NJUOS-25-输入输出设备模型
本文最后更新于:1 年前
复习
- 1-Bit 的存储
- Volatile: Delay line, SRAM/DRAM
- Non-volatile: 磁 (磁芯/磁带/磁鼓/软盘/硬盘)、坑 (光盘)、电 (NAND Flash; SSD)
本次课回答的问题
- Q: 器件之上的 “设备” 到底是什么?
本次课主要内容
- 计算机与外设的接口
- 总线、中断控制器和 DMA
- GPU 和异构计算
计算机与世界的接口
孤独的 CPU
CPU 只是 “无情的指令执行机器”
- 取指令、译码、执行

Altair-8800 (1975), with Intel 8080A; 256B 板卡 RAM
(你需要在面板上手工输入执行指令的起始地址)
交互方式都不一样,要把二进制开关给拨到正确的位置昂!
从一个需求说起
如何用计算机实现核弹发射箱?
- 关键问题:如何使计算机能感知外部状态、对外实施动作?
- 我们使用的并不是计算设备,而是 I/O 设备!

I/O 设备:“计算” 和 “物理世界” 之间的桥梁
I/O 设备 (CPU 视角):“一个能与 CPU 交换数据的接口/控制器”
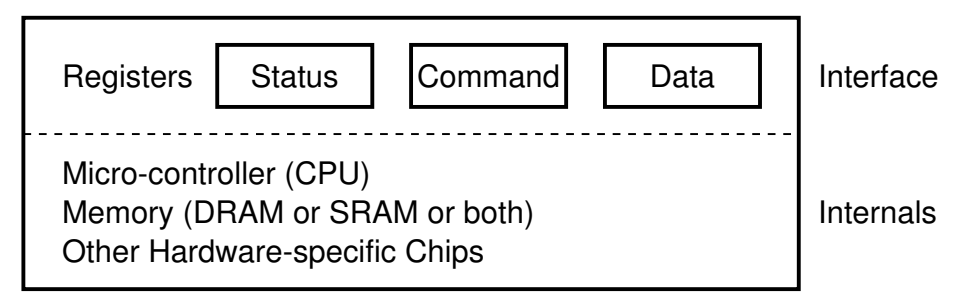
说人话
- 就是 “几组约定好功能的线” (RTFM)
- 通过握手信号从线上读出/写入数据
- 每一组线有自己的地址
- CPU 可以直接使用指令 (in/out/MMIO) 和设备交换数据
- (CPU 完全不管设备具体是如何实现的)
例子 (1): 串口 (UART)
“COM1”; putch() 的实现
1 | |
UART可进可出,就是个串口,可以便于进行IO设备和CPU中间交互的验证昂
例子 (2): 键盘控制器
IBM PC/AT 8042 PS/2 (Keyboard) Controller
- “硬编码” 到两个 I/O port:
0x60(data),0x64(status/command)
0x60是设备寄存器…
| Command Byte | Use | 说明 |
|---|---|---|
| 0xED | LED 灯控 | ScrollLock/NumLock/CapsLock |
| 0xF3 | 设置重复速度 | 30Hz - 2Hz; Delay: 250 - 1000ms |
| 0xF4/0xF5 | 打开/关闭 | N/A |
| 0xFE | 重新发送 | N/A |
| 0xFF | RESET | N/A |
参考 AbstractMachine 的键盘部分实现
真实的设备protocol是比较复杂的,可能就给你一个Manual,你自己去读吧,因此存在Bug,是挺正常的一件事儿昂!!!
例子 (3): 磁盘控制器
ATA (Advanced Technology Attachment)
- IDE (Integrated Drive Electronics) 接口磁盘
- primary:
0x1f0 - 0x1f7; secondary:0x170 - 0x177
- primary:
1 | |
本质就是很多的寄存器哇……把要读的盘块儿之类的数据放入对应的寄存器,全部写好之后,发一个R/W的命令,就可以完成R/W。
IO有专门的文档昂!!!驱动程序如果实现了对应的接口文档,就可以兼容这台机器,插入对应的机器就可以使用昂!
例子 (4): 打印机

打印机:将字节流描述的文字/图形打印到纸张上
- 可简单 (打字机)
- 可复杂 (编程语言描述的图形)
- 高清全页图片的传输是很大的挑战
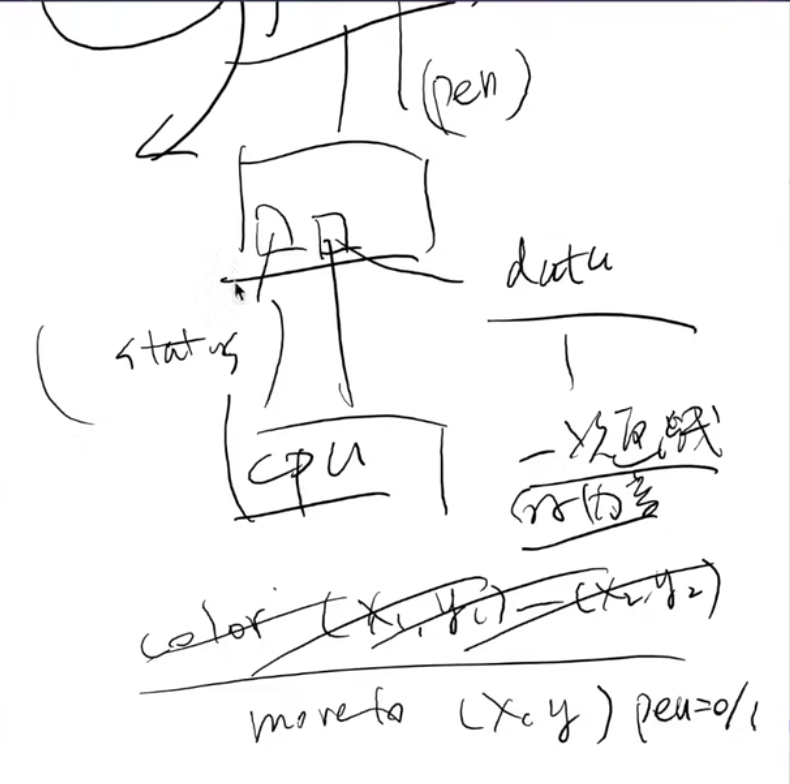
例如两个寄存器,一个是data,一个是status,CPU每次把对应的指令,放入status和data,就可以完成对于🖨️的操作了嘛!!!
例子:PostScript (1984)
- 一种描述页面布局的 domain-specific language
- 类似于汇编语言
- 可以用 “编译器” (例如 latex) 创建高质量的文稿
- PDF 是它的 superset (page.ps)
- 打印机是另一个带 CPU 的设备
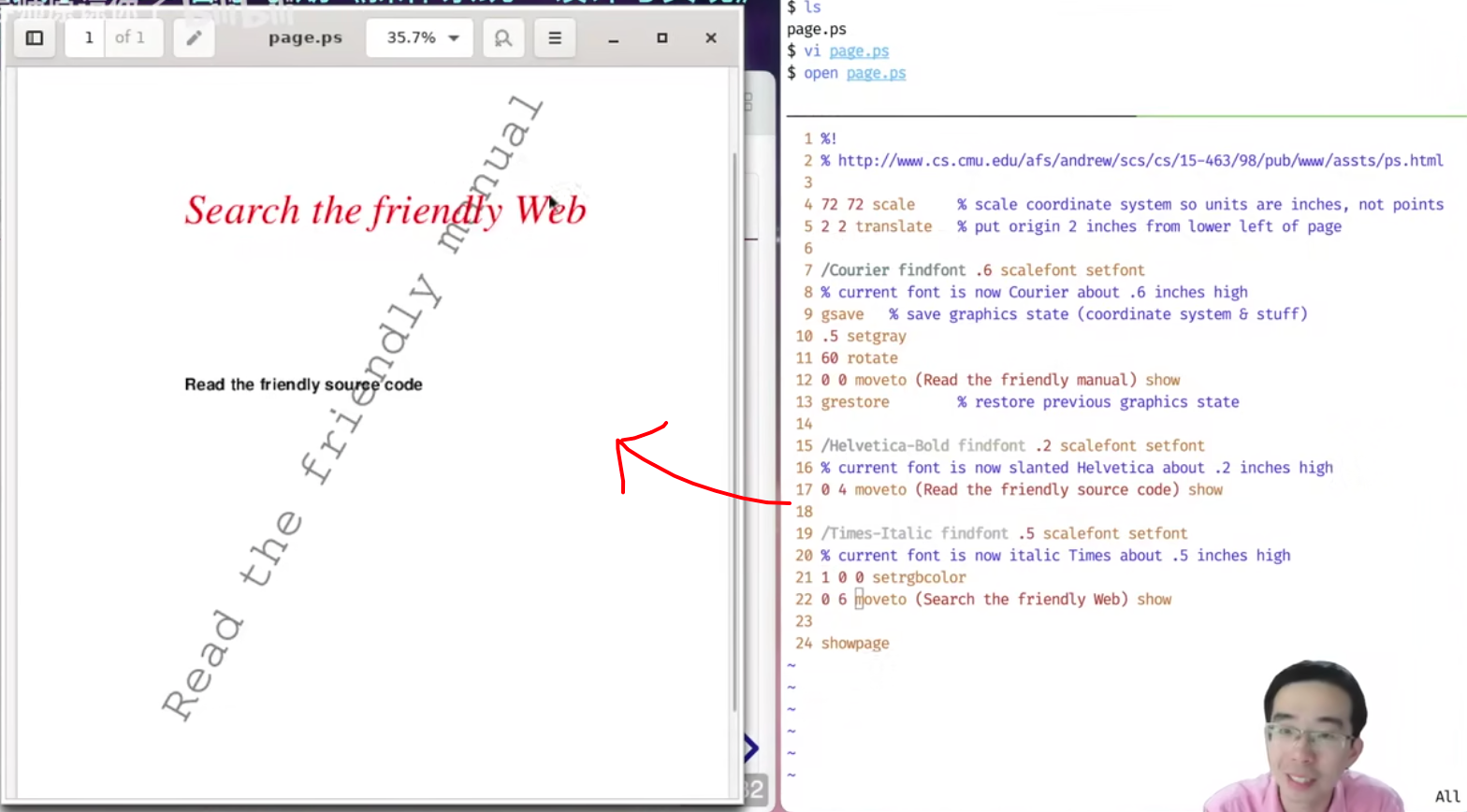
1980年就能,写好代码,编译好,就能打印出高质量矢量图形!!!(怎么感觉这个过程有点像C orz)
总线、中断控制器和 DMA
越来越多的 I/O 设备
如果你只造 “一台计算机”
- 随便给每个设备定一个端口/地址,用 mux 连接到 CPU 就行
- 你们的实验 (AbstractMachine) 和自制 CPU 就是这么做的
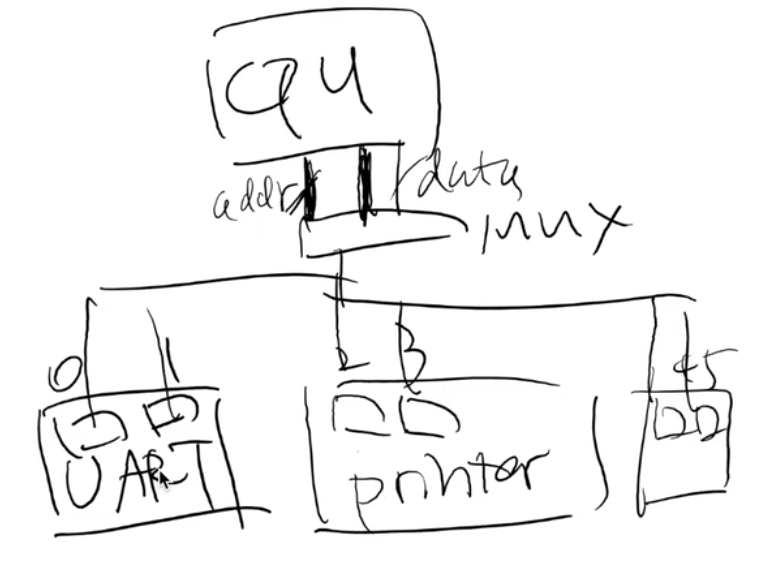
固定死了,每个寄存器和规定的交互,非常有限!!!打咩!!!这是一个开放的世界昂!!!
 但如果你希望给未来留点空间?
但如果你希望给未来留点空间?
- 想卖大价钱的 “大型机”
- IBM, DEC, …
- 车库里造出来的 “微型机”
- 名垂青史的梦想家
- 都希望接入更多 I/O 设备
- 甚至是未知的设备,但不希望改变 CPU?
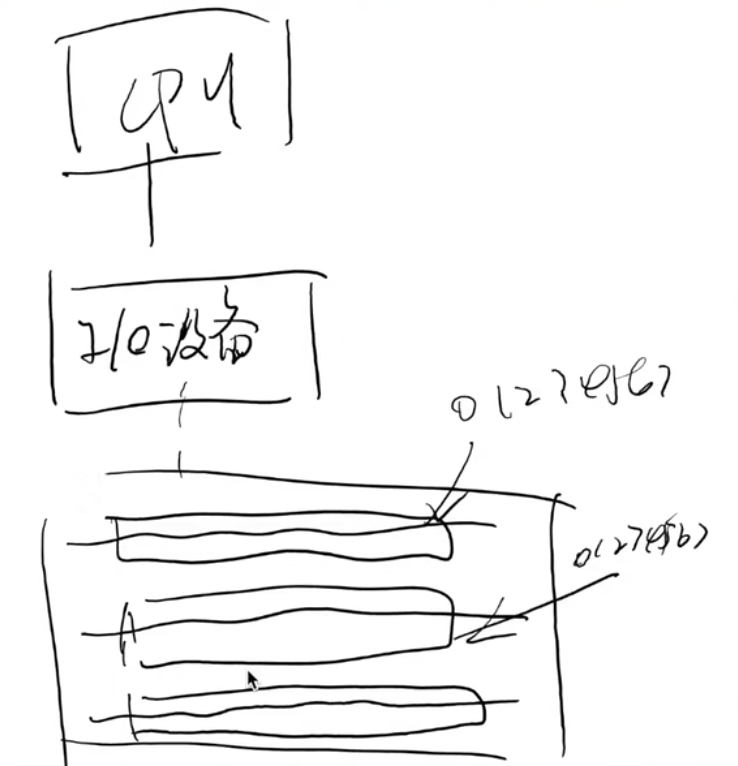
插槽,可拓展性!!!这个I/O设备,是所有的I/O设备的总管。甚至内存也连上去。。。
不叫I/O设备了,叫总线。。。
总线:一个特殊的 I/O 设备
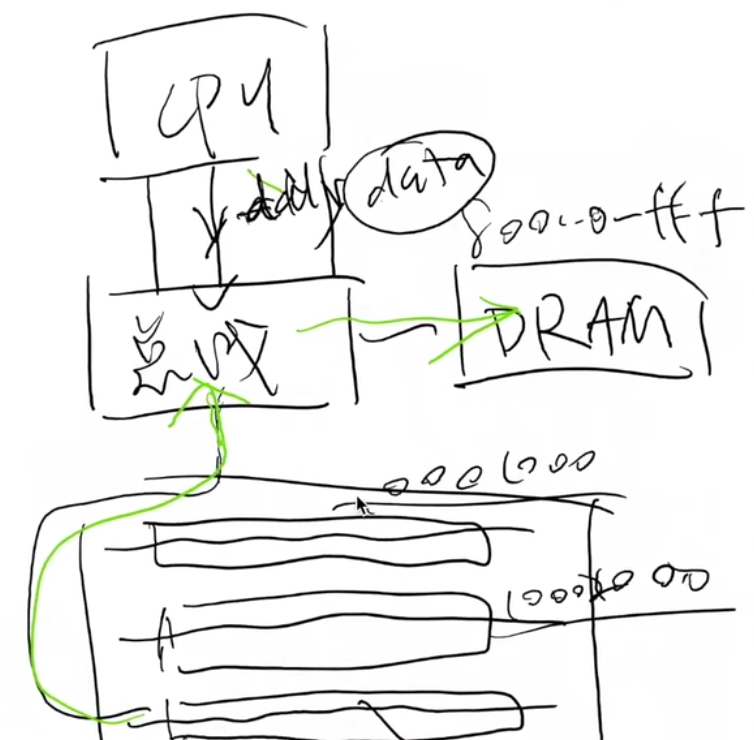
提供设备的注册和地址到设备的转发
- 把收到的地址 (总线地址) 和数据转发到相应的设备上
- 例子: port I/O 的端口就是总线上的地址
- IBM PC 的 CPU 其实只看到这一个 I/O 设备
这样 CPU 只需要直连一个总线 就行了!
- 今天 PCI 总线肩负了这个任务
- 总线可以桥接其他总线 (例如 PCI → USB)
- lspci -tv和lsusb -tv: 查看系统中总线上的设备
- 概念简单,实际非常复杂……
- 电气特性、burst 传输、中断、[Plug and Play](http://jyywiki.cn/OS/2022/slides/Windows 蓝屏)……
- 概念简单,实际非常复杂……
例子:PCI Device Probe
pci-probe.c (AbstractMachine, x86-64/i386)
- 试着给 QEMU 增加
-soundhw ac97的运行选项
1 | |
中断控制器
CPU 有一个中断引脚
- 收到某个特定的电信号会触发中断
- 保存 5 个寄存器 (cs, rip, rflags, ss, rsp)
- 跳转到中断向量表对应项执行
系统中的其他设备可以向中断控制器连线
- Intel 8259 PIC
- programmable interrupt controller
- 可以设置中断屏蔽、中断触发等……
- APIC (Advanced PIC)
- local APIC: 中断向量表, IPI, 时钟, ……
- I/O APIC: 其他 I/O 设备
中断没能解的问题
假设程序希望写入 1 GB 的数据到磁盘
- 即便磁盘已经准备好,依然需要非常浪费缓慢的循环
- out 指令写入的是设备缓冲区,需要去总线上绕一圈
- cache disable; store 其实很慢的
1 | |
能否把 CPU 从执行循环中解放出来?
- 比如,在系统里征用一个小 CPU,专门复制数据?
- 好像
memcpy_to_port(ATA0, buf, length);
Direct Memory Access (DMA)
DMA: 一个专门执行 “memcpy” 程序的 CPU
- 加一个通用处理器太浪费,不如加一个简单的
支持的几种 memcpy
- memory → memory
- memory → device (register)
- device (register) → memory
- 实际实现:直接把 DMA 控制器连接在总线和内存上
- Intel 8237A
PCI 总线支持 DMA
- 干了非常多的脏事
GPU 和异构计算
I/O 设备和计算机之间的边界逐渐模糊
DMA 不就是一个 “做一件特别事情” 的 CPU 吗
- 那么我们还可以有做各种事情的 “CPU” 啊
例如,显示图形
1 | |
难办的是性能:NES: 6502 @ 1.79Mhz; IPC = 0.43
- 屏幕共有 256 x 240 = 61K 像素 (256 色)
- 60FPS → 每一帧必须在 ~10K 条指令内完成
- 如何在有限的 CPU 运算力下实现 60Hz?
CPU跟不上图形!!!
像DMA一样!!!DMA在CPU上增加了一个新的”CPU”,帮忙搬运。那能不能来一个新的“CPU”,专门帮忙画图呢???
NES Picture Processing Unit (PPU)

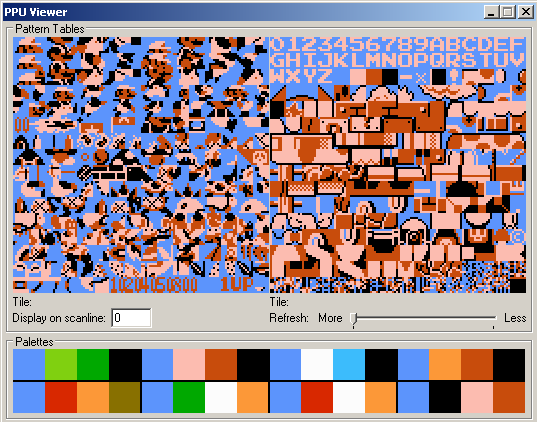
1 | |
CPU 只描述 8x8 “贴块” 的摆放方法
- 背景是 “大图” 的一部分
- 每行的前景块不超过 8 个
- PPU 完成图形的绘制
- 一个更简单的 “CPU”
在受限的机能下提供丰富的图形
前景:《魂斗罗》(Contra)中角色为什么要「萝莉式屈腿俯卧」?

背景:“卷轴” 操作

更好的 2D 游戏引擎
如果我们有更多的晶体管?
- NES PPU 的本质是和坐标轴平行的 “贴块块”
- 实现上只需要加法和位运算
- 更强大的计算能力 = 更复杂的图形绘制
2D 图形加速硬件:图片的 “裁剪” + “拼贴”
- 支持旋转、材质映射 (缩放)、后处理、……
实现 3D
- 三维空间中的多边形,在视平面上也是多边形
- Thm. 任何n边形都可以分解成n−2个三角形
以假乱真的剪贴 3D
GameBoy Advance
- 4 层背景; 128 个剪贴 objects; 32 个 affine objects
- CPU 给出描述;GPU 绘制 (执行 “一个程序” 的 CPU)

(V-Rally; Game Boy Advance, 2002)
但我们还是需要真正的 3D
三维空间中的三角形需要正确渲染
- 这时候建模的东西就多了
- 几何、材质、贴图、光源、……
- Rendering pipeline 里大部分操作都是 massive parallel 的

“Perspective correct” texture mapping (Wikipedia)
题外话:如此丰富的图形是怎么来的?

答案:全靠 PS (后处理)
例子:GLSL (Shading Language)
- 使 “shader program” 可以在 GPU 上执行
- 可以作用在各个渲染级别上:vertex, fragment, pixel shader
- 相当于一个 “PS” 程序,算出每个部分的光照变化
- 全局光照、反射、阴影、环境光遮罩……

现代 GPU: 一个通用计算设备
一个完整的众核多处理器系统
- 注重大量并行相似的任务
- 程序使用例如 OpenGL, CUDA, OpenCL, … 书写
- 程序保存在内存 (显存) 中
- nvcc (LLVM) 分两个部分
- main 编译/链接成本地可执行的 ELF
- kernel 编译成 GPU 指令 (送给驱动)
- nvcc (LLVM) 分两个部分
- 数据也保存在内存 (显存) 中
- 可以输出到视频接口 (DP, HDMI, …)
- 也可以通过 DMA 传回系统内存
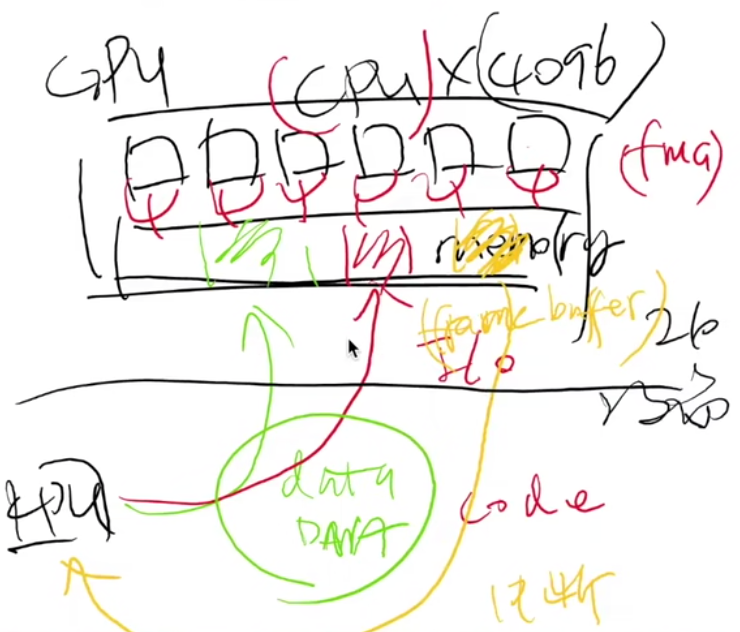
GPU既是I/O设备,其实也是另外一台计算机!!!
例子:PyTorch 和炼丹炉
什么是 “深度神经网络”?
如何 “训练”?
- 大量计算密集型的任务
1 | |
Dark Silicon Age 和异构计算
能完成 “同一件事” 的部件可能有很多
- 要选择功耗/性能/时间最合适的那个!

- CPU, GPU, NPU, DSP, DSM/RDMA
- 甚至可以丢到另一台计算机上执行:COMET: Code offload by migrating execution transparently (OSDI’12)
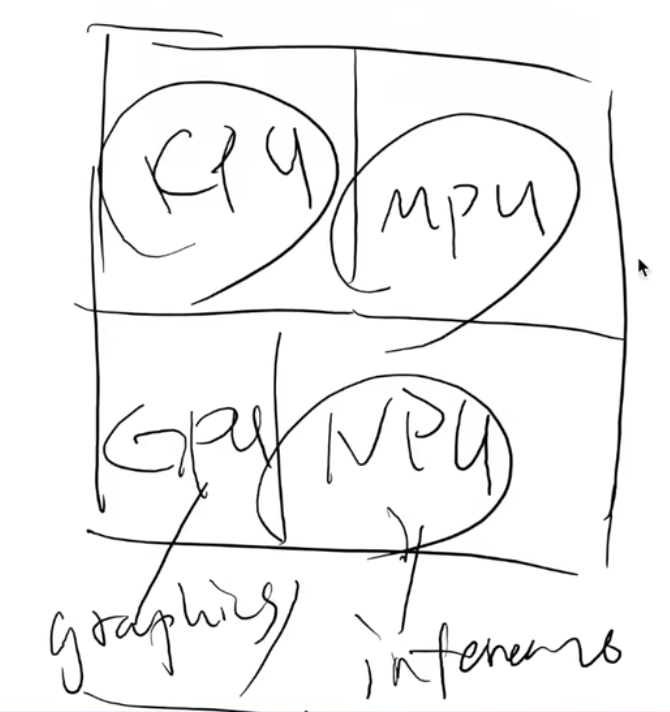
IO设备 -> 异构计算
总结
本次课回答的问题
- Q: 到底什么是输入输出设备?

Take-away messages
- I/O 设备 (控制器):一组交换数据的接口和协议
- Simply, RTFM & RTFSC
- 如果你 “自己造一台计算机”,你会发现这一切都是自然的
- “不容易理解” 的部分是随时间积累的复杂性