Stanford Pratical Machine Learning-数据获取
本文最后更新于:1 年前
这一节主要介绍数据获取的内容
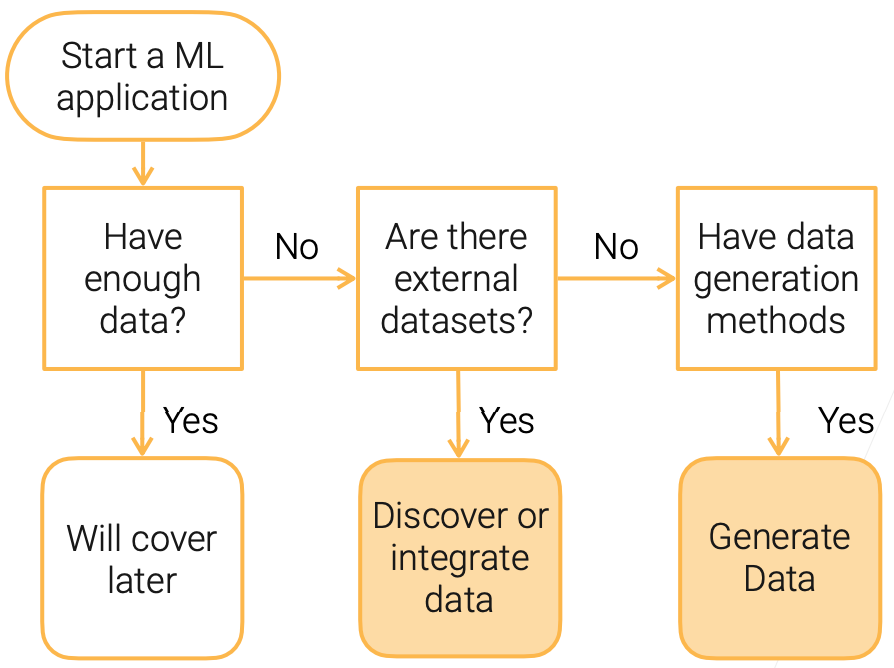
Flow chart for data acquisition
- Start a ML application
- Have enough data?
- Yes -> Will cover later
- No -> Are there external datasets?
- Yes -> Discover or integrate data
- No -> Have data generation methods?
- Yes -> Generate Data
- Have enough data?
Discover what data is available
- Identify existing datasets
- Find benchmark datasets to evaluate a new idea
- E.g. A diverse set of small to medium datasets for a new hyperparameter tuning algorithm
- E.g. Large scale datasets for a very big deep neural network
- Collect new data
- E.g. driving videos covering different driving scenarios
Popular ML datasets
- MNIST: digits written by employees of the US Census Bureau
- ImageNet: millions of images from image search engines
- AudioSet: YouTube sound clips for sound classification
- LibriSpeech: 1000 hours of English speech from audiobook
- Kinetics: YouTube videos clips for human actions classification
- KITTI: traffic scenarios recorded by cameras and other sensors
- Amazon Review: customer reviews and from Amazon online shopping
- SQuAD: question-answer pairs derived from Wikipedia
- More at https://en.wikipedia.org/wiki/List_of_datasets_for_machine-learning_research
Where to Find Datasets
- Paperswithcodes Datasets: academic datasets with leaderboard
- Kaggle Datasets: ML datasets uploaded by data scientists
- Google Dataset search: search datasets in the Web
- Various toolkits datasets: tensorflow, huggingface
- Various conference/company ML competitions
- Open Data on AWS: 100+ large-scale raw data
- Data lakes in your own organization
Datasets Comparison
| Pros | Cons | |
|---|---|---|
| Academic datasets | Clean, proper difficulty | Limited choices, too simplified, usually small scale |
| Competition datasets | Closer to real ML applications | Still simplified, and only available for hot topics |
| Raw Data | Great flexibility | Needs a lot of effort to process |
- You often need to deal with raw data in industrial settings
- Data curation can be a big projection involving multiple teams. Processing pipeline, storage, legal issue, privacy,…
工业界中Raw Data是比较多的昂!!!
Data Integration
数据零散,各有特色,做数据融合的时候,就需要花费很多的精力,使用很多不同的策略。
- Combine data from multiple sources into a coherent dataset
- Product data is often stored in multiple tables
- E.g. a table for house information, a table for sales, a table for listing agents
- Join tables by keys, which are often entity IDs
- Key issues: identify IDs, missing rows, redundant columns, value conflicts
Generate Synthetic Data
找不到数据集,我们可以生成数据集!
- Use GANs
- Data augmentations
- Image augmentation
- Back Translation
References
Stanford Pratical Machine Learning-数据获取
https://alexanderliu-creator.github.io/2023/08/23/stanford-pratical-machine-learning-shu-ju-huo-qu/