Stanford Pratical Machine Learning-偏差和方差
本文最后更新于:1 年前
这一章主要介绍Model Combination,首先引入偏差和方差的概念。
Bias & Variance
- 偏差:偏移真实情况的程度,偏差越大,预测离真实值越远。其实反应的是Underfitting,因为模型拟合不了数据,无法充分学习,导致和真实结果有偏差。
- 方差:数据自身的分布情况,方差越大,数据分布的越零散。其实反应的是Overfitting,学习到太多的数据,拟合的“太细”了,导致预测结果分散,哒咩!
Bias-Variance Decomposition
- Sample data $D = {(x_1, y_1), \dots,(x_n,y_n)}$ from $y = f(x) + \epsilon$
- Learn $\hat{f_D}$ from $D$ by minimizing MSE, we want it generates well over different choices of $D$.
- Evaluate generalization error $(y - \hat{f}_D(x)) ^ 2$
$$
E_D[(y - \hat{f}_D(x))^2] = Bias[\hat{f}_D]^2 + Var[\hat{f}_D] + \epsilon^2
$$
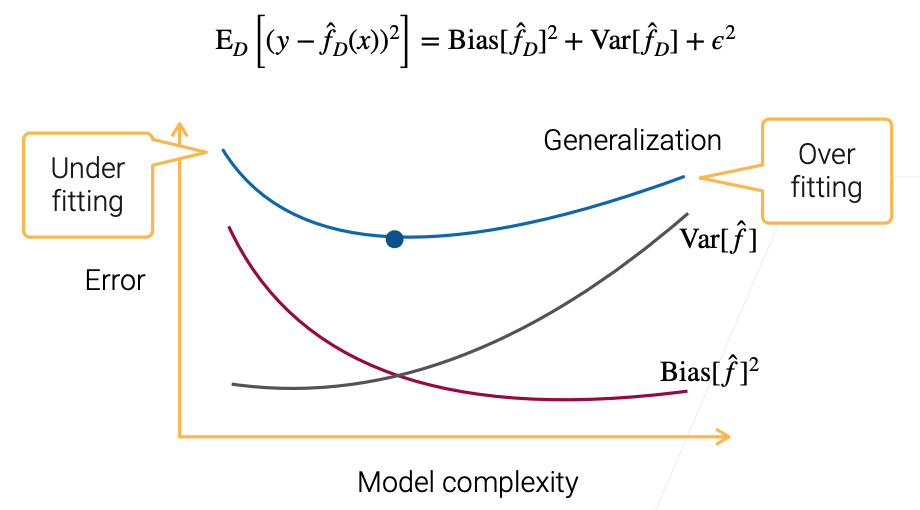
Reduce Bias & Variance
- Reduce bias
- A more complex model
- e.g. increase #layers, #hidden units of MLP
- Boosting
- Stacking
- A more complex model
- Reduce variance
- A simpler model
- e.g. regularization
- Bagging
- Stacking
- A simpler model
- Reduce $\epsilon^2$
- Improve data
Ensemble learning: train and combine multiple models to improve predictive performance
Summary
- Decompose model generalization error into bias, variance and intrinsic error
- Ensemble learning combines multiple models to reduce both bias and variance
References
Stanford Pratical Machine Learning-偏差和方差
https://alexanderliu-creator.github.io/2023/08/25/stanford-pratical-machine-learning-pian-chai-he-fang-chai/