Stanford Pratical Machine Learning-数据标注
本文最后更新于:1 年前
这一章主要介绍数据标注
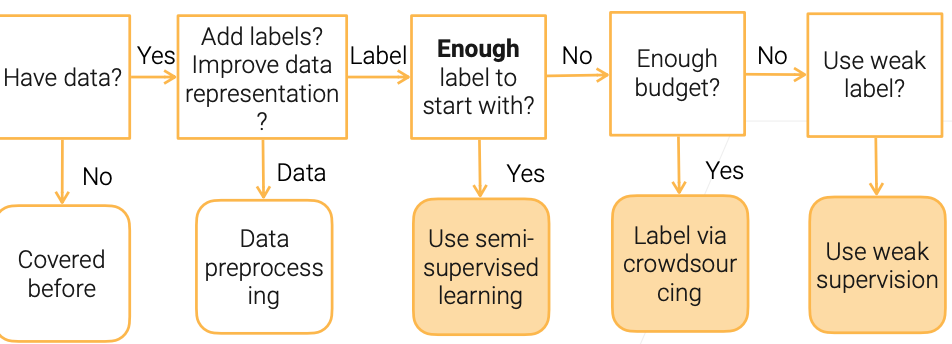
Flow Chart for Data Labelling
Semi-Supervised Learning (SSL)
半监督学习,解决一小部分的数据有标注的情况。
- Focus on the scenario where there is a small amount of labeled data, along with large amount of unlabeled data
- Make assumptions on data distribution to use unlabeled data
- Continuity assumption: examples with similar features are more likely to have the same label
- Cluster assumption: data have inherent cluster structure, examples in the same cluster tend to have the same label
- Manifold assumption: data lie on a manifold of much lower dimension than the input space
假设:
- 连续性假设:样本特征相似,应该有相同的标签。
- 聚类的假设:数据应该存在潜在的“类”,按照类来分布,同个类应该相似,拥有相同的标签。不同的类之间也可能是有相同的标签的。
- 流行假设:尽管数据维度高,但是可能主要数据内在的复杂性都分布在低维,数据远比我们看到的要简单。可以通过降维的方式来获取更加干净的数据。
Self-training
很出名的自学习!!!对于有标签的数据进行训练,并对没有标签的数据进行预测,然后将所有有标签的数据合并,再训练一个新的模型,并进行下一轮的迭代。
- Self-training is a SSL method
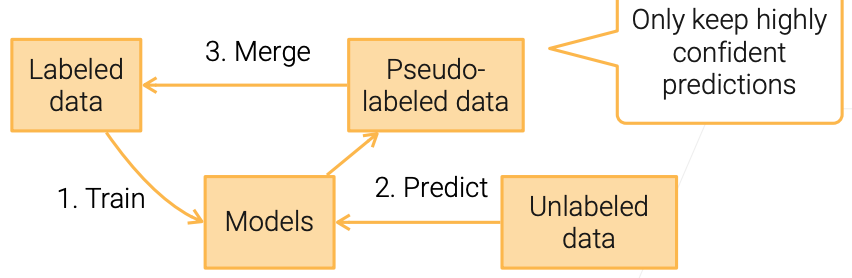
Only keep highly confident predictions.这样可以减少一下数据噪音带来的影响。
- We can use expensive models
- Deep neural networks, model ensemble/bagging
因为不上线部署,就是本地用用,所以可以搞贵一点的!!!
Label through Crowdsourcing
- ImageNet labeled millions of images through Amazon Mechanical Turk. It took several years and millions dollars to build
- According to Amazon SageMaker Ground Truth, the estimated price of using Amazon Mechanical Turk:
众包,低成本标数据,用的也越来越广!
| Image/text classification | $0.012 per label |
|---|---|
| Bounding box | $0.024 per box |
| Semantic segmentation | $0.84 per image |
Challenges
设计简单的众包任务,方便标注的人来标注昂!
- Simplify user interaction: design easy tasks, clear instructions and simple to use interface
- Needs to find qualified workers for complex jobs (e.g. label medical images)
- Cost: reduce #tasks X #time per task sent to labelers
- Quality control: label qualities generated by different labelers vary
Reduce #tasks: Active Learning
让人进行干预,和self-training类似,把最不确定的给人来Label
Focus on same scenario as SSL but with human in the loop
- Self training: Model helps propagate labels to unlabeled data
- Active learning: Model select the most “interesting” data for labelers
Uncertainty sampling
- Select examples whose predictions are most uncertain
- The highest class prediction score is close to random (1/n )
Query-by-committee
- Trains multiple models and select samples that models disagree with
Active Learning + Self-training
- These two methods are often used together
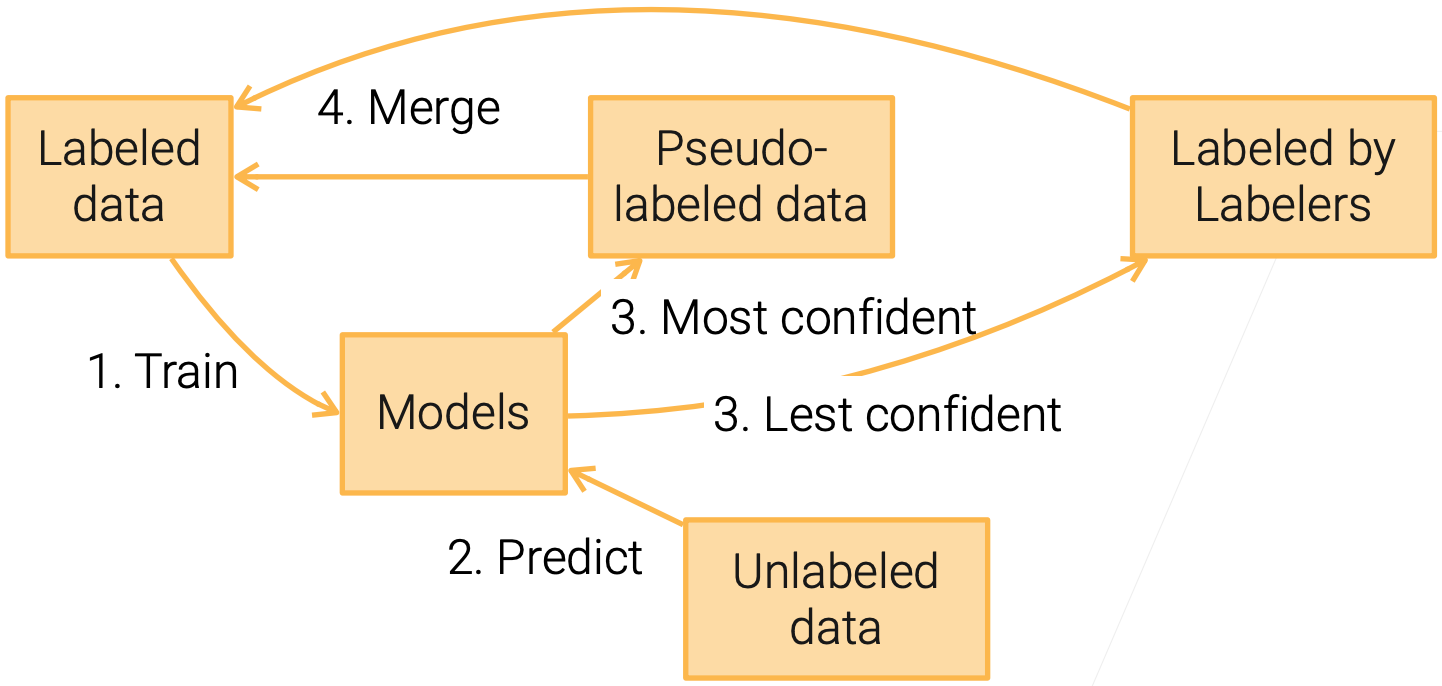
人和机器都做一部分!可以减少一部分的cost
Quality Control
- Labelers make mistakes (honest or not) and may fail to understand the instructions
- Simplest but most expensive: sending the same task to multiple labelers, then determine the label by majority voting
- Improve: repeat more for controversial examples, prune low-quality labelers
Weak Supervision
又没label,又没💰。弱监督学习!!!半自动生成标号(凭借启发式算法),比人差一些,但是也还不错,可以用来训练模型。启发式方法来Label,这种方法又被称为:数据编程!
- Semi-automatically generate labels
- Less accurate than manual ones, but good enough for training
- Data programming:
- Domain specific heuristics to assign labels
- Keyword search, pattern matching, third-party models
- E.g. rules to check if YouTube comments are spam or ham
1 | |
Summary
- Ways to get labels
- Self-training: iteratively train models to label unlabeled data
- Crowdsourcing: leverage global labelers to manually label data
- Data programming: heuristic programs to assign noisy labels
- Alternatively, You could also consider unsupervised/selfsupervised learnings
References
Stanford Pratical Machine Learning-数据标注
https://alexanderliu-creator.github.io/2023/08/23/stanford-pratical-machine-learning-shu-ju-biao-zhu/