哈工大操作系统
本文最后更新于:2 年前
这里对于操作系统面试内容的准备课程嗷!(来自于哈工大!!!)
第一章(启动):
什么是操作系统:
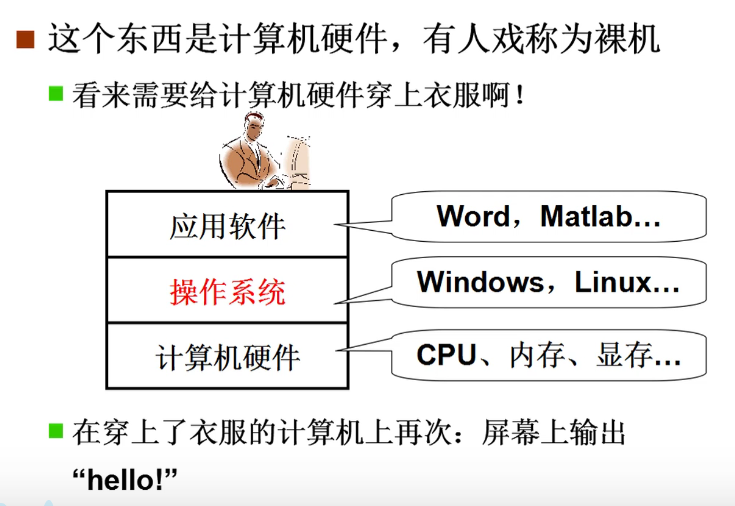
操作系统就是在计算机硬件上包了一层软件,方便我们使用硬件的!!!
管理哪些硬件:
- CPU
- 内存
- 终端
- 磁盘
- 文件
- 网络
- 电源
- 多核
学习什么?
- 掌握计算机关键技术的工程师
揭开钢琴的盖子:
- 冯诺依曼提出的存储程序的思想
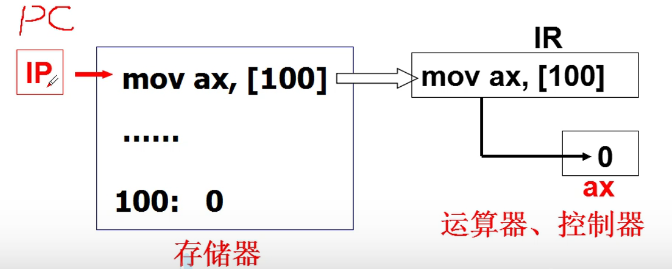
非常基本的尝试,将程序放入存储器,用指针指向代码,通过代码来执行。
取指执行
x86结构:
- ROM BIOS是固化的!!!(Base Input Output System就是固化的)
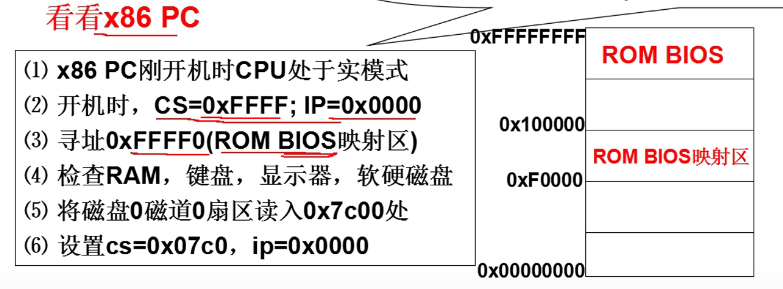
- 固化的这部分的内容,在电脑开机的时候,就会自动执行嗷!!!
- 0磁道0扇区,就是操作系统的引导扇区嗷!!!这是操作系统的第一段代码。

汇编:
- 不像C语言,可以对于操作系统的每一处地方进行完整的控制嗷!!!
启动过程汇编代码解析:

jmpi

- BootSect上半部分的代码把自己挪动了一下,腾出了空间嗷!!!上面的jmpi本质上就是跳到了一下段代码go,本质上还是顺序执行嗷!!!
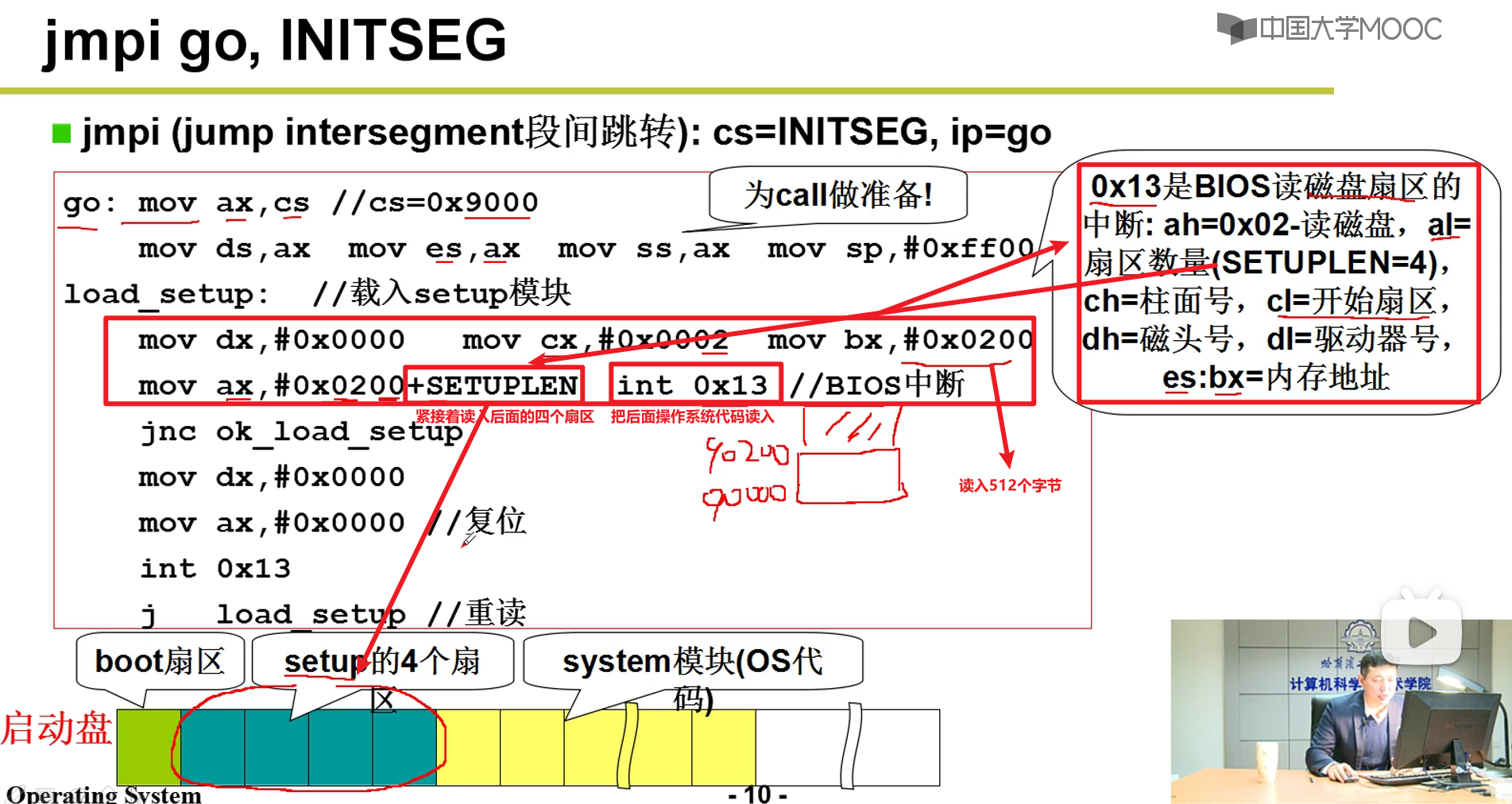
因为一个传统的硬盘扇区的大小就是512个字节嗷!!!
- 下面打印出了图标嗷!!!

- 下面就是跳转到了read_it部分的代码嗷!!!
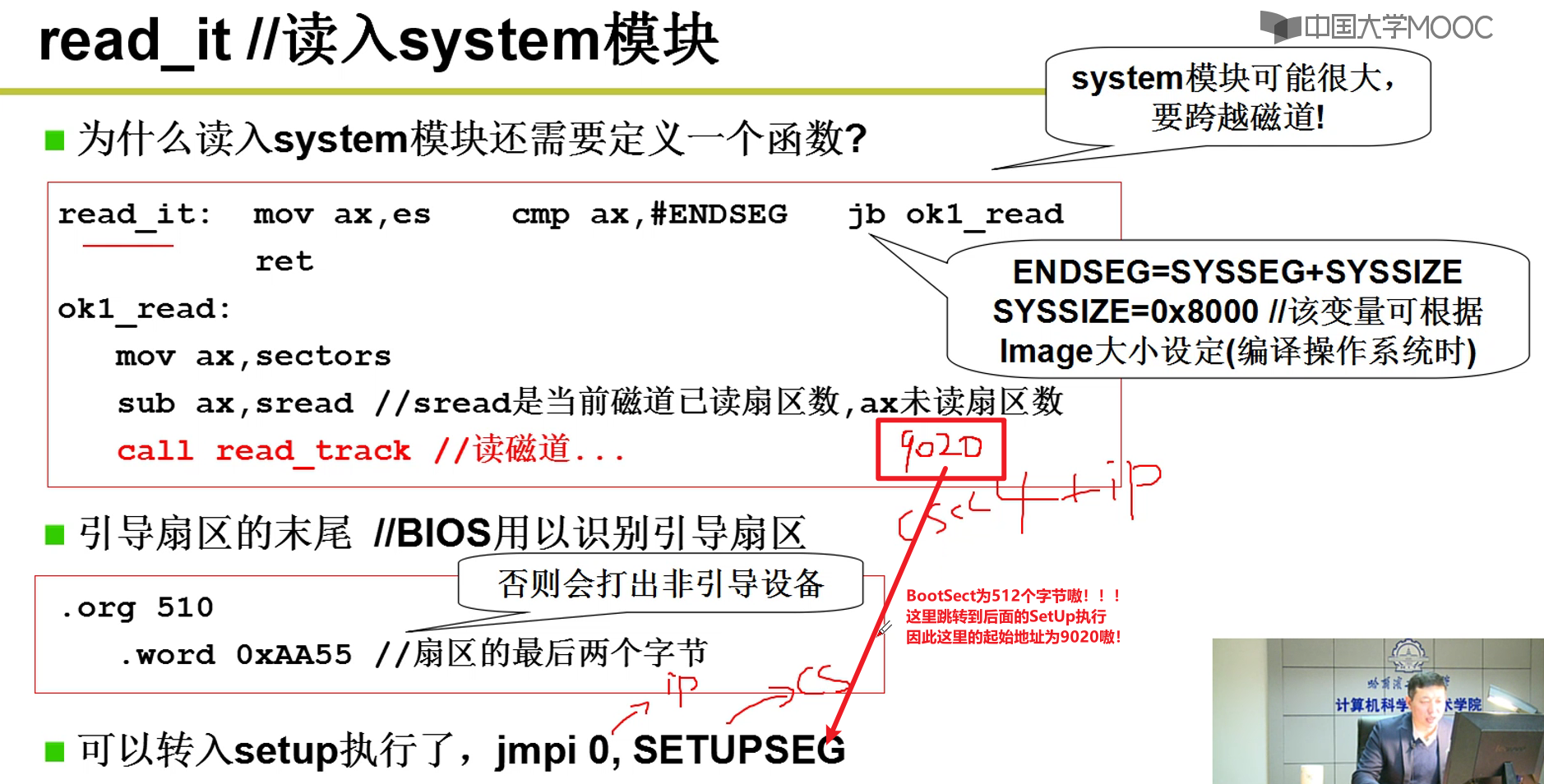
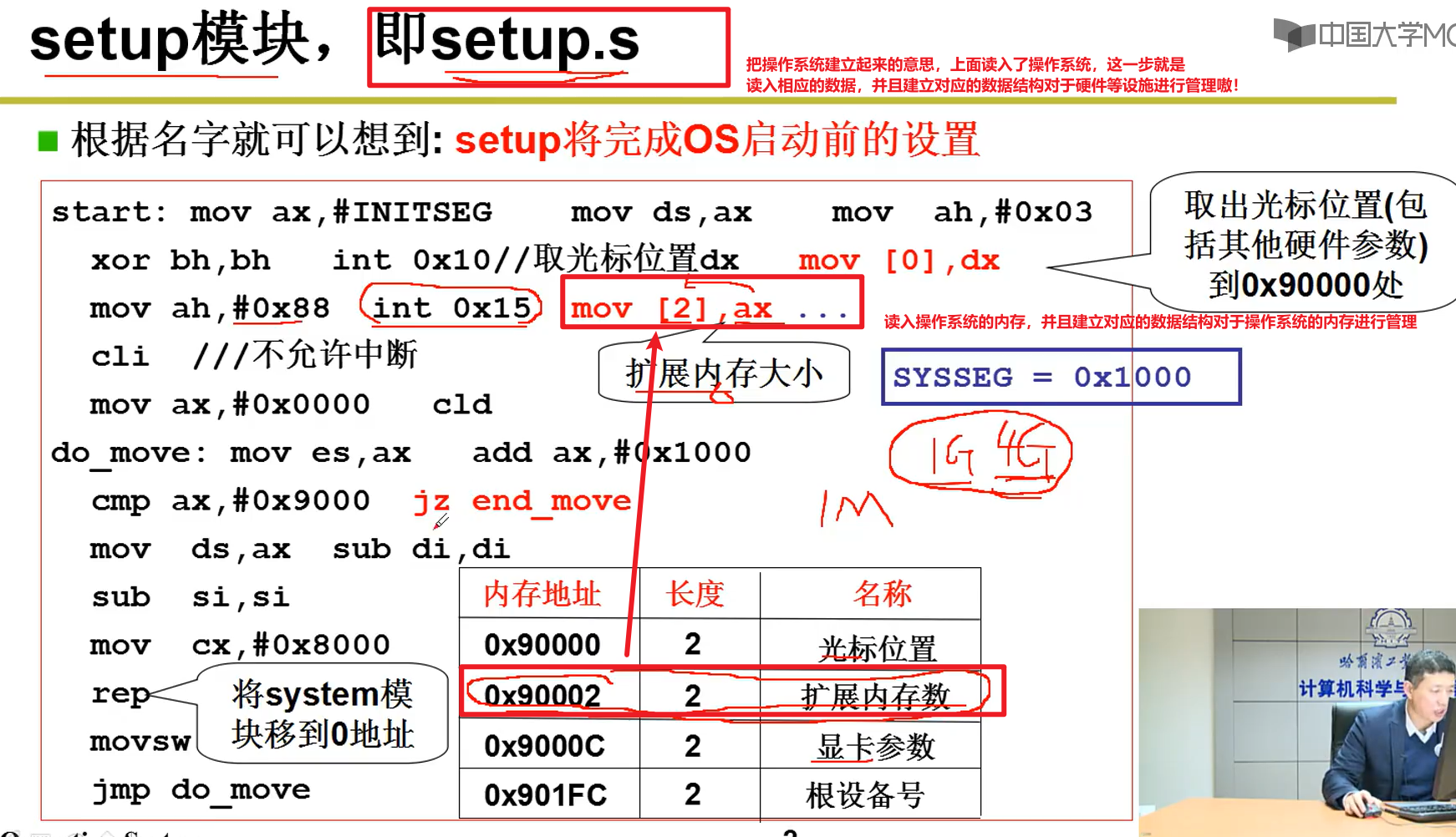
操作系统启动:
- Setup读入OS的相关设置:
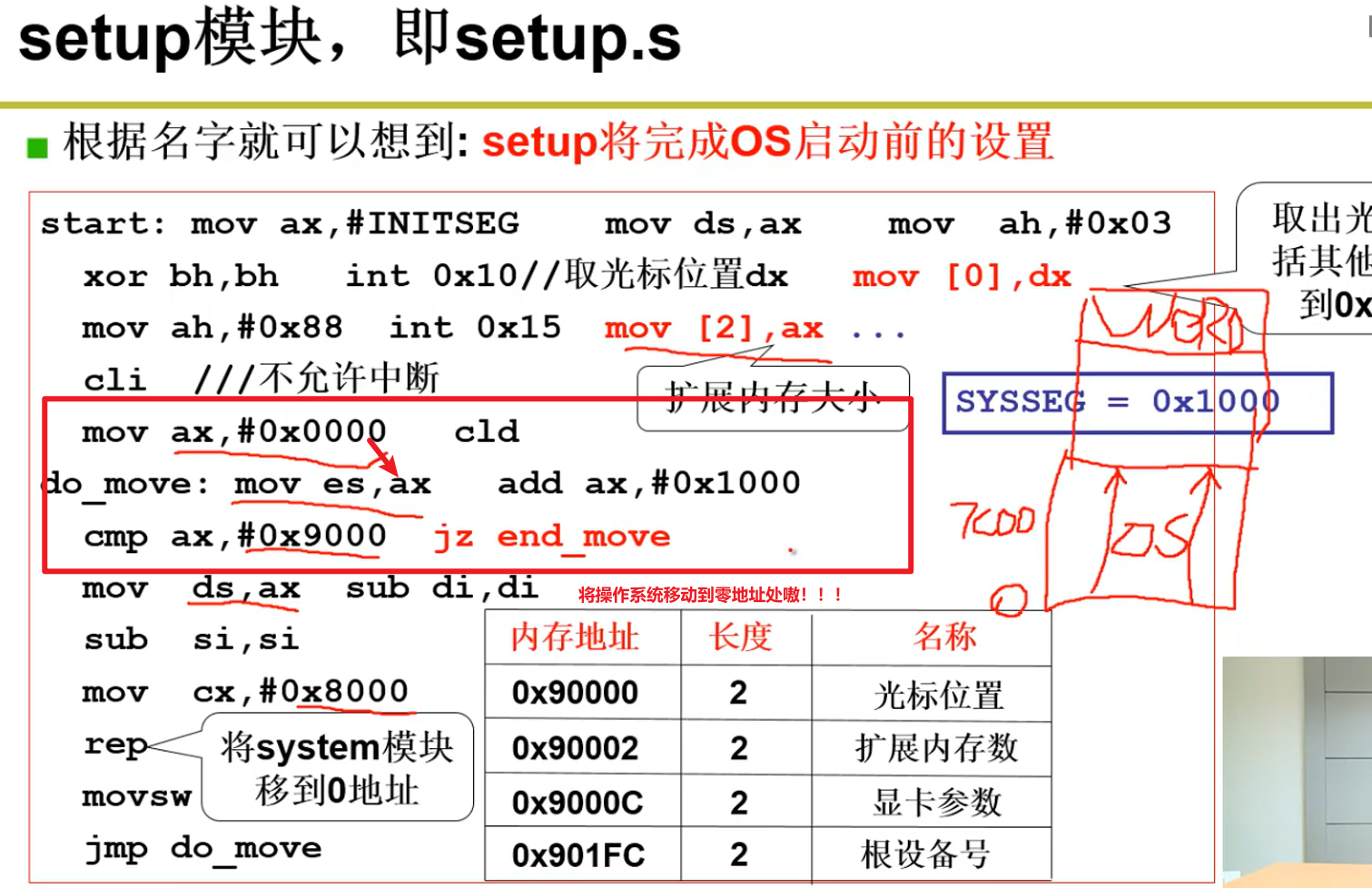
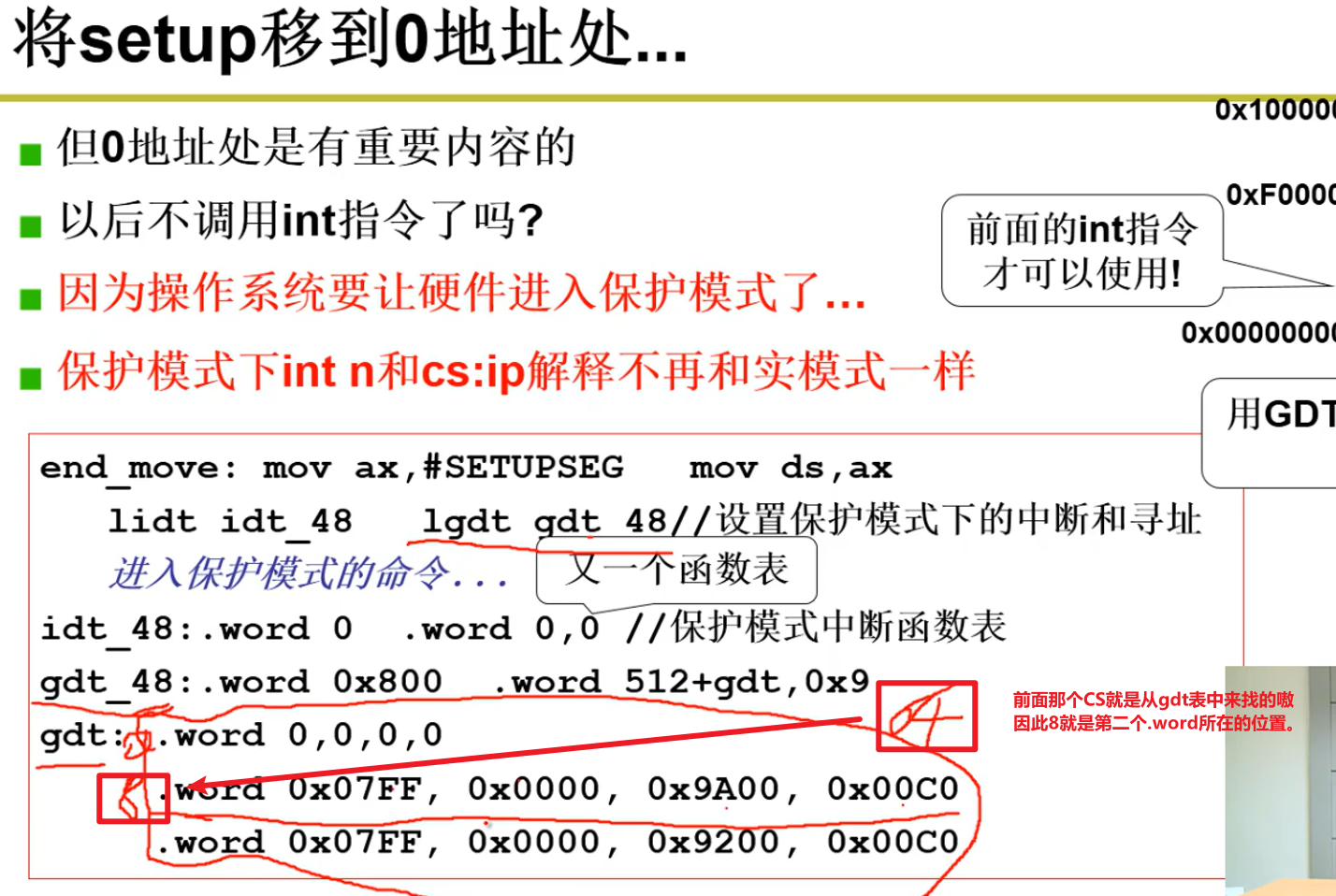
- Setup将操作系统代码移动到0地址嗷!!!:
- 保护模式:

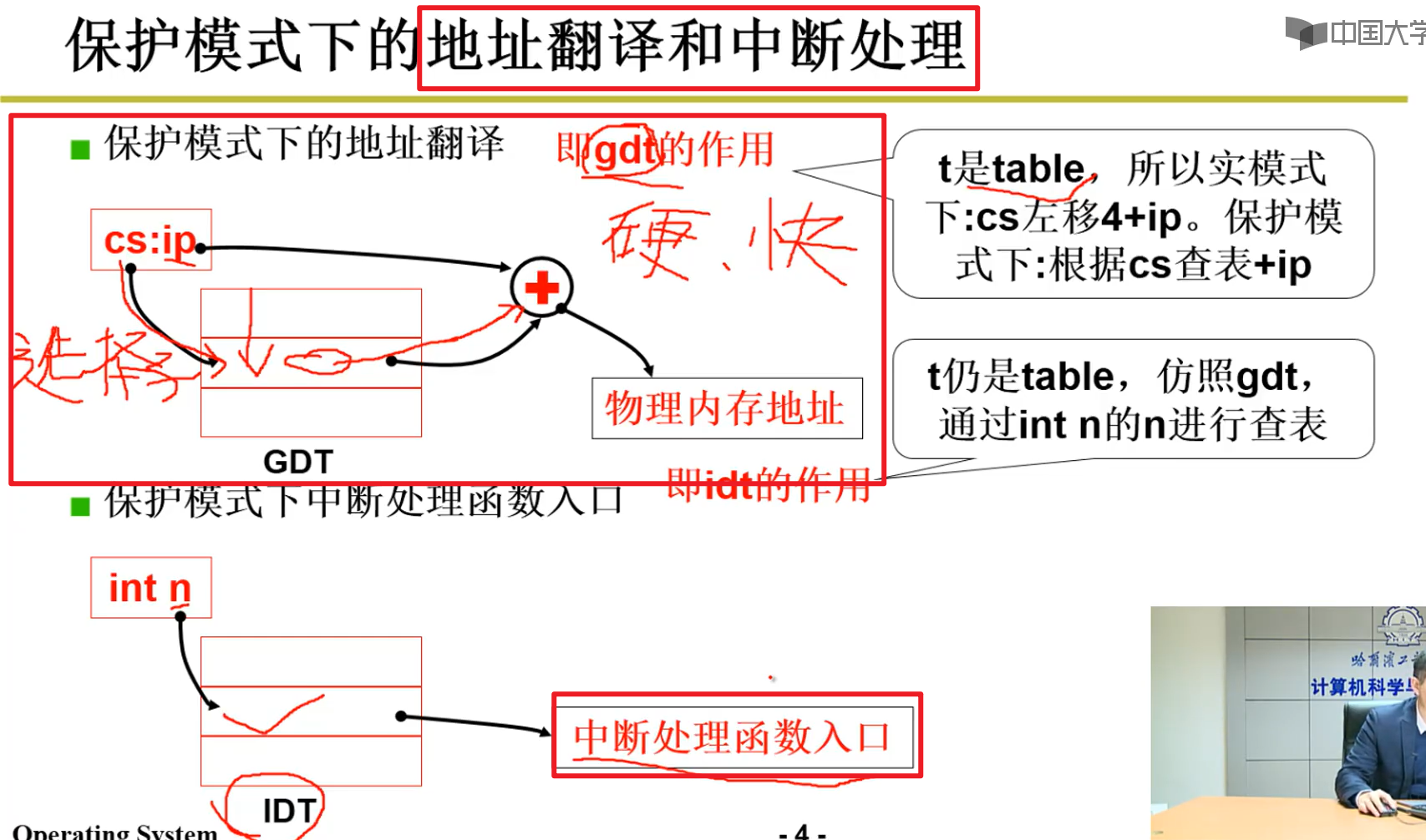
- 上面引入了GDT的概念:
- 地址翻译和中断处理:
- 下面就是8这个位置对应的东西,硬件是如何解释的:
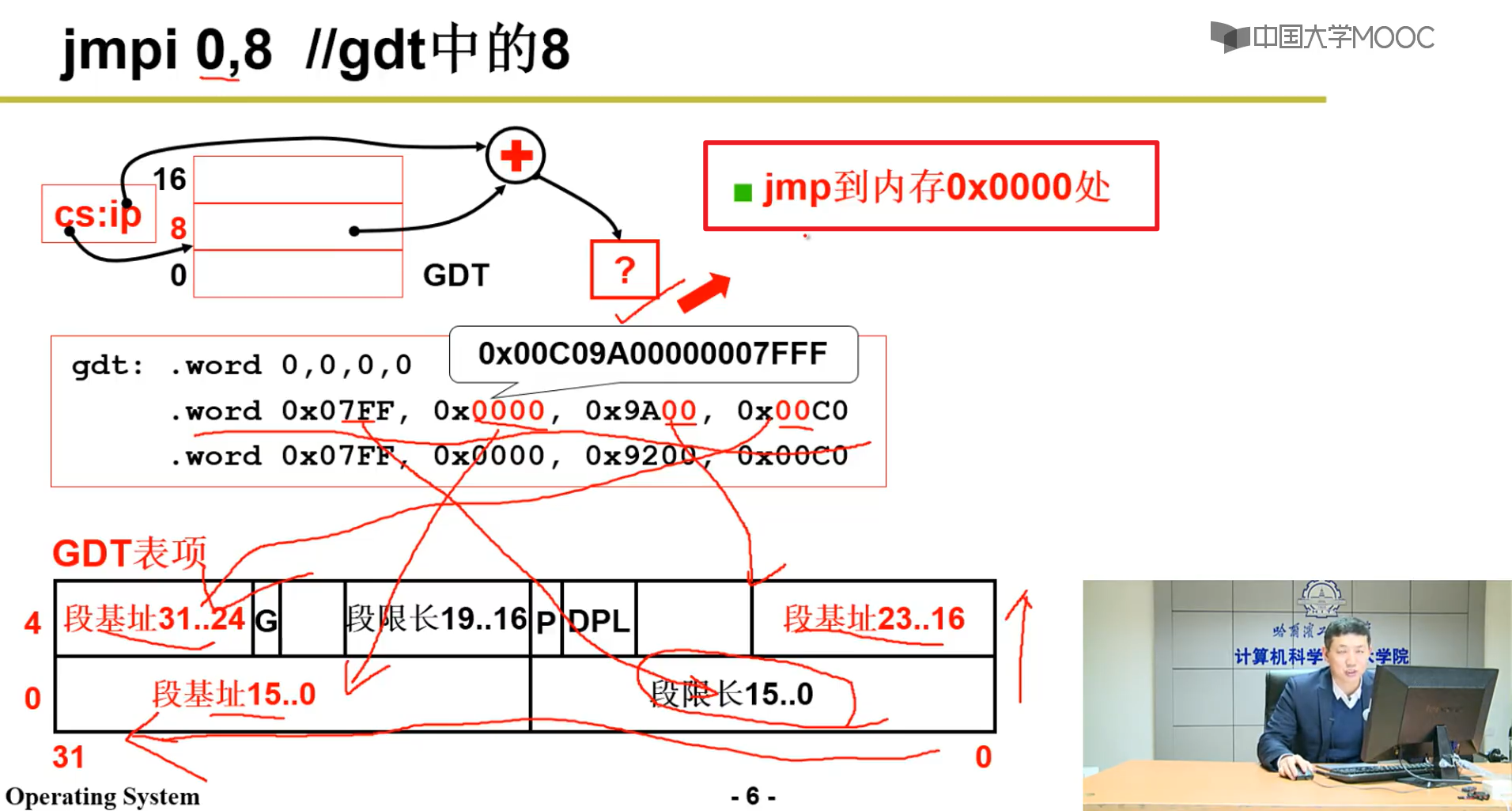
本质上还是跳转到了0000这个位置嗷!!!回到了操作系统代码的初始位置,开始执行操作系统的代码,启动过程到这里就结束了嗷!!!
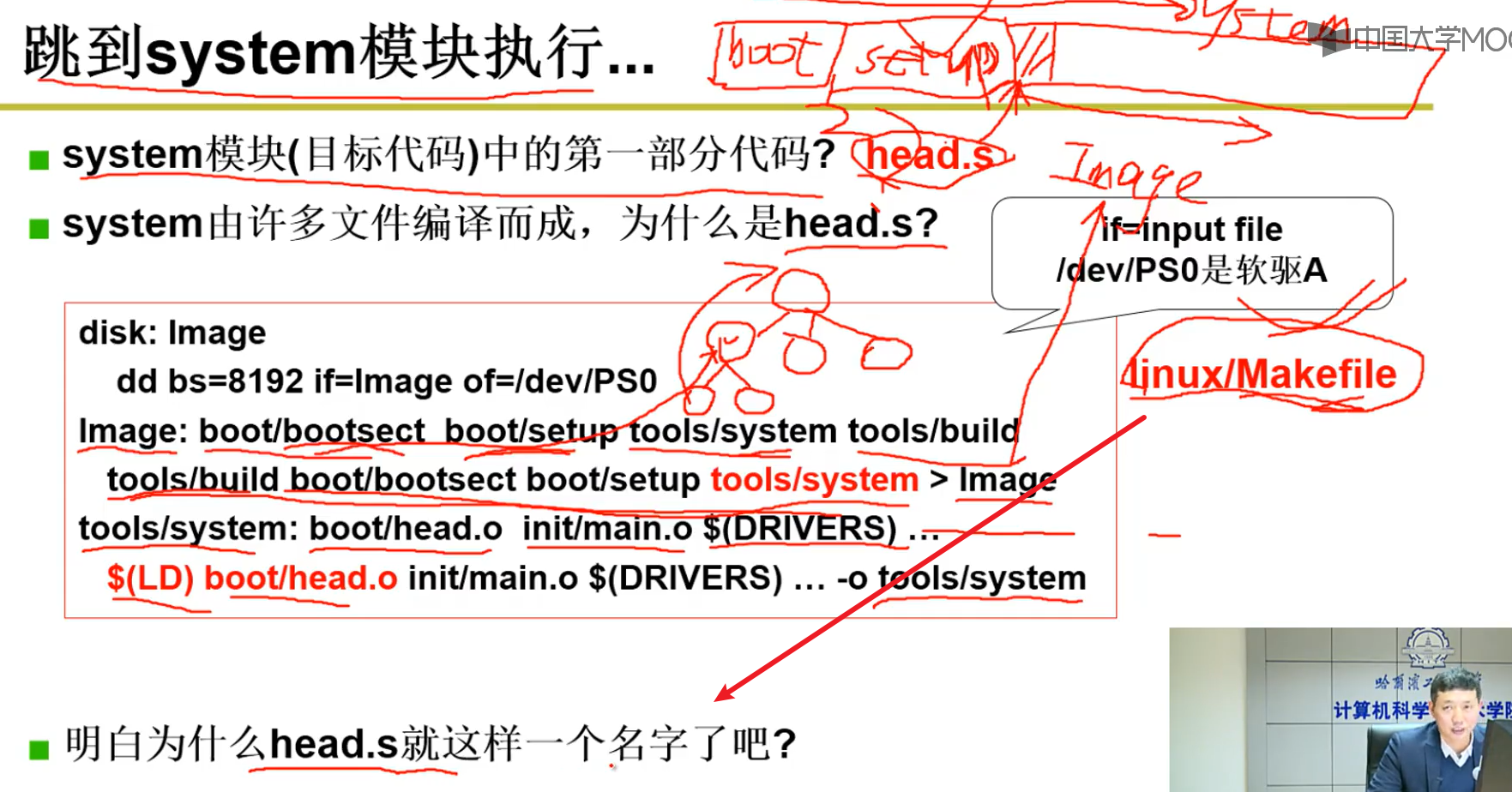
跳转到System模块执行:
- Bootsect —> Setup —> System,我们必须严格限制它们位于内存中的位置,一切的事情都要由我们自己控制。Linux/Makefile , Makefile十分重要嗷!!!每一个细节都要我们自己来做嗷!!!
- 操作系统被Makefile编译为了Image,这个Image通过对应的操作可以写入0磁道,0扇区的位置。然后再用Image进行操作系统的引导程序,这样才能成功嗷!!!
Head.s:
为啥叫head,因为是System第一个.s文件嗷!
- setup是进入保护模式,head是进入系统之后的初始化:
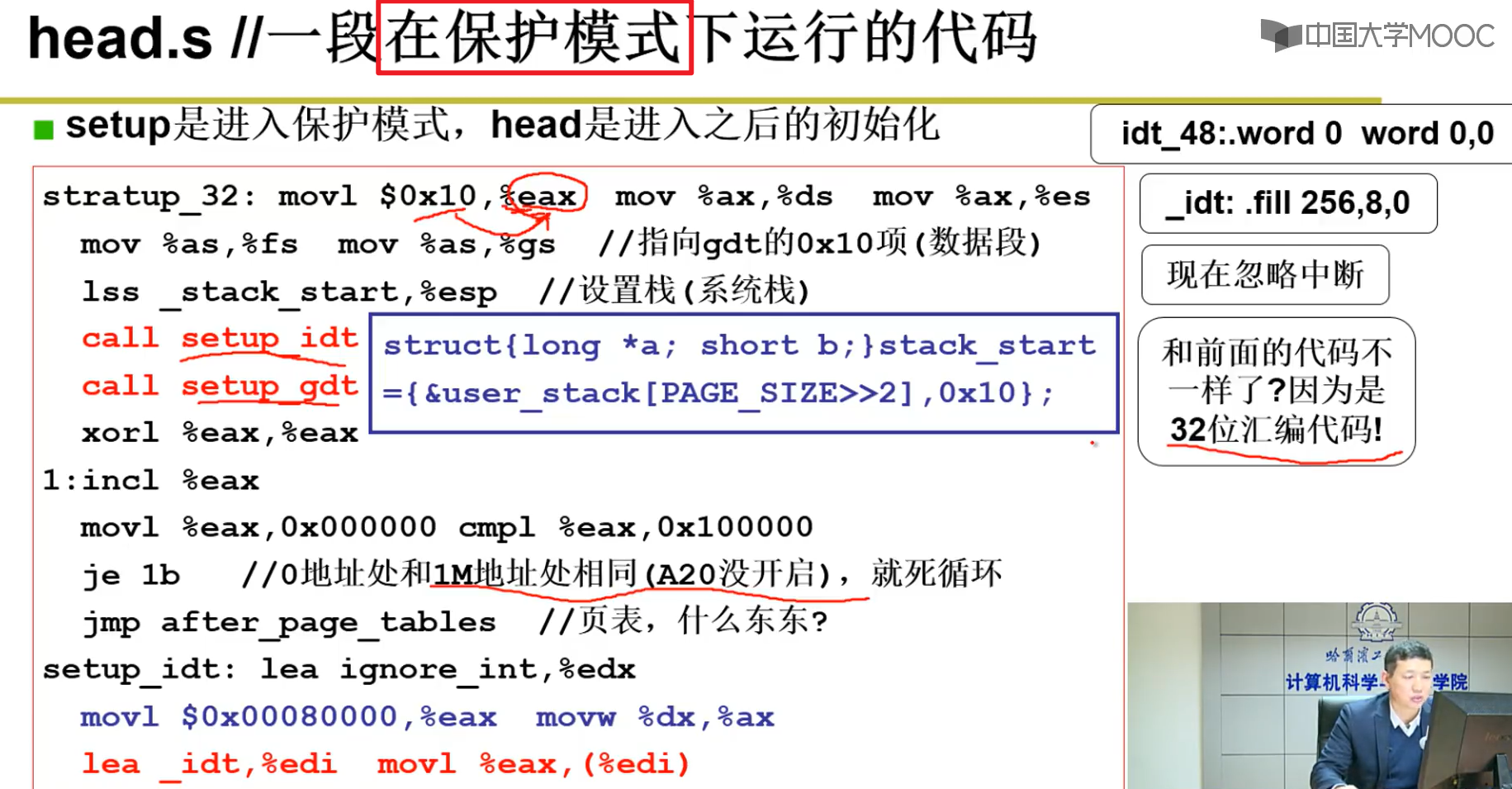
上面是建立临时的gdt表之类的,这里是正式的建立这些表格嗷!!!
使用了16位汇编,32位汇编,内嵌汇编等嗷!!!
- Head.s最后跳出来,执行main.c函数:
从汇编跳到c函数嗷!!!
汇编跳转到c函数:
- c -> c,本质上也是编译成了汇编,底层发生了对应地址的调用的嘛!!!
- 汇编 -> c,和上面没啥区别嗷!!!本质底层都是汇编嘛!!!本质上都是通过栈来实现的嗷!!!
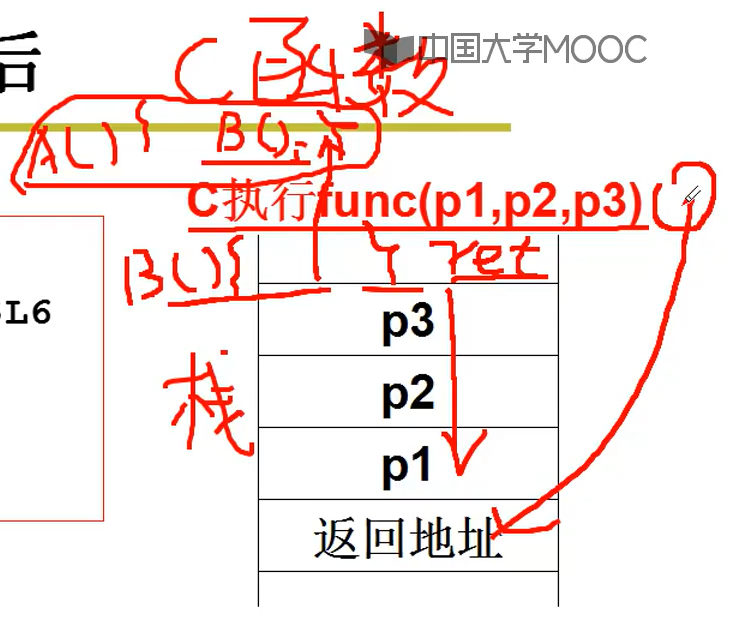
- 本质上,也是压入对应的参数,然后压入c语言函数对应的位置嘛!!!


上面就是把参数压入栈,然后把main返回地址压入栈嗷!!!
main.c和mem_init:
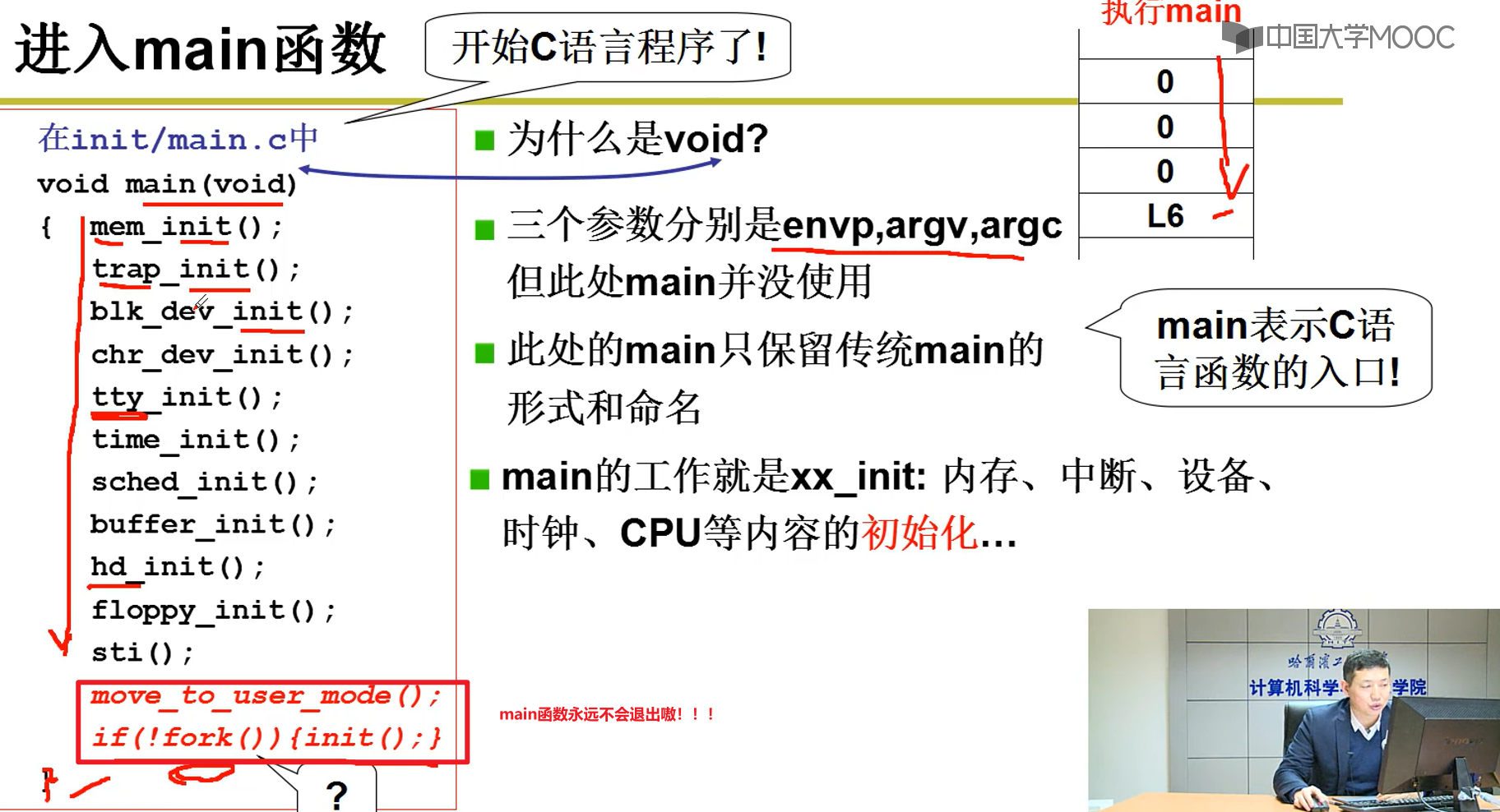
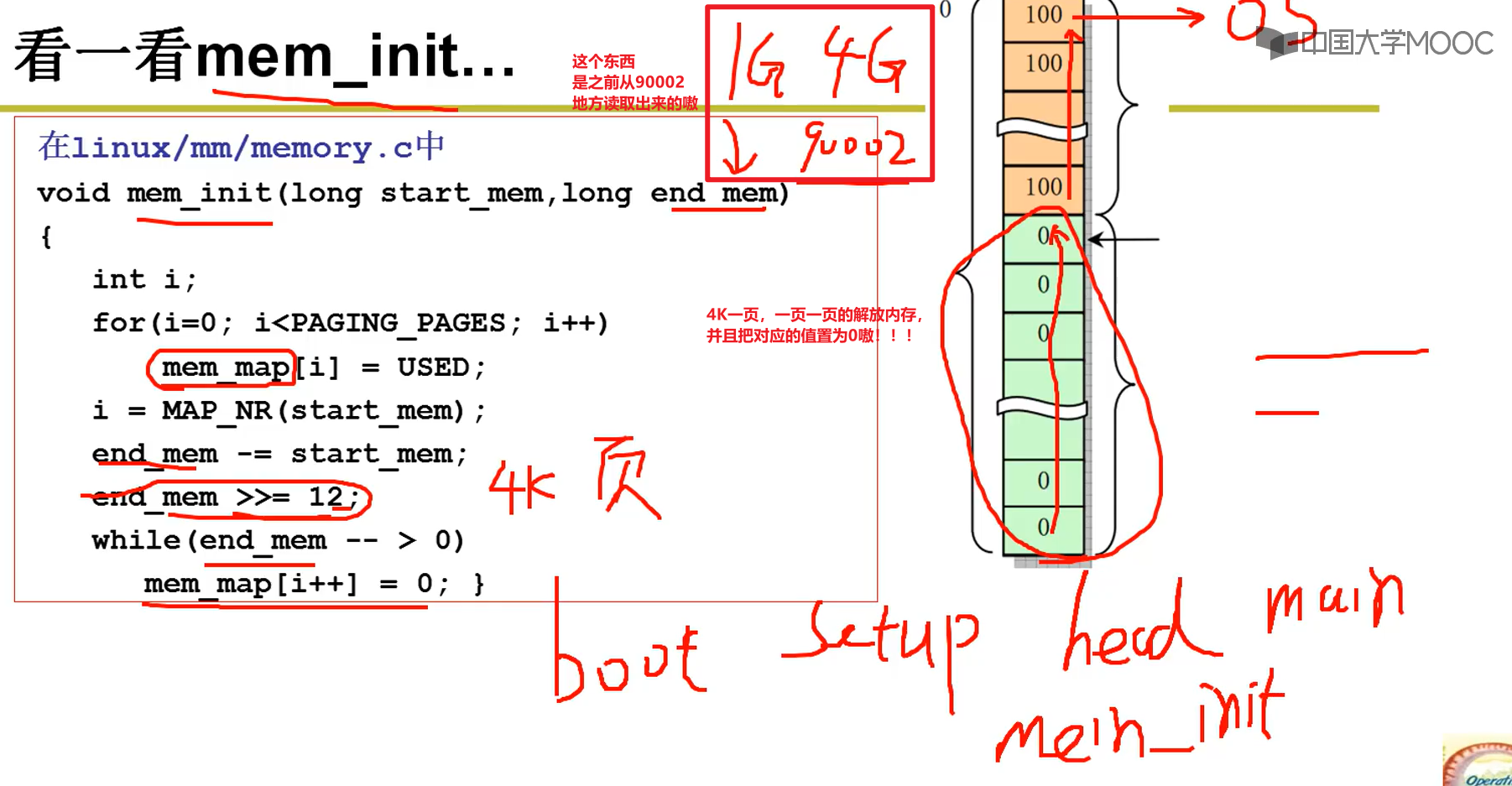
- summary:
- 将操作系统从硬盘读取内存!!!(这样我们才能取指执行嗷!!!)
- 完成相应内容的初始化操作嗷!!!(操作系统管理硬件,我们要读取硬件的信息,建立对应的硬件建立数据结构,这样才能实现我们操作系统的管理功能嗷!!!)
- bootsect —> setup —> head —> main —> mem_init
第二章(接口):
操作系统接口:
简介:
- 这里重点放在两个部分:
- 上层怎么调用系统接口的
- 系统接口在调用过程中发生了而什么
- shell也是一段程序,/bin/sh。系统在初始化的最后一句就是启动/bin/sh。开启shell程序。
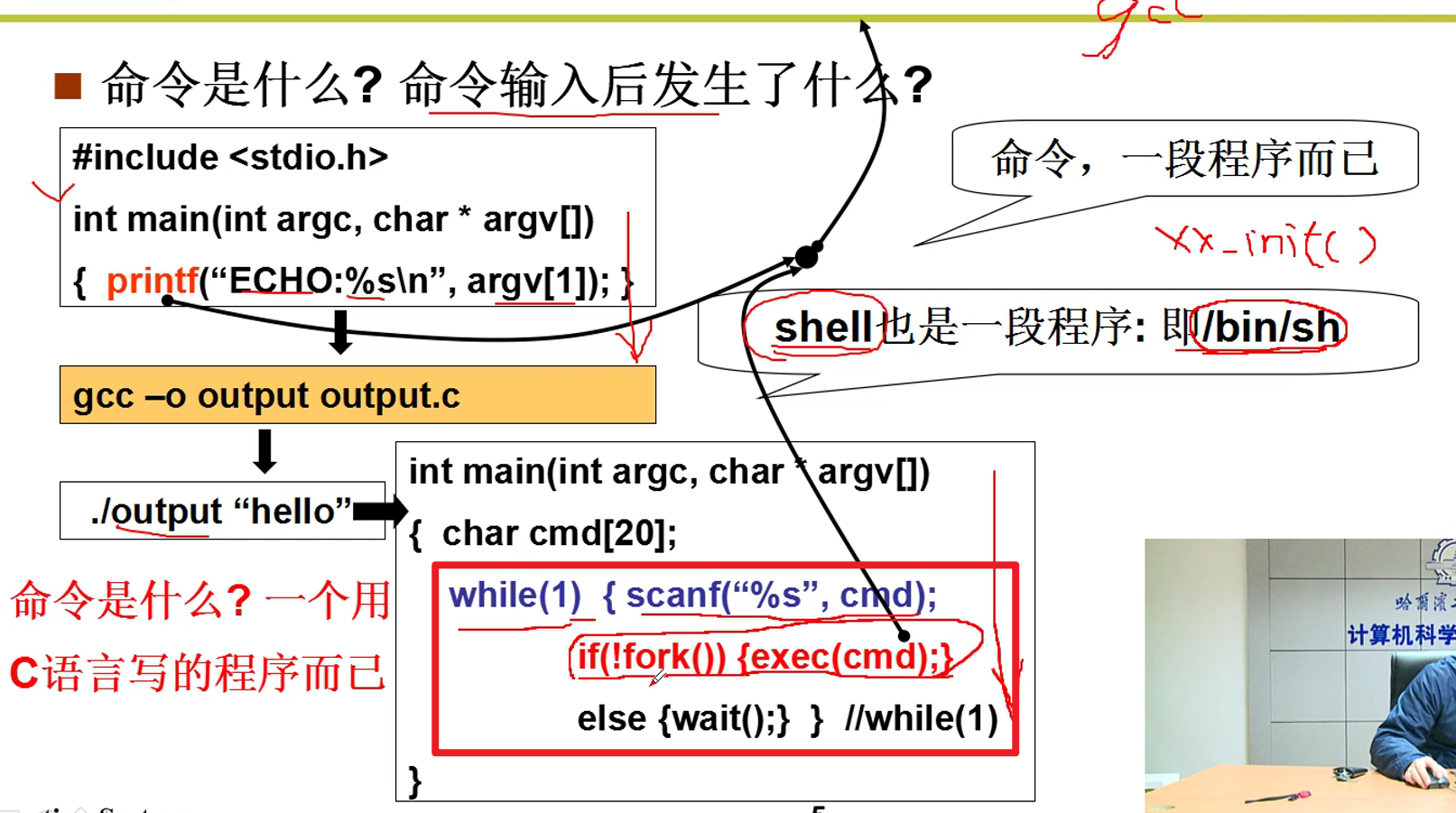
所以shell本质上就是一个无限循环的程序嗷!!!
- 图形化界面的原理:
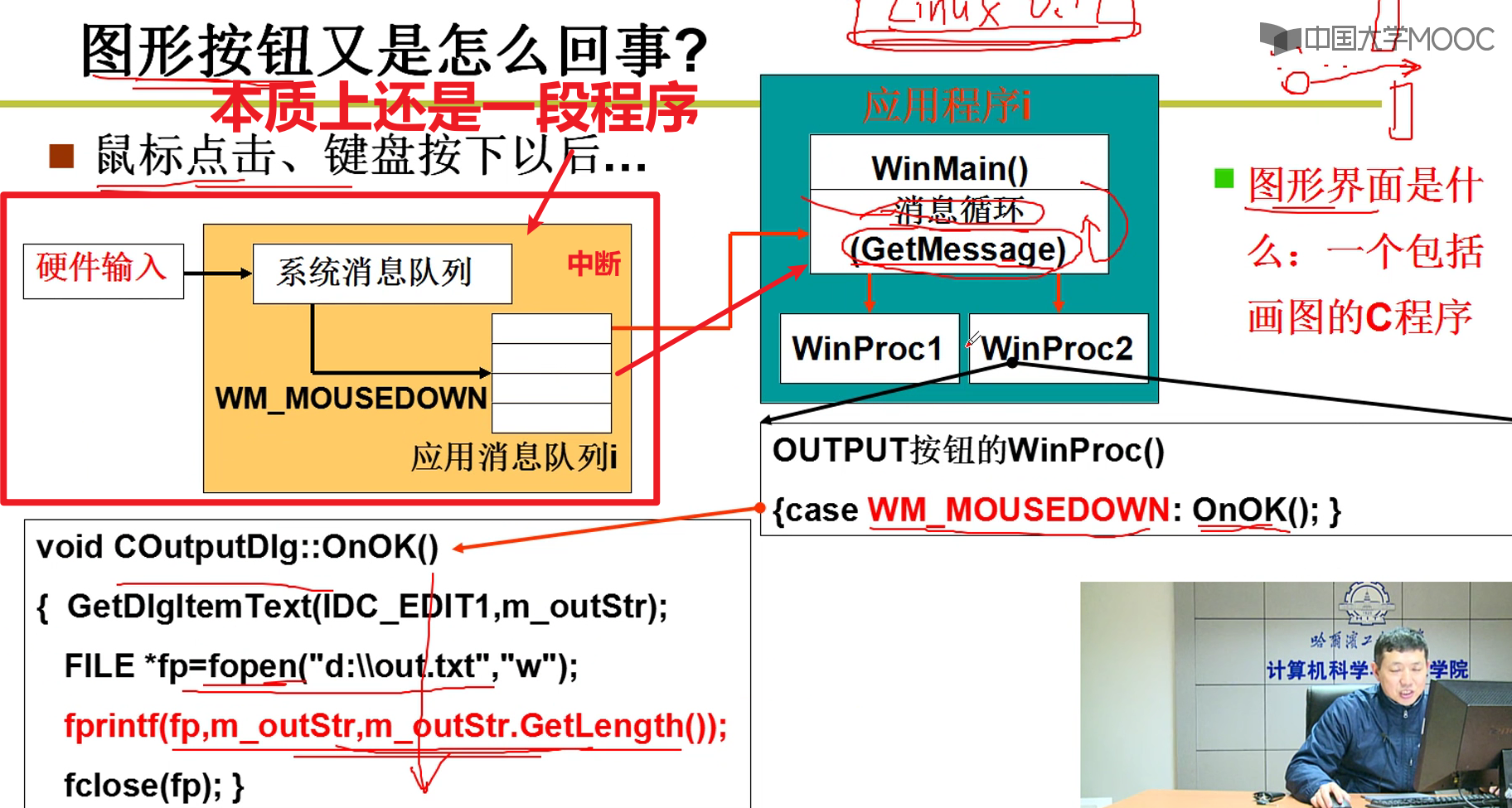
插座:C语言 + 重要函数(这个就是操作系统提供的接口嗷!!!)
- 系统调用:
system_call,就是与操作系统交互的接口嗷!!! - 系统调用例子:

POSIX就是IEEE定义的一个标准族,如果对于系统是否提供特定功能有疑惑,直接上POSIX官方文档查找即可。
- 总结:操作系统接口就是一堆系统调用函数嗷!!!
系统调用的实现:

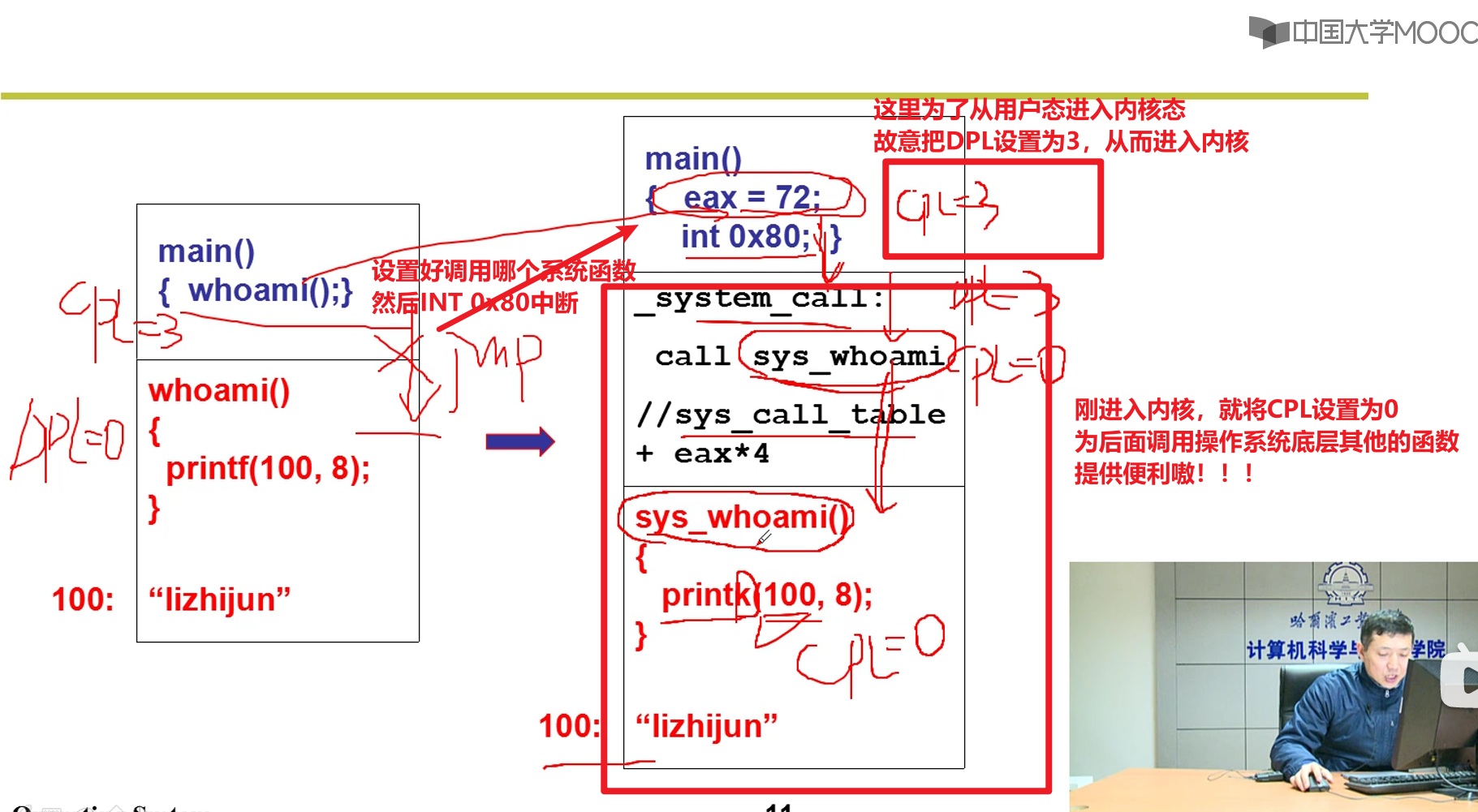
这里不让jump,咋不让他进去的?
- 硬件不让我们这么做的嗷!!!类似于GDT之类的,硬件非常重要嗷!!!这些功能都是硬件做的嗷!!!
那么硬件到底干了啥呢?
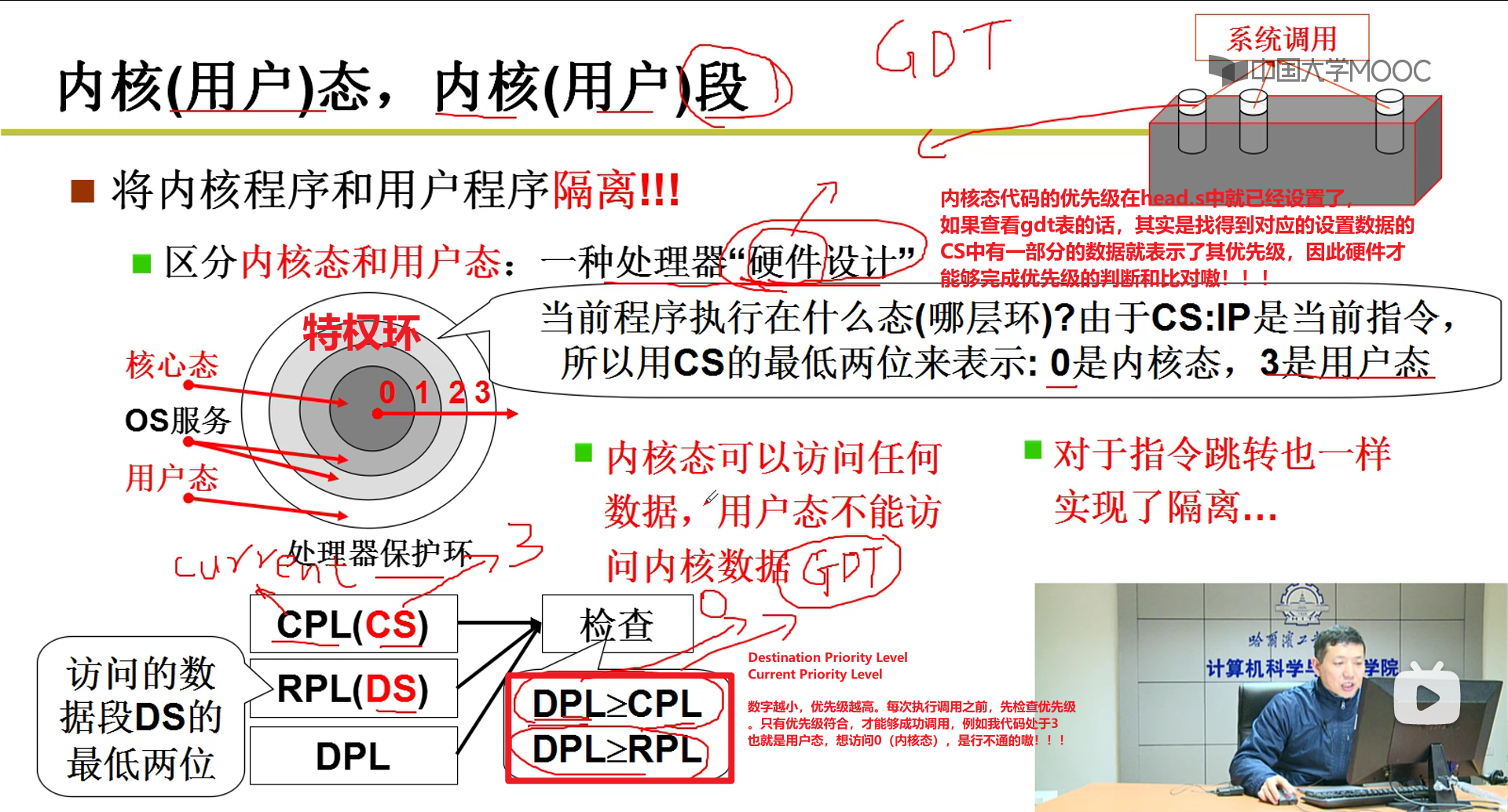
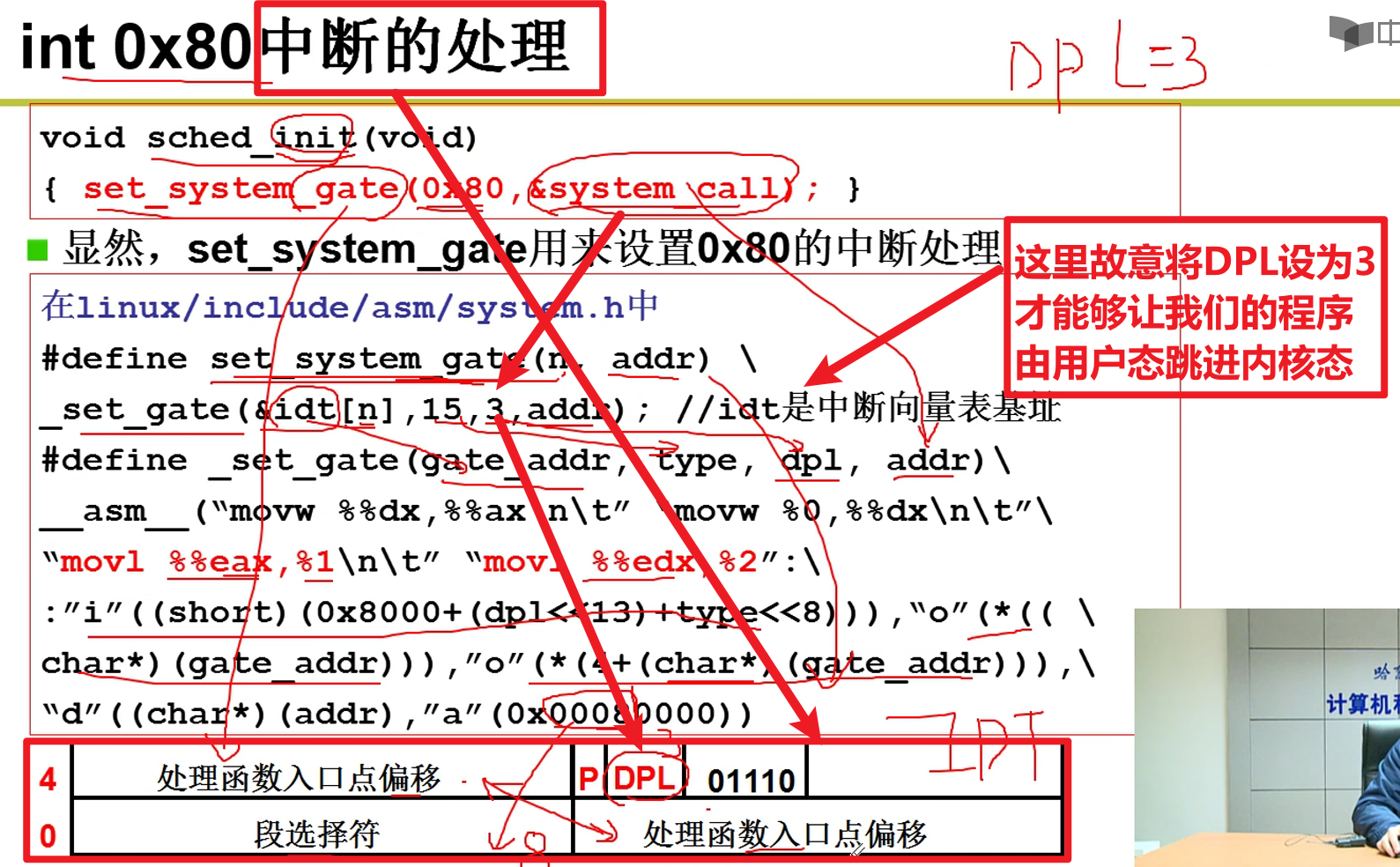
硬件判断是否符合优先级要求,只有符合要求的才能进得去嗷!!!
当OS启动Shell给用户执行的时候,CS中的CPL就是3,gdt表中对应的DPL对应的表项为0。当执行系统调用的时候变为0,回到用户态的时候又变成了3嗷!!!
- 计算机提供了唯一的办法可以进入内核嗷!!!:
- 设计了一些中断可以进入内核嗷!!!
- 中断!!!:
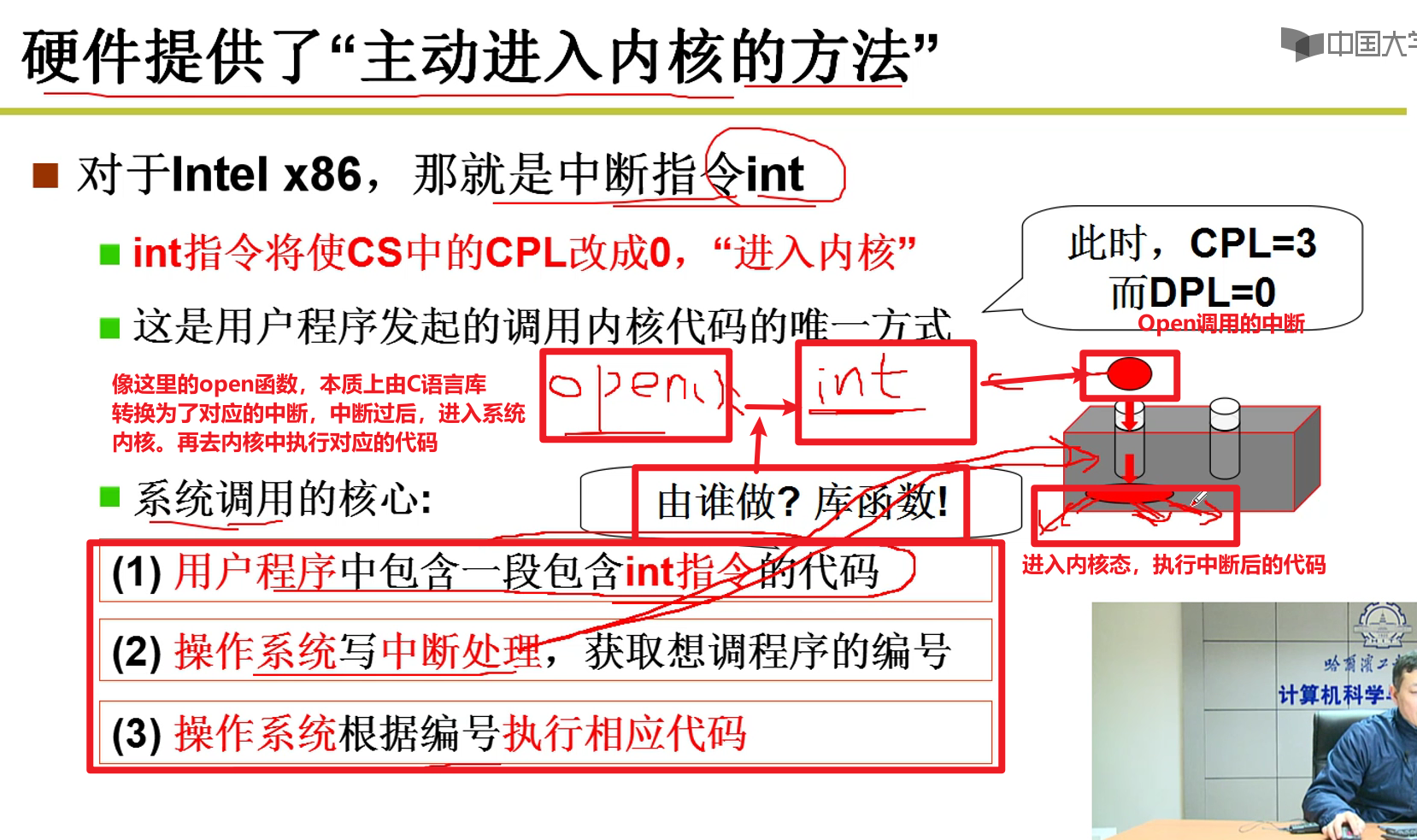
- 从printf到最终调用操作系统经历了什么?
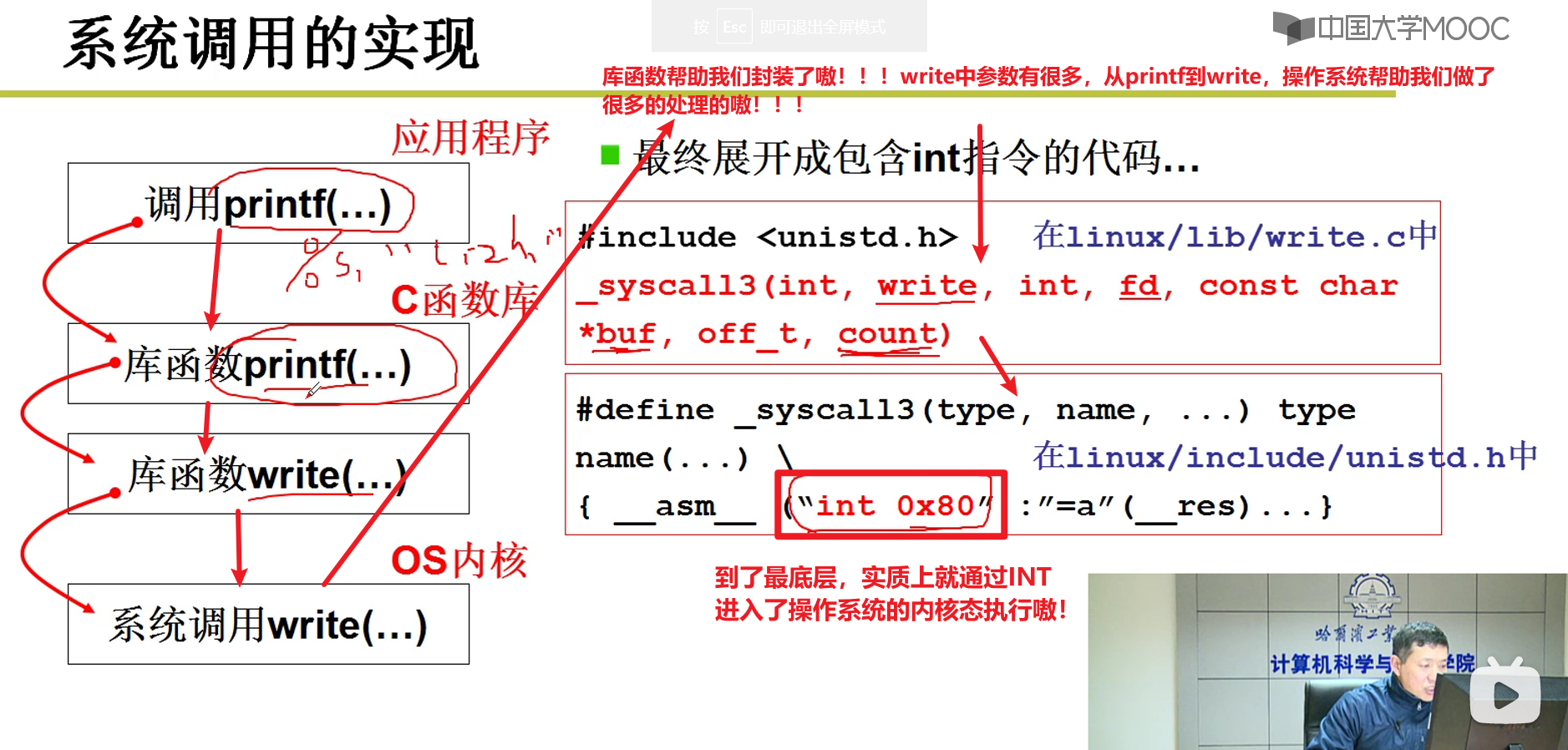
实现细节:
- 通过宏来实现的嗷!!!
- 上面那个右下方就是定义了一个系统调用的宏嗷!!!
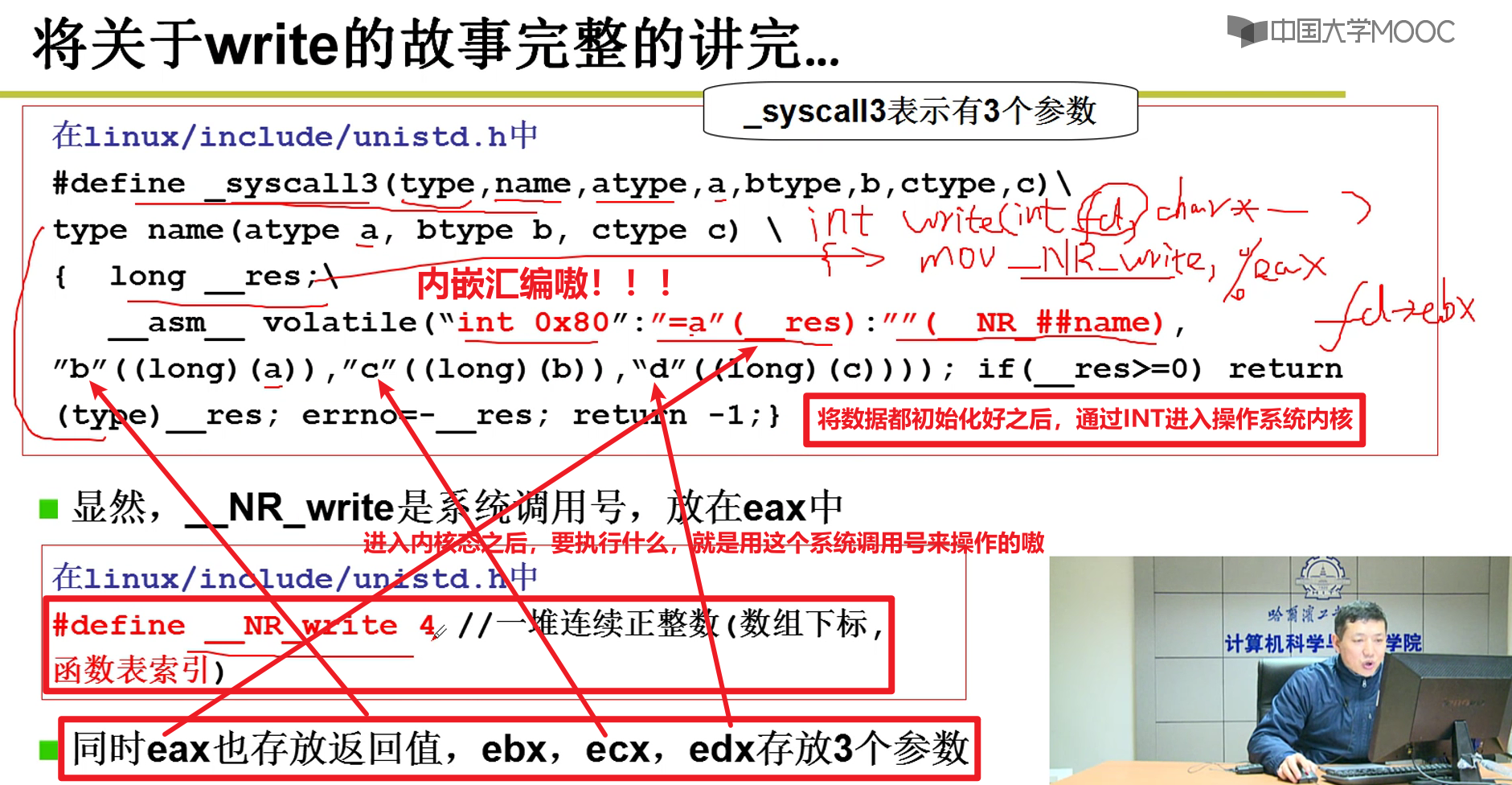
INT 0x80如何执行?
从int 0x80进入执行,执行完成之后再跳出来,之后继续执行嗷!!!
本质就是把后面那张表给填好了
CS设置为8,addr设置为system_call
这里的8很熟悉啊,jmpi 0 ,8, CS=8的时候刚好是写系统代码段嗷!!!
跳进去之后,CS变为8了,CPL变为0了,这个时候特权级就变成0了嗷!!!到了内核,就什么都可以做了嗷!!!
- system_call又干了什么呢?

这里就从中断表中,找到了对应的中断函数的地址,转去执行中断函数了嗷!!!
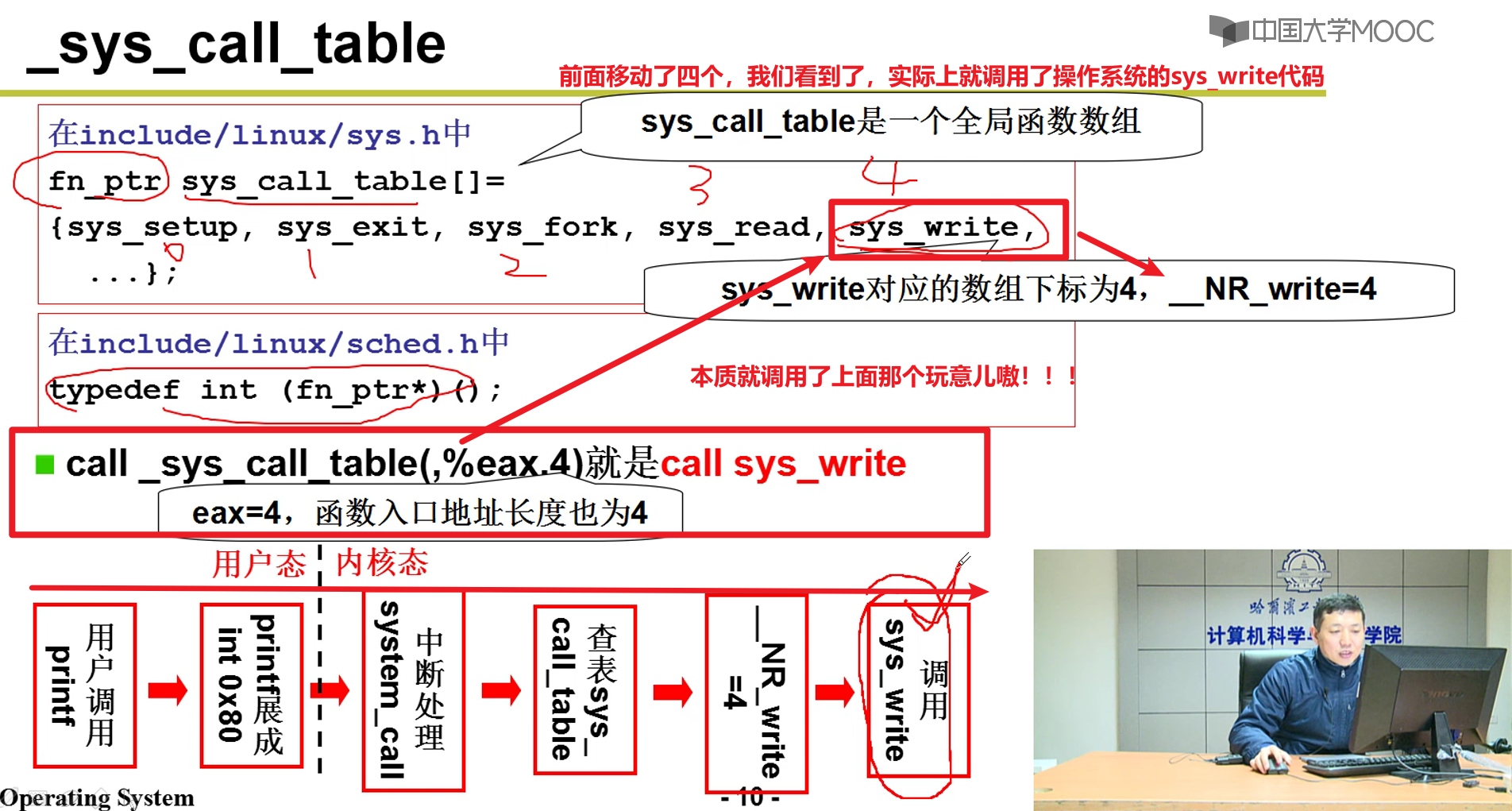
- 总结:
操作系统的历史:
批处理系统嗷!!!(一个作业完成,自动读入下一个作业嗷!!!)。
作业之间的切换和调度成为核心。(多线程)
分时系统 —> Unix —> Linux,核心一直是多进程结构,多任务结构。
DOS —> Windows
多进程 —> 用户友好交互
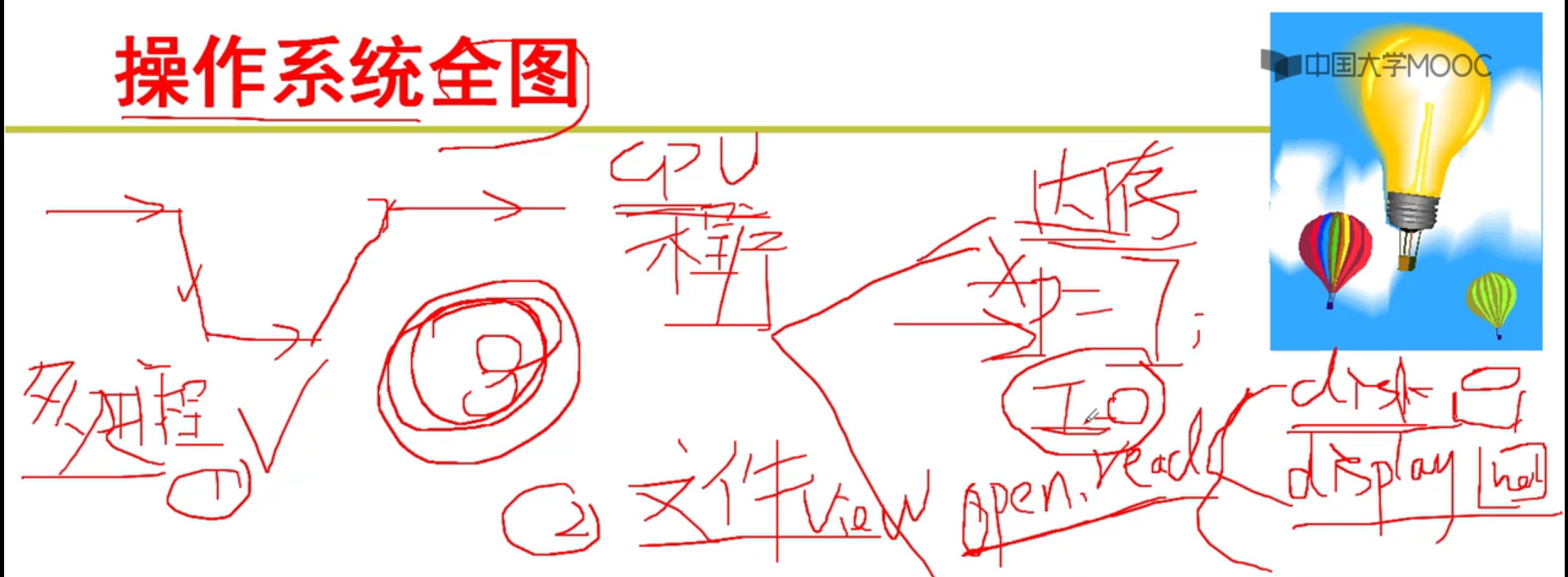
任务:
- 掌握,实现操作系统的多进程图谱。
- CPU
- 内存
- 掌握,实现操作系统的文件操作视图。
- 文件
- 磁盘
- I/O
- 掌握,实现操作系统的多进程图谱。
我们的学习任务:
- CPU,内存, I/O等等
第三章(进程):
CPU管理的直观想法:
- 多进程管理明白了CPU嗷!!!
- CPU管理的直观想法:
- 让CPU更加高效的使用,就管理好了呀!!!
- CPU如何工作?自动的取值,执行嗷!!!
- 最直观想法:
- 你把PC初值设置好了之后,让其自动执行就可以了嘛!!!CPU就会自动取值执行嗷!!!
- 有问题吗?

- I/O太慢了,CPU又要等I/O。如果执行10^6的计算指令,一条I/O指令,CPU利用率采用50%的利用率orz,所以I/O没有管理好哇!!!
- 如何解决?
- 当我们遇到I/O这样的事情的时候,让CPU去干别的事情,不要死等着呀,切到别的程序去执行哇!!!
- 让CPU忙起来哈哈哈哈哈哈!!!
- 多道程序交替执行,好东西啊!!!哈哈哈哈哈!!!
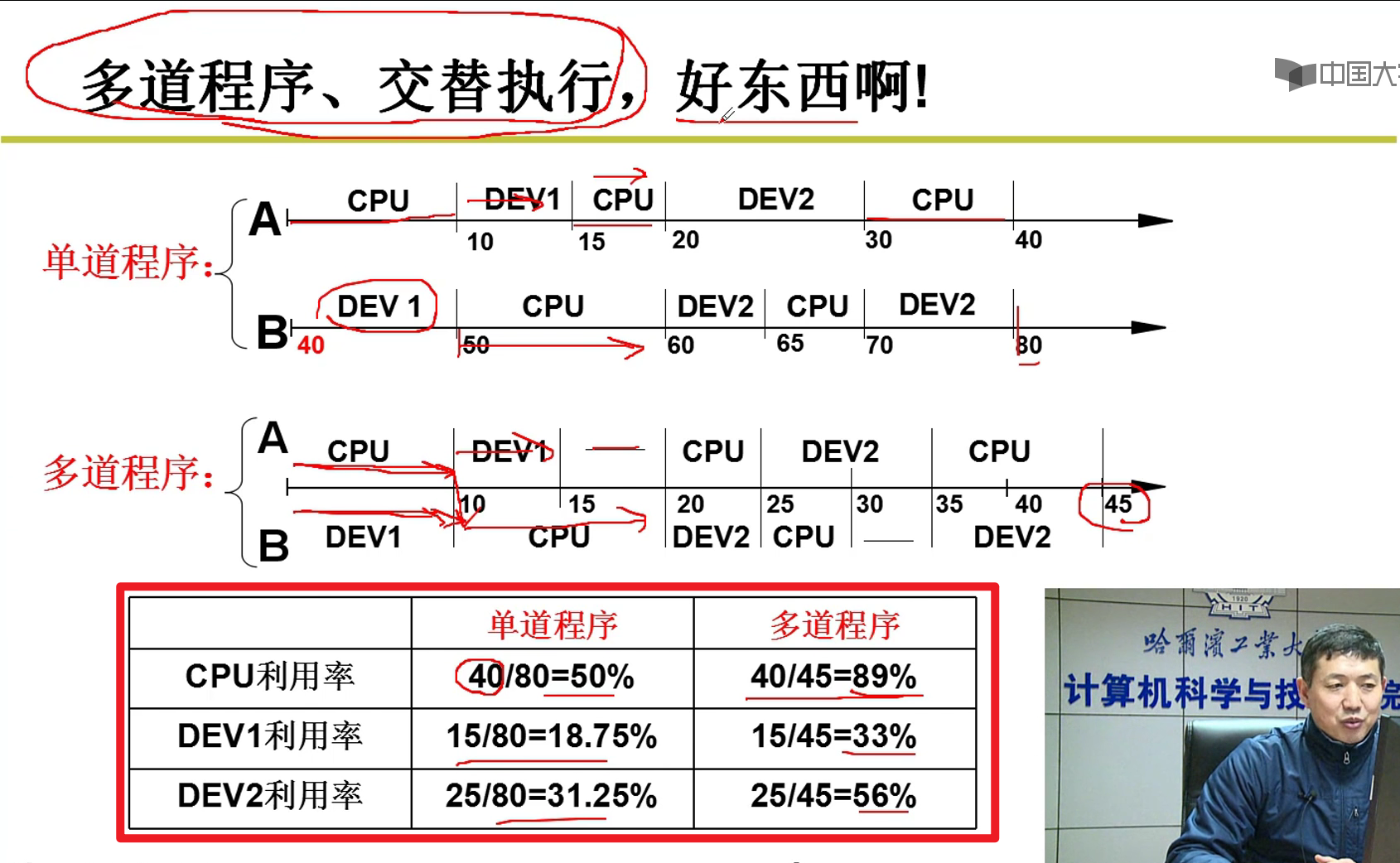
- CPU上交替的执行多个程序被称为并发嗷!!!
- 怎么做到并发呢?
- 我们控制PC进行切换就行
- 只修改PC就行了吗?
- 不行哇!!!还要记录一些信息,例如寄存器的信息嗷!!!
- 运行的程序和静态的程序不一样哇!!!
- 引入进程的概念:
- 进行中的程序,和静态的程序不一样嗷!!是动态的程序嗷!!!
- 将所有的信息存放在PCB中,PCB就是用于记录进程的信息的嗷!!!
多进程图像:
多个进程使用CPU的图像
多进程图像从启动开始到关机结束:
if(!fork()){init();},这是main.c中的最后一个调用,init执行了shell
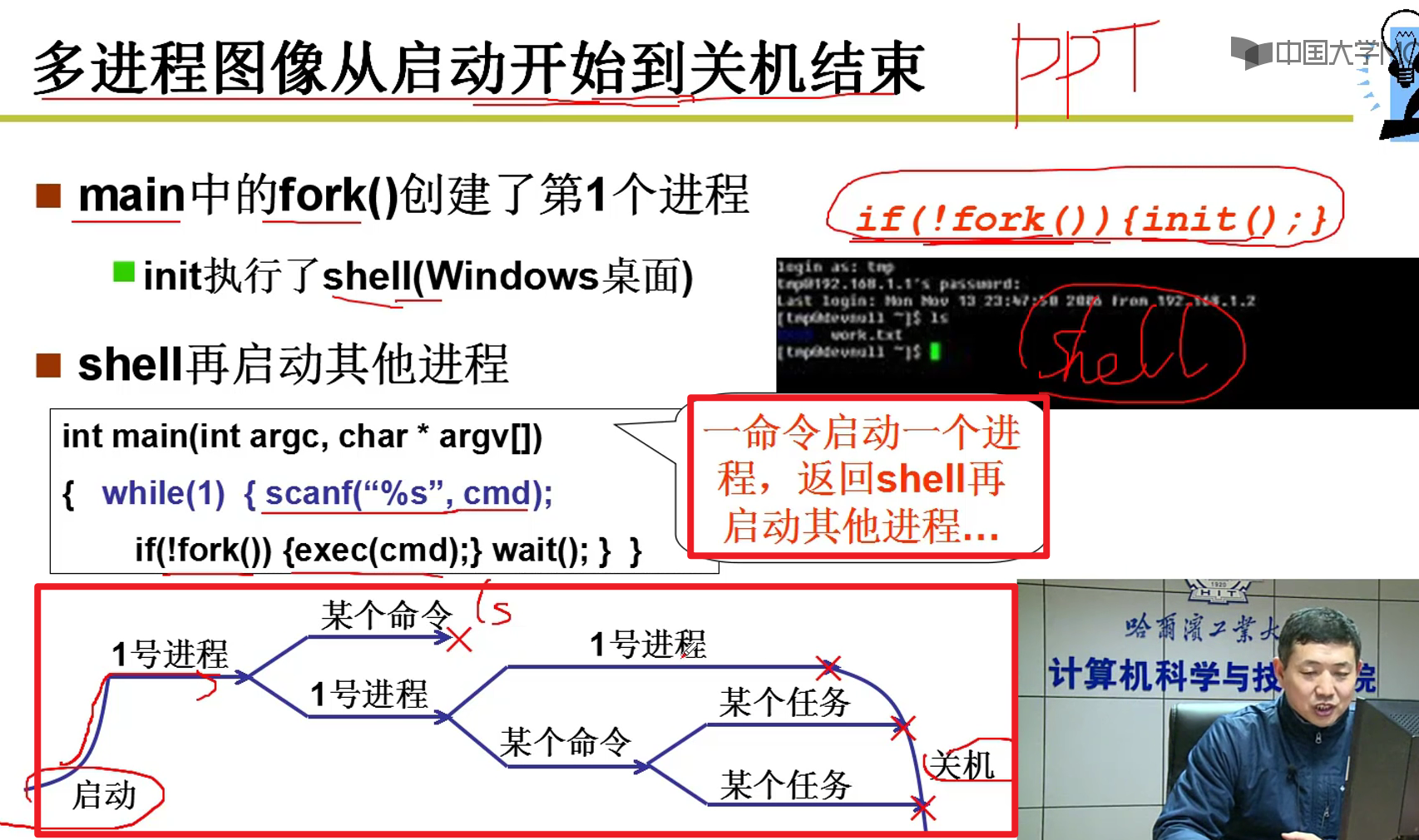
操作系统就是通过管理进程来管理用户对于计算机的使用的嗷!!!
多进程如何组织和存放?
感知和组织进程全靠PCB嗷!!!
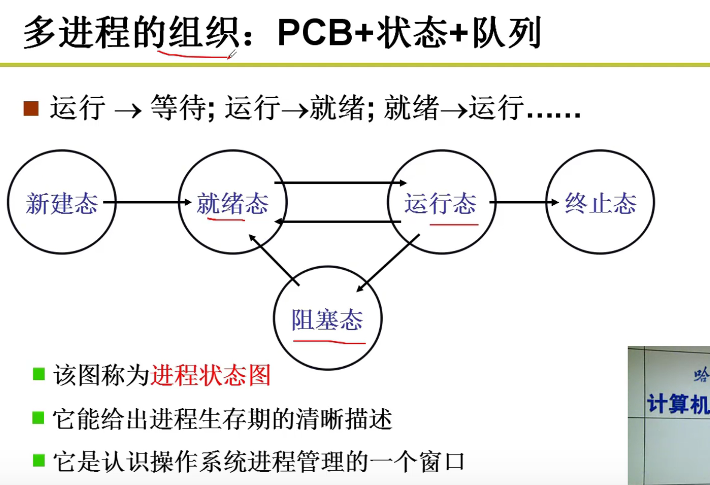
多进程如何交替?
操作系统常见的进程调度算法:
- FIFO
- Priority
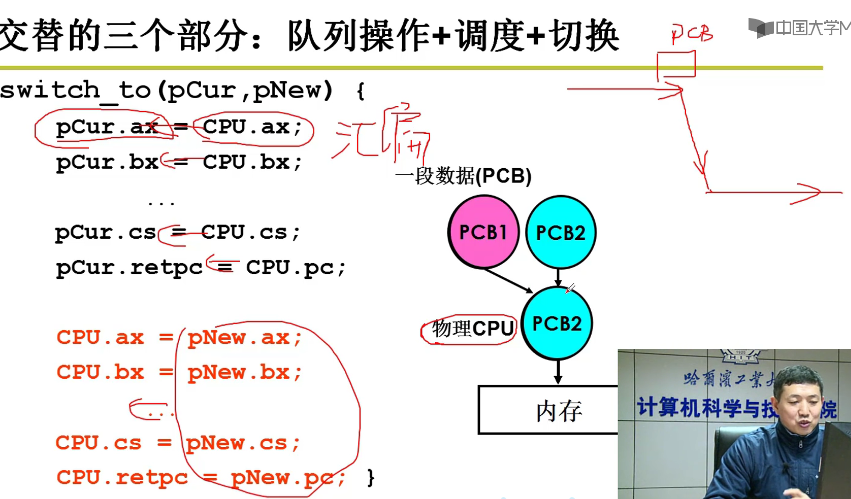
交替的三个部分:
- 队列操作
- 调度
- 切换
把CPU中上一个进程的信息保存在对应的PCB中,然后把下一个调度的进程的信息装入CPU中,再进行下一个进程的调度嗷!!!
要用汇编进行控制嗷,C语言的控制不够精细,要用汇编实现精细的控制嗷!!!

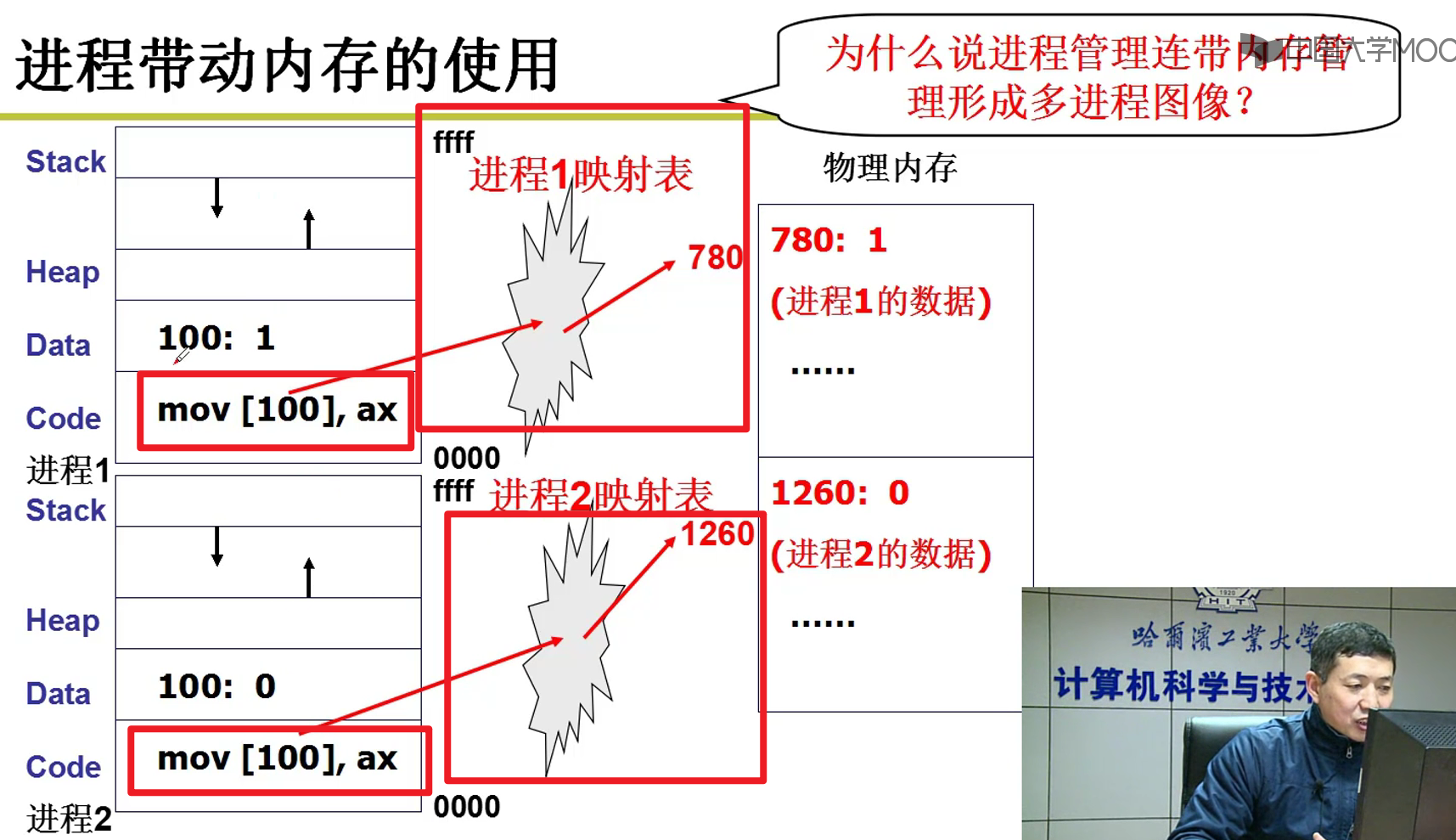
多个进程相互操作的时候,可能会产生相互影响嗷!!!如果进程1,修改了进程2的东西,不就会导致出现问题吗?
- DPL和CPL可以吗?不可以,这些东西设计出来是为了保护操作系统的,不是用在这种场合的嗷!!!对于用户进程来说,DPL都是等于3啊…
- 如何限制进程之间的相互访问和修改?通过映射表实现多进程的地址的分离嗷!!!
多进程如何合作?
- 有人往共享缓冲区里放置,有其他人往共享缓冲区里防止,还有人从缓冲区里面取。由此,才实现了合作嗷!!!
- 核心在于进程同步:合理的推进顺序嗷!!!(加锁加锁加锁!!!)
用户级线程:
线程:将资源和指令的执行分开。既保留了并发的特点,又避免了进程切换的代价嗷!!!
线程的存在有价值吗?
- 多个执行顺序 + 一个地址空间是否实用?
- 例如浏览器的下载:一些时间下载,一些时间加载到页面上,本质上是一个进程嗷!!!
不能让下载线程一直执行,不然用户不友好。因此先下载一段,然后再切到显示页面的线程,把页面显示出来嗷!!!
相比于多个进程的地址空间分离,还要拷贝内容,显然不太合适,因此线程切换是有非常大的使用价值的嗷!!!
Yield(线程切换):
线程切换的骨干代码:
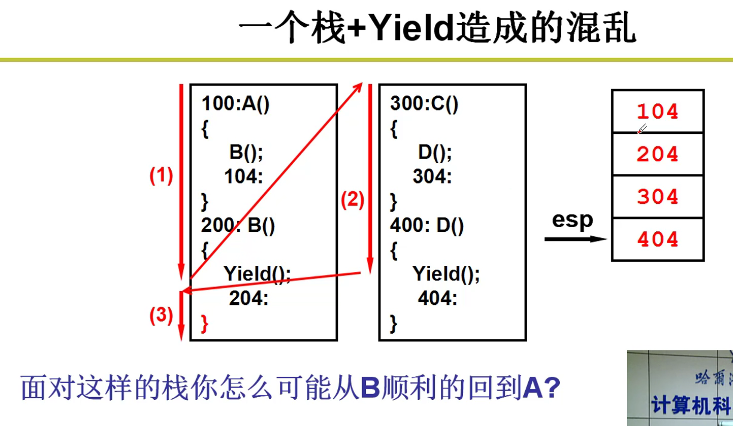
两个执行序列和一个栈:
- Yield会让当前进程放弃CPU嗷!!!但是ret从理论上来说,应该在本进程中切换回别的函数执行嗷!!!(这里是模拟进程切换嗷!!!)
- return会弹栈,然后跳转到弹栈的栈顶,开始继续执行嗷!!!
- Yield才允许跨栈,ret是不允许跨栈的嗷!!!
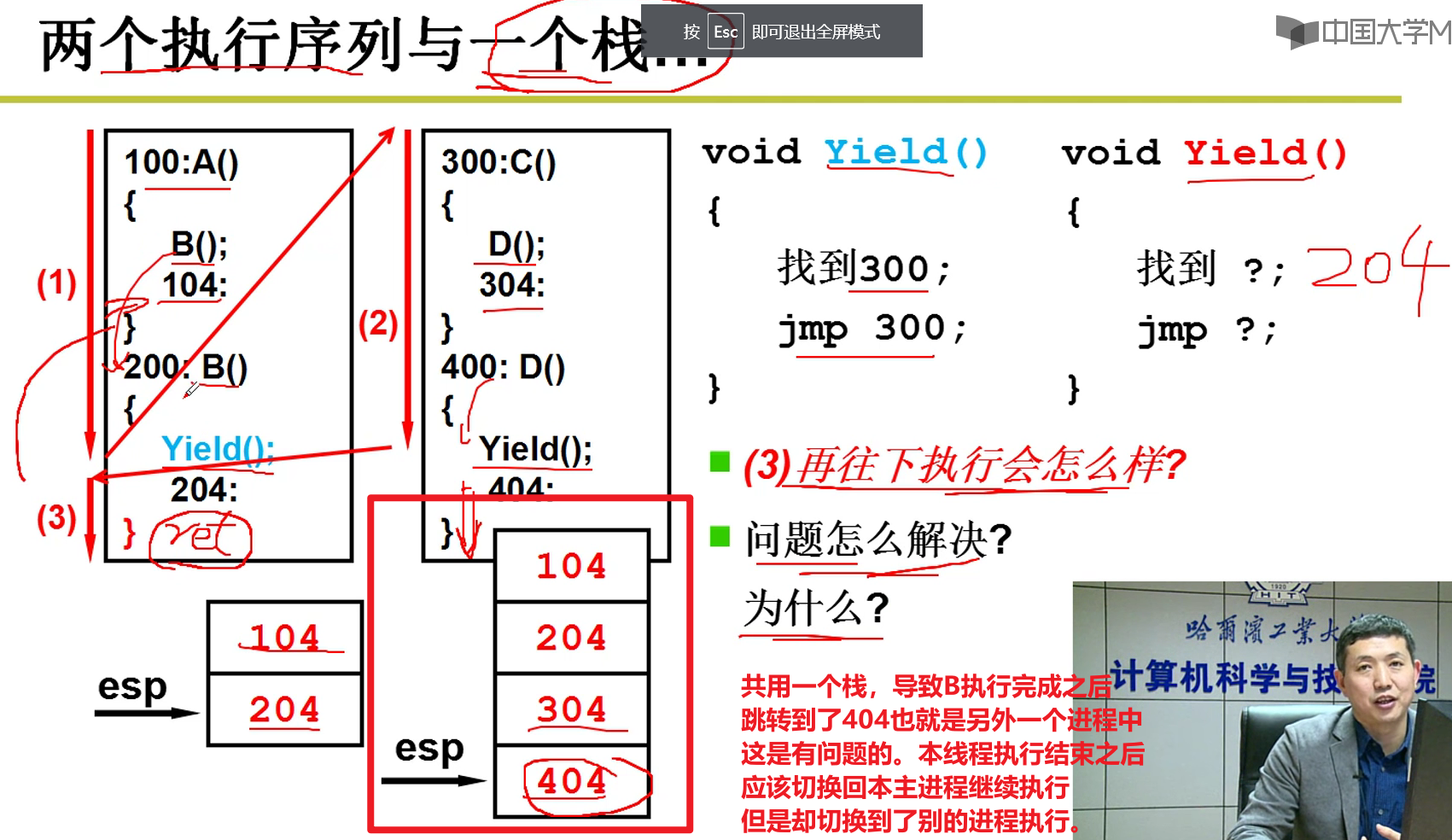
- 这里的逻辑是,A调用了B,B执行完了,应该回到A。但是这里的B执行完了之后却跳转到了D中执行,人傻了orz。
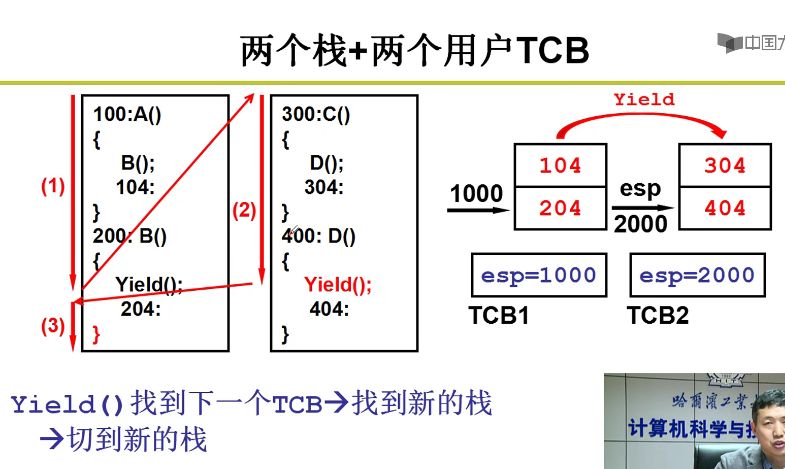
一个栈到两个栈:
- 切换进程的时候,首先栈也是要切换的嗷!!!要切换目标进程对应的栈嗷!!!
- TCB是一个全局的数据结构嗷!把栈的指针会放入到全局的TCB中,在切换进程的时候,对应的栈就进行了切换嗷!!!

100 -> 200 -> 300 -> 400 -> 400执行完成之后,还是执行100中的内容:
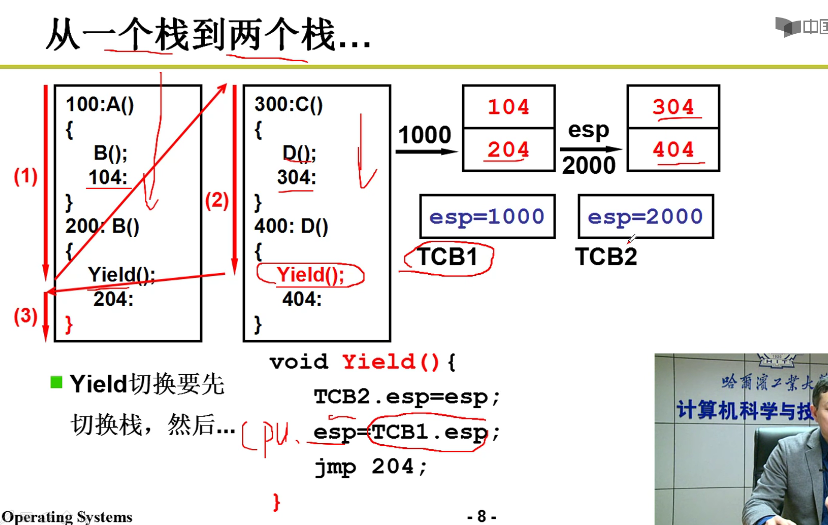
- 上面哪个Yield,本质上就对于内存中的寄存器,进行了切换栈的操作嗷!!!TCB和栈相互配合,这是核心的部分嗷!!!
下面这一段Yield就出现问题了,跳转到204去执行,这个时候对应的是esp=1000的这个栈。执行完成204之后,遇到了},会自动从栈中弹出元素,跳转到这个元素继续执行。我们发现弹出来的元素是204 … ,这样导致204及以下的代码又被执行了一遍嗷!!!
切换栈的时候,根据不同的进程才去切换不同切换嗷!!!
- 核心代码解决这个问题:

jmp 204这个语句,导致}不执行,栈内保存的204这个地址始终没有弹出来orz,咱把它去掉,那么栈中的204就会弹出来啦!!!
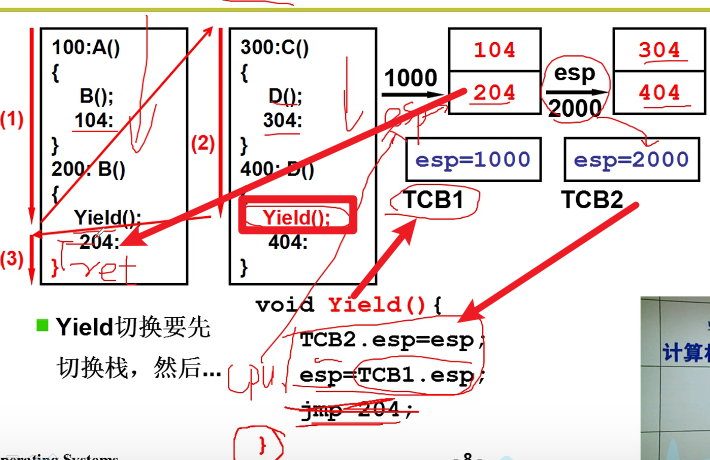
说白了,这里的Yield函数,本质上就是把寄存器中的栈切换为了1000而已,进程的跳转,本质上是通过1000的204栈顶元素和Yield函数的}实现的嗷!!!
204弹出来执行之后,再次遇到}。再次ret弹出来104,跳转到了A中的方法继续执行,这样就实现了我们的目的嗷!!!
- Yield实现线程的切换 -> 进程独立的栈(TCB和栈相互对应嗷!!!)加上寄存器的切换(栈的切换),实质上就实现了进程切换和顺序执行协调的功能嗷!!
Create(线程初始化):

- 初始化无非就是完成了线程对应的栈的初始化而已嘛!!!

- 用户级线程切换就可以这样实现嗷!!!
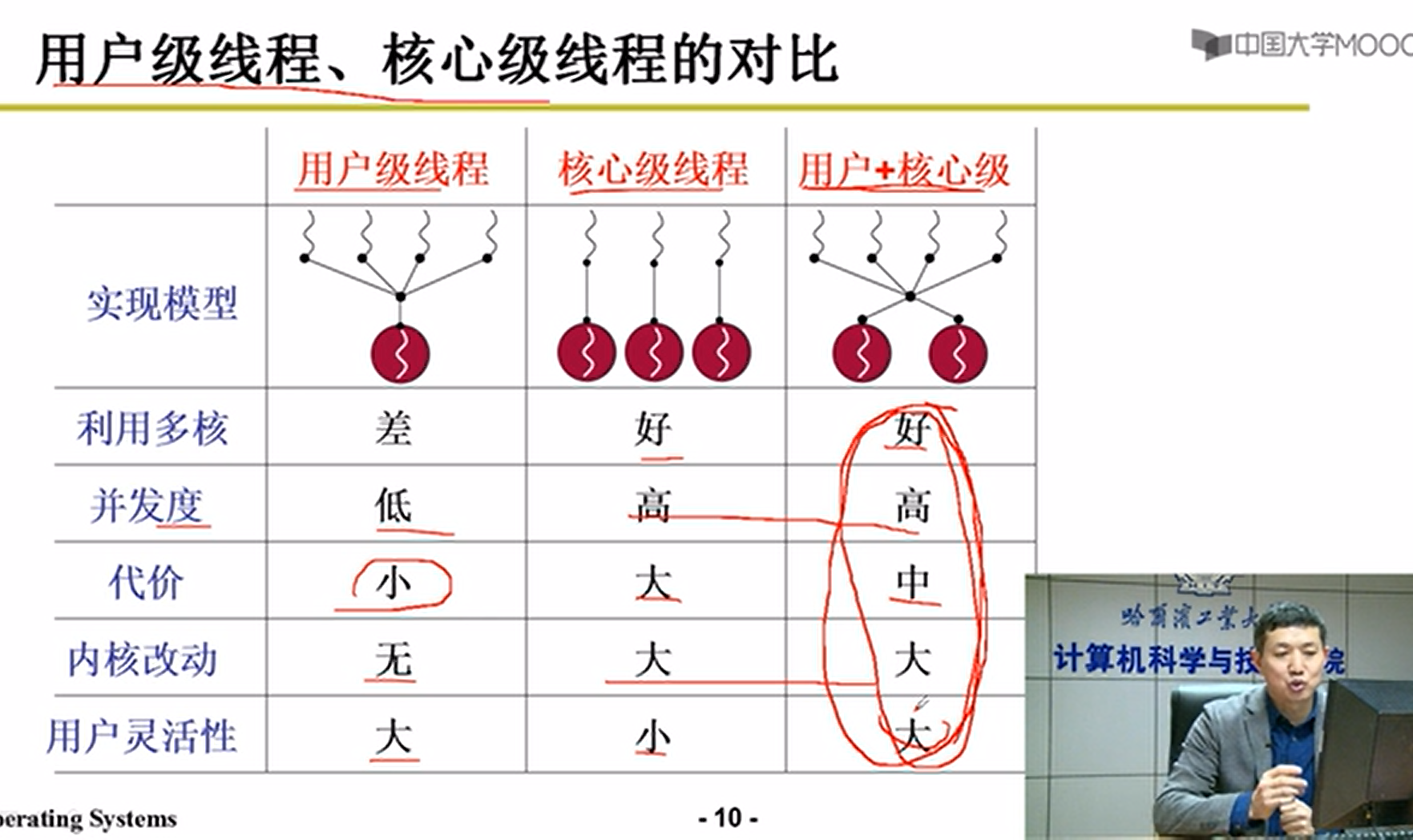
用户级别线程:
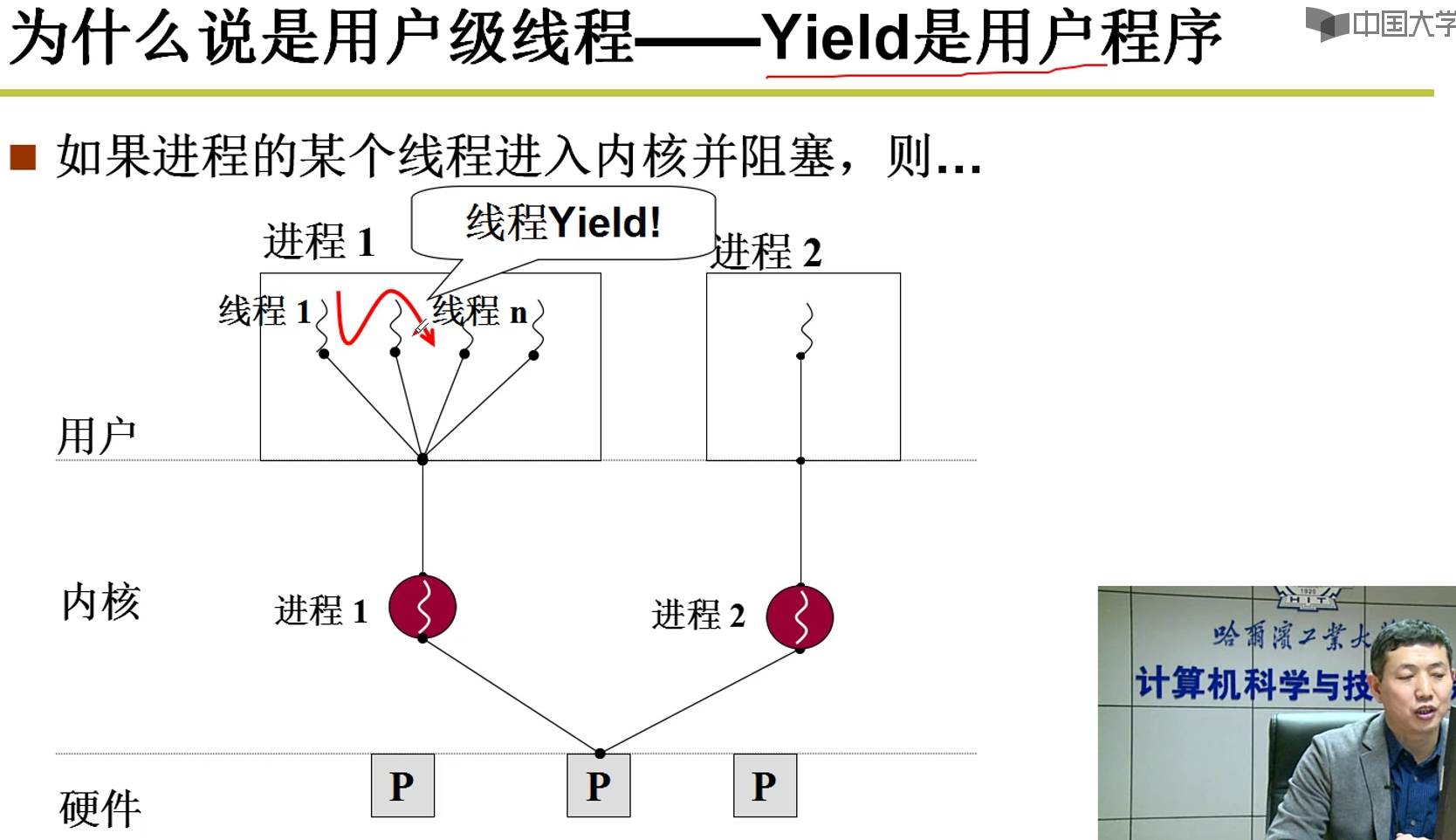
上面这种模式的问题就是:虽然有非常多的用户级线程,但是对应的只有一个内核级进程,内核无法感知到用户级线程的存在。比如两个线程分别为下载和显示,对应的内核进程的下载阻塞了,但是进程1无法感知到显示进程的存在。这个阻塞,就会导致内核的进程切换,切换到了进程2,这样浏览器下载的内容还是显示不出来啊orz,导致用户体验极差orz。这就是上面这种模式的缺点嗷!!!如果系统中没有其他线程,甚至会导致CPU空转。
内核级别线程:
- 创建线程的时候,就在内核中创建,TCB存在于内核之中,内存可以感受到TCB的存在嗷!!!
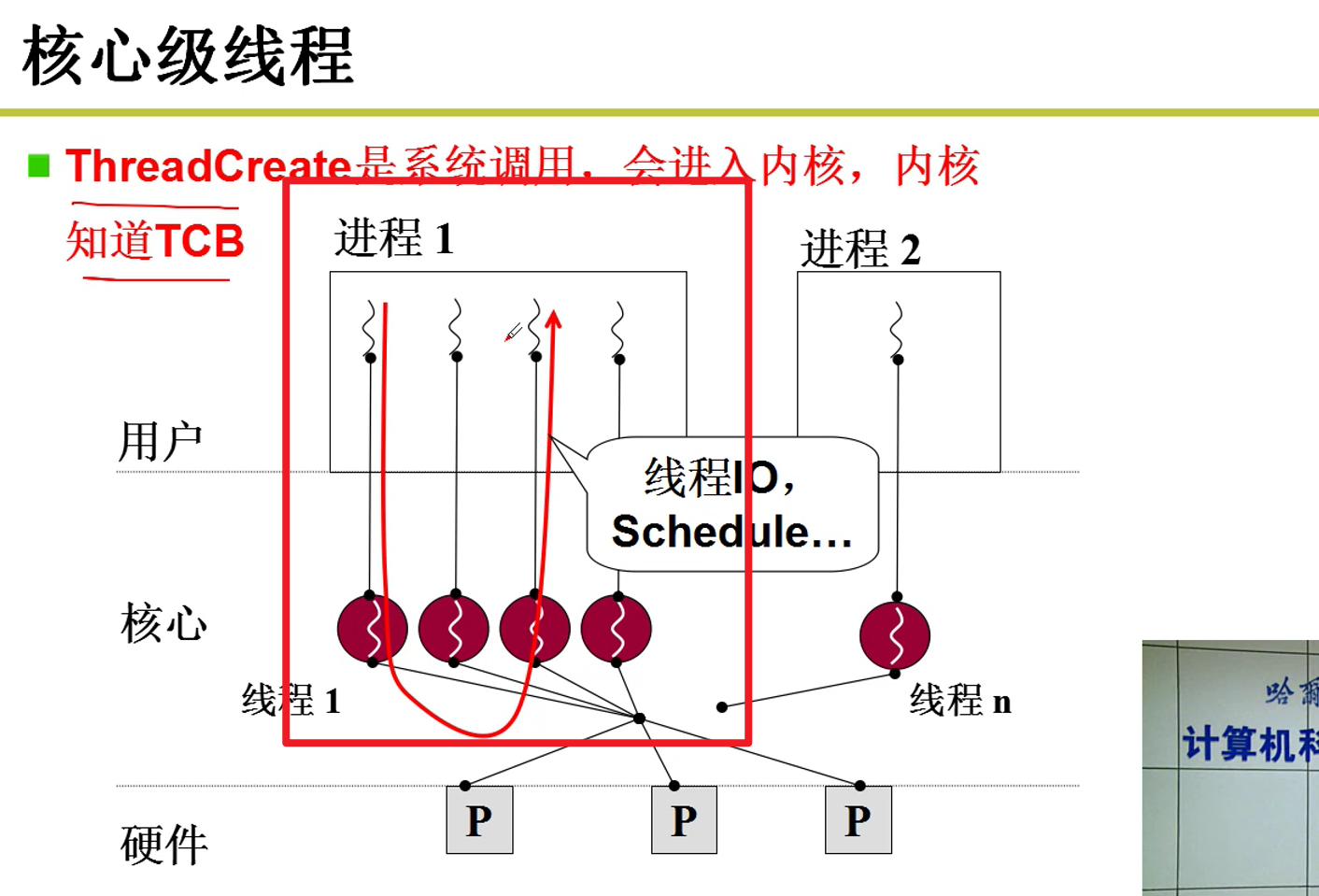
内核感知到一个进程中某个线程阻塞,就可以及时切换到别的线程执行嗷!!!就解决了上述的问题嗷!!!
- 系统级别的线程的系统调用所通过的Yield方法,是用户不可见的,调度点由系统决定嗷!!!Yield如果在内核中被称为Schedule,比用户级别的线程要复杂嗷!!!
内核级线程:
- 进程都在内核嗷!!!为什么进程在内核呢?
- 因为要分配资源
- 要访问系统中的一些资源
- 因此进程作为资源分配的基本单位,在内核中嗷!!!
- 多核(这个概念和多处理器还有点区别)要想充分发挥作用:
- 就要使用线程嗷!!!
- 多个线程可以使用多个核,这样才能保证多核的资源被充分利用嗷!!!
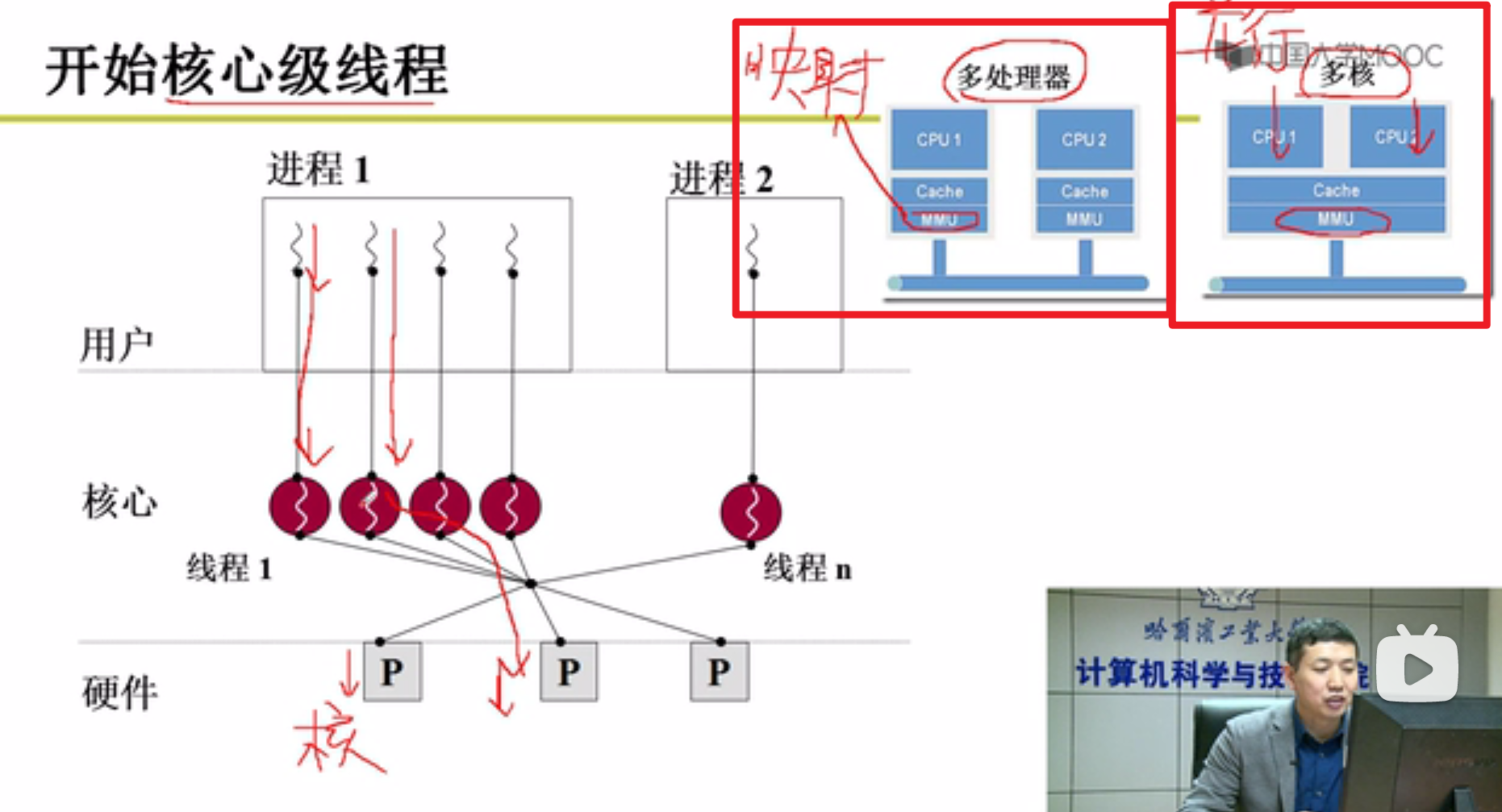
可以看出来,所谓的多核是在同一个MMU和Cache的基础上,并行运行的多个CPU。这就保证了,在进程所分配的资源,例如MMU不变的基础上,能够同时运行多个进程,榨干多核的处理能力嗷!!!
看到左图中的核心级线程,只有核心级线程能够被操作系统中的多核感知,被多核调度,并发并行执行,这也是内核级线程的优点嗷!!!多进程,用户级线程都做不到,但是核心级线程做的到嗷!!!
- 从用户级别线程引申出来:
- 切换到内核,在内核栈中分配空间,才能够创建内核级别的线程嗷!
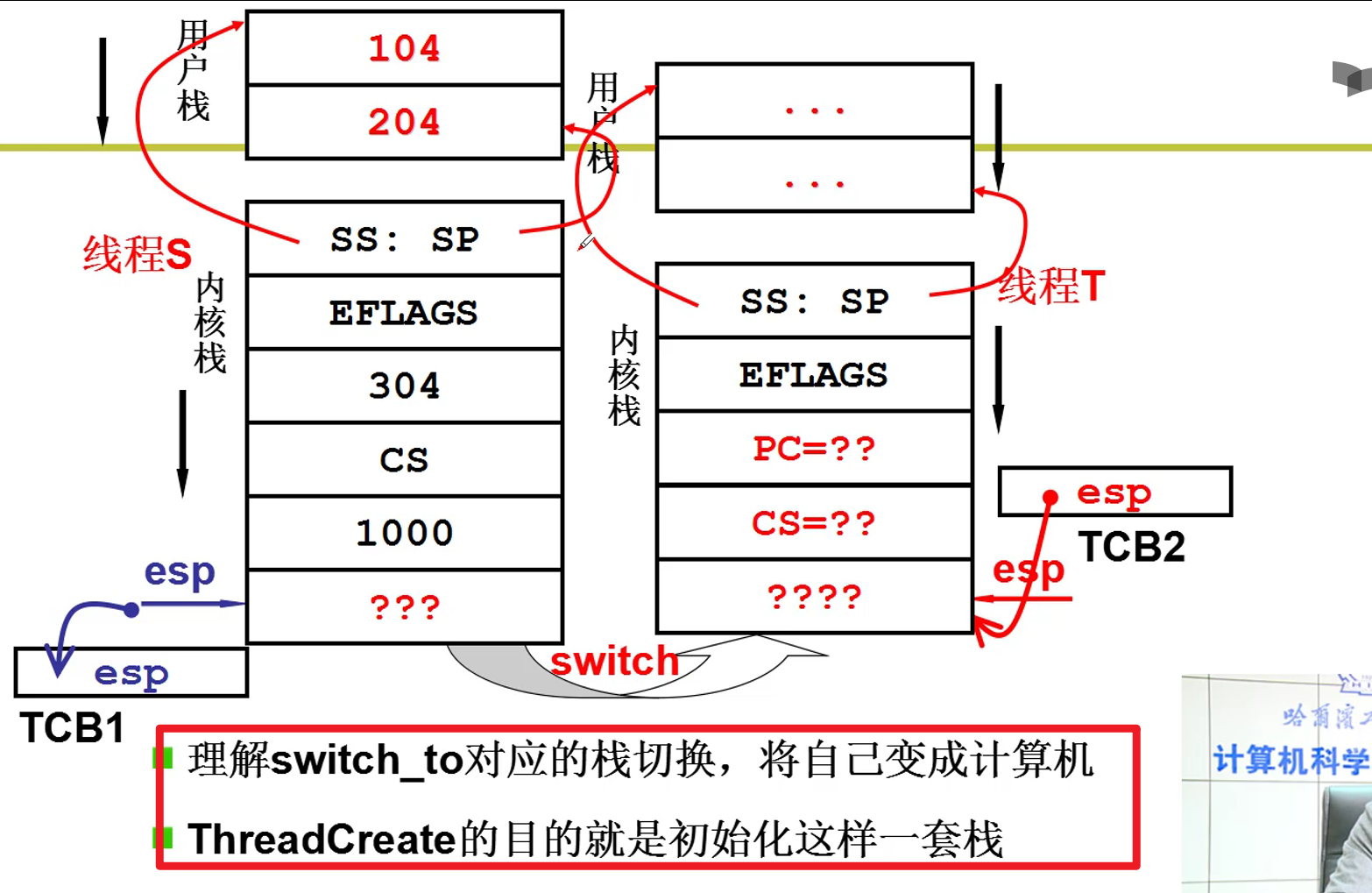
- 两个栈,是用户级线程的核心。两套栈,是内核级别线程的核心嗷!!!

内核级别的TCB切换的时候,用户栈和内核栈,这一套栈都要切换嗷!!!
- 用户栈和内核栈之间的关联:
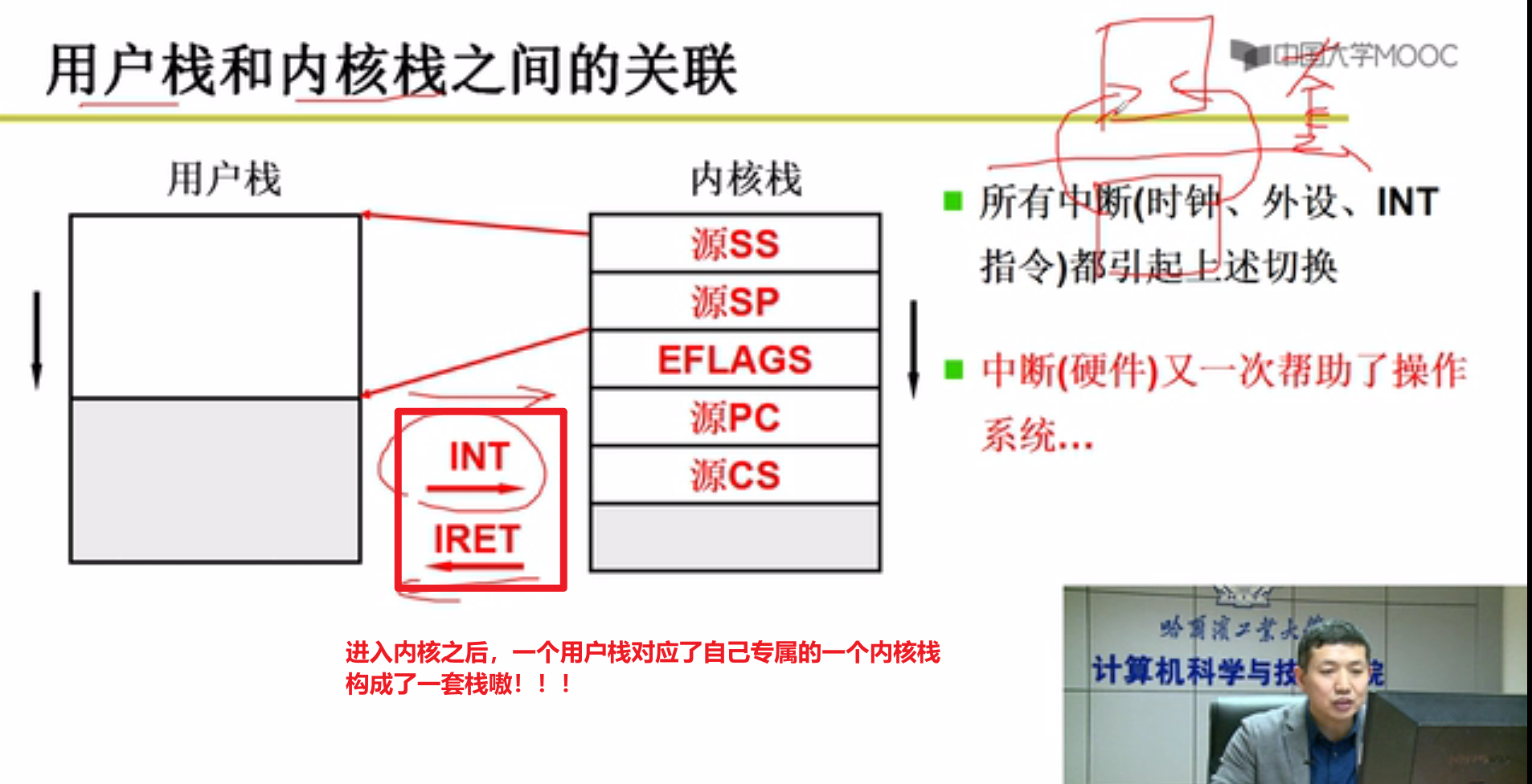
- 带着中断进入到核心级线程的例子:
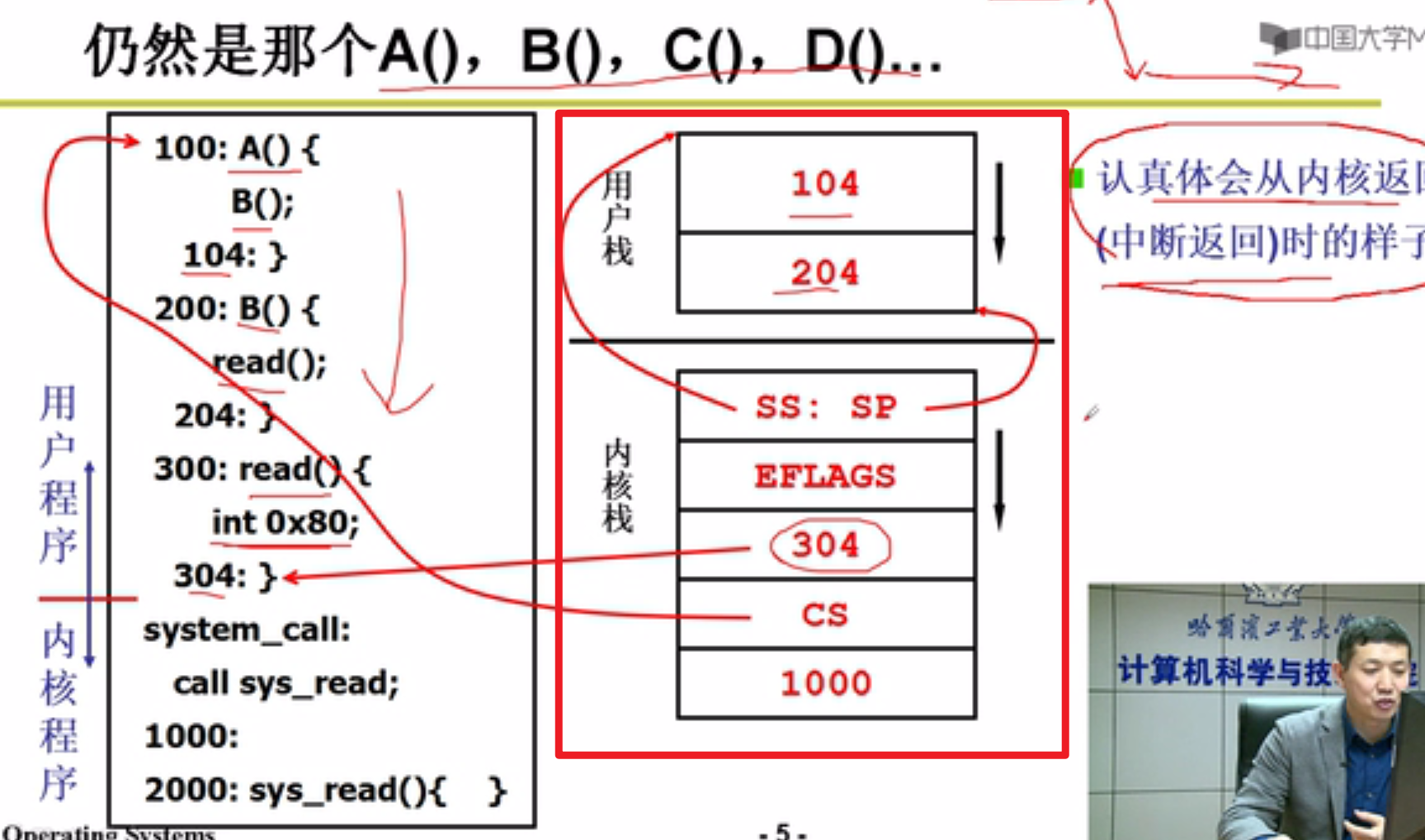
以前用户栈的切换就是切换用户栈,现在是切换内核栈,由于内核栈和用户栈紧紧绑定,就实现了用户栈线程之间的切换嗷!!!
上面就是内核态线程切换的核心代码嗷!!!通过中断进入内核就是通过INT 0x80来实现的嗷!!!
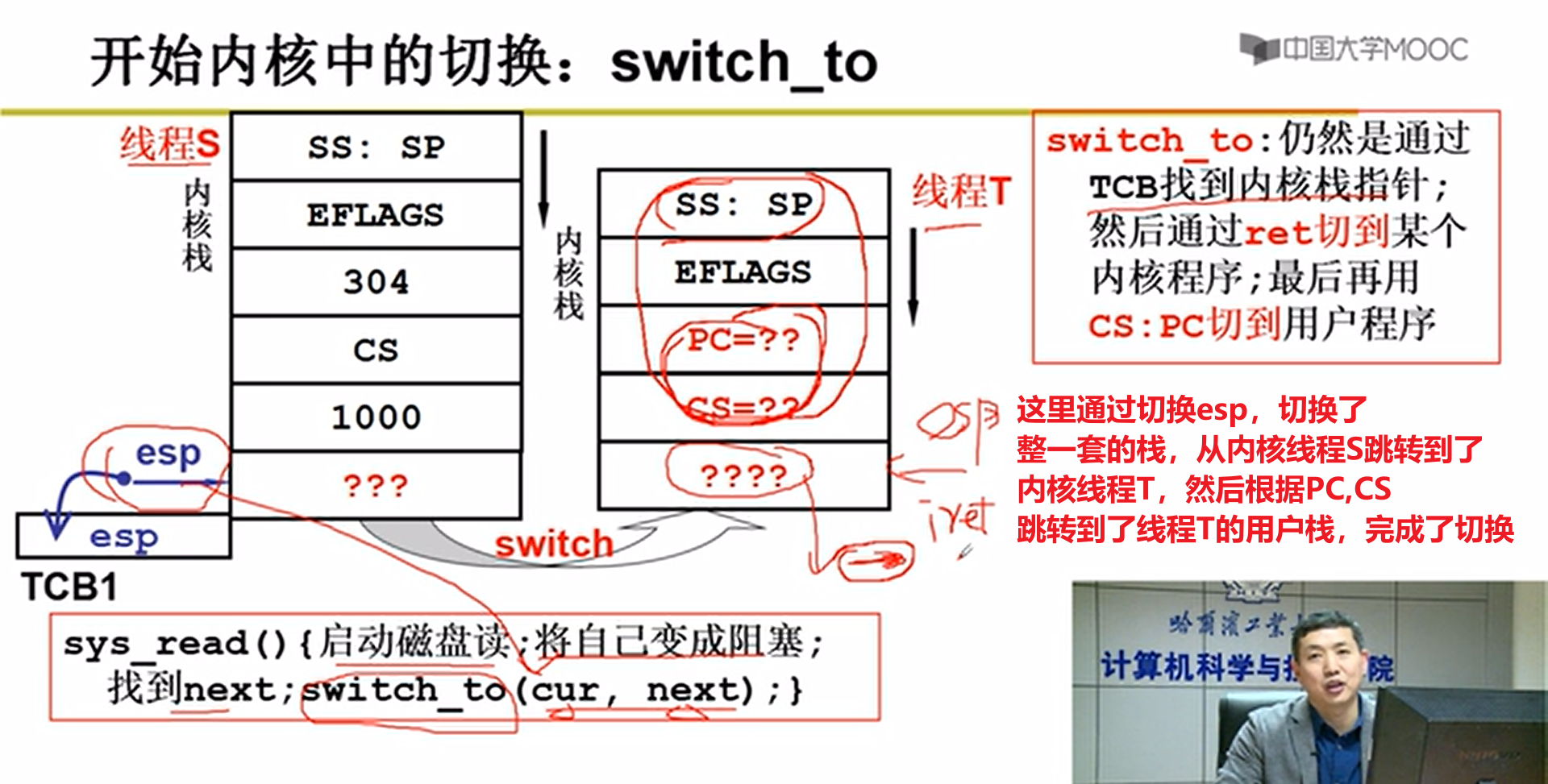
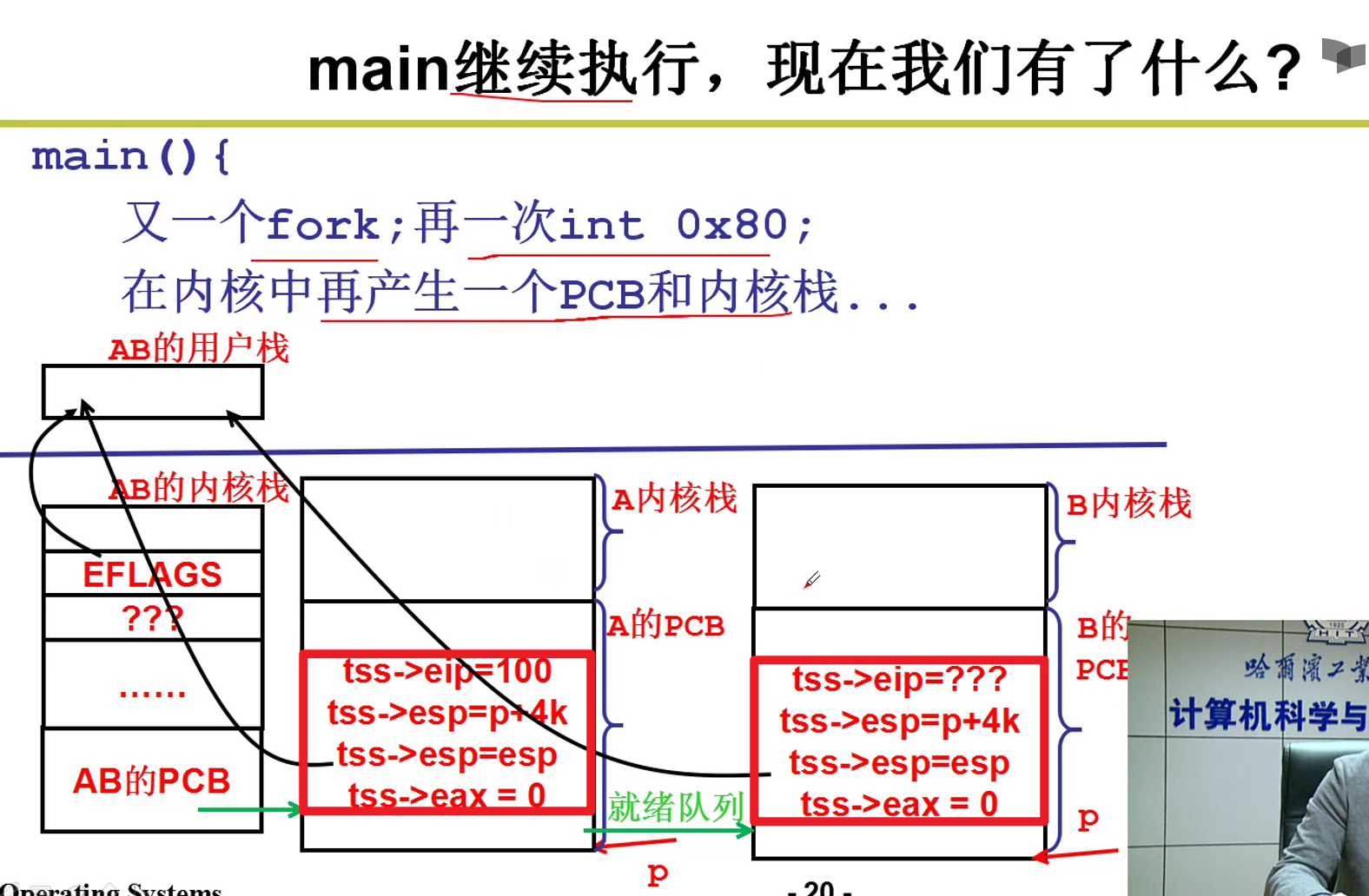
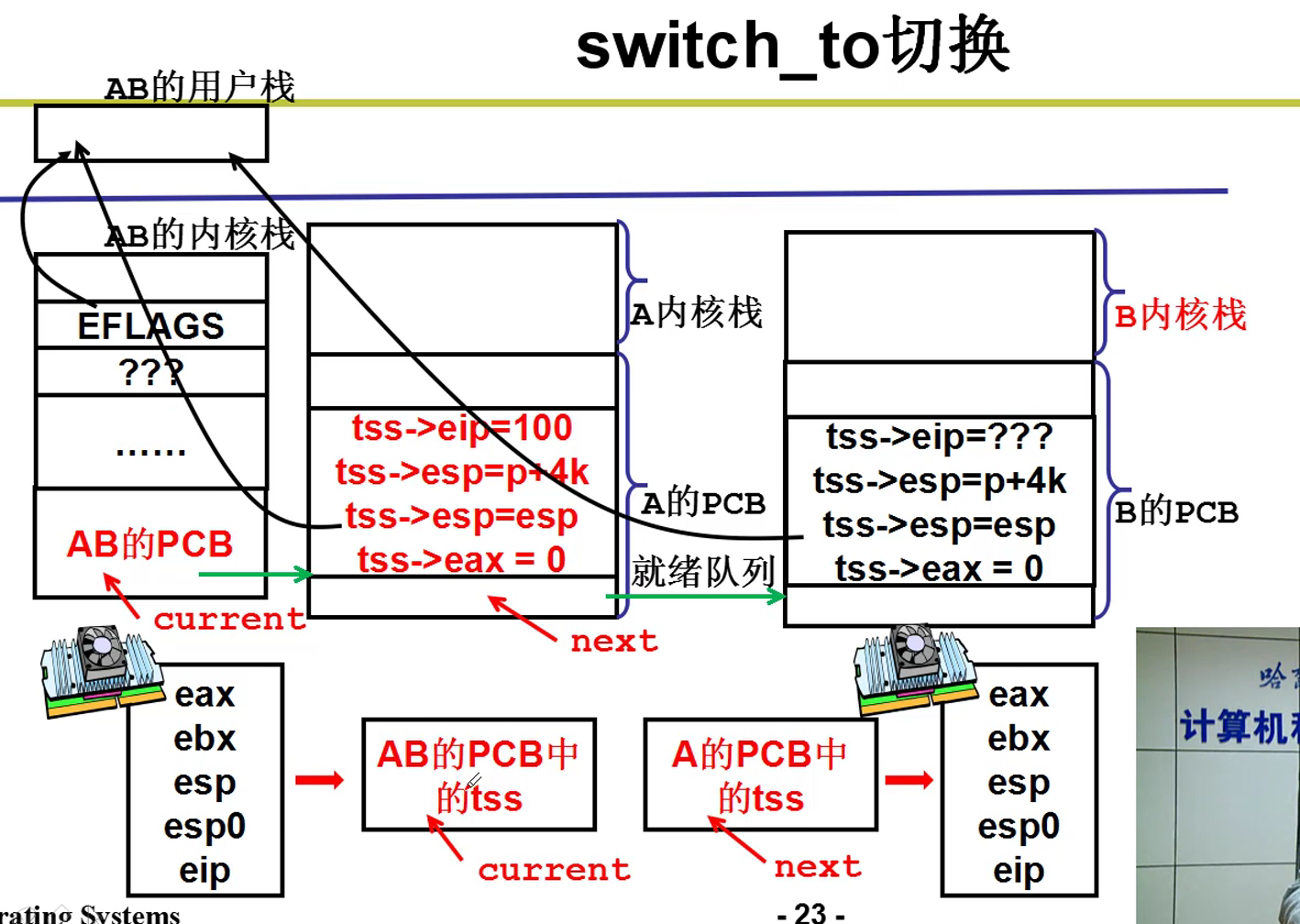
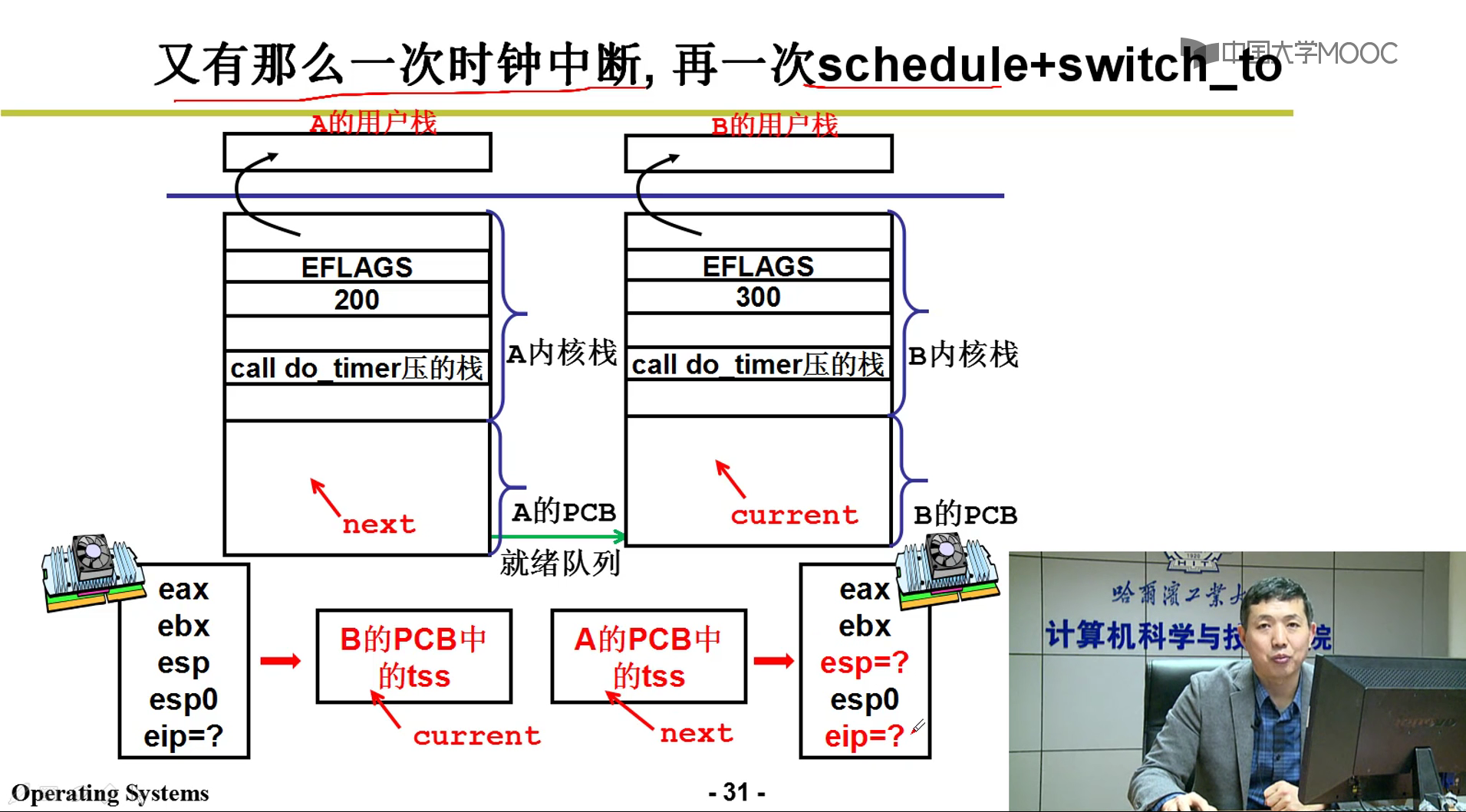
- 内核switch_to五段论:
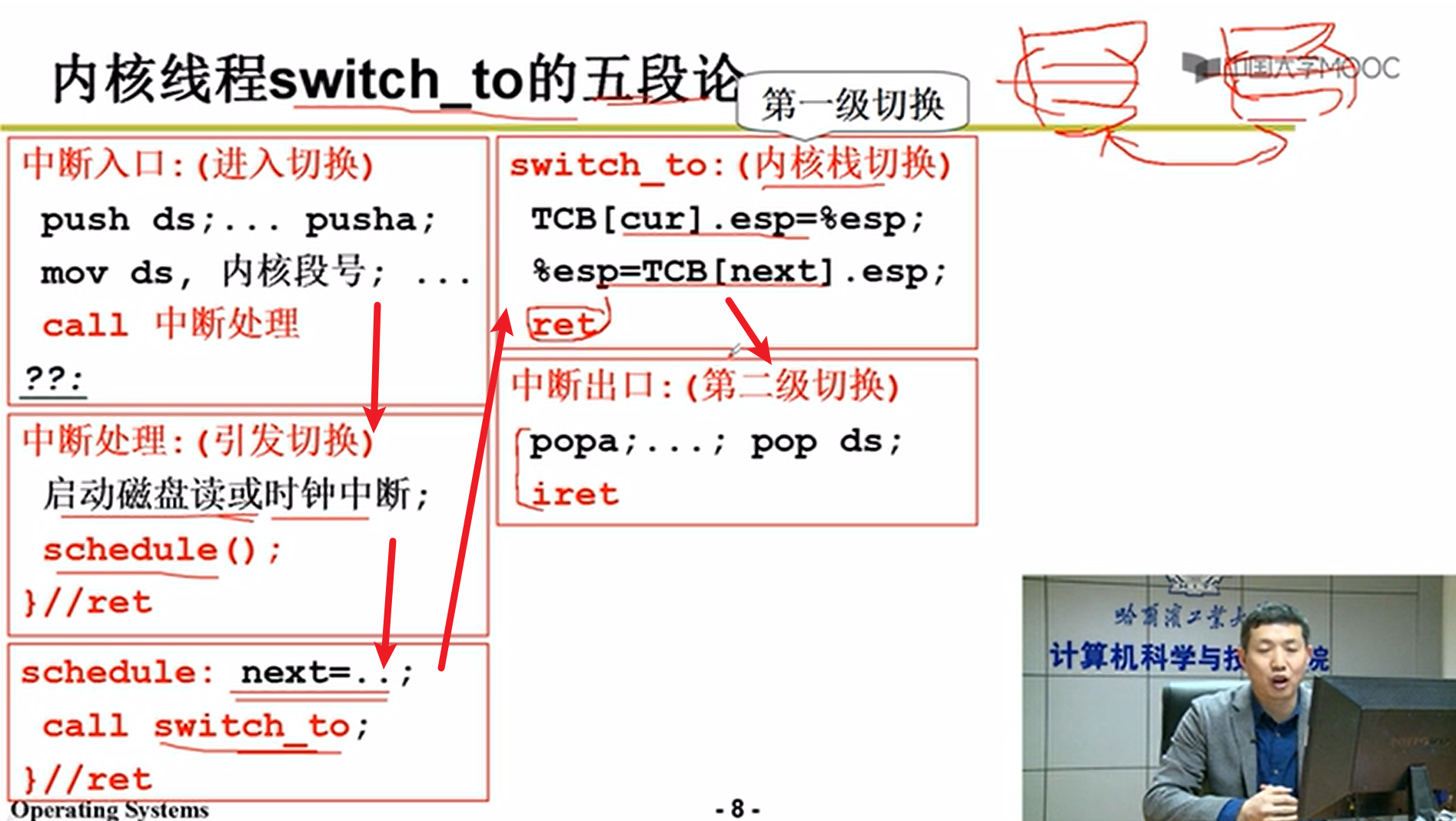
上面这个过程就是switch_to的整个流程嗷!!!

- 手动创建内核级别线程:
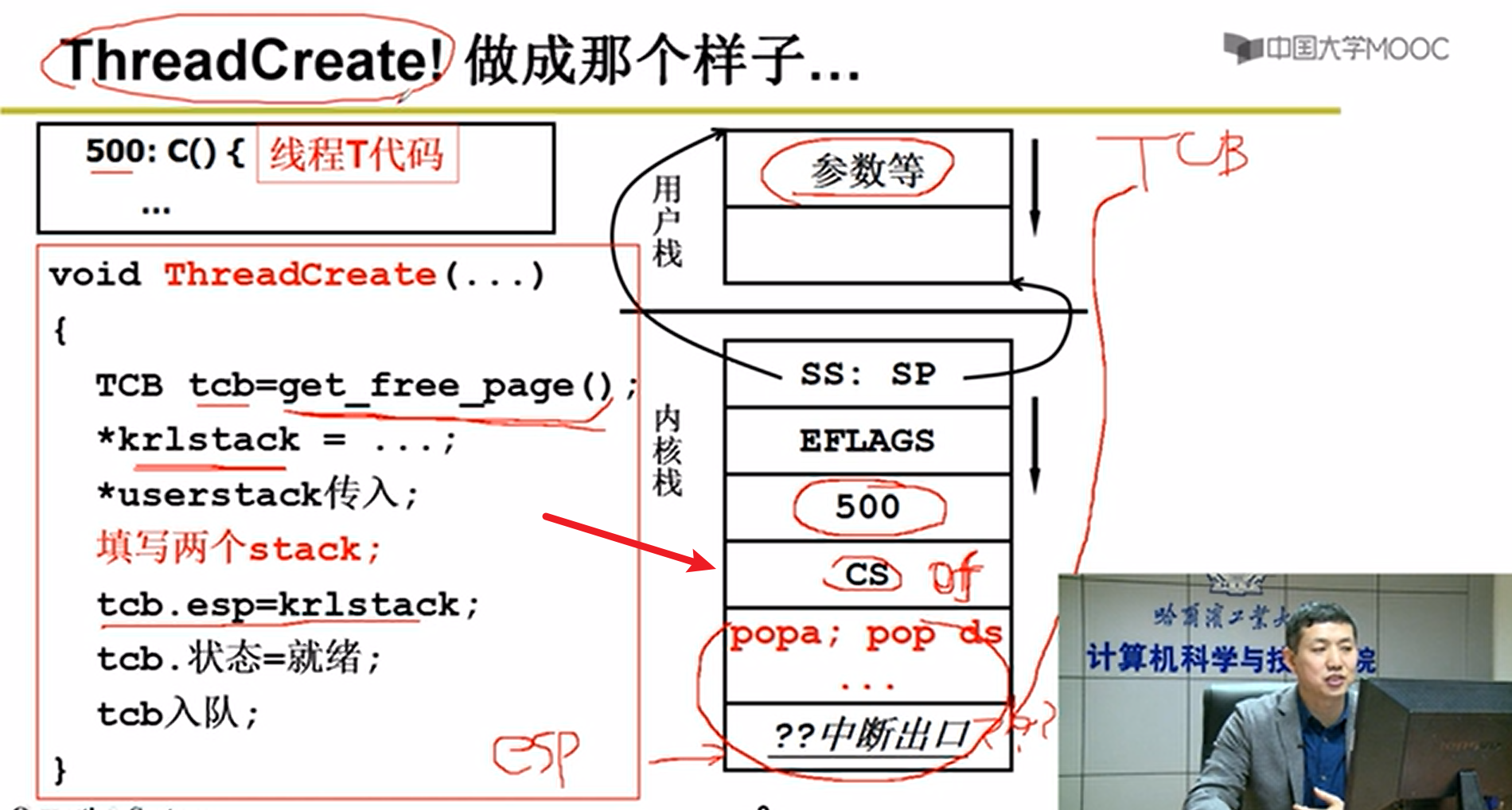
可以看出来,这里的Thread线程的创建,无非是在模拟我们的。
- 对比图嗷!!!
内核级别的代码实现:
- 回顾:
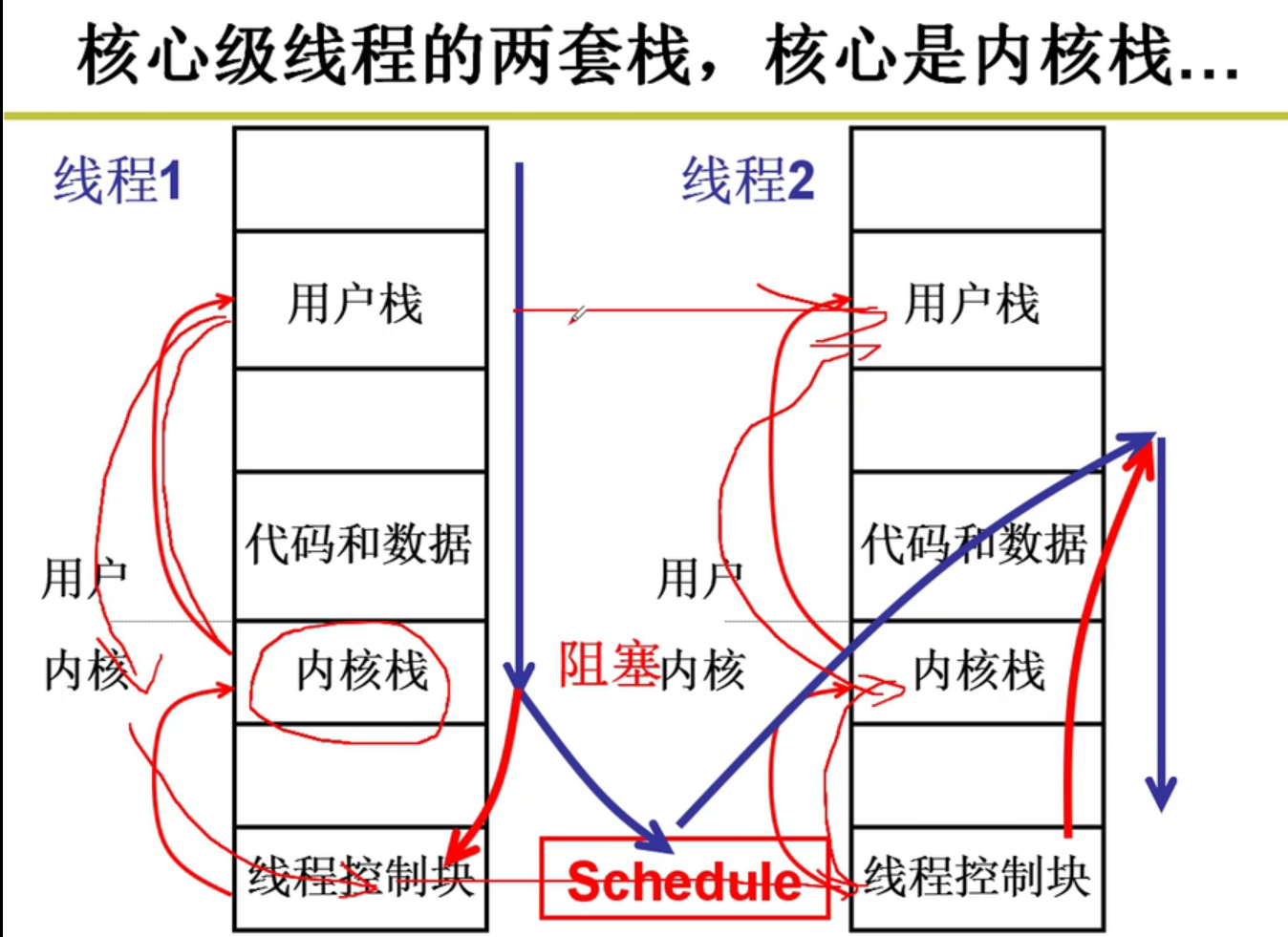
上图就是我们常说的五段论,用户只能看到内核之上的用户线程的切换。但是实际上,加起来一共进行了五次大的切换嗷!!!
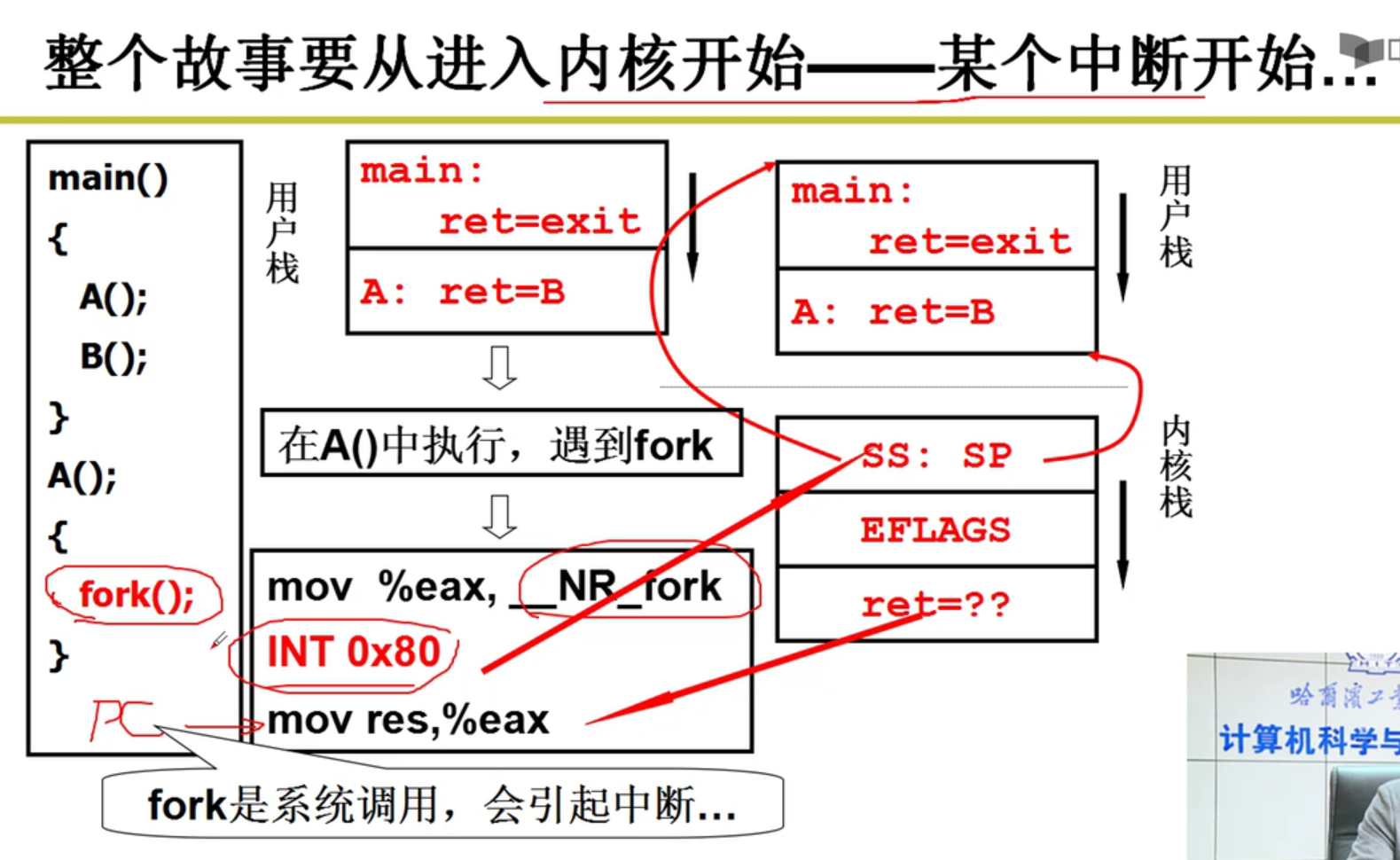
fork本质上引起了0x80这个中断,在0x80执行完成之后,才成功进入到内核。在执行0x80的时候,PC还是指向mov这条指令的。就在这个时候,ret被设置好,并且硬件帮助我们自动把SS和SP和用户栈建立了关联嗷!!!
ret下面就是system_call,执行中断处理函数,因此接着执行system_call函数嗷!!!
- sys_fork和类似于sys_write这种:
不一定能够正常执行,有可能被其他的线程阻塞,这个时候,就应该重新调度嗷!!!

下面那个cmp1和counter的计算,是时间片的判断,如果时间片用光了,也要触发重新调度的嗷!!!
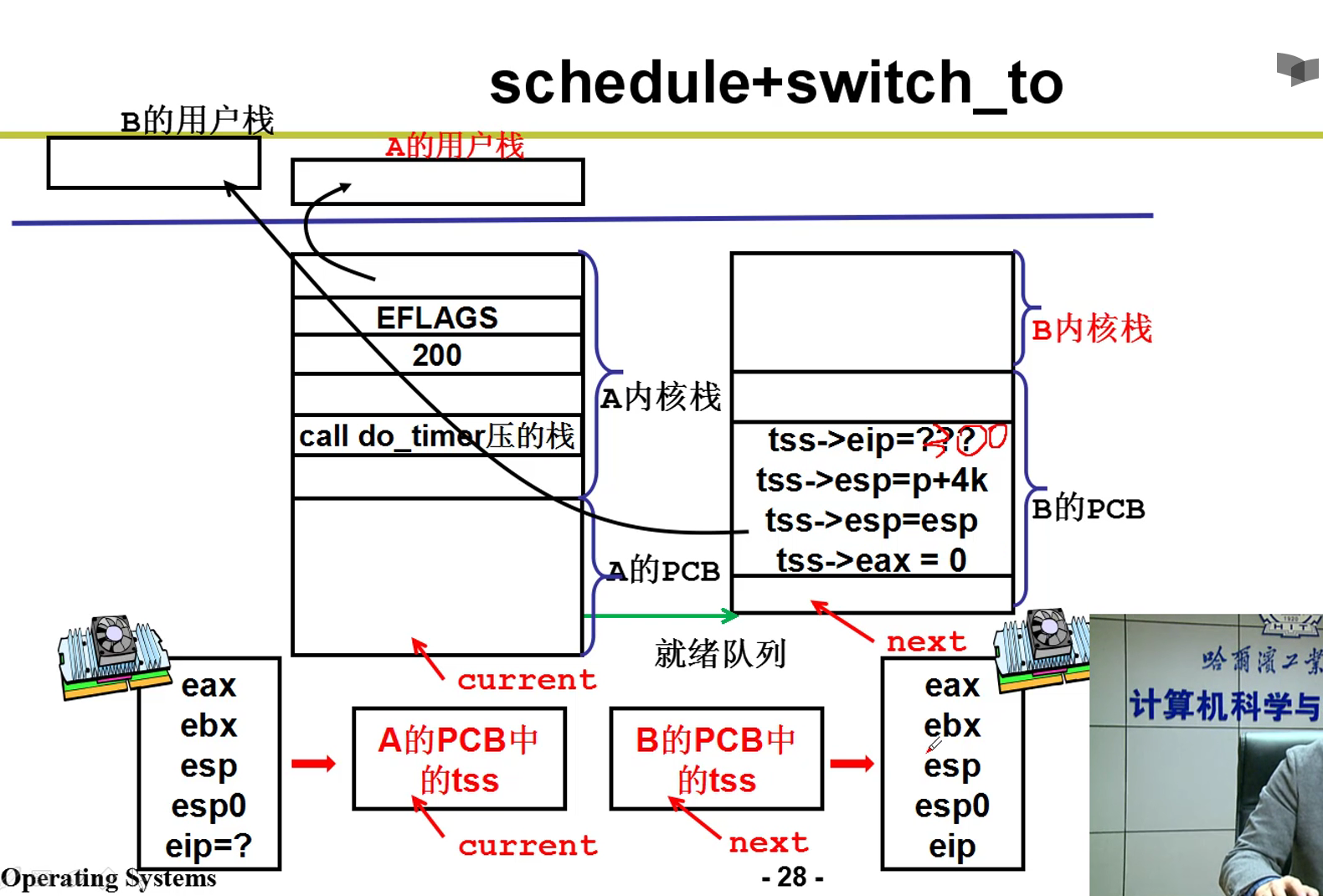
接下来,ret_from_sys_call就会执行中断返回函数嗷!!!

可以看到reschedule本质上就是将ret那个函数的地址压栈,jmp _schedule是调用了一个schedule的c函数。在C函数的最后,有一个
}。默认就是将栈中的ret_from_sys_call弹出来,执行这一段函数。本质上就是在执行完成schedule之后,执行系统调用返回函数嗷!!!中断入口是一堆push,中断出口是一堆pop
五段论中的schedule和中断出口:
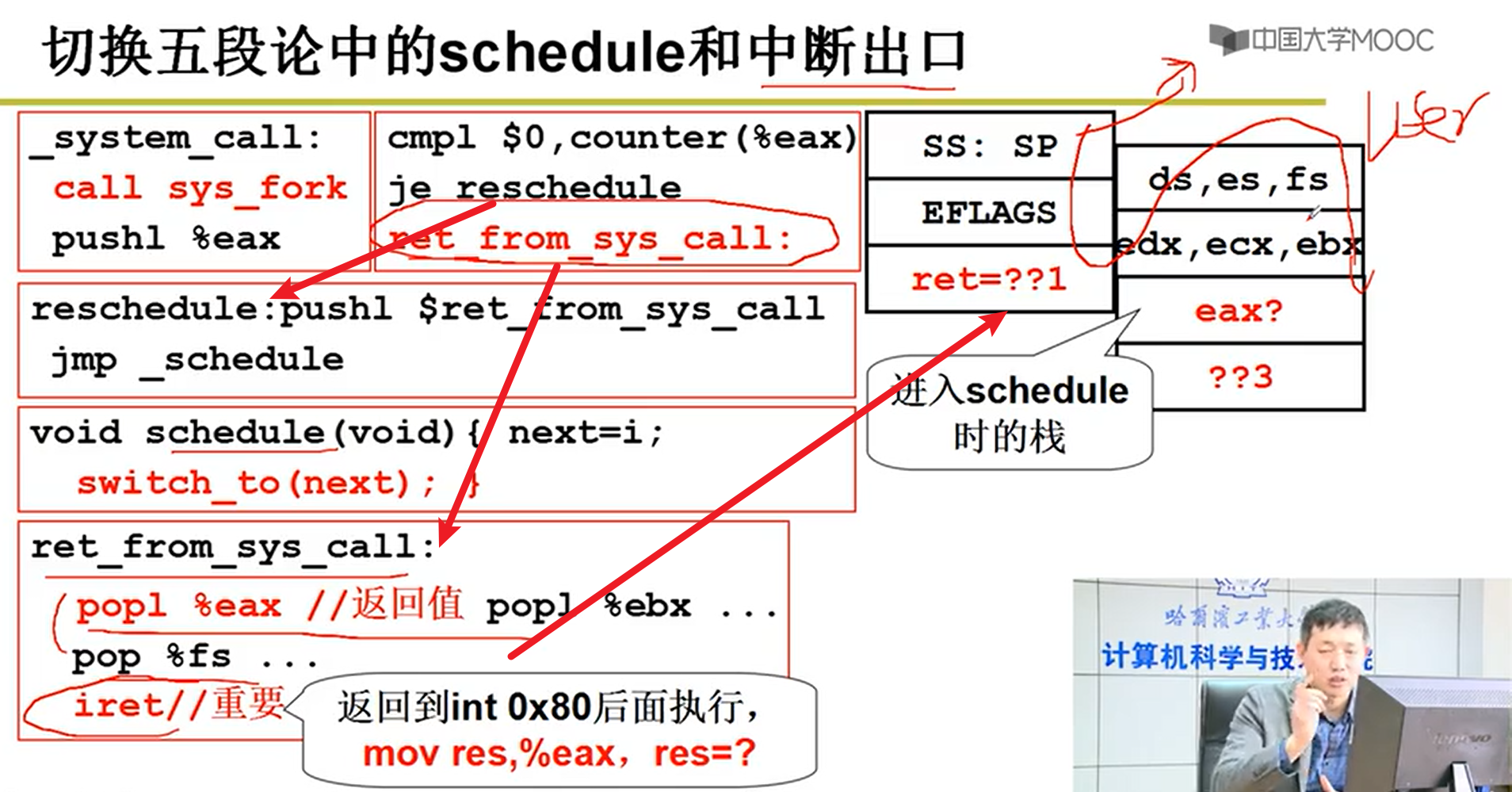
- schedule中的switch_to函数:
基于TSS的切换:不常用,一句长跳转指令非常方便,但是执行效率特别低,所以现在用的都是kernel
TR是固有的寄存器,选择描述符,指向TSS描述符。TSS就类似于之前的CS。
TSS就是类似于某个线程某个状态的所有寄存器的快照,切换就是把整个TSS状态扣在寄存器上,由此就完成了切换嗷!!!
这一条指令会非常长,没有办法变成指令流水,无法适用硬件的加速功能等嗷!!!
切换步骤:
- 将当前CPU的内容,由当前TR指向的TSS,将快照保存在TSS中
- 核心线程切换的时候,会将TR指向新的线程的TSS描述符
- 将新的TSS描述符中指向的新的TSS中的内容,扣到CPU的每一个寄存器中,这样就完成了线程栈的切换嗷!!!
INT —> Switch_to(Long_Jump) —> IRET(完成用户栈的切换嗷!!!)
只要做好TSS和TCB,就能够非常方便的进程切换嗷!!!
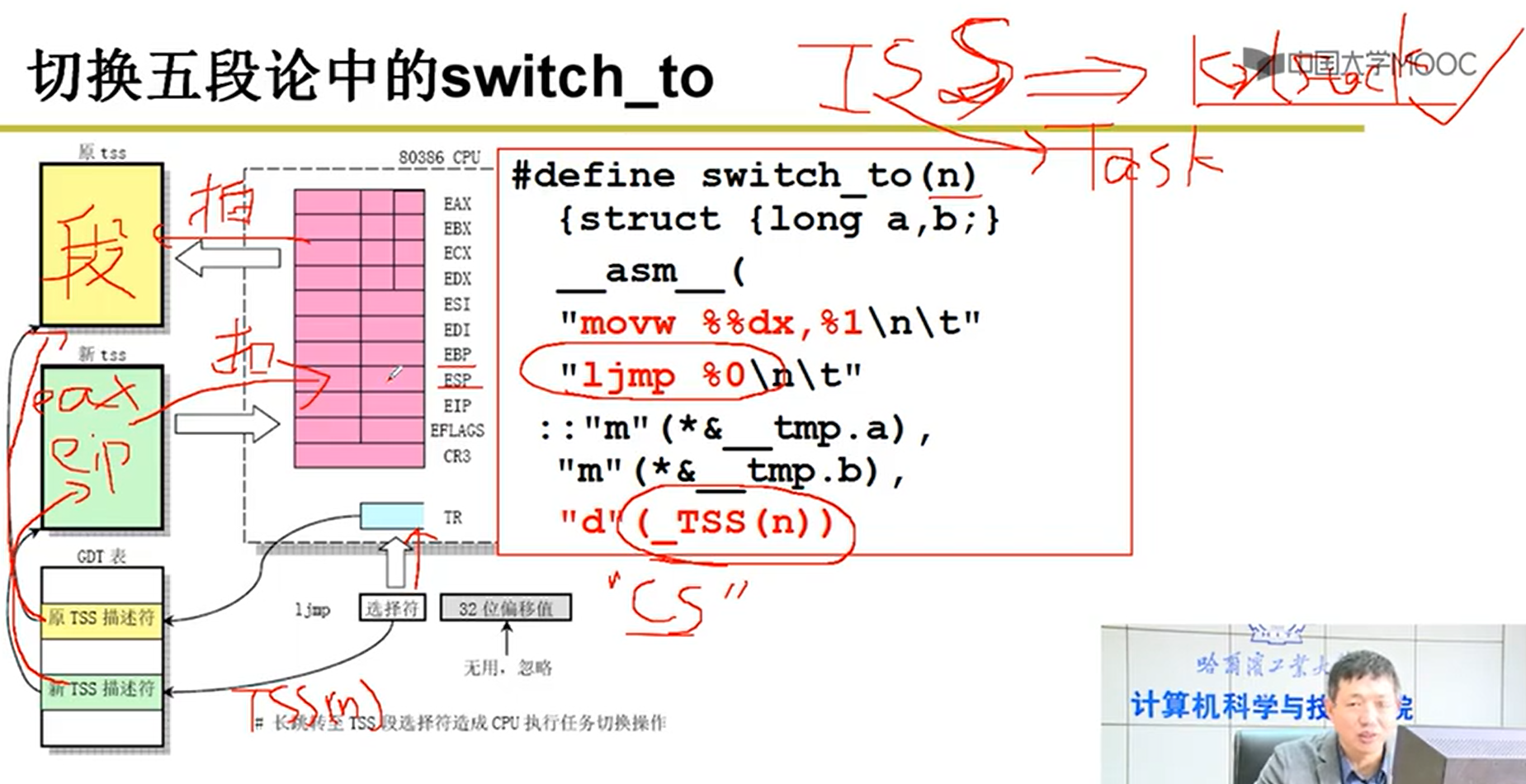
TSS实质上就是TCB中的一个子段嗷!!!
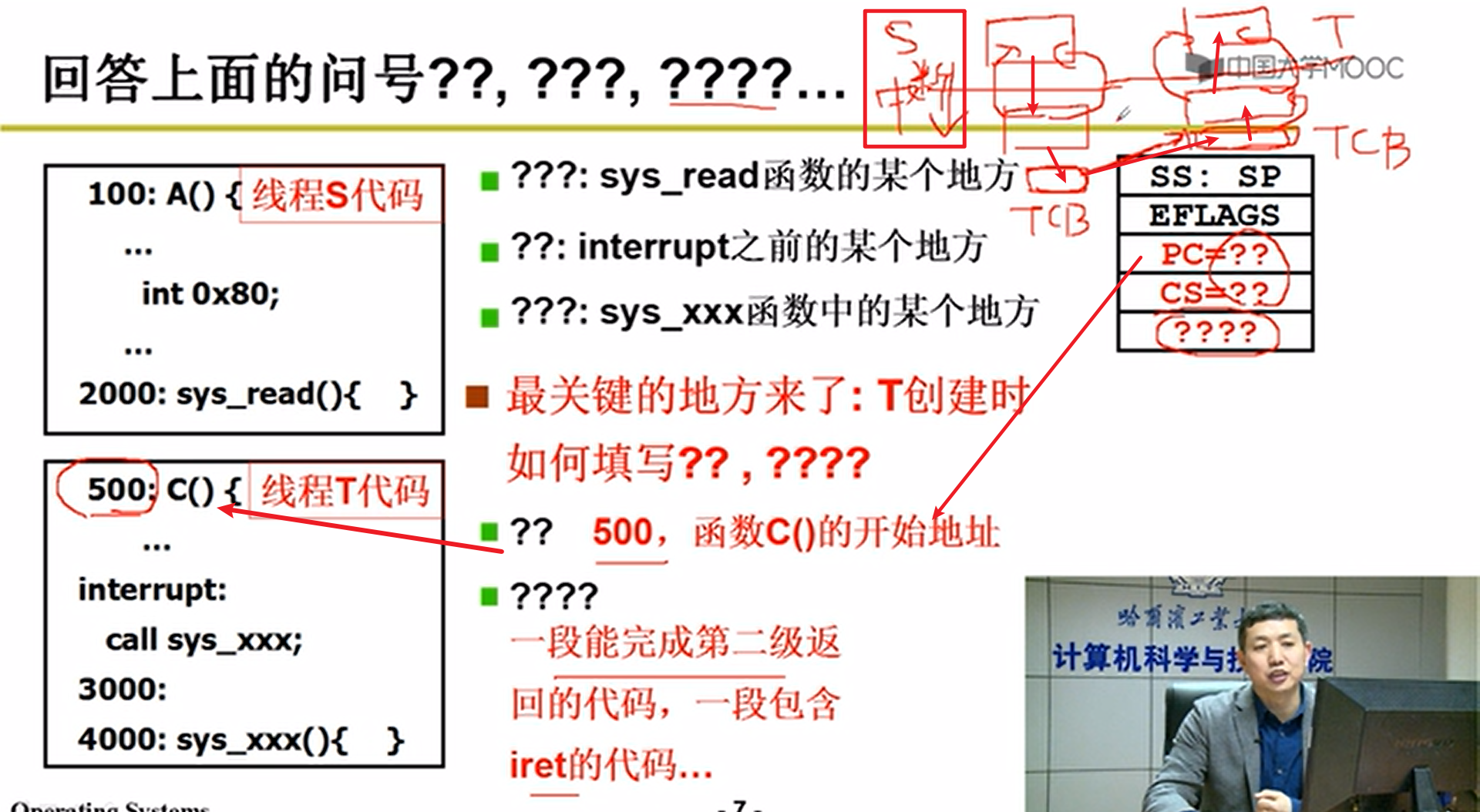
ThreadCreate:
- TCB要有,然后再把TSS做好,就能够成功嗷!!!

- copy_process的细节:创建栈:

不能用malloc,malloc是用户级代码,get_free_page才是内核级代码嗷!!!
创建TCB,创建用户栈,创建内核栈,关联两个栈:
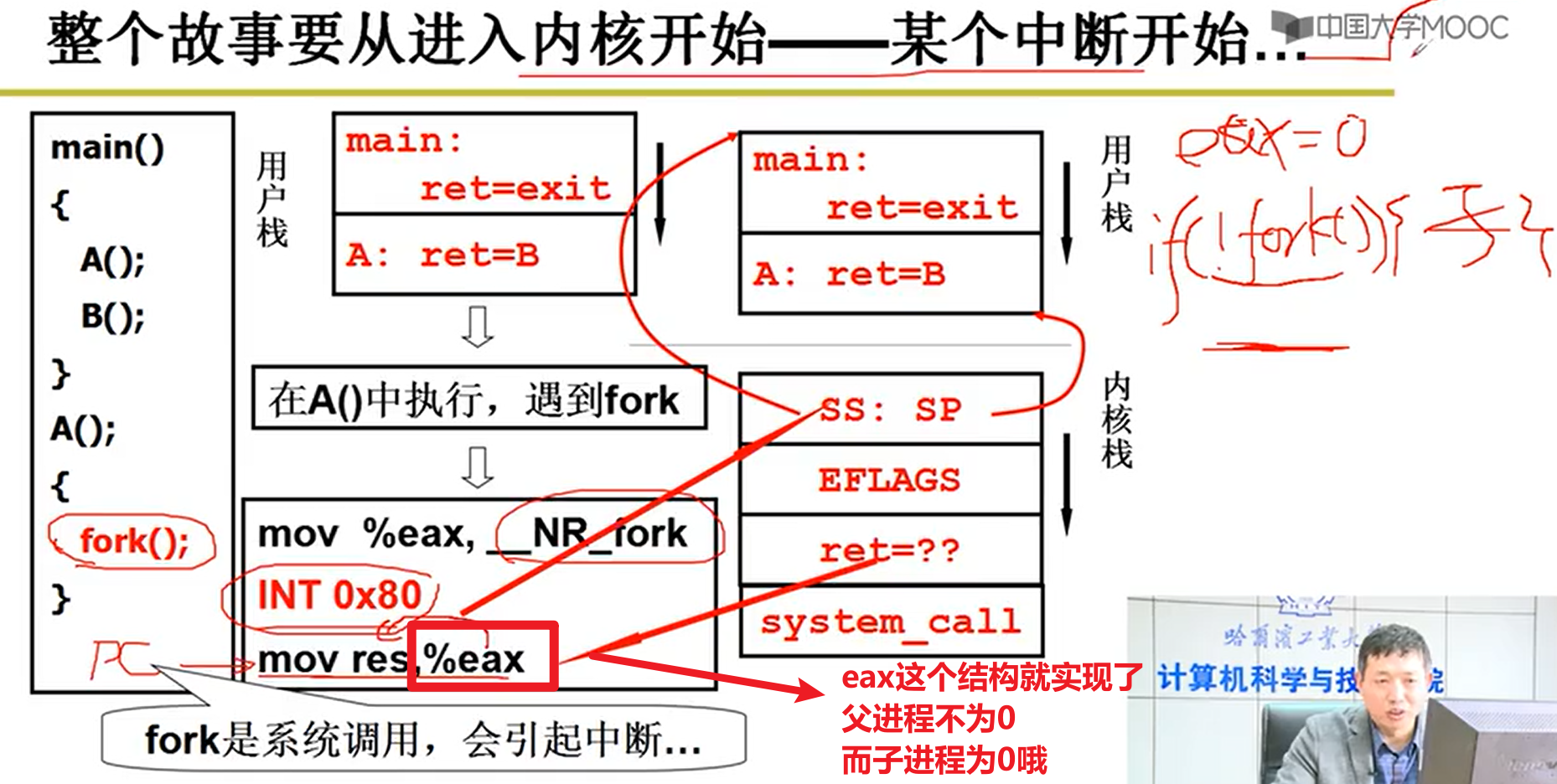
注意,子进程创建的时候,eax寄存器中的值被置为0了。mov的过程中,就会把res的值赋予为0,这就有了我们经典if(!fork())中那个0的由来嗷!!!
父进程为啥不是0呢?可以看看代码嗷!!!
- 如何执行我们想要的代码?
也就是子进程在exec(cmd)后,如何跳转并执行我们规定子进程执行的代码:
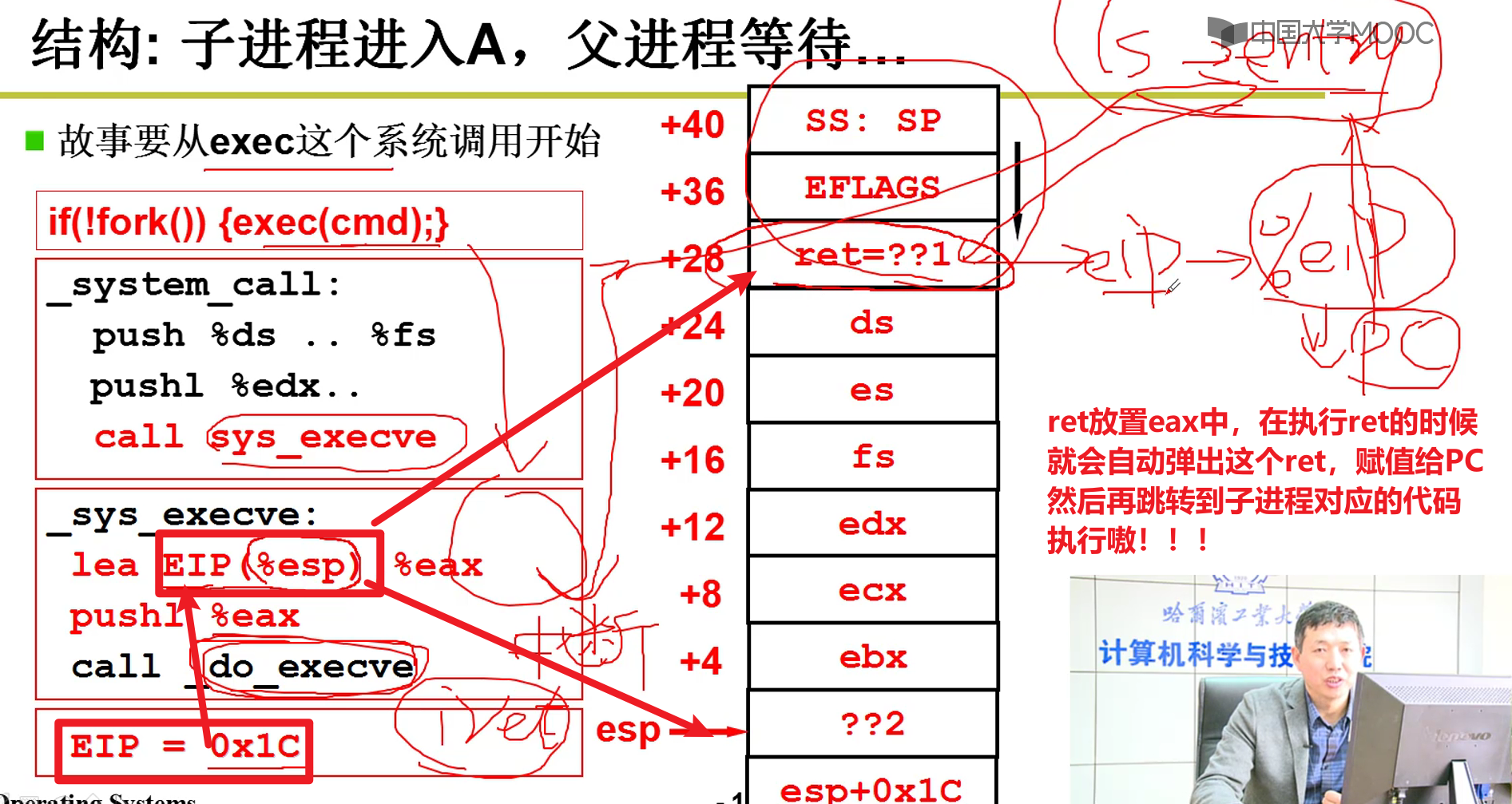

- summary:
操作系统的那颗“树”:
CPU -> 要让CPU好好运转嗷!!! -> 跳转 -> 如何跳转?
一直用户态怎么办?
- 引入内核态切换


- switch_to的切换:

- 如何打出B?
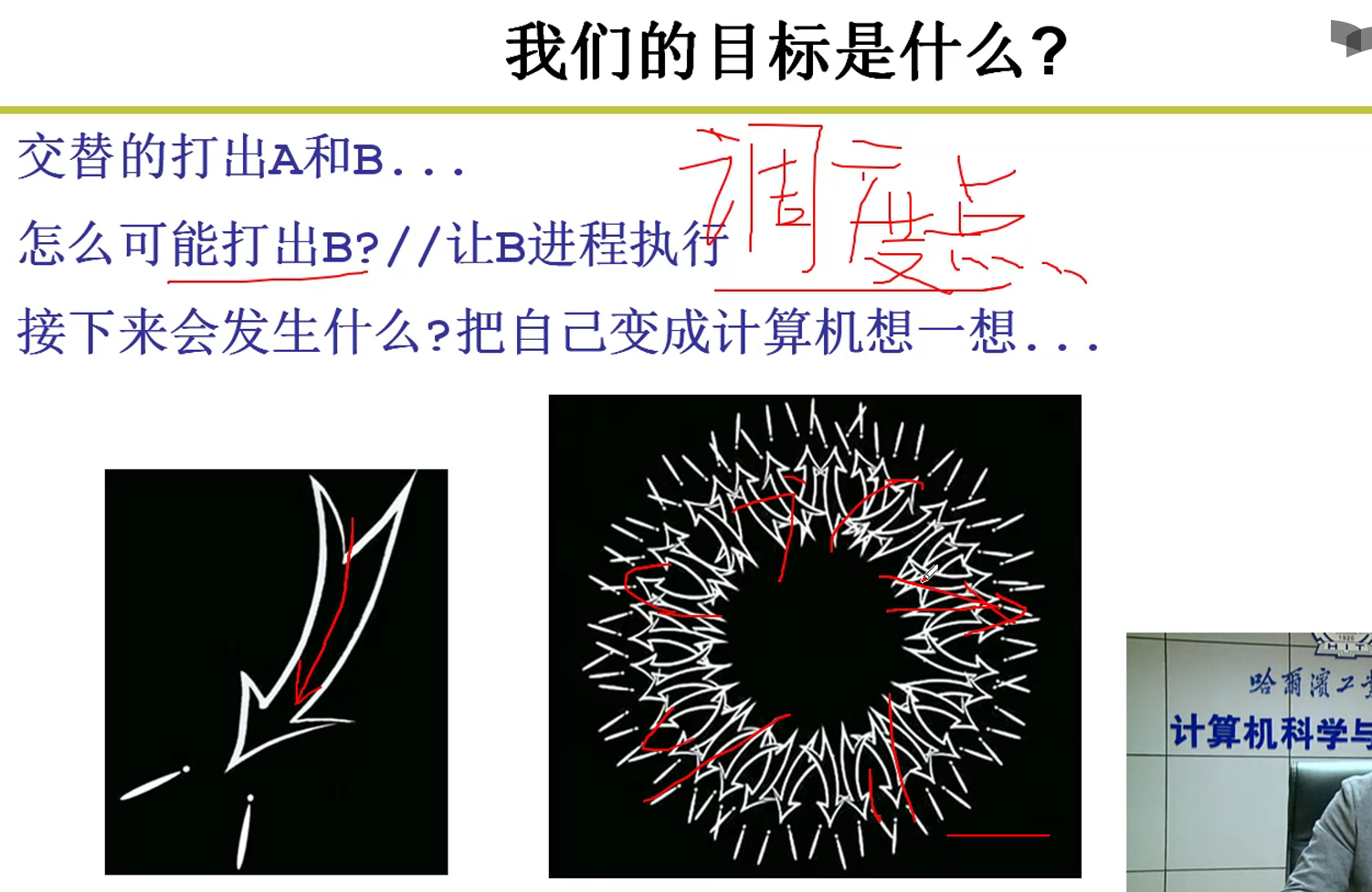
那就要中断才能进入内核,如何调用schedule函数来进入内核呢?才能够切换到B哇!!!
这个中断怎么整??? -> INT 0x80,如何引发这个中断呢? -> 时钟中断!!!

- 接下来?

- 是不是还要中断才能打A哇???

CPU调度策略:
- 基本方法:
- FIFO
- Priority
- 算法应该让什么更好?
- 面对客户:用户满意
- 面对进程:进程满意
- 怎么让进程满意?
- 尽快结束任务
- 操作尽快响应
- 系统内耗时间少:吞吐量
- 总原则:专注于任务执行,合理分配任务

比如下面两个,I/O的优先级就会比CPU要高嗷!!!I/O尽早调度运行,使用一段时间后启动I/O。这个时候,I/O和CPU就可以充分并行,充分利用各种资源嗷!!!
折中和综合让操作系统复杂,但是有效的系统又要求尽量的简单orz。。。。。
- 常见CPU调度算法:
- FCFS
- SJF(引入优先级)
- RR(引入时间片)
- 优先级 -> 动态优先级
一个实际的schedule函数:
- 实际的schedule函数是怎么做的?

基于counter的优先级和时间片嗷!!!
- counter如何修改:
- 就绪态进程的counter都用完了
- 下面这个就是counter的处理,处于阻塞状态的进程回来之后,优先级一定要高一些嗷!!!
- counter是个多面派:

当counter(时间片)的值减少到了0,就自动引发schedule函数嗷!!!

I/O就是前台进程的特征,优先级也比只用CPU的线程的优先级要高嗷!!!

进程同步和信号量:
- 信号 —> 信号量(生产者消费者进程的合作嗷!!!)
- 信号能够表达的信息太少了,因此引入了信号量来记录整体的信息嗷!!!
- 例如只有唤醒信号,那我是唤醒呢?还是别的咋整呢???

- 信号量如何工作?

信号量成功记录了系统中的资源数,在信号量的基础上,信号得以正常的发送和沟通,信号量yyds!!!
- 习题:

- 信号量定义:

1 | |
- 解决生产者-消费者问题(你电特色):

什么时候会停下来?特别有意思
mutex为互斥信号量,一次只能有一个人进去。
empty为缓冲区信号量,用于记录系统资源。
在兔兔看来,信号量就是用于表示系统中争抢占用的共享资源的。特殊用法就是作为mutex(只能有一个人进去对于资源进行修改嗷!!!),控制进程间的顺序。
信号量临界区保护:
- 不好保护出现的问题:

并不是变成造成的错误,而是多个进程并发操作共享数据引起。
错误和调度顺序有关,难于发现和调试
- 直观想法:
- 改之前上锁哇!!!(类似于数据的操作)
- 一段代码一次只允许一个进程进入嗷!!!
- 临界区:
- 一次只允许一个进程进入的该进程的那一段代码
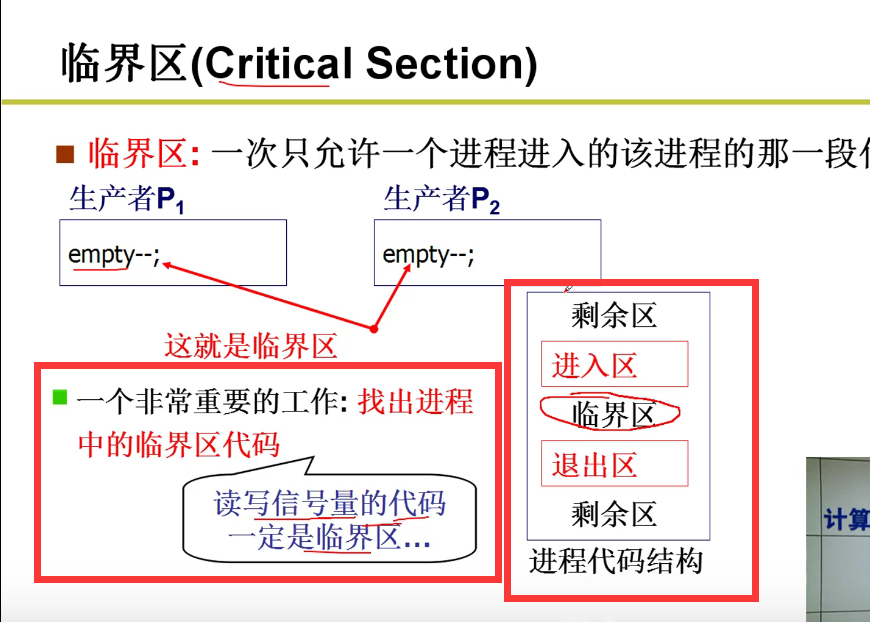
- 进入区和退出区才是核心代码嗷!!!怎么写这些代码是个大问题!!!

- 轮换法:
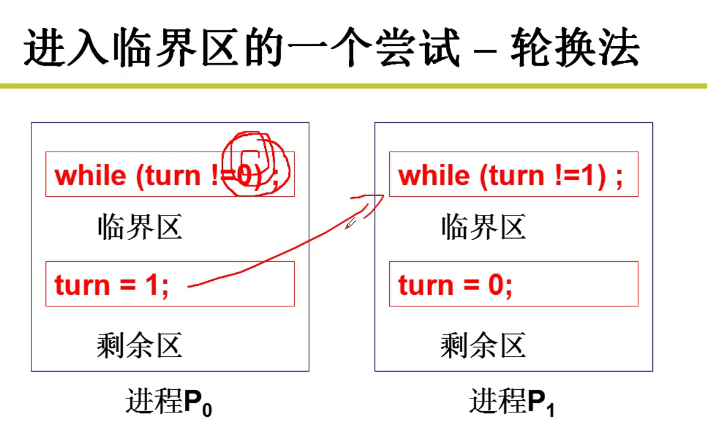
可以实现,但是不满足空闲让进和有限等待的原则嗷!!!
- 标记法:

但是这个可能有问题,互斥可能会出问题嗷!!!
- 非对称标记:

- Peterson算法:
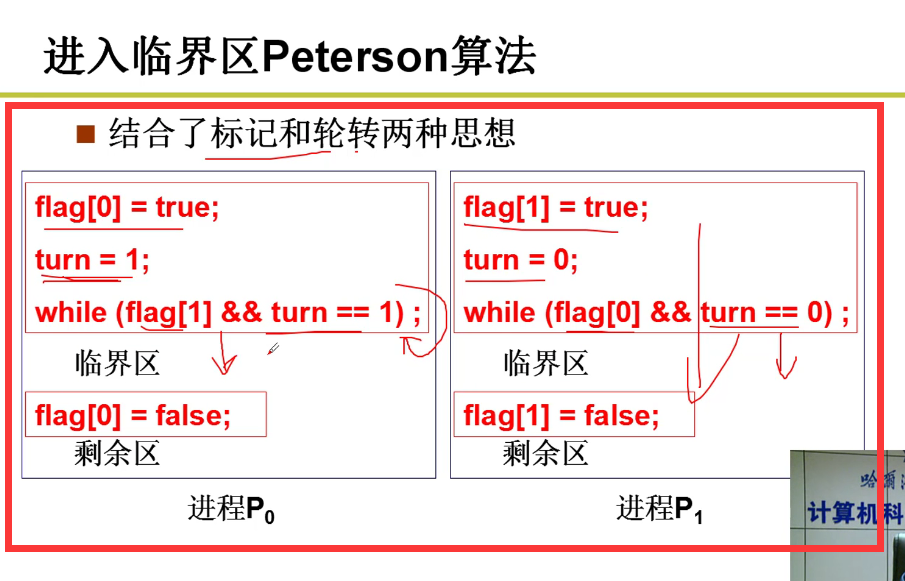
满足互斥条件(可以通过反证法来证明,特别好用!!!)

三个条件都满足嗷,特别有意思嗷!!!
- 多个进程咋办捏?
仍然可以标记+轮转进行结合来解决这个问题嗷!!!

就有点像排队取号考驾照,里面的人出来了,你手上有号,并且考场是空的,你才能进去考试嗷!!!
- 太复杂了,有没有简单的方法?硬件yyds,硬件和软件相互合作,协同设计,能够更加有效哦!
从硬件角度来看,软件通过schedule,调用中断,才能够实现线程或者进程的切换。老子直接从硬件上不让你中断,你能咋地???因此先从硬件上把中断关了,让程序正常执行,执行完成之后再开中断,这就是硬件的做法嗷!!!

单个CPU是这样,但是如果是多CPU的,a在A的CPU上,b在B的CPU上。A关中断了,但是管不到B,那还是gg,会造成中断。多核情况下会不好使哦!!!
- 硬件的原子指令:
锁就是一个信号量嗷!!!!(信号量的保护套娃了orz)
硬件能不能内部就直接完成信号量的保护呢?
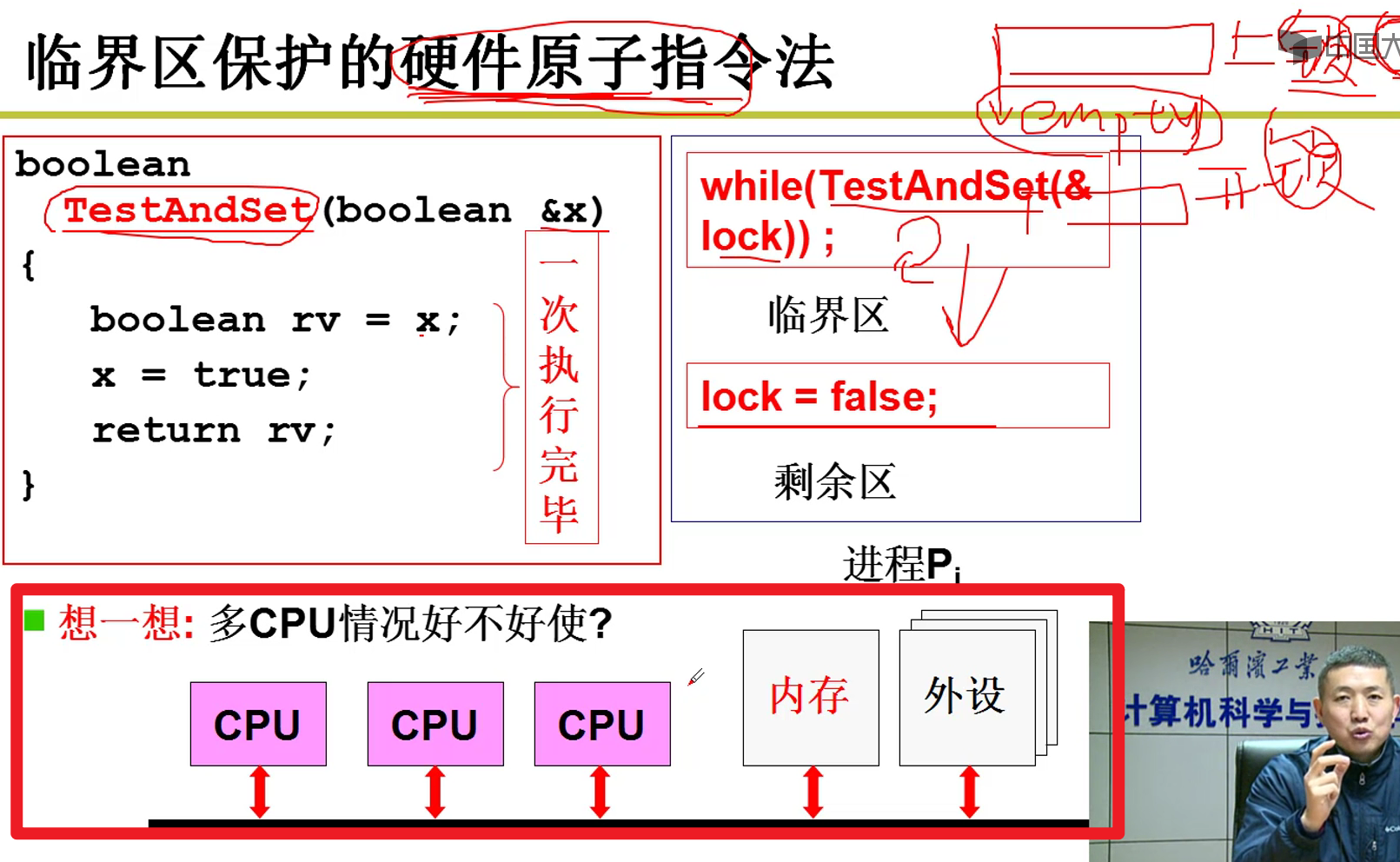
多CPU可以吗???
个人思考:可以,上面的关中断那种方式是针对于CPU来说的。但是多个CPU可以修改同一个存储单元地址,导致了问题的发生。这里原子指令,无论是哪一个CPU去执行这条指令,只有一个原子指令可以执行成功。确实,不可以被打断,但是没有说不可以等待呀!!!

说白了就是硬件这部分处理的地方不一样,一个是单独的CPU上,会有冲突,还有一个是作用在总线上,抢夺资源,因此可以实现多CPU的原子性操作的功能嗷!!!
- summary:
用临界区去保护信号量,用信号量来实现同步
信号量的代码实现:
- sem_open和sem_wait:

- lock_buffer:

- 世界上最隐蔽的队列嗷!!!
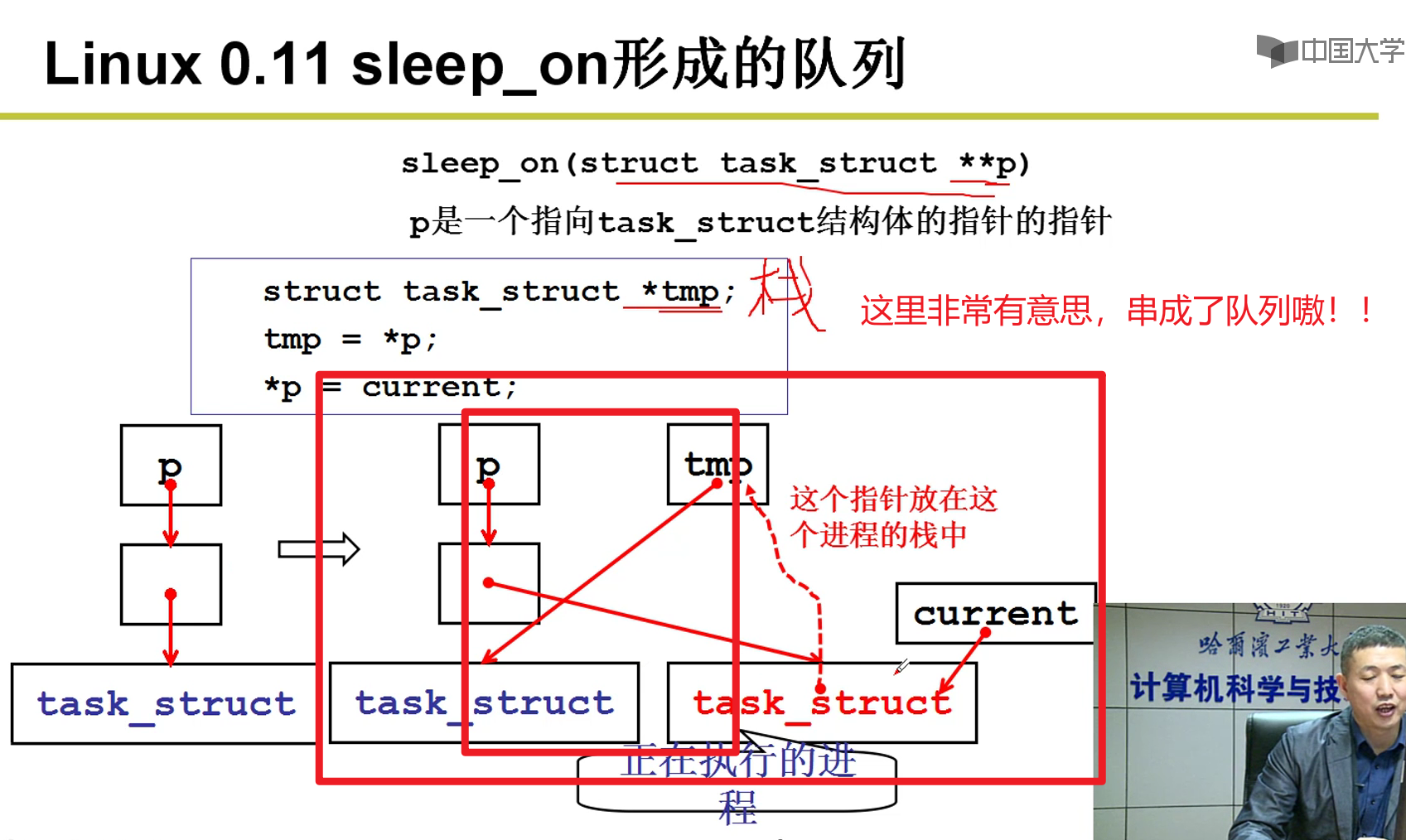
- 唤醒这个队列中的东西
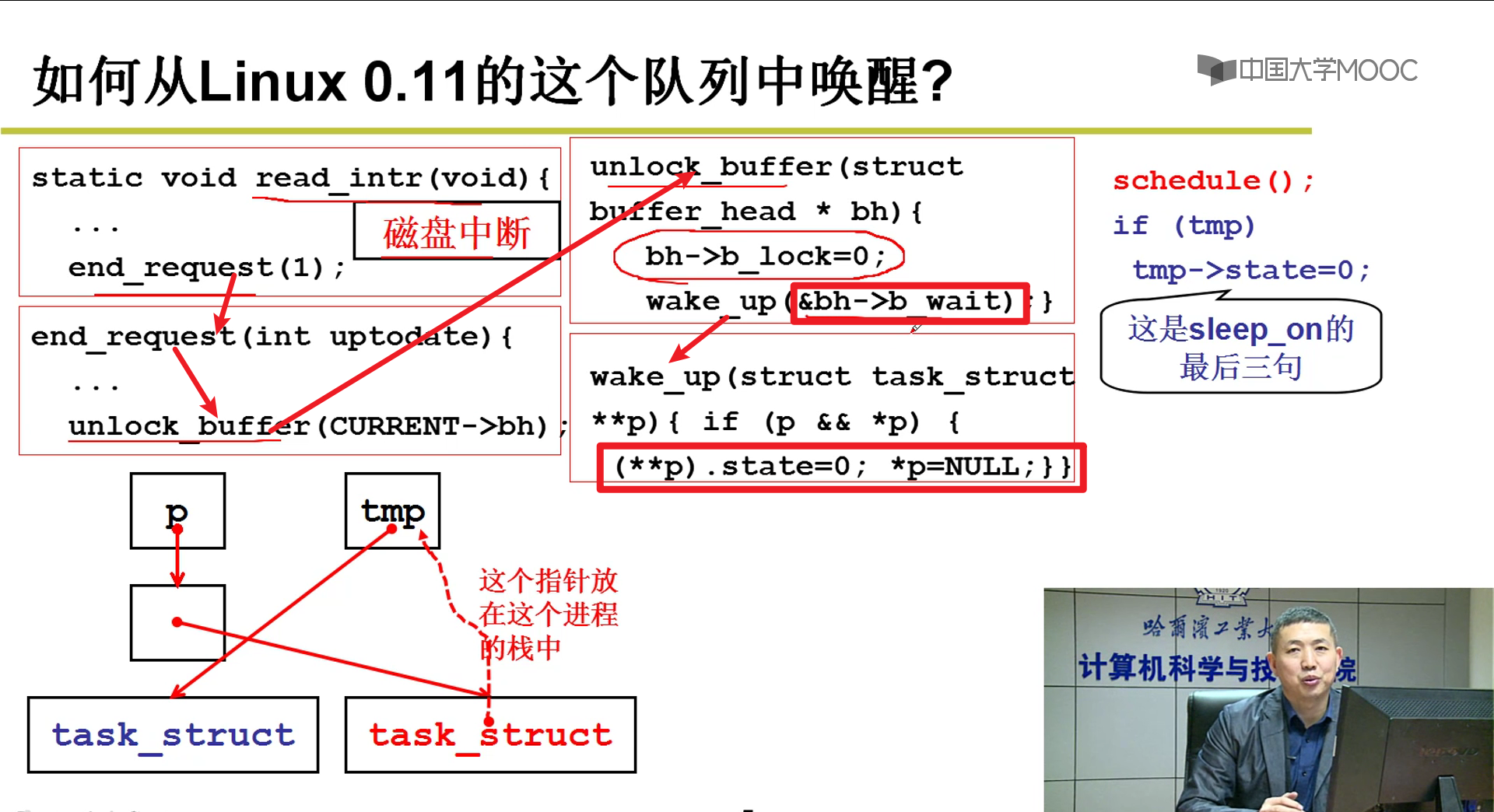
和上面就是对应的,将进程的状态改为就绪态(0),就可以了嗷!
- 唤醒之后会从刚刚停下的地方往后执行,也就是刚刚上面schedule()方法之后往后执行:

通过这种队列不断套娃往前唤醒的机制,实质上把队列中的每一个元素全部都唤醒了嗷!!!
这又解释了,上面为啥是while嗷!!!
- 为啥while?

所有进程全部唤醒,然后由schedule()来决定谁来执行嗷(优先级高的进程先执行),其他的进程再次判断资源(while),再次进行阻塞哦!!!
所有进程唤醒之后先抢一下资源,再去睡眠,这是一个循环往复的过程。因此这里使用的是while而不是if嗷!!!
特点:信号量不需要有负数,因为不需要记录有多少个进程在等待,我有个队列嘛,反正每次全部唤醒。队列中没人自然就不用唤醒了呀!!!while这个东西就弥补了没有记录数量的缺陷嗷!!!
死锁处理:

原因:
- 互斥使用
- 不可抢占
- 请求和保持
- 环路等待
死锁处理:
- 死锁预防:
- 破坏死锁出现的条件
- 死锁避免:
- 检测某个资源请求,造成死锁就拒绝
- 死锁检测+恢复:
- “灭火”,发现死锁就检查并且处理
- 死锁忽略:
- 不管
- 死锁预防:
预防:
- 一次性申请所有需要的资源
- 资源必须按照资源顺序进行
总会有浪费,不推荐使用嗷!!!
避免:
- 银行家算法
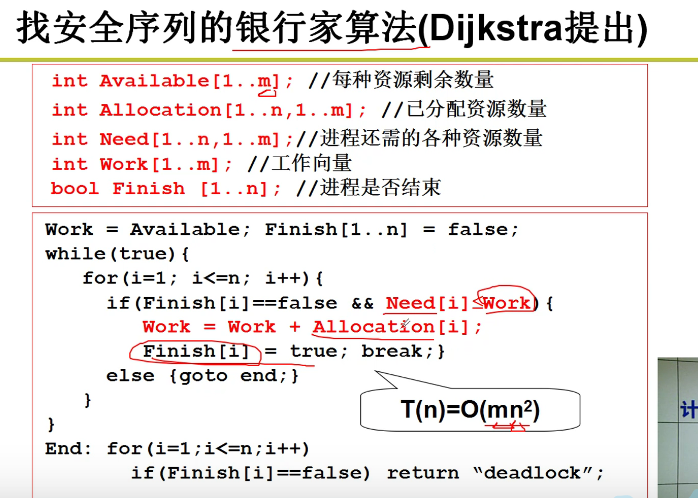
效率太低了orz,可以考虑采用先发现问题再处理的方式进行处理嗷!!!
- 定时检测或者是发现资源利用率低的时候检测嗷!

死锁检测+恢复:
- 例如上面这个,一段时间利用银行家算法进行一次检测或当CPU利用率低的时候进行检测,来减少消耗嗷!!!
死锁忽略:

死锁忽略代价小,对于Windows和Linux来说,重启就解决了,很方便。而且编程也很困难,因此这种方式的适用性还是非常好的嗷!!!!
实际的开发过程中使用这种偏多嗷!!!
第四章(内存管理):
内存使用和分段:
- 如何让内存用起来:
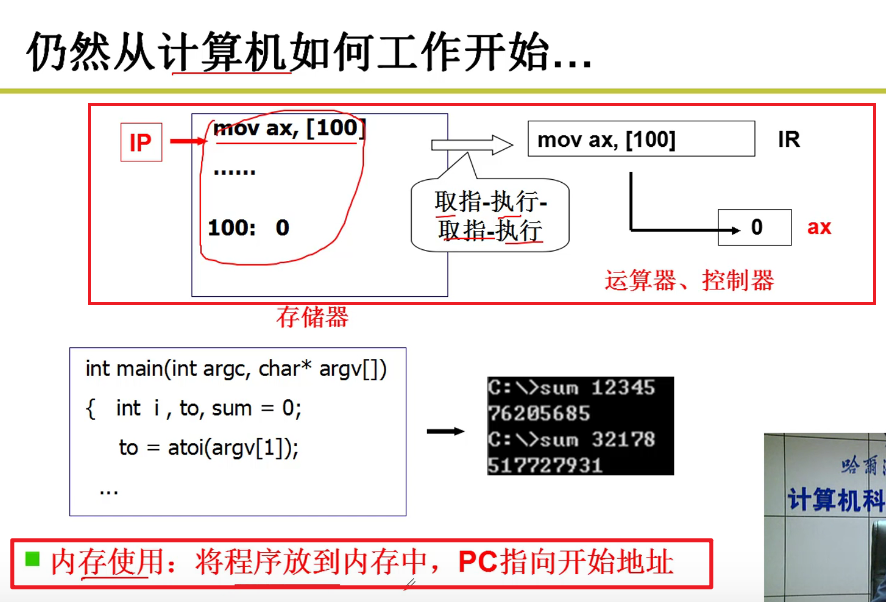
将程序放入内存中跑起来,内存就用起来了嘛!!!
- 相对地址需要转换:
注意哈:指令call 40本质上是直接往地址总线上发40,访问40地址的这个东西,是行不通的嗷!!!(把40赋值给IP了嗷!!!)
不能仅仅把程序搬过来!!!
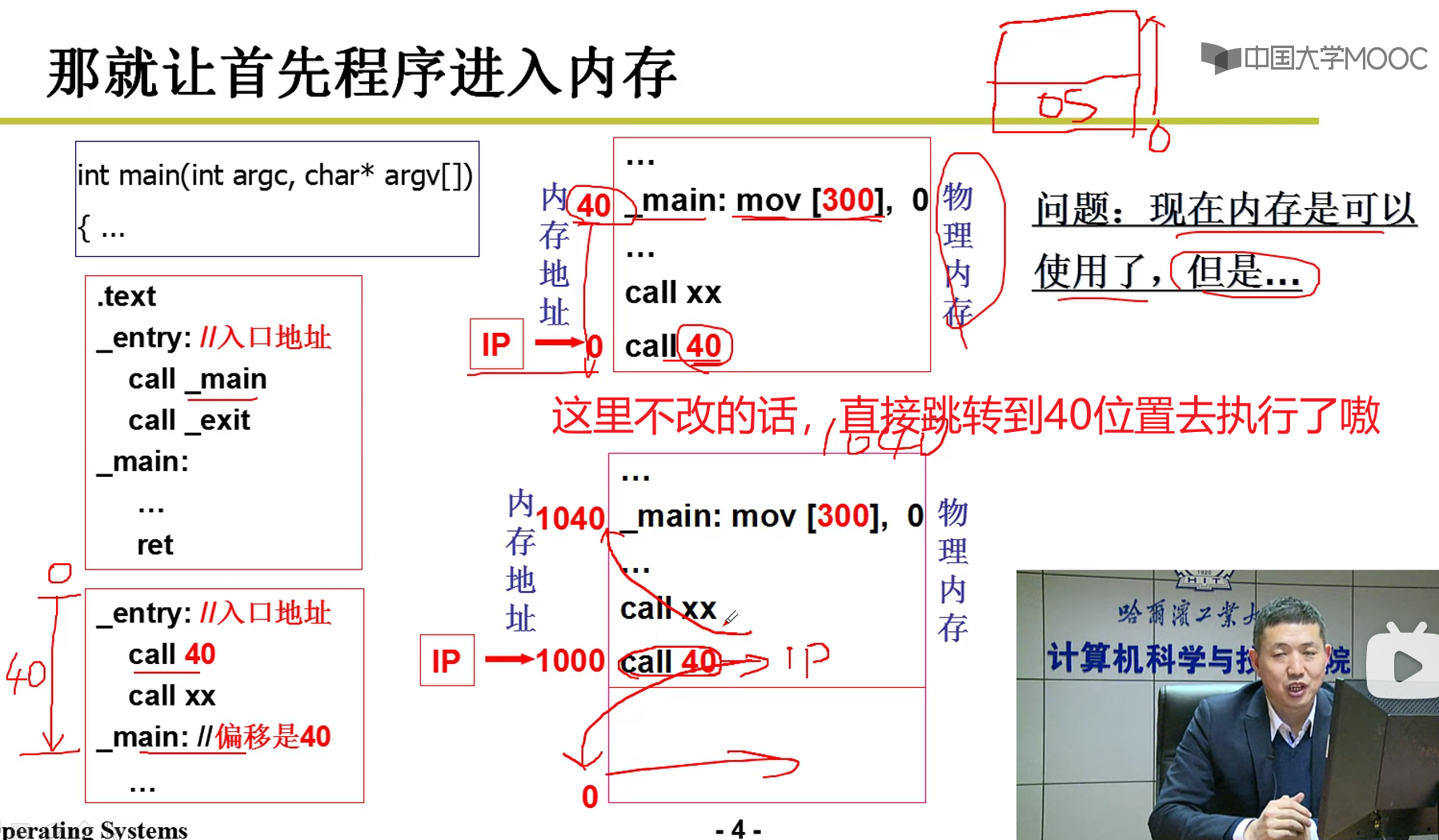
如果这样的话,就算搬到1000位置,还是废的,执行call之后还是跳转到40,这个地址空间去执行了嗷!!!
- 逻辑地址(逻辑地址) -> 物理地址:
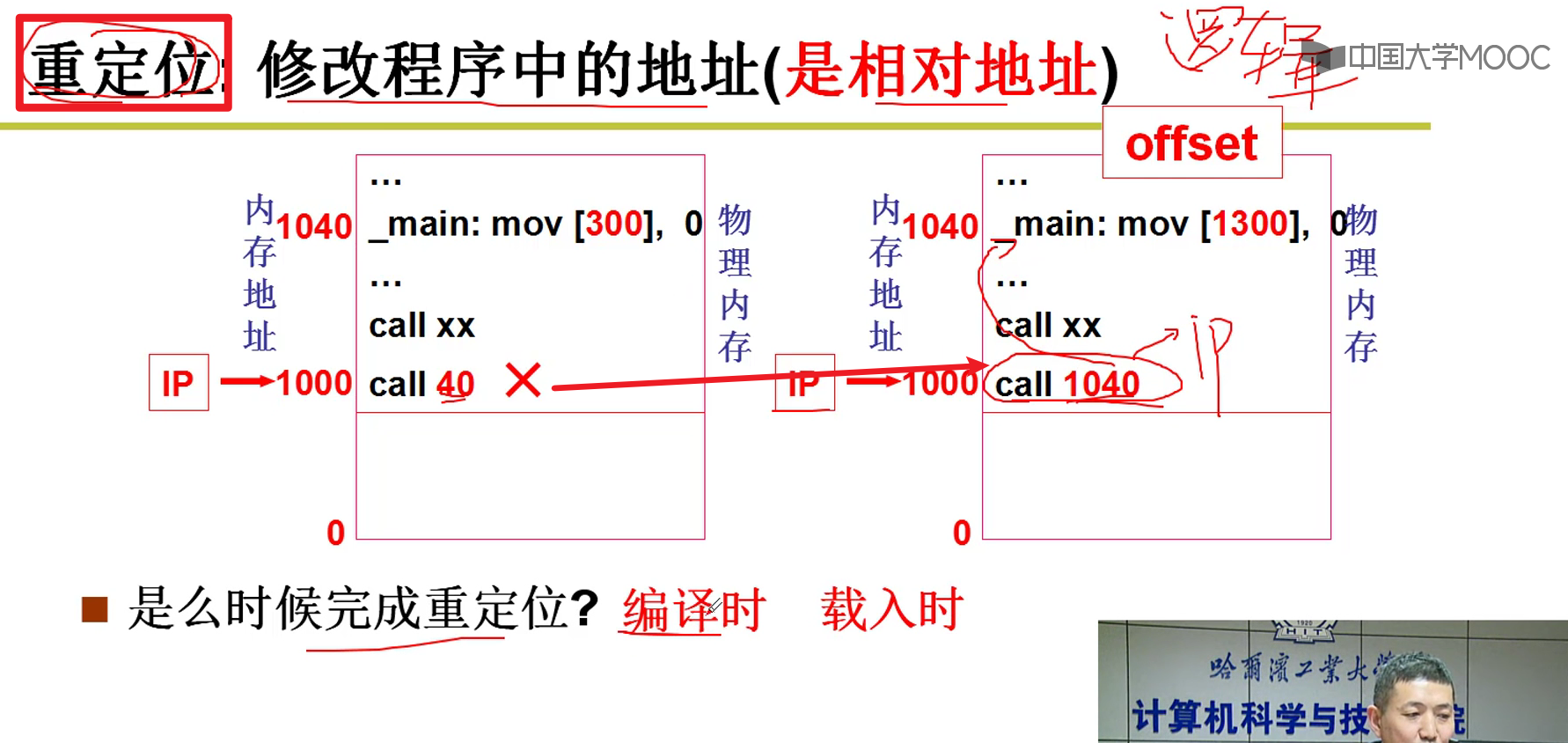
- 什么时候完成重定位:
- 编译时:除非能够确定嗷!!!不然编译的时候一般是不能确定位置的,因为系统是动态的而不是静态的嗷!!!
- 载入时:更加灵活,根据哪一段空闲,再去进行基址的转化哦!!!(虽然会稍微慢一点嗷!!!)

载入的时候还要移动咋办orz:
- 交换的概念:
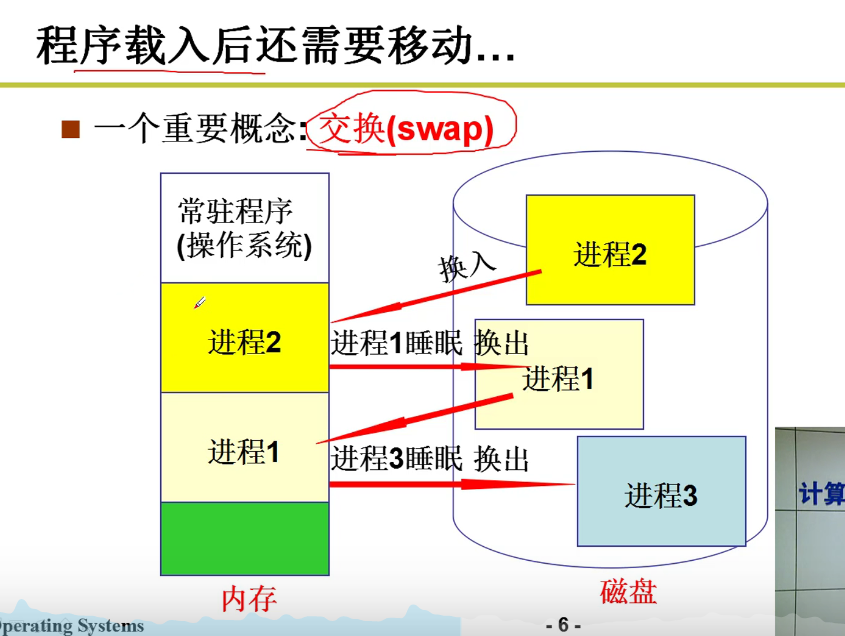
内存宝贵,内外交换
- 运行时重定位!!!
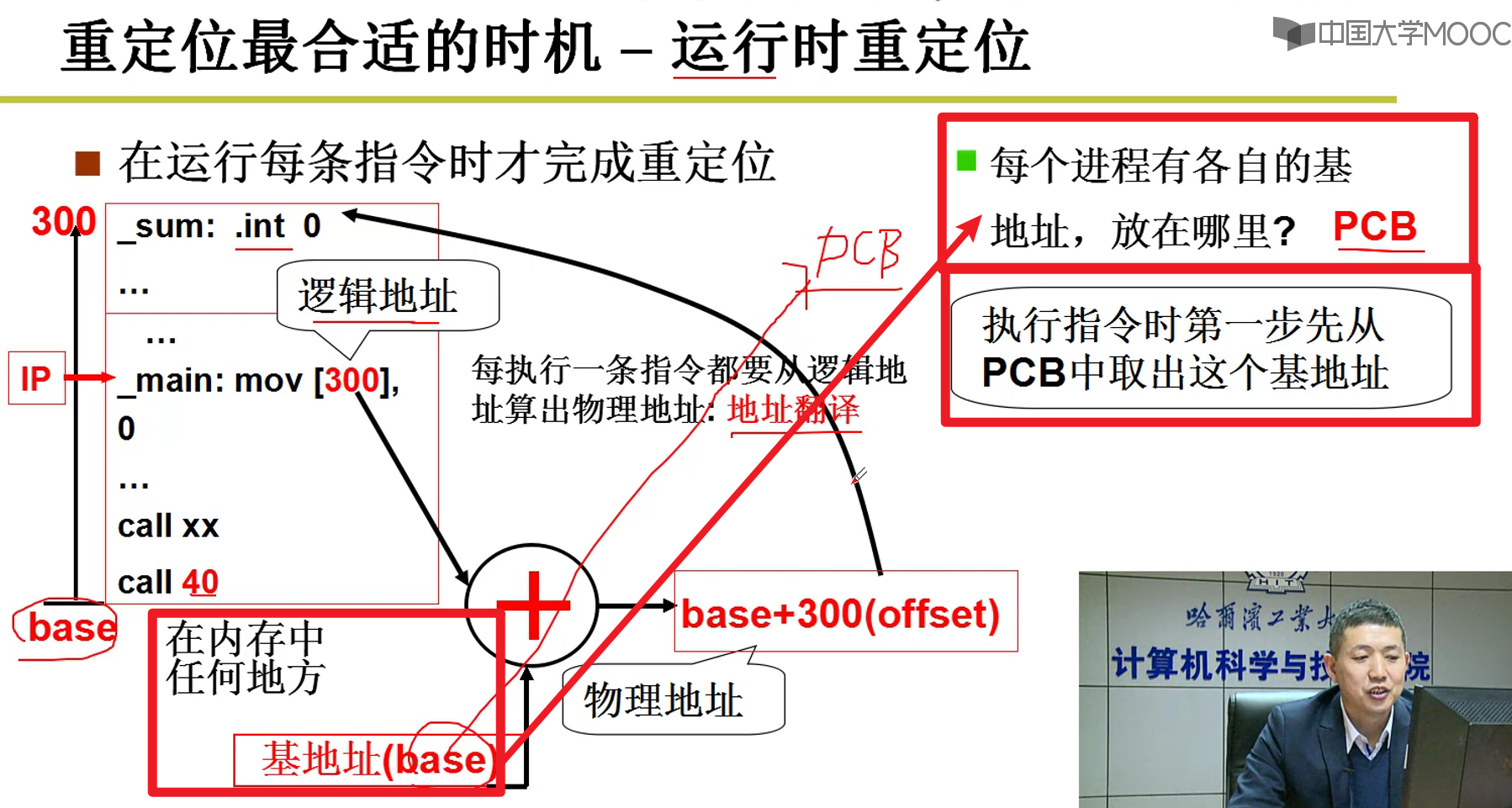
- 这种情况下,编译不用动任何内容,找到内存中的空位,把起始地址赋予PCB,然后就可以把程序放进去,就可以跑了嗷!!!
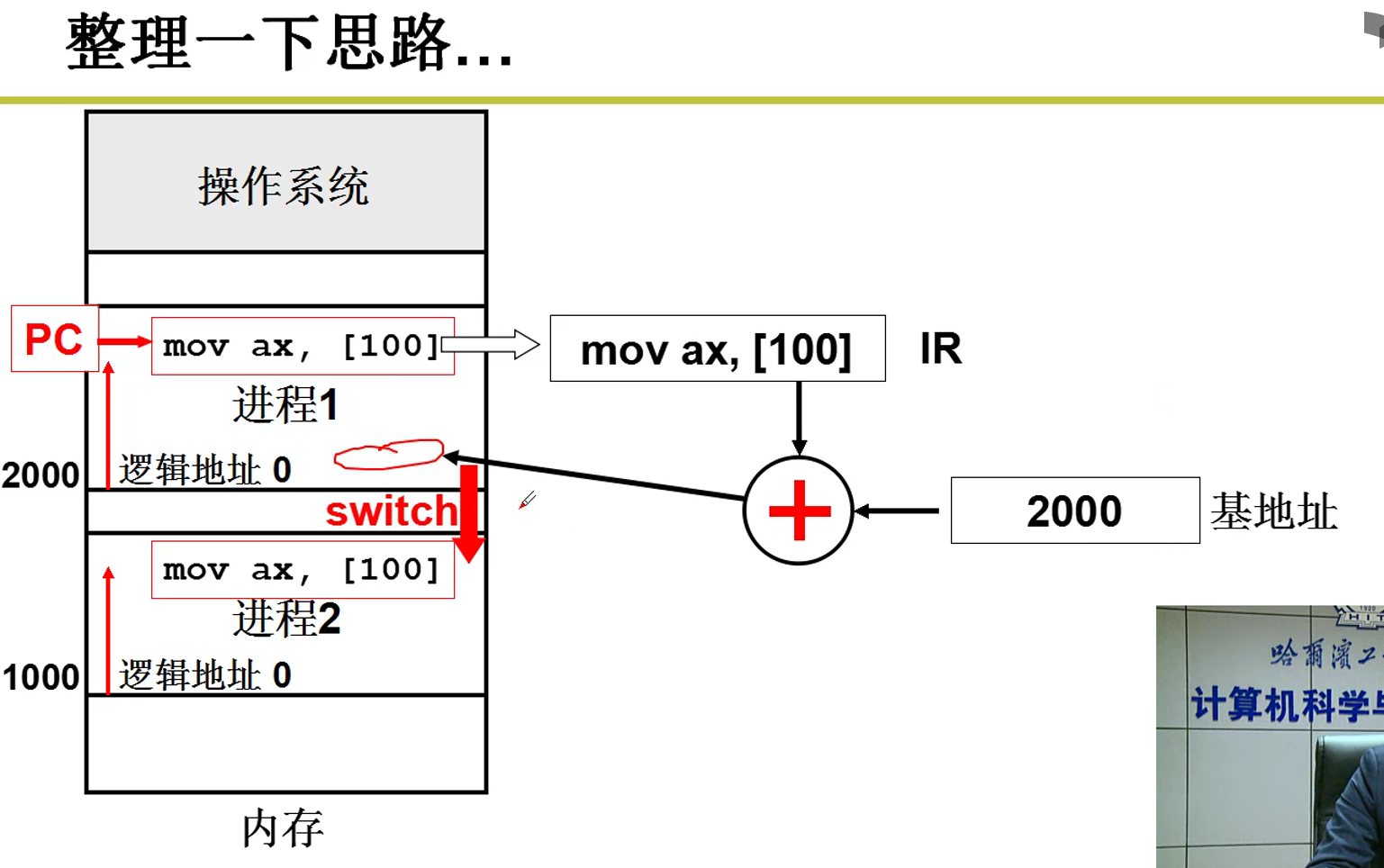
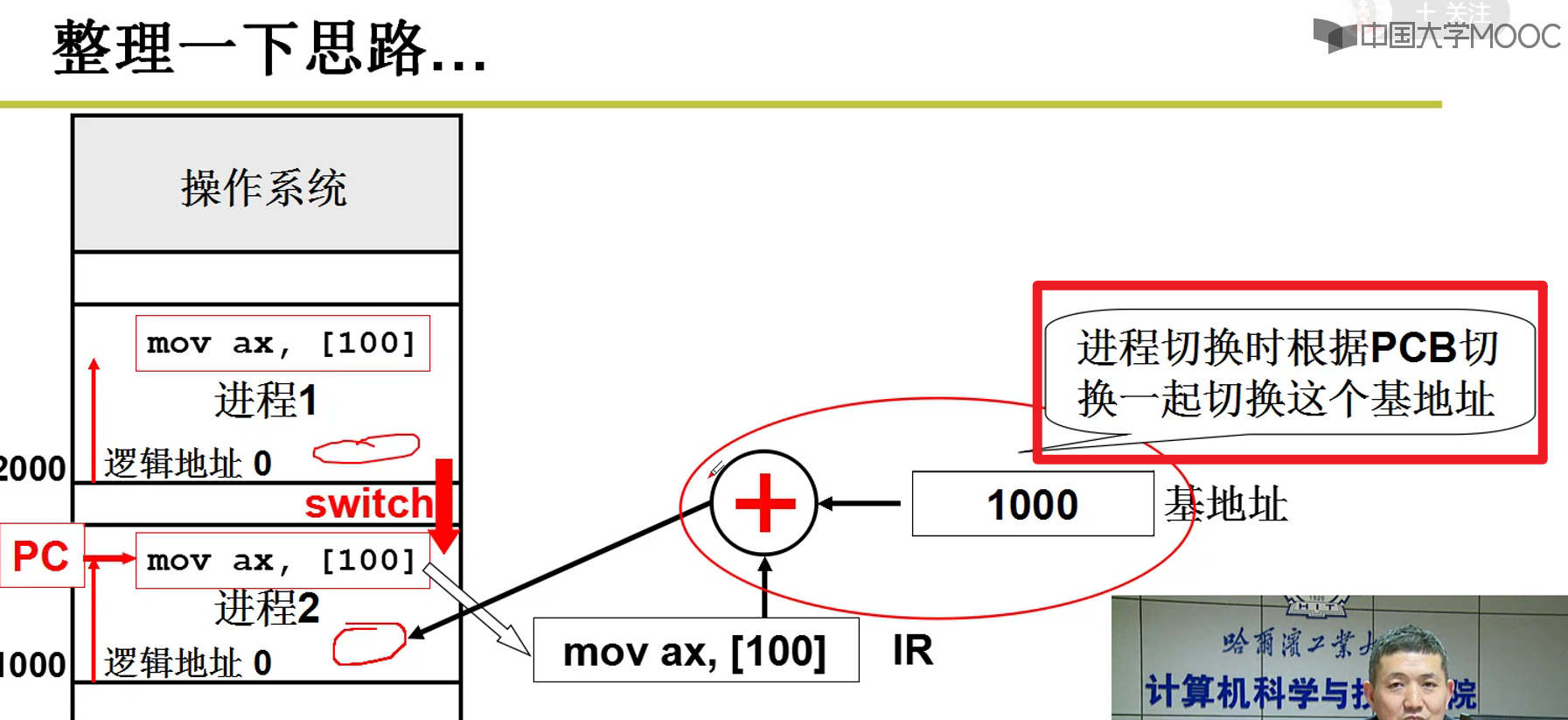
引入分段:
- 是将整个程序一起载入内存中吗?
- 若干部分(段)组成,每个段都有各自的特点,用途

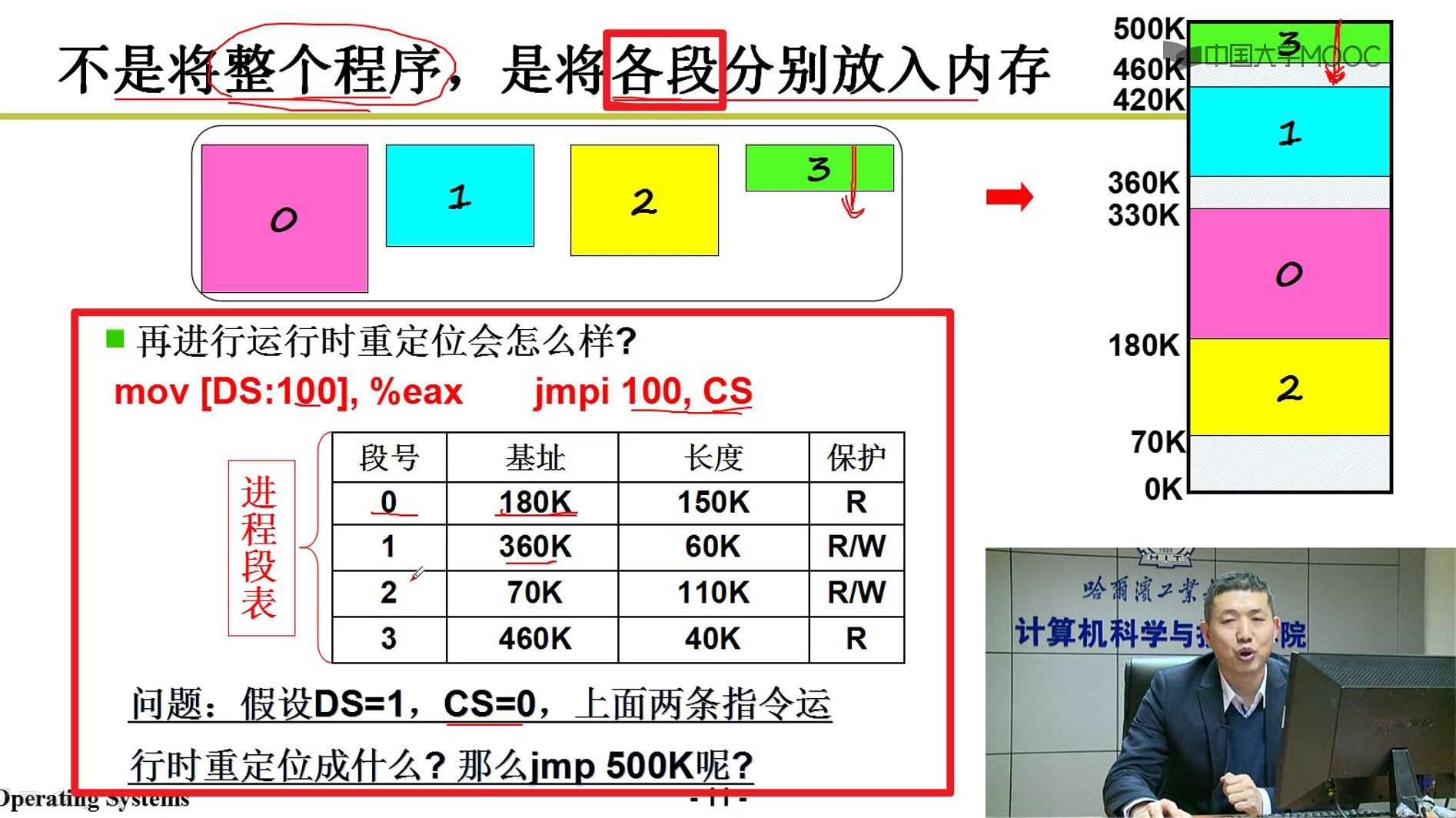
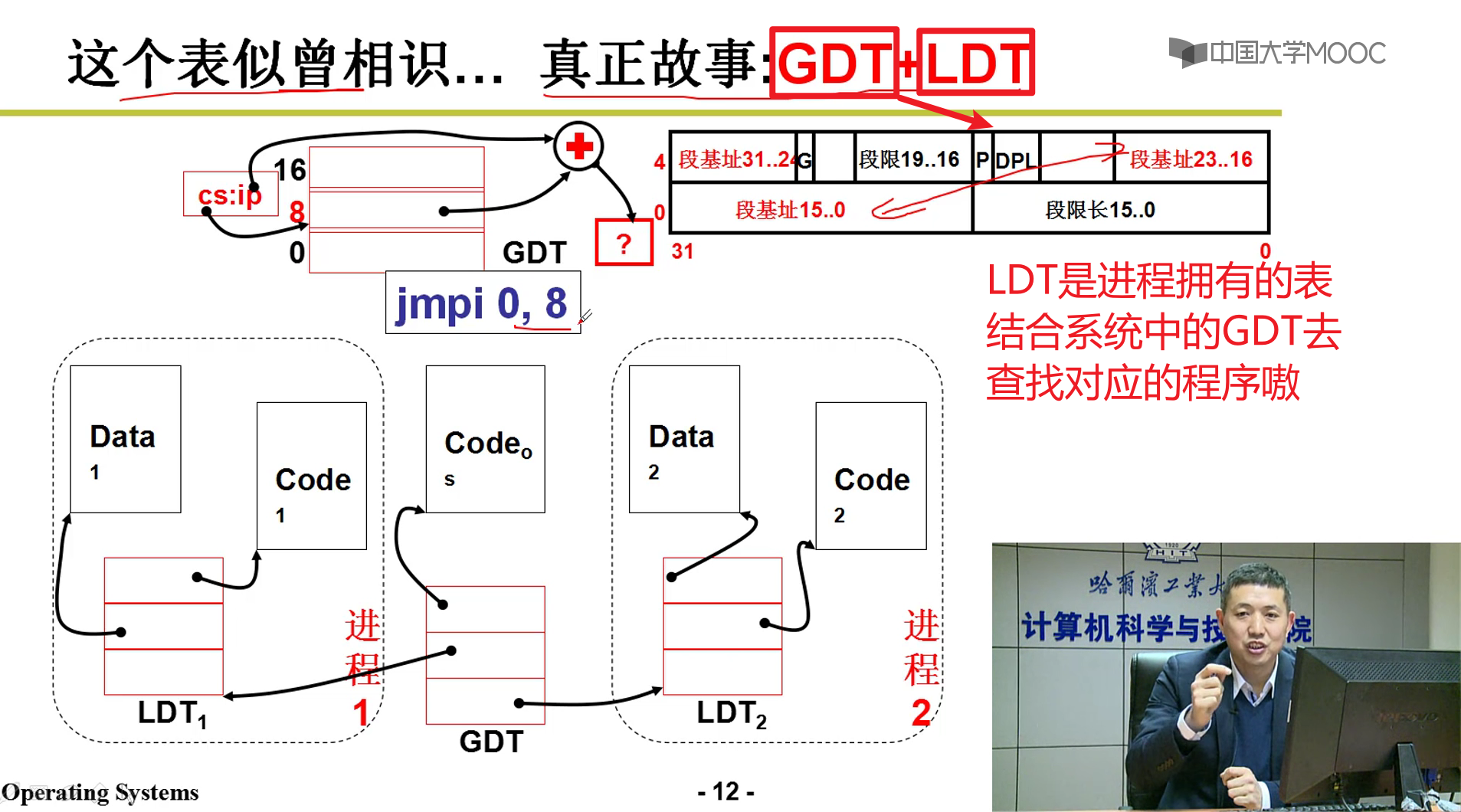
- 每个PCB中都有一个LDT,LDT结合GDT就能够正确重定位到跳转指令的位置嗷!!!
- GDT就是段表寄存器
内存分区与分页:
- 可变分区的管理过程:
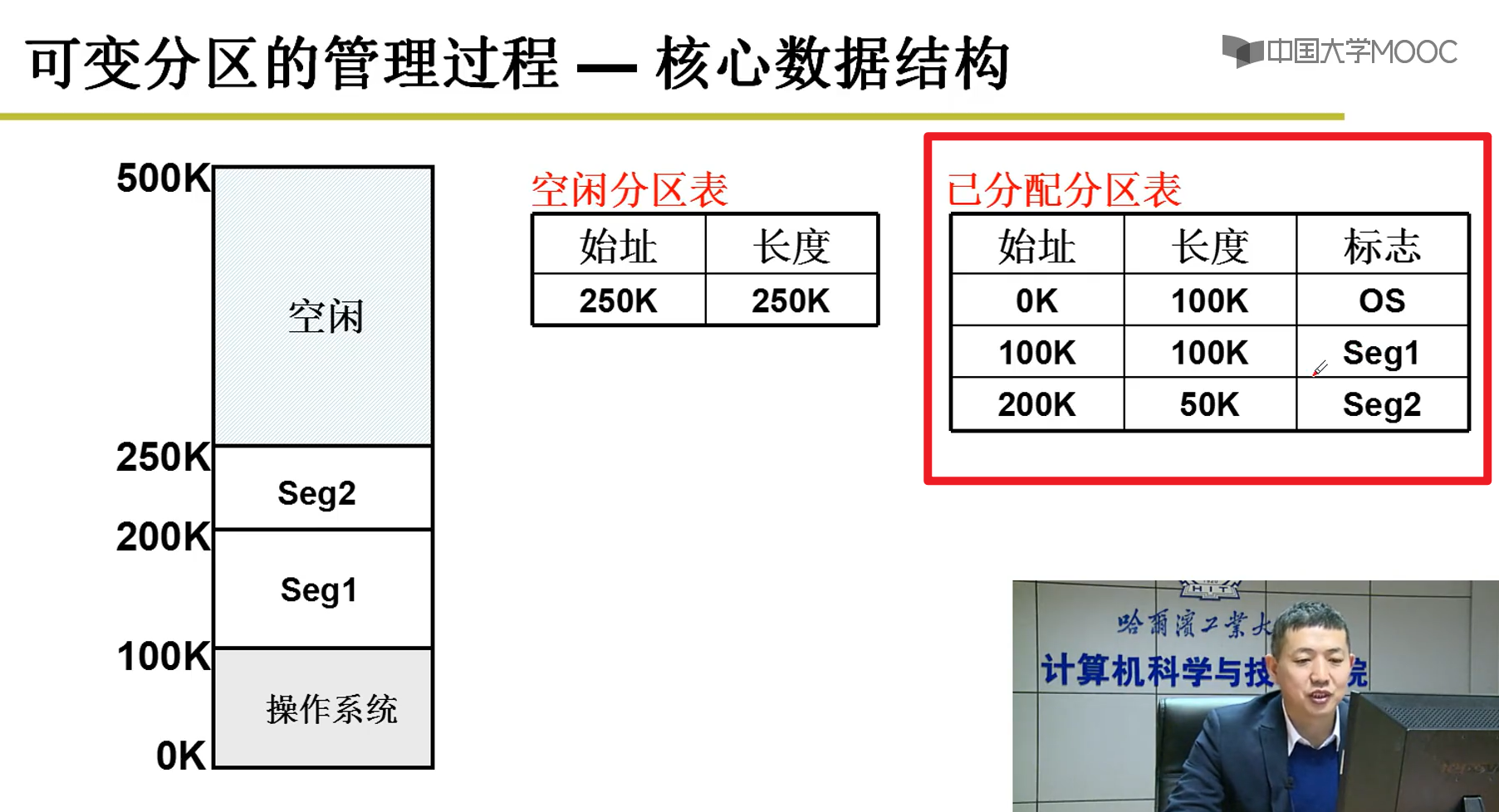
内存可以分配和回收嗷!!!这个东西我比较清楚,就不写了嗷!!!
适配算法:
- 最佳适配
- 最差适配
- 首先适配(快)
分页:
- 一个进程最多浪费4K嗷,如果一页的大小是4K的话
- 好处:不用进行紧缩嗷,物理内存浪费少了嗷!!!
- 用户希望分段,物理内存希望分页,因此出现了段页式嗷!!!
CR3就是页表寄存器
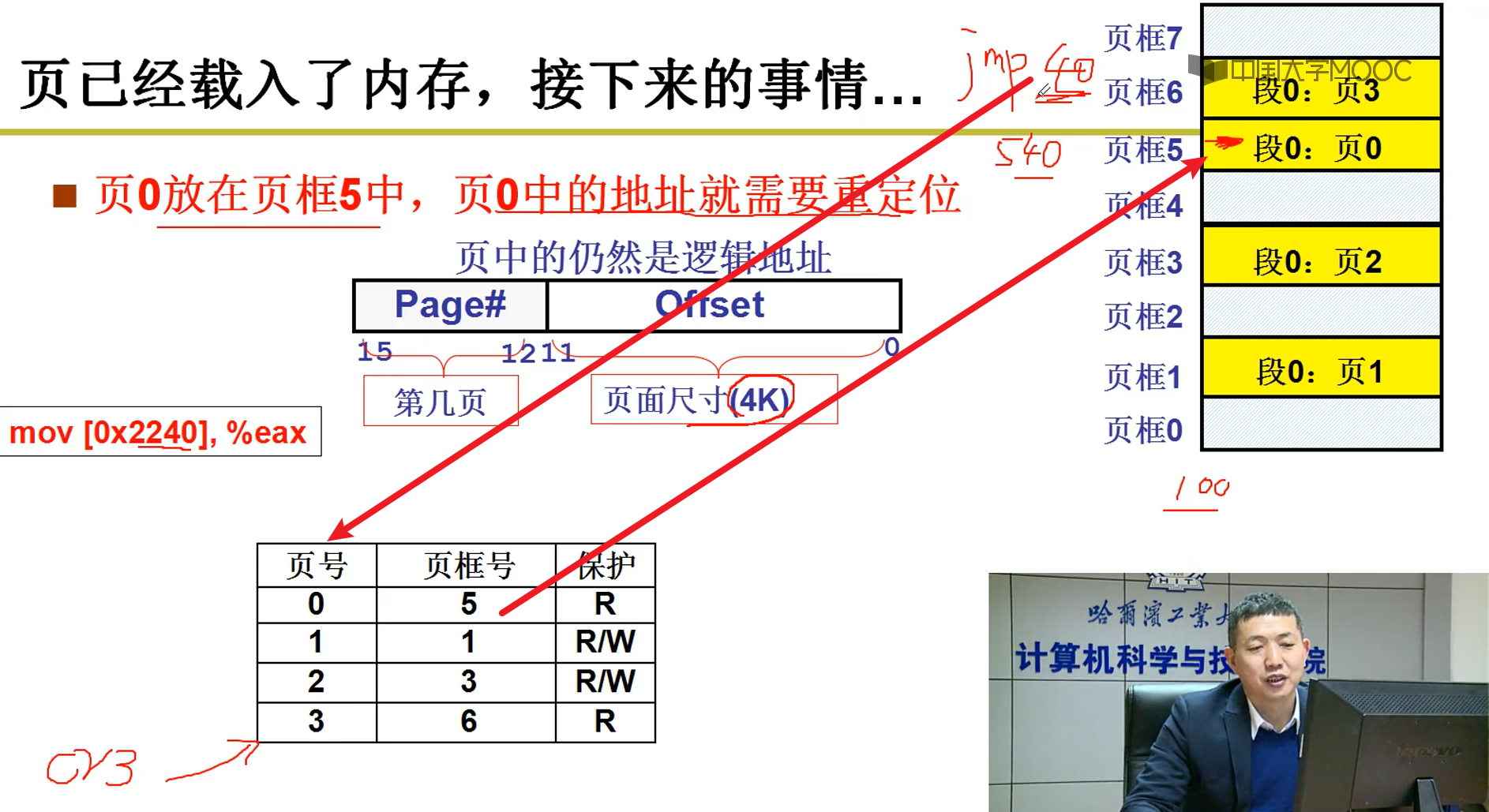
实际上这个操作都是MMU这个硬件做的嗷!!!自动帮助我们完成从偏移地址到对应页的地址转换嗷!!!
MMU自动根据CR3就去计算,实际的物理地址。查页表,重定位,进行计算嗷!!!
多级页表与快表:
- 分页问题:
- 页小了,页表就大了orz,内存高效利用 -> 页小 -> 页表大
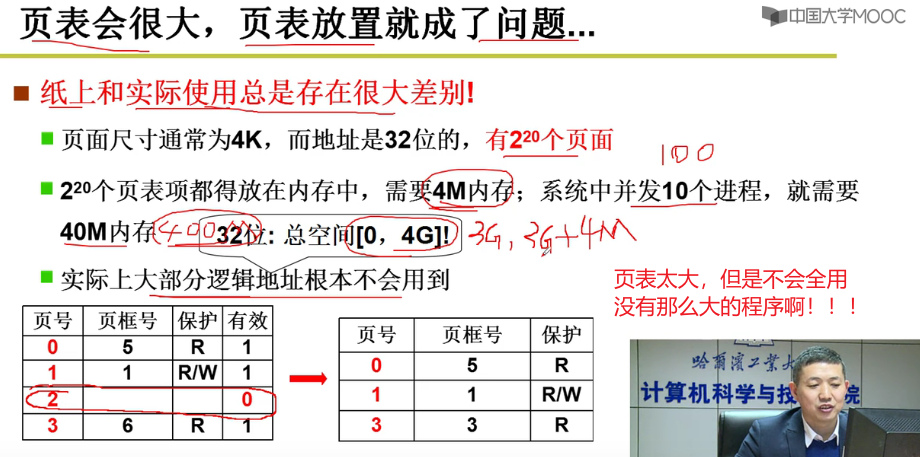
- 尝试:只存放用的页!!!内存中只存用到的页嗷!!!页表目的:根据页号找到物理页框号。
- 页表查找:
页表长,顺序查找某个页号,那很费时间啊orz
怎么解决:折半查找!!!(还是时间长啊orz)
页号连续,查到第一个之后,之后根据每一行的大小进行偏移,可以很快找到嗷!!!
但是问题:页表连续,即使没有用到的,也要占住内存中的位置才能方便我们查找,how?
既要连续又要让页表占用内存少???

多级页表的诞生:
- 书的章目录和节目录来类比嗷!!!
把中间分成大段,然后根据不同的章节,再去
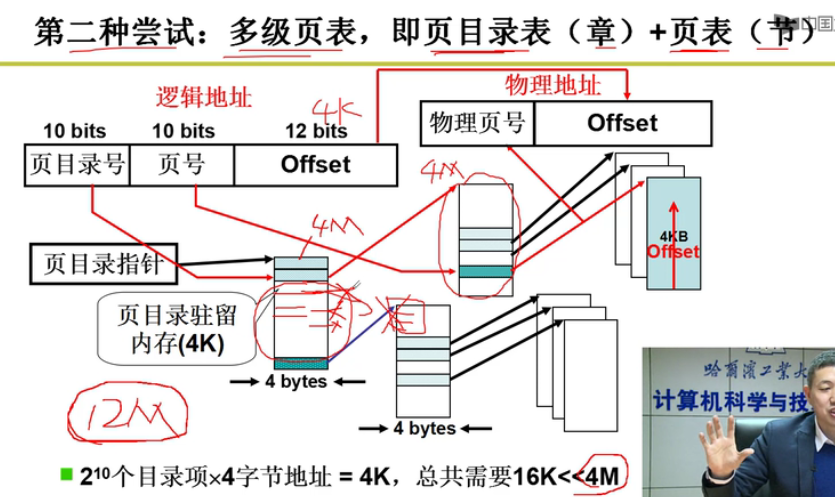
只用看章,不用看其中的很多节,只看我对应要看的节。因此省了很多内存嗷!!!(专门拿了一个4K的页面出来作为目录嗷!!!)
空间上高效,时间上呢?会有损耗!!!会增加一级,就会多访问一次内存嗷!!!时间上就会有所损耗嗷!!!
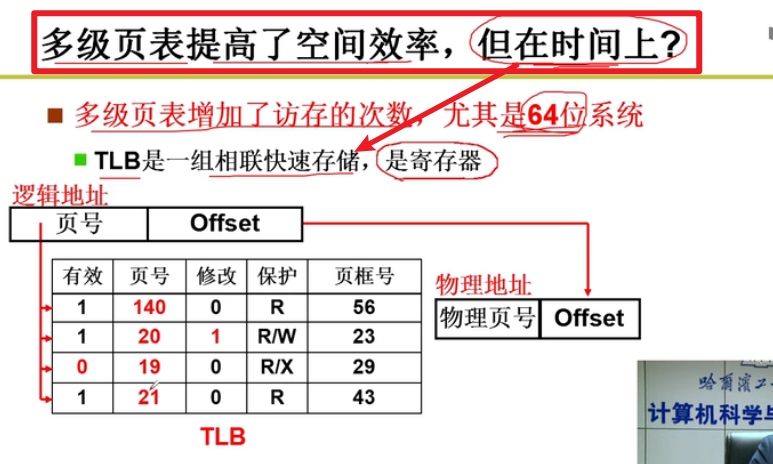
引入了快表这个概念嗷!!!
- 快表:
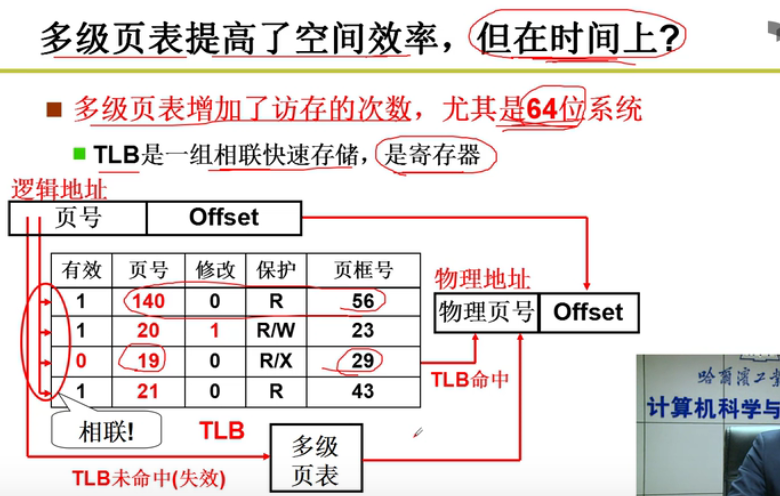
快表+多级页表的结构:既节省了时间,又节省了空间嗷!!!
TCB存在寄存器中嗷!!!速度特别快嗷!!!


正因为程序具有这种局部性,所以这种方式才能够生效嗷!!!
段页结合的实际内存管理:
- 程序员用段 , 物理内存(硬件)需要用页 , 因此产生了段页结合的方法嗷!!!
- 段隔开了地址空间,再映射到实际的物理页上!!!
段 -> 虚拟内存 -> 物理页
- 段页同时存在:
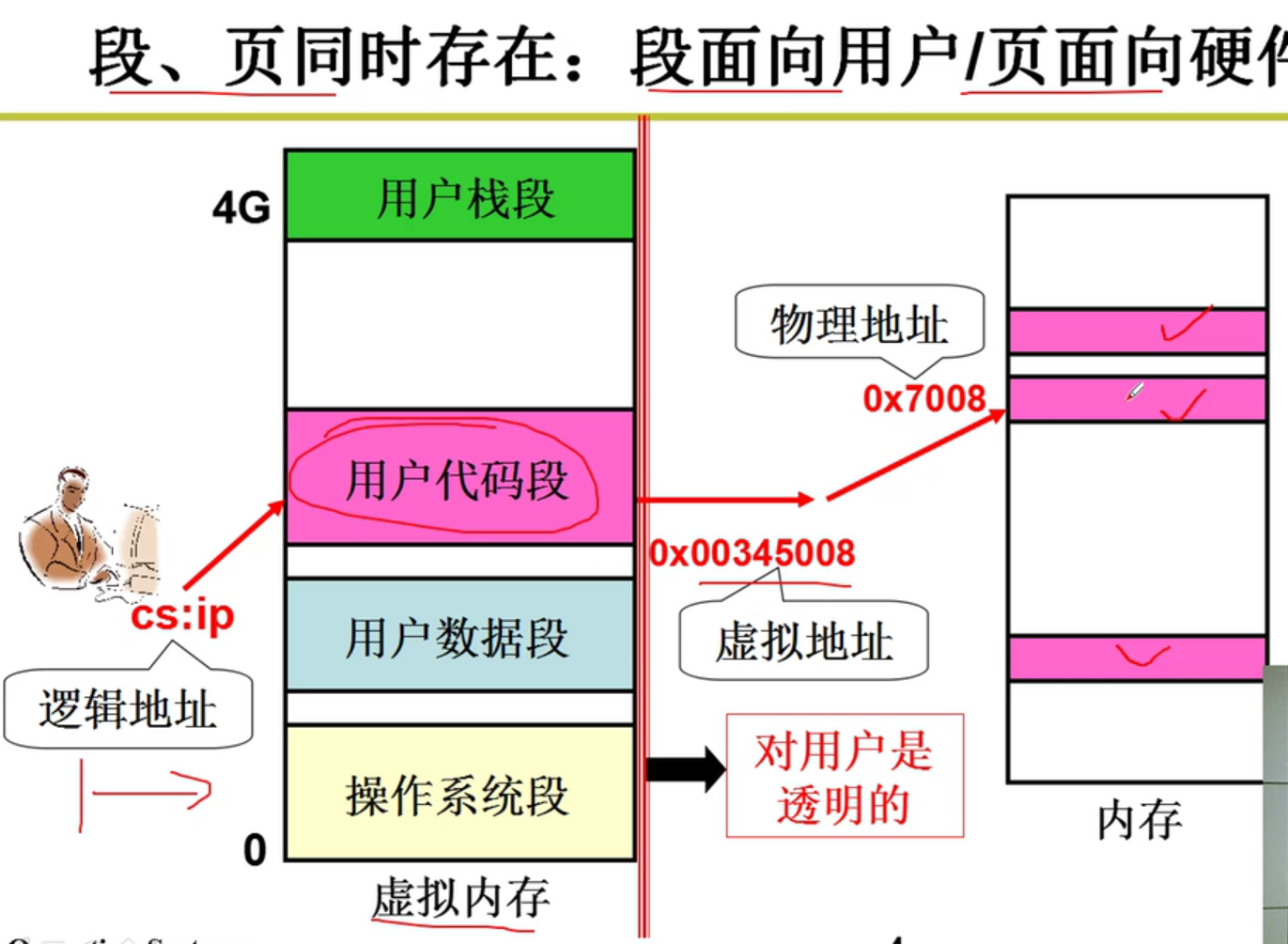
虚拟地址:
- 这个概念是在段和页揉在一起的情况下引出的,隐藏了物理地址上页的分配,从而为用户提供段的服务嗷!!!
- 透明的那一层映射,干了什么?
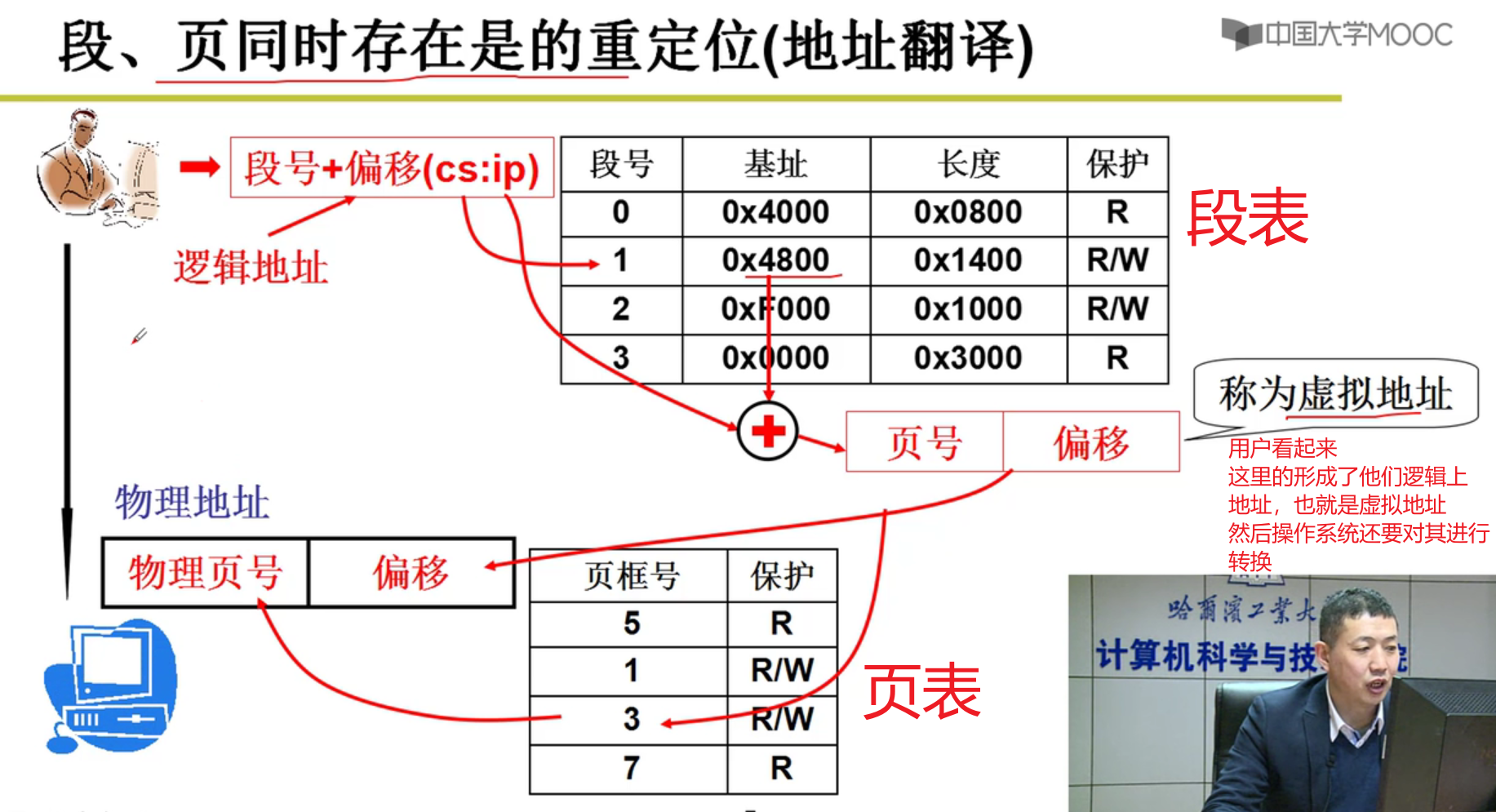
- 内存管理的核心就是内存分配,所以将程序放入内存
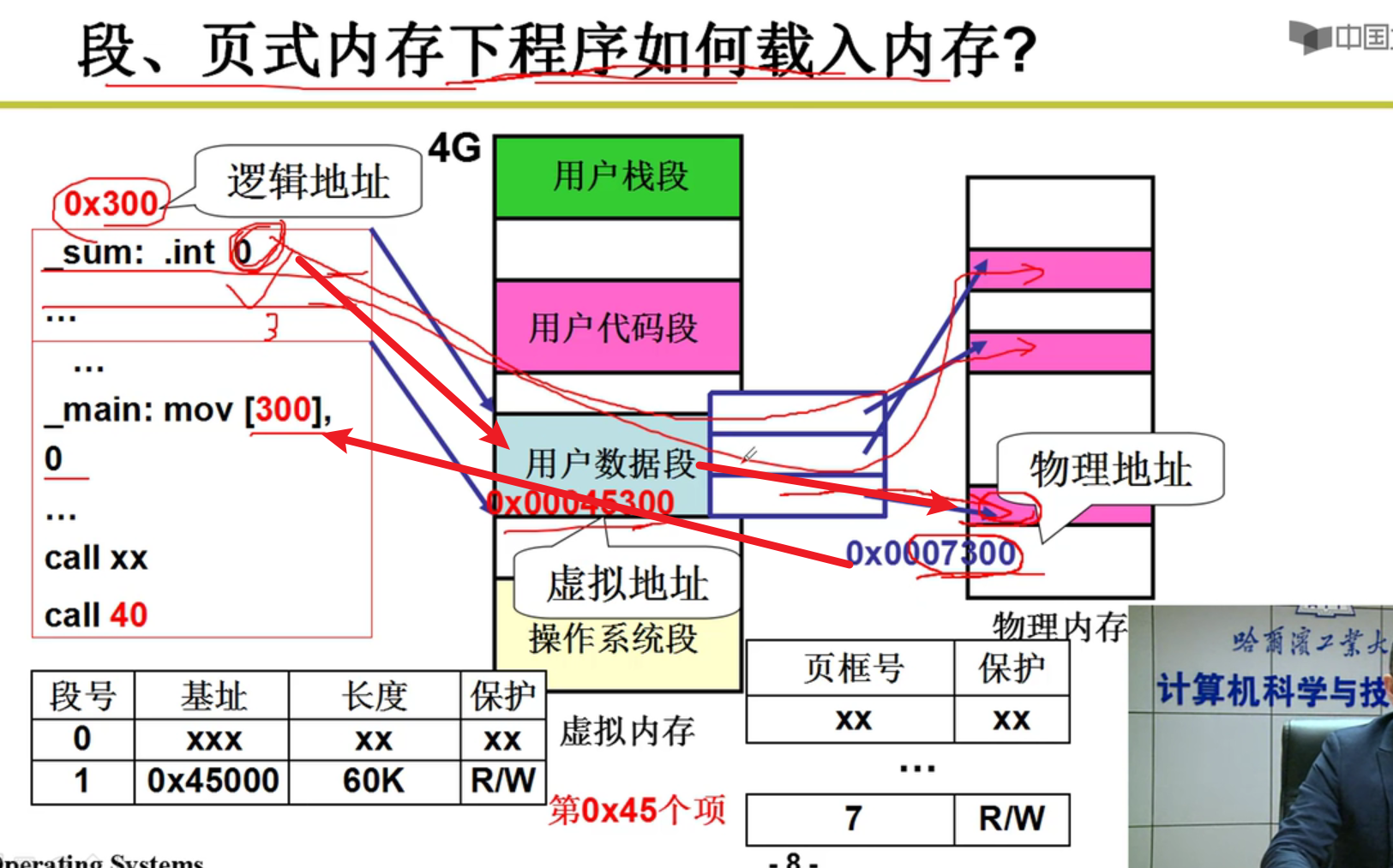
内存故事:
- 从fork进程开始探究整个过程:
分配虚存,建段表

- 虚存简化:

- 分配内存,建页表:
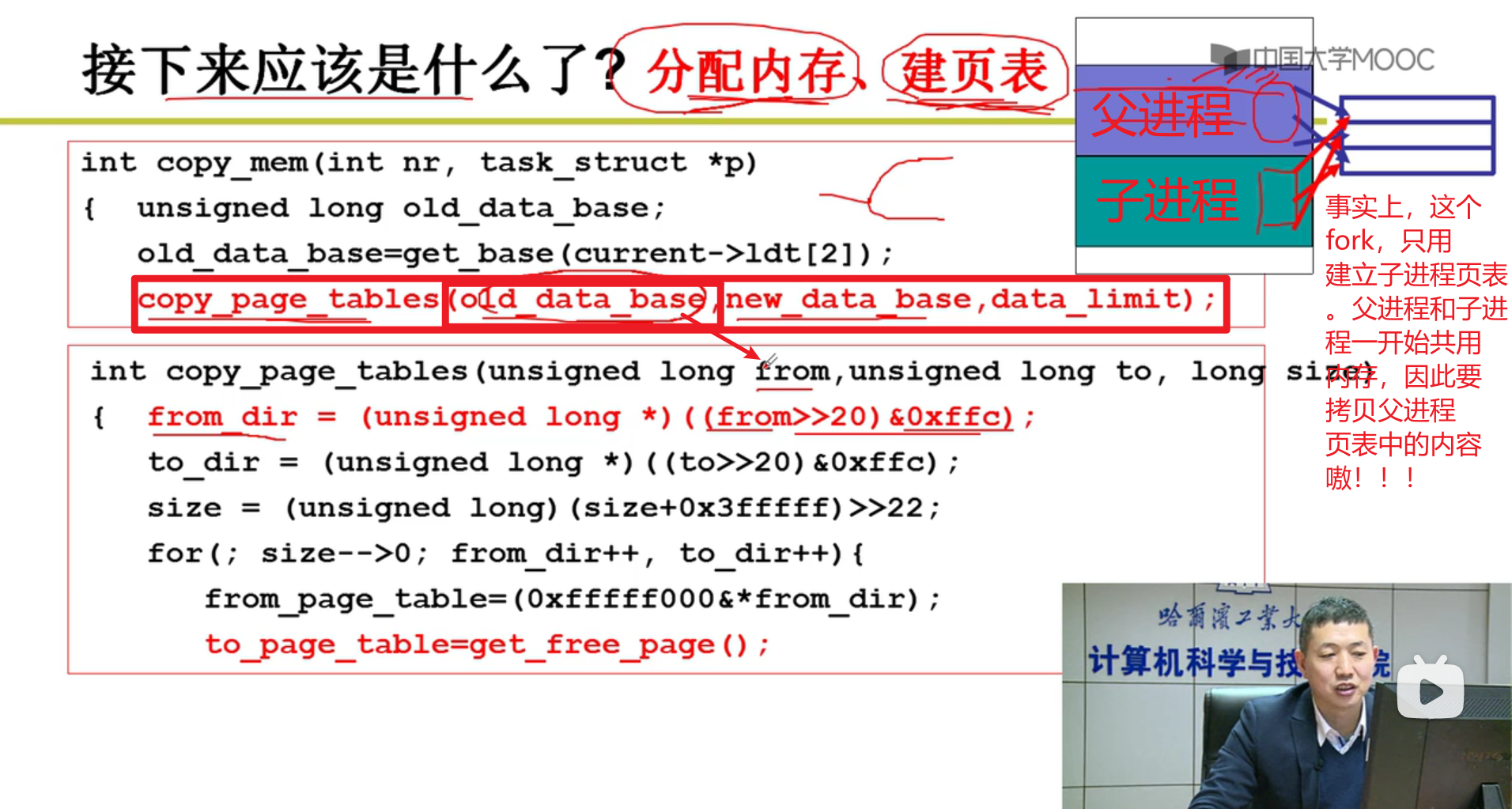
from是父进程的页表的地址
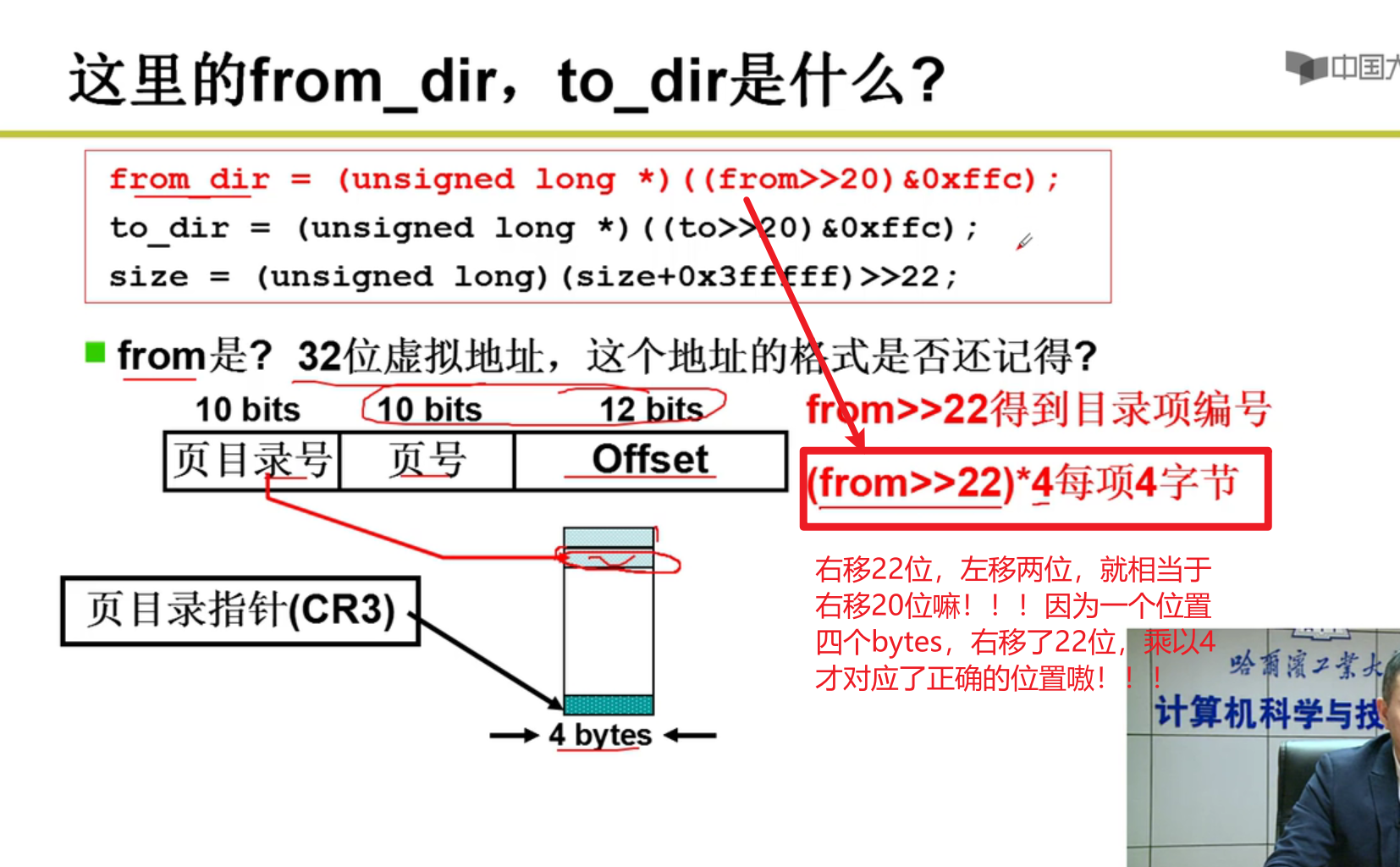
上面这里只是找到了哪一章,接下来要找是哪一节(段页式),因此还需要一次转换嗷!!!
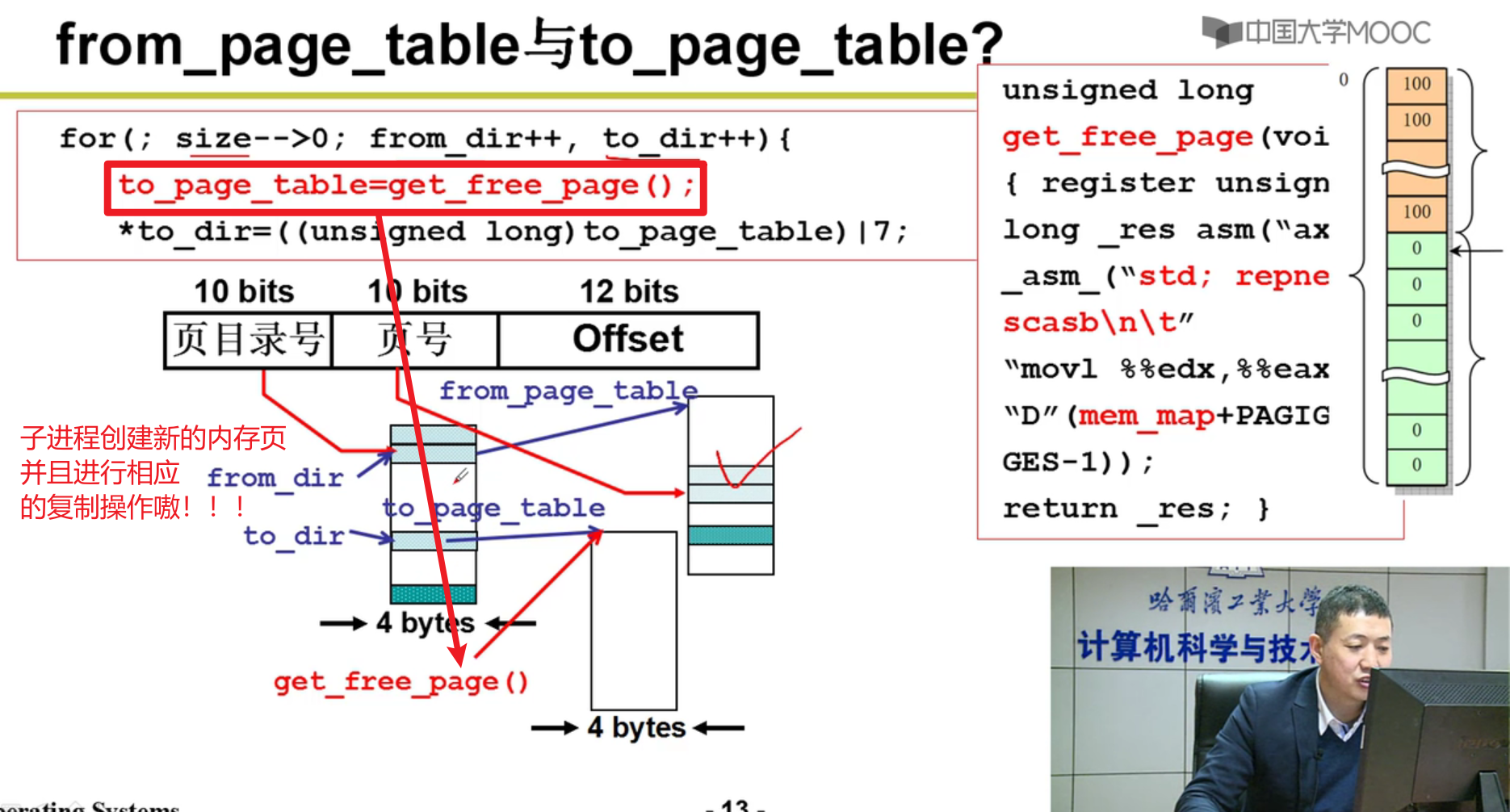
- 操作拷贝:
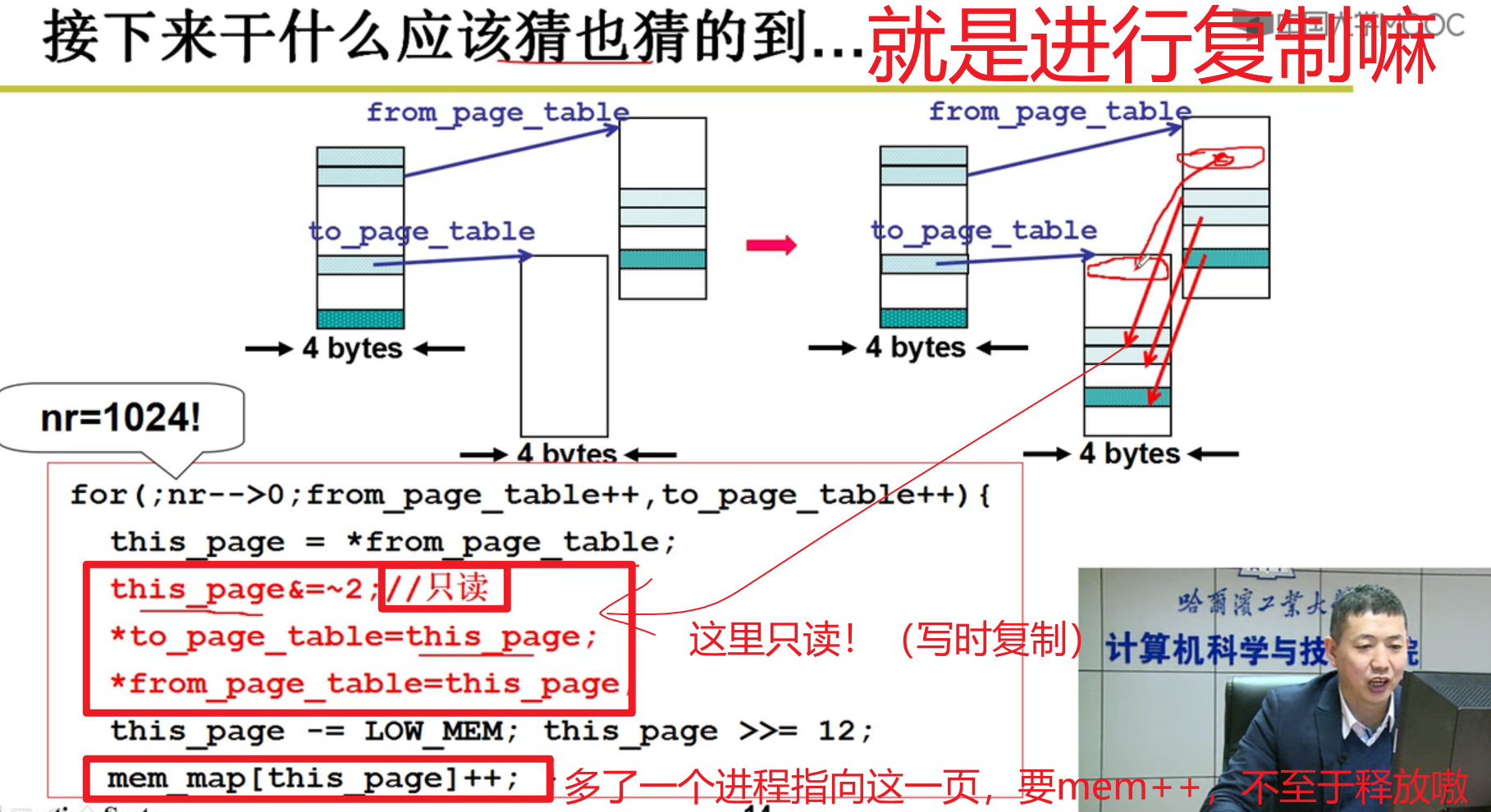
注意这里,写时复制!!!
- 复制完之后,整体架构:
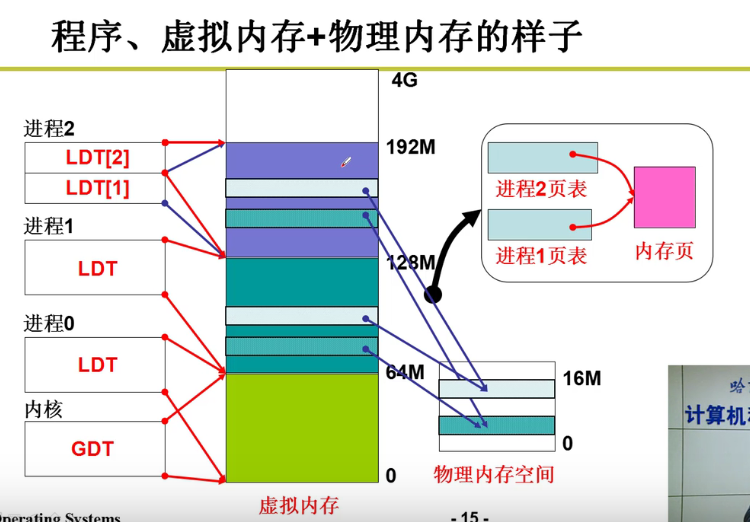
可以看出来,这里fork之后,创建了进程的LDT,并且分配了虚拟内存和页表给进程,指向了父进程实际的内存空间,至少能跑了orz
写时复制:
- 写时复制!!!子进程如何体现???
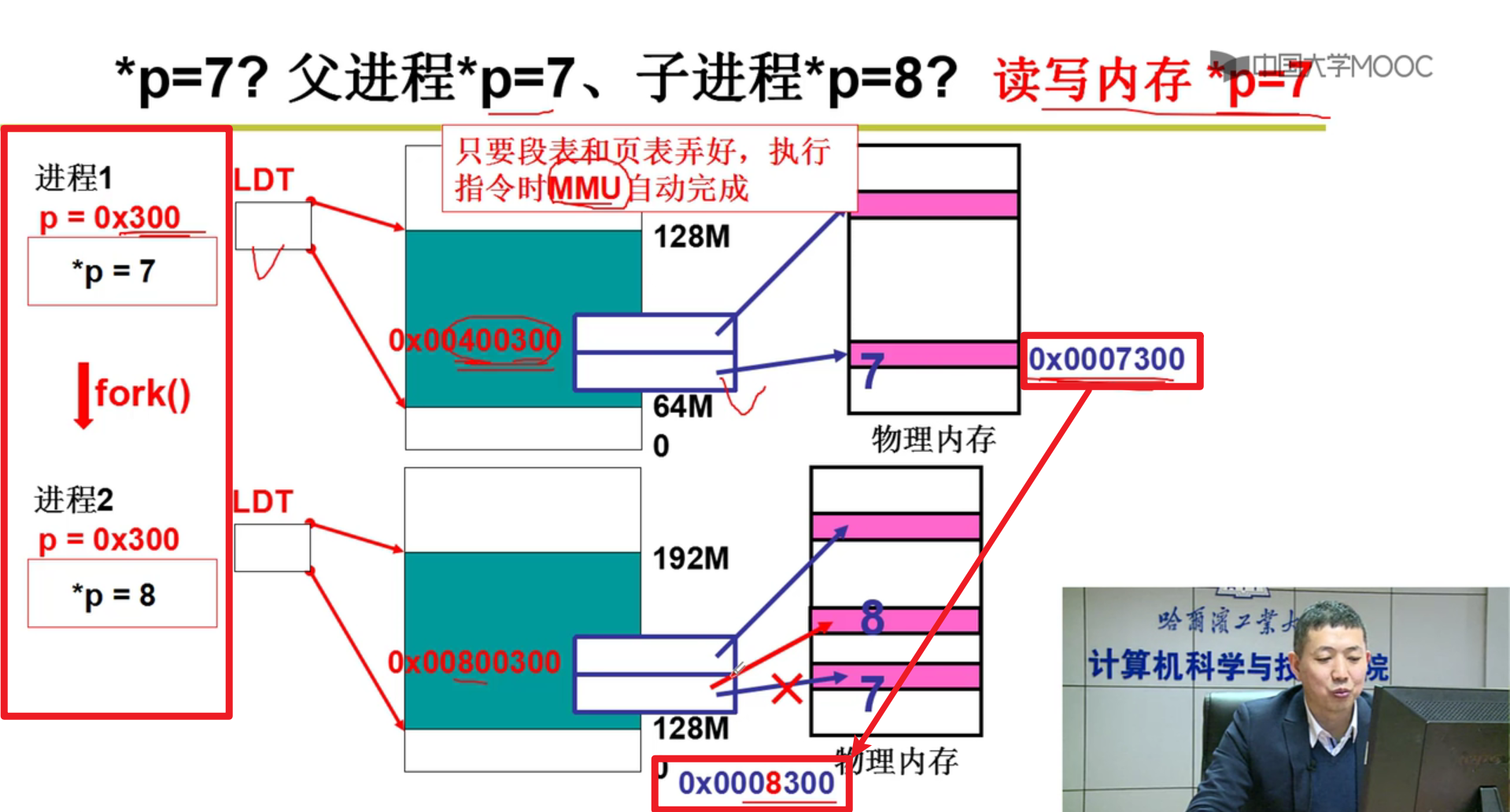
还记得前面子进程和父进程指向一样的地方吗?为啥设置为只读,就是为了这里的写时复制,多个进程在内存中的时候。写时复制就能够帮助我们消除多个进程fork的影响!!!就能够独立运行嗷!!!
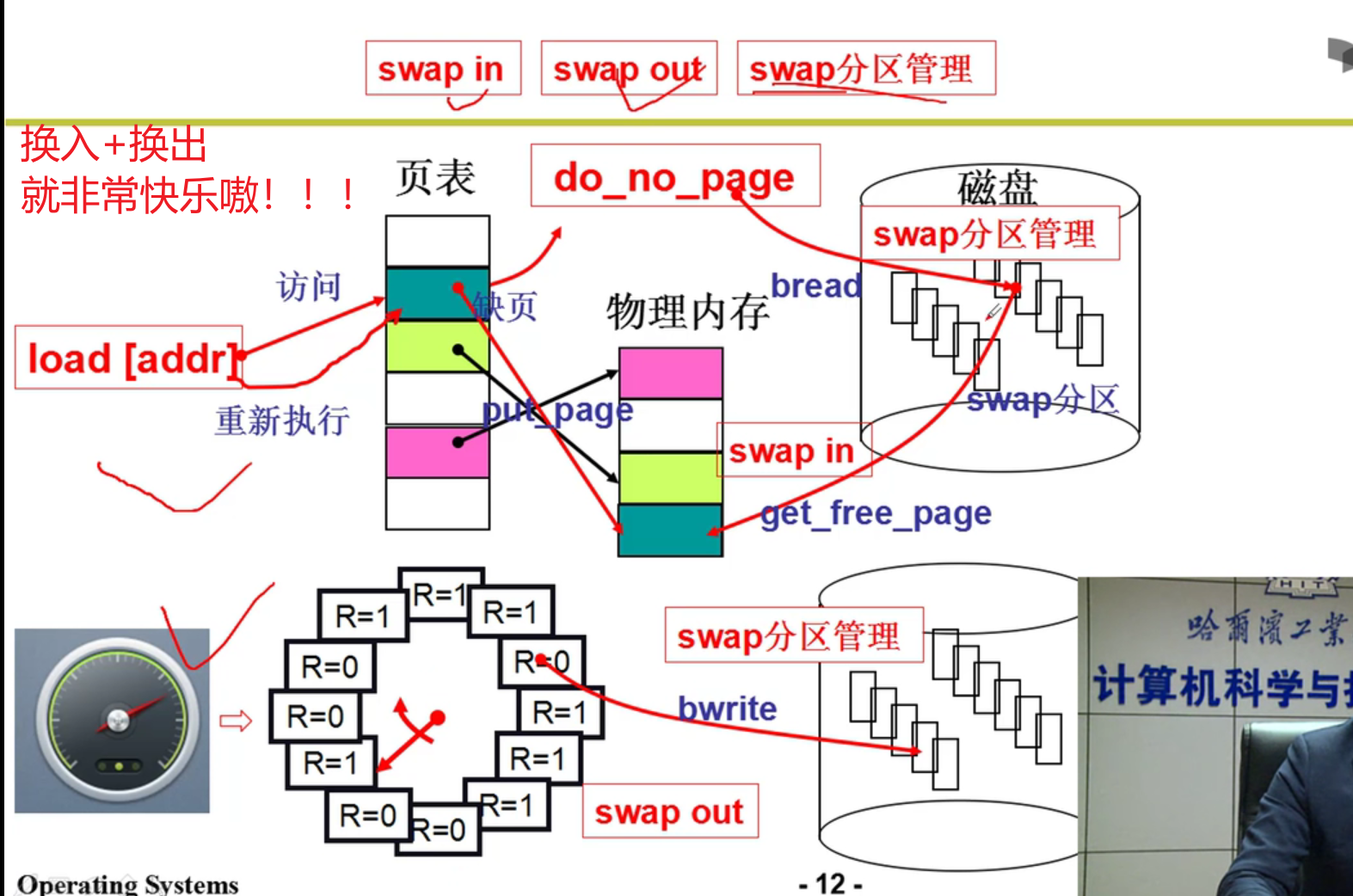
内存换入-请求调页:
- 虚拟内存!!!
- 用户眼里的内存:
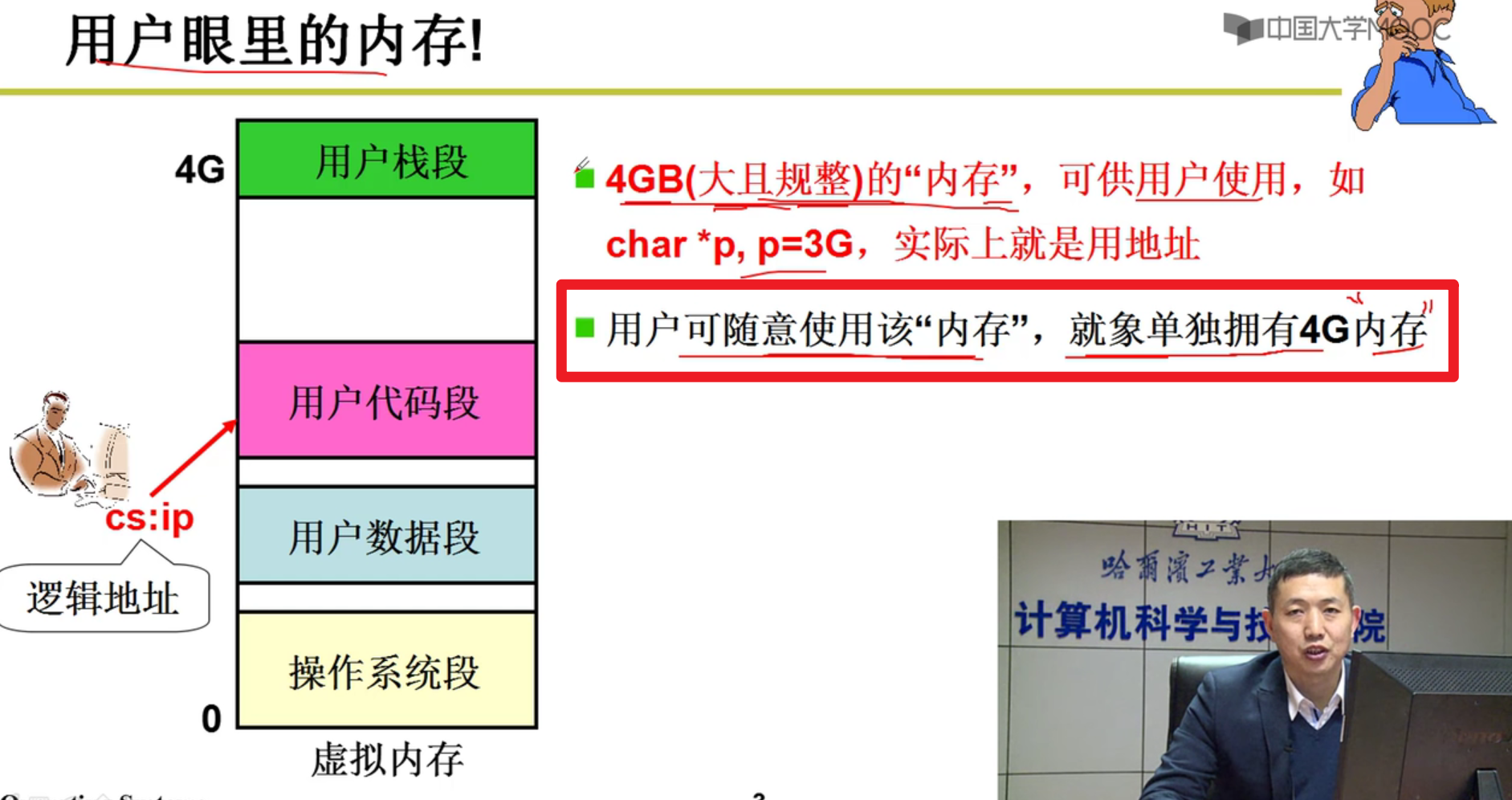
用户不知道后面的细节,由操作系统完成映射,为用户提供“假象”
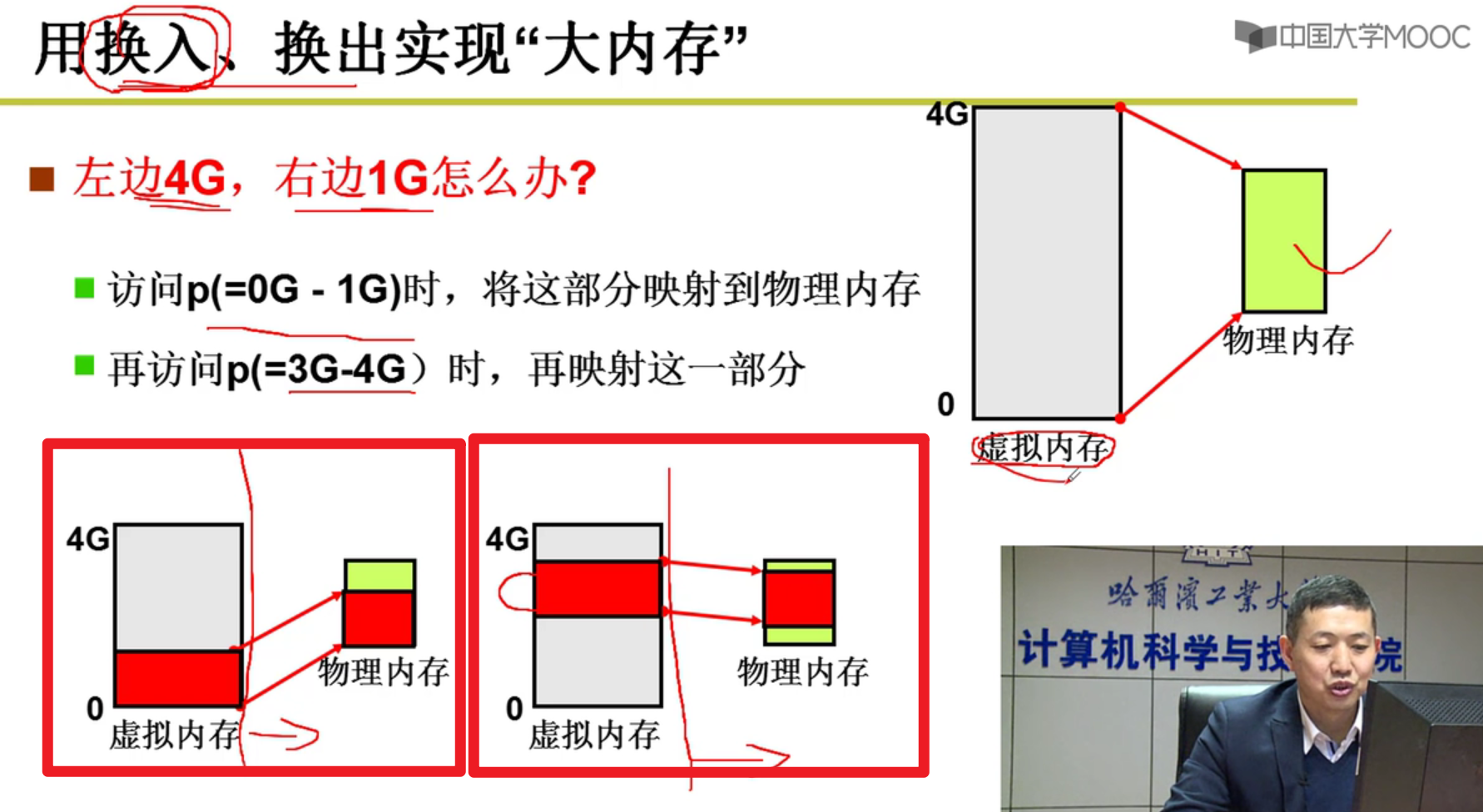
通过换入来实现展现给用户的假象嗷!!!
- 请求调页:
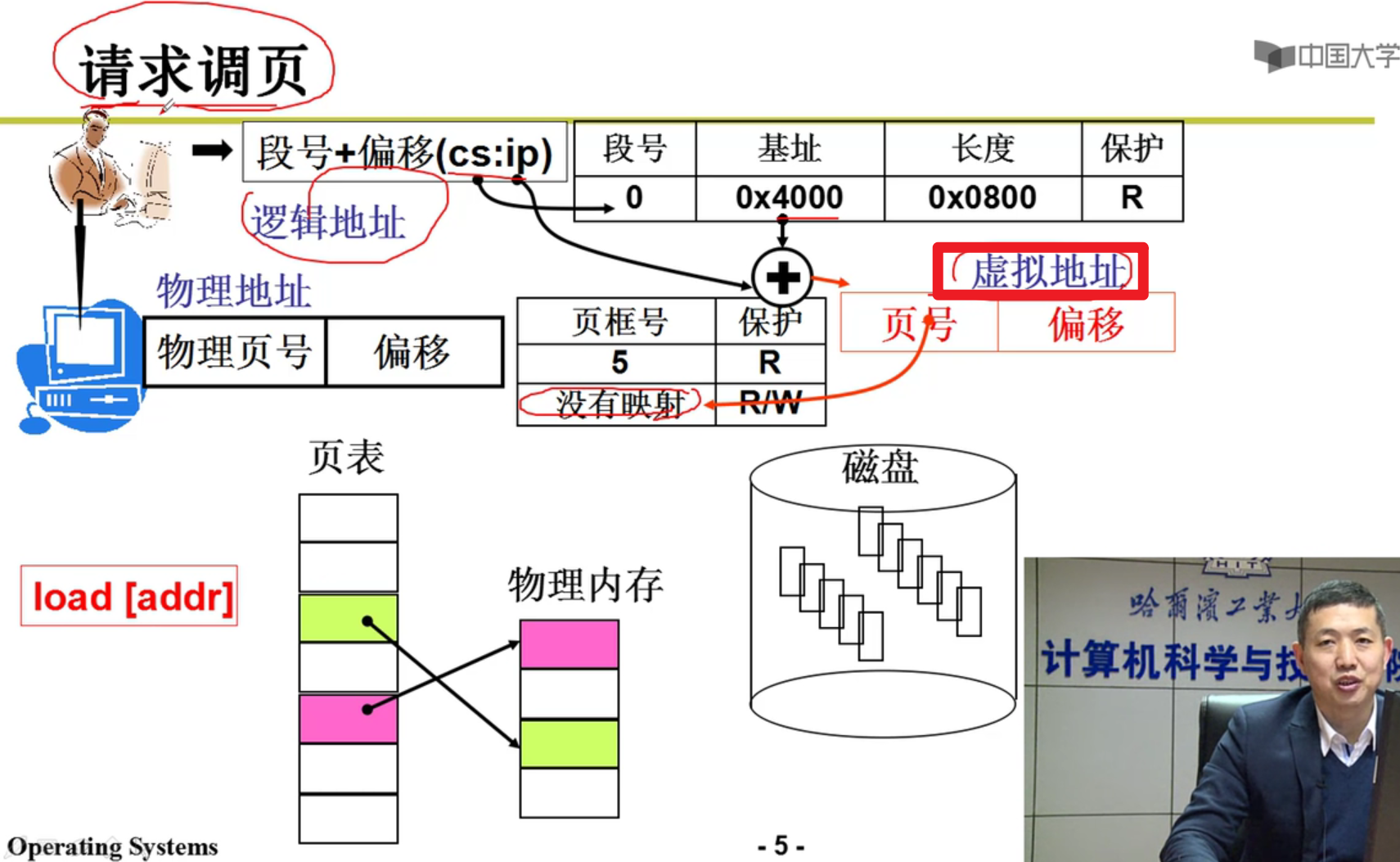
虚拟地址和虚拟内存有啥关系呢?虚拟地址的取值范围就是虚拟内存的范围,给用户的感受就是这些虚拟内存(虚拟地址)我可以随意使用。至于虚拟地址映射到哪个真正的物理地址上,不需要咱操心嗷!!!
上面告诉了我们页表可以映射到物理内存上,这里告诉了我们,当页表和物理内存不是一一对应的时候,操作系统是如何实现的(通过请求调页实现的嗷!!!)
- 发现缺页了怎么办???
中断!!!转去执行页错误处理程序嗷!!!
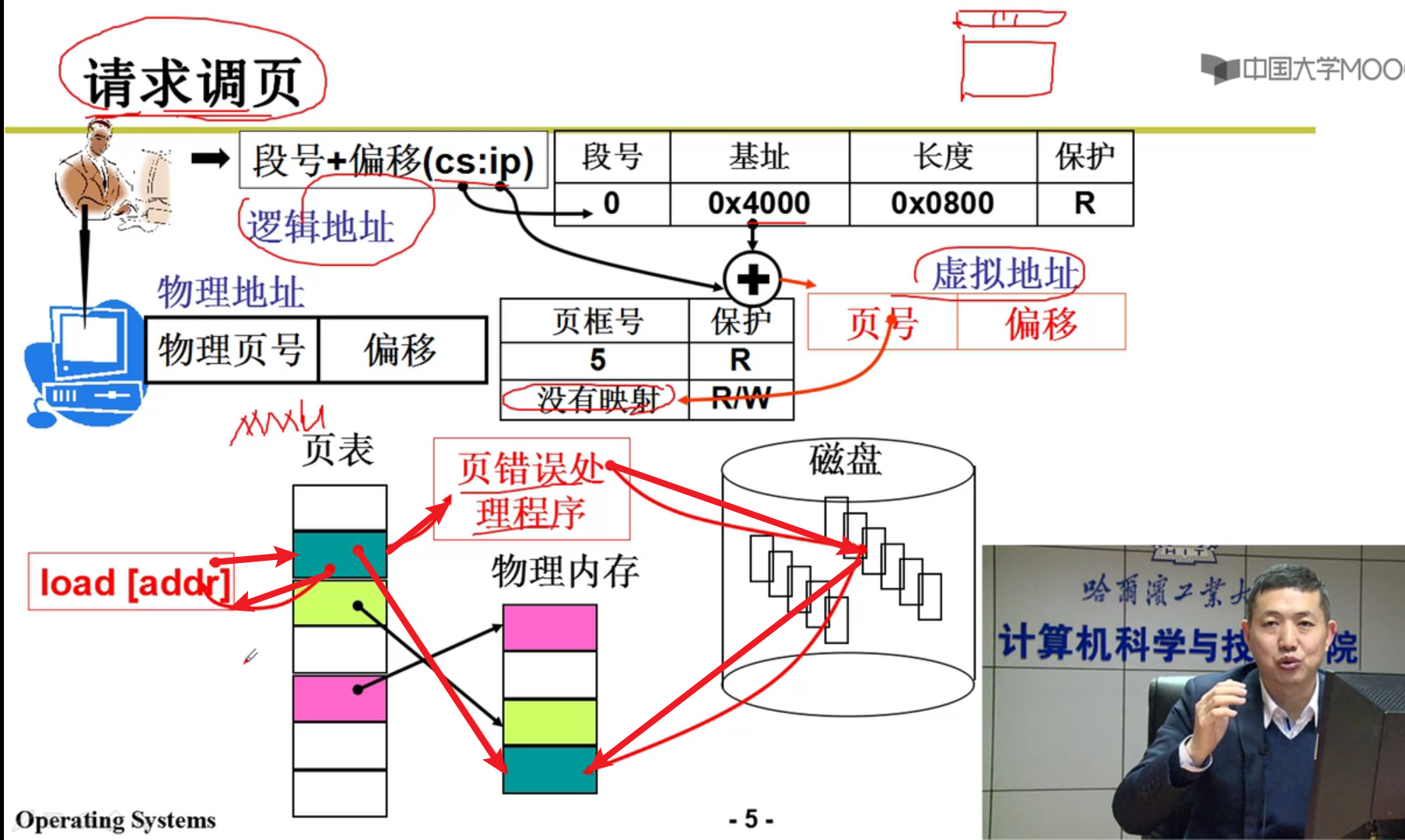
- 问题:

答案肯定是C哇!!!整个段也太浪费了叭呜呜,又不一定都用的上orz!!!
请求调页故事:

这里的14中断号就代表着请求调页嗷!!!
- 处理中断page fault:
将当前栈中的内容保存:
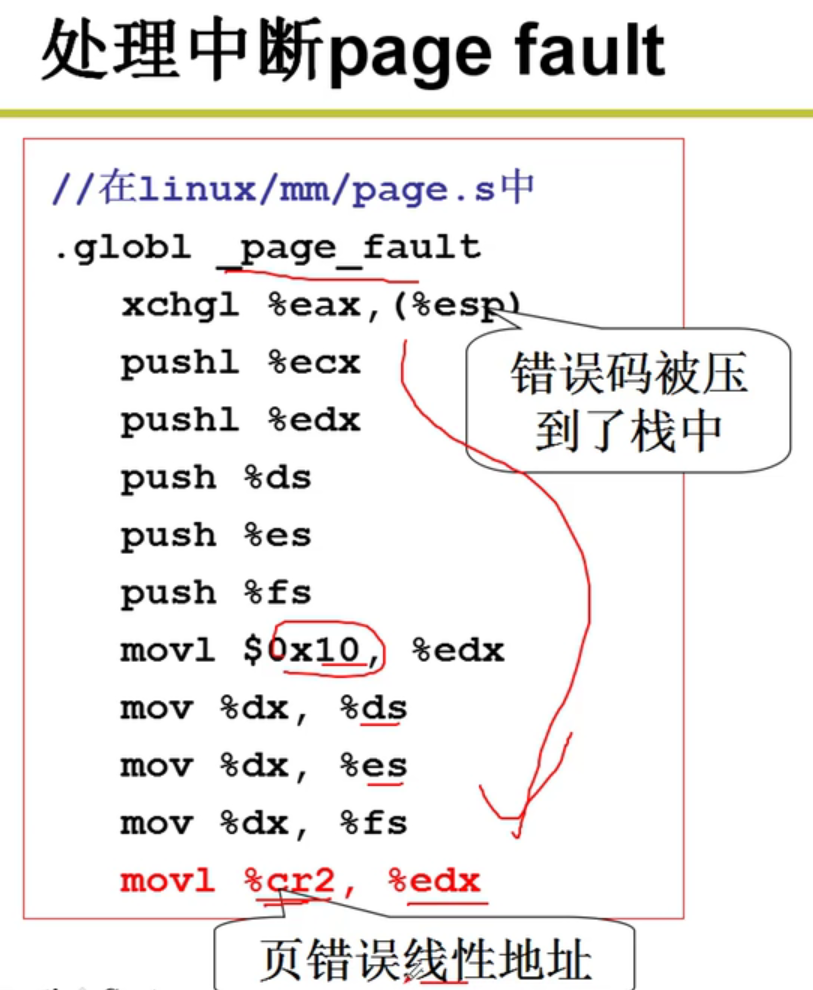
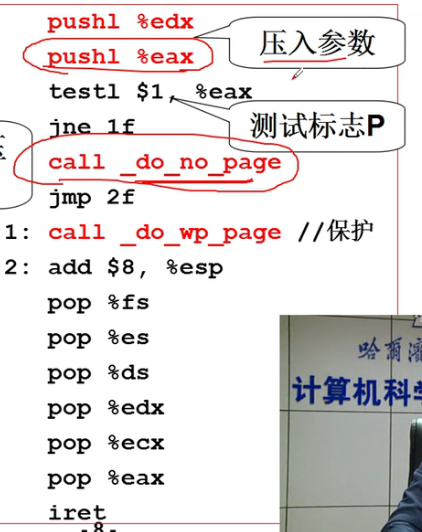
- 这里的_do_no_page干了什么?


- 建立虚拟页与物理页的映射:
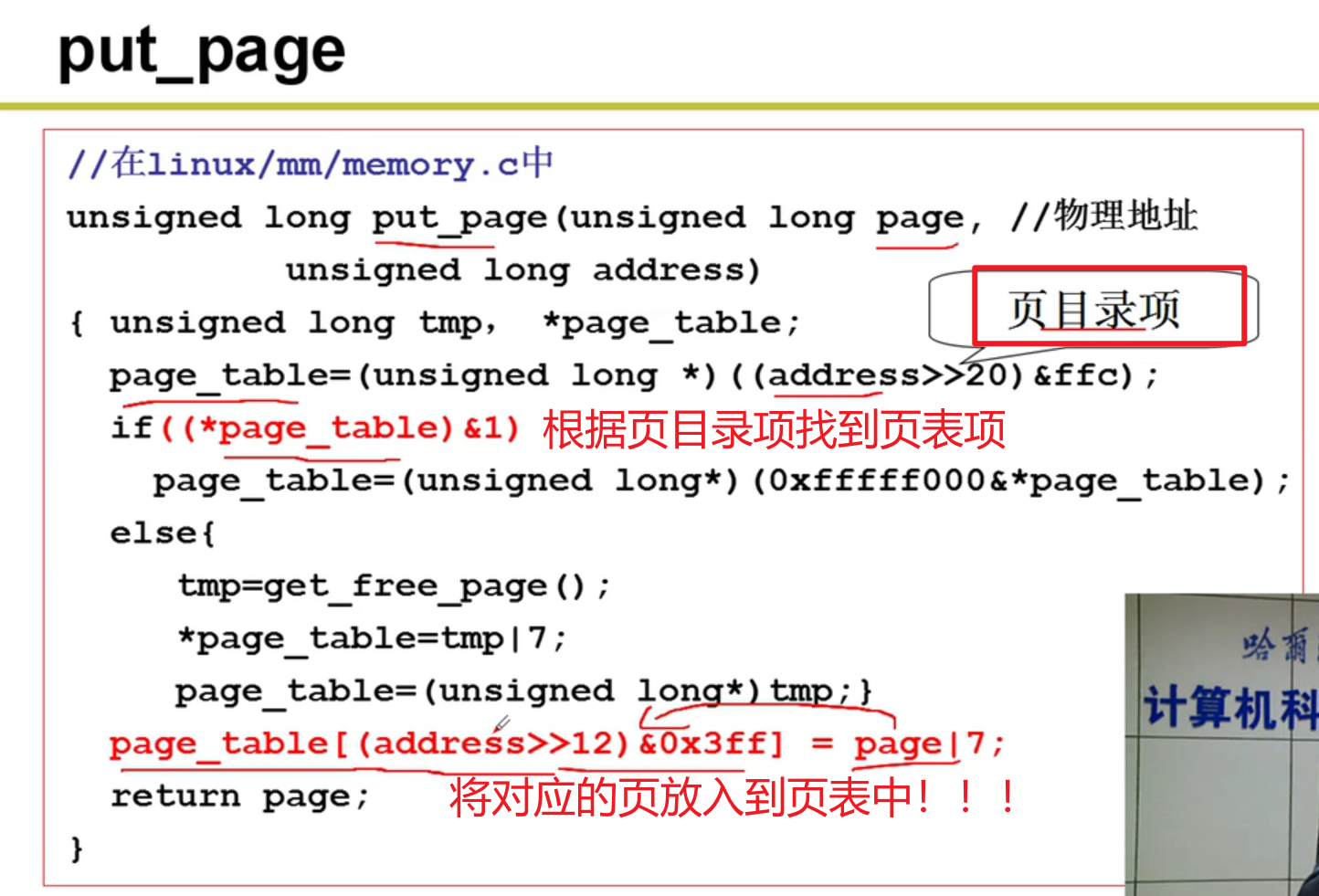
- 这些都做完了,给用户的感觉就是:你访问0-4G的内存都有东西嗷!!!我一个人拥有了4G的内存呢!!!
内存换出:
- 上面的get_free_page有问题,不一定总是能够获得新的空闲页嗷!!!:

换出算法:
- FIFO:
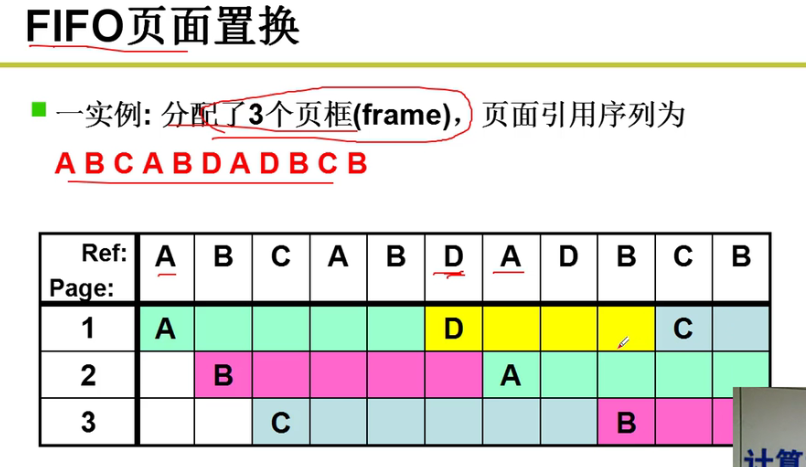
评价准则:缺页次数!!!
换出算法:
- MIN页面置换:
最优的情况!!!最好情况的置换!!!
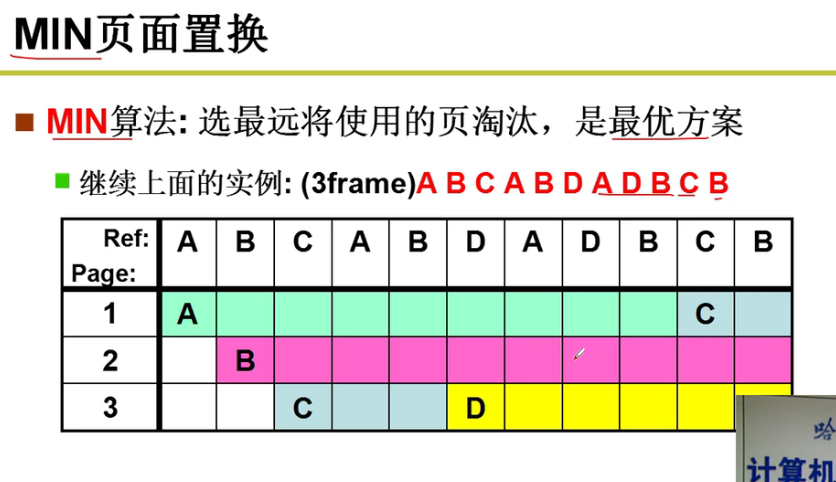
可惜,预测未来很困难,MIN不现实啊orz
换出算法:
- LRU页面置换:
用过去来预测未来,用到了程序的局部性嗷!!!
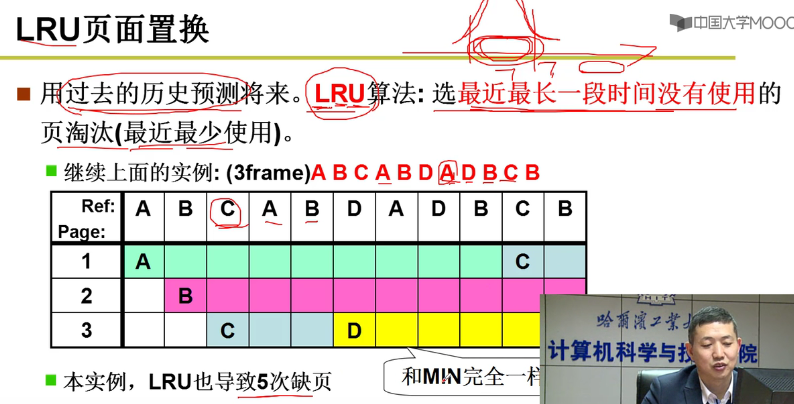
效果非常不错嗷!!!
- 如何实现?
- 想法:时间戳(time stamp)
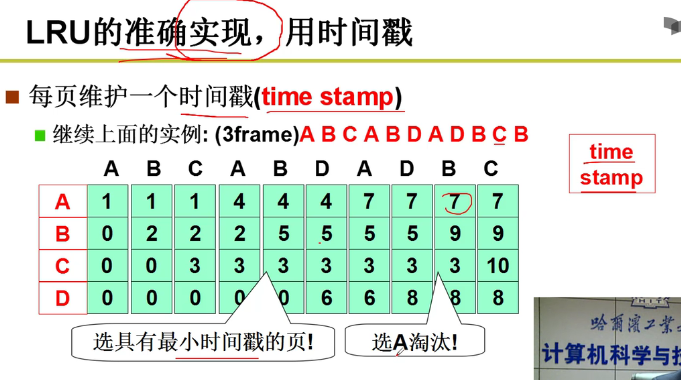
但是这个算法放入实际的操作系统中,是非常困难的嗷!!!维护一张大表,还有可能出现溢出的情况,计算机负担非常重orz。玩一玩可以,不可行!!!
另外的想法:页码栈:
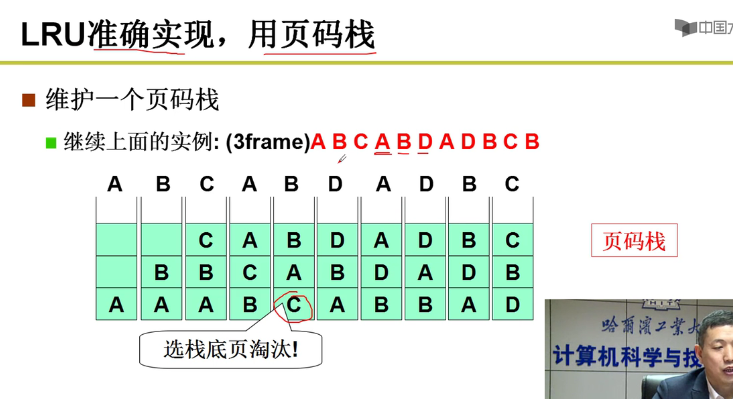
也是和上面一样,多次修改,实现代价非常大嗷!!!
LRU准确实现用的少嗷!!!
- LRU的近似实现(最近没有使用) - 将时间计数变为是与否:
就是我们上课讲的CLOCK算法嗷!!!(Clock Algorithm)
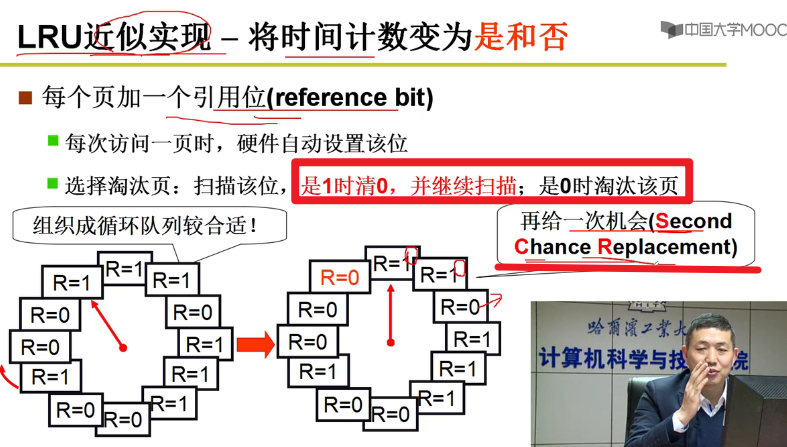
SCR算法:Second Chance Replacement,这个R标志位甚至可以给MMU,让MMU查页表的时候就自动对于其进行修改嗷!!!
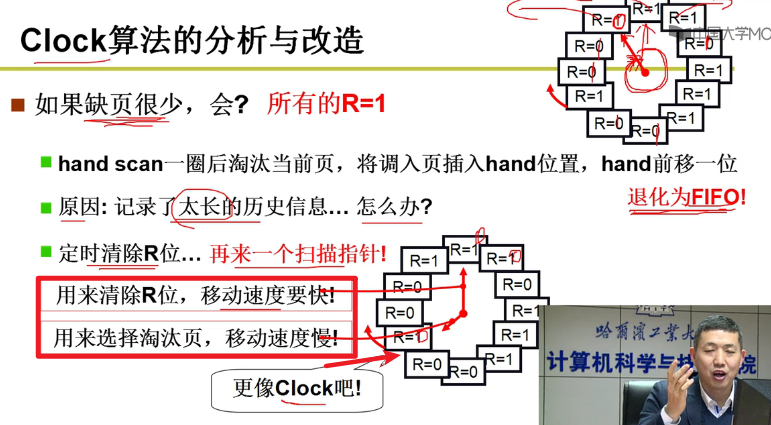
- Clock算法的分析和改造:
如果缺页很少???如果缺页少,慢慢的从0变为1,一次全清为0,然后接下来不就是遍历换出,那就退化成了FIFO算法了嗷!!!
原因:指针转的太慢了,记录了太长时间的历史信息
解决方法:定时清除R位置。再来一个扫描指针清除为0,这样就可以表达:从清除为0到现在这一段时间都没有使用嗷!!!(最近最少使用!!!准确来说是最近没有使用orz)
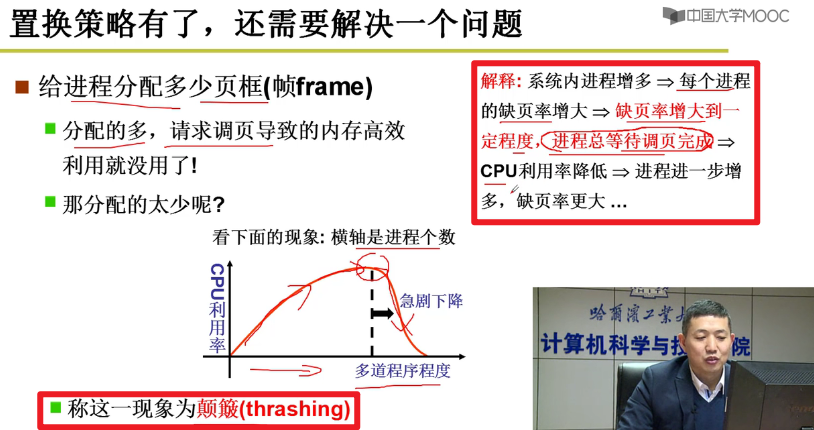
- 策略有了,还需要解决问题,给进程分配多少个页框呢?
工作集的概念嗷!!!也可以动态分配嘛!!!
虚拟 -> 段页 -> 程序 -> 进程
第五章(IO):
IO与显示器:
- 外设是如何工作的?
例如显示器,有一个显卡,我们给显卡中的寄存器中写入对应的内容。硬件的控制器就会根据寄存器中的内容来实际操作硬件嗷!!!
- 使用外设无非就是往控制器发指令嘛!!!本质上就是一条OUT指令嗷!!!
- 外设工作完成之后,CPU进行中断处理后续的东西就成了嗷!!!
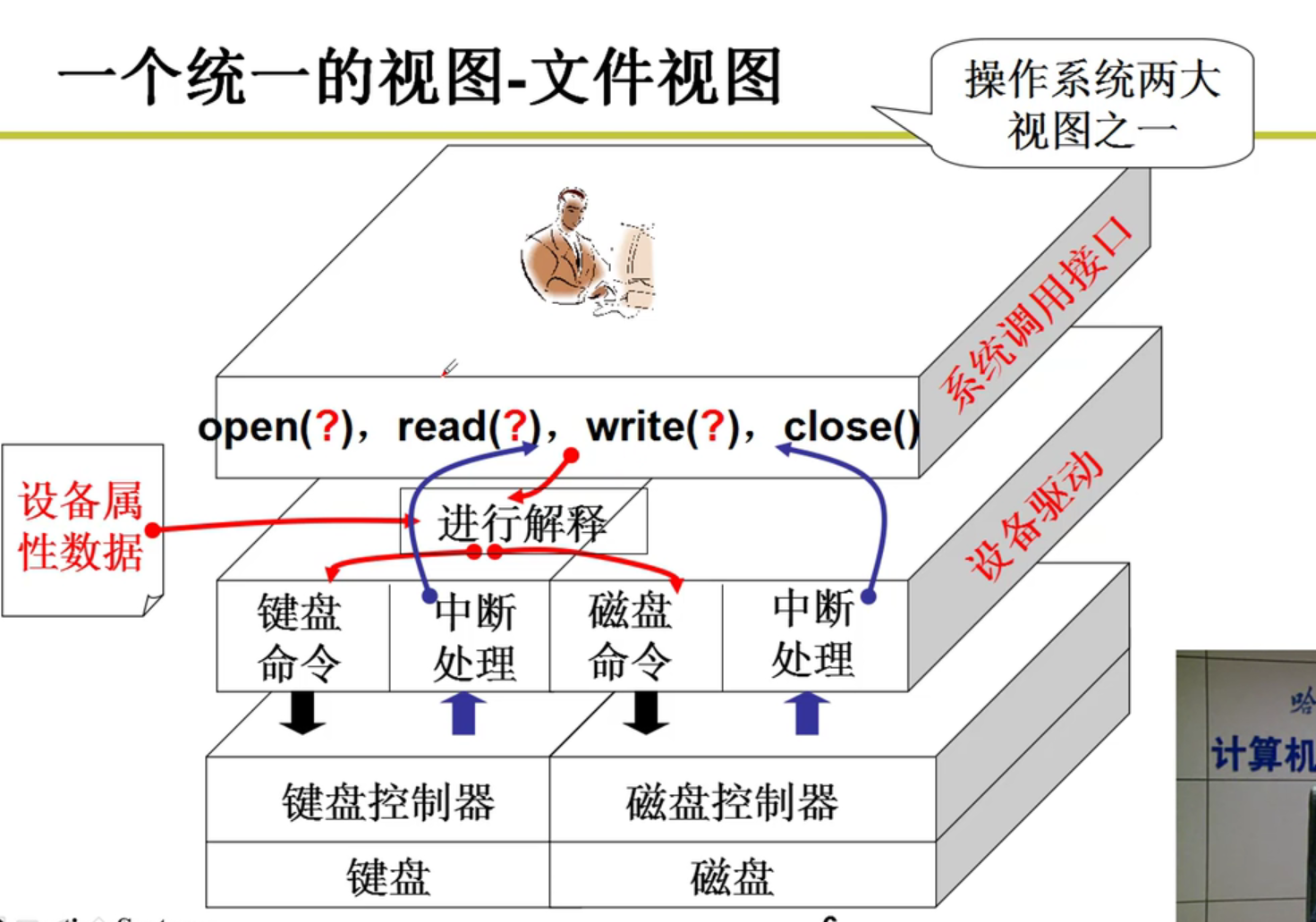
- 为了让使用外设简单,要形成一种统一的视图——文件视图,这样会比较方便啊!!!
- 实际操作外设的形式:

printf的故事:
- 从printf开始嗷!!!
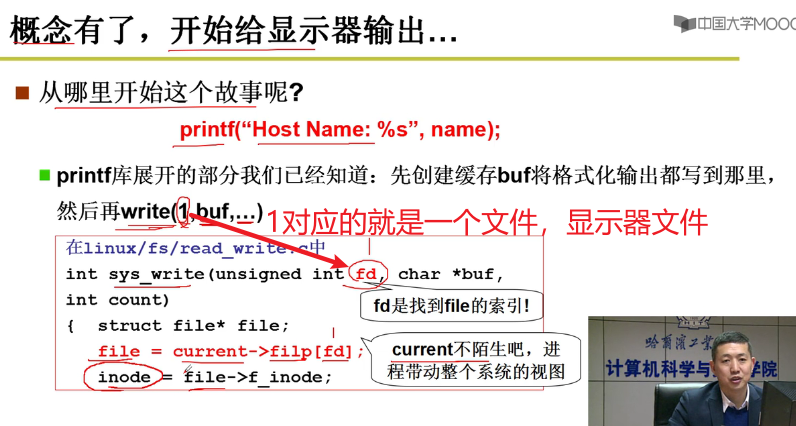
这里就获取到了打印机所对应的文件,并且得到了这个文件的inode结点嗷!!!
- filp从哪里来?
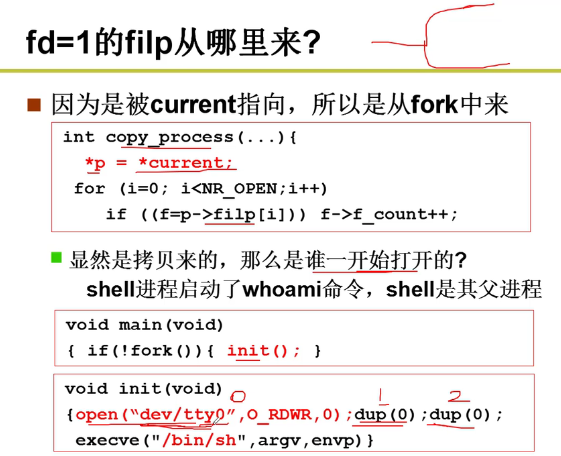
很显然,这里是从fork中所创建的嗷!!!
所有进程的PCB都是从父进程拷贝而来的,这里为了探究一开始这个文件是谁创建的,显然要从shell进行分析嗷
- open系统调用完成了什么?
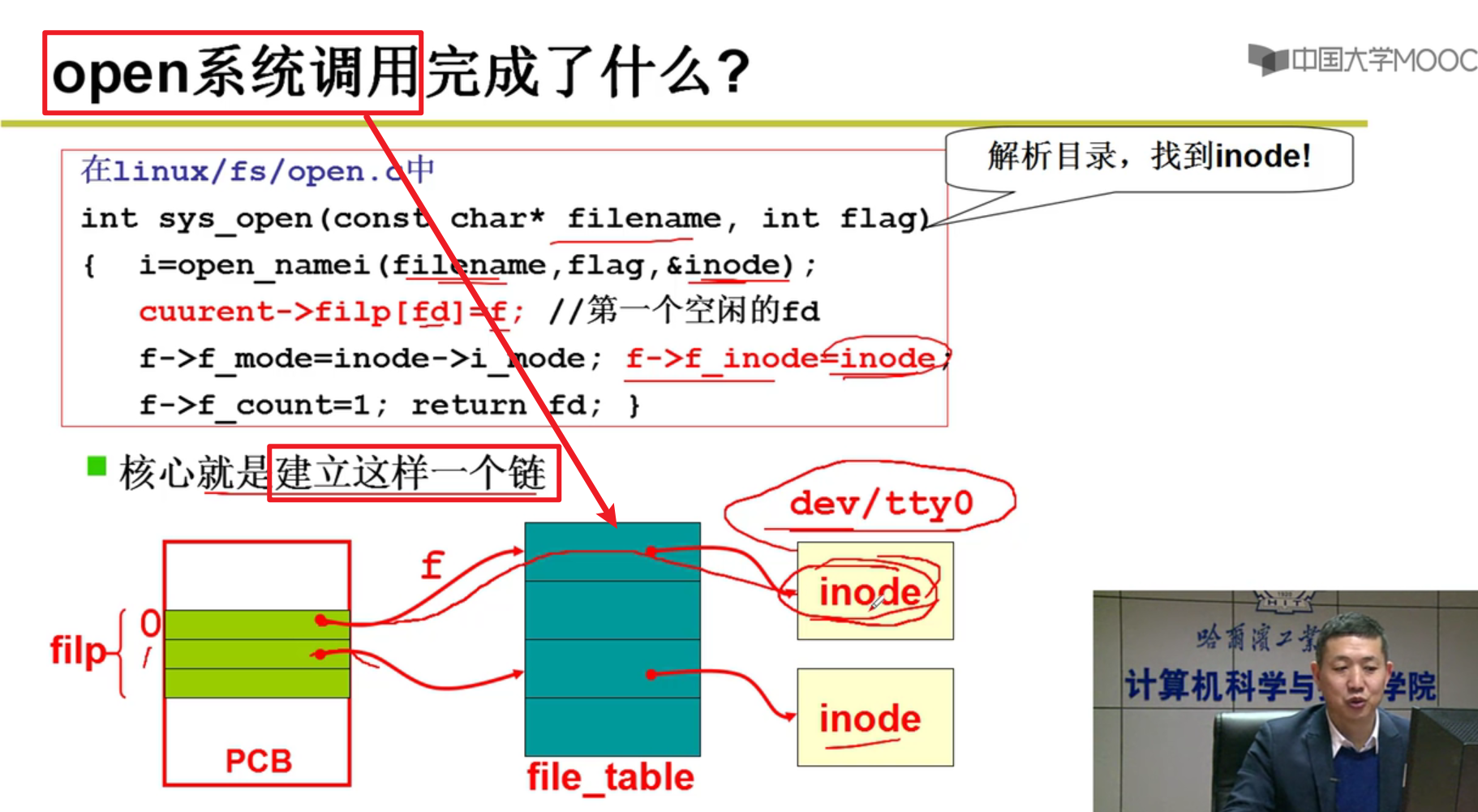
- open完成,真正向屏幕输出!!!
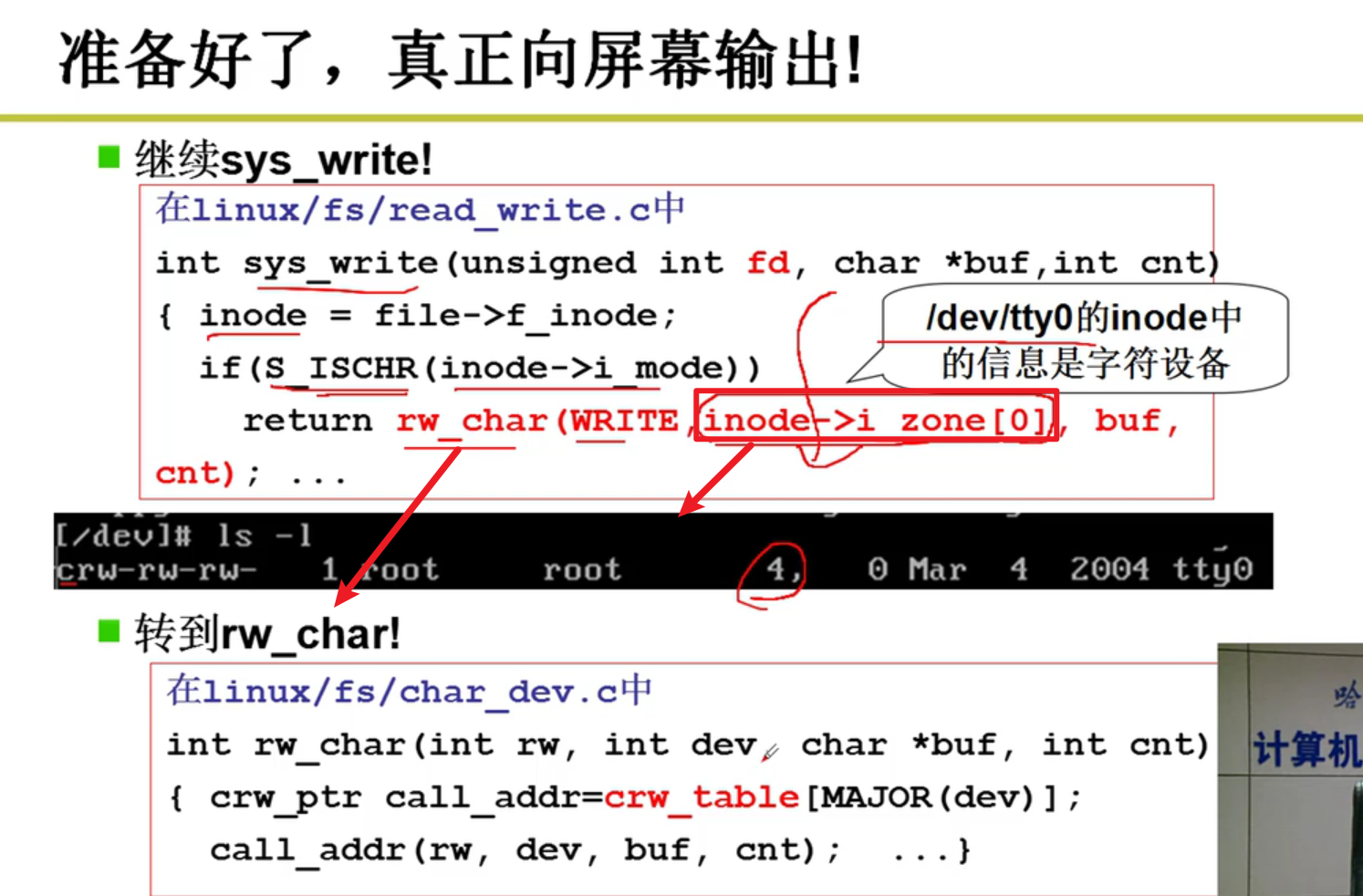
注意哈,rw_char中传入的第一个参数是Write嗷,这代表着这是一个写操作嗷!!!

- tty_write:
真正准备往设备里面写了,tty -> write_q,本质上就是往输出队列中写入相应的信息。如果队列满了,就应该sleep嗷,sleep_if_full。

- tty->write真的向屏幕输出啦!!!

下面这里实际写入屏幕实际上将数据放入了al,将数据属性放入ah,然后将构造好的ax放入pos,这个pos就是显卡的寄存器嗷!!!

说白了这个out就是这里的内嵌汇编mov嗷!!!
这里是一个循环嗷!!!不断把数据写出到屏幕上嗷!!!
- 设备驱动怎么写?
写出核心的Out指令,注册在表上,创建对应的dev文件,也和表对应起来,就完成了设备驱动的编写嗷!!!

操作系统初始化的时候起始我们见过这个90000,初始化鼠标的时候,其实我们都见过这个90000嗷!!!

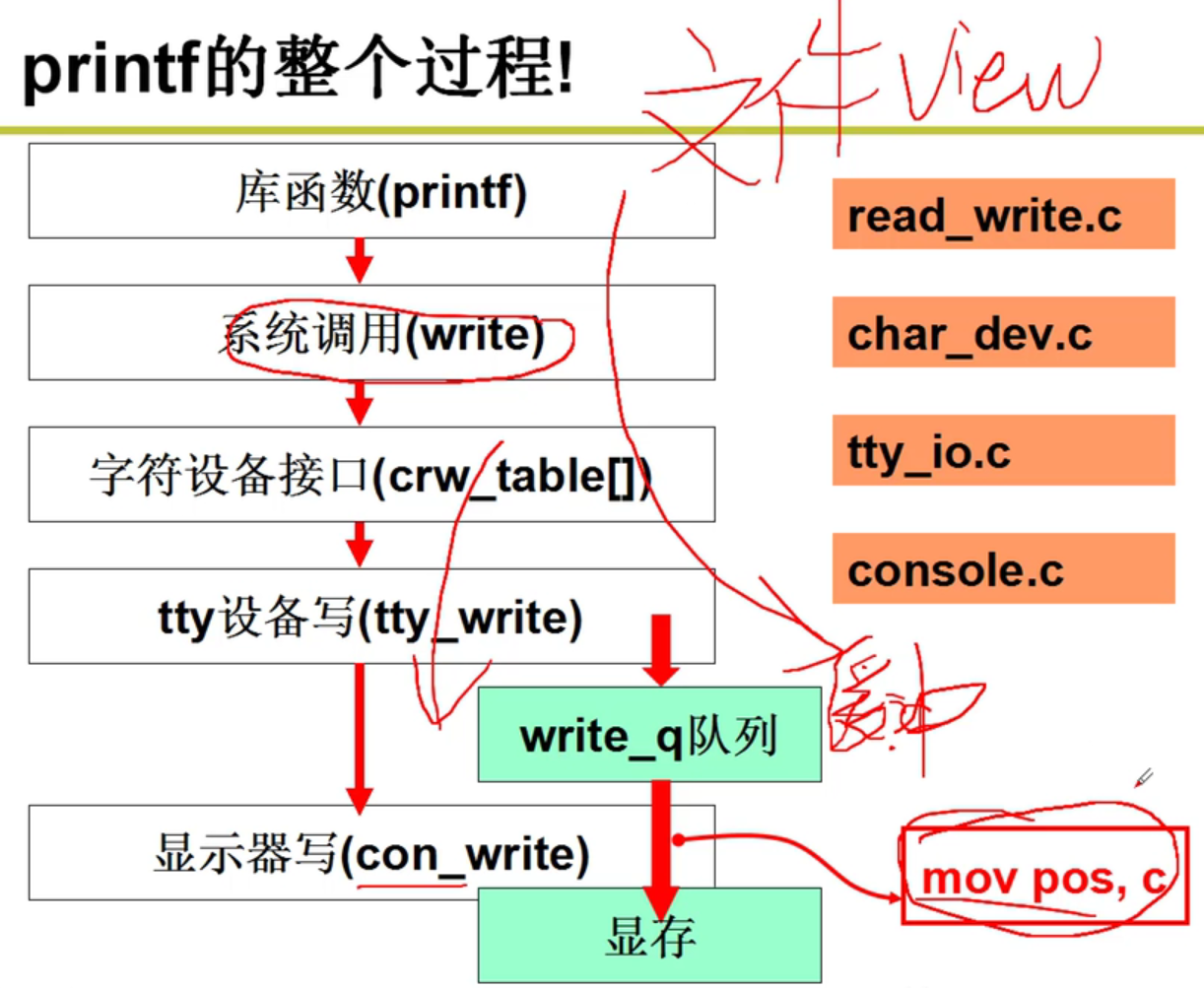
- 整个流程整理:
键盘:
- 键盘的故事从哪里开始?
- 按下键盘就会触发系统中断嗷!!!
- 从键盘中断(中断初始化开始嗷!!!)

根据系统码查表,进行不同的操作嗷!!!
- 处理扫描码
key_table + eax*4
key_table是一个函数数组,根据读取的标号去寻找并使用对应的函数嗷!!!
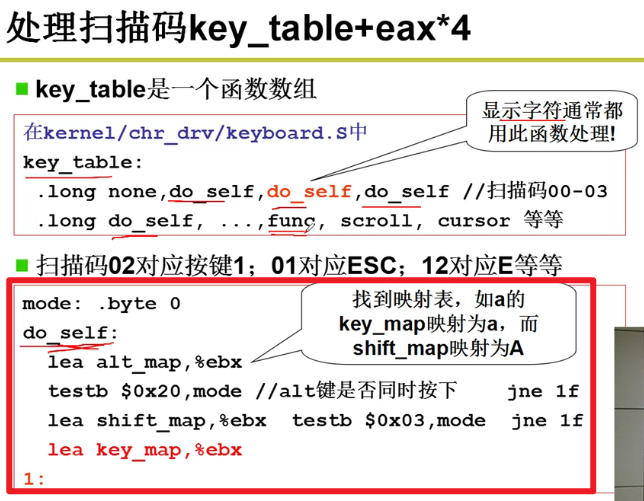
注意这里,我们将读取出来的数据放在了key_map中嗷!!

注意一下这里哦,这里读取到了对应的ascii码之后,就放到了对应的队列中,就是缓冲区嘛,和之前一样的嗷!!!call put_queue就是将其放入缓冲区中嗷!!!

- 目前还差什么呀?
回显!!!

- 键盘处理流程:
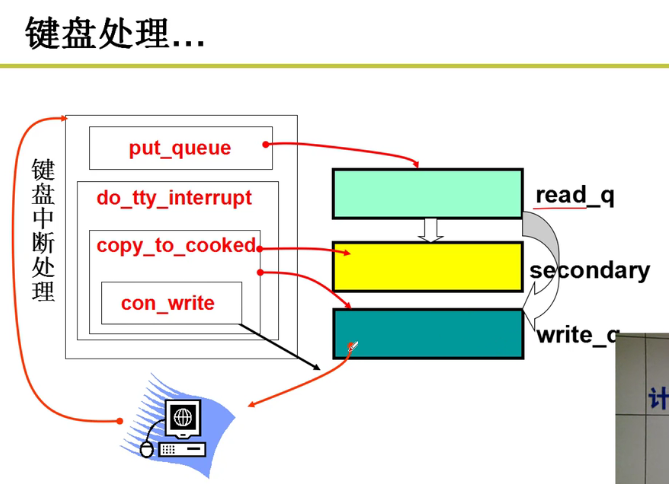
read_q到secondary无非就是对于读入的字符进行一些类似于转义之类的处理哇,供计算机方便使用嘛,比如转成ascii码嗷!!!
- 统一的文件视图:
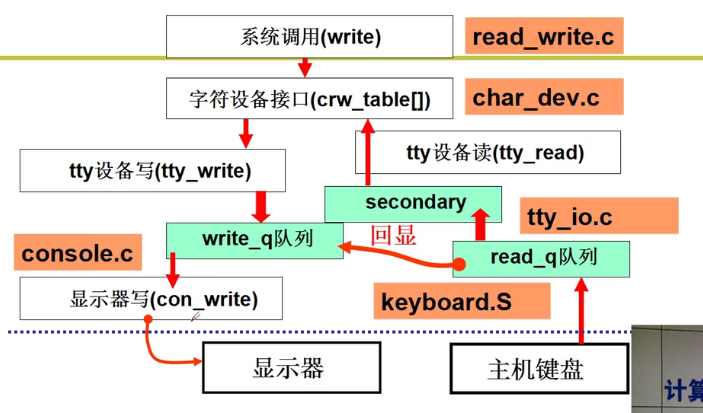
问题:按下F12,让ls的输出为*,怎么办?调用的处理函数改成我们自己的函数就行嗷!!!
磁盘管理:
生磁盘的使用:
- 磁盘结构:
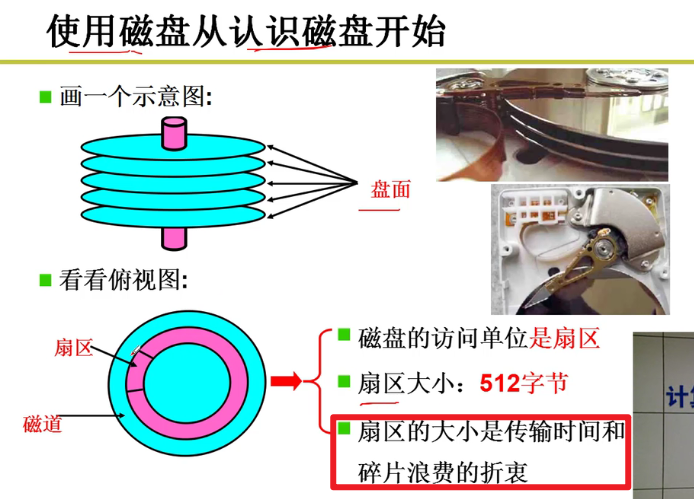
- 基本工作过程:
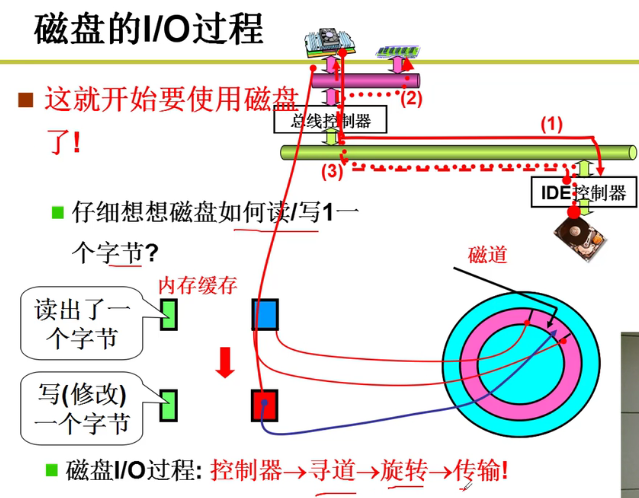
- 核心就是算出寻道,旋转和传输的距离(三个参数)然后搭配OUT和IN就完成了整个过程嗷!!!
- 太复杂了orz,所以引出了第一层抽象:
- 只用给盘块号,磁盘自动计算出CHS(cyl , head , sec),磁盘自动找到对应的位置嗷!!!
- 编址转换:一维block号到三维实际磁盘结构
- 下面的一些知识:
注意,这里程序传入的是block盘块号,经过磁盘驱动,转换为了对应的磁道,扇区和位置嗷!!!
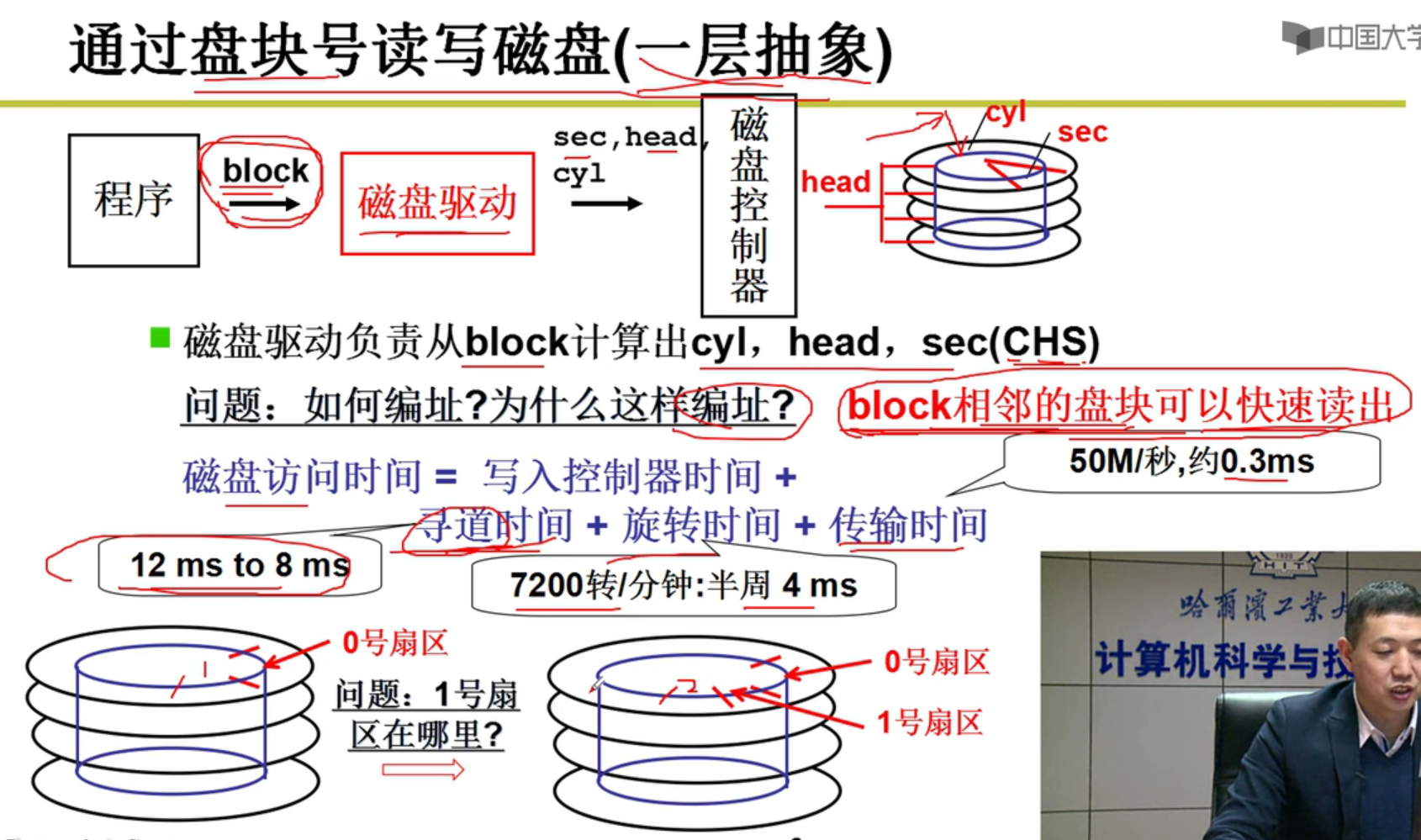
加快速度:一条磁道读完了,怎样最快读下一条磁道呢?
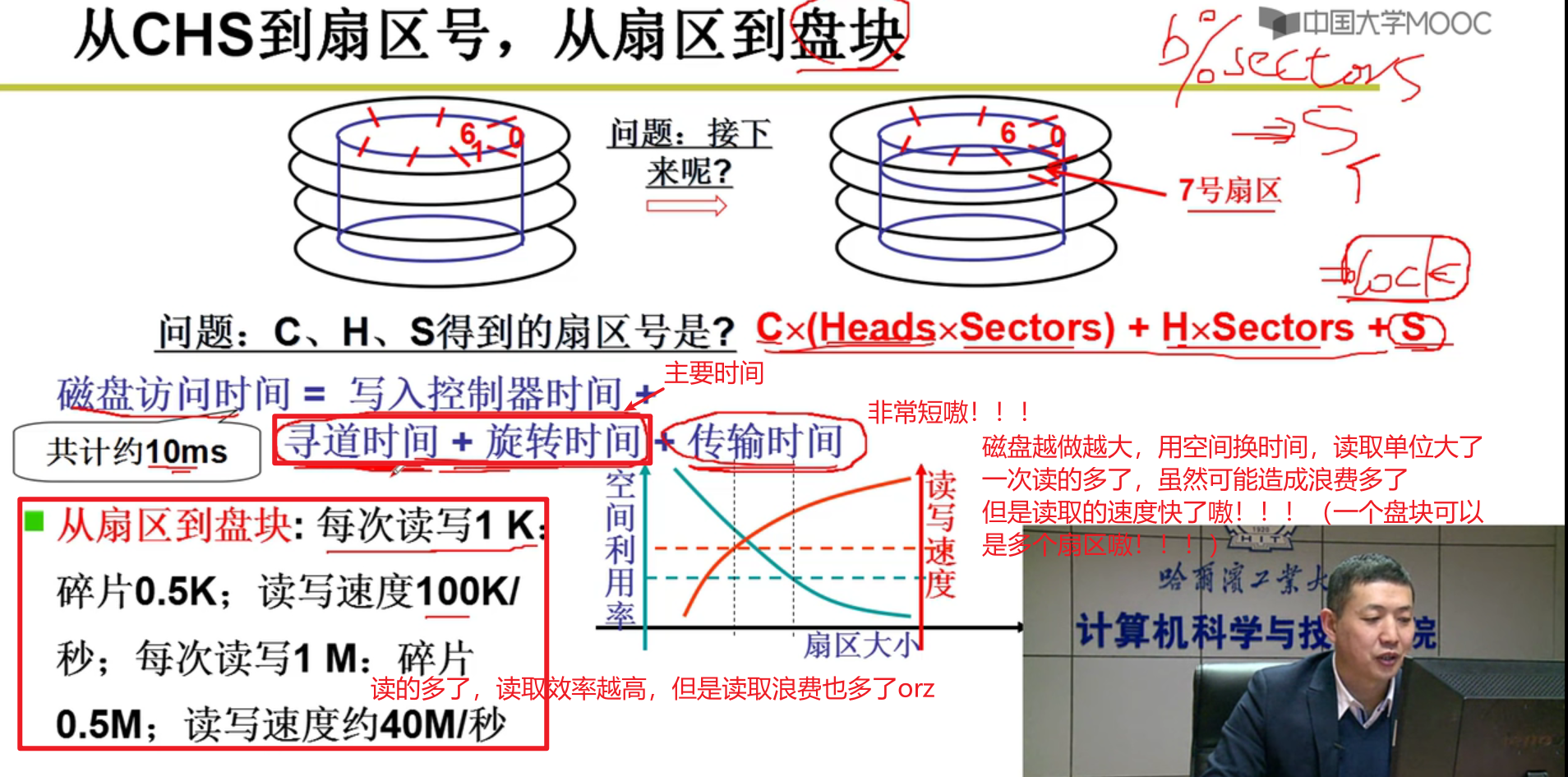
- 程序输出block:

req->sector = bh->b_blocknr << 1;
这个东西左移越多读取越快,一次读的越多,干的活越多,虽然浪费可能越多,但是效率就越高嗷!!!
- 第二层抽象(多个进程通过队列使用磁盘):
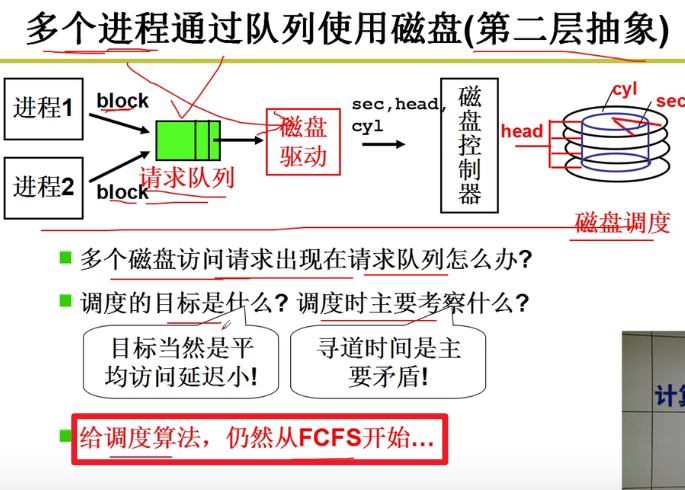
寻道时间是主要矛盾,让寻道时间越短越好嗷!!!
算法:
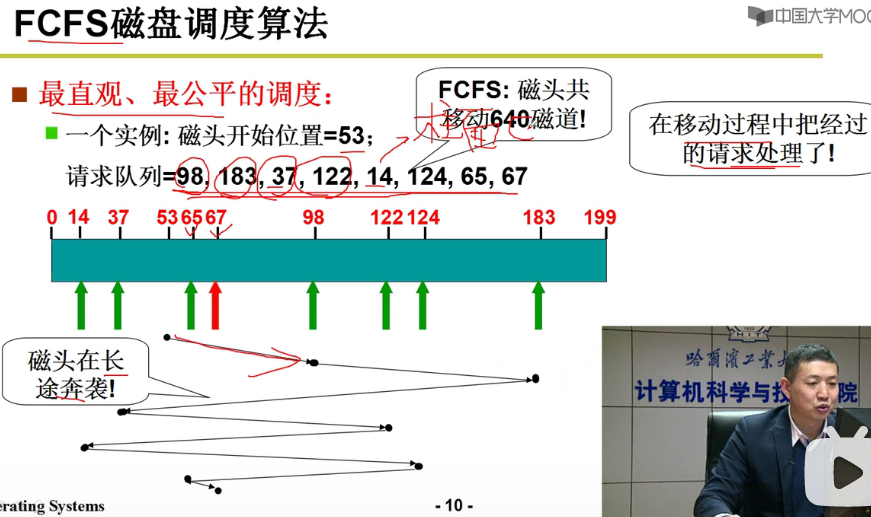
- FCFS磁盘调度算法:
- SSTF磁盘调度:
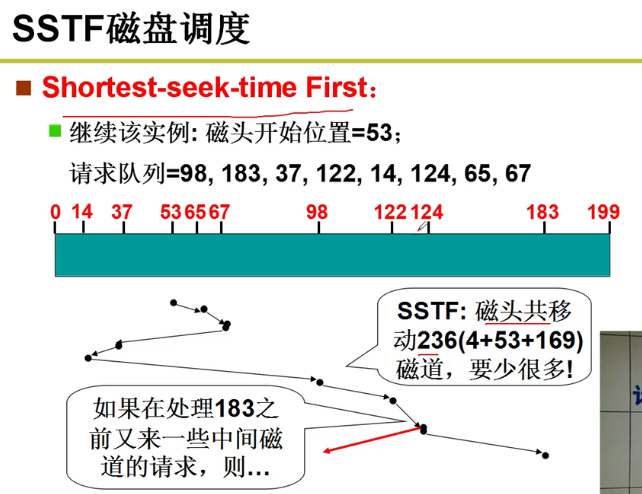
存在饥饿现象
- SCAN磁盘调度:
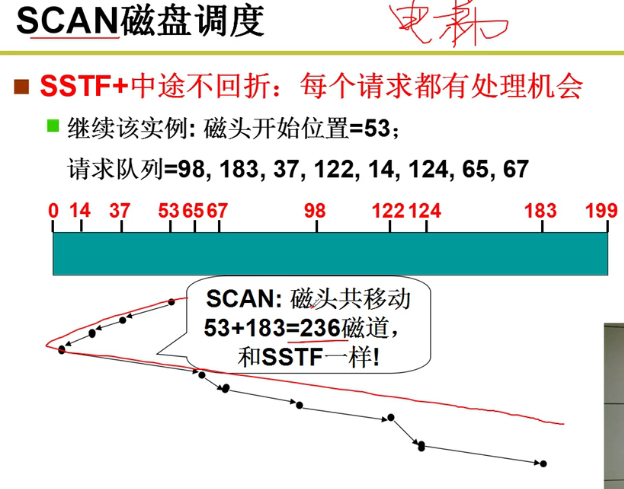
- C-SCAN算法:
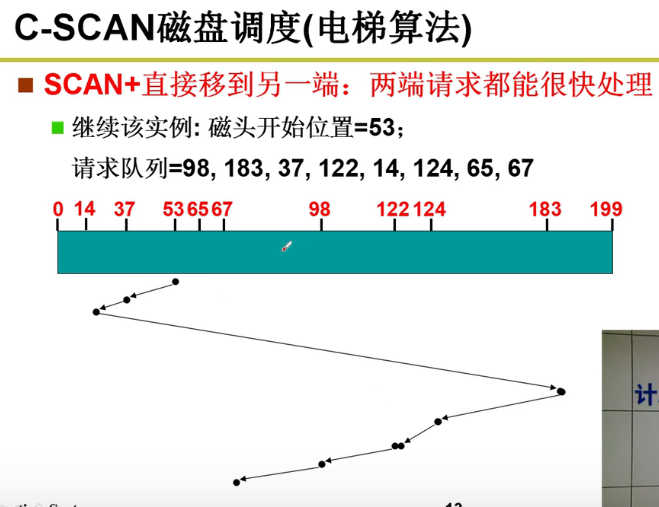
磁头复位非常快嗷!!!这种方法就十分公平嗷!!!
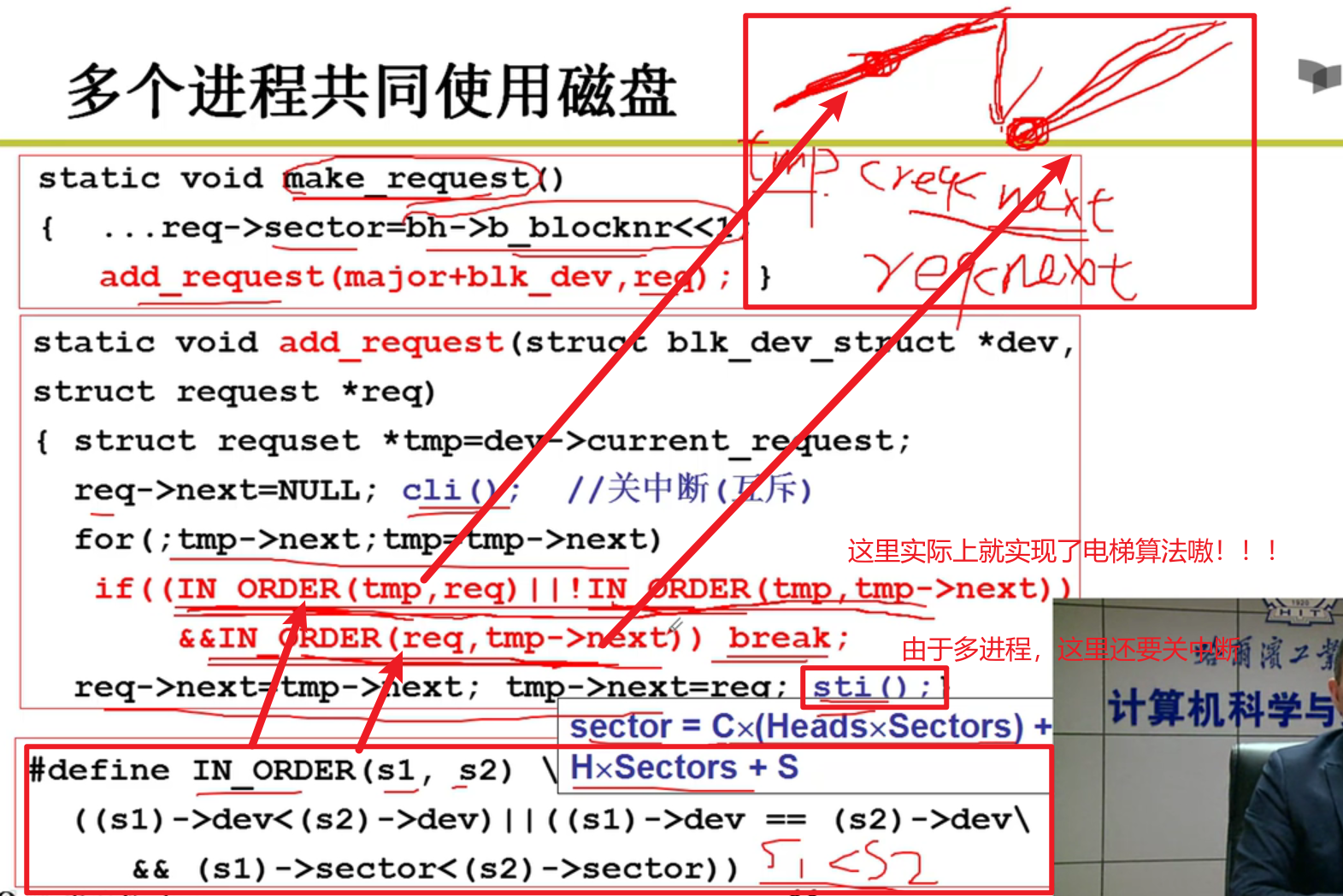
多个磁盘共同使用磁盘要产生请求放在请求队列中,然后在磁盘中断的时候,从请求中取出内容,换算为CHS,再发给磁盘控制器嗷!!!
- 使用整理:

从生磁盘到文件:
- 对于磁盘使用的第三层抽象:
- 文件
- 用户眼里的文件是什么样子?
- 文件本身就是一堆字符序列而已(字符流)
- 磁盘上的文件无非就是建立一个从字符流到盘块的映射嗷!!!(从文件得到盘块号)
- 示意图:
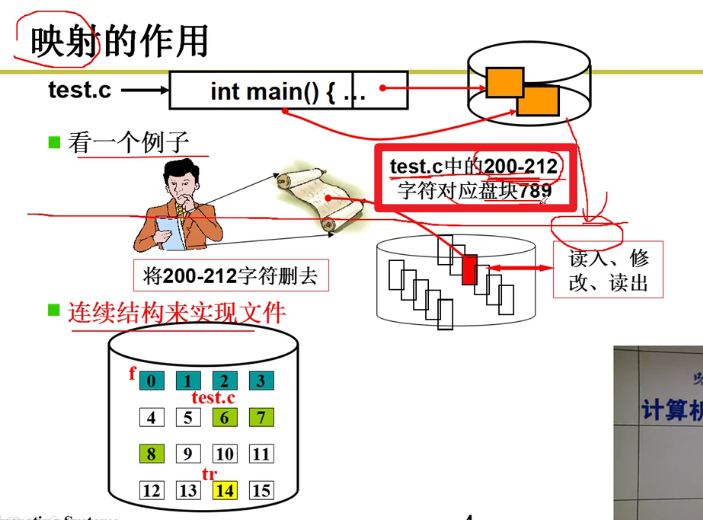
操作系统会从200-212帮助我们找到对应的盘块,然后修改其中的内容,再写回盘块中嗷!!!
连续结构存放文件需要存放什么?第一块儿的块号,存在FCB中,File Control Block。这个东西只要给了计算机,计算机根据你修改的位置,除以每一个盘块的默认大小,就知道具体的偏移量,这个时候我们只要直到起始位置,就能定位到磁盘上的对应位置!!!因此FCB中只要提供初始盘块号就行嗷!!!
文件 -> 表 -> 盘块号(抽象实质)
再思考?连续可行吗?不可行,类似于word,越来越多,万一没空间了呢?(整块儿重新分配再挪动,非常耗时orz),或者没有连续的地址空间分配怎么办呢?
链式结构!!!
- 如果一个连一个呢?非常麻烦,一个一个找也太惨了orz。
索引架构(Index,Inode的思想)
- 索引结构下的映射表:
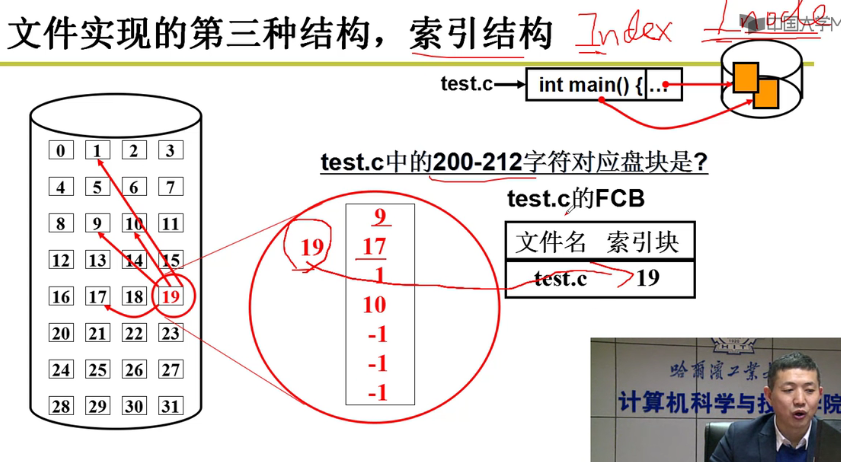
- 把索引放一起,就很方便嗷!!!
- 把inode中的文件对应的索引块填入FCB中,非常方便嗷!!!
多级索引(实际系统中使用的!!!)
Inode结点嗷!!!
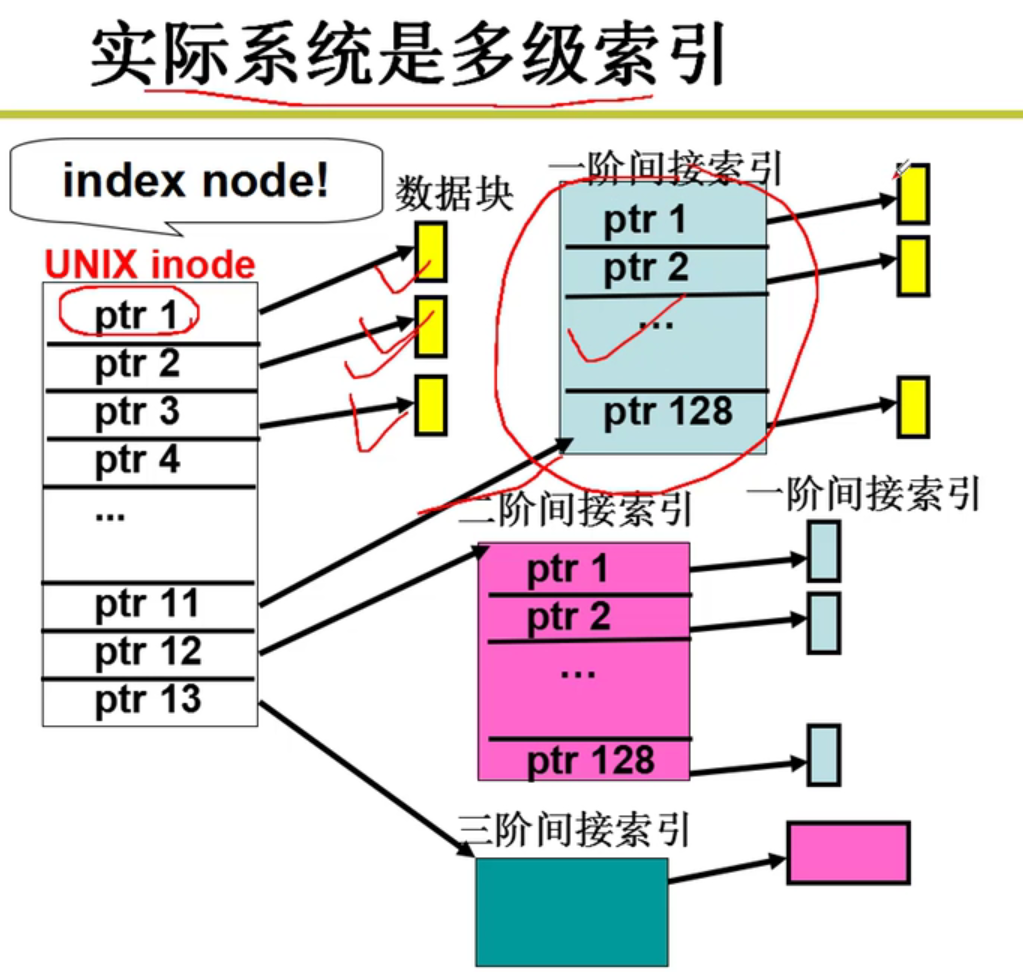
注意一下,这个Inode结点指向的黄色的都是实际上的盘块号嗷!!!
非常机智的做法,非常灵活嗷!!!

- 题目:

由于词霸中的内容固定的,如果采用索引,还需要用额外的空间来存储索引,索引还需要时间,肯定没有顺序快啊!!!顺序其实是最快的,链式是顺序失效的情况下,较为有效的管理方法嗷,索引,inode都是为了提高索引的效率,减少索引的次数,但是本质上,顺序就访问了一次内存,还不需要多余的空间,当然是最好的嗷!!!!!
文件使用磁盘的实现:
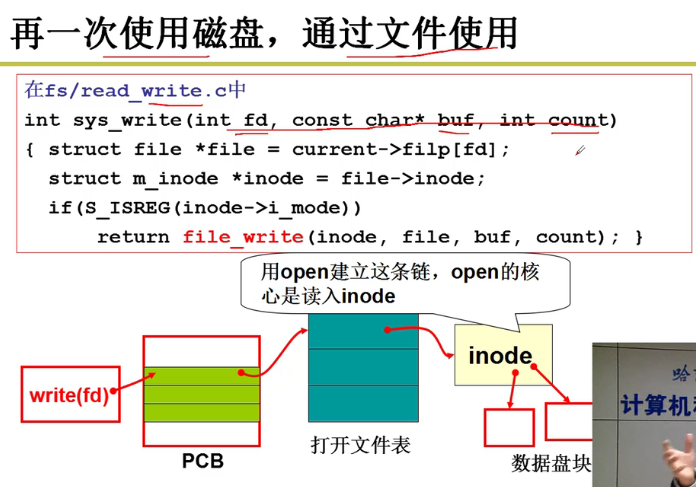
fd文件描述符 -> file_write到inode中嗷!!!
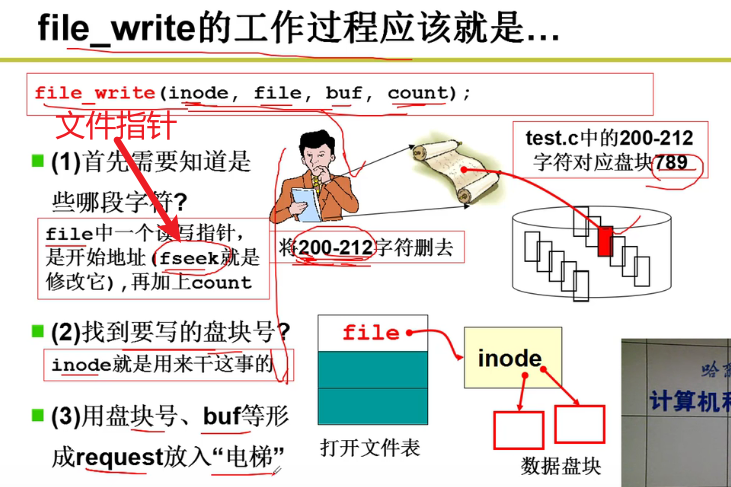
- file_write的实现:

- 算出盘块号:

找到了对应的盘块号之后,就返回block,再对于block进行读写嗷!!!
- 不同的i_mode:

如果是磁盘对应的话,我们就会拿磁盘进行操作。如果是其他的话,就会有不同的文件处理方式嗷!!!
- 整个故事:
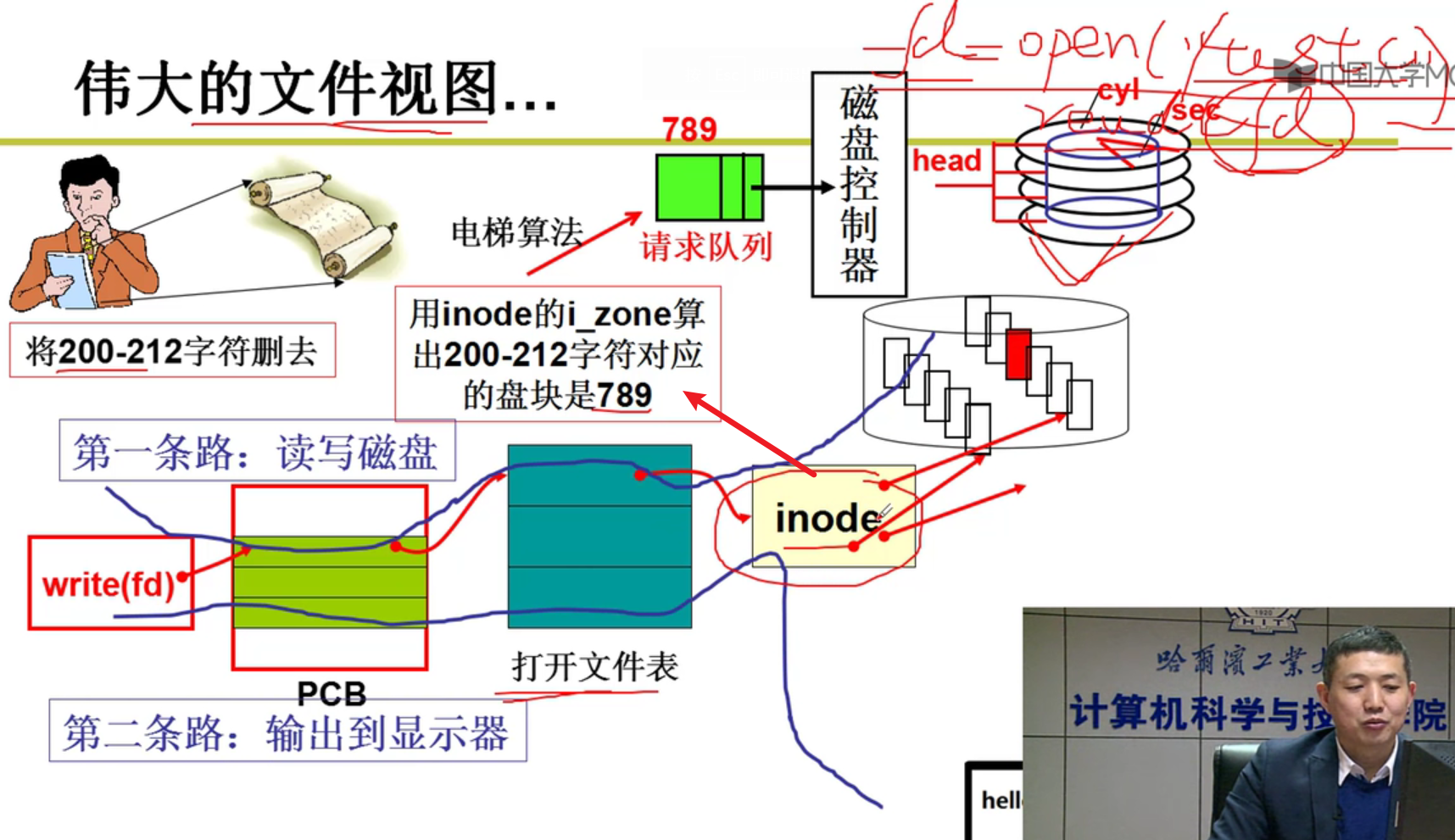
第六章(文件系统):
目录与文件系统:
第四层的抽象(抽象整个磁盘为文件系统)
故事的开始:
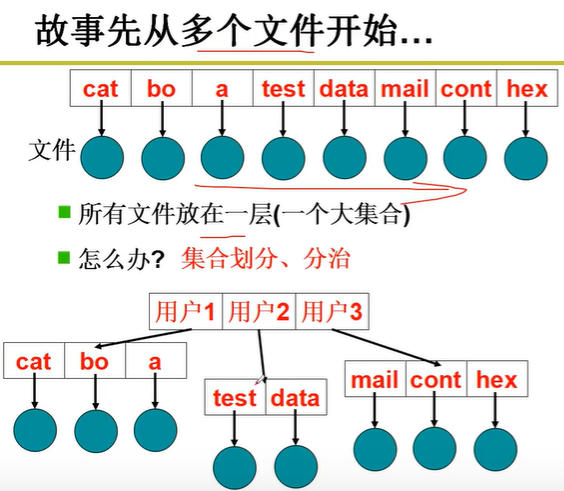
目录树是典型的分治,如果K次划分,每个集合中的文件数为O(logkN)嗷!!!树状结构拓展性好,非常清晰,最常用嗷!!!
目录:文件结合,实现目录成为了关键问题!!!
说白了就是对于FCB进行了一个管理嘛,给我一个路径,我就能够得到文件的FCB,得到inode,就能够操纵磁盘了嗷!!!
目录中应该有什么?
- 本质上也是一个文件嗷!!!
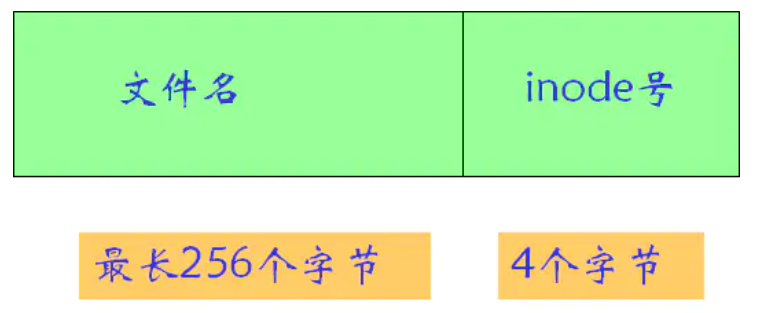
- 目录中存放其中所有文件的FCB信息,这不就找到了所有的文件吗?可以吗?可以!高效吗?不高效,一一匹配效率高吗???!!!
- 目录中实际上应该存放文件的名字(用于匹配文件),匹配上之后,我要能够找到FCB(存放FCB的指针呗!!!,这里的指针本质上是对应的磁盘中的某个盘块嗷!!!)
存放模型:
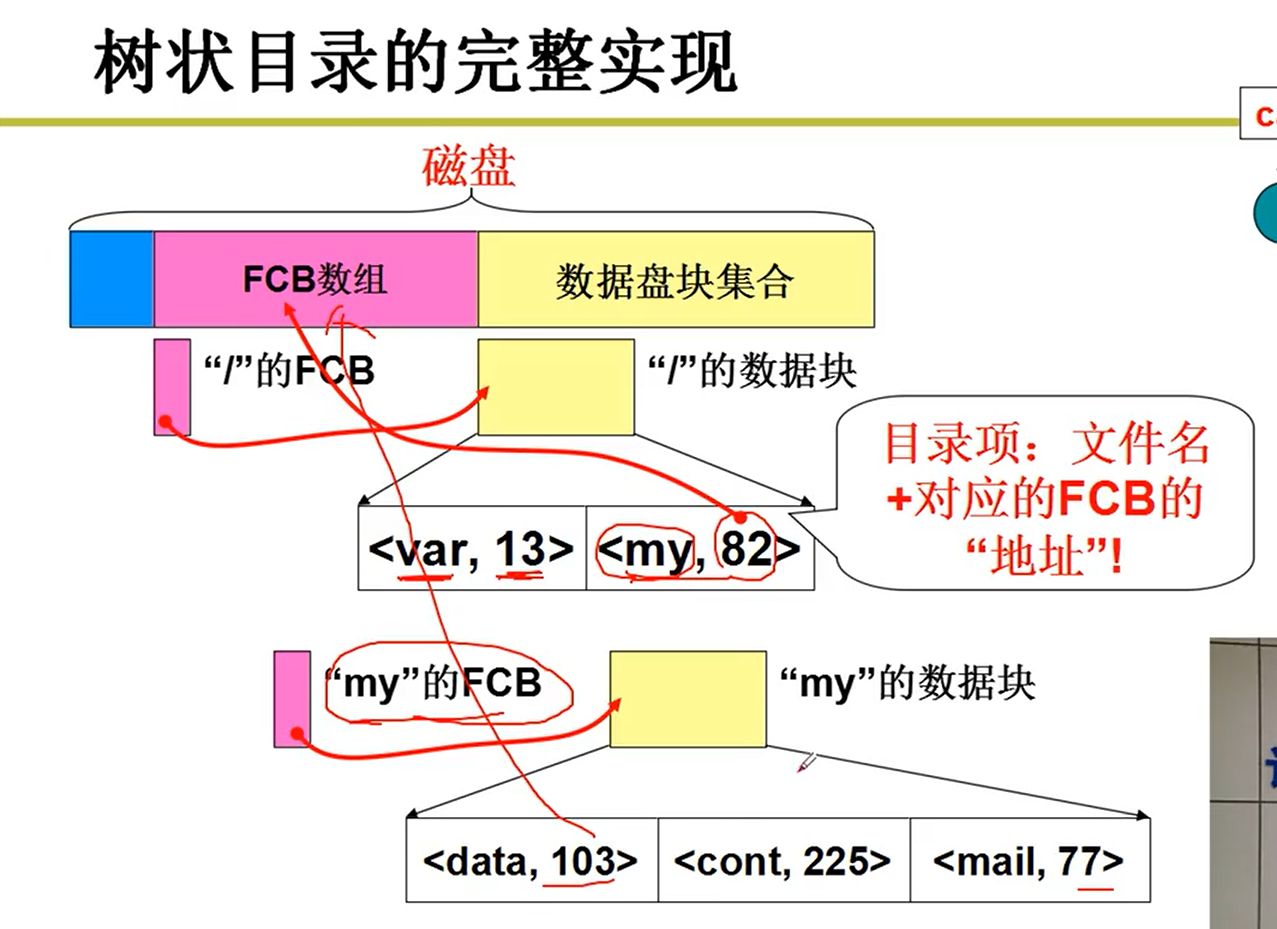
可以看出来,粉红色的就是根目录,根目录中存放的就是默认第一层下的一些数据信息嗷!!!
- 那文件系统的根目录存在哪里呢?

磁盘的mount实际上就是把超级块读进来,把根目录mount进来嗷!!!根据根目录,就能够读取到下一层的目录,并且继续向下索引到我们需要的文件嗷!!!
- 整体流程:
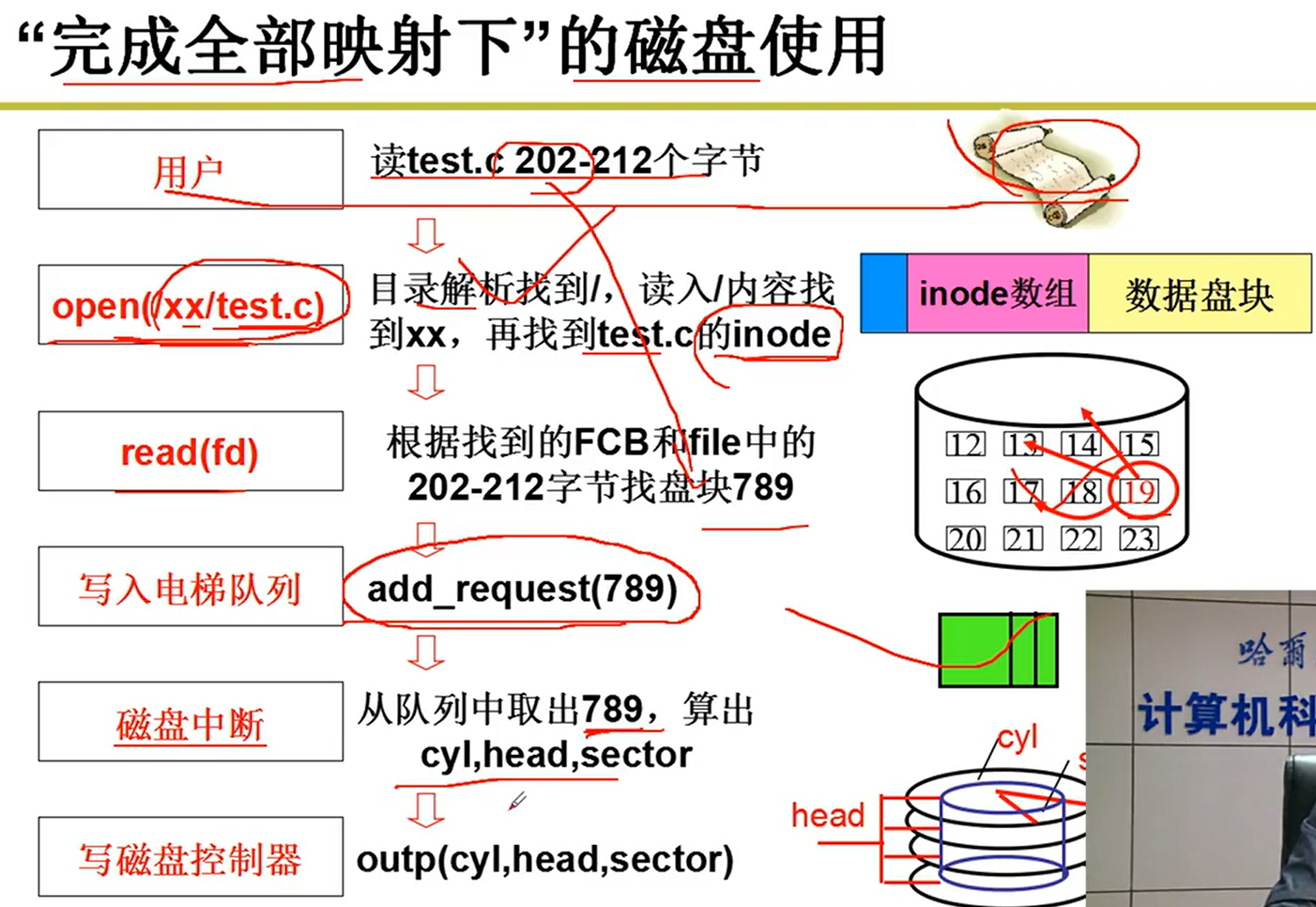
目录解析代码实现:
- 将open弄明白嗷!!!
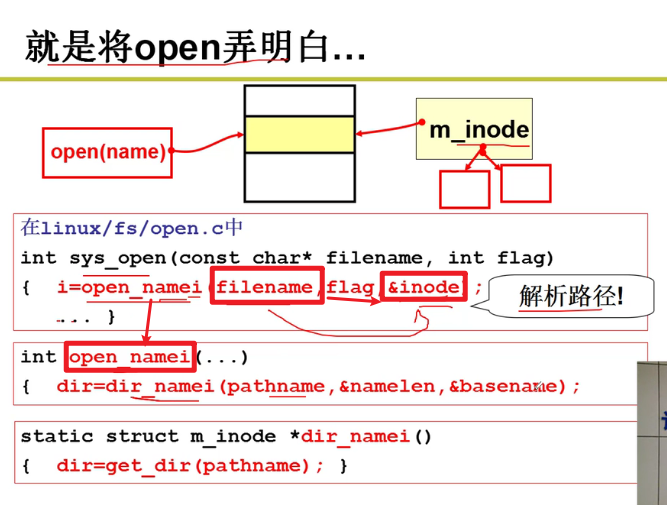
- get_dir

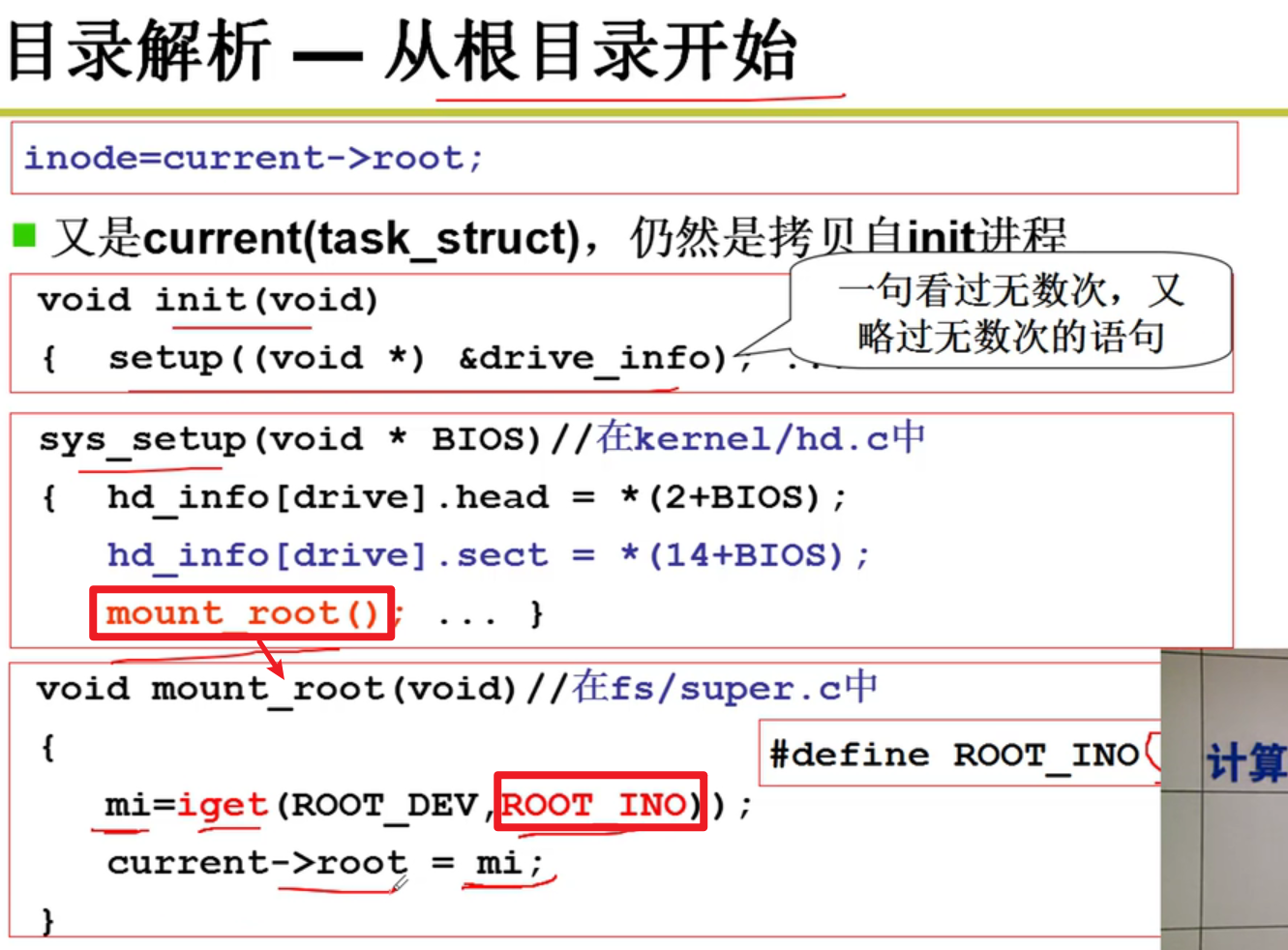
current -> root是从前面自举的过程中就初始话好了的嗷!!!
- 目录解析 – 从根目录开始
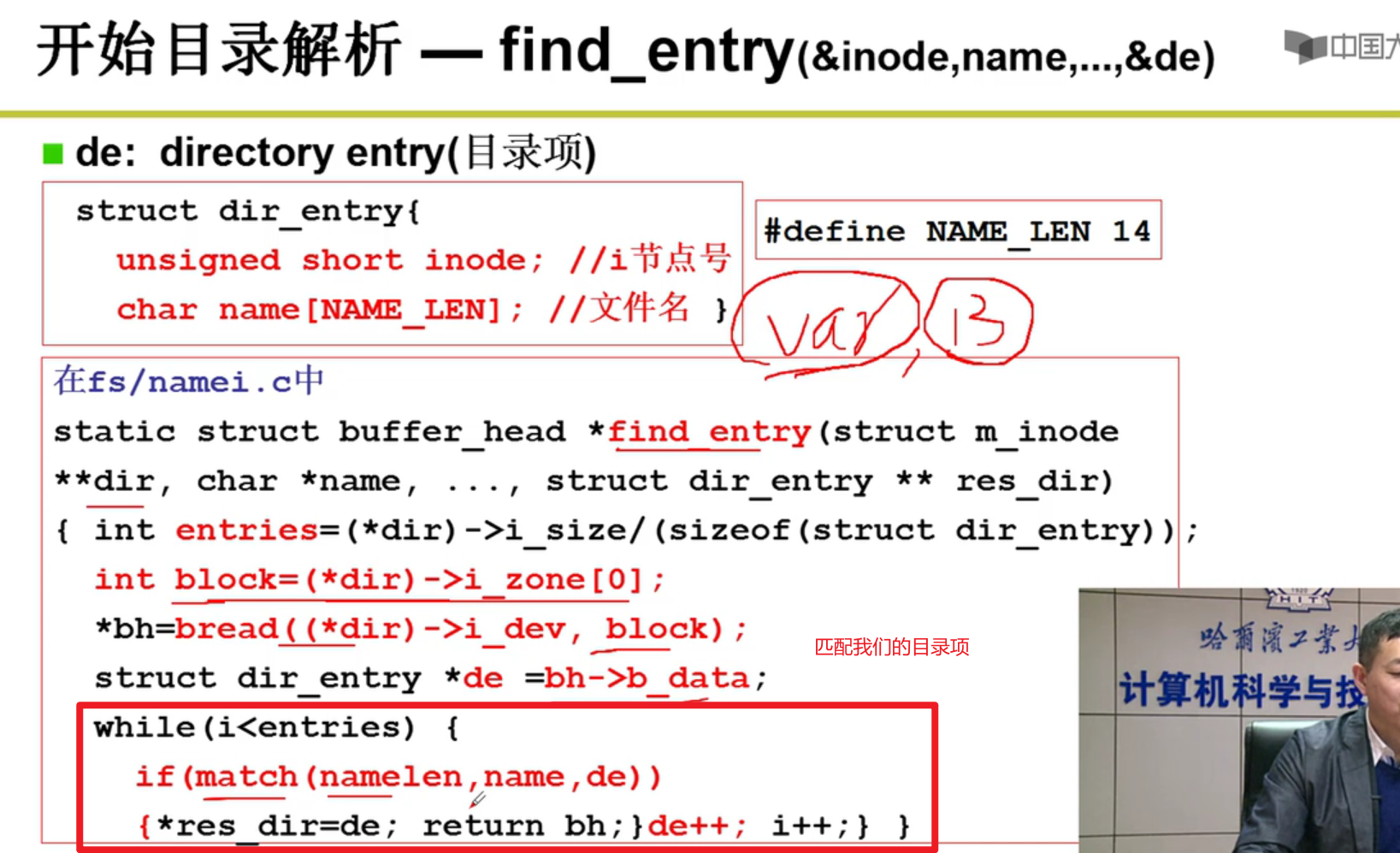
- iget函数:

- find_entry:找到目录项

过程:
- 根据超级块和引导块的大小,找到根目录的inode所在的盘块的位置。使用iget函数,将对应的盘块中的内容读取出来。(根的inode)
- 根据FCB(inode),读取出对应的内容,将接下来的目录和读取出来的文件内容进行比对,一直while,直到找到你需要的文件嗷!!!
FCB中存储的就是当前结点的名字和其对应的inode结点所对应的盘块,读取到了inode之后,根据inode就能够找到根目录中对应的内容。
操作系统整体轮廓:
- 多进程视图,交替进行,使CPU充分忙碌
- 内存管理
- 外设管理
- 磁盘管理 -> 文件系统