入进模型里面
Practical Considerations
BERT fine-tuning on small datasets can be unstable
- BERT removed bias correction steps in Ada
- Too few (=3) epochs
Randomly initializing some top transformer layers help
- Features learned by top layers are too specific to the pre-training tasks
- The cutoff depends on downstream tasks
BERT这篇paper出来的时候,微调时结果不稳定(超参数没有弄对),因为BERT使用了Adam的改版(前期的时候去掉了整个对系数估计的不确定性),这个对BERT是没问题的(数据量很大);但是对于微调来讲,它的数据集不大也不会跑很久,再使用改版的Adam会使得结果没那么稳定;所以推荐使用完整版的Adam;
BERT对哪个任务都是训练3次数据迭代,大家发现三次并没有完整的收敛,最好是训练多几个Epoch;
这些是比较常见的小技巧,做任何微调时都可以去调一下这些东西;
对于一个Transformer来讲,它跟一个CNN是没有什么本质上的不同的,就是有很多层,对底层来说是有保留一些更低的语义层次的信息,越往上的话它跟标注空间越像;在BERT中也可以像CV一样固定住下面的层只调上面的,甚至可以对上面那些层进行随机初始化(不一定要用预训练里训练好的权重)【可以不受之前语言模型的影响】
Where to Find Pre-trained Models
- HuggingFace: a collection of pre-trained transformer models on both PyTorch and TensorFlow
1 | |
Applications
“(BERT) obtains new state-of-the-art results on eleven natural language processing tasks”, including
- If a sequence of words is a grammatical English sentence
- Sentiment of sentences from movie reviews
- Sentences/questions in a pair are semantically equivalent, or similar
- If the premise entails the hypothesis
- Find the span of the answer for a question
“(T5) achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more”
BERT在11门语言上取得了最好的结果:包含了去判断一个句子中的词的语法是否正确,判断评论的正负与否,判断两句话在语义上是否等价,或者两个问题在语义上是否等价,判断假设和结论是否有加强关系,在问题里面能不能找到答案;
BERT采用的是编码器的架构,会有局限性,在适合编码器解码器架构的任务就不会那么适用了;
GPT更适合给出一段话,然后生成更长的一段话;
T5也在很多地方取得了不错的结果,它使用的是编码器解码器的架构,可以做一些别的不一样的事情(对文章做摘要,或者是做Q&A)
根据自己的任务来选择使用Transformer的哪个部分(BERT,GPT,T5等) -> 基本上三选一
Summary
- 在自然语义里面,预训练模型通常是通过自监督来完成的(因为自然语言的数据集没有那么大的标好的数据集),一个常见的应用是做语言模型或者是做带掩码的语言模型;
- BERT是一个特别大的Transformer的编码器,GPT就是一个特别大的解码器,T5就是一个特别大的解码器加编码器;
- BERT在对下游任务做微调时就跟CV很像了,一般只要改最后一层就好了,但是在输入上要有一定的构造
References
- 沐神Vedio
- MSRA 王晋东大神 迁移学习导论
- CV 笔记
- NLP 笔记
- CV Field ppt: https://c.d2l.ai/stanford-cs329p/_static/pdfs/cs329p_slides_14_1.pdf
- NLP Field ppt: https://c.d2l.ai/stanford-cs329p/_static/pdfs/cs329p_slides_14_2.pdf
- Tensorflow Hub: https://tfhub.dev/;(允许用户去提交模型)
- TIMM(把pytorch上能找到的各种代码实现弄过来): https://github.com/rwightman/pytorch-image-models;(ross 自己维护的一个包【文档不错,模型性能暂时一般般】)