D2L-8-Computer Vision
本文最后更新于:1 年前
这一章节本质上是几个章节的融合:计算机视觉章节和计算性能章节
CPU vs GPU
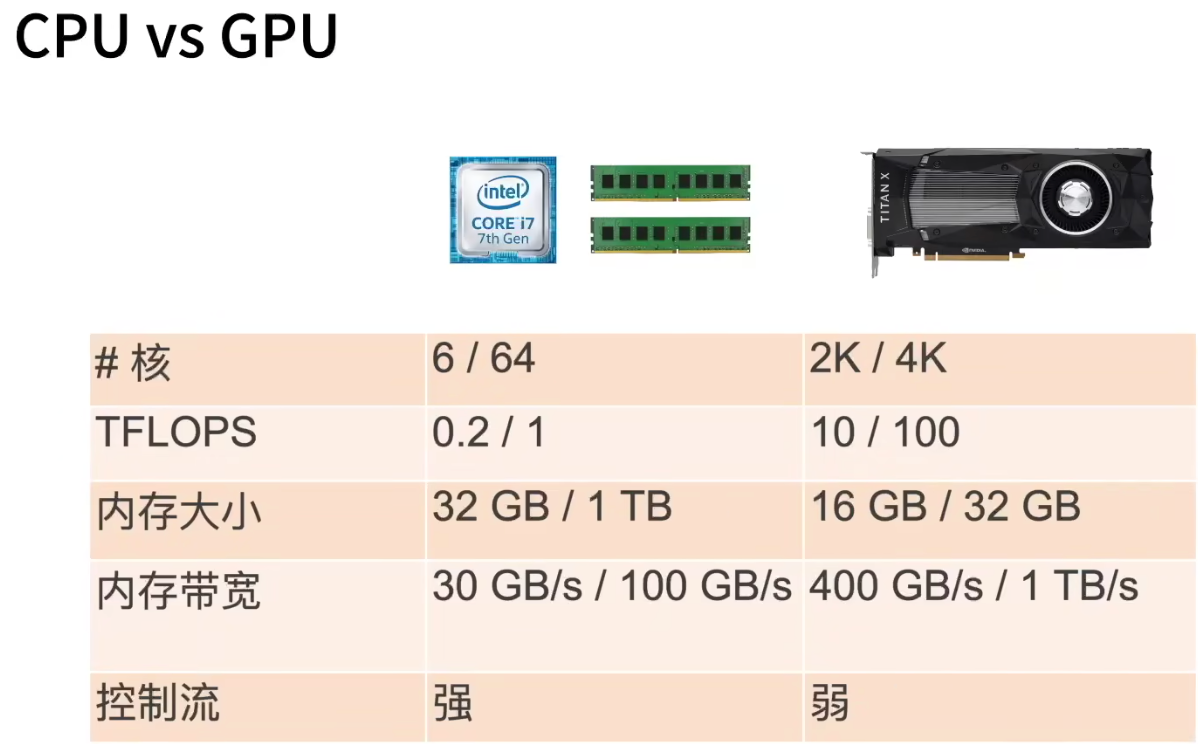
提升CPU利用率:
- 缓存:
- 时间:重用数据使得保持它们在缓存里
- 空间:按序读写数据使得它们可以预读取
- 并行利用所有核
- 缓存:
提升GPU利用率:
- 并行:使用数千个线程
- 内存本地性:缓存更小,架构更简单
- 少用控制语句:
- 支持有限
- 同步开销很大
不要频繁在CPU和GPU之间传数据:
- 带宽限制
- 同步开销
CPU/GPU高性能计算编程
- CPU: cpp or 其他高性能语言,编译器成熟!
- GPU:
- Nvidia上用CUDA:编译器和驱动成熟
- 其他用OpenCL
总结:
- CPU:通用计算,性能优化考虑读写效率和多线程。
- GPU:大规模并行计算任务,使用更多的小核和更好的内存带宽。
更多的芯片
- DSP:Digital Signal Process芯片
- 数字信号处理芯片,擅长卷积,傅立叶变换等。
- 特点:性能高、功耗低。
- VLIW: Very long instruction word,超长指令处理很牛。
- 编程&调试困难,编译器质量良莠不齐。
- FPGA:可编程阵列
- 可编程逻辑单元和可配置连接
- 可以配置成计算复杂函数,编程语言:VHDL, Verilog
- 通常比通用硬件更高效
- 工具链质量良莠不齐
- 一次“编译”需要数小时
- AI ASIC:Application Specific Integrated Circuit
- 深度学习的热门领域
- Google TPU是标志性芯片
- 媲美Nvidia GPU性能
- 在Google大量部署
- 核心是systolic array
- Systolic Array
- 计算单元(PE)阵列
- 特别适合做矩阵乘法
- 设计和制造相对简单。
- 对于一般的矩阵乘法,通过切分和填充来匹配SA的大小
- 批量输入来降低延时
- 通常有其他硬件单元来处理别的NN操作子,例如激活层

越专用,越难卖,但是对于特定领域性能越高,功耗越低!!!
单机多卡并行
- 单机多卡并行:
- 一台机器可以装多个GPU(1-16)
- 训练和预测时,我们将一个小批量计算切分到多个GPU上来达到加速目的
- 常用切分方案有:
- 数据并行
- 模型并行
- 通道并行(数据+模型并行)
- 数据并行 vs 模型并行
- 数据并行:小批量分为n块,每个GPU拿到完整参数计算一块儿数据的梯度。通常性能更好。 -> 单卡计算拓展到多卡计算
- 模型并行:模型分为n块,每个GPU拿到一块儿模型计算它的前向和方向结果。通常用于模型大到单GPU放不下。 -> 超大模型并行
多GPU训练实现
手写
allreduce方法简介实现
- 在一个核上完成所有核中数据的累加
- 将这个核上的结果,广播到其他所有核
1
2
3
4
5def allreduce(data):
for i in range(1, len(data)):
data[0][:] += data[i].to(data[0].device)
for i in range(1, len(data)):
data[i] = data[0].to(data[i].device)小批量数据均匀分布到多个GPU上
1 | |
- Split_batch函数:
1 | |
- 训练:
1 | |
简洁实现
- 引入依赖
1 | |
- 简单网络
1 | |
- 训练
1 | |
- 训练结果:
1 | |
Batch_size本质上是从全部样本中抽样
- 由于GPU变多,我们为了增大性能,可以通过增大batch_size(一台GPU就256,两台GPU就应该512嘛),不然性能提升不明显。但是如果我们提升了batch_size,训练精度可能出现降低的情况,是可能由于:抽样的样本增多,学习率没有调整到位。样本本身太少,抽样的样本太多,重复样本多,重复的数据学不到东西捏!
- 验证集准确率震荡较大是learning rate这个参数影响最大。
分布式训练
上面是单机多卡,这里直接就是多机,其实是类似的,本质上没有什么区别昂!!!
- GPU架构(老的架构)
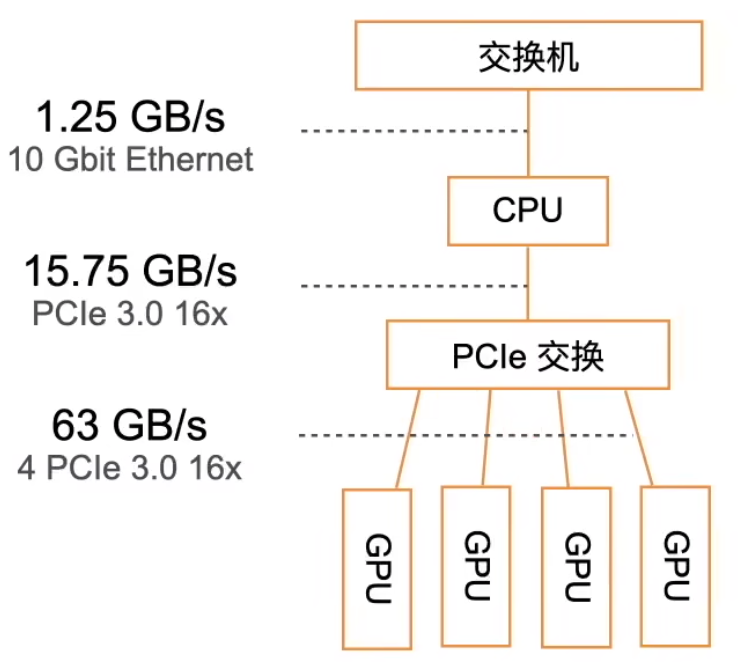
尽量少的搬运数据
- 层次的参数服务器:
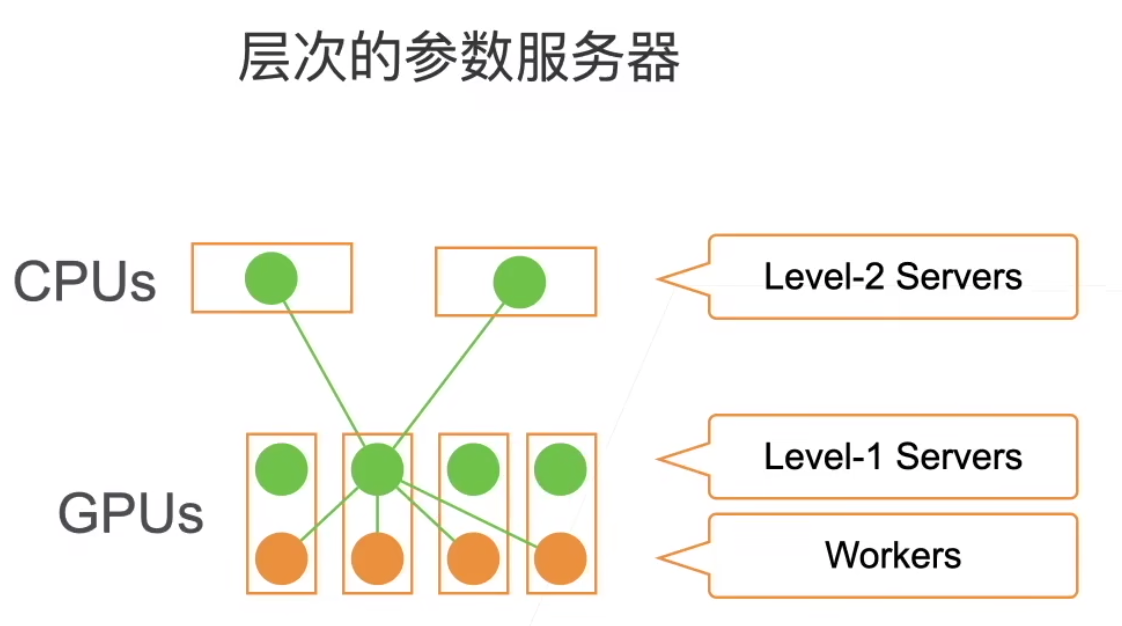
一样的,本地尽可能完成梯度更新的加和,每个服务器对梯度求和,并更新参数。
- 同步SGD
- 这里每个worker都是同步计算一 个批量,称为同步SGD
- 假设有n个GPU,每个GPU每次处理b个样本,那么同步SGD等价于在单GPU运行批量大小为nb的SGD
- 在理想情况下,n个GPU可以得到相对个单GPU的n倍加速
- 性能:
- t1=在单GPU_上计算b个样本梯度时间
- 假设有m个参数,一个worker每次发送和接收m个参数、梯度
- t2 = 发送和接收所用时间
- 每个批量的计算时间为max(t1, t2)
- 选取足够大的b使得t1 > t2(数据计算的时间 > 数据收发的时间)
- 增加b或n导致更大的批量大小,导致需要更多计算来得到给定的模型精度
- 性能的权衡:
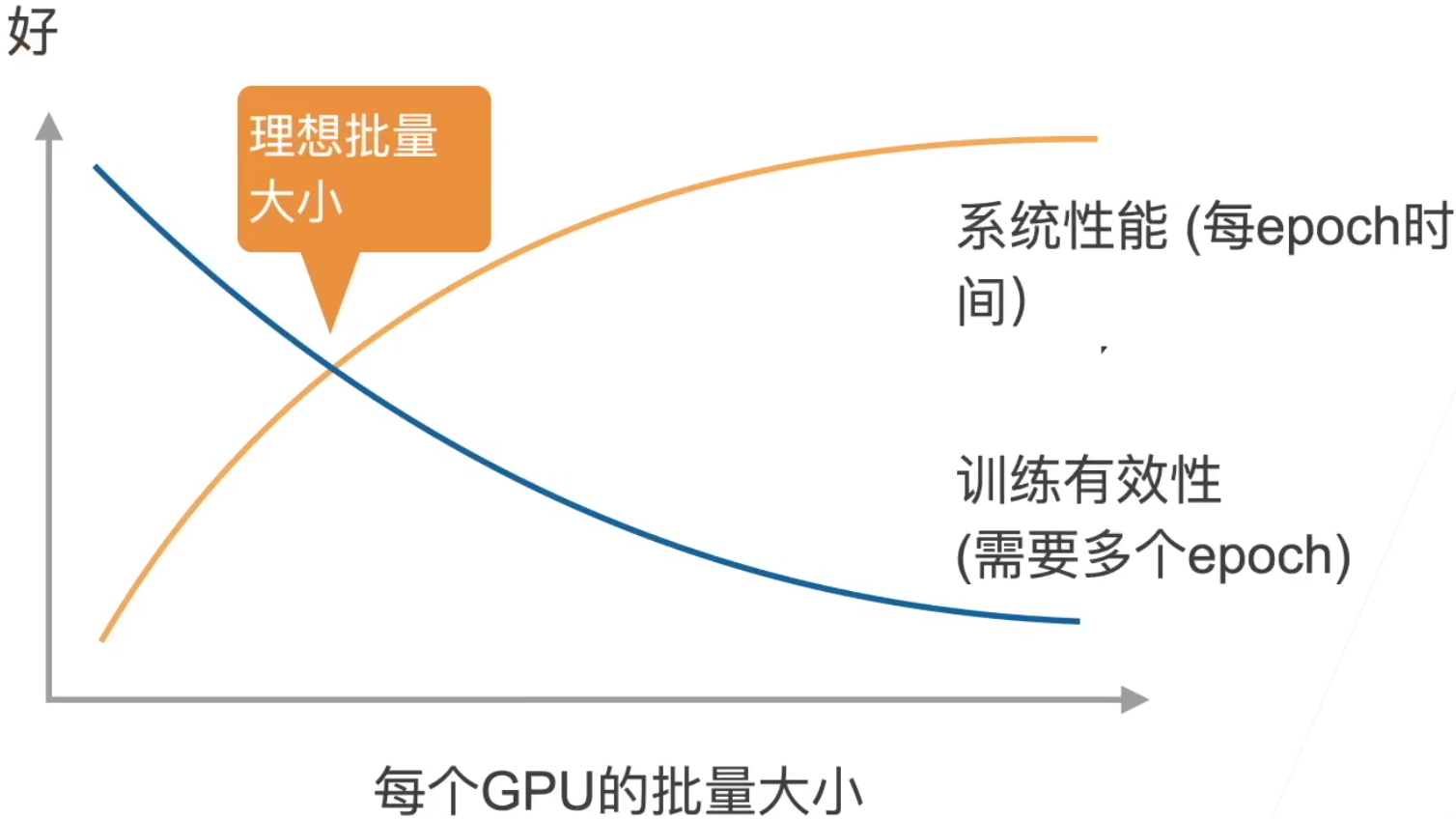
- 收敛指的是:需要多少个epoch,才能达到我们的训练精度。沐神太强了,小批量里数据多样性强,性能好。大批量数据的重复度高,对于梯度计算来说冗余,白费了计算性能。
- 我觉得是因为batchsize越大,每个epoch里的iter数越少,iter少到一定程度,导致每个epoch更新参数不到位,所以需要更多epoch才够。那要是数据足够大呢?大到后面某些step梯度都不怎么变了呢。这里的训练有效性不是从准确率上讲的,是从计算有效性上,属于计算效率。
- 样本多了,需要花更多的时间去计算梯度,收敛效率降低,我认为可以理解为达到某个精度需要的时间长了
- 实践的建议:
- 使用一个大数据集
- 需要好的GPU-GPU和机器-机器带宽
- 高效的数据读取和预处理
- 模型需要有好的计算(FLOP) 通讯(model size)
- Inception > ResNet > AlexNet
- 使用足够大的批量大小来得到好的系统性能
- 使用高效的优化算法对对应大批量大小
数据增广
- 增加一个已有的数据集,使得有更多的多样性
- 语言里面加入各种背景噪音
- 改变图片形状,色温,亮度等
- 如何使用:在线生成!从原始数据读取图片,随机进行增强,生成不一样的图片,再进行训练。只有训练的时候用,测试的时候不用昂!!
- 常见方法:
翻转

切割
- 从图片中切割一块,变形到固定形状
- 随机高宽比
- 随机大小
- 随机位置
颜色
- 色调,饱和度,明亮度
还有几十种其他方法,photoshop能干的,都能作用于图片上面!从后往前推,测试集 or 实际情况下可能遇到某些情况,我们才去对训练集做某些调整!
- 上面的很重要,讲清楚了,我们什么时候应该做数据增广,如何去做!!!不能随便做哈!!!
代码实现
- Dependency:
1 | |
- 图片增广方法:
1 | |
- 左右翻转
1 | |
- 上下翻转
1 | |
- 随机裁剪
1 | |
- 随机更改图像的亮度
1 | |
- 随机更改图像的色调
1 | |
- 随机更改图像的亮度(
brightness)、对比度(contrast)、饱和度(saturation)和色调(hue)
1 | |
- 结合多种图像增广方法
1 | |
实战
- 使用图像增广进行训练
1 | |
- 只使用最简单的随机左右翻转
1 | |
- 定义一个辅助函数,以便于读取图像和应用图像增广
1 | |
- 定义一个函数,使用多GPU对模型进行训练和评估
1 | |
- 定义
train_with_data_aug函数,使用图像增广来训练模型
1 | |
总结
- 由于样本的多样性不够!我们就需要数据增广,手动增加样本的多样性!!!增广的目的本来的就是:让训练集更加像测试集!!!要是一样就更好啦!想让训练集 cover 所有测试集中的情况or现实生活中可能出现的数据。
- 对于极度偏斜数据,也可以尝试使用重采样或者数据增广来进行数据增强!!!
- 图片增广后,数据分布大致是不改变的,但是数据多样性增加了,variance变大了。可以理解为:均值不变,方差变大了!
- mix-up增广很有效!
微调(Fine-tuning)
网络架构:
- 特征抽取将原始像素变成容易线性分割的特征(特征抽取)
- 线性分类器来做分类(Softmax回归)
预训练模型(Pretrained-Model):
- 特征抽取的部分,我们想拿来继续复用一下!
- 但是分类器我们要改成我们自己的捏!
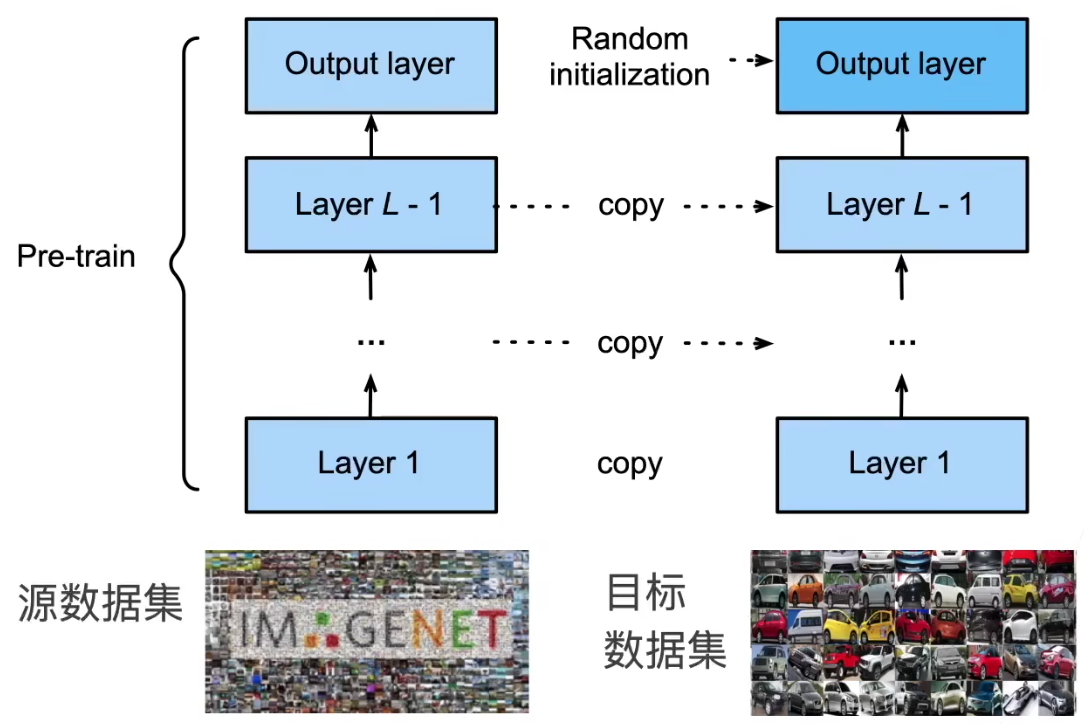
复用别人训练好的,特征提取模块!
训练:
- 是一个目标数据集上的正常训练任务,但使用更强的正则化:
- 更小的学习率
- 更少的数据迭代
- 源数据集远复杂于目标数据,通常微调效果更好
- 是一个目标数据集上的正常训练任务,但使用更强的正则化:
重用分类器权重:
- 源数据集可能也有目标数据中的部分标号
- 可以使用预训练好分类器中对应标号对应的向量来做初始化
固定一些层
- 神经网络通常学习有层次的特征表示:
- 低层次的特征更加通用
- 高层次的特征则更跟数据集相关
- 可以固定底部一些层的参数,不参与更新
- 更强的正则
- 神经网络通常学习有层次的特征表示:
别人训练好的可以直接拿来用,因此!工业界非常欢迎!
代码
- dependency
1 | |
- 数据增广
1 | |
- 定义和初始化模型:
1 | |
- 构造模型:
1 | |
- 微调模型:
1 | |
- 使用较小的学习率:
1 | |
- 为了进行比较, 所有模型参数初始化为随机值
1 | |
Tips
建议就是fine-tuning,别从头开始。一般不会有坏处,可以先试试。
但是如果我们用的数据,和pre-trained用的数据很不一样,建议从头开始捏!(先试试,不行就从头开始)
Fine-Tuning 本质上就是 Transfer Training 中的一种算法
微调对学习率不敏感,选一个比较小的学习率就行了!!!人家抽特征,最重要的部分都训练好了嘛,你就拿来用就行,改一改最后的输出层!
目标检测(Object Detection)
边缘框
用于表示物体的位置
- 边框表示方式:
- 左上x,左上y,右下x,右下y
- 左上x,左上y,宽,高
- 目标检测数据集
- 每行表示一个物体,图片文件名,物体类别,边缘框
- Coco Dataset,80物体,330k图片,1.5M物体
实现
- Dependencies
1 | |
- 表示位置
1 | |
- 定义图像中狗和猫的边界框
1 | |
- 将边界框在图中画出
1 | |
怪不得要转换,matplotlib要使用嘛!!!
数据集
目标检测的数据集没有特别好的,特别小的数据集
- 手动构造小的数据集的读入:
1 | |
- 读取香蕉检测数据集:
1 | |
- 创建一个自定义
Dataset实例
1 | |
- 为训练集和测试集返回两个数据加载器实例
1 | |
- 读取一个小批量,并打印其中的图像和标签的形状
1 | |
- 示范
1 | |
锚框(Anchor box)
目标检测算法是基于锚框
- 提出多个被锚框的区域(边缘框)
- 预测每个锚框里是否含有关注的物体
- 如果是,预测从这个锚框到真实边缘框的偏移
IoU - 交并比
- 用于计算框的相似度,0表示无重叠,1表示重合
- Jacquard指数的特殊情况:$\frac{|A\ \cap\ B|}{|A\ \cup\ B|}$
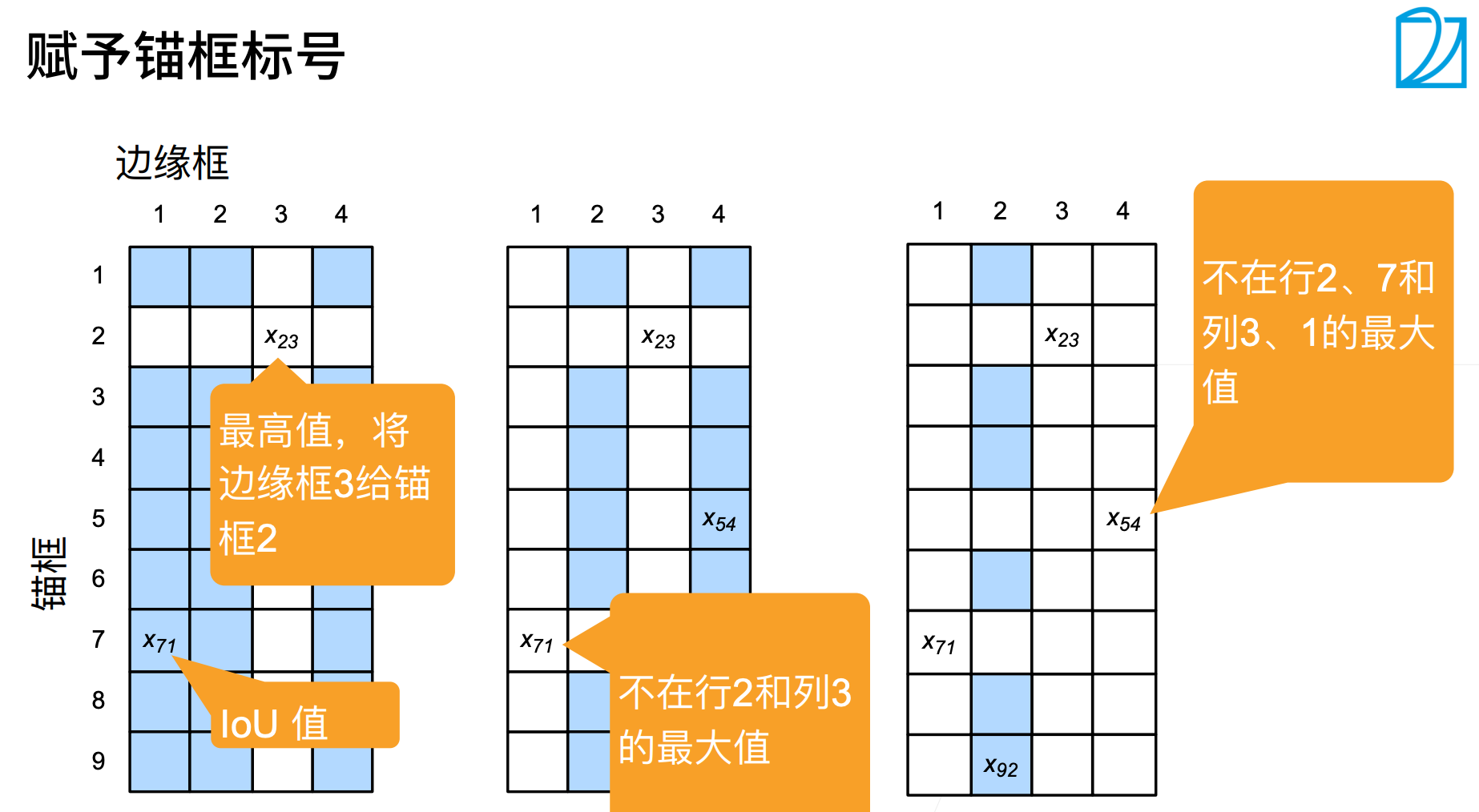
赋予锚框标号:
- 每个框是一个训练样本
- 每个框要么是背景,要么关联一个真实边缘框
- 一个算法,可能会生成大量的框,其中大多数都是背景(负类样本)
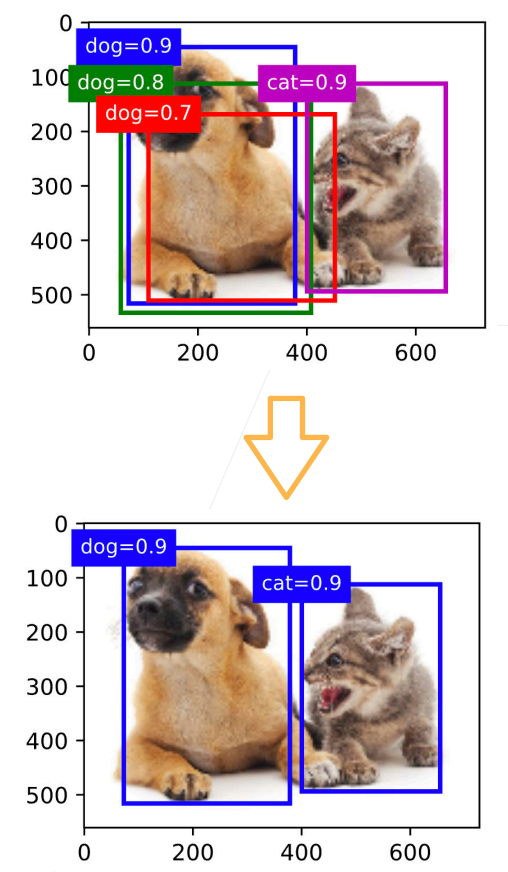
使用非极大值抑制(NMS)输出
- 每个框预测一个边缘框
- NMS可以合并相似的预测
- 选中的非背景累的最大值
- 去掉所有其它和它IoU值大于$\theta$的预测
- 重复上述过程所有预测要么被选中,要么被去掉
总结
- 一类目标检测算法基于锚框来预测
- 首先生成大量锚框,并赋予标号,每个锚框作为一个样本进行训练
- 在预测时,使用NMS来去掉冗余的预测
代码
- Dependencies:
1 | |
- 锚框的宽度和高度分别是$ws\sqrt{r}$和$ws/\sqrt{r}$,我们只考虑组合:
$$
(s_1, r_1), (s_1, r_2), \ldots, (s_1, r_m), (s_2, r_1), (s_3, r_1), \ldots, (s_n, r_1)
$$
1 | |
- 返回的锚框变量
Y的形状
1 | |
- 访问以 (250, 250) 为中心的第一个锚框
1 | |
- 显示以图像中一个像素为中心的所有锚框
1 | |
- 交并比(IoU)
1 | |
- 将真实边界框分配给锚框
1 | |
给定框A和B,中心坐标分别为$(x_a,y_a)$, 和$(x_b,y_b)$,宽度分别为$w_a$和$w_b$,高度分别为$h_a$和$h_b$。 我们可以将𝐴的偏移量标记为
$$
\left( \frac{ \frac{x_b - x_a}{w_a} - \mu_x }{\sigma_x},
\frac{ \frac{y_b - y_a}{h_a} - \mu_y }{\sigma_y},
\frac{ \log \frac{w_b}{w_a} - \mu_w }{\sigma_w},
\frac{ \log \frac{h_b}{h_a} - \mu_h }{\sigma_h}\right)
$$
1 | |
- 标记锚框的类和偏移量
1 | |
- 在图像中绘制这些地面真相边界框和锚框
1 | |
- 根据狗和猫的真实边界框,标注这些锚框的分类和偏移量
1 | |
- 应用逆偏移变换来返回预测的边界框坐标
1 | |
- 以下
nms函数按降序对置信度进行排序并返回其索引
1 | |
- 将非极大值抑制应用于预测边界框
1 | |
- 将上述算法应用到一个带有四个锚框的具体示例中
1 | |
- 在图像上绘制这些预测边界框和置信度
1 | |
- 返回结果的形状是(批量大小,锚框的数量,6)
1 | |
- 输出由非极大值抑制保存的最终预测边界框
1 | |
R-CNN
- 使用启发式算法来选择锚框
- 使用预训练模型来对每个锚框抽取特征
- 训练一个SVM来对类别分类
- 训练一个线性回归模型来预测边缘框偏移
Rol pooling
兴趣区域汇聚层(RoI pooling -> region of interest)
- 给定一个锚框,切n x m块,输出每块里面的最大值
- 不管锚框多大,总是输出nm个值

Fast R-CNN
- 使用CNN对图片抽取特征。
- 使用RoI池化层,对每个锚框生成固定长度特征

用CNN对整个图片抽取特征,在用RoI pooling抽取锚框中的特征时,Selective search找出对应位置的特征。这样就不需要和CNN一样,每个锚框分别还要RoI pooling,不再对每个锚框分别抽取特征,变得fast。
Faster R-CNN
- 使用一个区域提议网络来代替启发式搜索来获得更好的锚框。

Faster R-CNN (Ren et al., 2015)提出将选择性搜索替换为区域提议网络(region proposal network),从而减少提议区域的生成数量,并保证目标检测的精度。
- 区域提议网络的计算步骤如下:
- 使用填充为1的的卷积层变换卷积神经网络的输出,并将输出通道数记为$c$。这样,卷积神经网络为图像抽取的特征图中的每个单元均得到一个长度为$c$的新特征。
- 以特征图的每个像素为中心,生成多个不同大小和宽高比的锚框并标注它们。
- 使用锚框中心单元长度为$c$的特征,分别预测该锚框的二元类别(含目标还是背景)和边界框。
- 使用非极大值抑制,从预测类别为目标的预测边界框中移除相似的结果。最终输出的预测边界框即是兴趣区域汇聚层所需的提议区域。
区域提议网络作为Faster R-CNN模型的一部分,是和整个模型一起训练得到的。 换句话说,Faster R-CNN的目标函数不仅包括目标检测中的类别和边界框预测,还包括区域提议网络中锚框的二元类别和边界框预测。 作为端到端训练的结果,区域提议网络能够学习到如何生成高质量的提议区域,从而在减少了从数据中学习的提议区域的数量的情况下,仍保持目标检测的精度。
Mask R-CNN
- 如果在训练集中还标注了每个目标在图像上的像素级位置,那么Mask R-CNN (He et al., 2017)能够有效地利用这些详尽的标注信息进一步提升目标检测的精度。

- refer to R-CNN Behavior
R-CNN系列总结
- R-CNN是最早、最有名的一类,基于锚框和CNN的目标检测算法
- Fast/Faster R-CNN持续提高性能
- Faster R-CNN 和 Mask R-CNN是要求高精度场景下的常用算法(可能训练速度会慢一点)
SSD
Single Shot Detection,一发跑完!
- 生成锚框:
- 对每个像素,生成多个以它为中心的锚框
- 给定n个大小$s_1,\dots,s_n$和m个高框比,生成n + m - 1个锚框。
- 单发多框检测模型主要由基础网络组成,其后是几个多尺度特征块。 基本网络用于从输入图像中提取特征,因此它可以使用深度卷积神经网络。单发多框检测论文中选用了在分类层之前截断的VGG (Liu et al., 2016),现在也常用ResNet替代。 我们可以设计基础网络,使它输出的高和宽较大。 这样一来,基于该特征图生成的锚框数量较多,可以用来检测尺寸较小的目标。 接下来的每个多尺度特征块将上一层提供的特征图的高和宽缩小(如减半),并使特征图中每个单元在输入图像上的感受野变得更广阔。
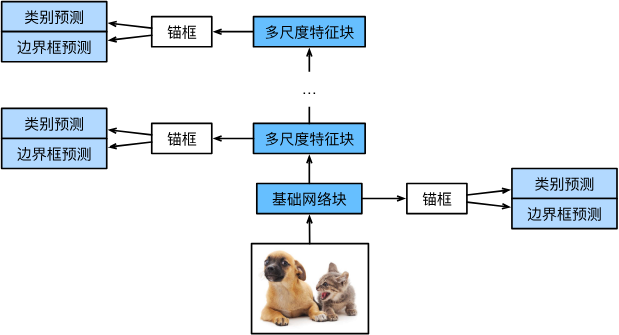
由于接近 图13.7.1顶部的多尺度特征图较小,但具有较大的感受野,它们适合检测较少但较大的物体。通过多尺度特征块,单发多框检测生成不同大小的锚框,并通过预测边界框的类别和偏移量来检测大小不同的目标,因此这是一个多尺度目标检测模型。
- 一个基础网络来抽取特征,然后多个卷积层块来减半高宽
- 在每段都生成锚框
- 底部段来拟合小物体,顶部段来拟合大物体
- 对每个锚框预测类别和边缘框
总结
- SSD通过单神经网络来检测模型
- 以每个像素为中心的产生多个锚框
- 在多个段的输出。上进行多尺度的检测
YOLO
You Only Look Once
- SSD中锚框大量重叠,浪费了很多计算
- YOLO将图片均匀分成S x S个锚框
- 每个锚框预测B个边缘框
建议看看教程
多尺度目标检测实现
这里主要是代码实现
- 依赖:
1 | |
- 在特征图 (
fmap) 上生成锚框 (anchors),每个单位(像素)作为锚框的中心
1 | |
- 探测小目标:
1 | |
- 将特征图的高度和宽度减小一半,然后使用较大的锚框来检测较大的目标
1 | |
- 将特征图的高度和宽度减小一半,然后将锚框的尺度增加到0.8
1 | |
SSD代码实现
- 依赖:
1 | |
- 特征图每个像素对应a锚框,每个锚框对应q个分类,单个像素就要a*(q+1)个预测信息,这个信息,通过卷积核的多个通道来存储, 所以这里进行卷积操作。
- 图像分类,只预测分类情况,所以接全连接层,这里单个像素的预测结果太多,就用多个通道来存。
- 边界框预测层:
1 | |
- 连接多尺度的预测:
1 | |
- 高和宽减半块:
1 | |
变换通道数,高宽减半。
- 基本网络块:
1 | |
逐步增多通道数,减少高宽捏!!!
- 完整的单发多框检测模型由五个模块组成
1 | |
- 为每个块定义前向计算
1 | |
- 超参数
1 | |
- 定义完整的模型
1 | |
- 初始化其参数并定义优化算法
1 | |
- 创建一个模型实例,然后使用它执行前向计算
1 | |
- 读取香蕉检测数据集
1 | |
- 初始化其参数并定义优化算法
1 | |
- 定义损失函数和评价函数
1 | |
- 训练模型
1 | |
- 预测目标
1 | |
- 筛选所有置信度不低于 0.9 的边界框,做为最终输出
1 | |
总结
- 总共两个损失,一个分类loss,一个回归loss。分类loss是我们对于锚框的分类造成的loss,回归loss是我们对于预测的框框和对应的边缘框框的回归loss。 -> 分别计算
- 比较的时候,我们是有个真实的Y,有个自己预测的Y。将锚框放在真实的Y上,我们就能得到这个锚框“应该”的值,然后拿我们自己预测的值,和应该的值做个对比,就能算出上面的损失来昂!!!
语义分割
给每个像素打上tag,有监督和无监督都能做,我们这是有监督的。

图像分割和实例分割
- 图像分割(image segmentation)和实例分割(instance segmentation)
- 图像分割将图像划分为若干组成区域,这类问题的方法通常利用图像中像素之间的相关性。它在训练时不需要有关图像像素的标签信息,在预测时也无法保证分割出的区域具有我们希望得到的语义。图像分割可能会将狗分为两个区域:一个覆盖以黑色为主的嘴和眼睛,另一个覆盖以黄色为主的其余部分身体。
- 实例分割也叫同时检测并分割(simultaneous detection and segmentation),它研究如何识别图像中各个目标实例的像素级区域。与语义分割不同,实例分割不仅需要区分语义,还要区分不同的目标实例。例如,如果图像中有两条狗,则实例分割需要区分像素属于的两条狗中的哪一条。(目标检测plus)
我们注重的第一种昂!!!
Pascal VOC2012 语义分割数据集
- Dependencies:
1 | |
- 读入所有的图片:
1 | |
- 下面我们绘制前5个输入图像及其标签。 在标签图像中,白色和黑色分别表示边框和背景,而其他颜色则对应不同的类别。
1 | |
- 接下来,我们列举RGB颜色值和类名。
1 | |
- 通过上面定义的两个常量,我们可以方便地查找标签中每个像素的类索引。 我们定义了
voc_colormap2label函数来构建从上述RGB颜色值到类别索引的映射,而voc_label_indices函数将RGB值映射到在Pascal VOC2012数据集中的类别索引。
1 | |
- 例如,在第一张样本图像中,飞机头部区域的类别索引为1,而背景索引为0。
1 | |
预处理数据
图片增广的使用,随机剪裁必须同时作用于图像和标签捏!
- 在之前的实验,我们通过再缩放图像使其符合模型的输入形状。 然而在语义分割中,这样做需要将预测的像素类别重新映射回原始尺寸的输入图像。 这样的映射可能不够精确,尤其在不同语义的分割区域。 为了避免这个问题,我们将图像裁剪为固定尺寸,而不是再缩放。 具体来说,我们使用图像增广中的随机裁剪,裁剪输入图像和标签的相同区域。
1 | |
自定义语义分割数据集类
- 我们通过继承高级API提供的
Dataset类,自定义了一个语义分割数据集类VOCSegDataset。 通过实现__getitem__函数,我们可以任意访问数据集中索引为idx的输入图像及其每个像素的类别索引。 由于数据集中有些图像的尺寸可能小于随机裁剪所指定的输出尺寸,这些样本可以通过自定义的filter函数移除掉。 此外,我们还定义了normalize_image函数,从而对输入图像的RGB三个通道的值分别做标准化。
1 | |
labels不好拉伸,不好差值,这里就不是resize,是用crop_size来进行剪裁!
读取数据集
- 我们通过自定义的
VOCSegDataset类来分别创建训练集和测试集的实例。 假设我们指定随机裁剪的输出图像的形状为320×480, 下面我们可以查看训练集和测试集所保留的样本个数。
1 | |
- 设批量大小为64,我们定义训练集的迭代器。 打印第一个小批量的形状会发现:与图像分类或目标检测不同,这里的标签是一个三维数组。
1 | |
整合所有组件
- 我们定义以下
load_data_voc函数来下载并读取Pascal VOC2012语义分割数据集。 它返回训练集和测试集的数据迭代器。
1 | |
转置卷积
本质就是卷积的逆运算,同样的卷积核、padding和stride,卷积之后,逆卷积能得到和卷积之前同样的size的矩阵。
- 卷积不会增大输入的高宽,要么不变,要么减半
- 转置卷积用于逆转下采样导致的空间尺寸减小,增大输入高宽。

卷积核为 2×2 的转置卷积。阴影部分是中间张量的一部分,也是用于计算的输入和卷积核张量元素。
基本操作
- 我们可以对输入矩阵
X和卷积核矩阵K实现基本的转置卷积运算trans_conv。
1 | |
- 转置卷积通过卷积核“广播”输入元素,从而产生大于输入的输出。我们可以构建输入张量
X和卷积核张量K从而验证上述实现输出。 此实现是基本的二维转置卷积运算。
1 | |
- 当输入
X和卷积核K都是四维张量时,我们可以使用高级API获得相同的结果。
1 | |
填充、步幅和多通道
- 与常规卷积不同,在转置卷积中,填充被应用于的输出(常规卷积将填充应用于输入)。将高和宽两侧的填充数指定为1时,转置卷积的输出中将删除第一和最后的行与列。
1 | |
老师的意思应该是转置卷积的padding是在输出上的,其效果是使输出的结果的上下减少1行、左右减少1列(padding=1的情况下);所以对比原来没有padding的结果是3X3的,现在的结果是1X1
- 步幅被指定为中间结果(输出),而不是输入。将步幅从1更改为2会增加中间张量的高和权重。

1 | |
- 对于多个输入和输出通道,转置卷积与常规卷积以相同方式运作。 假设输入有$c_i$个通道,且转置卷积为每个输入通道分配了一个$k_h\times k_w$的卷积核张量。 当指定多个输出通道时,每个输出通道将有一个$c_i\times k_h\times k_w$的卷积核。同样,如果我们将$\mathsf{X}$代入卷积层$f$来输出$\mathsf{Y}=f(\mathsf{X})$,并创建一个与$f$具有相同的超参数、但输出通道数量是$\mathsf{X}$中通道数的转置卷积层$g$,那么$g(Y)$的形状将与$\mathsf{X}$相同。 下面的示例可以解释这一点。
1 | |
与矩阵变换的联系
- 卷积:
1 | |
- kernel的卷积操作,变换为乘法操作。这样矩阵卷积,就可以简化为两个矩阵相乘:
1 | |
卷积核的卷积操作打平
W的矩阵乘法和向量化的X给出了一个长度为4的向量。 重塑它之后,可以获得与上面的原始卷积操作所得相同的结果Y:我们刚刚使用矩阵乘法实现了卷积。
1 | |
- 同样,我们可以使用矩阵乘法来实现转置卷积。 在下面的示例中,我们将上面的常规卷积2×2的输出
Y作为转置卷积的输入。 想要通过矩阵相乘来实现它:
1 | |
W.T本质上就是上面trans_conv中的卷积核,又一次解释了转置卷积。卷积核的卷积操作,和卷积核转置后的转置卷积操作,是对应的昂!!!
全连接卷积神经网络
全卷积网络(fully convolutional network,FCN)采用卷积神经网络实现了从图像像素到像素类别的变换 (Long et al., 2015)。 与我们之前在图像分类或目标检测部分介绍的卷积神经网络不同,全卷积网络将中间层特征图的高和宽变换回输入图像的尺寸:这是通过在 13.10节中引入的转置卷积(transposed convolution)实现的。
- 用转置卷积层来替换CNN最后的全连接层,来实现每个像素的预测

核心:转置卷积层可以保留图片的空间信息
构造模型
- dependencies
1 | |
- 我们使用在ImageNet数据集上预训练的ResNet-18模型来提取图像特征,并将该网络记为
pretrained_net。 ResNet-18模型的最后几层包括全局平均汇聚层和全连接层,然而全卷积网络中不需要它们。
1 | |
- 我们创建一个全卷积网络
net。 它复制了ResNet-18中大部分的预训练层,除了最后的全局平均汇聚层和最接近输出的全连接层。
1 | |
- 给定高度为320和宽度为480的输入,
net的前向传播将输入的高和宽减小至原来的1/32,即10和15。
1 | |
- 接下来使用1×1卷积层将输出通道数转换为Pascal VOC2012数据集的类数(21类)。 最后需要将特征图的高度和宽度增加32倍,从而将其变回输入图像的高和宽。
1 | |
初始化转置卷积层
- 在图像处理中,我们有时需要将图像放大,即上采样(upsampling)。 双线性插值(bilinear interpolation) 是常用的上采样方法之一,它也经常用于初始化转置卷积层。
- 为了解释双线性插值,假设给定输入图像,我们想要计算上采样输出图像上的每个像素。
- 将输出图像的坐标$(x,y)$映射到输入图像的坐标$(x’,y’)$上。 例如,根据输入与输出的尺寸之比来映射。 请注意,映射后的$x’$和$y’$是实数。
- 在输入图像上找到离坐标$(x’,y’)$最近的4个像素。
- 输出图像在坐标$(x,y)$上的像素依据输入图像上这4个像素及其与$(x’,y’)$的相对距离来计算。
1 | |
- 双线性插值的上采样实验
1 | |
- 用双线性插值的上采样初始化转置卷积层。对于1×1卷积层,我们使用Xavier初始化参数
1 | |
转置卷积初始化 = 转置卷积 + 双线性插值
- 读取数据集
1 | |
- 训练
1 | |
每个样本是个矩阵,因此取了一个均值。之前的loss都是对于一个一维的,现在是个二维的,因此mean()了一下
- 预测
1 | |
- 可视化预测的类别
1 | |
风格迁移
使用卷积神经网络,自动将一个图像中的风格应用在另一图像之上,即风格迁移(style transfer)。我们需要两张输入图像:一张是内容图像,另一张是风格图像。 我们将使用神经网络修改内容图像,使其在风格上接近风格图像(不用修改网络)

方法
- 我们希望内容一样,风格也一样

实现
- Dependencies:
1 | |
- 预处理和后处理
1 | |
preprocess: Picture -> Tensor, postprocess: Tensor -> Picture
- 抽取图像特征
1 | |
- 定义损失函数
1 | |
- 风格转移的损失函数是内容损失、风格损失和总变化损失的加权和
1 | |
- 初始化合成图像
1 | |
- 训练模型
1 | |
- 训练模型
1 | |
总结
- 我们通过前向传播(实线箭头方向)计算风格迁移的损失函数,并通过反向传播(虚线箭头方向)迭代模型参数,即不断更新合成图像。 风格迁移常用的损失函数由3部分组成:
- 内容损失使合成图像与内容图像在内容特征上接近;
- 风格损失使合成图像与风格图像在风格特征上接近;
- 全变分损失则有助于减少合成图像中的噪点。
- 我们初始化合成图像,例如将其初始化为内容图像。 该合成图像是风格迁移过程中唯一需要更新的变量,即风格迁移所需迭代的模型参数。 然后,我们选择一个预训练的卷积神经网络来抽取图像的特征,其中的模型参数在训练中无须更新。 这个深度卷积神经网络凭借多个层逐级抽取图像的特征,我们可以选择其中某些层的输出作为内容特征或风格特征。我们首先选择一张内容图像和一张风格图像。通过预训练的CNN模型,分别提取出这两张图像的内容特征和风格特征。接下来,通过调整生成图像的像素值,使得生成图像的内容特征与内容图像的内容特征相似,同时生成图像的风格特征与风格图像的风格特征相似。