本文最后更新于:2 年前
JYY就是我的男神!这一堂课开始逐渐接触多进程,多线程的概念了。
多线程视角
全局变量 + Heap -> Global变量
Stack -> 私有变量
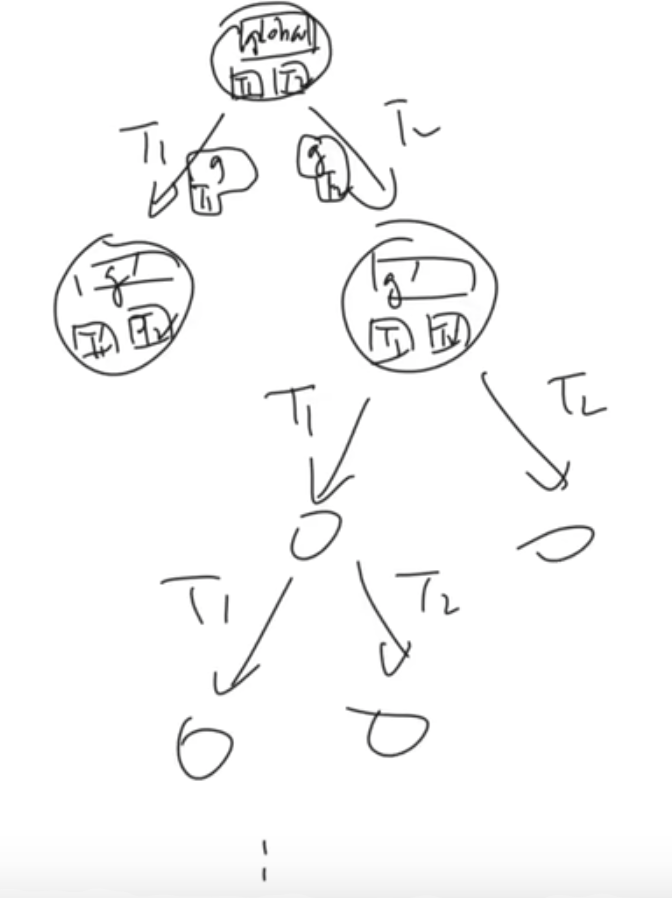
Stack是每一个线程私有的,Heap和全局变量是各个线程共享的。 -> 每一个状态,相当于选定 全局状态 + 执行的线程的私有状态(局部状态) ,进行执行,并得到结果。
由于并发程序是并发执行的,具有不确定性。导致状态机从一个链表,变成了一棵多叉树,复杂度飙升!!!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #include <stdlib.h> #include <stdio.h> #include <string.h> #include <stdatomic.h> #include <assert.h> #include <unistd.h> #include <pthread.h> #define NTHREAD 64 enum { T_FREE = 0 , T_LIVE, T_DEAD, };struct thread {int id, status;pthread_t thread;void (*entry)(int );struct thread tpool[NTHREAD], *tptr = tpool;void *wrapper (void *arg) struct thread *thread = (struct thread *)arg;entry (thread->id);return NULL ;void create (void *fn) assert (tptr - tpool < NTHREAD);struct thread) {1 ,pthread_create (&(tptr->thread), NULL , wrapper, tptr);void join () for (int i = 0 ; i < NTHREAD; i++) {struct thread *t = &tpool[i];if (t->status == T_LIVE) {pthread_join (t->thread, NULL );void cleanup () join ();
she-test.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include "thread.h" int x = 0 ;void Thello (int id) {100000 );printf ("Hello from thread #%c\n" , "123456789ABCDEF" [x++]);int main () {for (int i = 0 ; i < 10 ; i++) {
stack-probe.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include "thread.h" char *base, *cur; int id;void set_cur (void *ptr) { cur = ptr; }char *get_cur () { return cur; }void stackoverflow (int n) {if (n % 1024 == 0 ) {int sz = base - get_cur();printf ("Stack size of T%d >= %d KB\n" , id, sz / 1024 );1 );void Tprobe (int tid) {void *)&tid;0 );int main () {stdout , NULL );for (int i = 0 ; i < 4 ; i++) {
提出疑问:这个大小为啥是这样?能否手动设置,使用呢?
多线程特性 原子性
常见假设:当前程序独占处理器执行(根本不成立啊…)
为什么经典的i++类似的并行会出问题,但是,printf,不会打印到一半,突然暴毙?
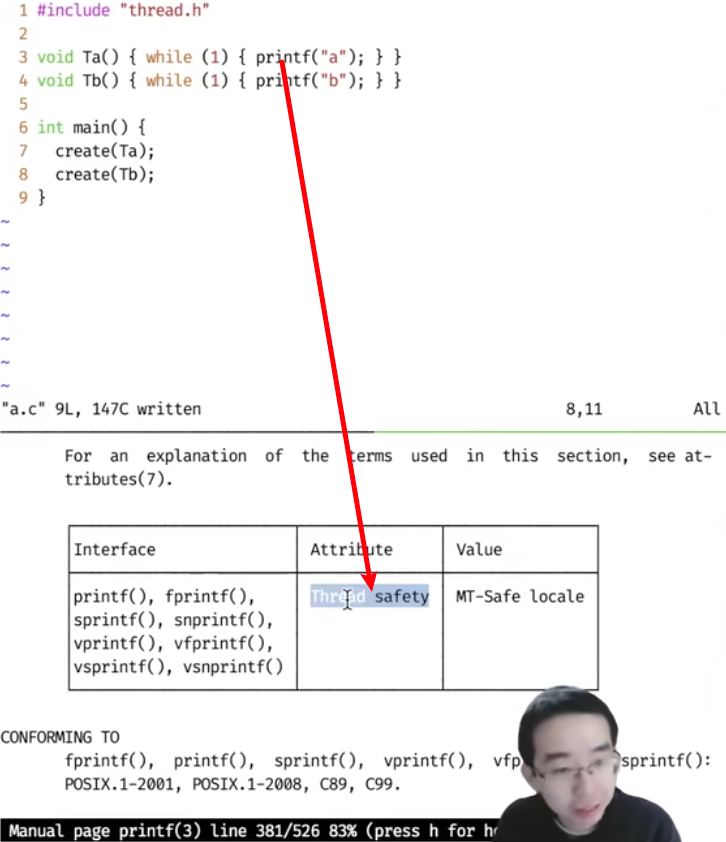
1 2 3 4 5 6 7 void Ta () {while (1 ){printf ("aaaaa" )}};void Tb () {while (1 ){printf ("bbb" )}};int main () {
man 3 printf -> / thread(搜索和thread相关的)
发现系统库早就考虑了昂!!!
字符串没有相互交集,可以自己测的。去查手册验证,确实printf是线程安全的。
顺序
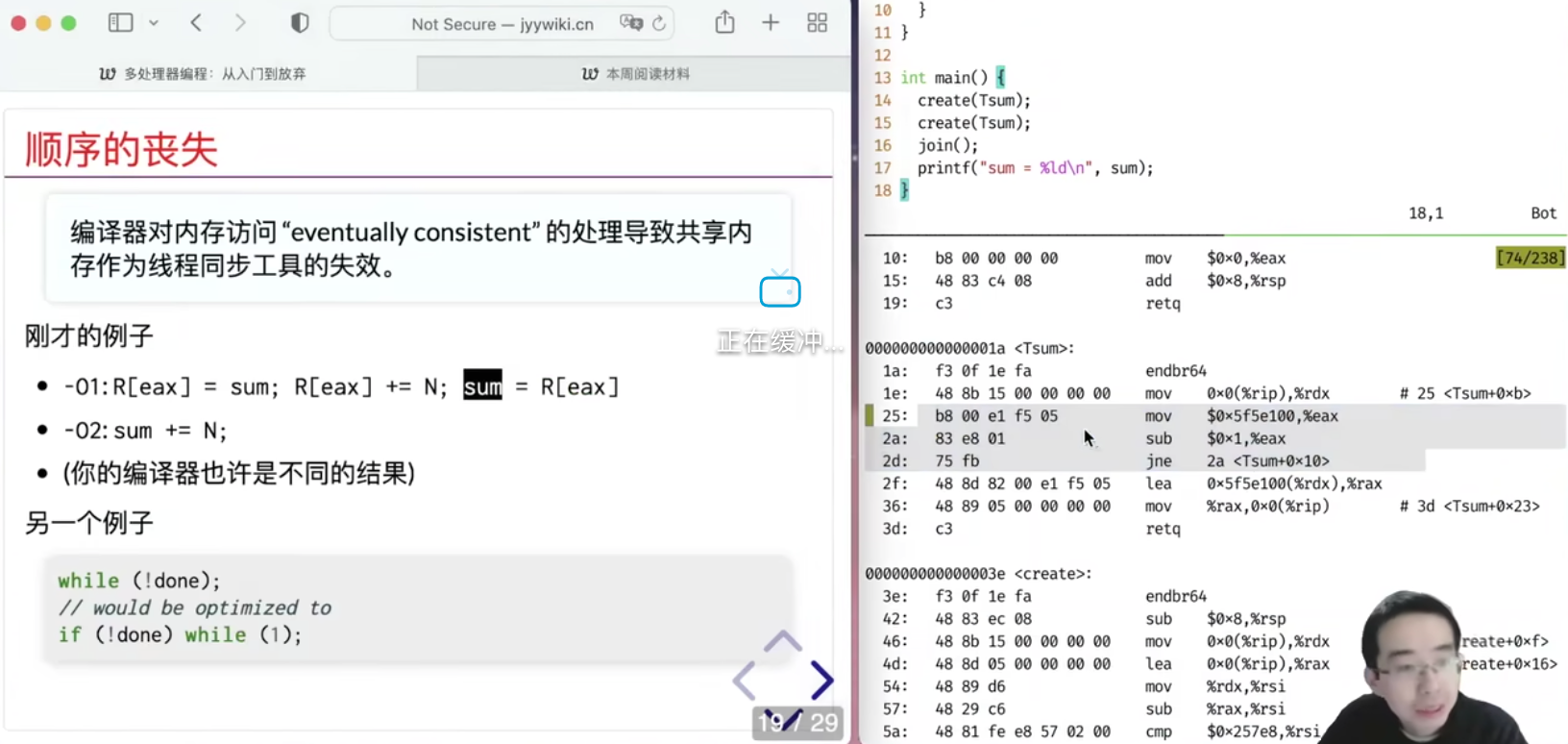
编译器会去优化代码昂!!!
如果想让编译器不去做这样的优化:
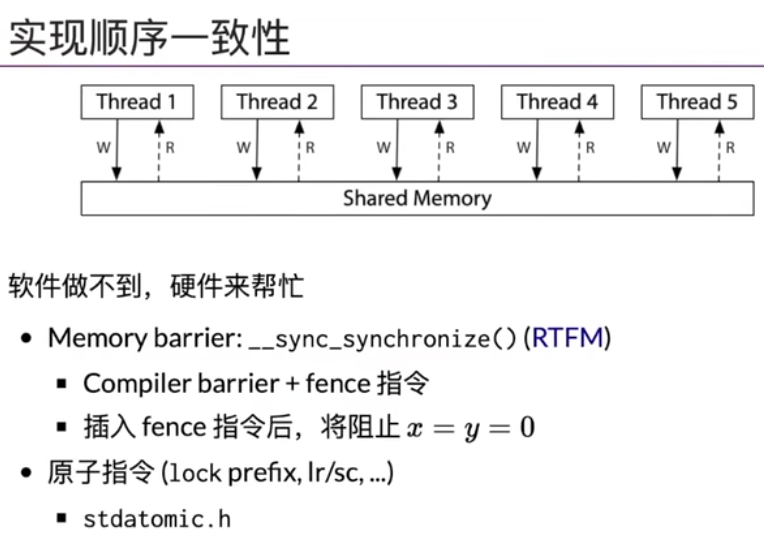
可见性
Mem-ordering.c
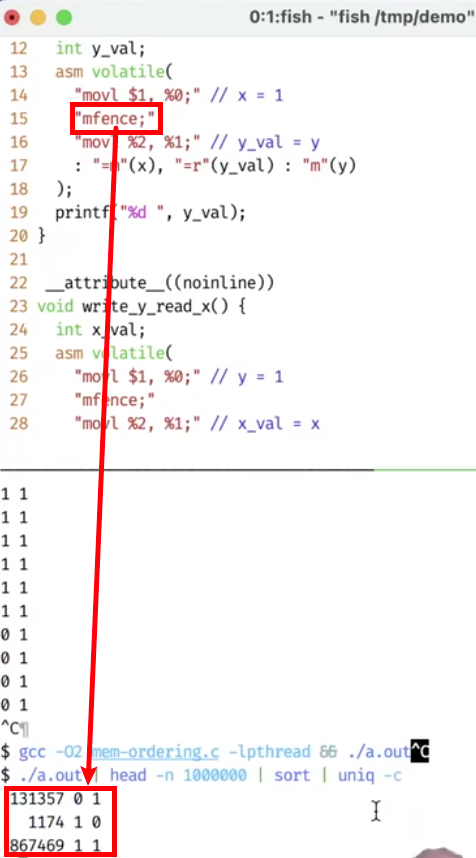
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 #include "thread.h" int x = 0 , y = 0 ;atomic_int flag;#define FLAG atomic_load(&flag) #define FLAG_XOR(val) atomic_fetch_xor(&flag, val) #define WAIT_FOR(cond) while (!(cond)) ; void write_x_read_y () {int y_val;asm volatile ( "movl $1, %0;" "movl %2, %1;" : "=m" (x), "=r" (y_val) : "m" (y) ) ;printf ("%d " , y_val);void write_y_read_x () {int x_val;asm volatile ( "movl $1, %0;" "movl %2, %1;" : "=m" (y), "=r" (x_val) : "m" (x) ) ;printf ("%d " , x_val);void T1 (int id) {while (1 ) {1 ));1 );void T2 () {while (1 ) {2 ));2 );void Tsync () {while (1 ) {0 ;1 ); 0 );3 );0 );printf ("\n" ); fflush(stdout );int main () {
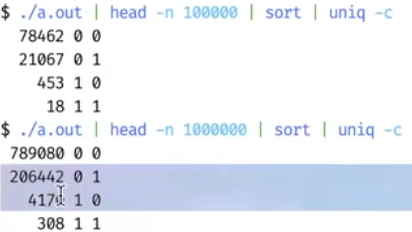
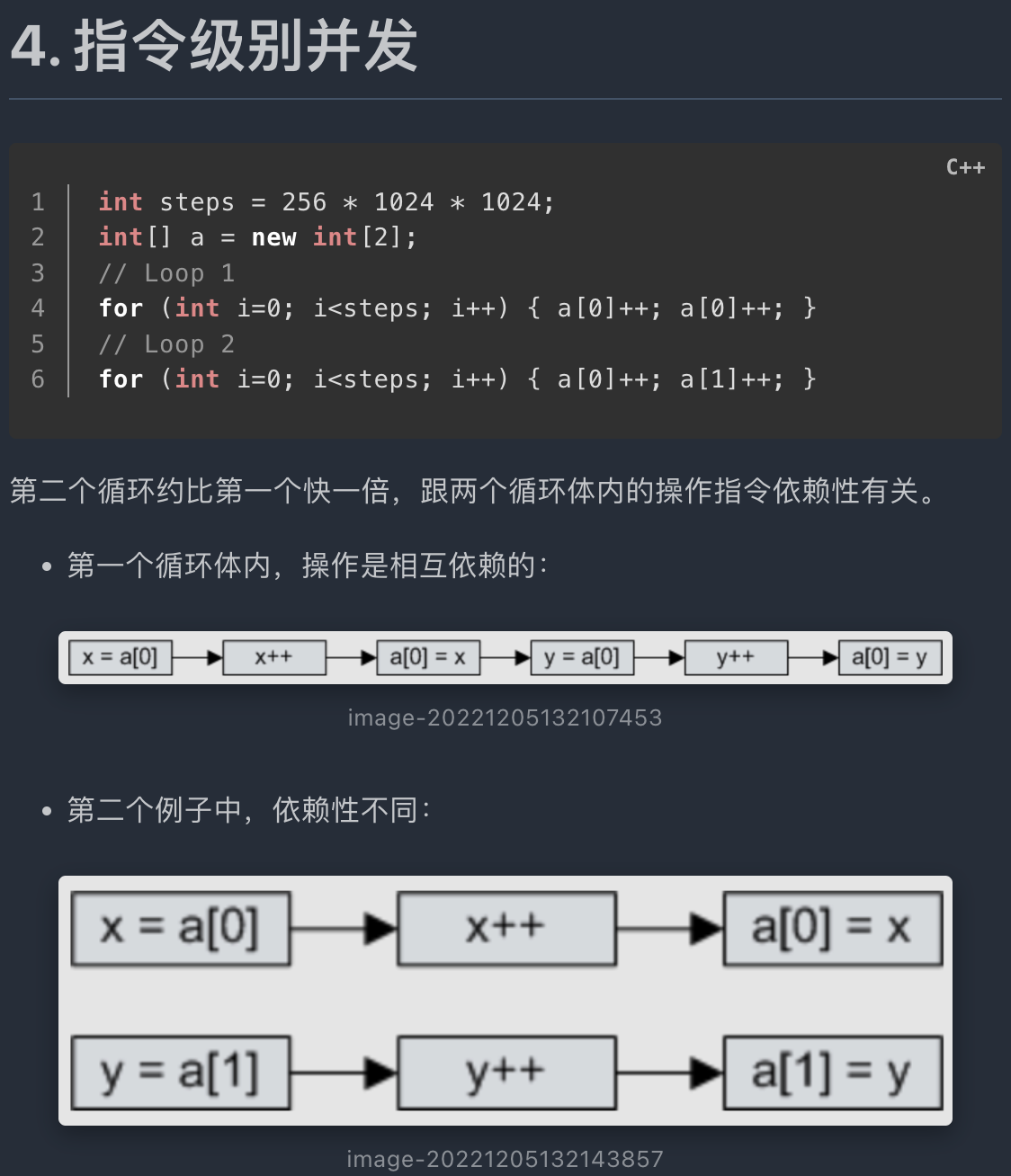
本质上,这里的代码就是上面那幅图的level up 版本,但是,高级一点点,我们发现了很炸裂的事情。。。
理论上,这里的x, y的取值,是看不到同时为0的。。。但是,他确实是出现了同时为0的情况。。。
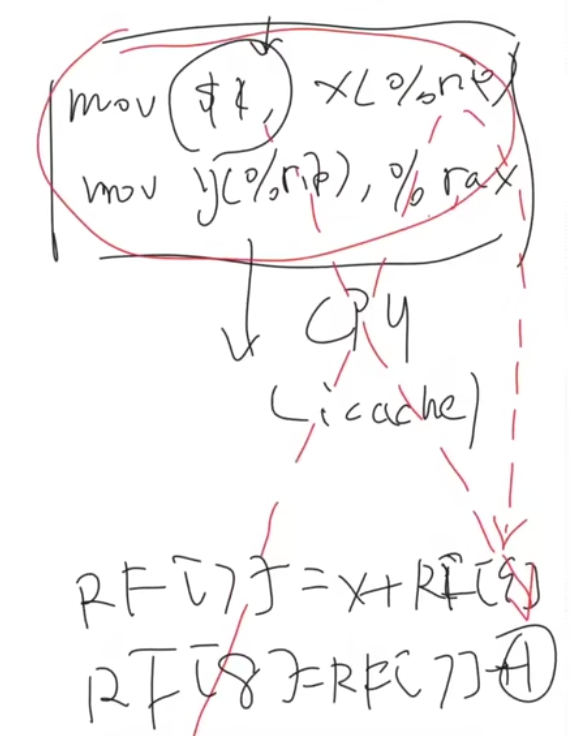
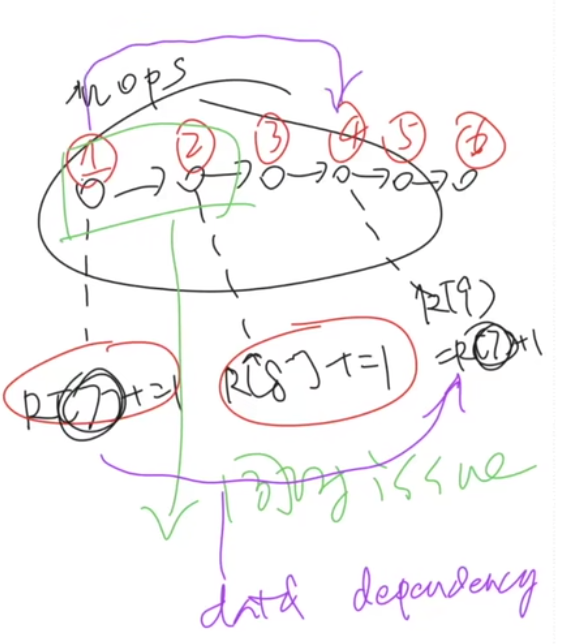
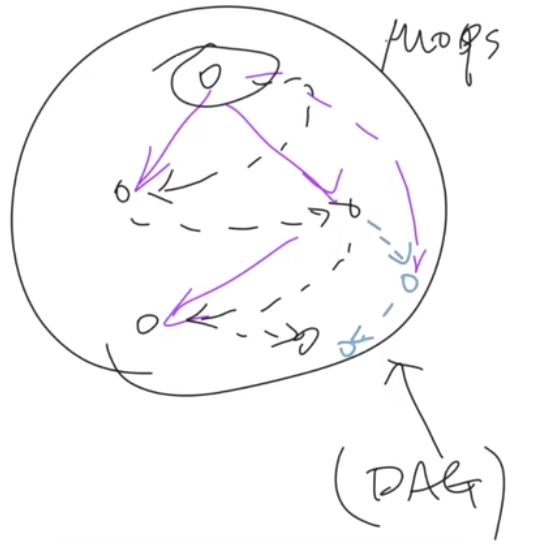
处理器还会把我们的汇编再经过一次编译,得到一个处理器看的懂的,更小的操作(uOps)
上面绿色的这里就是,处理器又回自己把能并行的给并行了。处理器内部维护了一个这样的(DAG),并且在一个时钟周期内,取出多条可以同时执行的指令,突然让我想到了https://alexanderliu-creator.github.io/2022/12/05/cpu-cache-xue-xi/
C语言 —(C编译器)—> 汇编指令(内存屏障生效)
汇编指令 —(CPU)—> 机器指令(uOps) CPU根据数据依赖性等关系,可以同时将多条不冲突的指令,issue到多核上去执行昂!
CPU执行指令的顺序,不一定和你的汇编版本的是一致的!!! CPU也会自己维护关系,并且尽可能实现并发!!!
我的理解:
C -> 汇编(串行 -> 并行)
汇编 -> uOps(串行 -> 并行)
每一次FLAG_XOR(3) -> 来自于上面的代码的时候,Cache总是会被Invalidate,总是miss的,CPU会去取后面的指令执行。Cache Line还是被共享的状态,下面这条指令就被扔到了上面去执行。
https://jyywiki.cn/OS/2022/slides/3.slides#/4/4
从编译 -> 机器指令的编译,其实也是可以保持一致的:
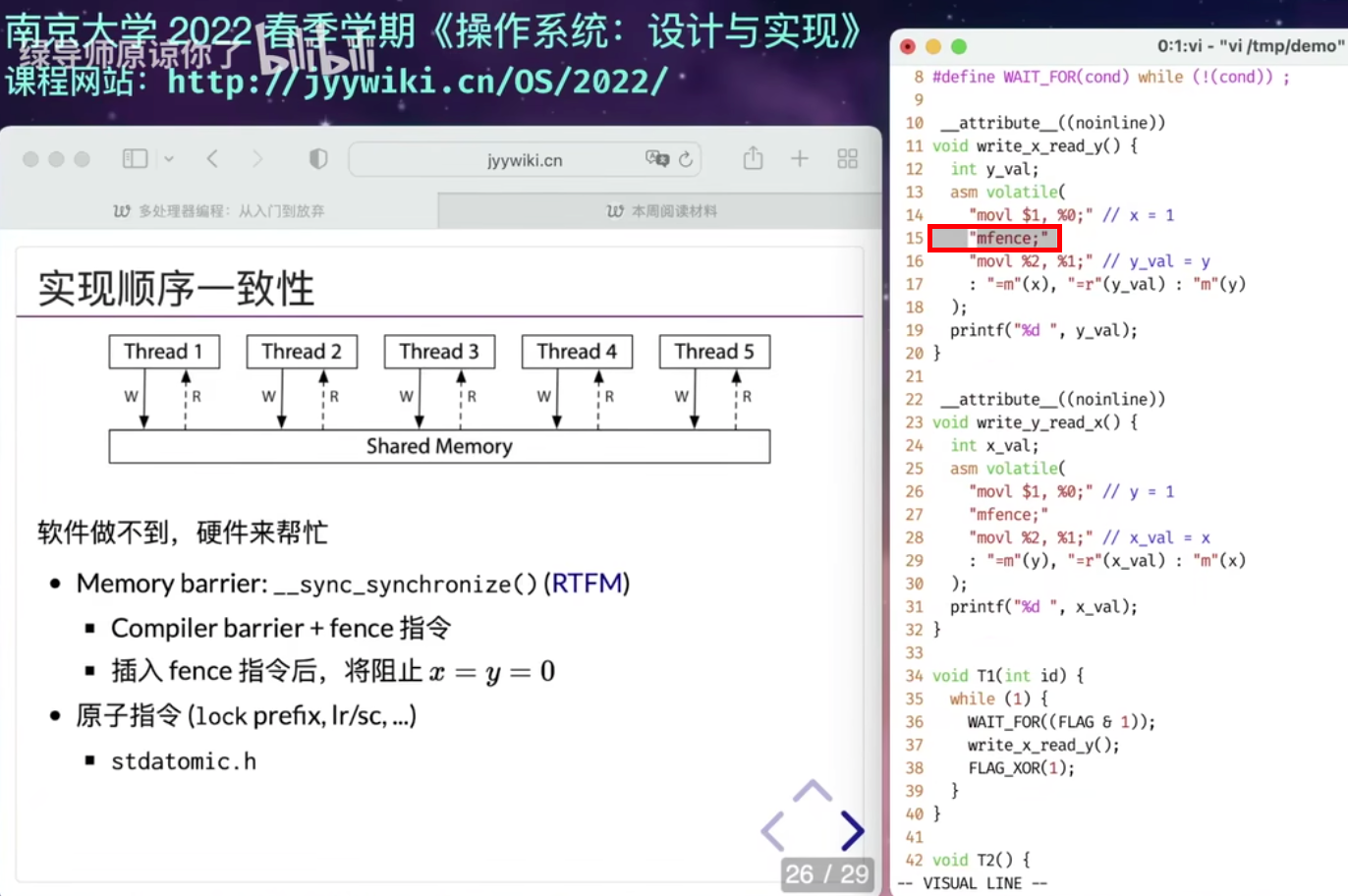
mfence -> 可以在多处理器之间,保证一致性!!!
References
mac中获取su权限:https://blog.csdn.net/fgx_123456/article/details/109550283
Dtruss: https://blog.csdn.net/kfy2011/article/details/48102843 -> Dtruss需要命令行拥有su的权限,才能够执行昂!!
查看pthread的手册:
思路:能不能手动设置分配的堆栈内存大小。
man的使用:
https://blog.csdn.net/u012349696/article/details/50314215
gcc可以对代码进行优化:
https://www.zhihu.com/question/27090458
objdump的使用:https://blog.csdn.net/zoomdy/article/details/50563680
head指令(-n参数),sort指令,uniq指令
内存一致性模型:https://research.swtch.com/hwmm
MESI: https://xiaolincoding.com/os/1_hardware/cpu_mesi.html#%E5%86%99%E5%9B%9E
内存屏障: https://zhuanlan.zhihu.com/p/125737864