D2L-1-Introduction
本文最后更新于:2 年前
起因是研究生组内需要做一些大模型相关的工作,自己进行了一些AI相关的学习。主要采用的《动手学深度学习》,Dive Into Deep Learning,版本是第二版,所有的资源都在网上有。参考链接为:https://zh-v2.d2l.ai/index.html。后续博客,主要记录所有相关的代码和配置。为了运行大模型和AI相关的环境,笔者使用硬件设备的是win11的系统,配备有4090显卡和64G的内存,硬盘为两个T,跑基本的模型是没啥问题。此外还有一台写文档的Mac,但是性能不是很行,一部分的简单学习内容和代码表现,是在Mac上完成的。
大模型估计只能fine tune了orz。先学点AI再说!!!由于之前用过一些pytorch,这里主要采用pytorch作为工具进行示例学习,尽量写的简洁,记录一下过程和结果就好。
学习框架介绍
- 知识体系框架:

涉及到了Machine Learning, Deep Learning等很多知识,吴恩达的机器学习的课程还是可以看看参考一下的昂!
环境配置
- 安装Anaconda -> Win可以下载一个安装包安装,Mac可以安装包 or homebrew。
- 使用conda创建python环境:
1 | |
- 安装深度学习框架和
d2l软件包
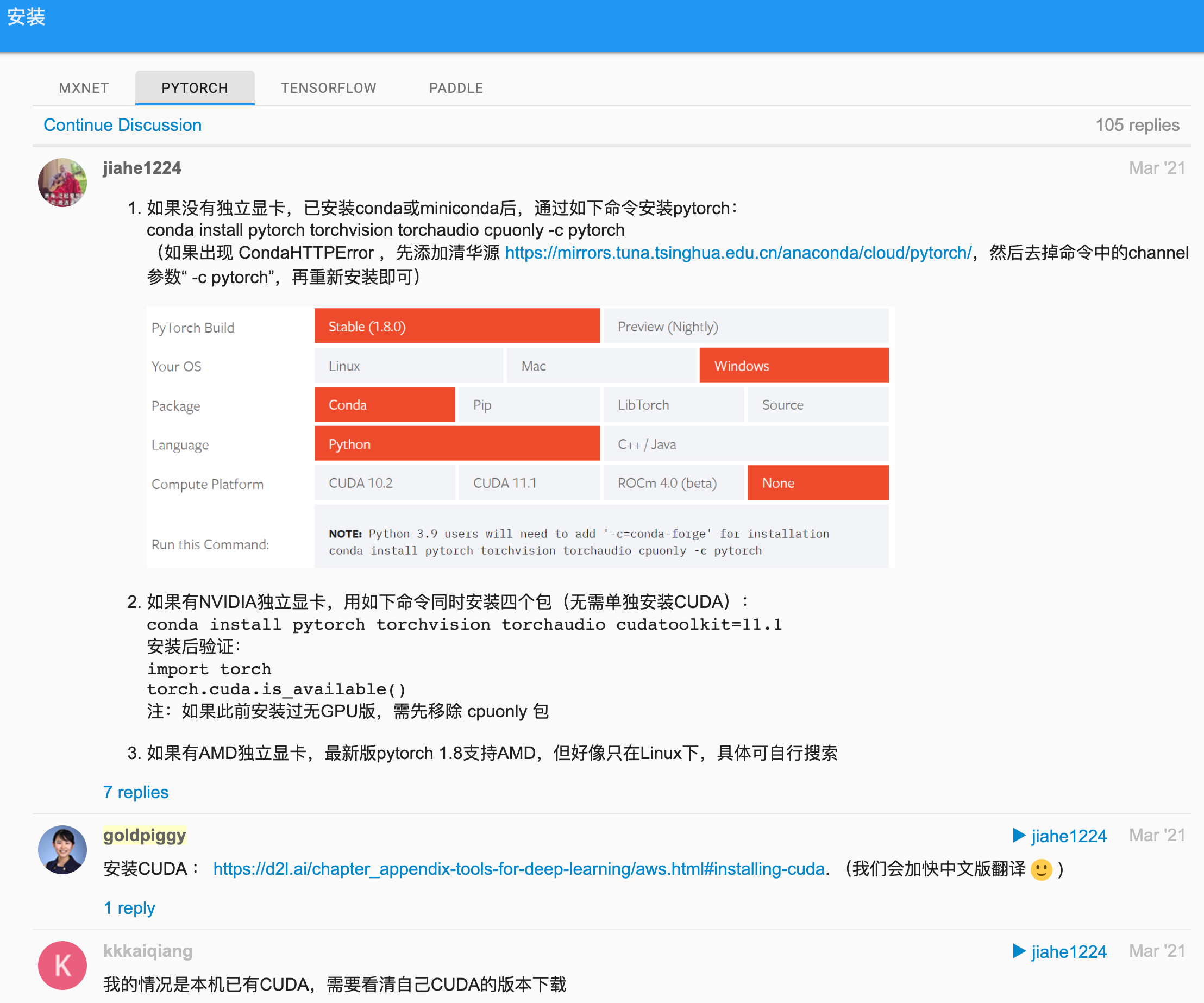
可以查看计算机是否装有NVIDIA GPU并已安装CUDA。 如果机器没有任何GPU,没有必要担心,因为CPU在前几章完全够用。 但是,如果想流畅地学习全部章节,请提早获取GPU并且安装深度学习框架的GPU版本。(这里后面我们再安装,先简单着来,Mac安装下面这些,Win11后面安装了Cuda驱动之后,再去安装torch)
1 | |
- 下载Jupyter Notebook教程:
1 | |
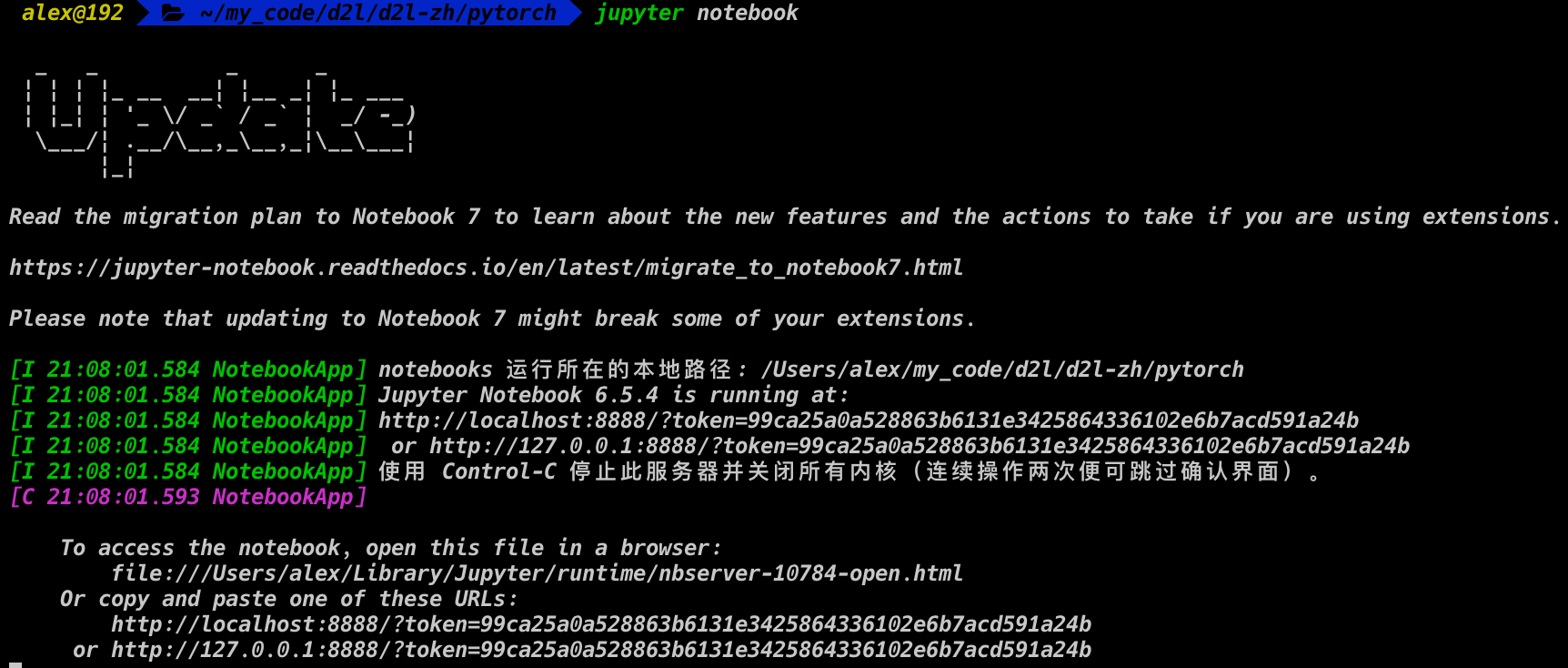
安装完成后我们可以通过运行以下命令打开Jupyter笔记本(在Window系统的命令行窗口中运行以下命令前,需先将当前路径定位到刚下载的本书代码解压后的目录):
1 | |
现在可以在Web浏览器中打开http://localhost:8888(通常会自动打开)。 由此,我们可以运行这本书中每个部分的代码。 在运行书籍代码、更新深度学习框架或d2l软件包之前,请始终执行conda activate d2l以激活运行时环境。 要退出环境,请运行conda deactivate。
- 效果:
- 关于CUDA和显卡的一些内容:
符号介绍
- 数字
$$
x: 标量 \
\mathbf{x}: 向量 \
\mathbf{X}: 矩阵 \
\mathsf{X}: 张量 \
\mathbf{I}: 单位矩阵 \
x_i, [\mathbf{x}]i: 向量x的第i个向量 \
x{ij}, [\mathbf{X}]_{ij}: 矩阵X的第i行,第j列个元素
$$
- 集合论
$$
f(\cdot): 函数 \
\log(\cdot): 自然对数 \
\exp(\cdot): 指数函数 \
\mathbf{1}_\mathcal{X}: 指示函数 \
\mathbf{(\cdot)}^\top: 向量或矩阵的转置 \
\mathbf{X}^{-1}: 矩阵的逆 \
\odot: 按元素相乘 \
[\cdot, \cdot]: 连结 \
\lvert \mathcal{X} \rvert: 集合的基数 \
|\cdot|_p: L_p正则 \
|\cdot|: L_2正则 \
\langle \mathbf{x}, \mathbf{y} \rangle: 向量x和y的点积 \
\sum: 连加 \
\prod: 连乘 \
\stackrel{\mathrm{def}}{=}: 定义
$$
- 微积分
$$
\frac{dy}{dx}: 导数 \
\frac{\partial y}{\partial x}: 偏导数 \
\nabla_{\mathbf{x}} y: 梯度 \
\int_a^b f(x) ;dx: f在x到y区间上关于x的定积分 \
\int f(x) ;dx: f关于x的不定积分
$$
- 概率与信息论
$$
P(\cdot): 概率分布 \
z \sim P: 随机变量z具有概率分布P\
P(X \mid Y): X\mid Y的条件概率\
p(x): 概率密度函数\
{E}{x} [f(x)]: 函数f对x的数学期望 \
X \perp Y: 随机变量X和Y是独立的 \
X \perp Y \mid Z: 随机变量X和Y在给定随机变量Z的条件下是独立的 \
\mathrm{Var}(X): 随机变量X的方差 \
\sigma_X: 随机变量X的标准差 \
\mathrm{Cov}(X, Y): 随机变量X和Y的协方差 \
\rho(X, Y): 随机变量X和Y的相关性\
H(X): 随机变量X的熵 \
D{\mathrm{KL}}(P|Q): P和Q的KL-散度\
$$
- 复杂度
$$
\mathcal{O}: 大O标记
$$
引言
机器学习的概念
- 模型中的参数可以被看作旋钮,旋钮的转动可以调整程序的行为。 任一调整参数后的程序被称为模型(model)。 通过操作参数而生成的所有不同程序(输入-输出映射)的集合称为“模型族”。 使用数据集来选择参数的元程序被称为学习算法(learning algorithm)。
- 在开始用机器学习算法解决问题之前,我们必须精确地定义问题,确定输入(input)和输出(output)的性质,并选择合适的模型族。
- 在机器学习中,学习(learning)是一个训练模型的过程。 通过这个过程,我们可以发现正确的参数集,从而使模型强制执行所需的行为。 换句话说,我们用数据训练(train)模型。

- 模型训练的过程:
- 从一个随机初始化参数的模型开始,这个模型基本没有“智能”;
- 获取一些数据样本(例如,音频片段以及对应的是或否标签);
- 调整参数,使模型在这些样本中表现得更好;
- 重复第(2)步和第(3)步,直到模型在任务中的表现令人满意。
通过用数据集来确定程序行为”的方法可以被看作用数据编程(programming with data)
机器学习中的关键组件
- 组件包括:
- 可以用来学习的数据(data);
- 如何转换数据的模型(model);
- 一个目标函数(objective function),用来量化模型的有效性;
- 调整模型参数以优化目标函数的算法(algorithm)
数据
- 每个数据集由一个个样本(example, sample)组成,大多时候,它们遵循独立同分布(independently and identically distributed, i.i.d.)。 样本有时也叫做数据点(data point)或者数据实例(data instance),通常每个样本由一组称为特征(features,或协变量(covariates))的属性组成。机器学习模型会根据这些属性进行预测。 在上面的监督学习问题中,要预测的是一个特殊的属性,它被称为标签(label,或目标(target))。
- 当每个样本的特征类别数量都是相同的时候,其特征向量是固定长度的,这个长度被称为数据的维数(dimensionality)。 固定长度的特征向量是一个方便的属性,它可以用来量化学习大量样本。然而,并不是所有的数据都可以用“固定长度”的向量表示。例如文本和图片不容易满足固定长度的条件(裁剪可以,但是会丢失信息),与传统机器学习方法相比,深度学习的一个主要优势是可以处理不同长度的数据。
- 一般来说,拥有越多数据的时候,工作就越容易。 更多的数据可以被用来训练出更强大的模型,从而减少对预先设想假设的依赖。 数据集的由小变大为现代深度学习的成功奠定基础。 在没有大数据集的情况下,许多令人兴奋的深度学习模型黯然失色。 就算一些深度学习模型在小数据集上能够工作,但其效能并不比传统方法高。
- 仅仅拥有海量的数据是不够的,我们还需要正确的数据。 如果数据中充满了错误,或者如果数据的特征不能预测任务目标,那么模型很可能无效。垃圾数据无用(“Garbage in, garbage out.”),数据不均衡也会产生问题。再比如,当数据不具有充分代表性,甚至包含了一些社会偏见时,模型就很有可能有偏见。
模型
- 深度学习与经典方法的区别主要在于:前者关注的功能强大的模型,这些模型由神经网络错综复杂的交织在一起,包含层层数据转换,因此被称为深度学习(deep learning)。 在讨论深度模型的过程中,本书也将提及一些传统方法。
目标函数
- 什么才算真正的提高呢? 在机器学习中,我们需要定义模型的优劣程度的度量,这个度量在大多数情况是“可优化”的,这被称之为目标函数(objective function)。 我们通常定义一个目标函数,并希望优化它到最低点。 因为越低越好,所以这些函数有时被称为损失函数(loss function,或cost function)。 但这只是一个惯例,我们也可以取一个新的函数,优化到它的最高点。 这两个函数本质上是相同的,只是翻转一下符号。
- 当任务在试图预测数值时,最常见的损失函数是平方误差(squared error),即预测值与实际值之差的平方。 当试图解决分类问题时,最常见的目标函数是最小化错误率,即预测与实际情况不符的样本比例。 有些目标函数(如平方误差)很容易被优化,有些目标(如错误率)由于不可微性或其他复杂性难以直接优化。 在这些情况下,通常会优化替代目标。
- 通常,损失函数是根据模型参数定义的,并取决于数据集。 在一个数据集上,我们可以通过最小化总损失来学习模型参数的最佳值。 该数据集由一些为训练而收集的样本组成,称为训练数据集(training dataset,或称为训练集(training set))。 然而,在训练数据上表现良好的模型,并不一定在“新数据集”上有同样的性能,这里的“新数据集”通常称为测试数据集(test dataset,或称为测试集(test set))。
- 可用数据集通常可以分成两部分:训练数据集用于拟合模型参数,测试数据集用于评估拟合的模型。 然后我们观察模型在这两部分数据集的性能。测试性能可能会显著偏离训练性能。 当一个模型在训练集上表现良好,但不能推广到测试集时,这个模型被称为过拟合(overfitting)的。
优化算法
- 当我们获得了一些数据源及其表示、一个模型和一个合适的损失函数,接下来就需要一种算法,它能够搜索出最佳参数,以最小化损失函数。 深度学习中,大多流行的优化算法通常基于一种基本方法–梯度下降(gradient descent)。 简而言之,在每个步骤中,梯度下降法都会检查每个参数,看看如果仅对该参数进行少量变动,训练集损失会朝哪个方向移动。 然后,它在可以减少损失的方向上优化参数。
各种机器学习问题
监督学习
- 监督学习(supervised learning)擅长在“给定输入特征”的情况下预测标签。 每个“特征-标签”对都称为一个样本(example)。 有时,即使标签是未知的,样本也可以指代输入特征。 我们的目标是生成一个模型,能够将任何输入特征映射到标签(即预测)。
- 监督学习之所以能发挥作用,是因为在训练参数时,我们为模型提供了一个数据集,其中每个样本都有真实的标签。 用概率论术语来说,我们希望预测“估计给定输入特征的标签”的条件概率。 虽然监督学习只是几大类机器学习问题之一,但是在工业中,大部分机器学习的成功应用都使用了监督学习。 这是因为在一定程度上,许多重要的任务可以清晰地描述为,在给定一组特定的可用数据的情况下,估计未知事物的概率。

- 监督学习的学习过程一般可以分为三大步骤:
- 从已知大量数据样本中随机选取一个子集,为每个样本获取真实标签。有时,这些样本已有标签;有时,这些样本可能需要被人工标记。这些输入和相应的标签一起构成了训练数据集;
- 选择有监督的学习算法,它将训练数据集作为输入,并输出一个“已完成学习的模型”;
- 将之前没有见过的样本特征放到这个“已完成学习的模型”中,使用模型的输出作为相应标签的预测。
即使使用简单的描述给定输入特征的预测标签,监督学习也可以采取多种形式的模型,并且需要大量不同的建模决策,这取决于输入和输出的类型、大小和数量。 例如,我们使用不同的模型来处理“任意长度的序列”或“固定长度的序列”。
回归模型
- 回归(regression)是最简单的监督学习任务之一。当标签取任意数值时,我们称之为回归问题,此时的目标是生成一个模型,使它的预测非常接近实际标签值。比如,预测用户对一部电影的评分可以被归类为一个回归问题。 再比如,预测病人在医院的住院时间也是一个回归问题。 总而言之,判断回归问题的一个很好的经验法则是,任何有关“有多少”的问题很可能就是回归问题。
分类模型
- 这种“哪一个”的问题叫做分类(classification)问题。 分类问题希望模型能够预测样本属于哪个类别(category,正式称为类(class))。 例如,手写数字可能有10类,标签被设置为数字0~9。 最简单的分类问题是只有两类,这被称之为二项分类(binomial classification)。当有两个以上的类别时,我们把这个问题称为多项分类(multiclass classification)问题。
- 分类可能变得比二项分类、多项分类复杂得多。 例如,有一些分类任务的变体可以用于寻找层次结构,层次结构假定在许多类之间存在某种关系。 因此,并不是所有的错误都是均等的。 人们宁愿错误地分入一个相关的类别,也不愿错误地分入一个遥远的类别,这通常被称为层次分类(hierarchical classification)。 (例如毒蘑菇的概率,但是我们关注的是死亡的概率)。 层次结构相关性可能取决于模型的使用者计划如何使用模型。
标记问题
有些分类问题很适合于二项分类或多项分类。很多问题将其视为分类问题可能没有多大意义。 取而代之,我们可能想让模型描绘输入图像的内容(例如一只猫、一只公鸡、一只狗,还有一头驴)。
学习预测不相互排斥的类别的问题称为多标签分类(multi-label classification)。 举个例子,人们在技术博客上贴的标签,比如“机器学习”“技术”“小工具”“编程语言”“Linux”“云计算”“AWS”。 一篇典型的文章可能会用5~10个标签,因为这些概念是相互关联的。
搜索
- 有时,我们不仅仅希望输出一个类别或一个实值。 在信息检索领域,我们希望对一组项目进行排序。 以网络搜索为例,目标不是简单的“查询(query)-网页(page)”分类,而是在海量搜索结果中找到用户最需要的那部分。 搜索结果的排序也十分重要,学习算法需要输出有序的元素子集。 即使结果集是相同的,集内的顺序有时却很重要。
- 该问题的一种可能的解决方案:首先为集合中的每个元素分配相应的相关性分数,然后检索评级最高的元素。PageRank,谷歌搜索引擎背后最初的秘密武器就是这种评分系统的早期例子,但它的奇特之处在于它不依赖于实际的查询。 在这里,他们依靠一个简单的相关性过滤来识别一组相关条目,然后根据PageRank对包含查询条件的结果进行排序。 如今,搜索引擎使用机器学习和用户行为模型来获取网页相关性得分,很多学术会议也致力于这一主题。
推荐系统
- 另一类与搜索和排名相关的问题是推荐系统(recommender system),它的目标是向特定用户进行“个性化”推荐。 例如,对于电影推荐,科幻迷和喜剧爱好者的推荐结果页面可能会有很大不同。 类似的应用也会出现在零售产品、音乐和新闻推荐等等。推荐系统会为“给定用户和物品”的匹配性打分,这个“分数”可能是估计的评级或购买的概率。 由此,对于任何给定的用户,推荐系统都可以检索得分最高的对象集,然后将其推荐给用户。以上只是简单的算法,而工业生产的推荐系统要先进得多,它会将详细的用户活动和项目特征考虑在内。 推荐系统算法经过调整,可以捕捉一个人的偏好。
- 尽管推荐系统具有巨大的应用价值,但单纯用它作为预测模型仍存在一些缺陷。 首先,我们的数据只包含“审查后的反馈”:用户更倾向于给他们感觉强烈的事物打分。此外,推荐系统有可能形成反馈循环:推荐系统首先会优先推送一个购买量较大(可能被认为更好)的商品,然而目前用户的购买习惯往往是遵循推荐算法,但学习算法并不总是考虑到这一细节,进而更频繁地被推荐。 综上所述,关于如何处理审查、激励和反馈循环的许多问题,都是重要的开放性研究问题。
序列学习
以上大多数问题都具有固定大小的输入和产生固定大小的输出。模型只会将输入作为生成输出的“原料”,而不会“记住”输入的具体内容。如果输入的样本之间没有任何关系,以上模型可能完美无缺。 但是如果输入是连续的,模型可能就需要拥有“记忆”功能。比如,在医学上序列输入和输出就更为重要。 设想一下,假设一个模型被用来监控重症监护病人,如果他们在未来24小时内死亡的风险超过某个阈值,这个模型就会发出警报。 我们绝不希望抛弃过去每小时有关病人病史的所有信息,而仅根据最近的测量结果做出预测。
序列学习需要摄取输入序列或预测输出序列,或两者兼而有之。 具体来说,输入和输出都是可变长度的序列,例如机器翻译和从语音中转录文本。 虽然不可能考虑所有类型的序列转换,但以下特殊情况值得一提。
应用场景:
标记和解析。这涉及到用属性注释文本序列。 换句话说,输入和输出的数量基本上是相同的。 例如,我们可能想知道动词和主语在哪里,或者可能想知道哪些单词是命名实体。 通常,目标是基于结构和语法假设对文本进行分解和注释,以获得一些注释。 这听起来比实际情况要复杂得多。
自动语音识别。在语音识别中,输入序列是说话人的录音,输出序列是说话人所说内容的文本记录。 它的挑战在于,与文本相比,音频帧多得多(声音通常以8kHz或16kHz采样)。 也就是说,音频和文本之间没有1:1的对应关系,因为数千个样本可能对应于一个单独的单词。 这也是“序列到序列”的学习问题,其中输出比输入短得多。
文本到语音。这与自动语音识别相反。 换句话说,输入是文本,输出是音频文件。 在这种情况下,输出比输入长得多。 虽然人类很容易识判断发音别扭的音频文件,但这对计算机来说并不是那么简单。
机器翻译。 在语音识别中,输入和输出的出现顺序基本相同。 而在机器翻译中,颠倒输入和输出的顺序非常重要。 换句话说,虽然我们仍将一个序列转换成另一个序列,但是输入和输出的数量以及相应序列的顺序大都不会相同。
无监督学习
监督学习:即需要向模型提供巨大数据集,每个样本包含特征和相应标签值。
无监督学习:数据中不含有“目标”的机器学习问题。
- 如果工作没有十分具体的目标,就需要“自发”地去学习了。 比如,老板可能会给我们一大堆数据,然后要求用它做一些数据科学研究,却没有对结果有要求。 这类数据中不含有“目标”的机器学习问题通常被为无监督学习(unsupervised learning)
- 解决的问题:
- 聚类(clustering)问题:没有标签的情况下,我们是否能给数据分类呢?比如,给定一组照片,我们能把它们分成风景照片、狗、婴儿、猫和山峰的照片吗?同样,给定一组用户的网页浏览记录,我们能否将具有相似行为的用户聚类呢?
- 主成分分析(principal component analysis)问题:我们能否找到少量的参数来准确地捕捉数据的线性相关属性?比如,一个球的运动轨迹可以用球的速度、直径和质量来描述。再比如,裁缝们已经开发出了一小部分参数,这些参数相当准确地描述了人体的形状,以适应衣服的需要。另一个例子:在欧几里得空间中是否存在一种(任意结构的)对象的表示,使其符号属性能够很好地匹配?
- 因果关系(causality)和概率图模型(probabilistic graphical models)问题:我们能否描述观察到的许多数据的根本原因?例如,如果我们有关于房价、污染、犯罪、地理位置、教育和工资的人口统计数据,我们能否简单地根据经验数据发现它们之间的关系?
- 生成对抗性网络(generative adversarial networks):为我们提供一种合成数据的方法,甚至像图像和音频这样复杂的非结构化数据。潜在的统计机制是检查真实和虚假数据是否相同的测试,它是无监督学习的另一个重要而令人兴奋的领域。
与环境互动
- 不管是监督学习还是无监督学习,我们都会预先获取大量数据,然后启动模型,不再与环境交互。 这里所有学习都是在算法与环境断开后进行的,被称为离线学习(offline learning)。 对于监督学习,从环境中收集数据的过程类似于

这种简单的离线学习有它的魅力。 好的一面是,我们可以孤立地进行模式识别,而不必分心于其他问题。 但缺点是,解决的问题相当有限。 这时我们可能会期望人工智能不仅能够做出预测,而且能够与真实环境互动。 与预测不同,“与真实环境互动”实际上会影响环境。 这里的人工智能是“智能代理”,而不仅是“预测模型”。 因此,我们必须考虑到它的行为可能会影响未来的观察结果。
考虑“与真实环境互动”将打开一整套新的建模问题。以下只是几个例子。
环境还记得我们以前做过什么吗?
环境是否有助于我们建模?例如,用户将文本读入语音识别器。
环境是否想要打败模型?例如,一个对抗性的设置,如垃圾邮件过滤或玩游戏?
环境是否重要?
环境是否变化?例如,未来的数据是否总是与过去相似,还是随着时间的推移会发生变化?是自然变化还是响应我们的自动化工具而发生变化?
当训练和测试数据不同时,最后一个问题提出了分布偏移(distribution shift)的问题。
强化学习
在我看来就是模型online & offline的区别,offline的模型不更新,没有和环境的交互。online的模型会从环境持续学习更新,和环境持续交互学习。
如果你对使用机器学习开发与环境交互并采取行动感兴趣,那么最终可能会专注于强化学习(reinforcement learning)。 这可能包括应用到机器人、对话系统,甚至开发视频游戏的人工智能(AI)。 深度强化学习(deep reinforcement learning)将深度学习应用于强化学习的问题,是非常热门的研究领域。
在强化学习问题中,智能体(agent)在一系列的时间步骤上与环境交互。 在每个特定时间点,智能体从环境接收一些观察(observation),并且必须选择一个动作(action),然后通过某种机制(有时称为执行器)将其传输回环境,最后智能体从环境中获得奖励(reward)。 此后新一轮循环开始,智能体接收后续观察,并选择后续操作,依此类推。强化学习的目标是产生一个好的策略(policy)。 强化学习智能体选择的“动作”受策略控制,即一个从环境观察映射到行动的功能。

- 强化学习框架的通用性十分强大。 例如,我们可以将任何监督学习问题转化为强化学习问题。 假设我们有一个分类问题,可以创建一个强化学习智能体,每个分类对应一个“动作”。 然后,我们可以创建一个环境,该环境给予智能体的奖励。 这个奖励与原始监督学习问题的损失函数是一致的。
- 当然,强化学习还可以解决许多监督学习无法解决的问题。 例如,在监督学习中,我们总是希望输入与正确的标签相关联。 但在强化学习中,我们并不假设环境告诉智能体每个观测的最优动作。 一般来说,智能体只是得到一些奖励。 此外,环境甚至可能不会告诉是哪些行为导致了奖励。
- 强化学习者必须处理学分分配(credit assignment)问题:决定哪些行为是值得奖励的,哪些行为是需要惩罚的。 就像一个员工升职一样,这次升职很可能反映了前一年的大量的行动。 要想在未来获得更多的晋升,就需要弄清楚这一过程中哪些行为导致了晋升。
- 强化学习可能还必须处理部分可观测性问题。 也就是说,当前的观察结果可能无法阐述有关当前状态的所有信息。 比方说,一个清洁机器人发现自己被困在一个许多相同的壁橱的房子里。 推断机器人的精确位置(从而推断其状态),需要在进入壁橱之前考虑它之前的观察结果。
- 在任何时间点上,强化学习智能体可能知道一个好的策略,但可能有许多更好的策略从未尝试过的。 强化学习智能体必须不断地做出选择:是应该利用当前最好的策略,还是探索新的策略空间(放弃一些短期回报来换取知识)。
- 一般的强化学习问题是一个非常普遍的问题。 智能体的动作会影响后续的观察,而奖励只与所选的动作相对应。 环境可以是完整观察到的,也可以是部分观察到的,解释所有这些复杂性可能会对研究人员要求太高。 此外,并不是每个实际问题都表现出所有这些复杂性。 因此,学者们研究了一些特殊情况下的强化学习问题。
- 当环境可被完全观察到时,强化学习问题被称为马尔可夫决策过程(markov decision process)。 当状态不依赖于之前的操作时,我们称该问题为上下文赌博机(contextual bandit problem)。 当没有状态,只有一组最初未知回报的可用动作时,这个问题就是经典的多臂赌博机(multi-armed bandit problem)。