Java常问面试题总结与提高2
本文最后更新于:3 年前
这里是对于Java基础和其他一些概念的深入理解!!!
Java基础
Java字符串常量池
- 题目:
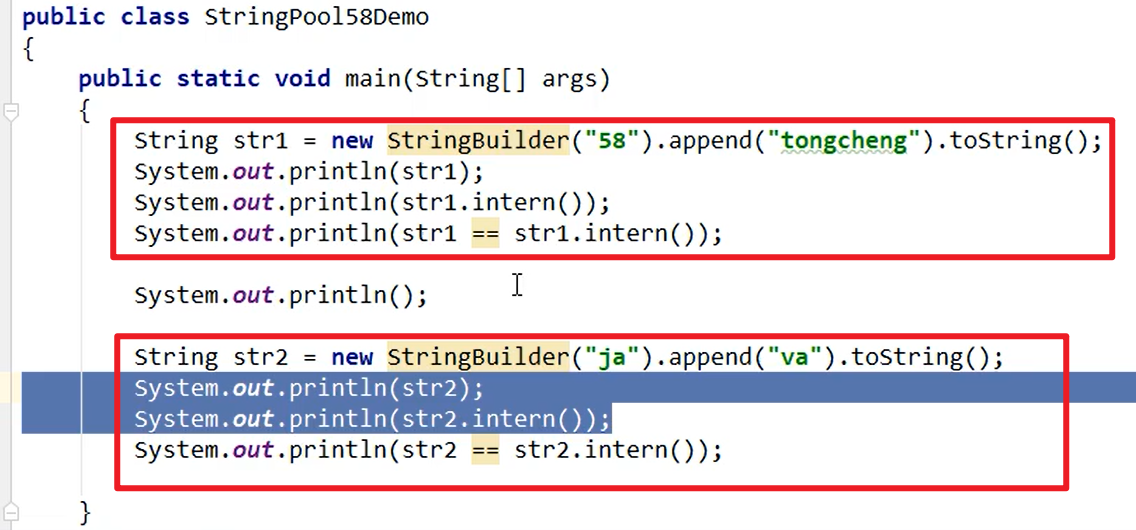
- Intern()方法:
- 如果字符串常量池存在这个常量的话,就直接返回这个常量的引用。
- 如果字符串常量池不存在这个常量的话,就会自动创建出这个字符串,并且加入到常量池中嗷!!!
- new StringBuilder会构造一个全新的字符串并且返回应用,如果它发现,字符串常量池中没有这个字符串,它就会把自己加入到字符串常量池中,因此,返回的是true嗷,intern()获得的,就是我们构造的嗷!!!
- 我们intern()得到的Java,不是我们自己构建的Java,说明Java早就存在于字符串常量池中了,这个Java,是从
sun.misc.Version这个类中加载进来的嗷!!!
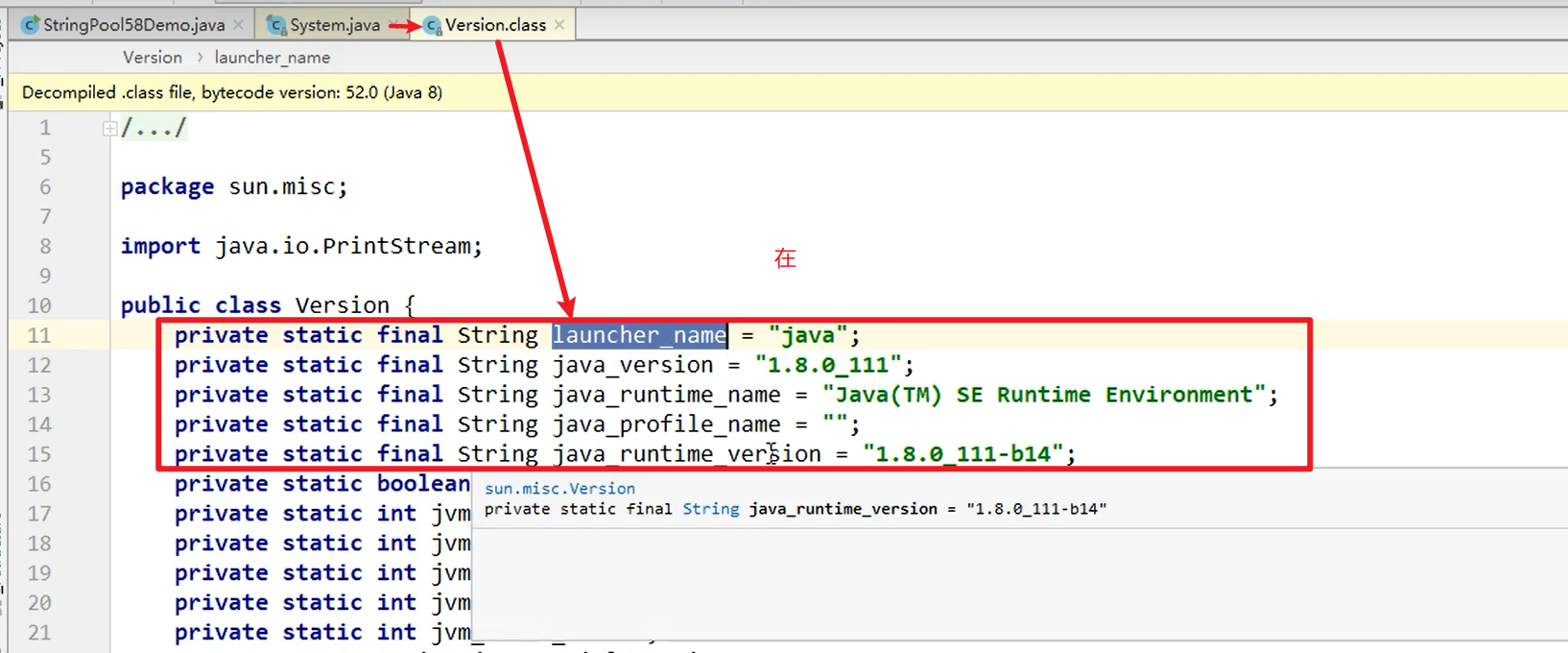
由于我们调,用了System,System这个类加载的时候,会自动加载Version这个类,这个类中具有很多静态变量,静态字符串常量,在这个过程中,Java被加载进来了嗷!!!

- 书中讲解:

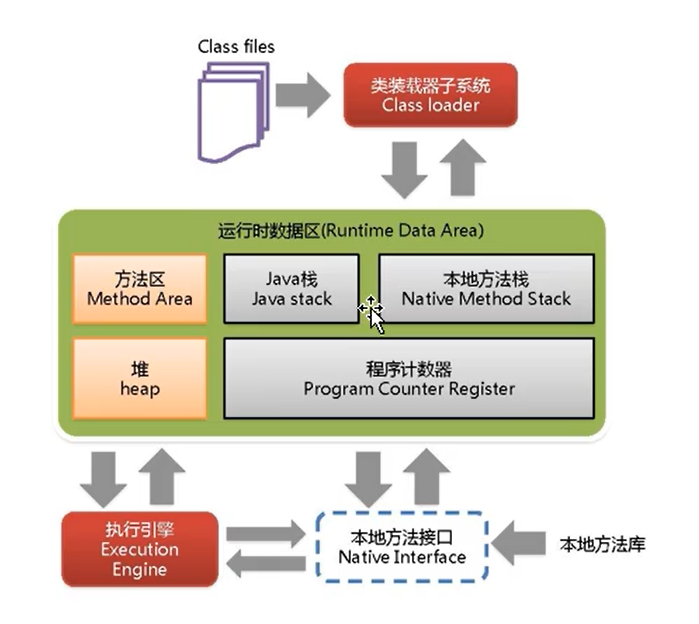
- JVM结构:
OpenJDK8源码分析:
考点:
- intern()方法
- 《深入了解JVM虚拟机》
高并发和JUC
可重入锁(递归锁)
- 程序多层,外 -> 中 -> 内,只要拿到最外层的锁进来了,内层的锁老子全都能够拿到嗷!!!
- 前提:锁对象要是同一个对象
- 一个线程中的多个流程可以获取同一个锁。
- 重入锁的种类:
- 隐式锁:即synchronized关键字使用的锁,默认是可重入锁
- 显式锁:Lock,例如ReentrantLock就是可重入锁嗷!!!
可重入锁验证1:
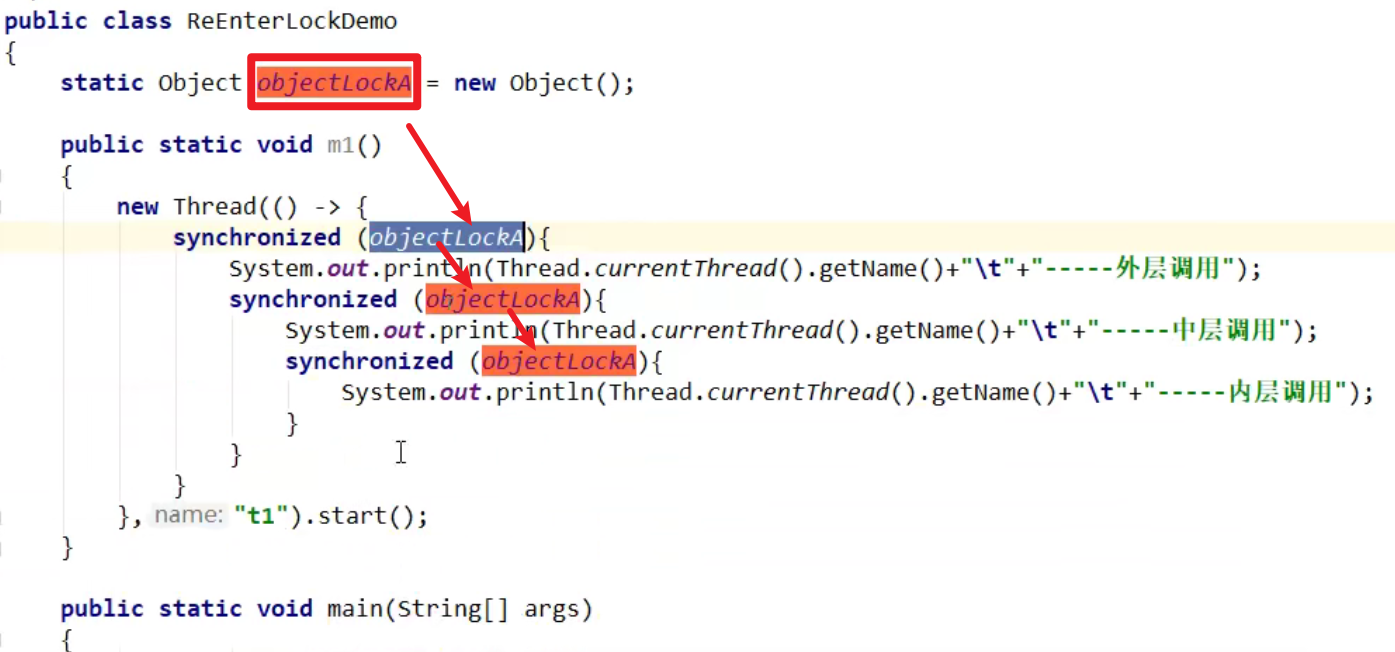
这里注意一下,这里锁住的是同一个对象嗷,不然的话不可重入嗷!!!
- 一个线程可以多次获得同一把锁嗷!!!
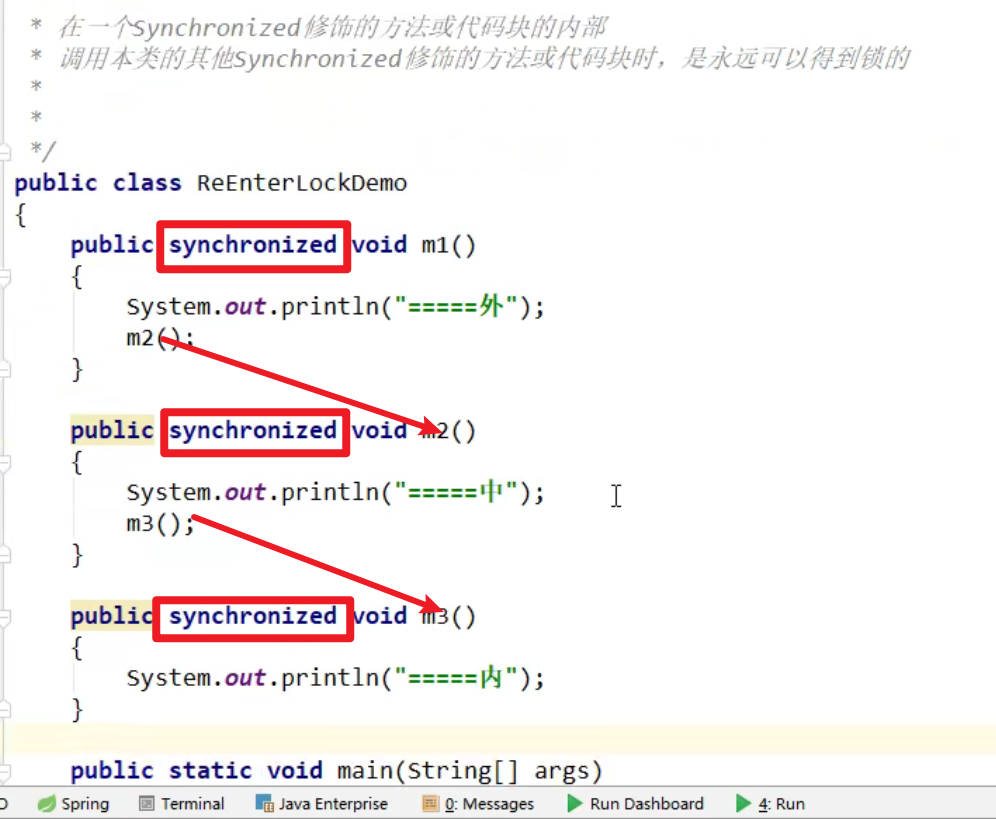
可重入锁验证2:
- 在一个synchronized的代码块内,调用本类其他synchronized修饰的方法或代码块的时候,是永远可以得到锁的!!!
底层:
- monitorenter和monitorexit:

加一次锁就释放一次锁,一一配对。
- 每一个锁对象都拥有一个锁计数器和一个指向该锁的线程的指针。
monitorenter,如果计数器为0,那么说明它没有被其他线程所持有,JVM会将该锁对象所持有的线程设置为当前线程,并且计数器加1。- 否则就要等待,纸质持有线程释放锁。
monitorexit,Java虚拟机会将锁对象的计数器减1,计数器为0代表锁被释放。
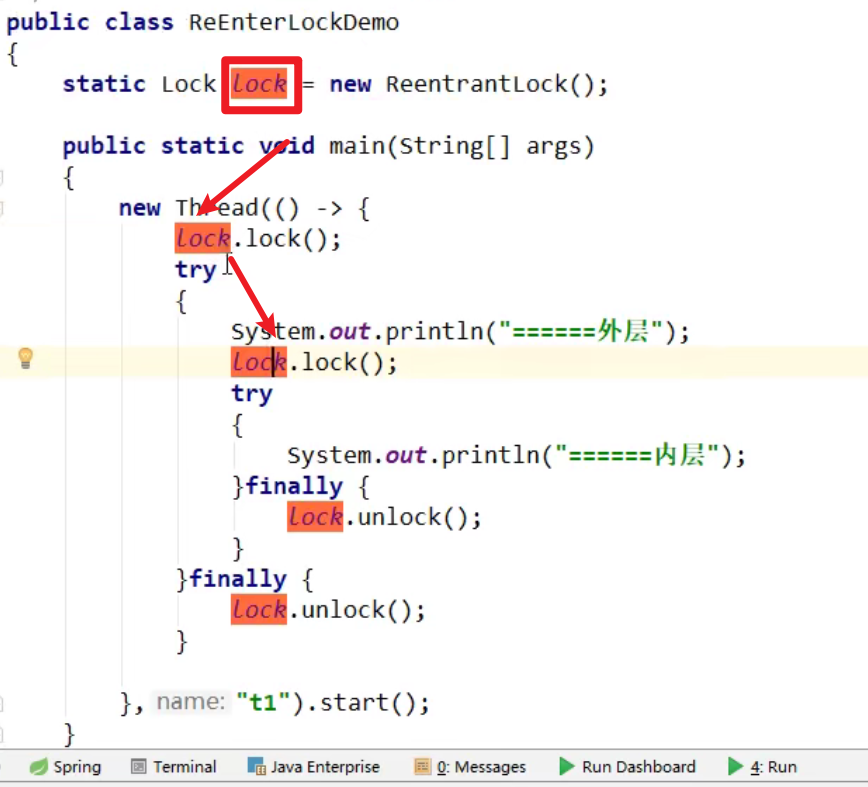
可重入锁由于可以被已经获得锁的进程多次获取,lock几次,就要unlock几次嗷!!!两两要配对嗷!!
可以避免一定程度的死锁嗷!!!
LockSupport:
- 线程的等待和唤醒机制,wait/notify的升级版本嗷!!!
- 方法:
- park() 阻塞线程
- unpark() 唤醒线程
- 技术演变过程:


技术横向对比:
- Object类中的wait和notify方法实现线程的等待和唤醒
- 示例代码:

异常1:
- wait和notify方法,两个都去掉同步代码块
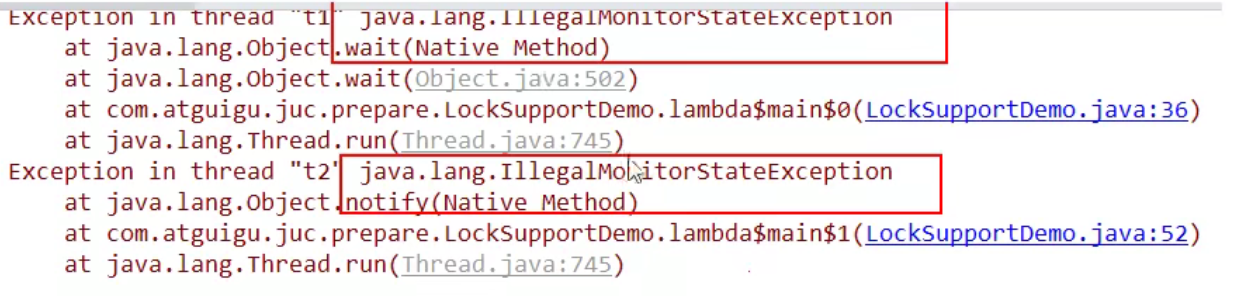
异常2:
- notify如果因为调度原因在wait方法前面执行,无法执行,无法唤醒。
小总结:
- wait和notify必须在同步块或者方法里面才能使用并且应该成对使用!
- 先wait后notify才ok嗷!!!
- Condition接口中的await和signal方法实现线程的等待和唤醒
- 示例代码:

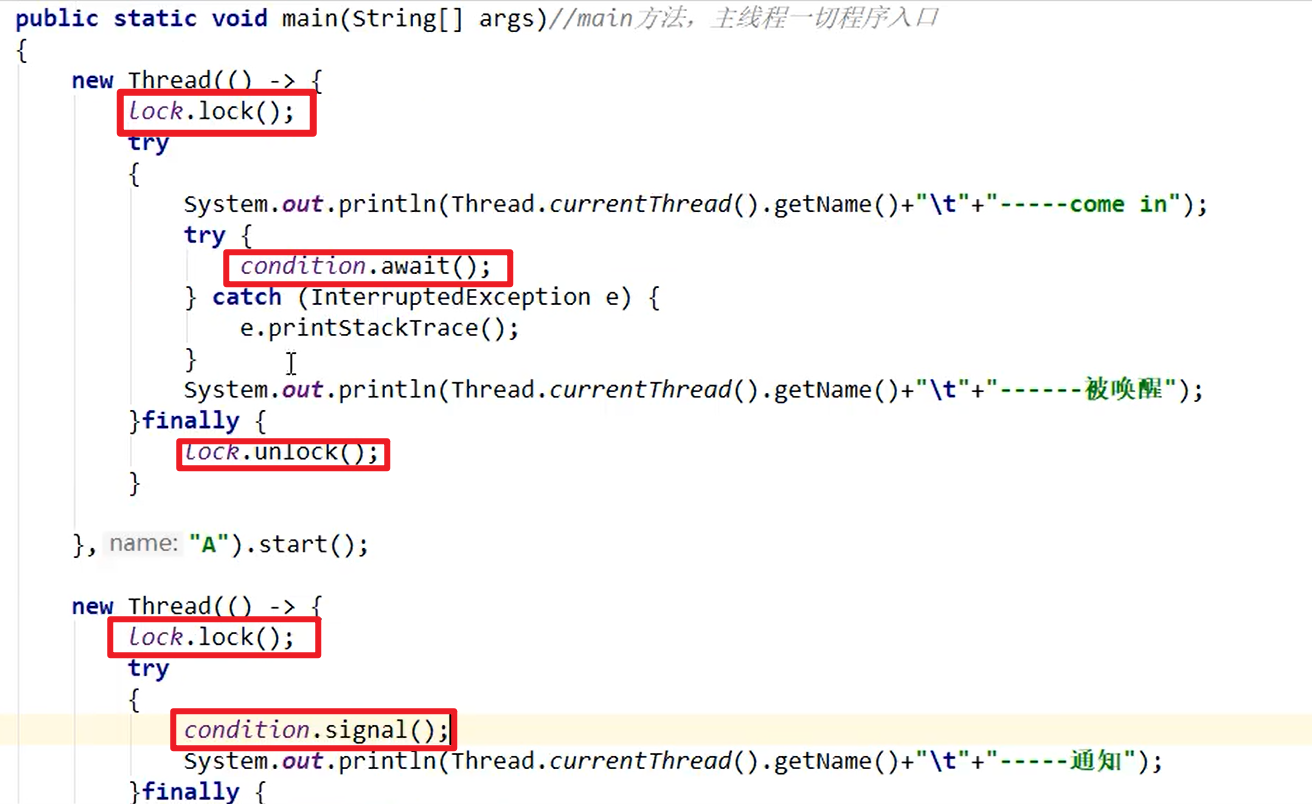
- await和signal
- 异常的两个遇到的问题,和上面是一样的嗷!!!
- 小总结:
- await和signal必须在lock和unlock之间,才能使用嗷!!!
- 必须要先等待后唤醒,线程才能够被唤醒嗷!!!
- LockSupport类中的park等待和unpark唤醒

- LockSupport提供了一种名字为Permit(许可)的概念来做到阻塞和唤醒线程的功能,每个线程都有一个Permit。Permit可以被看做为0,1信号量,默认为0嗷!!!许可的累加上限为1。
- 阻塞和唤醒函数以及底层:

底层:
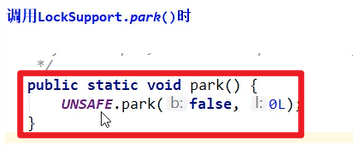


调用的都是底层的Unsafe类嗷!!!
到了这个时候,我们已经能够具体操纵,哪个线程的唤醒了嗷!!!
示例代码:
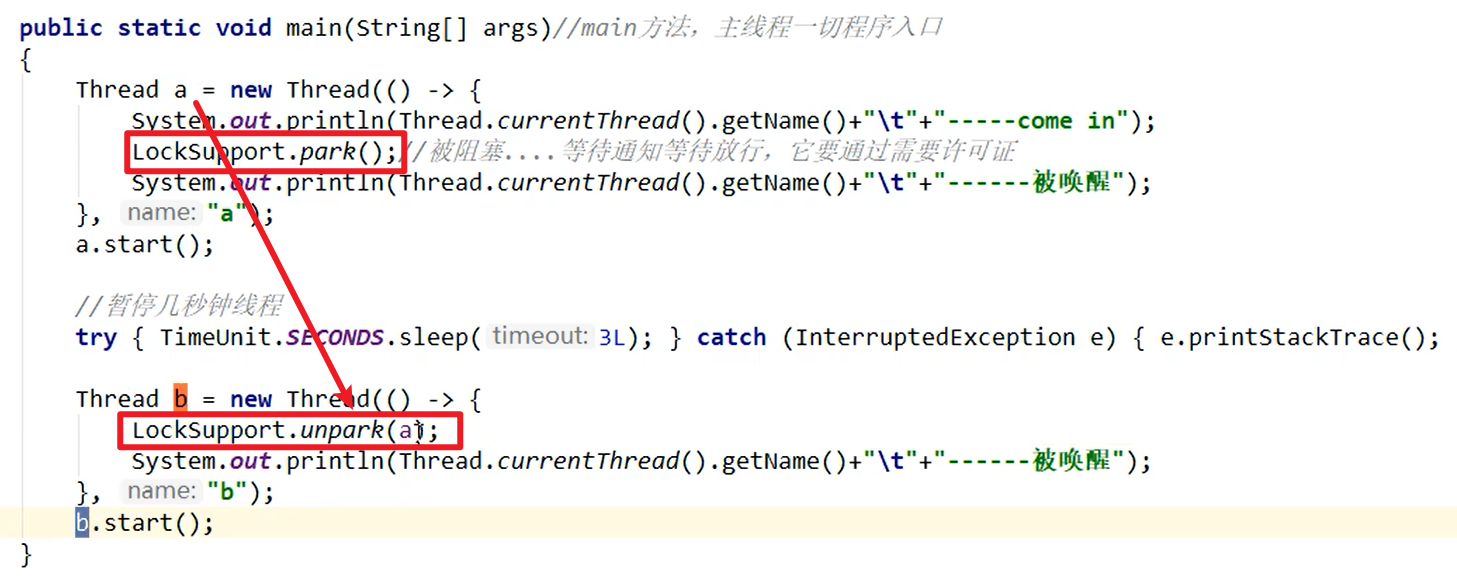
不用之前的synchronized和lock,直接可以使用,十分方便嗷!!!
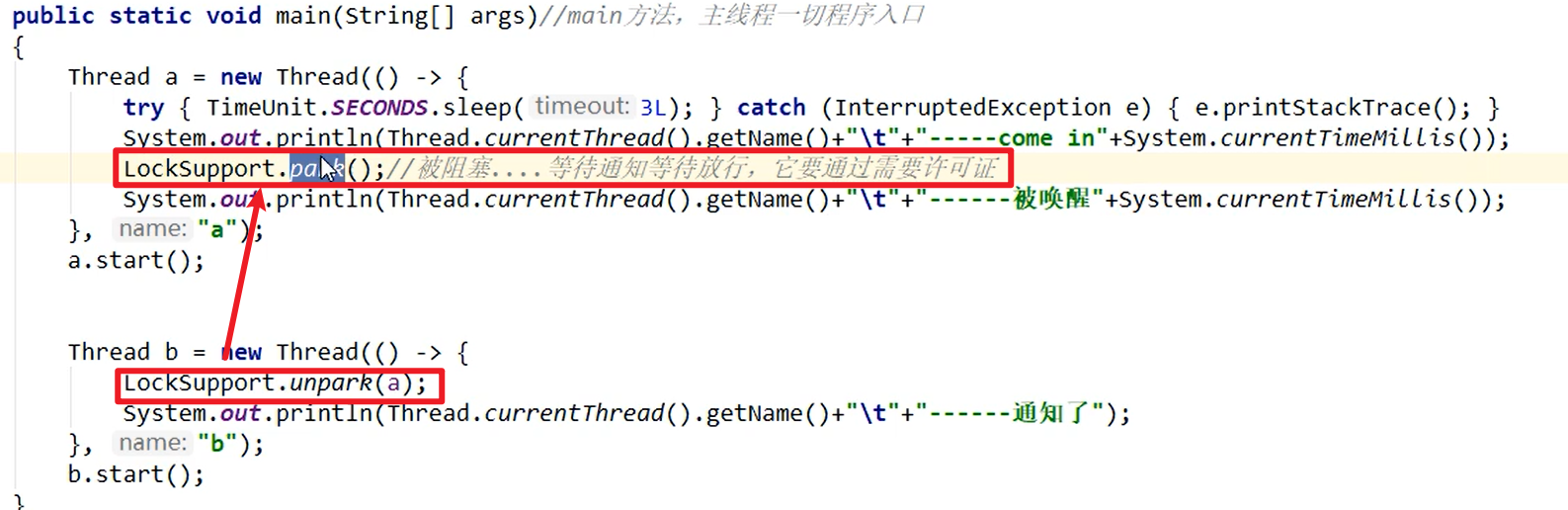
- unpark甚至能够在park之前执行嗷!!!
- 上面两点的劣势都不复存在嗷!!!超级棒!!!
LockSupport解析:
- LockSupport是一个线程阻塞工具类,所有的方法都是静态方法,可以让线程在任意位置阻塞,阻塞之后也有对应的唤醒方法,LockSupport底层调用的Unsafe中的native代码嗷!!!

- 有点像请柬,一个人没有拿到请柬就进不了聚会厅。他可以等在门口,等别人给他请柬,他才能进去。他也可以先拿到给他的请柬,直接进入聚会厅。但是,给一个人的请柬只能有一张,他不可以同时拥有多张专属于他的请柬。这次舞会结束,可以再发给他下次的,但是他不能同时持有多张请柬嗷!!!
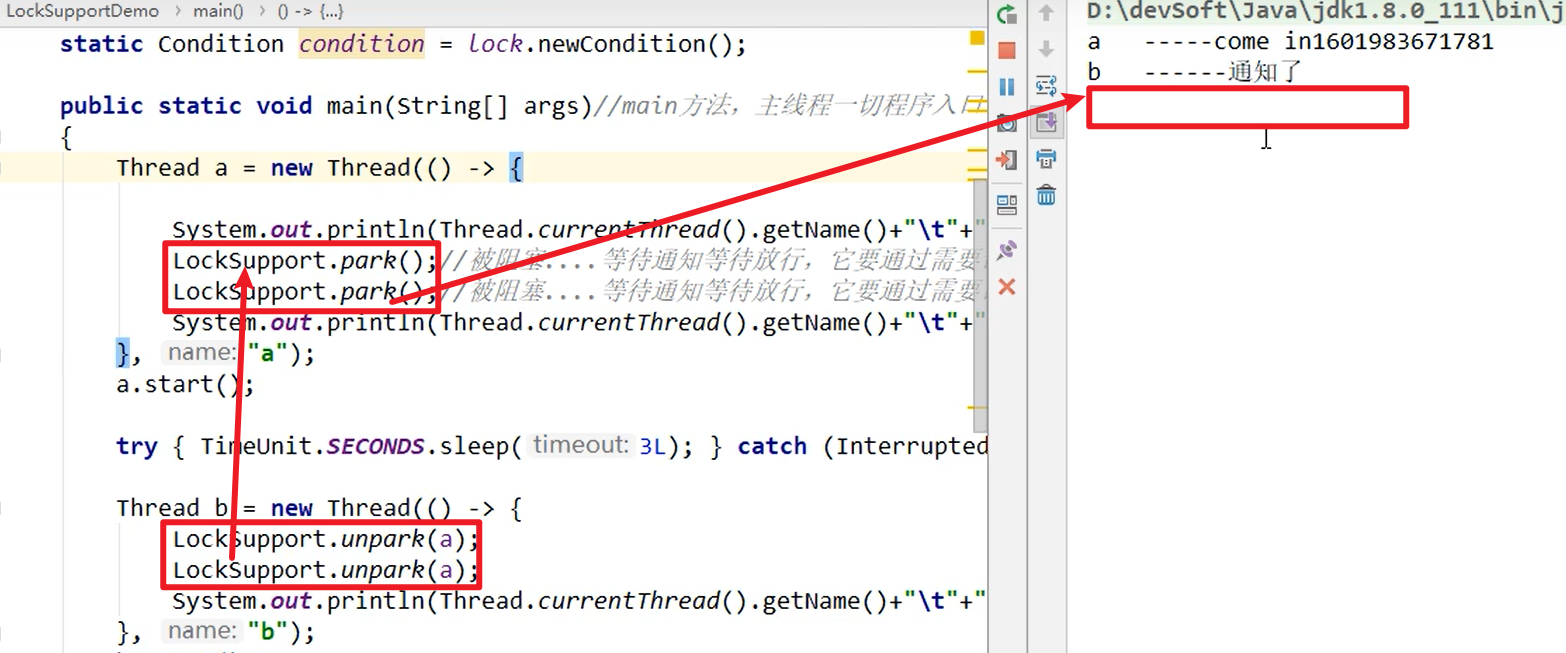
unpark最多发放一个Permit给对应的线程,多次调用unpark也只能给一个凭证嗷!!!
- 面试题:

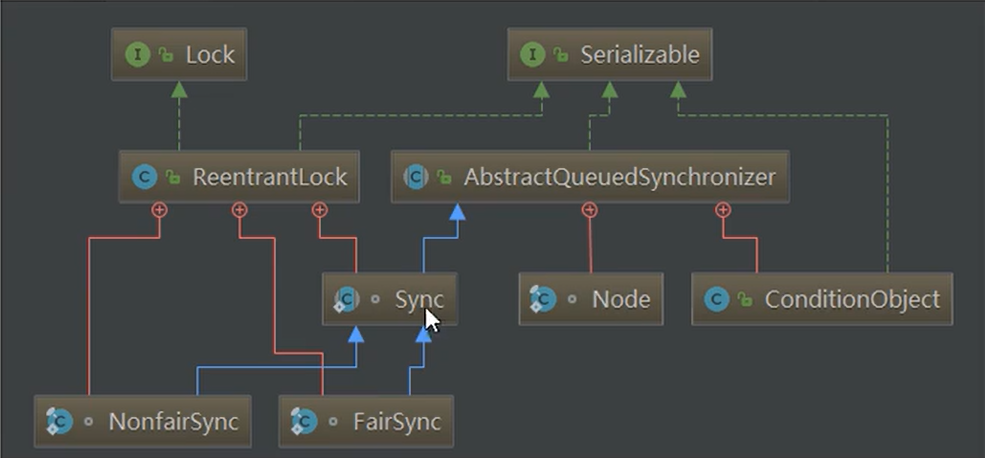
AQS:
- AbstractQueuedSynchronizer,抽象队列同步器
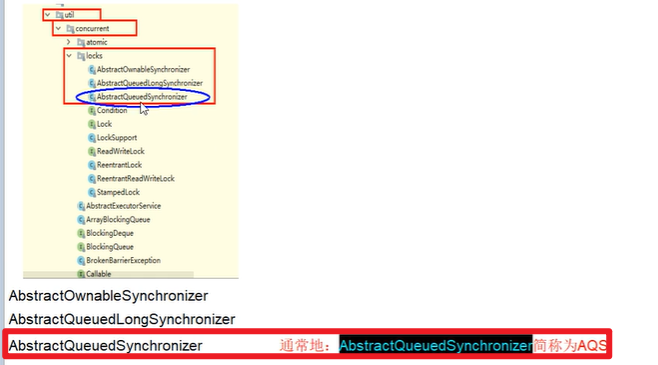
接口,定义的方法足够底层嗷!!!
- 基础解释:用来构建所或者其他同步器组件的 重量级基础框架以及整个JUC体系的基石 ,通过内置的FIFO队列来完成资源获取线程的排队工作,并且通过一个 int型变量表示持有锁的状态。
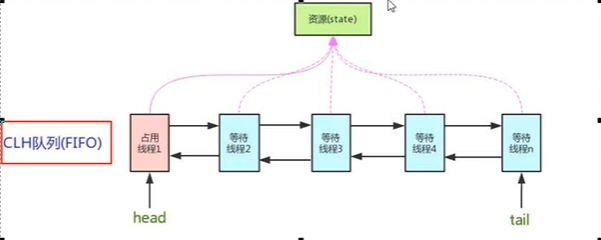
就是阻塞队列???多了一个Int变量来表示锁的状态而已嗷!!!
AQS能干啥?
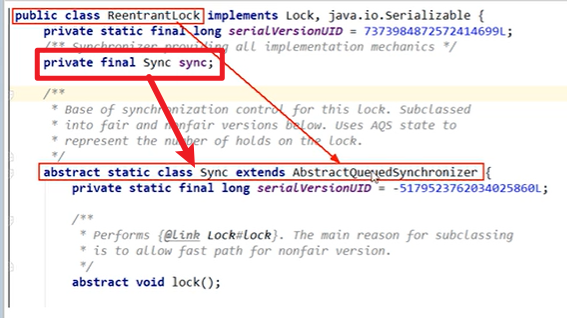
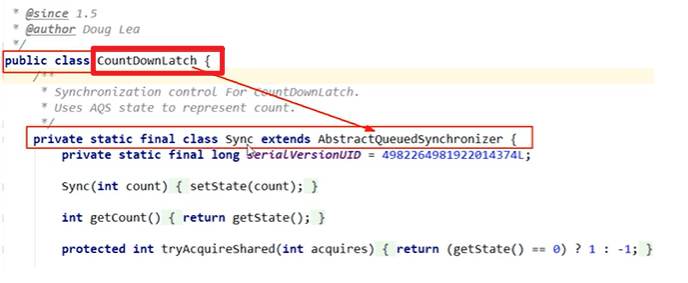
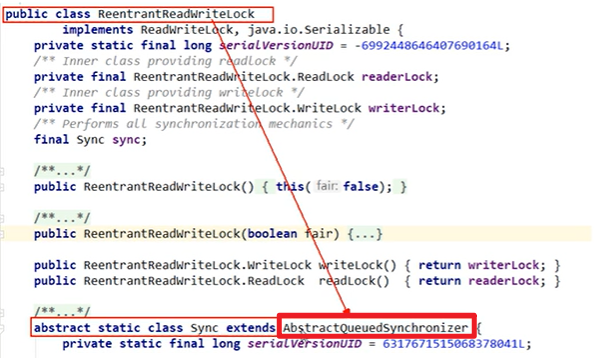
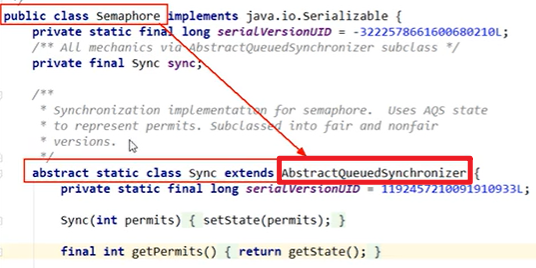
- 好多东西底层都是AQS
- 锁和同步器的关系:
- 锁:是面向锁的对象的使用者,定义了程序员和锁交互的使用层API,隐藏了实现细节,你调用就成。
- 同步器:是面向锁的对象的实现者,是Java开发的大神所写的Java同步规范嗷!!!
- 使用场景:
- 加锁导致阻塞 -> 阻塞就需要排队,排队就需要队列管理
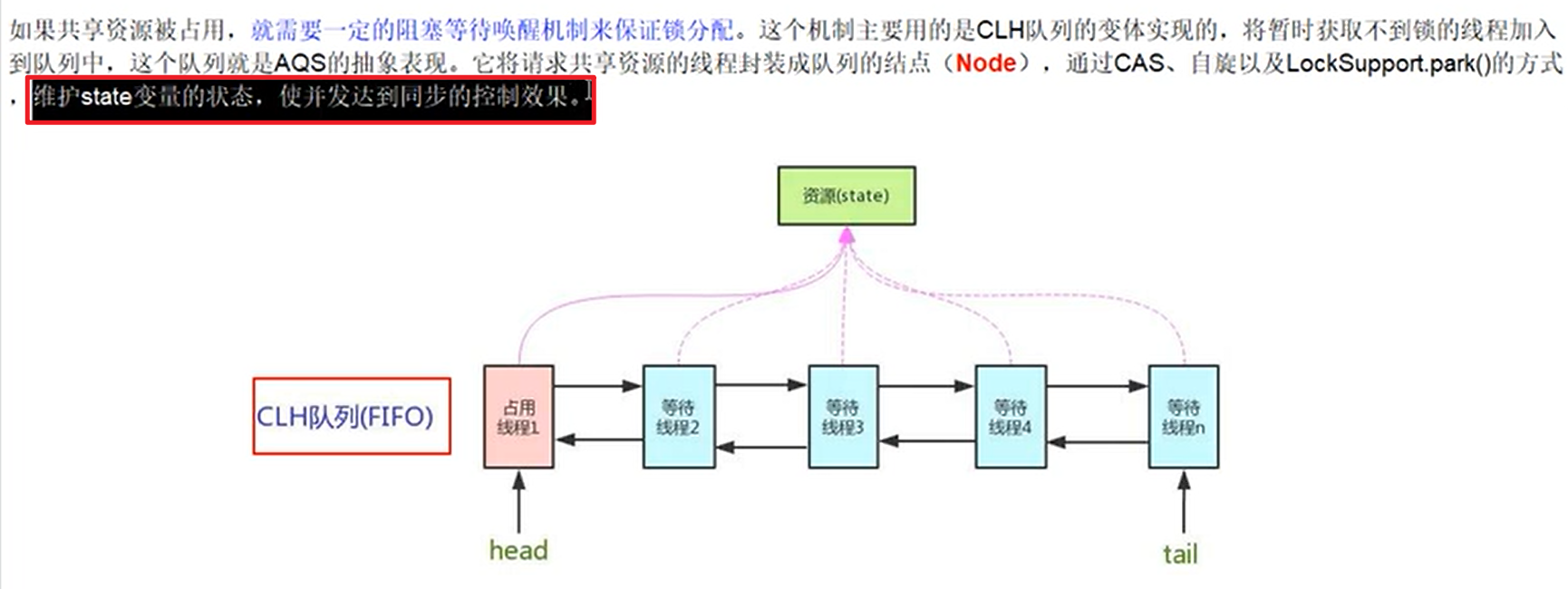
源码体系:
使用volatiled的int类型的成员变量来表示同步状态,通过内置的FIFO队列来完成资源获取的排队工作。将每条要去抢占资源的线程封装为一个Node节点来实现锁的分配,通过CAS完成对于State值的修改!!!
底层和HashMap有点相似嗷!!!

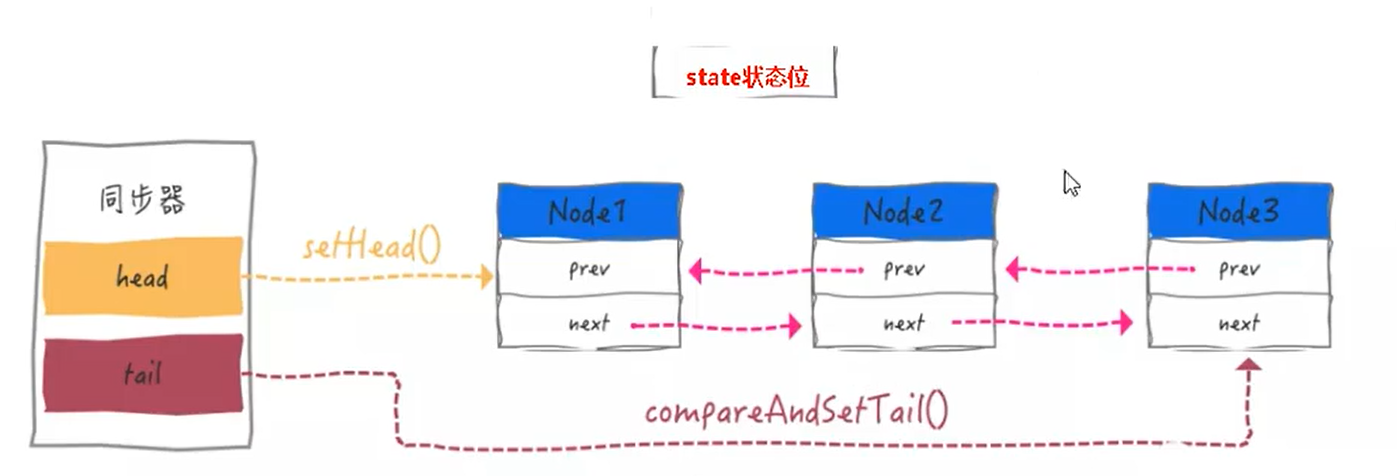
将thread封装为一个叫做Node的数据结构,放入一个双向链表中进行管理嗷!!!
- 内部体系架构:
AQS的同步状态State成员变量:
private volatile int state- 等于0就是先抢先得,大于等于1,就阻塞,让县城们乖乖等着
- CLH队列:
- 默认是一个单向的队列,这里我们改为双向队列
总结:本质底层就是用state成员变量 + CLH变种的双端队列。
有阻塞就需要排队,实现排队必然需要队列。
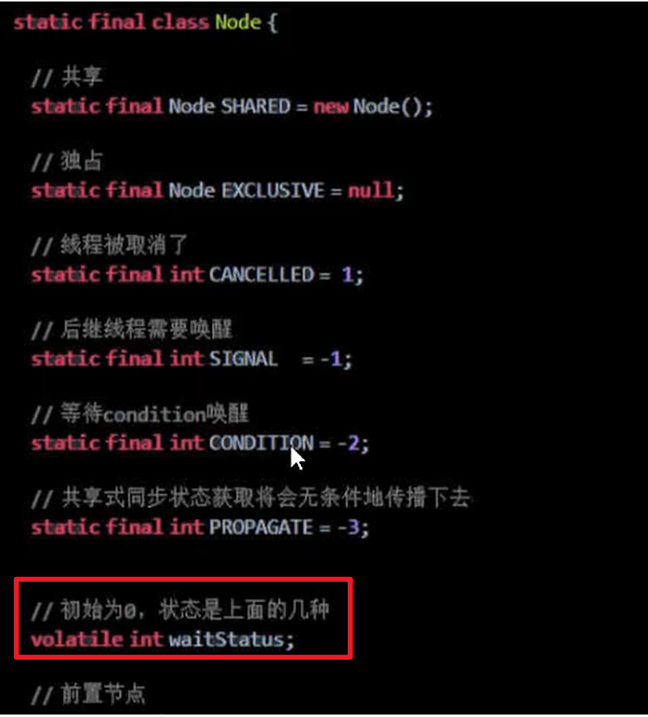
内部类Node:
- 具有volatile修饰的Node的头指针和尾指针,前指针,后指针
- volatile int waitStatus 等待状态
- volatile Thread thread 封装的线程
每个等待线程的封装体就是一个Node,每个Node都有一个自己的等待状态嗷!!!
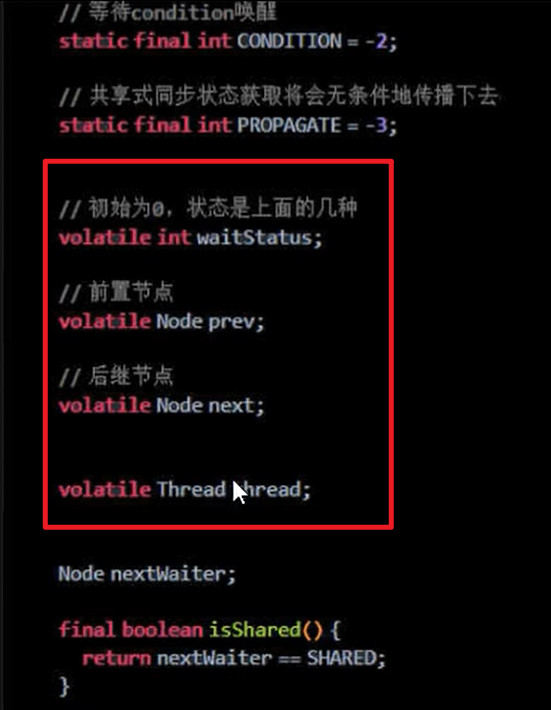
Node = waitStatus + 前后指针指向
塔玛希之图:
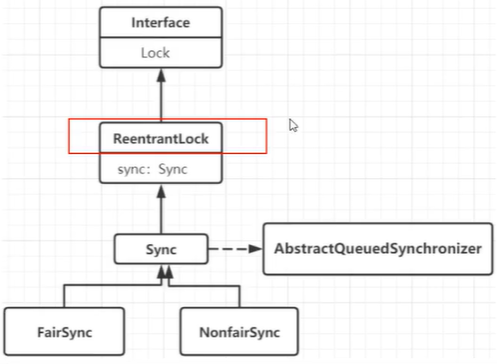
AQS源码解读:
ReentrantLock的例子:
- 这里以ReentrantLock为例子来解读AQS
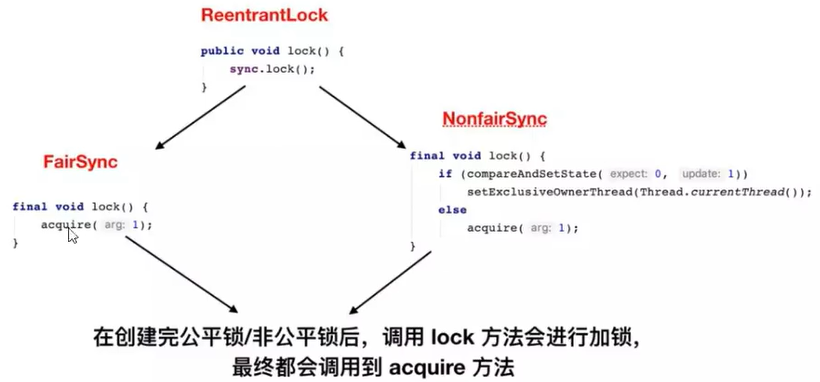
- 公平与非公平:

- 我们看一眼源码:

发现区别非常小。。。hasQueuedPredecessors()是公平锁加锁时等待队列中是否存在有效节点的方法。

- 公平锁先来先得,排队,按照队列顺序来给你锁。
- 非公平锁:不管是否等待,如果可以立即获取锁,立即获得锁对象,
- ReentrantLock的加锁过程,可以分为三个阶段:
- 尝试加锁
- 加锁失败,线程进入队列
- 线程加入队列之后,进入阻塞状态
三个线程办理业务例子:
Lock解析:
- A办理业务20分钟,B,C都只能等着嗷!!!
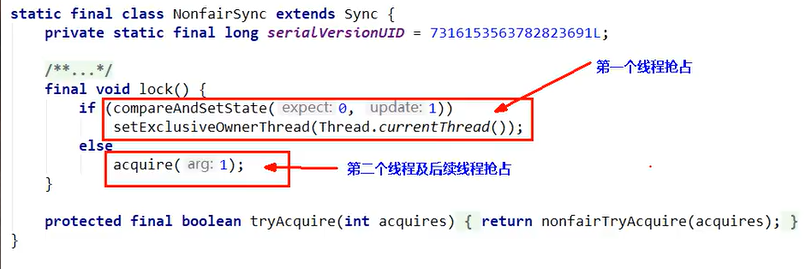
- 默认new的那个锁是非公平锁,我们找到非公平对于这个方法的实现:
1 | |
compareAndSetState的底层就是Compare And Set嗷!!!底层的保证原子性的,这里的意思就是抢到了这把锁并且置为1。(这里用到了底层CAS中的那个state,把那个state的值置为1了嗷!!!)
setExclusiveOwnerThread,设置了占用这个锁的线程为当前抢到锁的线程嗷!!!
B和C来的时候,if都进不去嗷!!!因为state的值为1,CAS进不去,执行else,都执行
acquire(1);
1 | |
- 这里有三个方法,我们一一解析:
- !tryAcquire(arg):
1 | |
第一个方法走到头了,我们找到在非公平锁中,其对应的实现,我们查看上面源码中的流程。
- addWaiter(Node.EXCLUSIVE):
1 | |
- 一开始tail就是为null,完了之后,if失败了,就执行
enq(node)
1 | |
这里看到,t就是尾指针,t就是null,然后就初始化,在Head上new了一个新的Node节点作为占位符。
- 意思是:如果尾指针为null,说明还没有任何一个元素在队列中。新建一个Node节点设置为头节点。然后把头节点赋值为尾节点。
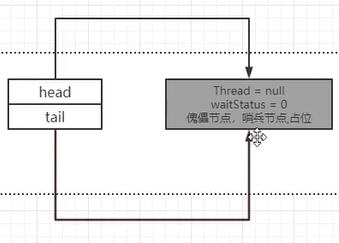
相当于对于链表进行了一个初始化嗷!!!
- 说白了第一次进入循环完成了队列初始化,第二次进入循环,将当前节点(B节点),放到队尾。修改指针。
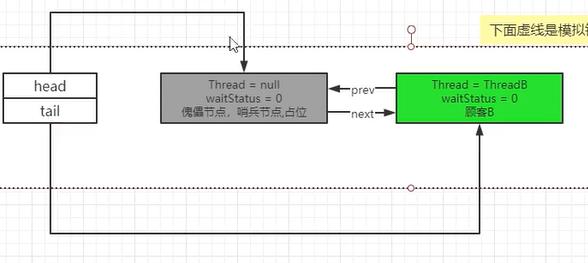
- C来了,由于队列已经初始化好了,因此C可以直接append到B的后面嗷,直接进入enq的else嗷!!!!!
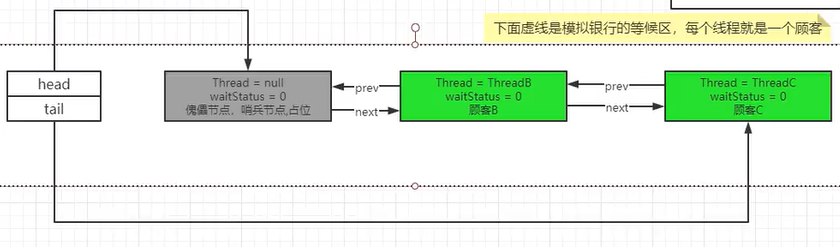
- acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
1 | |
上面这里的for是个自旋嗷!!!
- node.predecessor()方法:
1 | |
可以看到,这里获取了我们上面灰色的那个哨兵节点嗷!!!
当返回的节点为头节点的时候,再次调用tryAcquire方法,尝试去获取锁嗷!!!B入队了之后任然不老实,还想去抢这个节点嗷!!!如果还没抢到,就要执行下面的代码:
- shouldParkAfterFailedAcquire
1 | |
获取前一个结点(头节点)的status,值仍然为0嗷!!!
ws == Node.SIGNAL将wait Status的值设置为了-1,然后compareAndSetWaitStatus,将头节点的值设置为-1。再次进入的时候,这里就直接返回True,就能够退出这个循环了嗷!!!
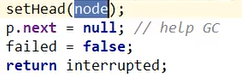
- parkAndCheckInterrupt():
1 | |
到这一步,才真正的park了B这个结点,B这样才真正的被阻塞挂起了嗷!!!要有人来唤醒B才行嗷!!!等A出来,执行unlock()的时候,才unpark嗷!!!B才能继续往前走哦!!!
C也一样的,C也会park,在这里等待嗷!!!
UnLock解析:
底层调用的是
sync.release(1);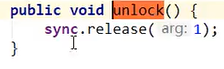
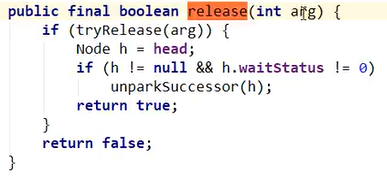

tryRelease定义的足够高,如果子类不实现,我父类默认实现的就给你报错嗷!!!
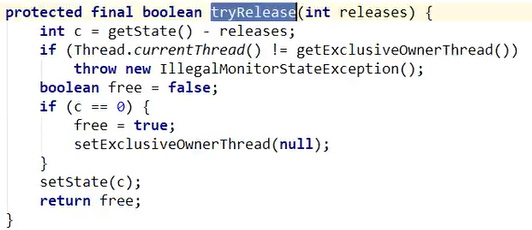
这里的tryRelease(),当A退出的时候:
- c就变成0了
- free设置为false
- c == 0,所以free就变成true了
- 当前窗口占用的线程设置为null
- 设置State为0嗷!!!
- return true
继续执行release:
- 获得头指针
- 哨兵结点确实不等于null , 并且waitStatus确实不为0,执行unparkSuccessor()
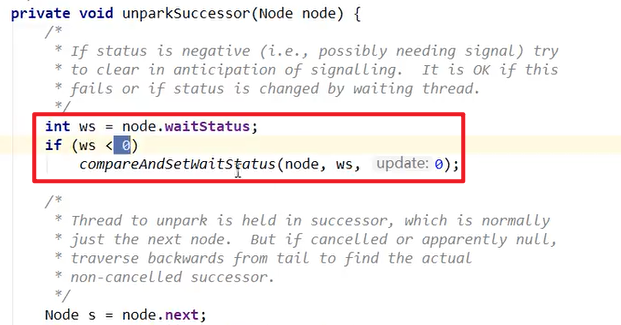
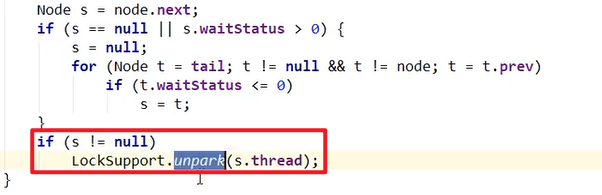
B出来之后,再次循环,抢到了,就成功了嗷!!!从循环中出来,继续执行。B出来之后:
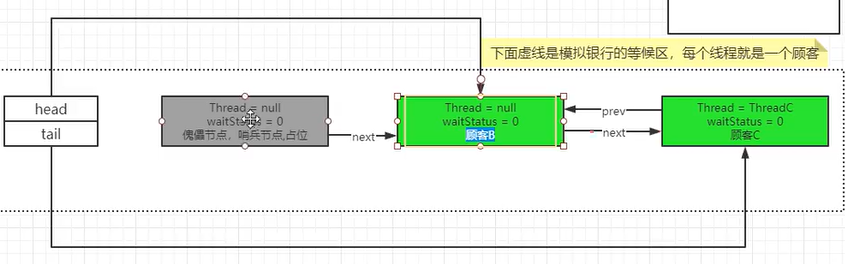
原结点B变成了新的哨兵结点,原哨兵结点的next也被设置为了null,这个时候原哨兵结点就再也没有东西引用了,就会被GC逐步收集掉了嗷!!!
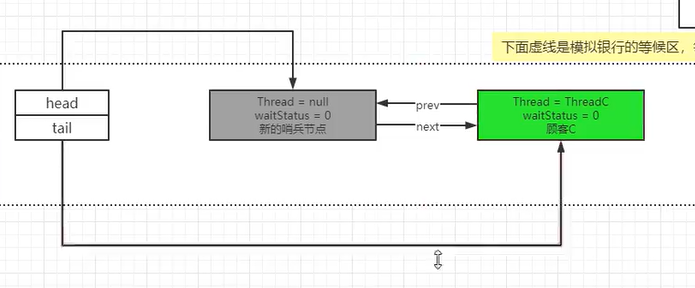
总结:
公平性的体现:
- 体现在 入队前
- 你不在队列中,也可以和队列中的线程竞争锁,谁抢到了算谁的,如果你没有抢到,你乖乖到队列中排着。
- 就是上面所提到的那一点点区别嗷!!!入队之后,公平和非公平都是一样的了,一个一个来嗷!!!
- 非公平性的就是不管啥,你先来排队排着,一个一个来嗷!!!
Spring:
AOP:
常用注解:
- @Before:目标方法之前执行
- @After:目标方法之后执行(始终执行)
- @AfterReturning:返回后通知:执行方法结束前执行(异常不执行)
- @AfterThrowing:出现异常的时候通知
- @Around:环绕通知:环绕目标方法执行
底层的Spring的版本,随着Boot版本的升级也在升级嗷!!!
例子:
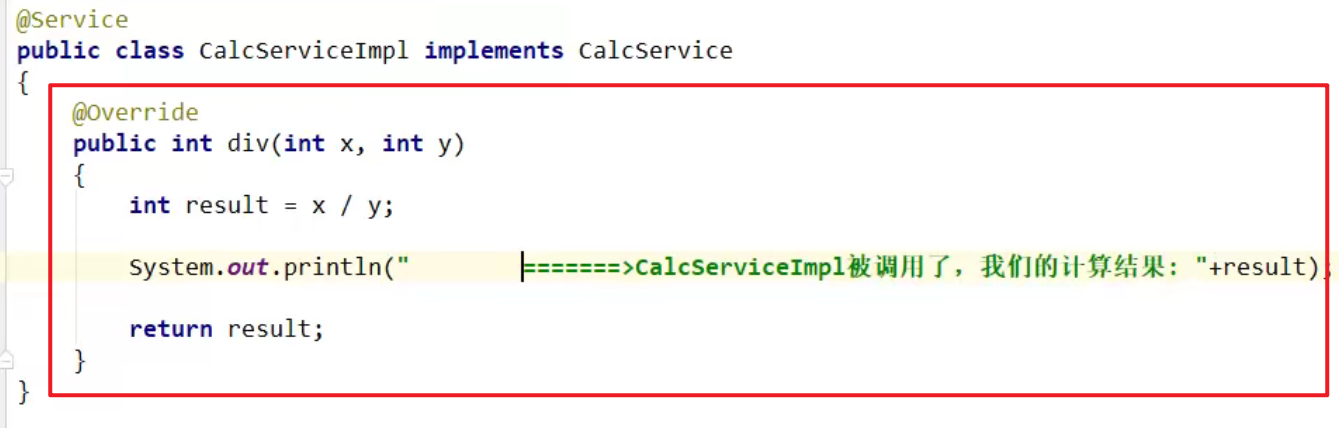
- Service类编程:
- 切面类编程:
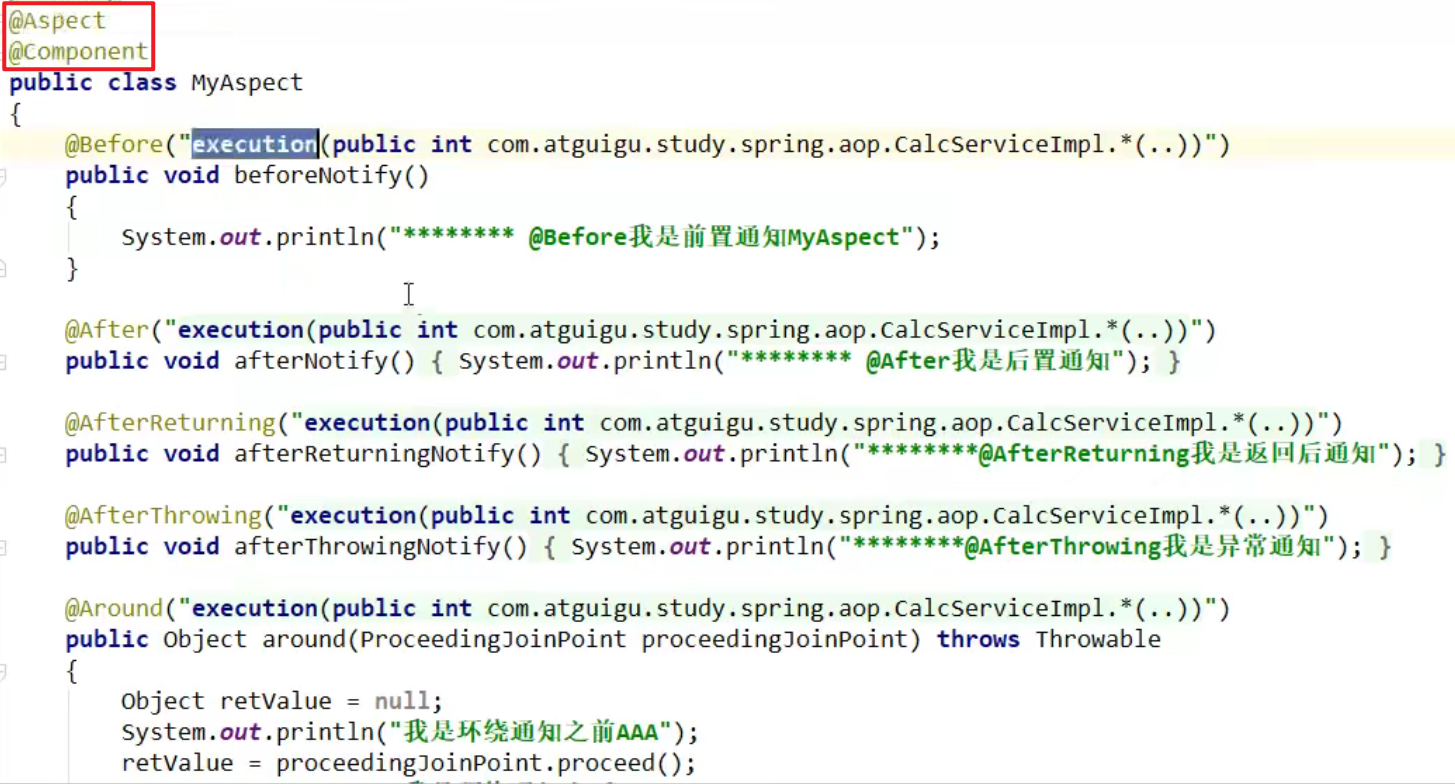
@Aspect,指定一个类为切面类
@Component,将其纳入Spring容器管理
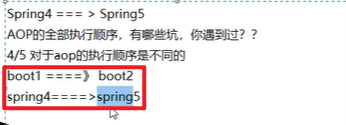
Boot使用1.x版本:
底层用的是本质上是Spring4嗷!!!!
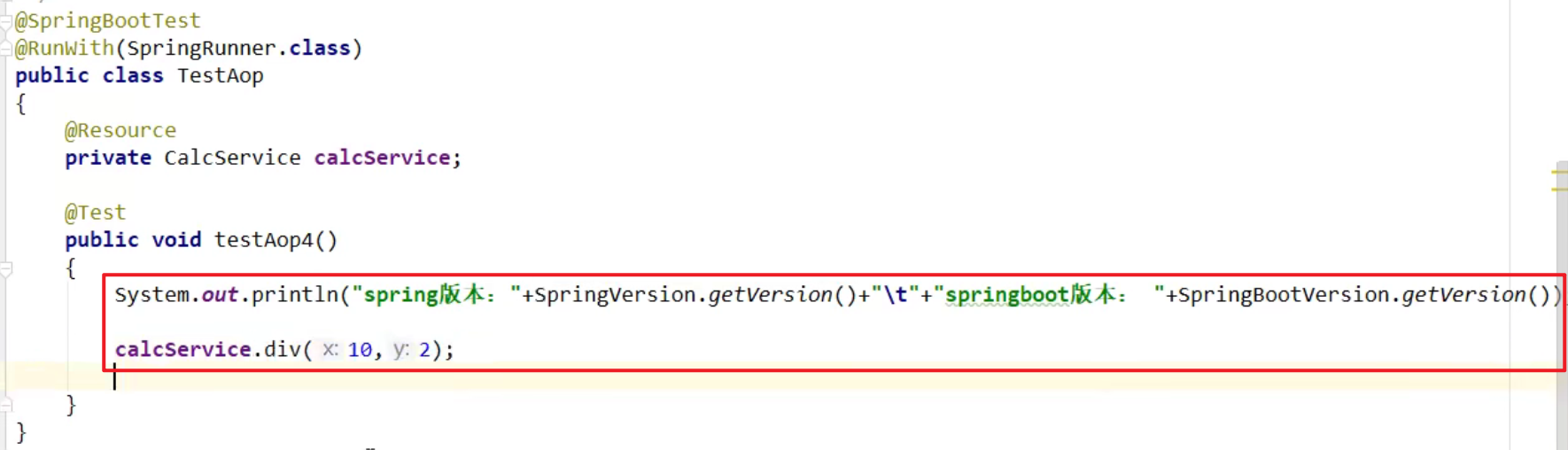
测试类编写:
- 结果:
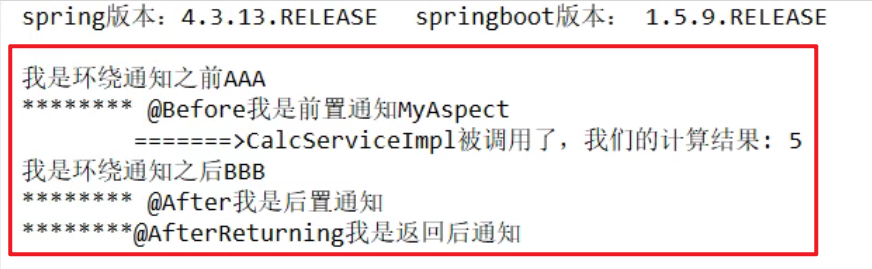

正常执行:@Before === @After === @AfterReturning
异常执行:@Before === @After === @AfterThrowing
至于环绕通知,正常的情况下在Before和After之前,异常的化只有Before没有After
Boot使用2.x版本:
- 底层用的是本质上是Spring5嗷!!!!
- 测试类和上面一样嗷!!!
- 结果:
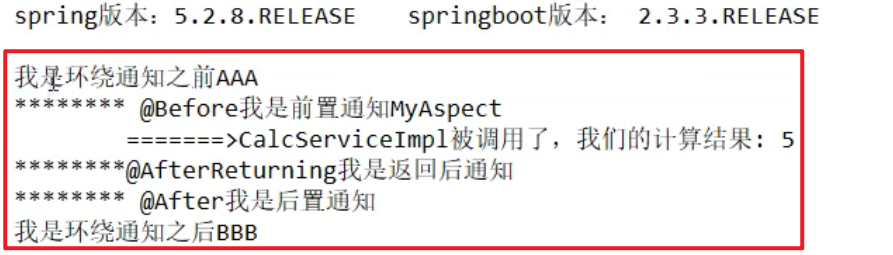
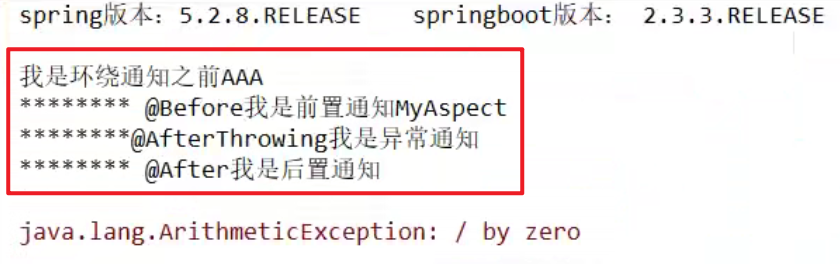
正常执行:@Before === @AfterReturning === @After
异常执行:@Before === @AfterThrowing === @After
@After的用法就和try … catch … finally 中的finally一样的嗷,这个是总会在最后执行的嗷!!!环绕通知就像饺子皮一样,包在最外面哦,如果出问题了,饺子皮被扯破了,就只有After兜着了嗷!!!
Spring循环依赖:
- 多个bean之间相互依赖,形成了一个闭环。比如A依赖于B,B又依赖于A。。。死锁了??????
- Spring如何解决循环依赖?一般是默认的单例Bean中,属性间相互依赖。
- 两种注入方式对于循环依赖的影响:
- 构造方法,对于循环依赖不友好嗷!!!一种可能的解决方法就是,通过配置set方法而不是构造方法注入嗷!!!
- 但是Set注入对于循环依赖就友好一些嗷!!!
- 当我们AB循环依赖问题只要A的注入方法是setter并且为Singleton,就不会有循环依赖问题嗷!!!
故障示例:
构造器导致循环依赖:
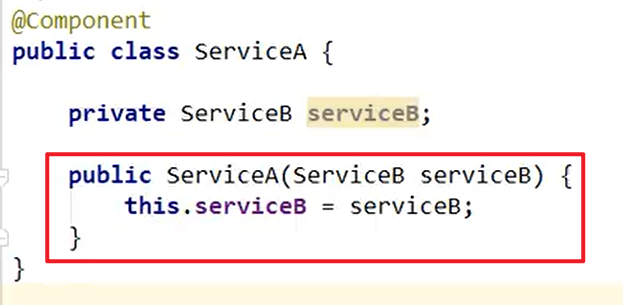


套娃了兄弟,构造器循环依赖了

Set解决循环依赖:
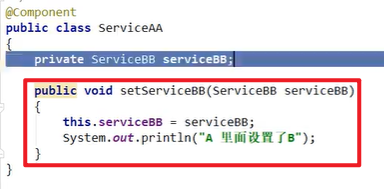
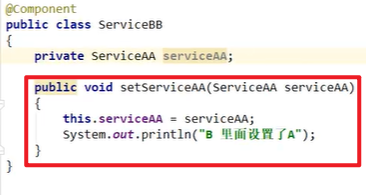
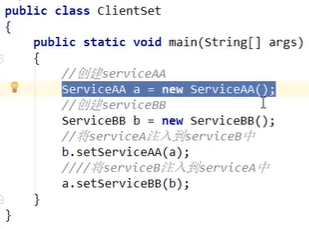
Set可以解决问题嗷!!!
Spring容器:
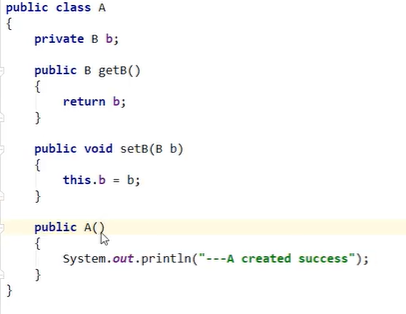
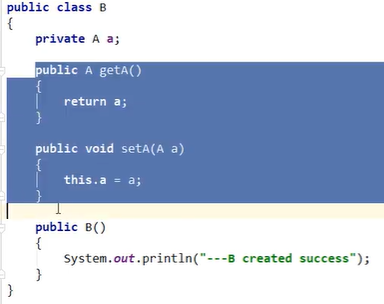
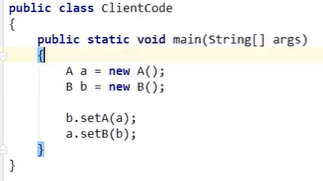
- 上面是code-Java的代码嗷!!!
- Spring容器中:
- 默认的singleton的场景是支持循环依赖的,不报错
- 原型Prototype的场景是不支持循环依赖的,会报错
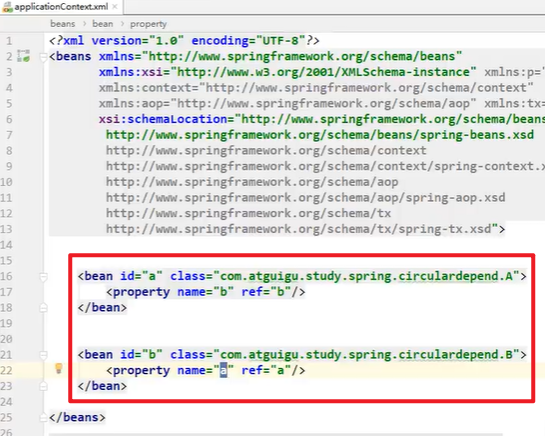
正常运行嗷!!!

改成prototype之后:
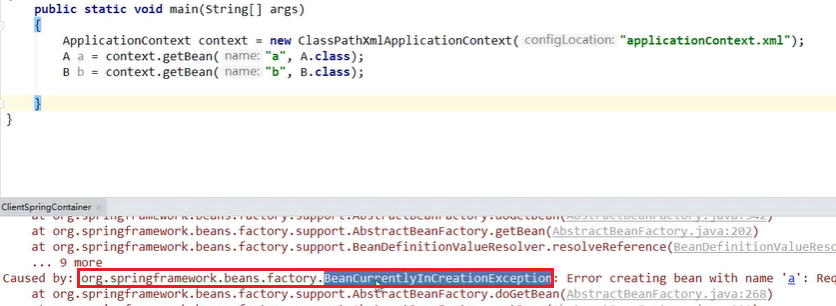

重要结论:
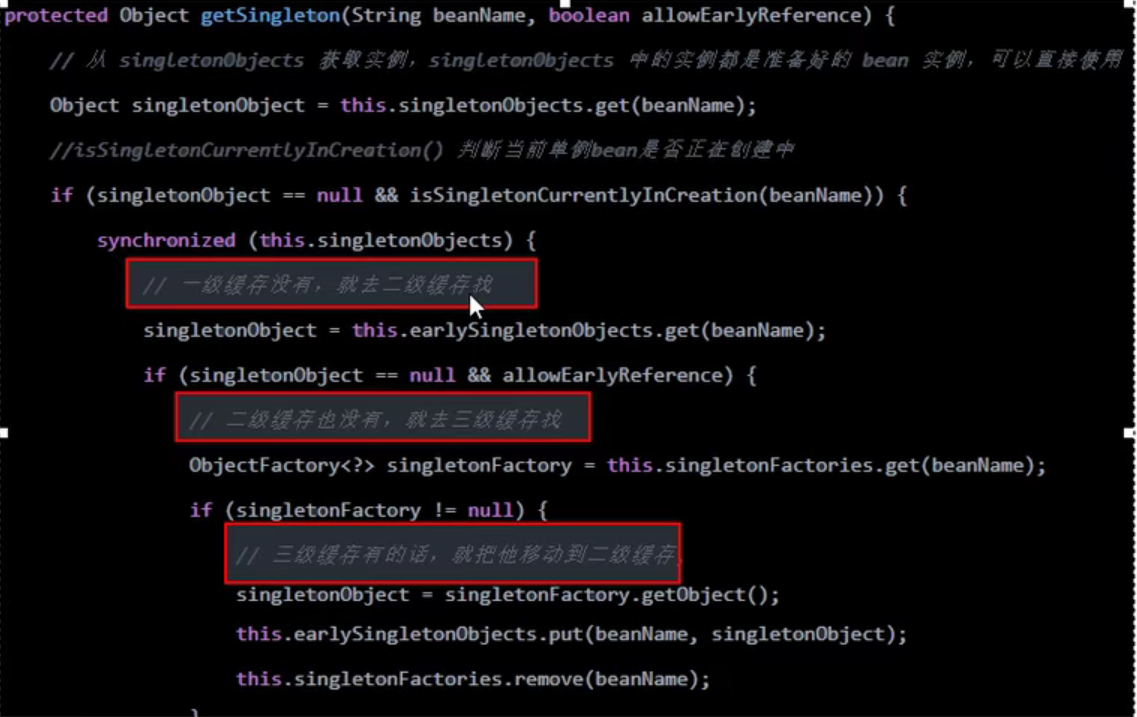
- Spring内部通过三级缓存来解决循环依赖嗷!!!
DefaultSingletonBeanRegistry- 本质上是三个Map嗷!!!
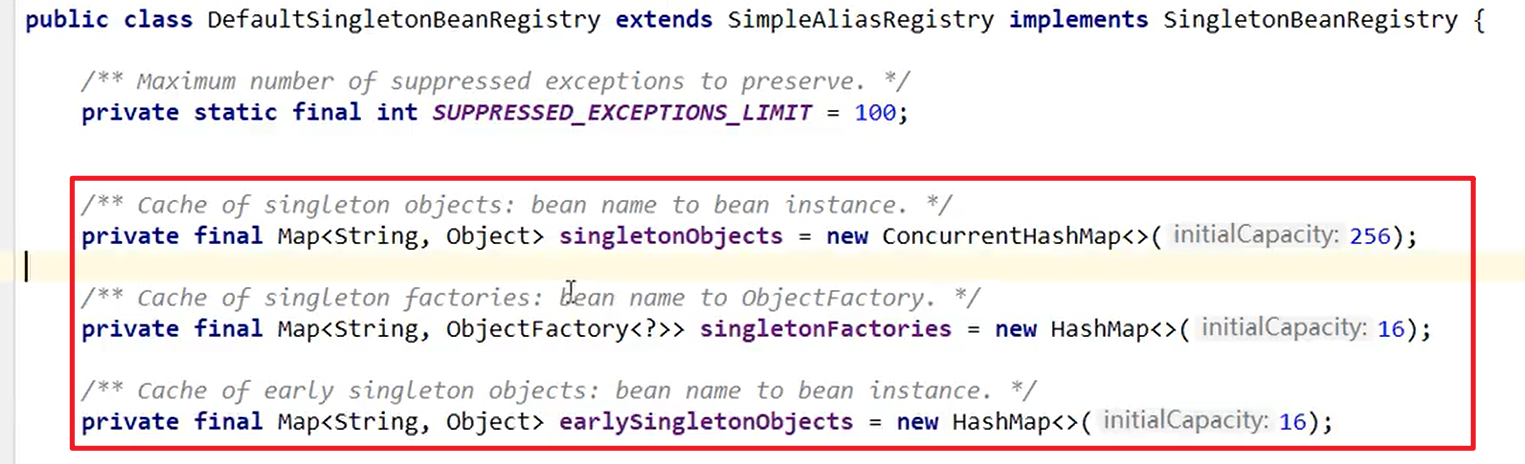
从上往下对应的缓存的顺序是,一级缓存,三级缓存,二级缓存嗷!!!
- 三级缓存:
- 一级缓存(单例池),singletonObjects,存放已经经历了完整生命周期的Bean对象。
- 二级缓存(earlySingletonObjects),存在早期暴露出来的Bean对象,Bean的生命周期未结束(属性还未填充完整的)
- 三级缓存(Map<String, ObjectFactory<?>> singletonFactories,存放可以生产Bean的工厂)
- 只有单例的bean会通过三级缓存提前暴露来解决循环依赖的问题。并非未单例的bean,每次从容器中获得一个新的对象,都会重新创建,所以非单例的bean是没有缓存的,不会将其放到三级缓存中嗷!!!
- 所以建议使用singleton单例模式来解决循环依赖的问题嗷!!!
循环依赖Debug-困难:
基本概念:
实例化和初始化的区别:
- 实例化:内存中申请一块内存空间。租好房子,自己的家具还没有搬进去。
- 初始化属性填充,完成属性的各种赋值嗷!!!
3个Map和四大方法:
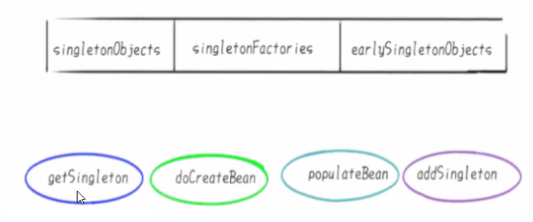
SingletonObjects存放的是已经初始化好了的Bean
earlySingletonObjects存放的是实例化了,但是没有初始化的Bean
singletonFactories存放的是FactoryBean,加入A类实现了FactoryBean,DI的时候不是A类,而是A类产生的Bean
- 迁移顺序:

断点查看源码:
打断点的位置是不固定的嗷,这种测试经常要看我们的日志的嗷!!!如果日志打印出来了,说明断点打晚了,把断点往前打就成嗷!!!
Spring中的do开头的方法才是真真正正的实际方法,干实事的嗷!!!
牛啊!!!
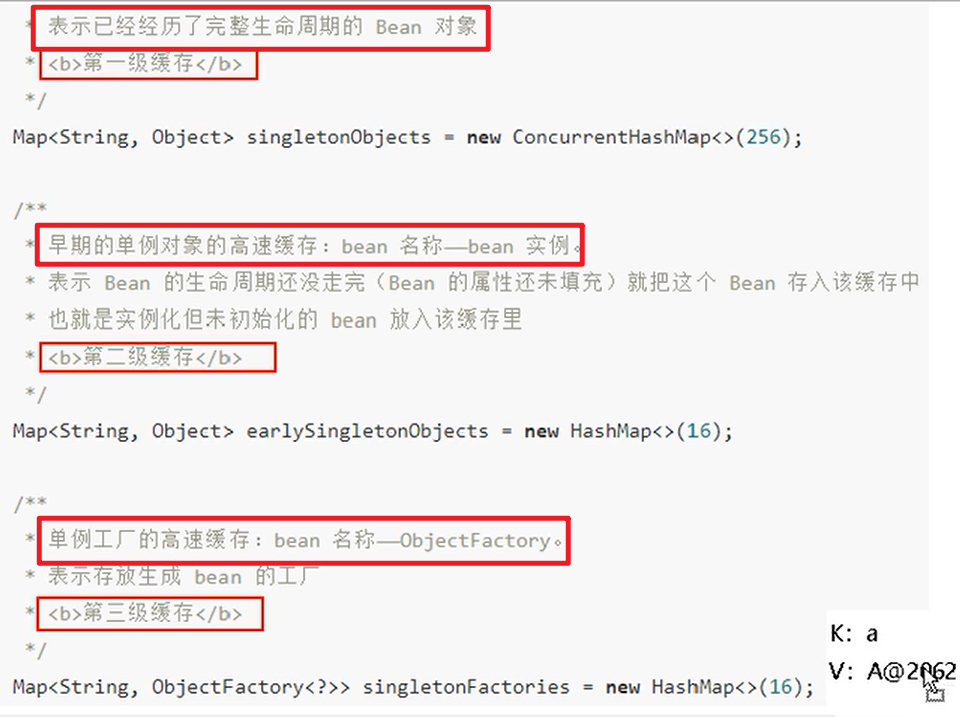
三级装的是还没实例化好的对象。
二级中装的是实例化但是没有初始化的对象。
一级中装的是初始化完成的对象。
精简版总结:
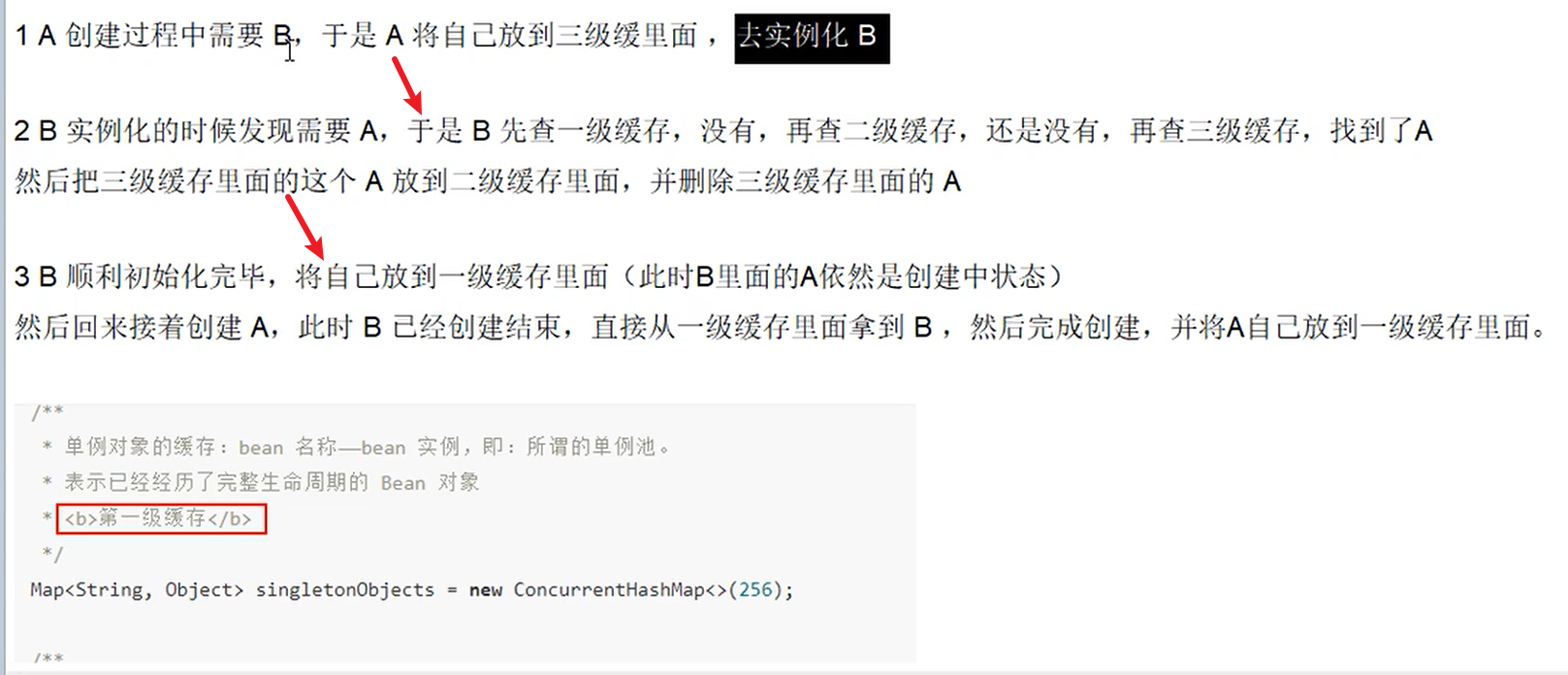

- 断点在哪里呀?
小总结:


Redis:
五大类型落地应用:
小细节说明:
- 命令是不区分大小写的,但是我们插入的key是区分大小写的嗷!!!
help @类型名称
例如:help @string
String的落地使用:
- 命令使用:
- set和get
- 获取多个键值

这里的m就是more的意思,可以同时插入/查找多个键值
- 数值增减:

- 获取字符串的长度:
STRLEN key
- 分布式锁:
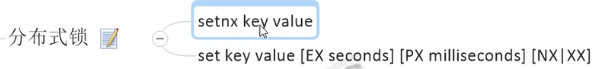

- 查看key的寿命:
ttl keyName
使用场景:
- 喜欢的商品点赞数/踩:
每次点赞,对应的商品所对应的key就+1:
INCR items:1商品编号,订单号采用INCR命令生成
- 文章喜欢数量,浏览数量
和上面一样用的是INCR
使用非常广泛嗷!!!
Hash的落地使用:
- Redis中的Hash在Java中是如何表现的?
Map<String , Map<Object,Object>>
- 命令使用:
- HSET key field value
- HGET key field
- HMSET key field value [field value …]
- HMGET key field [field ….]
- hgetall key:获取所有字段值
- hlen:获取某个key内的全部数量
- hdel:删除一个key
使用场景:
- 简单版的购物车,快递,订餐之类的(中小厂可以使用):
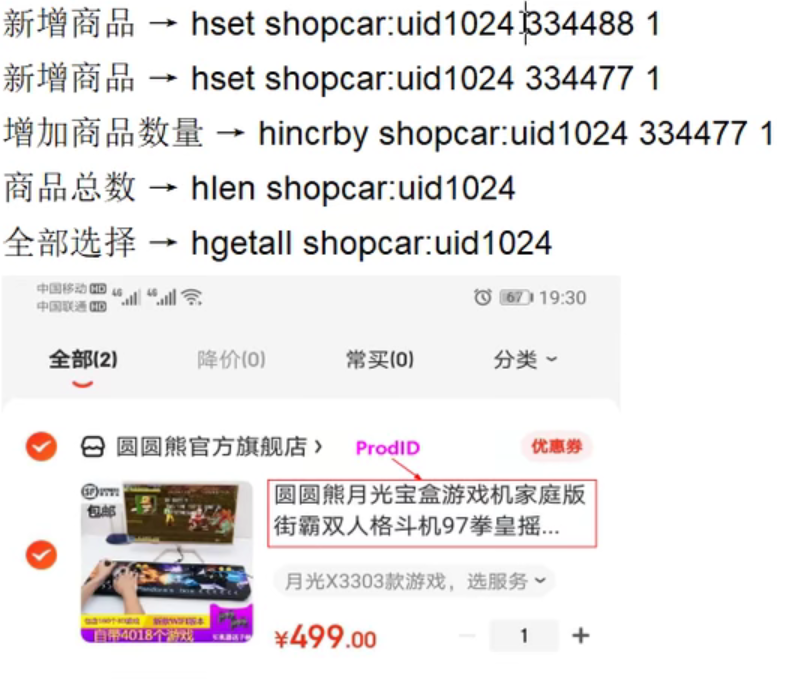
商品总数指的是,我们选中的商品有哪些嗷!!!
List的落地使用:
- 命令使用:
- lpush key value [value …]
- rpush key value [value …]
- lrange key start stop:
lrange key 0 -1 就是全部遍历嗷!!! - llen key
使用场景:
- 微信文章订阅公众号

关注的作者推送的文章全部塞进你的list里面,然后从上往下进行排序,一次显示几条这样子的嗷!!!List刚刚好就可以把最新更新的放在最上面,供我们观看嗷!!!
Set的落地使用:
- 无序无重复
- 常用命令:
SADD key member [member …]
SREM key member [member …]
SMEMBERS key:获取集合中的所有元素
SISMEMBER key member:判断元素是否在集合中
SCARD key:获取集合中的元素个数
SRANDMEMBER key [数字]:集合中随机弹出一个元素,元素不删除。数字不写默认就是一个,不然就是数字个数嗷!!!
SPOP key [数字]:集合中随机弹出一个元素,出一个删一个。数字不写默认就是一个,不然就是数字个数嗷!!!
DEL key:删除某个Set嗷!!!
集合运算:

应用场景:
- 微信抽奖小程序
SRANDMEMBER和SPOP经常使用嗷!!!
sadd 抽奖活动对应的key 参与抽奖的用户IDscard 抽奖活动对应的key显示参与抽奖活动的人数spop 抽奖活动对应的key number抽出用户
- 微信朋友圈点赞:

- 微博好友关注社交关系:
比如我们常见的,xxx位好友已关注:
本质上就可以使集合的交运算嗷!!!

关注的人也关注过:

- QQ内推:

你和我去掉我们的共同好友,就是我们可能想要相互认识的人嗷!!!Inter就是我们都认识的人,Diff就是我们其中一边认识的人嗷!!!
Set对于电商,社交关系查找和社交推荐都有很大的作用嗷,威力很大的嗷!!!
ZSet的落地使用:
- 向有序的集合中加入一个元素和该元素的分数
- 常用命令:

ZADD zset1 100 mov1 20 mov2
- ZRANGE key start stop [WITHSCORES]
按照元素分数从小到大的顺序,返回索引从start到stop之间的所有元素
- ZSCORE key member:获取元素的分数
- ZREM key member [member …] 删除元素
- ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] 获取指定分数范围的元素
- 增加某个元素的分数:ZINCRBY key increment member
- 获取集合中元素的数量:ZCARD key
- 获得指定分数范围内的元素个数:ZCOUNT key min max
- 按照排名范围删除元素:ZREMRANGEBYRANK key start stop
- 获取元素排名:
- ZRANK key member
- ZREVRANK key member
使用场景:
- 定义商品销售排行榜:

- 抖音热搜:
key使固定的,score一致在变,然后排序显示热榜就成嗷!!!

分布式锁:
- 加锁:
- JVM层面的加锁。
- 分布式微服务架构,拆分后各个微服务之间为了避免冲突和数据故障引入的一种锁。(分布式锁)
两个不一样,一个是单机版,另外一个是分布式的嗷!!!
- 实现方式:
- mysql
- zookeeper
- redis
Redis分布式锁
- 一般的互联网公司,习惯使用redis做分布式锁
redis —– redlock ===> redisson lock/unlock的分布式锁
- 常见面试题:

Boot整合Redis:
- 过程:
- 建Module
- 改POM
- 写YML
- 主启动
- 业务类
- POM配置:

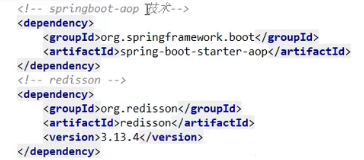
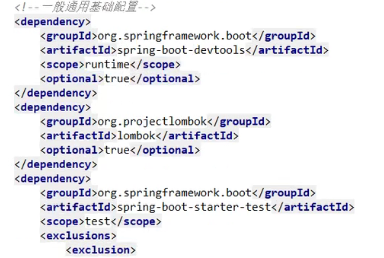
- 写Yaml:
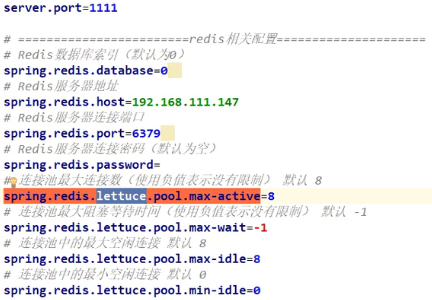
主启动自动就是好的嗷!!!
业务类:
- 为了使用RedisTemplate,我们需要将其注入到容器中来嗷!!!
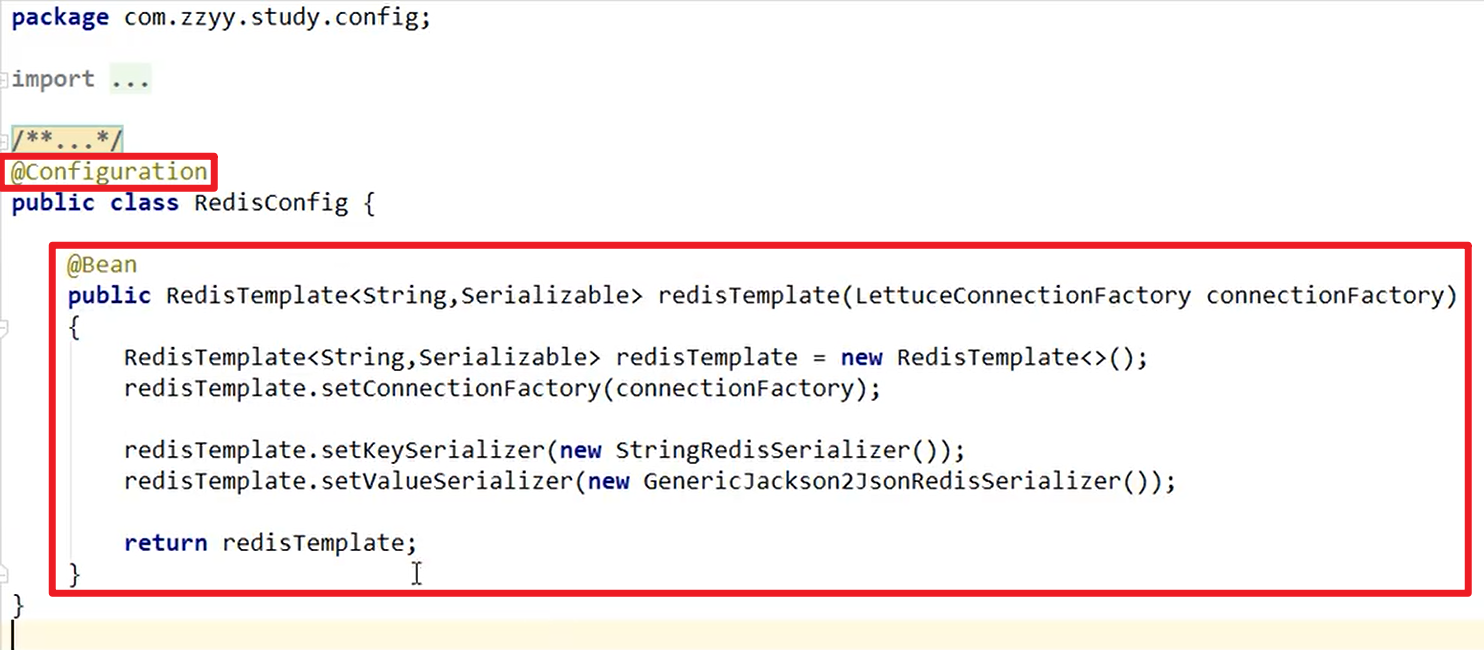
- 真正的业务类:
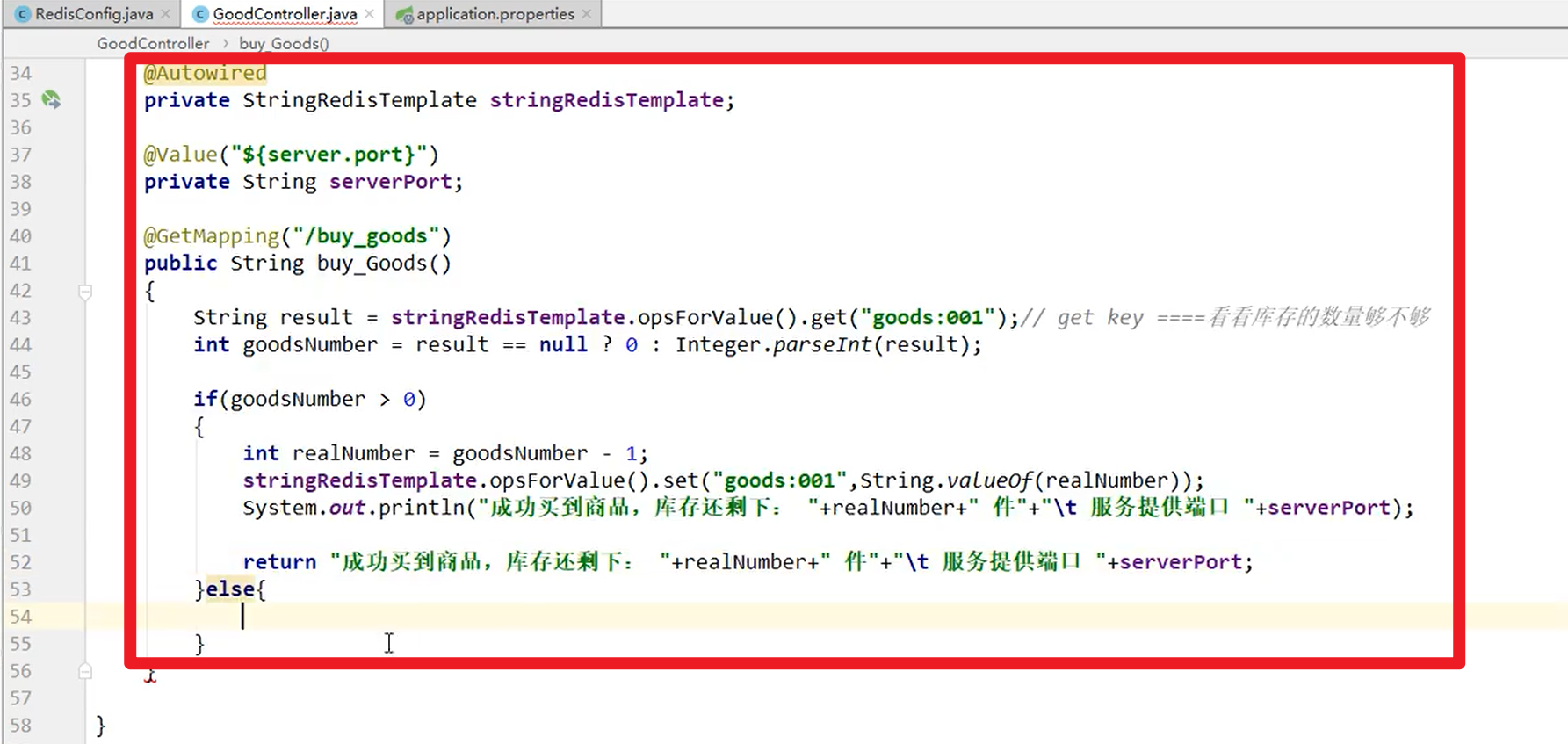
注入小工具,我们对于Redis进行操作
启动两台机器,代码都是一样的,只有端口不一样哈!!!
大家来找茬:
1. 单机版没有加锁
- 加锁加什么?
- sync和reentrantlock如何选择?
- sync叫不见不散,一定等到你其中的线程挂了或者执行完了,才能离开,容易造成 线程积压
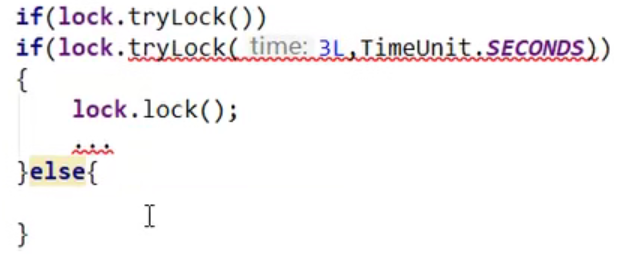
- reentrantlock叫过时不候,可以采用tryLock方法尝试获取锁。如果获取到了就执行,获取不到就放弃嗷!!!更加友好:

2. 单机锁出现超卖现象
- 启动Nginx并且测试通过嗷!!!

JMeter一压测,立马就出现超卖现象了嗷!!!
why?
- Nginx微服务架构的时候,同一个微服务会部署到不同的机器上
- 这个使用synchronized这样的锁,在不同的机器中是不同的this,都不是同一个锁,当然会出现问题嗷!!!
解决:
- 上redis的分布式锁setnx,Redis性能极高,且命令十分友好,借助SET命令就可以实现加锁处理嗷!!!
代码:
下面这个setIfAbsent就是setnx嗷!!!没啥区别,这儿就是先尝试去加锁,由于Redis中是单线程,操作都是原子操作嗷!!!
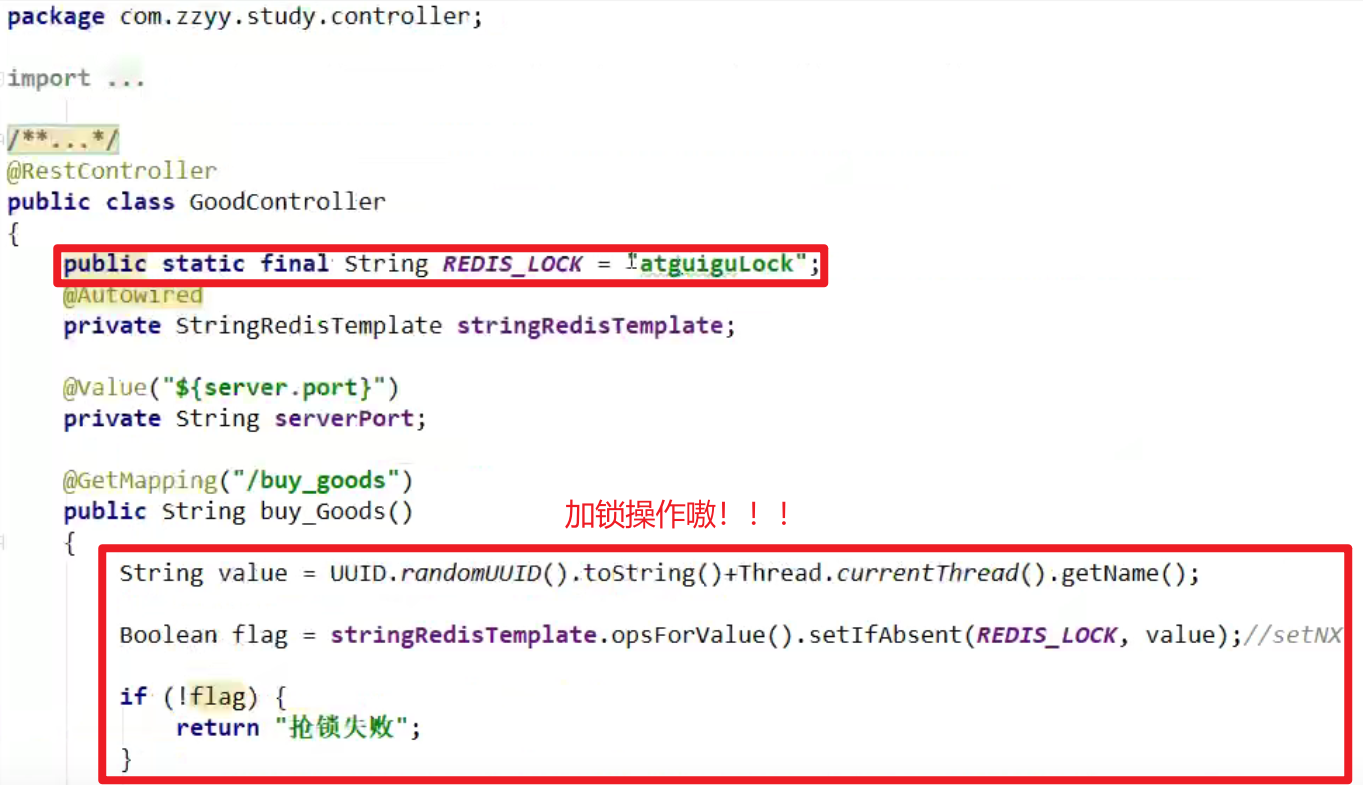
架构图是一个Nginx,两台Server,连接同一个Redis,这里就在Redis通过setnx这种操作来实现了加锁,十分简单方便嗷!!!
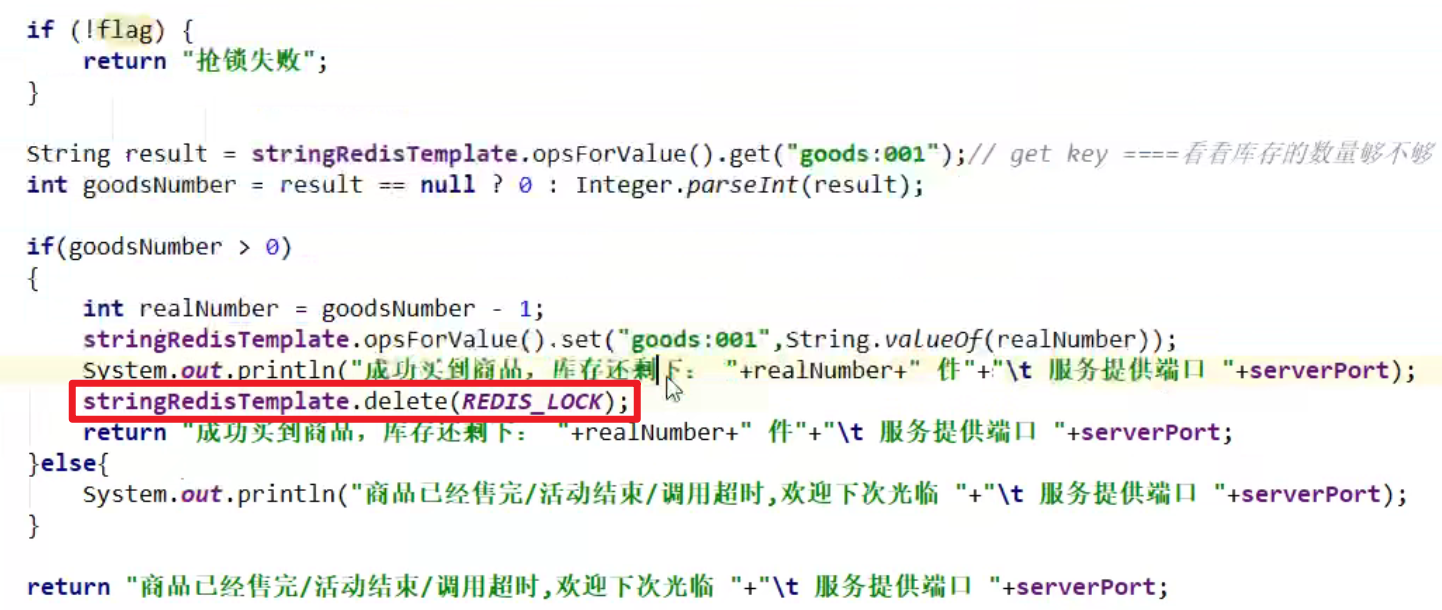
3. 锁出问题没有释放诶!
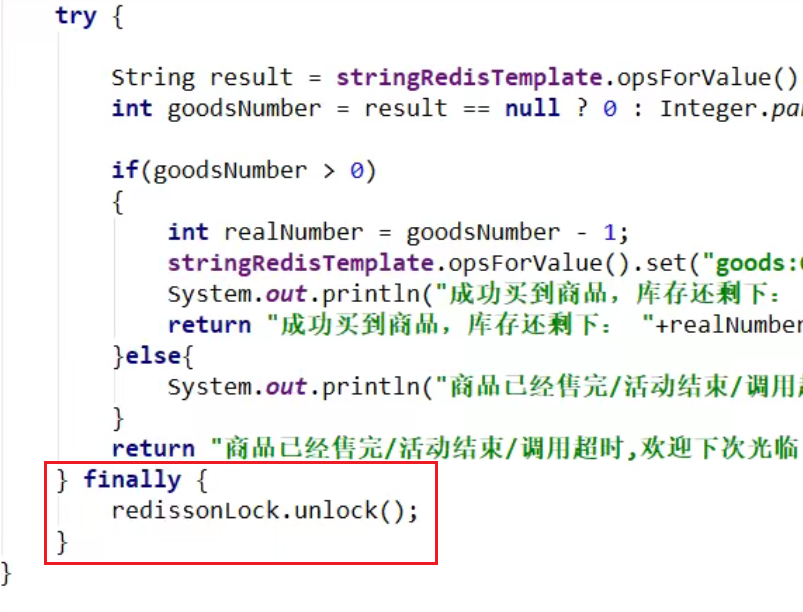
- 如果在业务代码执行间出错了,那么锁就一直解不了嗷,会造成非常大的问题嗷!!!
- 代码层面要加上try…finally…,解锁的时候一定要养成这个意识嗷!!!
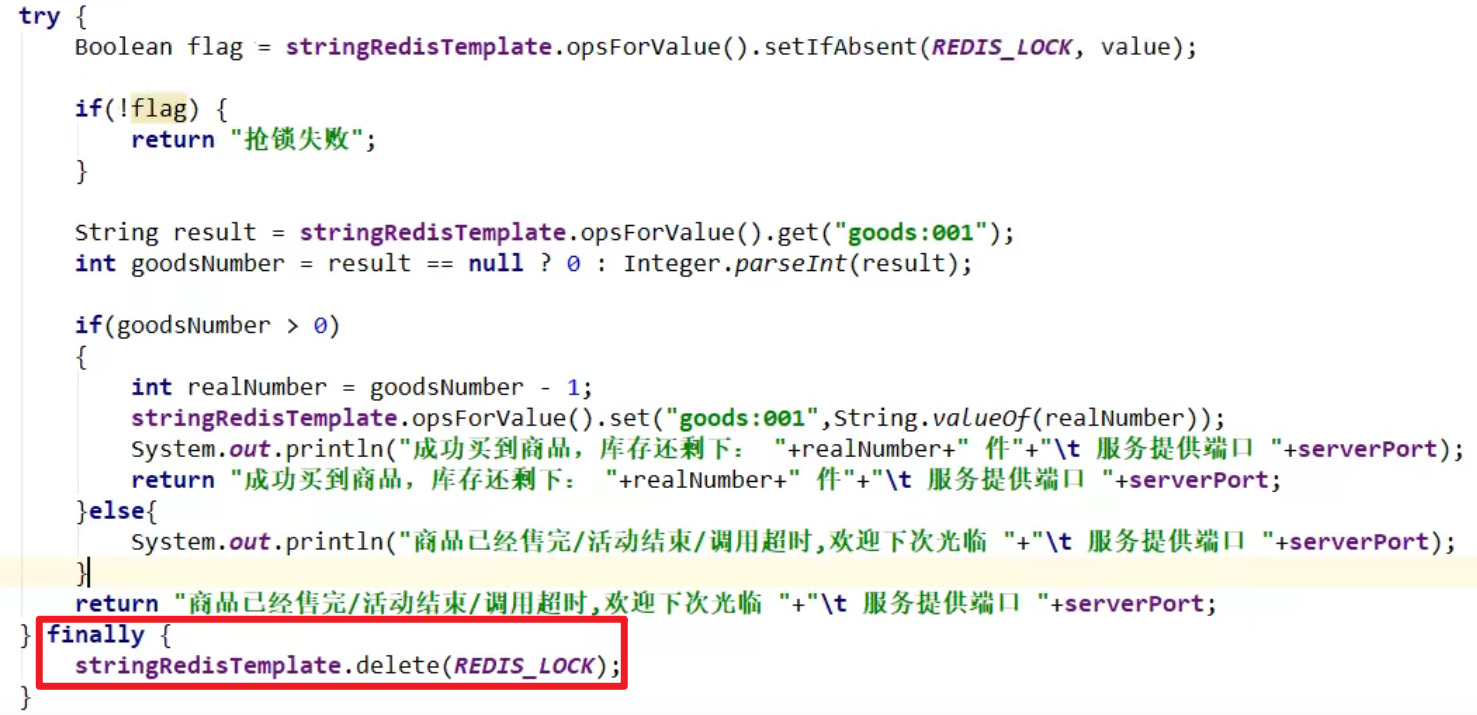
4. 宕机了orz
- 宕机了,机器根本走不到finally,裂开。代码层面保证了,硬件出现问题了嗷orz,这该咋办捏???
- 万全之策:对于加的这把锁设置一个过期时间嗷!!!就算出现问题的话,一段时间后也能够自行解决嗷!!!
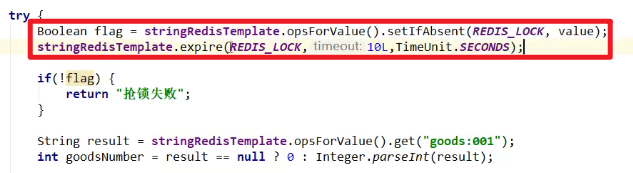
5. 加锁和设置过期时间
- 不在同一行啊啊啊啊
- 你前面设置了锁,还没来得及设置过期时间,然后机器就宕机了,不一样程序无法继续正常执行了嘛orz。
- 高并发一定要把原子性考虑清楚嗷!!!
- 问题:设置key + 过期时间分开了,必须要合并成一行并且具备原子性嗷!!!
- 解决:
- LUA脚本嗷!!!
stringRedisTemplate.opsForValue().setIfAbsent(key,value,10L,TimeUnit.SECONDS)就可以使用这一条原子指令一次搞定嗷!!!
6. 运行潜在隐患
- 业务逻辑没有完成,锁就过期了,这就导致并发冲突了orz,着很大的问题啊orz。A堵住了,A加的锁过期了,B进来了,诶,A又好了,A比B跑得快,A把B加的锁直接给释放了orz,这是个非常大的问题嗷!!!
- 张冠李戴,释放了别人的锁。这是非常严重的bug嗷!!!
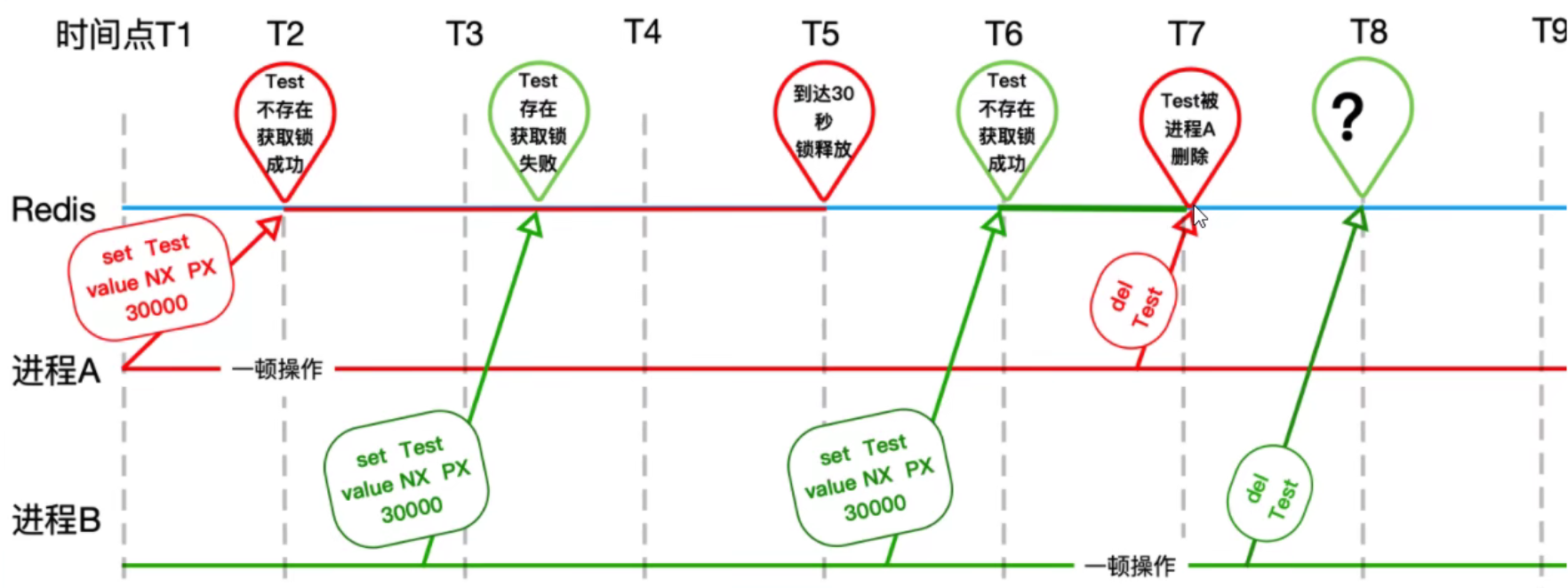
- 解决:
- 判断一下,只能删除自己的锁嗷!!!
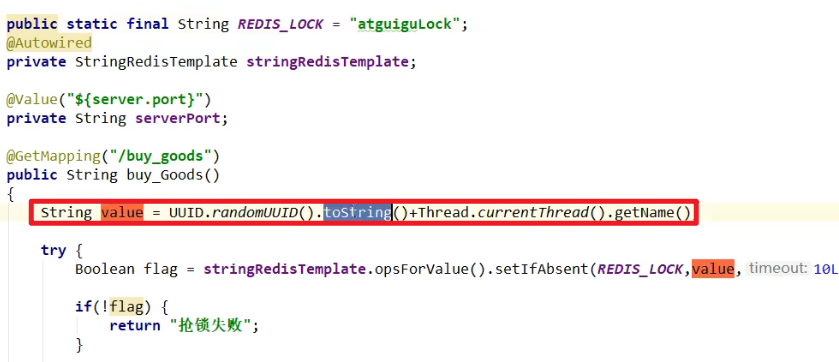
每一个value都是每个线程自己的,都是不一样的嗷!!!

释放的时候判断一下,这个锁对应的值是不是自己的,只有自己的才能够释放嗷!!!
7. 删除的原子性又裂开了

- 你判断为true,然后进来了,然后刚好锁过期了,别的线程加了一把锁,这就导致,你又把别人的锁释放了orz。
- LUA脚本来保证原子性!!!
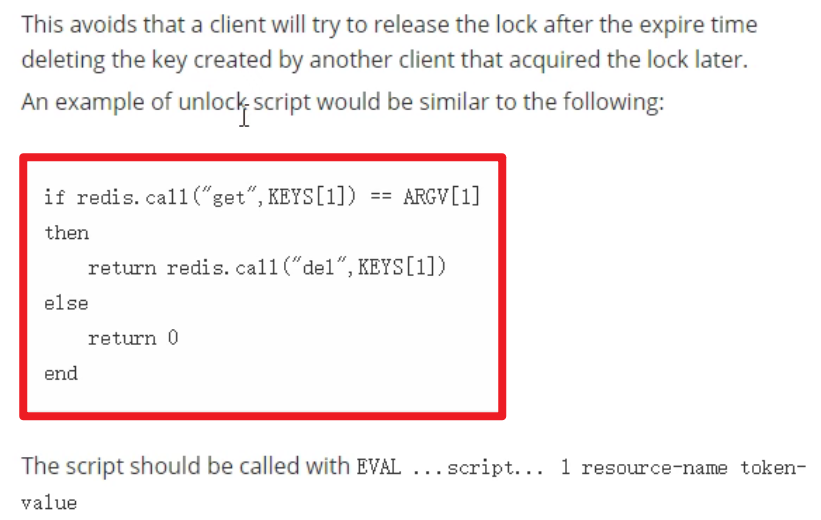
不可以用LUA脚本,怎么解决呢???
- Redis也有事务哇!!!



- 事务实例:
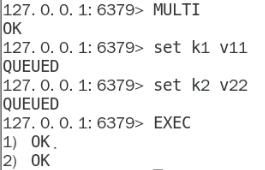
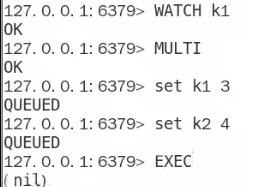
Watch指令可以监控某一个key,如果这个key被人动过了的话,那我的修改就会失败嗷!!!(乐观锁)
- 修改结果:

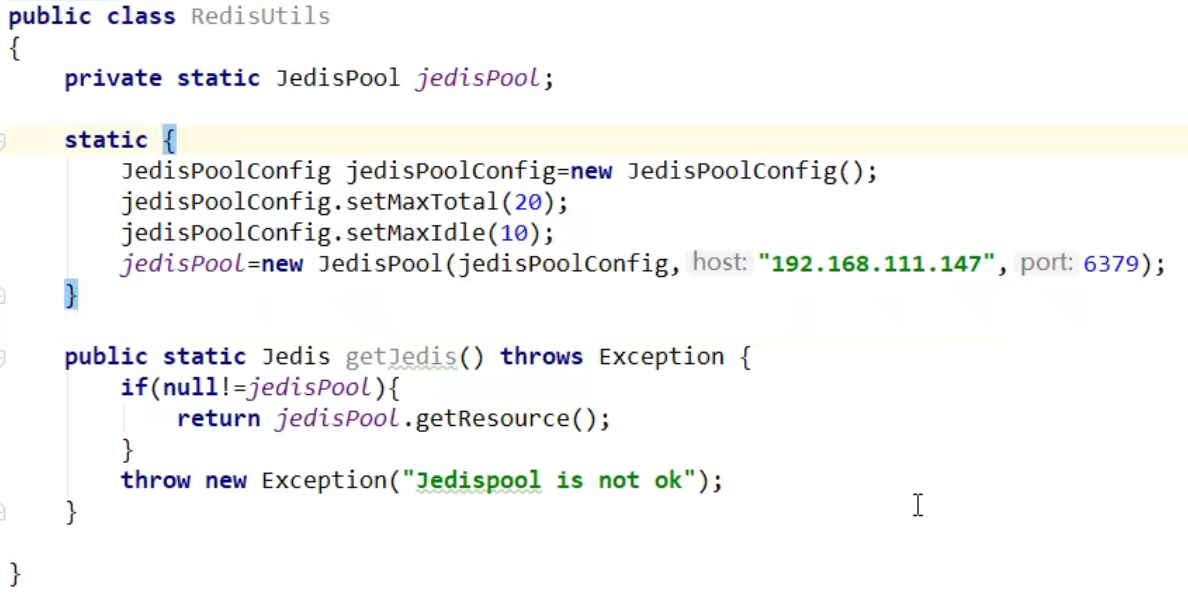
- 那LUA脚本如何使用呢?
- 编写Jedis工具类:
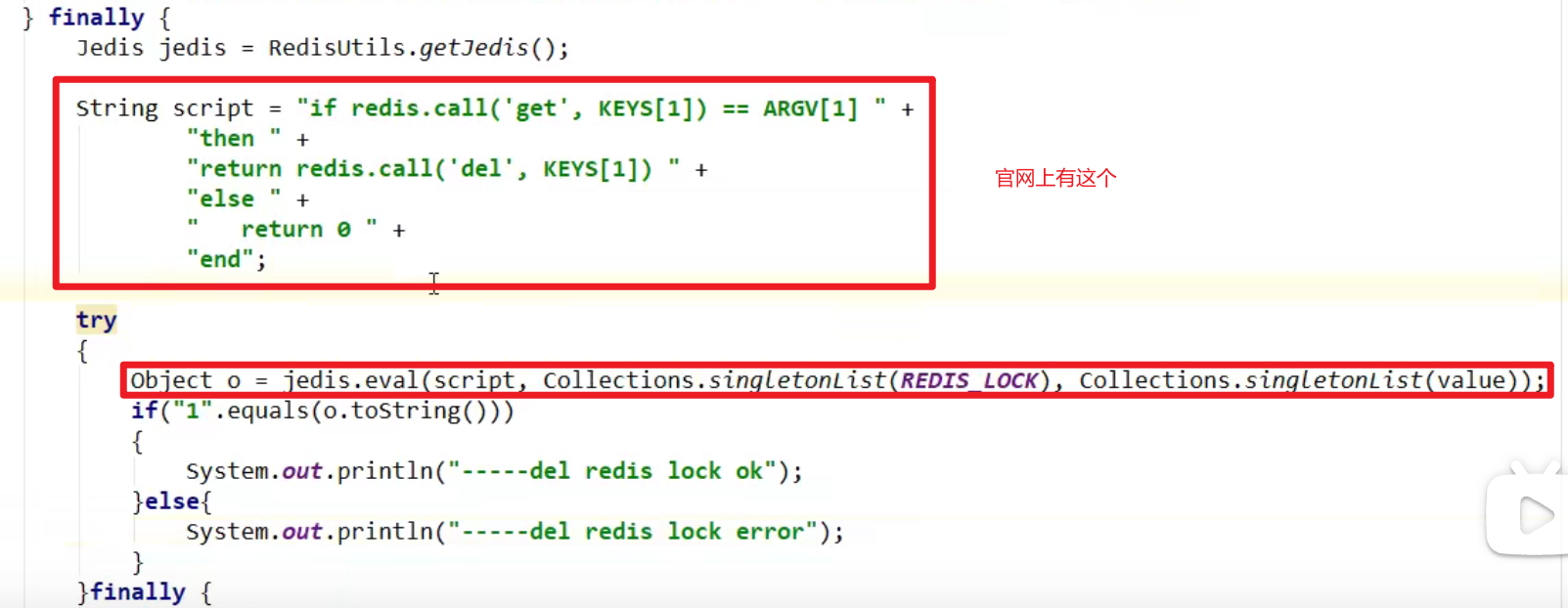
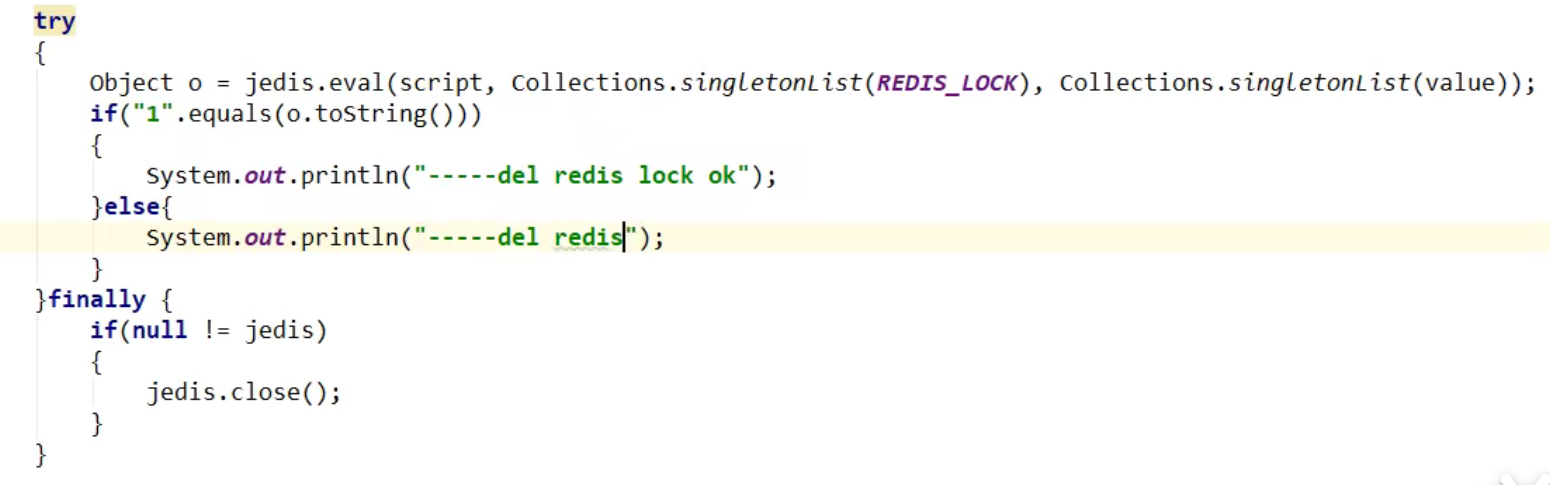
- finally中使用LUA脚本完成对应键值对的删除:
8. Redis锁的续期问题
如果对应的锁没有续期,就可能会导致并发冲突嗷!!!
解决方法:缓存续命!!!
还可能有很大的问题!!!

Redis为了保证AP,实际上是牺牲了一部分的C的嗷!!!
ZooKeeper就不一样嗷!!!ZooKeeper就是保证了CP,牺牲了C嗷!!!
理论是Zookeeper好,但是实际上redis保证了高可用性嗷!!!
正式为了解决Redis所面临的C的牺牲问题,才有了我们后面的RedLock之Redisson的落地实现嗷!!!
Redisson的使用:
- 将Redisson添加到容器中:
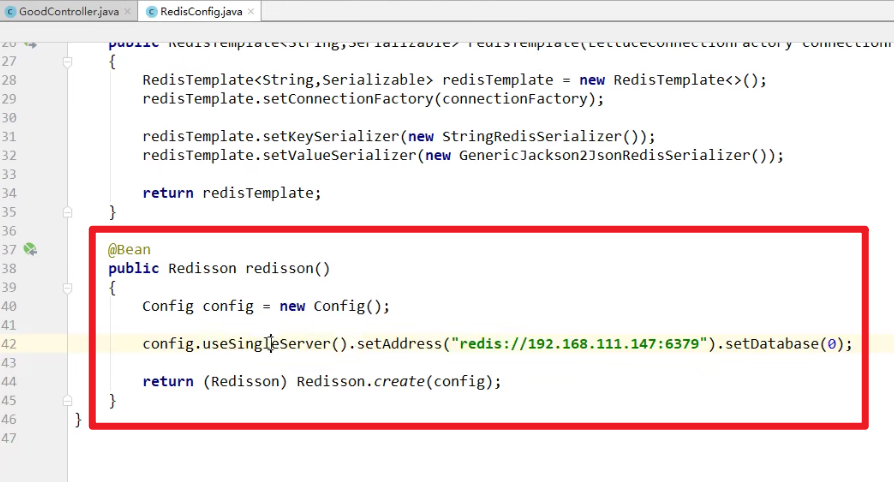
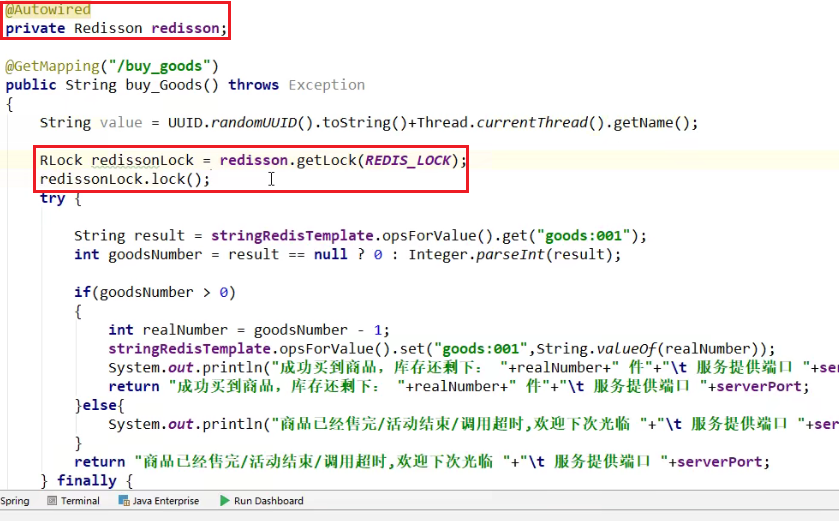
- 重写业务代码:
不用再苦苦自己考虑逻辑加锁了,也不用考虑原子性了,直接上大招!!!
- JMeter压测也没啥问题嗷!!!
9. unlock有问题
- 超高并发的情况下,可能会报出异常:
attempt to unlock lock, not locked by current thread by node id: xxx 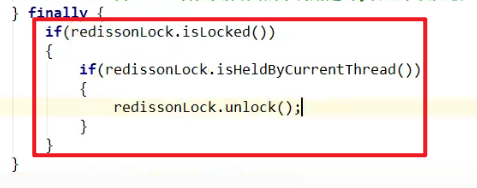
或者下面这个:

上面这个健壮性会好一些嗷!!!
Redis缓存过期淘汰策略
Redis内存满了咋办:
查看Redis最大内存:
- 可以看redis的内存有多少:
- 配置文件
- 命令行命令

注意:maxmemory是bytes字节类型,要注意转换嗷!!!
- 859行默认是被注释掉的,没有配置嗷!!!这样才能够多吃多占,充分利用性能嗷!!!
生产上如何配置:
- 类似于HashMap底层的负载因子是0.75,推荐Redis设置为最大物理内存的四分之三。
设置内存大小:
- 配置文件:

- 命令行配置:
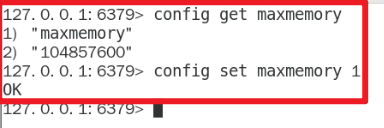
- 查看内存使用的命令:
在客户端中输入info memory就可以查看嗷!!!
内存超出最大值会咋样?(内存打满):
- 可以故意把最大值设置为1个byte来试试嗷!!!


内存淘汰策略:
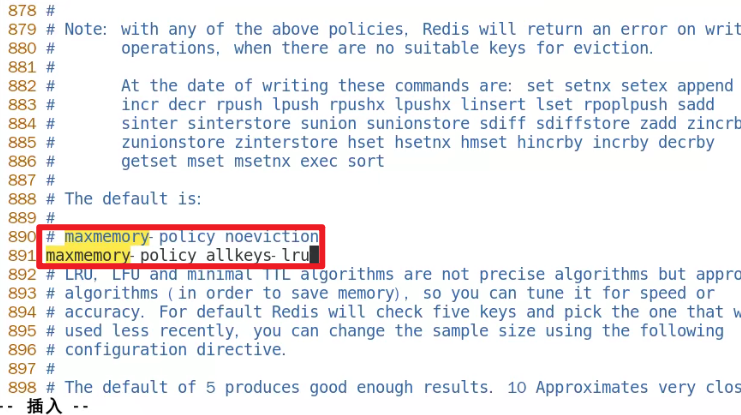
- 配置文件中有写嗷:

- 默认使用的是:
maxmemory-policy noeviction,不驱逐任何东西,当内存满了的时候,只会返回一个在写操作上的错误。
过期键的删除策略:
过期了,马上就从内存中清除了吗?打咩!!!
三种删除策略:
定时删除:保证过期后马上被删除,但是对于CPU不友好,CPU得一直盯着,忙死orz。会产生大量的性能消耗,影响数据的读取操作。用时间换空间,用处理器性能换取存储空间。
惰性删除:数据到达过期时间不处理。下次访问,如果未过期,返回数据。发现已经过期,删除,返回不存在。对于内存是最不友好的嗷!注意,过期的被访问的才被删除,恰好没有被访问的话,除非手动,否则也许永远不会删除。可以看作是 内存泄露 。
定期删除:前面两者的折中,每隔一段时间执行一次删除过期键的操作。周期性轮询redis库中的时效性数据,采用随机抽取的策略,利用过期数据占比的方式来控制删除频度。
特点1:CPU性能占用设置有峰值,检测频度可以自定义设置。
特点2:内存压力不是很大,长期占用内存的冷数据会被持续清理。
依旧有漏网之鱼嗷!!!
为了兜底,缓存淘汰策略登场!!!
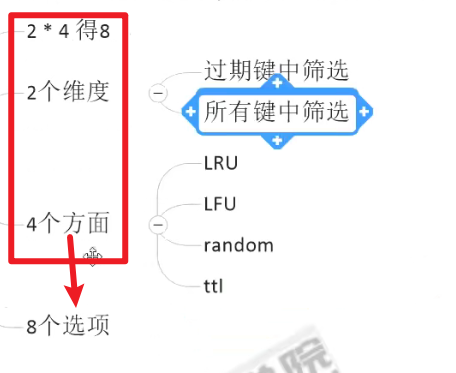
所有策略:

LRU和LFU是两种完全不一样的东西嗷!!!LRU有两个,一个是对于所有过期键筛选,另外一个是对于所有key筛选。
平时使用:
最常用是
allkeys-lru,不要用默认的嗷!!!如何配置:
也可以:
config set maxmemory-policy allkeys-lru
config get maxmemory-policy
查看内存相关配置:info memory
LRU简介:
Leetcode咱还刷过这道题目嗷,记得再回去康康嗷!!!
Least Recently Used
设计思想:
- O(1) : HashMap
- 排序加上插入和删除快:LinkedList
- 核心就是哈希链表
实现:
- LinkedHashMap:
源代码中:
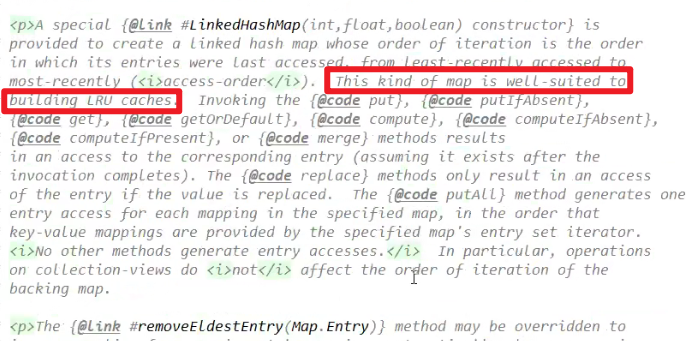
手写LRU算法和继承LinkedHashMap的内容建议上LeetCode自己复习嗷!!