Java常问面试题总结与提高
本文最后更新于:3 年前
Java高频考点


1. 局部变量表和计算栈
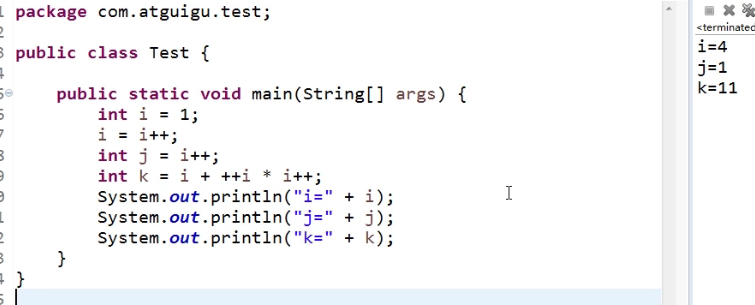
- 知识点在于栈,局部变量表等东西的操作嗷,类似于Println和符号运算这样的操作。本质上,都是先把操作数放在栈里面,然后对于栈里面的数字进行操作的。
- 然后就是++这样的操作,在前在后,对于局部变量表操作和栈操作的顺序是不一样的嗷!!!
2. Singleton示例
单例,系统中只有一个实例对象可以被获取和使用的代码模式。例如JVM运行环境中的Runtime类
要点:
某个类只能由一个实例
- 构造器私有化
必须自行创建这个实例
- 静态变量来保证实例唯一
必须向整个系统提供这个实例
- 向整个系统提供这个实例:
- 直接暴露
- 静态变量的get方法获取
创建类型:
- 饿汉式:
- 直接实例化饿汉式
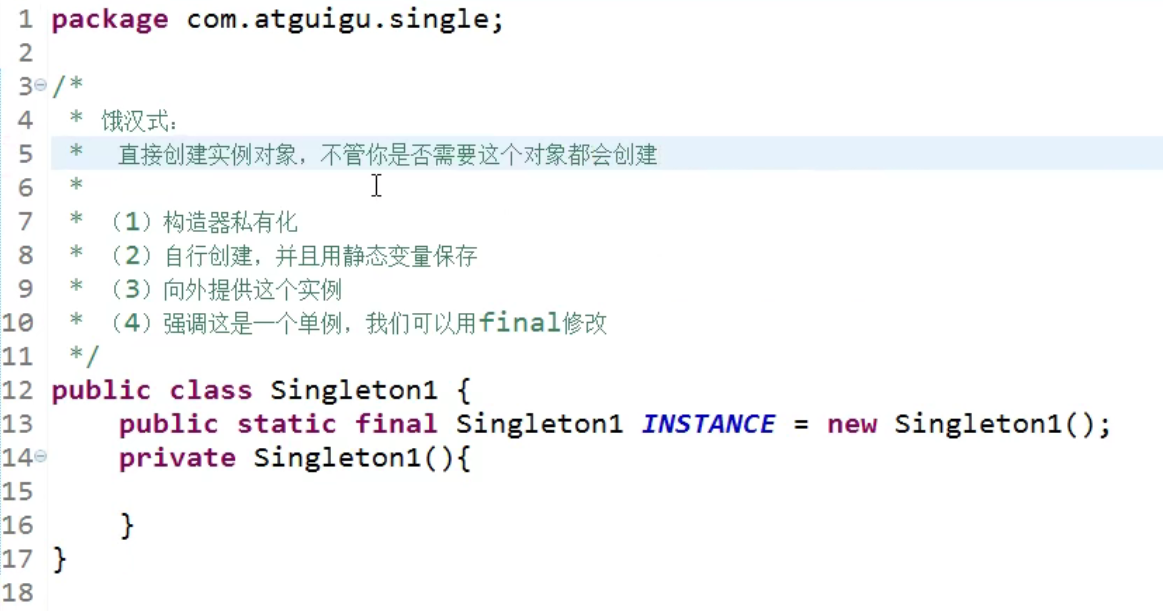
获取这个对象:
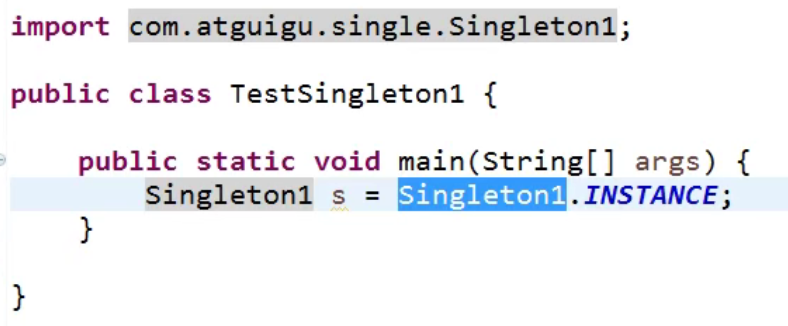
- JDK1.5之后,枚举类型:
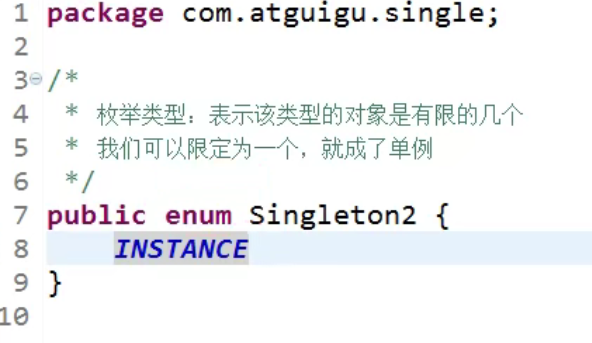
获取这个对象:
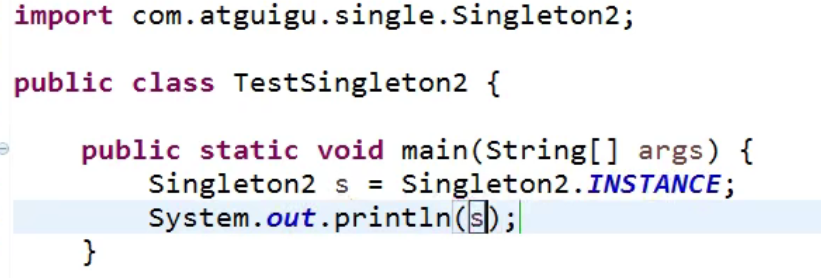
枚举类型会帮助我们重写String方法嗷!
- 静态代码块的方式:
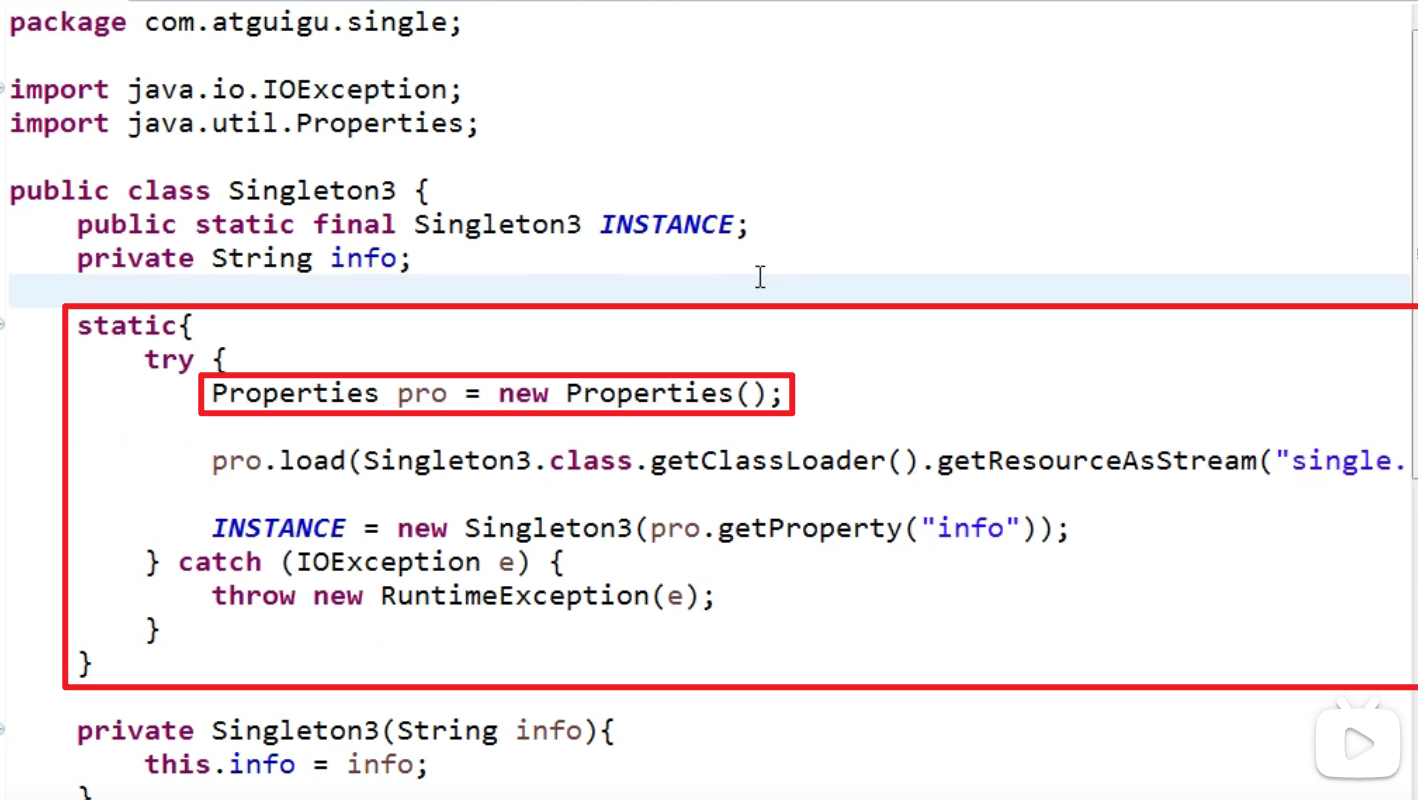
类初始化的时候new处对象,保证对象只在初始化的时候创建一次嗷!!!
- 懒汉式:
3. volatile:
volatile是什么
- 轻量级的同步机制
- 特性:
- 保证可见性
- 不保证原子性
- 禁止指令重排
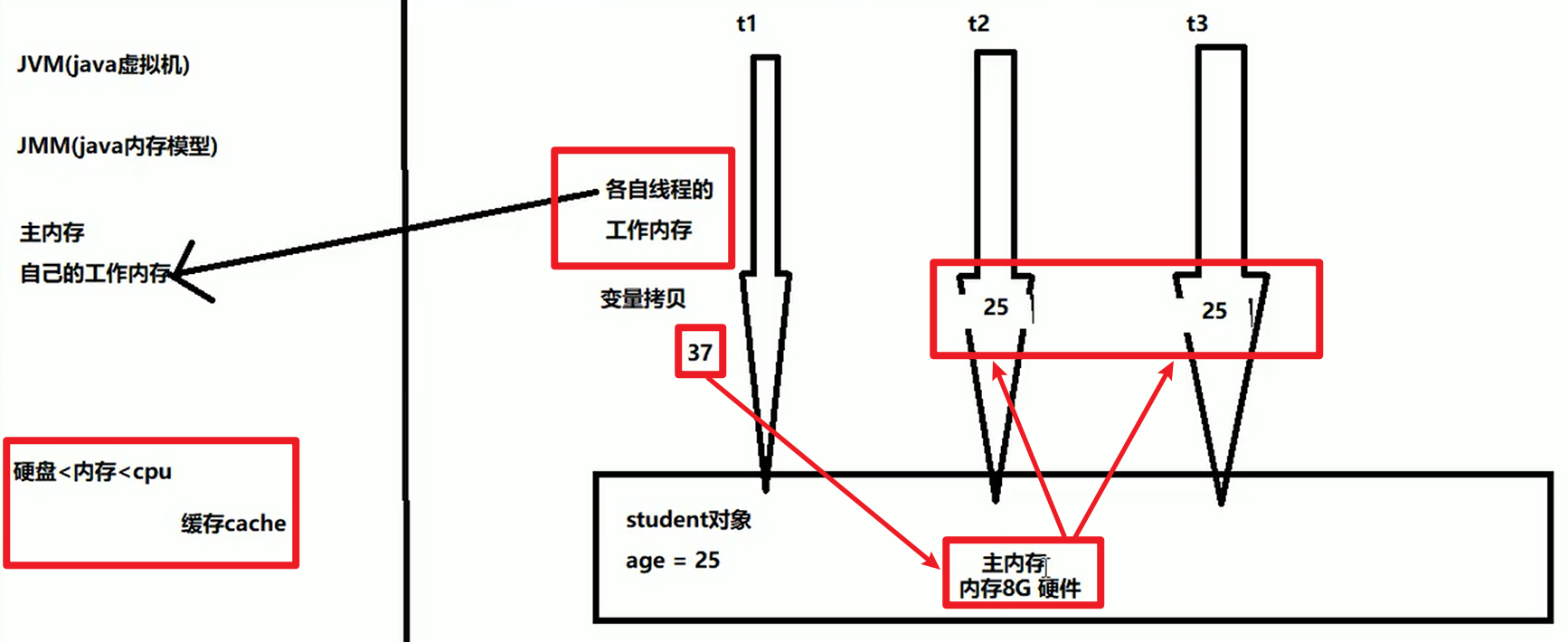
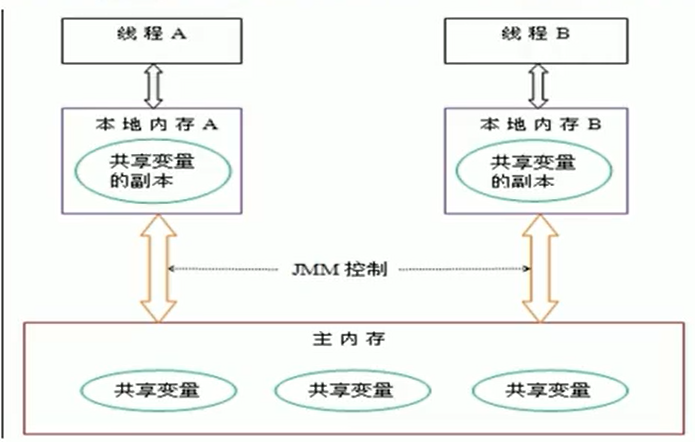
JMM:
- JVM(Java虚拟机)
- JMM(Java内存模型):
- 并不真实存在,描述的是一组规则或规范
- 几个概念:
- 主内存:
- 共享内存区域,所有线程都可以访问嗷!
- 工作内存:
- 每个线程私有的工作内存空间
- 主内存:
- 各自线程的工作内存会拷贝主内存中对应的数据,然后各自对于数据进行修改,修改完成之后,才会尝试将数据写回主物理内存。
- 只有在工作内存才能够对于变量进行修改嗷!!!不同的线程是不能够访问对方的工作内存嗷!!!工作内存的结果需要写回主内存之后,才能够真正的生效嗷!!!
可见性定义:
- 一个线程对于数据进行了修改并且写回了主内存之后,其他的线程要马上能够知道嗷!!!只要有变动,大家都要立马知道嗷!!!
- 第一时间通知到所有线程的过程,这个就叫做可见性。
原子性:
Volatile特性:

可见性:
1 | |
1 | |
- 没有volatile就没有多线程的可见性嗷!!!
- 然后你发现不得行!!!主线程仍然是卡住的,因为没有任何线程来通知主线程,这个值发生了改变,主线程自己的工作空间中的值,是没有变化的嗷!!!(默认是没有可见性的嗷!!!)
- 如何实现可见性呢?Volatile!!!
1 | |
- 测试和上面的代码是一样的嗷!!!然后发现,volatile其实就是起到了及时通知main线程,某个变量发生了改变的作用。
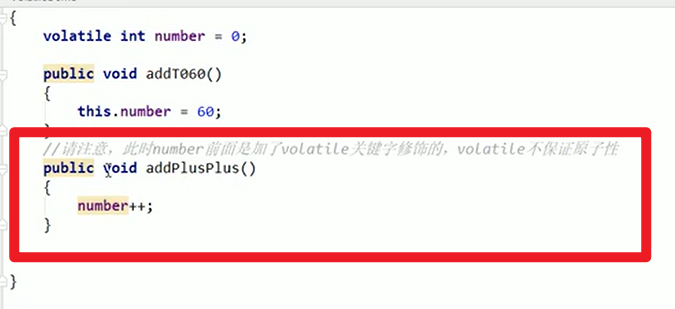
不保证原子性:
- 原子性是什么?
- 不可分割,完整性,也即某个线程不能被分割,要整体完成,要么同时成功,要么同时失败。
- 例子:
valatile i
public methodPlus(){i++}
然后启动多个线程来同时操作(也就是常见的i++的例子)
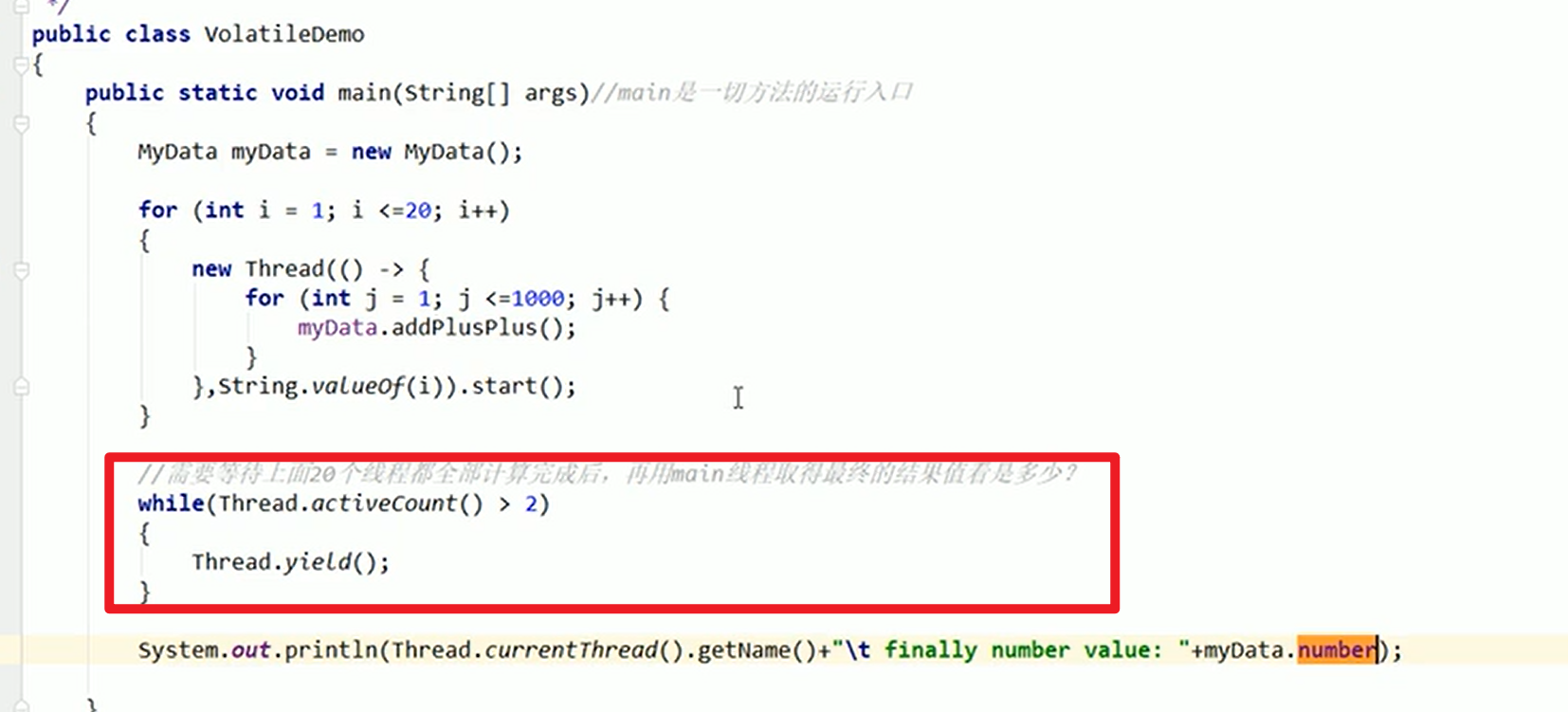
结果不是20000嗷!!!
- 原理解释:
- 可以在方法上加上sychronized吗?
- 可以,可以保证20000
- 但是不好,效率消耗太大了嗷!!!
- 可以在方法上加上sychronized吗?
- 为啥会<2000呀!!!
多线程的调度出问题了嗷!!!
A和B同时读入了0,同时加1。A写入1,还没来得及通知别的线程,B就再次被调度写入了1,这就出问题了orz,就会导致这种情况的出现嗷!!!
- 字节码:
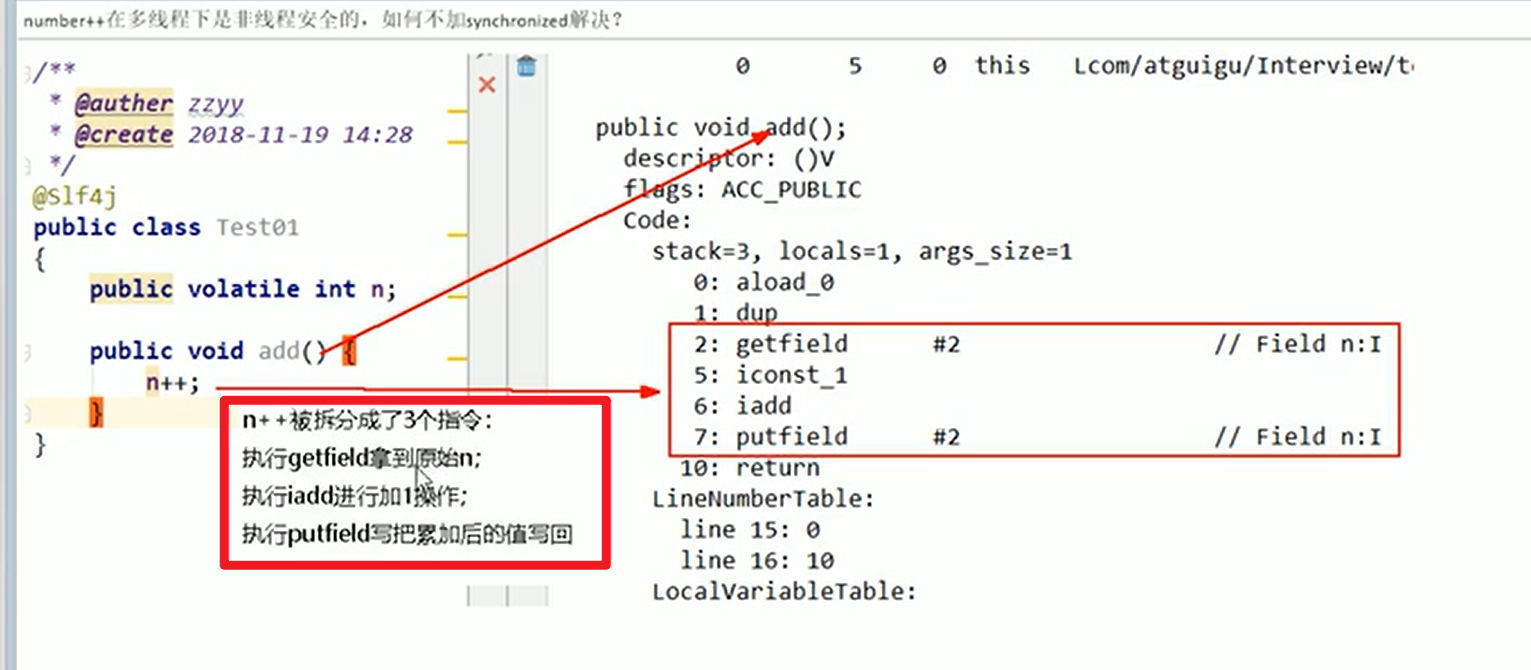
如何解决原子性:
- 加入sync,太重了,不用这个
AutomicInteger automicInteger = new AutomicInteger();
用法的话,建议去看看官方文档中怎么写的嗷!!!

说白了底层为CAS,比起volatile来说,还是加了个轻量级锁orz。
禁止指令重排:
- 多线程:
- 重排:

- 处理器在进行重排序的时候必须要考虑指令之间的数据依赖性
- 由于数据依赖性,指令重排也要考虑数据依赖性哈!!!volatile来决定嗷!!!
- 指令重排多线程下出现,这个重排是客观存在的,两个线程中使用的变量能够保证一致性嗷!!!避免指令重排优化,从而避免多线程环境下程序出现乱序执行的情况。

- 指令屏障(保证禁止指令重排嗷!!!):
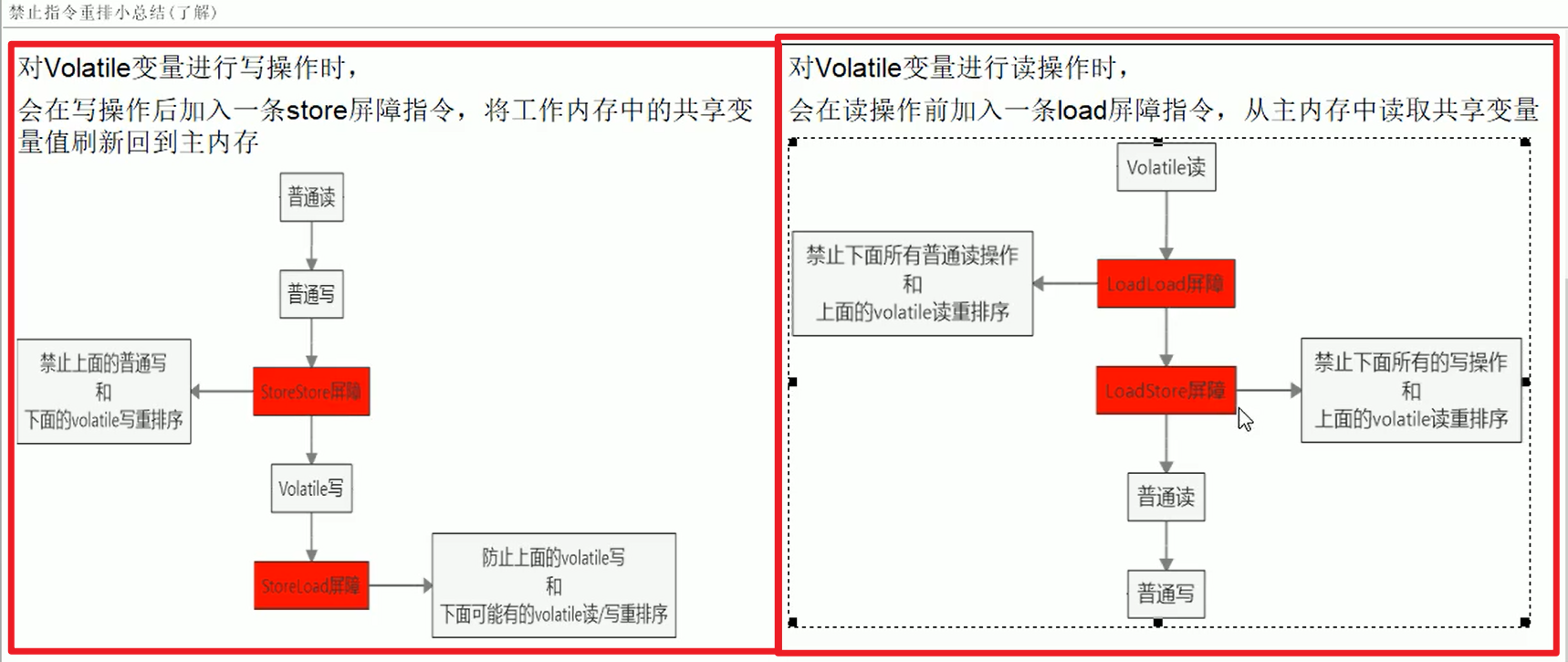
禁止指令重排嗷!!!保证了安全性嗷!!!
- volatile的特点:
- 可见性(强制刷出各种CPU的缓存数据嗷!!!)
- 禁止指令重排
什么时候用Volatile:
单例模式:
- 单例模式!!!本来是不用volatile的,但是当单线程 -> 多线程的时候,就会出问题了嗷orz
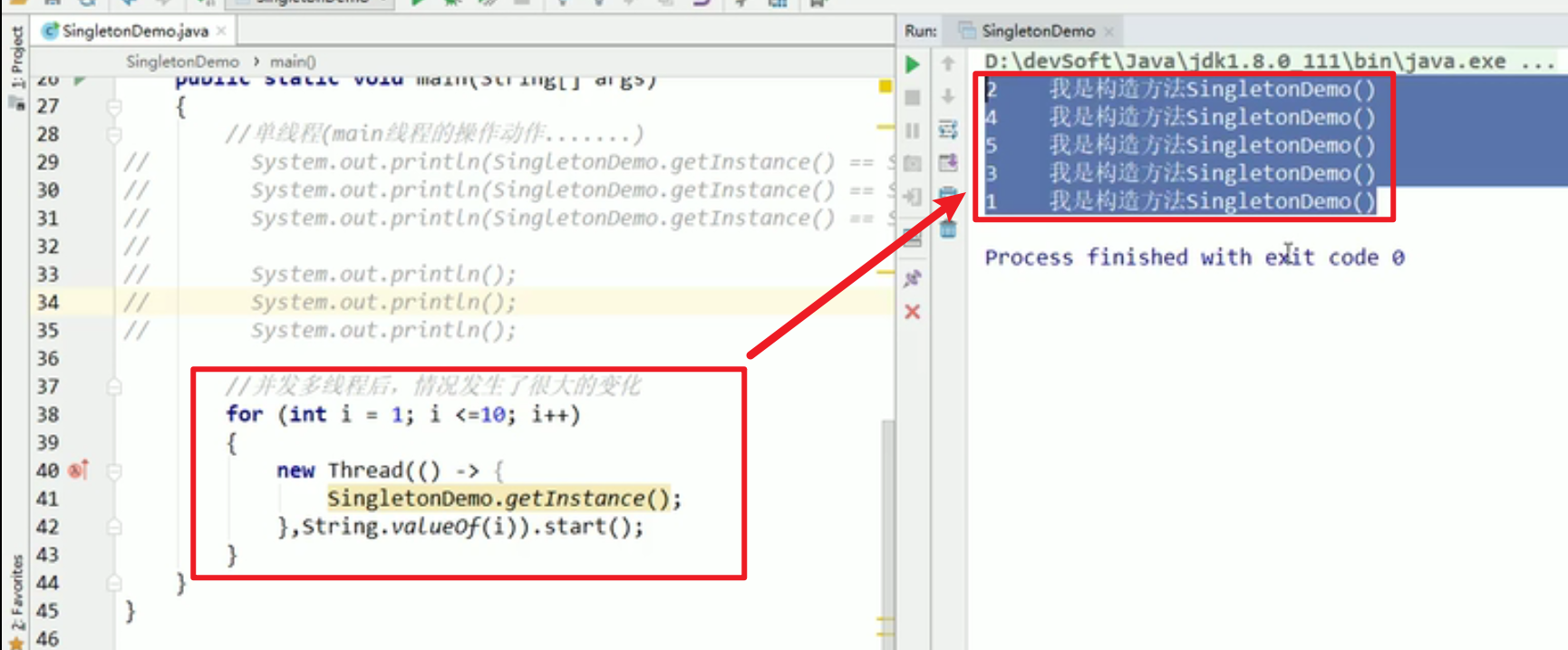
- 解决方法:
- getInstance方法前面加上synchronized,没有问题嗷!!!可以正常执行嗷!!!
- 但是太重了orz
DCL模式:
- Double Check Lock,双端检锁机制。

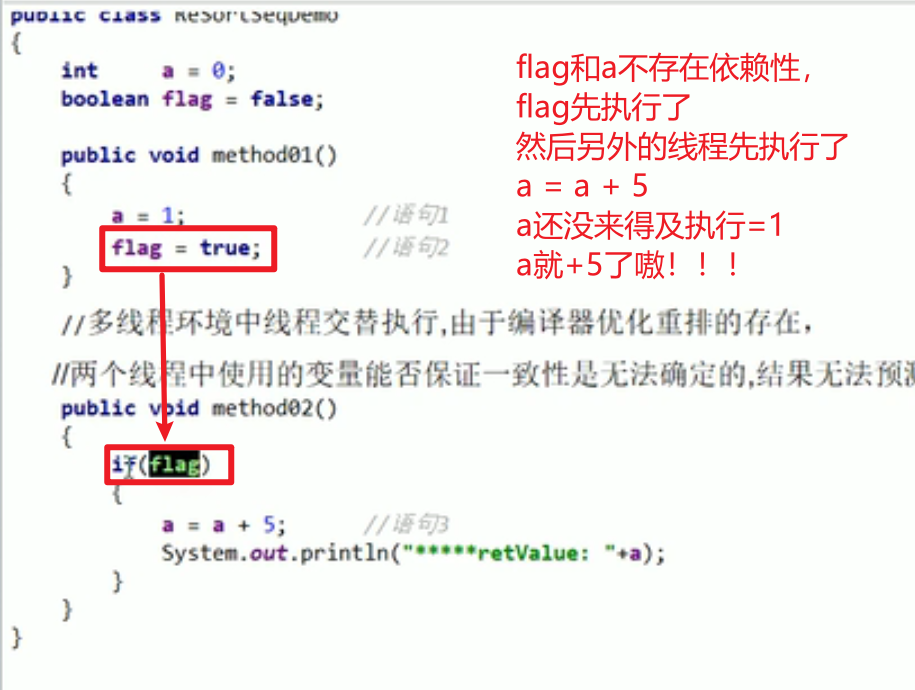
对吗?不对!!!多线程,为了指令的效果,会指令重排!!!
- DCL不一定安全,指令重排!!!

这个时候就可能取到null嗷!!!
- 指令重排只保证单线程情况下的指令一致性,多线程则不保证嗷!!!
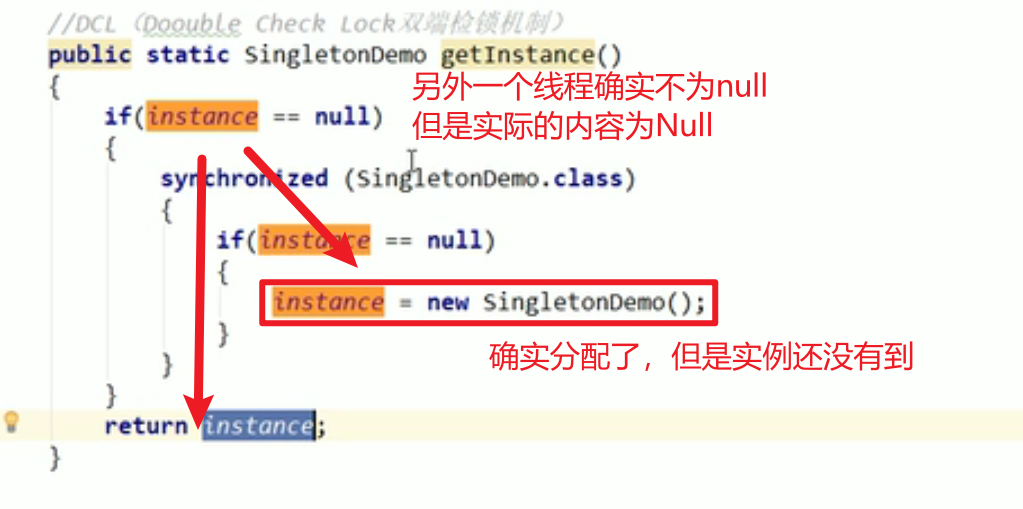
- 禁止指令重排:
public static volatile SingletonDemo instance = null;
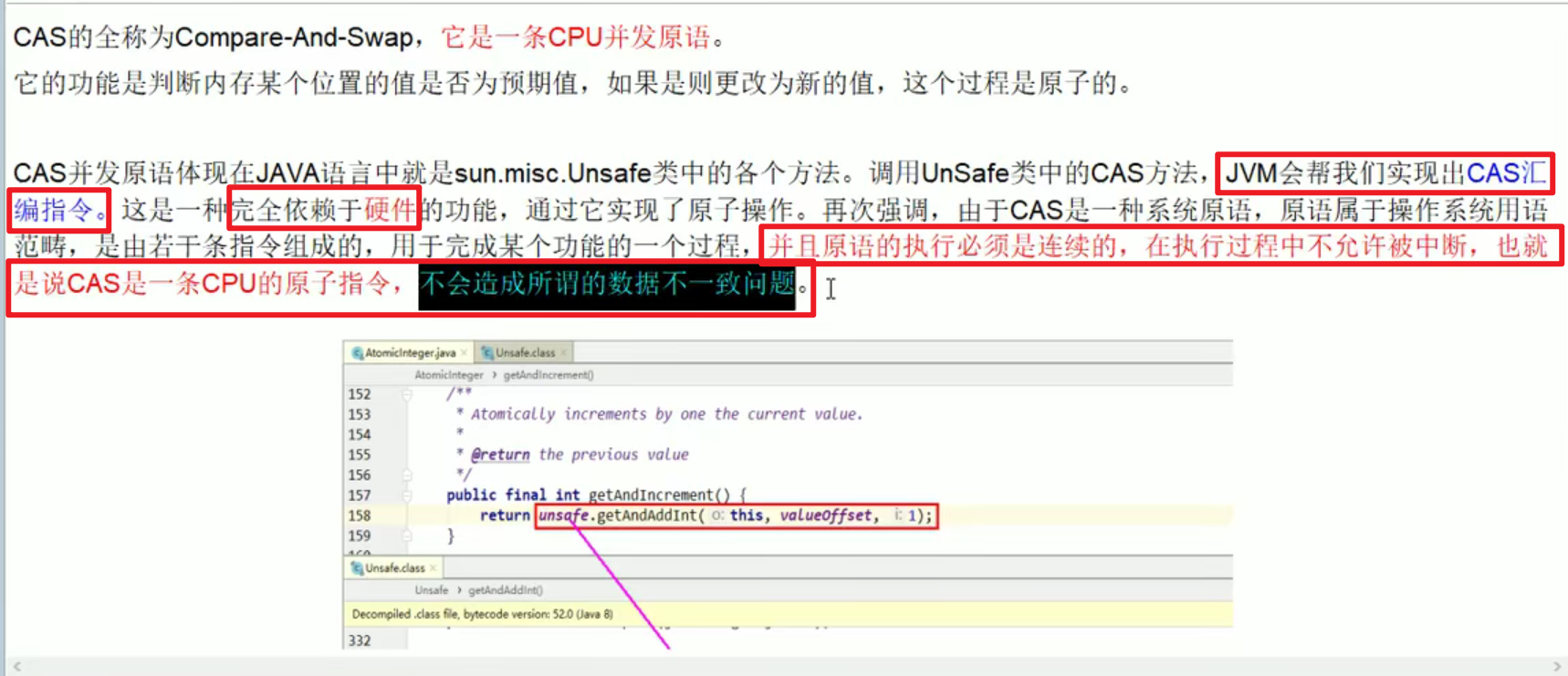
4. CAS:
- Compare And Set,比较并且交换
- Synchronized太重了,CAS就比synchronized轻量哦!!!
- 例如AutomicInteger ,
compareAndSet(expect , update)
底层原理:
- why CAS not Synchronized?底层原理:
- 自旋锁
- Unsafe
- getAndIncrement底层实现:
- 调用的JDK自带的unsafe类嗷!!!(都是底层的Native方法嗷!!!)

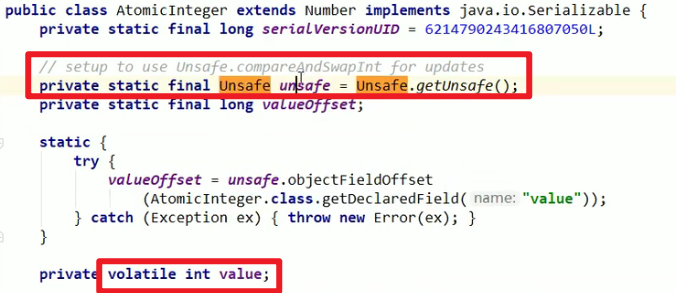
- Unsafe类:

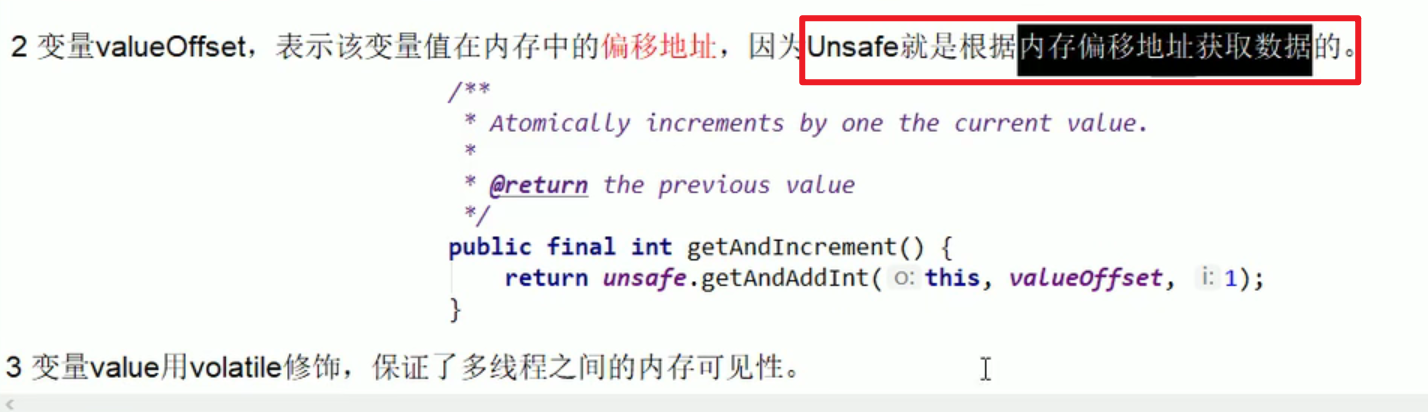
- getAndAddInt
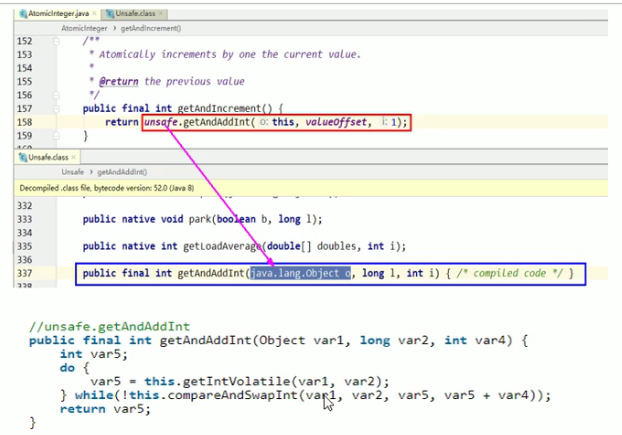
关键是底层的CAS的靠的是CPU的原子操作来实现的嗷!!!因此这样能够保证原子性嗷!!!读取,比较和设置一气呵成。不存在中间有线程特判比较的这种情况出现嗷!!!
- getAndIncrement:

- 原理:

Unsafe类+CAS思想(自旋)

缺点:
- 循环时间长,CPU开销大
- 只能保证一个变量的原子性操作,如果要一段代码,那就要synchronized嗷!!!
- 引出了ABA问题。
5. AtomicInteger的ABA问题:
- 原子引用更新 —>>> 如何规避ABA问题
- 狸猫换太子:
- 就是快速反复横跳,把值该到了,欸嘿,我又改回来了,吐了,慢的根本不知道嗷orz。
AutomicReference:
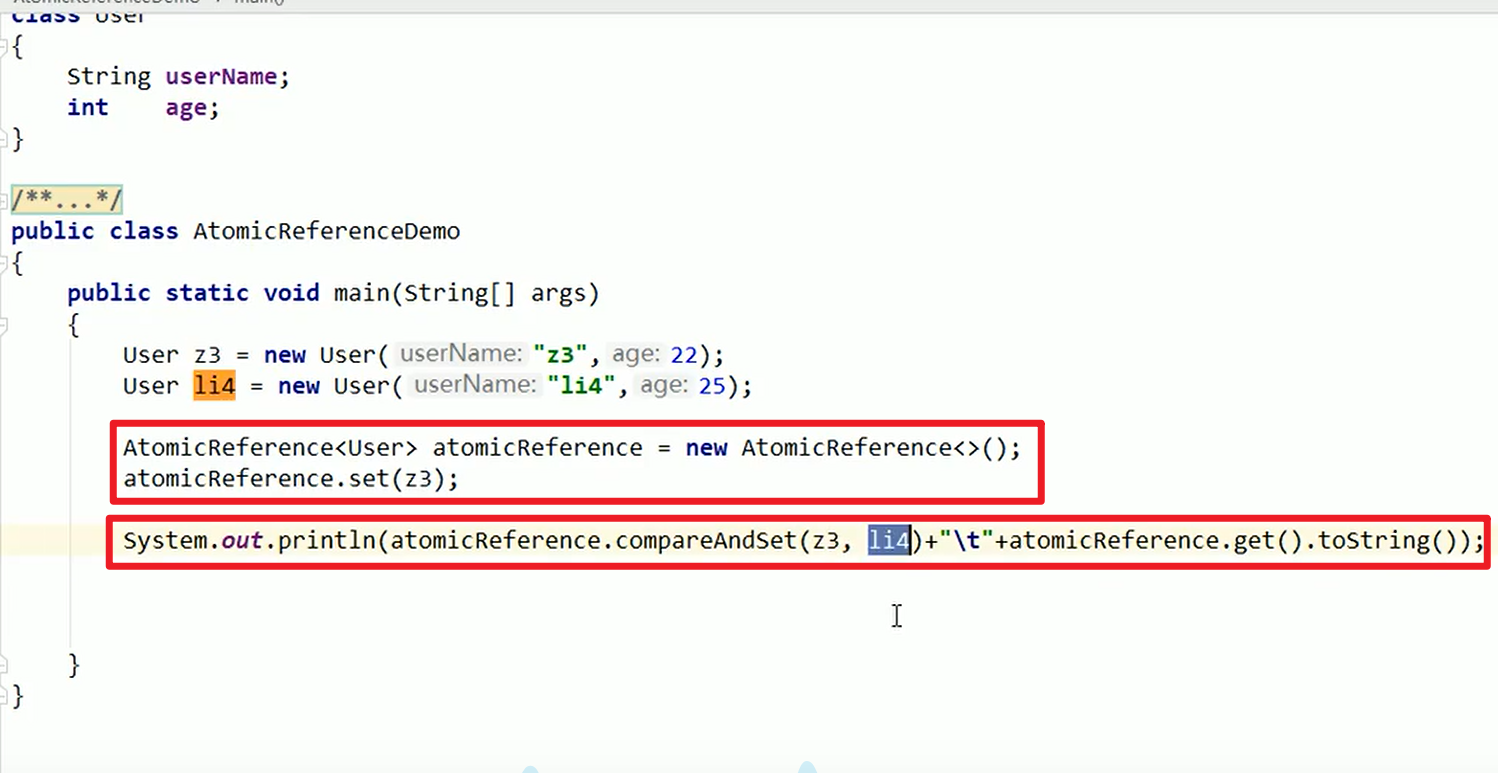
对于我们需要的类进行原子包装嗷!!!
时间戳的原子引用:
- 规避ABA问题:时间戳的原子引用
AtomicStampedReference

atomicStampedReference.compareAndSet(expectedReference , newReference , expectedStamp , newStamp)
常用用法:
boolean result = atomicStampedReference.compareAndSet(100 , 101 , automicStampedReference.getStamp() , automicStampedReference.getStamp()+1);
int stamp = atomicStampedReference.getStamp();
int result = atomicStampedReference.getReference();
相当于现在比较两个值了而已嘛,本质没啥区别
6. ArrayList线程不安全:
- 这里的名字不准确,应该是Collection类普遍不安全嗷!!!
写时复制:
- 扩容:默认的capacity是10,超过10了要扩容

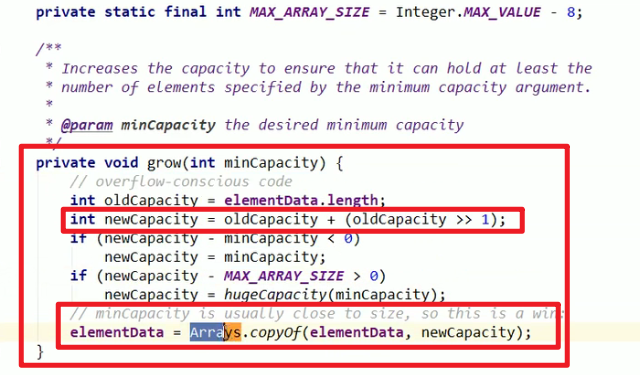
- 线程不安全!!!
ArrayList的add方法为了保证并发性和效率,没有加锁嗷!!!
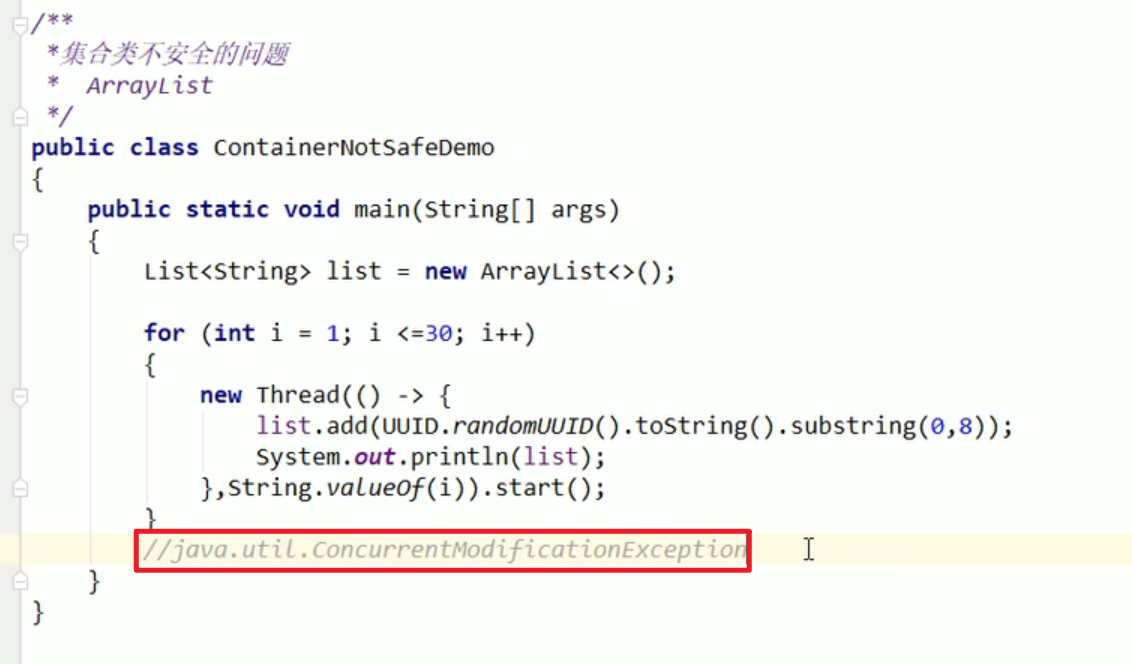
- 故障现象:
java.util.ConcurrentModificationException
- 导致原因:
并发争抢修改导致,两个进程抢着写的时候,造成了数据不一致的情况嗷!!!
CopyOnWrite , OnWrite的时候才Copy
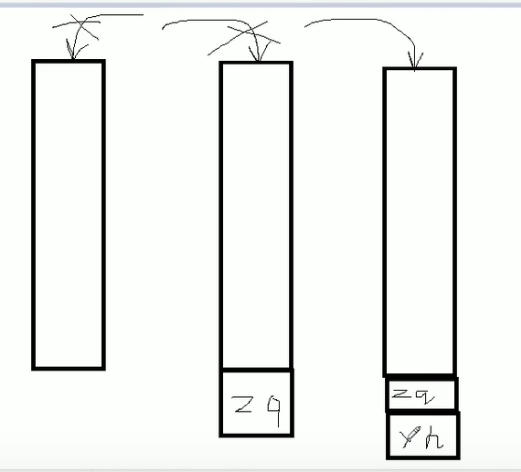
- 解决方案:
- 加锁!!!可以吗?不可以,JDK源码你加个锤子的锁???
- 3.1:用Vector类!!!
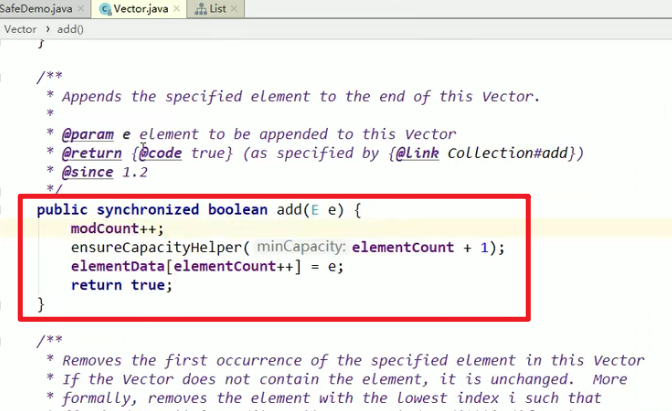
好使!!!但是太重了orz,而且Vector用的少orz,并发性低嗷orz。牺牲了安全性,提高了性能嗷!!!
3.2:Collection接口和Collections类!!!注意嗷,后面那个是类!!!Collections就是帮助我们来解决这个问题的嗷!!!
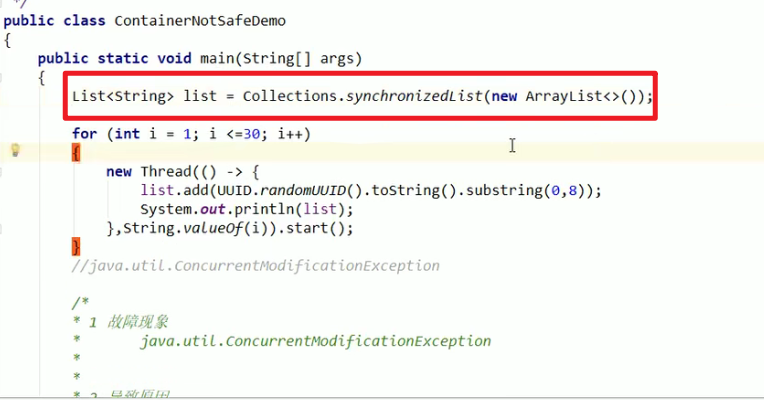
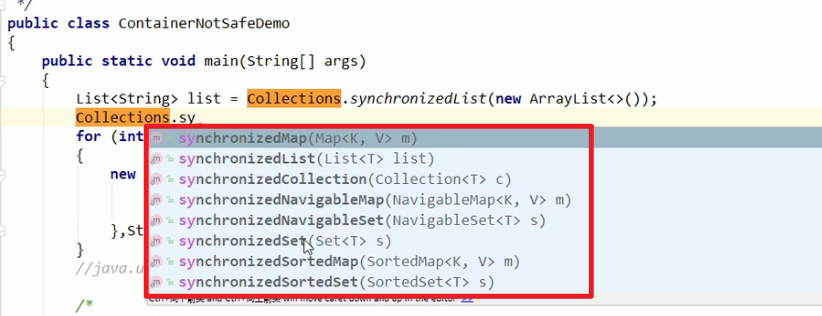
你设想一下,这里竟然有这么多Map , List , Set之类的,说明这些东西都是线程不安全的嗷!!!
- 3.3:CopyOnWriteArrayList
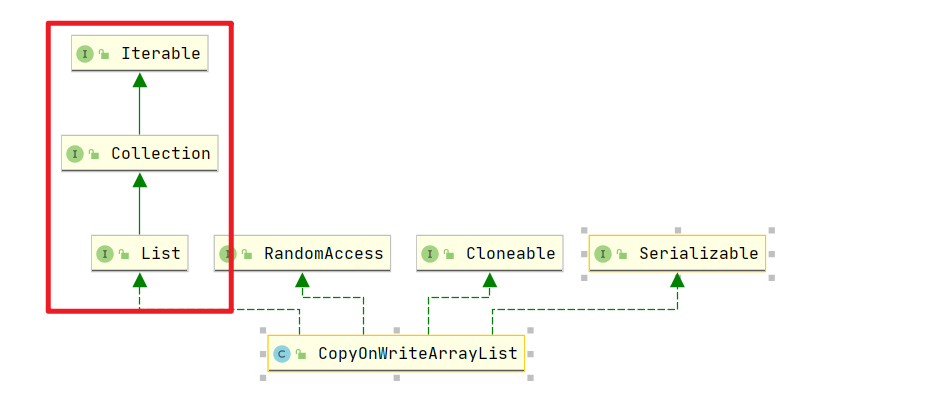
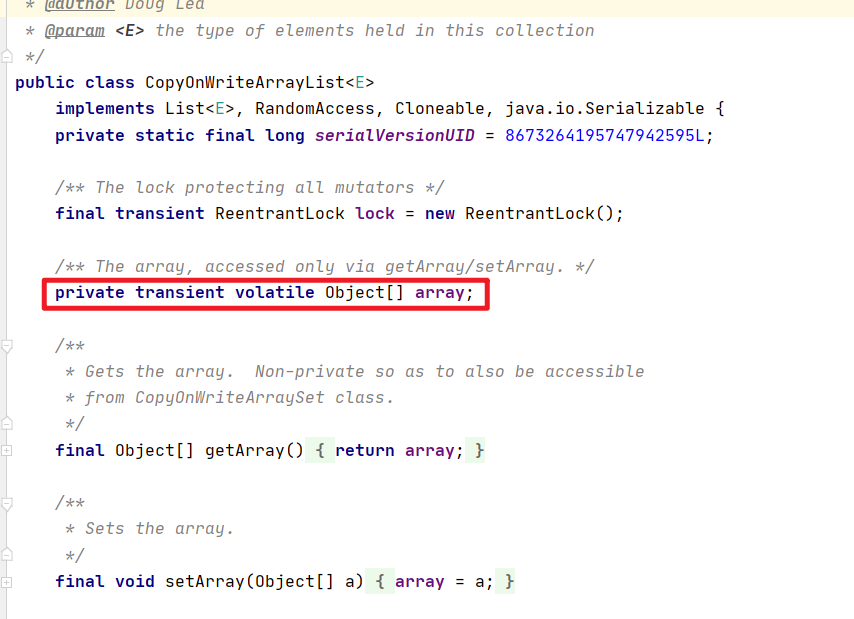
1 | |
- 老版本的copy出来,然后把自己的信息写进去,再让系统中的引用编程现在这个数组嗷!!!
- 优化建议:
HashSet线程不安全:
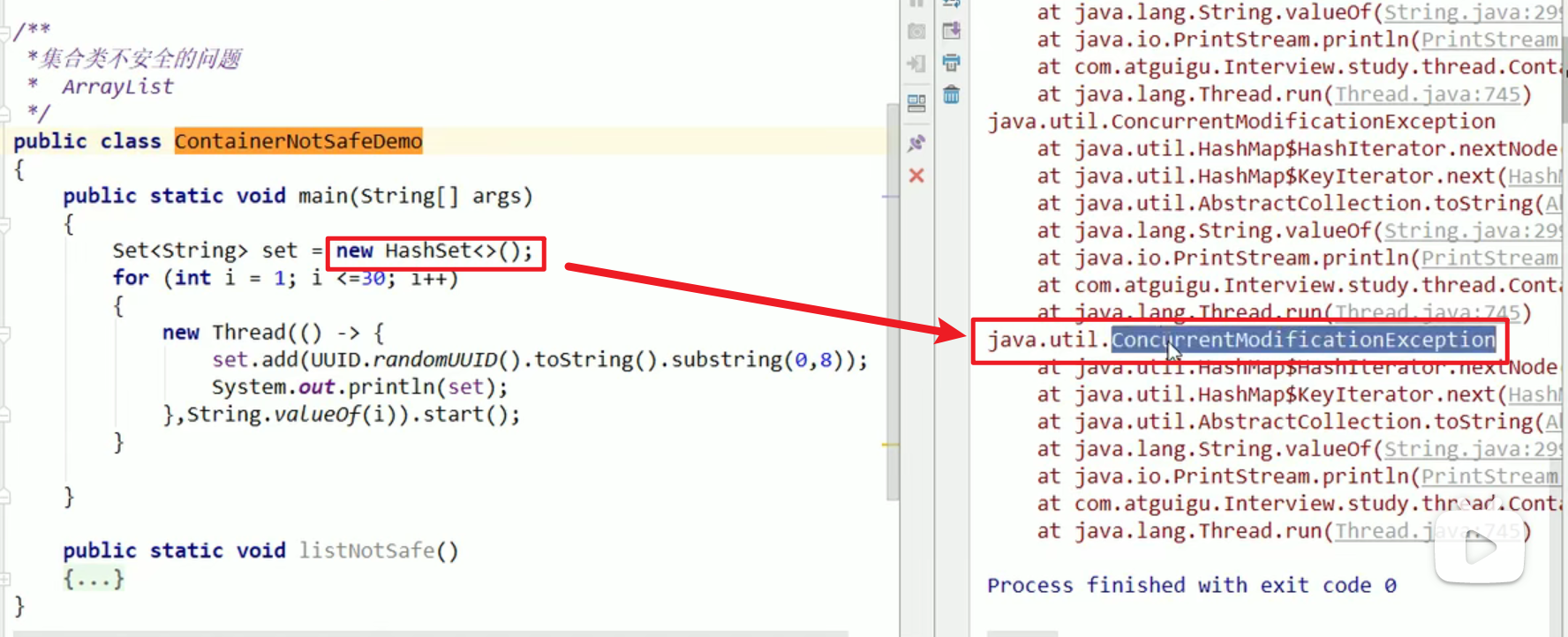
也是一样的问题嗷!!!
- 解决方法:
Collections.synchronizedSet(new HashSet<>());- JUC中的
CopyOnWriteSet<>()
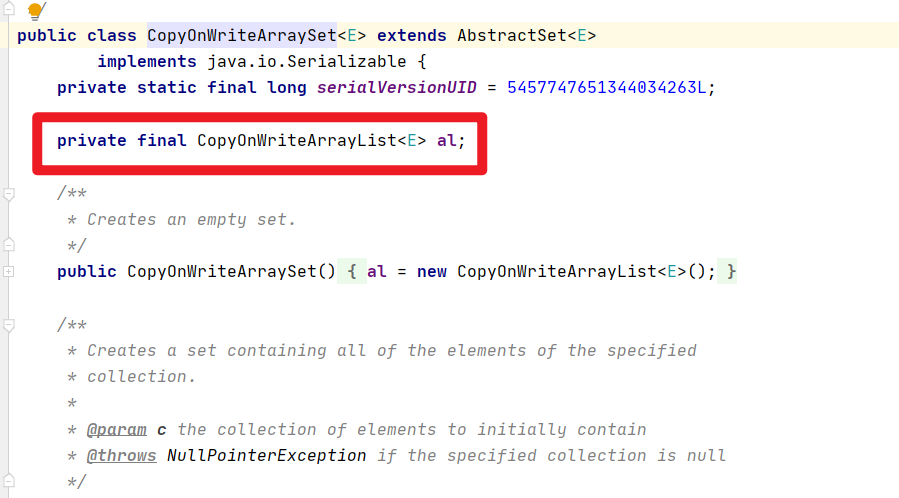
- HashSet底层数据结构就是HashMap<>()
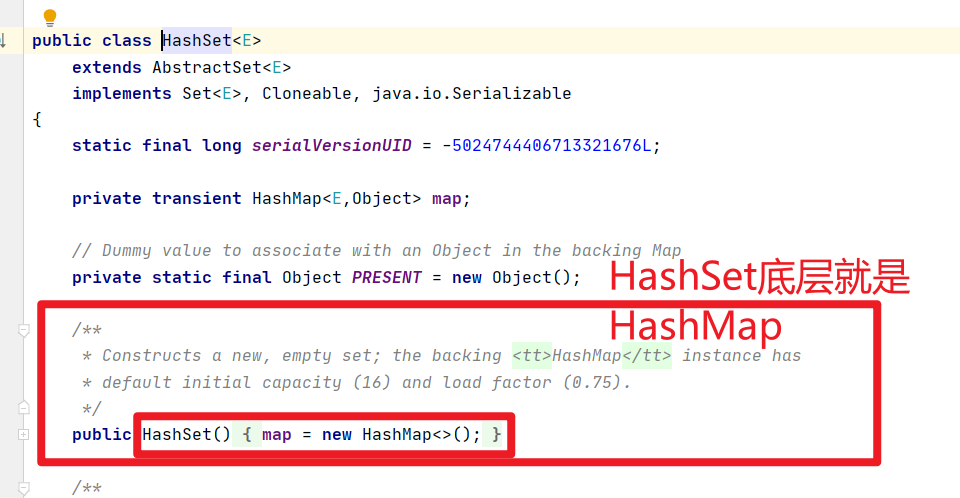
- HashSet底层如果是HashMap,那为啥add方法只有一个参数捏???
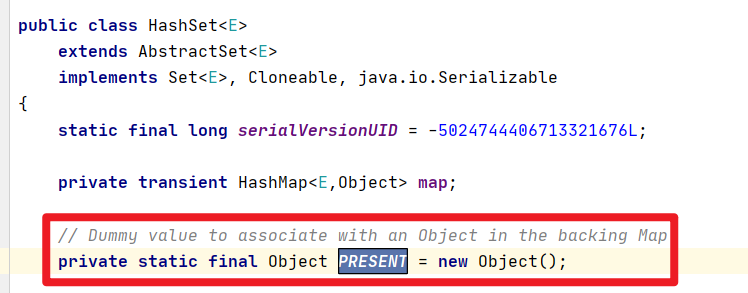

value是个恒定的值哦!!!
HashMap线程不安全:
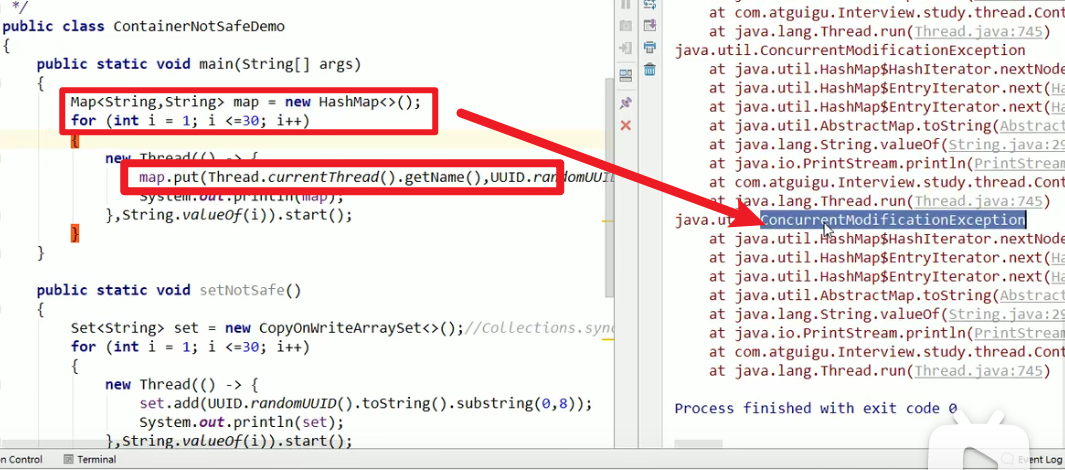
- 解决方法:
ConcurrentHashMapCollections.synchronizedMap
7. TransferValue醒脑:
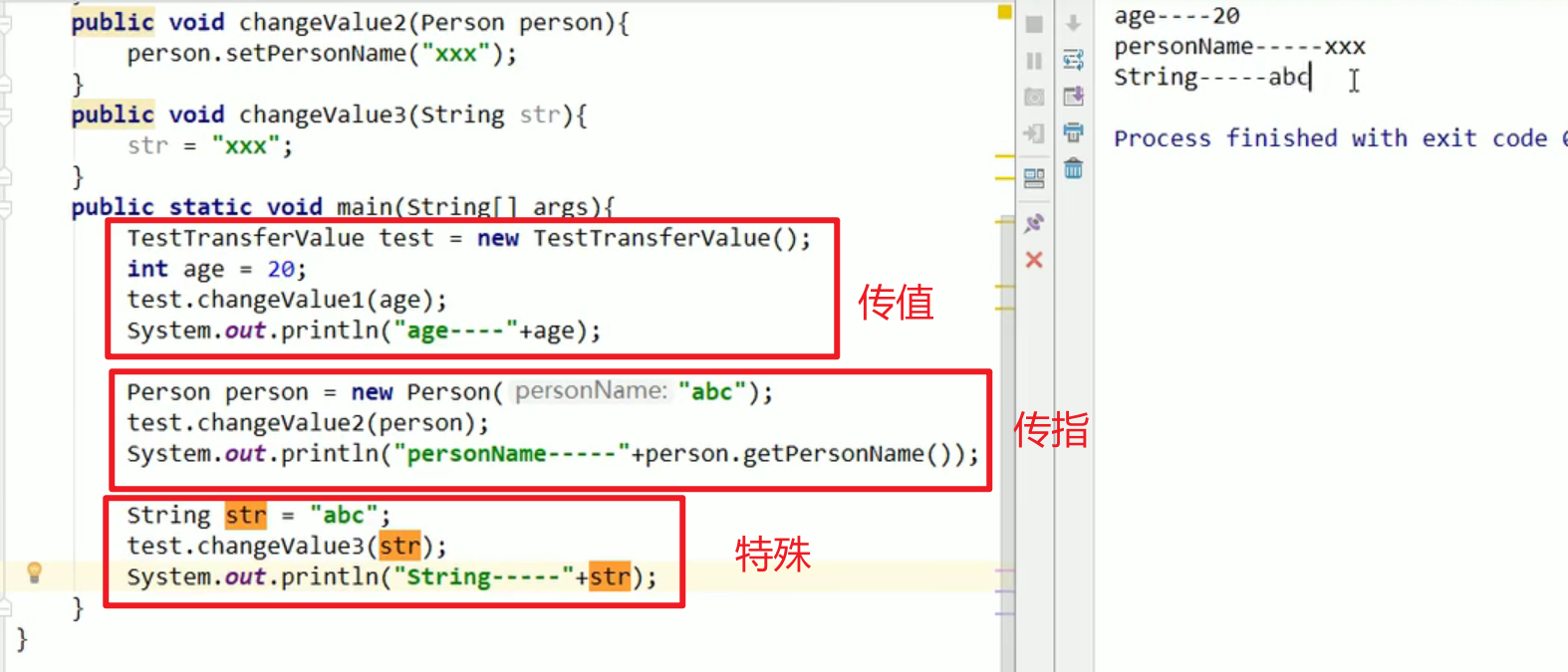
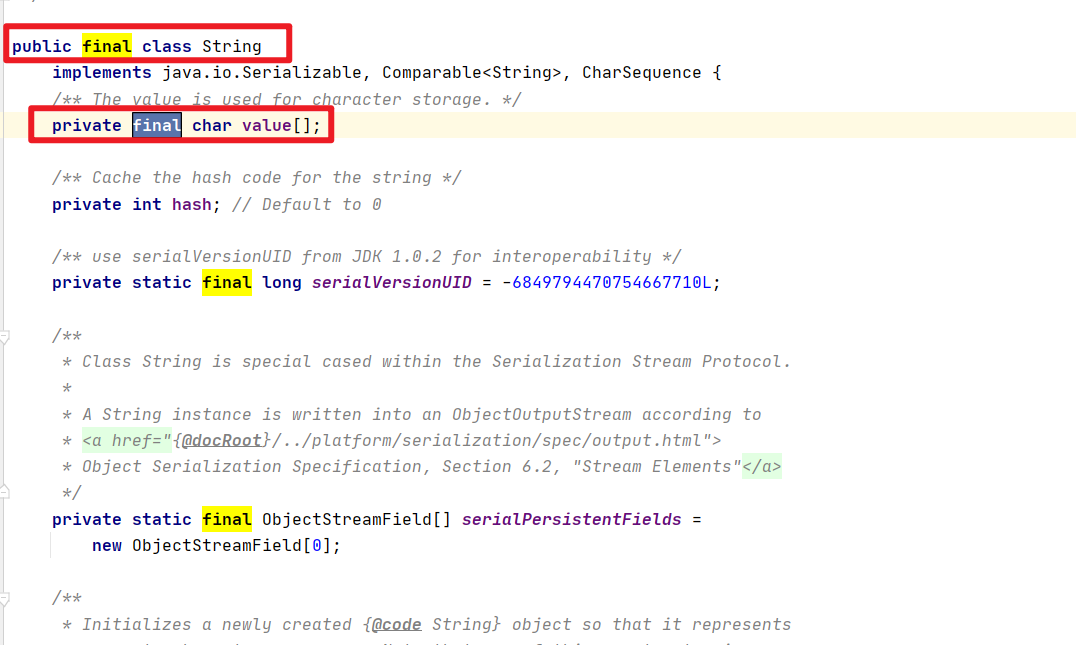
String比较特殊嗷!!!它是final,赋予了地址之后,这个地址是不会变动的。String str = “abc”,String指向了常量池中的地址。而str = “XXX”,确实找到了常量池中的”XXX”,如下右图:
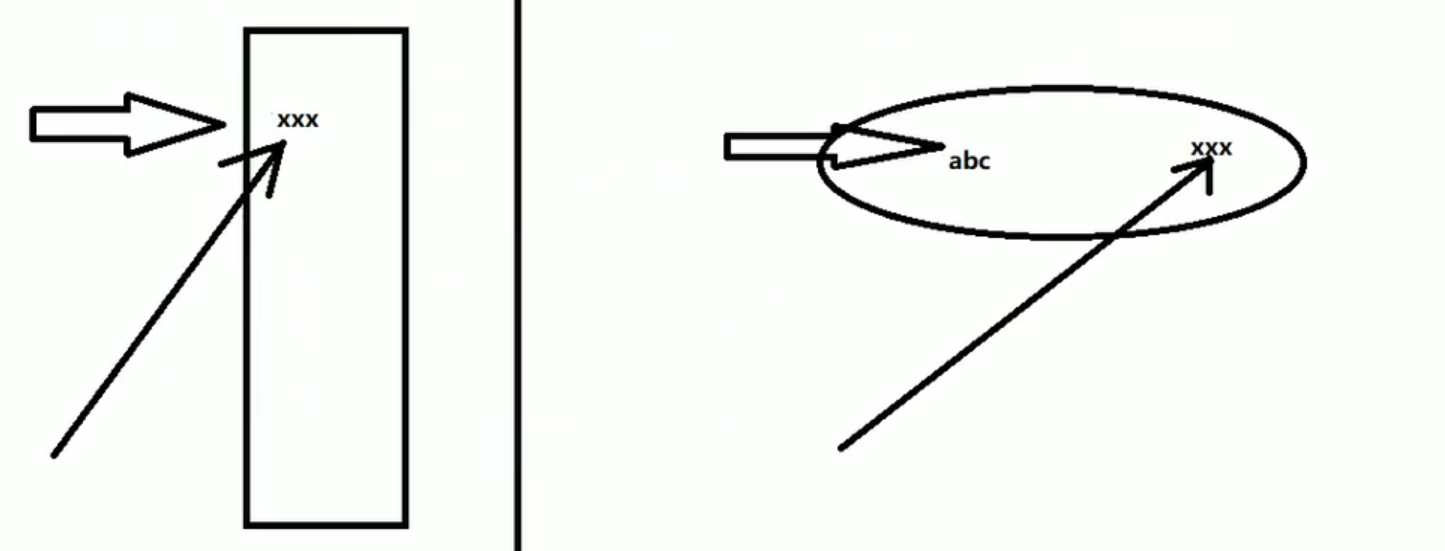
说白了就是传进去就是一个地址,方法中参数的str本质上也是一个拷贝,一个指向这个地址的指针的拷贝,这里的赋值,无非是把拷贝指针的指向变了,改变不了原指针的指向嗷!!!
8. Java中的锁们:
公平锁和非公平锁:
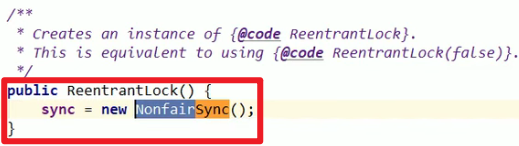
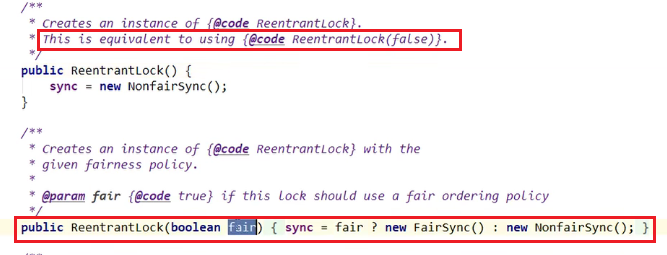
这里不传参数等于传入了false参数嗷!!!天生这个即使非公平锁嗷!!!公平锁就是先来后到,非公平就是允许某些线程能够“不公平竞争”,能够加塞!!!

ReentrantLock:

默认为非公平锁,非公平锁的有点在于吞吐量比公平锁大嗷!!!说白了又是体现了优先级呗!!!优先级高的能被响应,吞吐量就会大嗷!!!
- Synchronized而言,也是一种非公平锁哦!!!
可重入锁(递归锁):
- ReentrantLock就是可重入锁哦!!!
- 可重入锁就是递归锁
- 指的是统一线程外层函数获得锁之后,内层递归函数仍然能获取该锁的代码!在同一个线程在外层方法能够获取锁的时候,在进入内层方法会自动获取锁嗷!!!(也就是说:线程可以进入任何一个它已经拥有的锁所同步着的代码块!!!)
- 线程可以进入任何一个它已经拥有的锁所同步的代码块。
- ReentrantLock/Synchronized就是典型的非公平可重入锁嗷!!!
- 最大作用:避免死锁
- 代码:
Case1:

这个就是例子:sendSMS()调用了sendEmail,进入sendSMS中执行sendEmail的时候会自动获取锁并进入这个代码块执行嗷!!!
Case2:
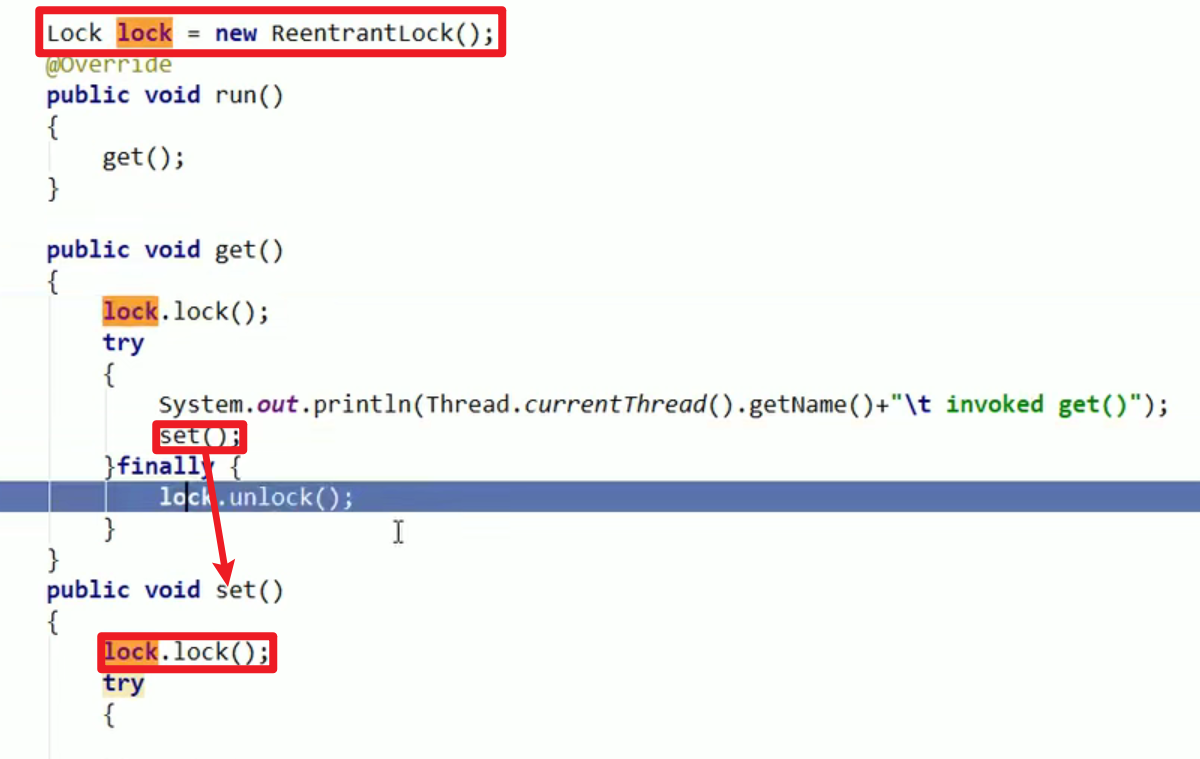
- 运行结果:

- 思考:

只要锁配对正确,加几把锁都没问题嗷!!!可以正确运行嗷!!!!
自旋锁:
- spinlock:尝试获取锁的线程不会立即阻塞,而是采用循环的方式尝试去获取锁。好处是减少了上下文切换的消耗,缺点是循环会消耗CPU嗷!!!
手写自旋锁:
- 本质:while + compareAndSet()方法
本质上利用一个拥有compareAndSet()方法的变量来帮助我们实现就行嗷!!!
1 | |
1 | |
- 这里非常有技巧性,这里的AtomicReference的泛型就可以拥有compareAndSet方法,但是为了让每个线程都可以“独立的拥有一些特征来获得自旋锁”,我们采用了线程作为泛型对象进行操作嗷!!!
thread.currentThread()就能够获得当前的线程,不同线程的这个值肯定不一样嗷!!!这样就比较好一些嗷!!!
独占锁(写锁)/ 共享锁(读锁)/ 互斥锁
独占锁(写锁)
指该锁一次只能被一个线程所持有。
对于ReentrantLock和Synchronized而言都是独占锁。
发展历程:
sync ---> lock ---> ReentrantReadWriteLock读写锁提高了并发效率嗷!!!从保证原子性到提高效率嗷!!!
规则:
- 读-读可以共存
- 读-写不能共存
- 写-写不能共存
实例代码:
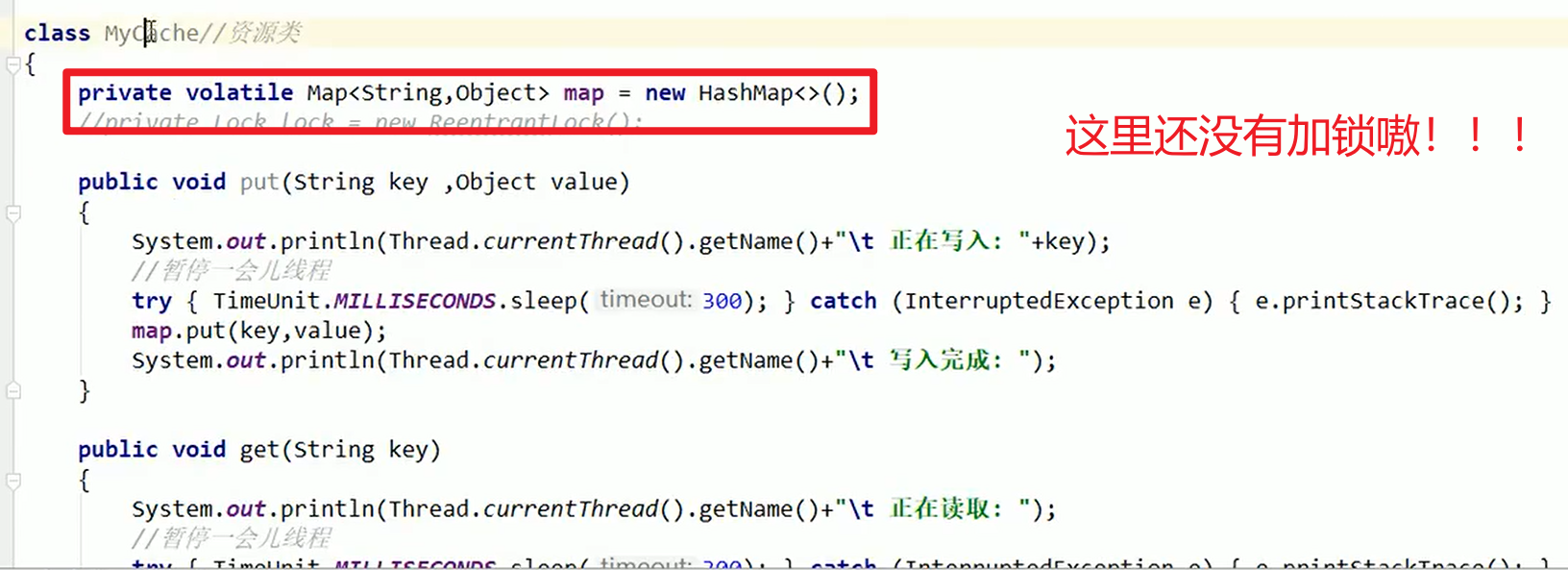
写操作:必须原子 + 独占(写锁)
这里模拟的时候,底层都是要用volatile的,保证可见性非常重要!!!缓存的可见性和及时性非常重要!!!
- ReentrantReadWriteLock读写同体,对于不同的方法要调用不同的方法适配嗷!!!
1 | |
- 加写锁例子:

- 加读锁例子:

- 以上两者对比:
共享锁(读锁):
- 该锁可以被多个线程所持有
9. CountDownLatch / CyclicBarrier / Semaphore
CountDownLatch:
有点像Linux中那个等待子线程结束(waitpid / pthread_join),主线程才能够最后退出的函数方法。
Demo:
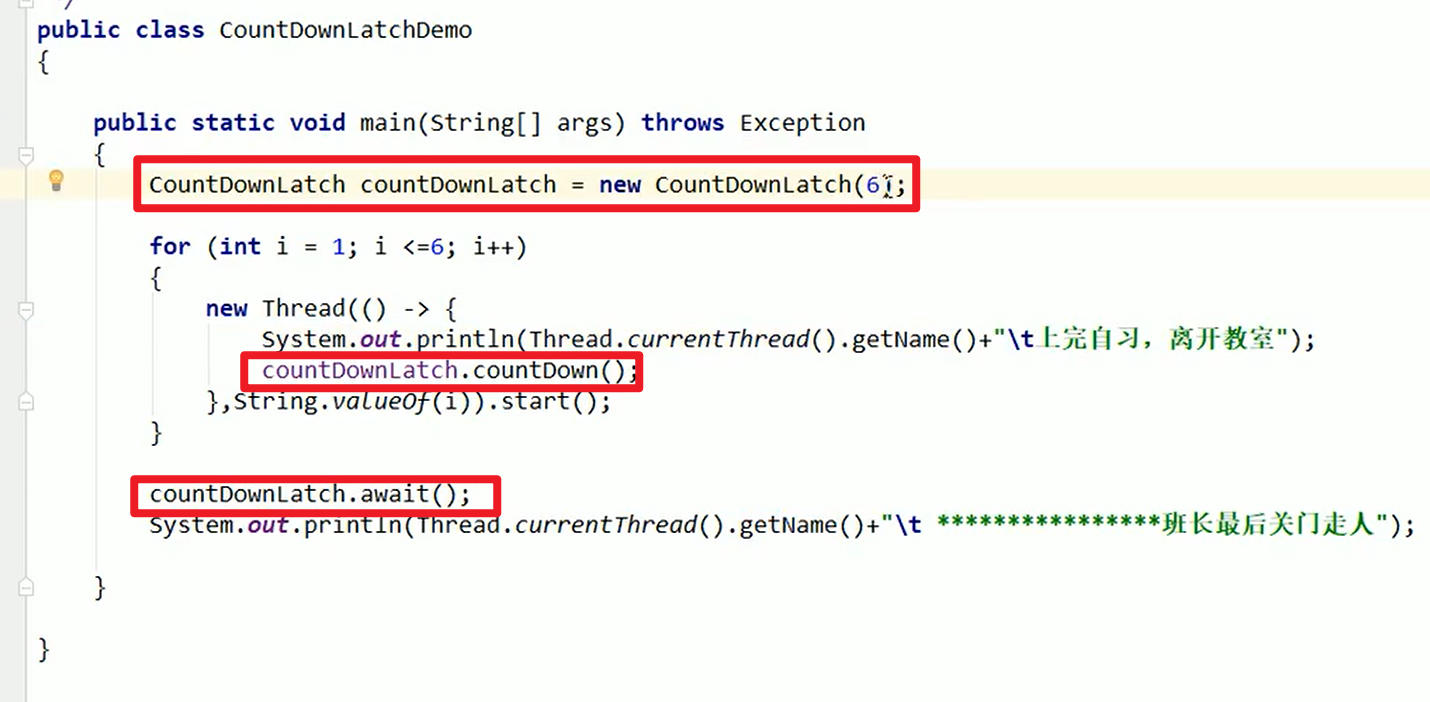
- 可谓是非常像了,这个玩意儿就是卡在这里,等所有线程的东西执行完了,才会继续往下执行嗷!!!
枚举:
- 可以当作小数据库来用嗷???还有这种操作???
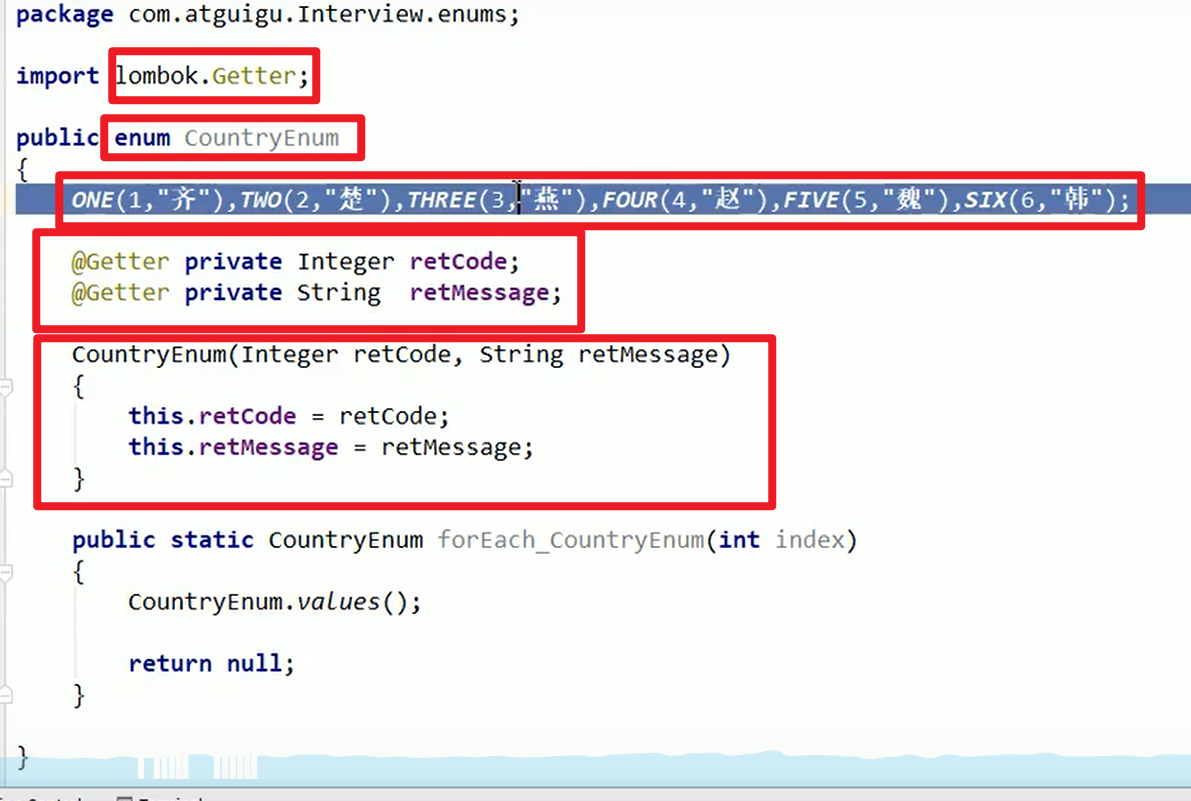
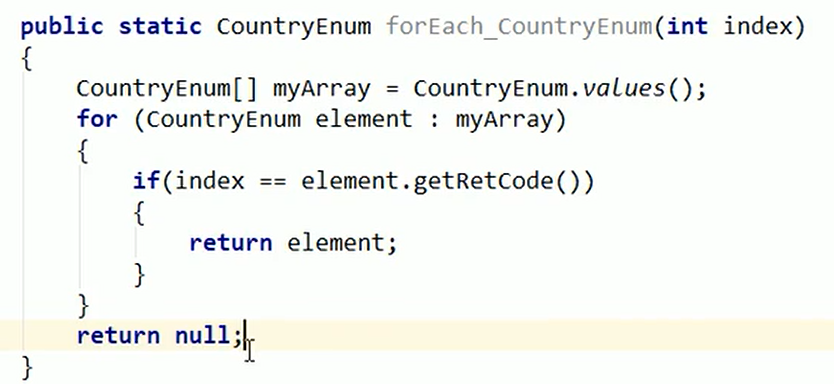
- 原来的代码的修改:
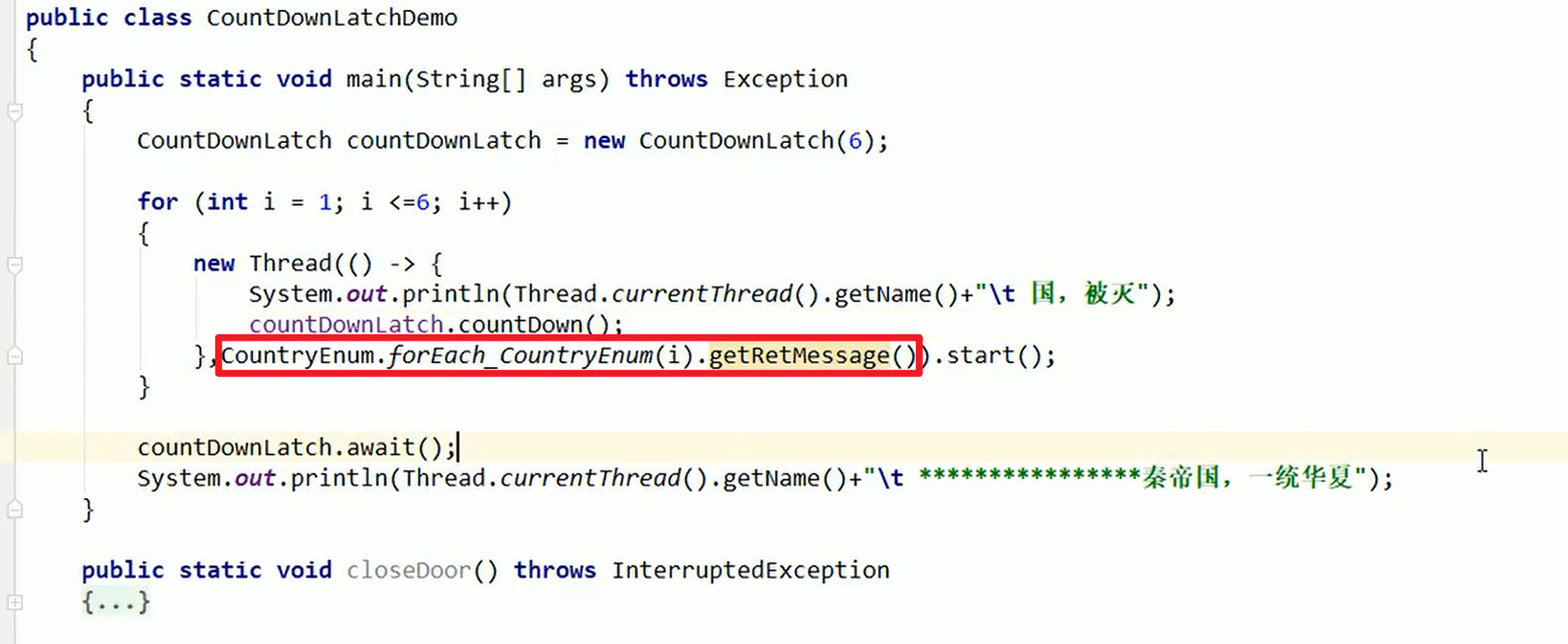
程序耦合度急剧降低,只要修改枚举中的元素,处处生效嗷!!!
- 枚举中元素的读取:

第一个相当于行的名字,第二三行相当于读取这一行某个元素的值嗷!!!
- 非常实用嗷!!!
CyclicBarrier:
- 增加到多少就能够发生某件事,和上面相反,这个是做甲方。
- 等人齐了,才能够开会~。

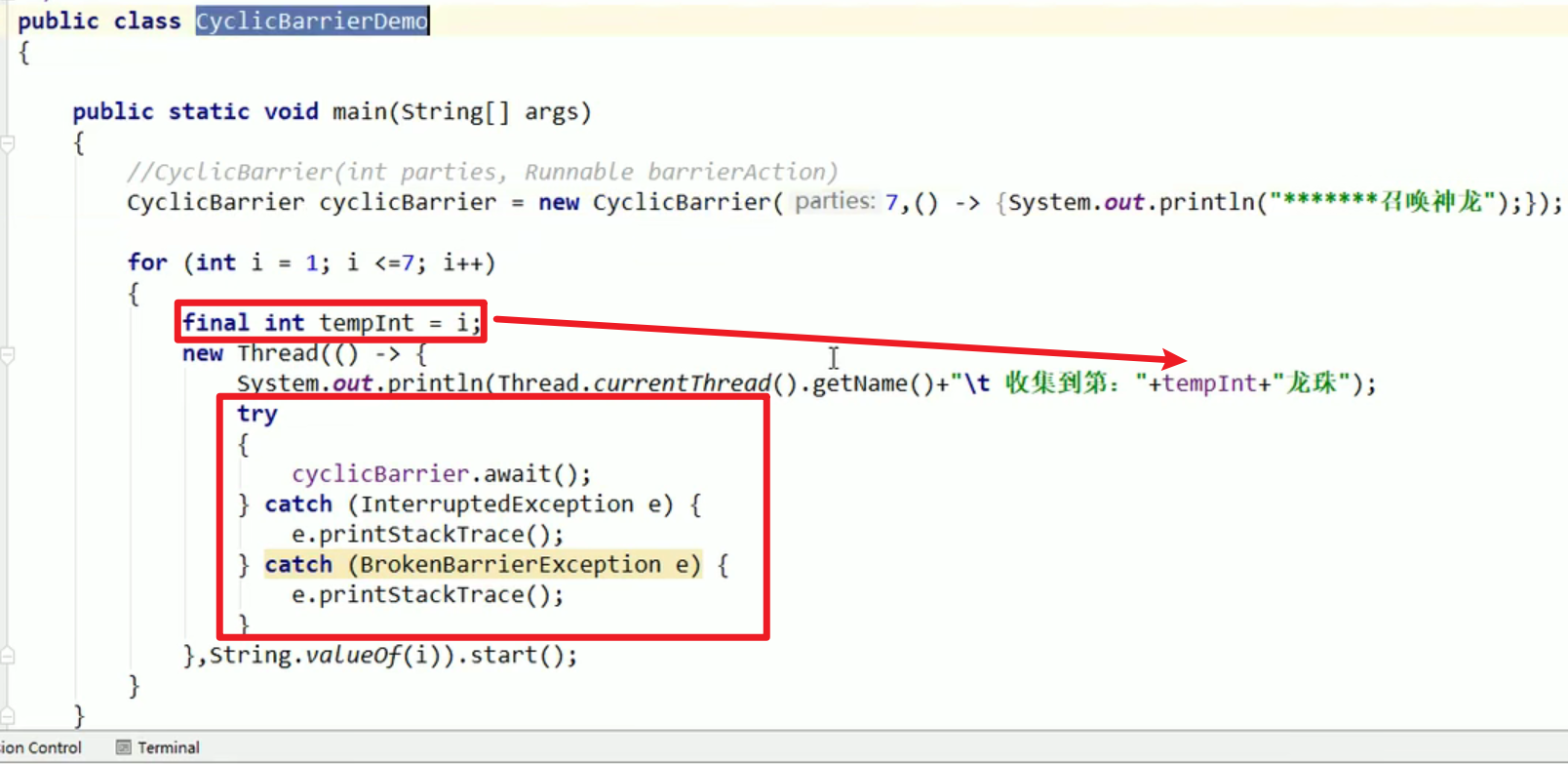
Semaphore:
- 多个资源抢多份资源怎么控制哇?
- 这个就是信号量,一个是用于多个共享资源的互斥实用,另外一个适用于并发线程控制嗷!!!
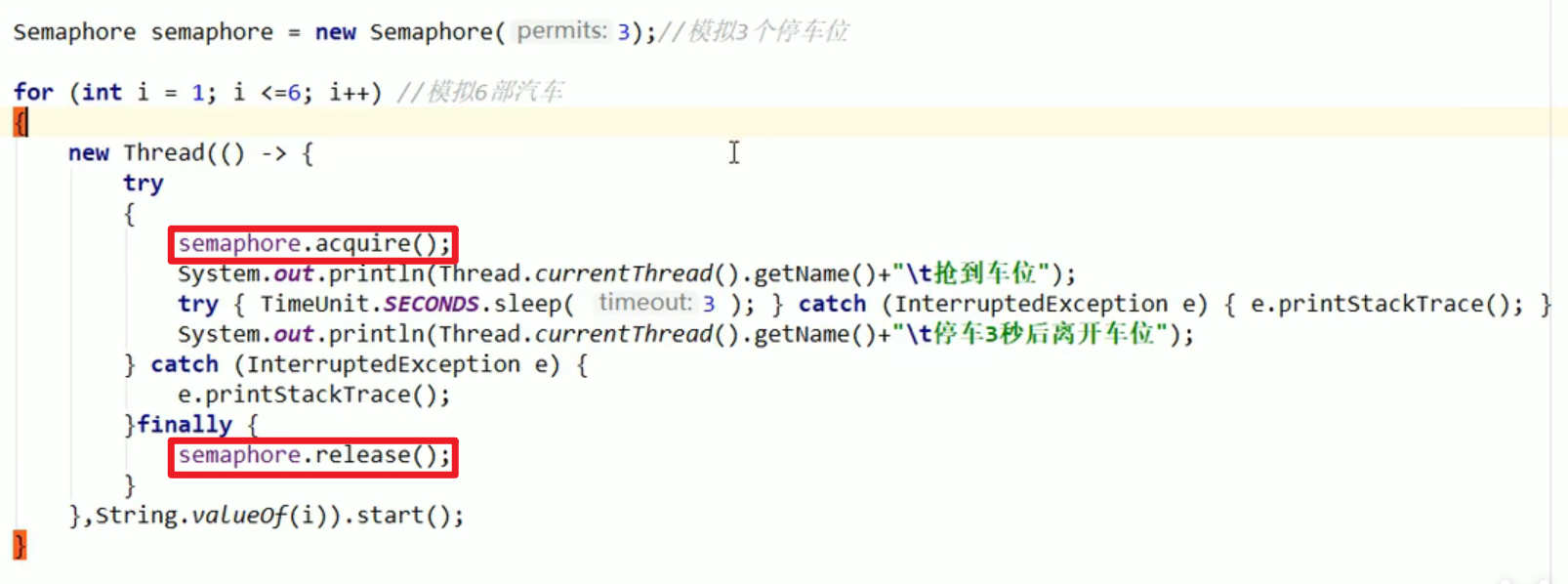
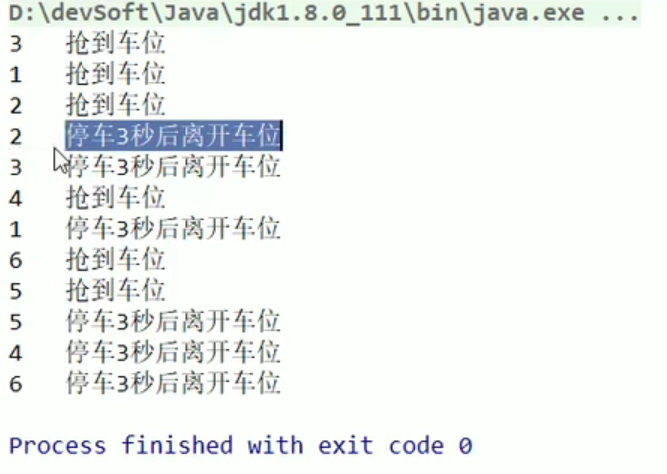
- 这个和操作系统中的没啥区别,都是信号量嗷!!!一个信号量可以当作锁来用嗷!!!
10. 阻塞队列
阻塞队列:
- 阻塞队列有好的一面。
- 不得不阻塞,如何管理?
队列+阻塞队列以及其api:
- 就是生产者和消费者问题的Java版本而已
- 空的队列拿元素,阻塞。满的队列添加元素,阻塞。
- why BlockingQueue?不需要关心什么时候阻塞和唤醒线程,BlockingQueue给我们一手包办了嗷!!!这个效率非常高嗷!!!(手动挡变成了自动挡嗷!!!)
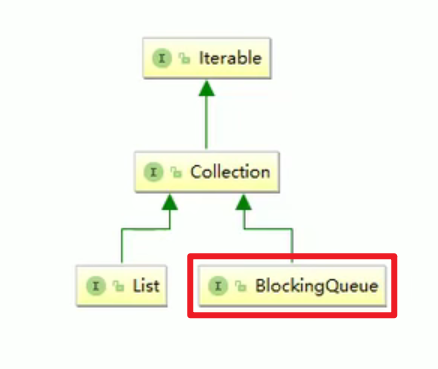
- 有好多实现类嗷!
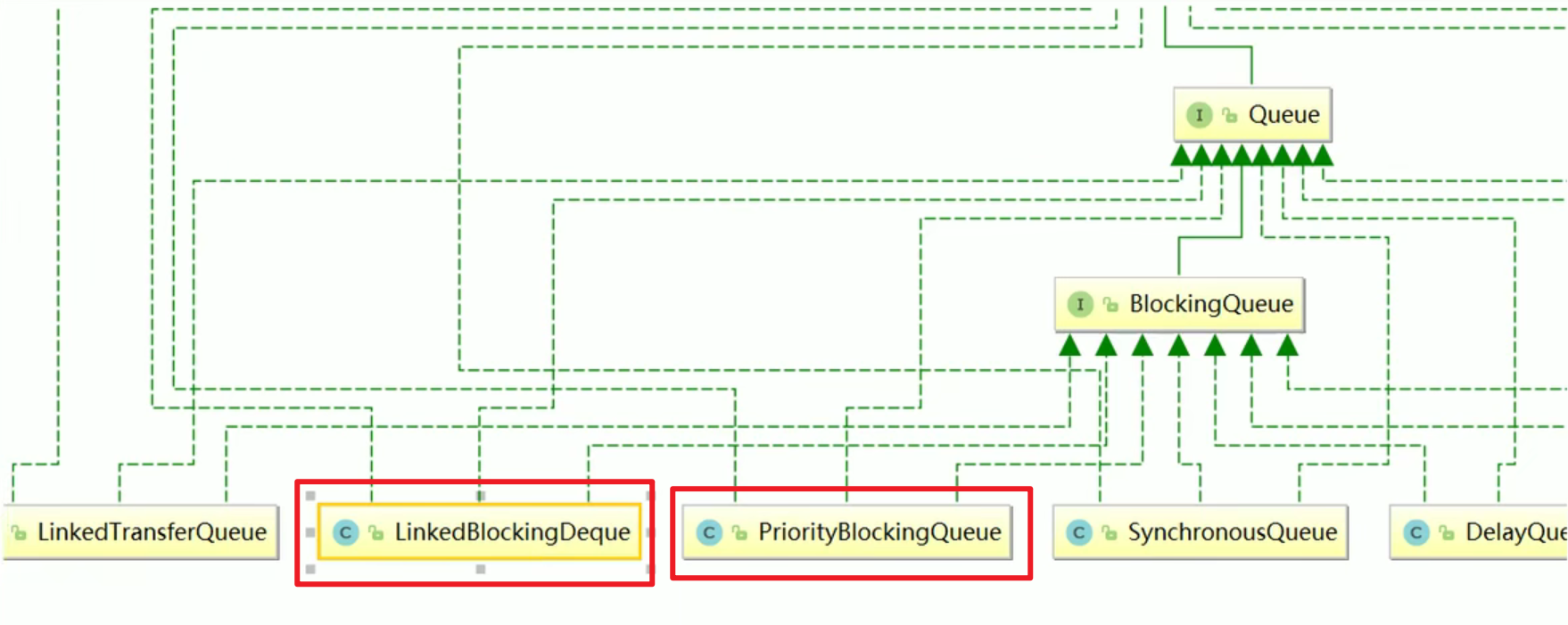

红色的是重点,这三个就是线程池的底层嗷!!!
最后一个是Deque嗷!!!双端队列,和上面的Queue是有区别的嗷!!!
SynchronousQueue专属定制版,就一个嗷!!!
- 常用情况(抛出异常):
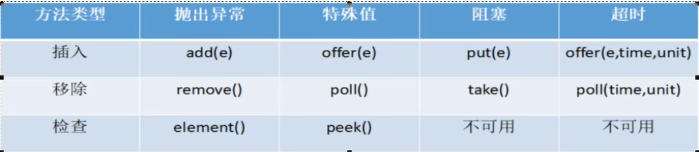
像这个Queue,符合先进先出的概念,element就是检查第一个元素嗷!!!add和remove还有element就是有这样的一个特点:如果对应的操作失败,就会抛出异常嗷!!!
- 常用情况(特殊值):
操作成功返回true,操作失败返回false嗷!!!
取出来的时候,取得到就是对应的元素,取不到就是NULL
- 常用情况(阻塞):
如果操作失败的话,默认会进行阻塞,等待嗷!!!

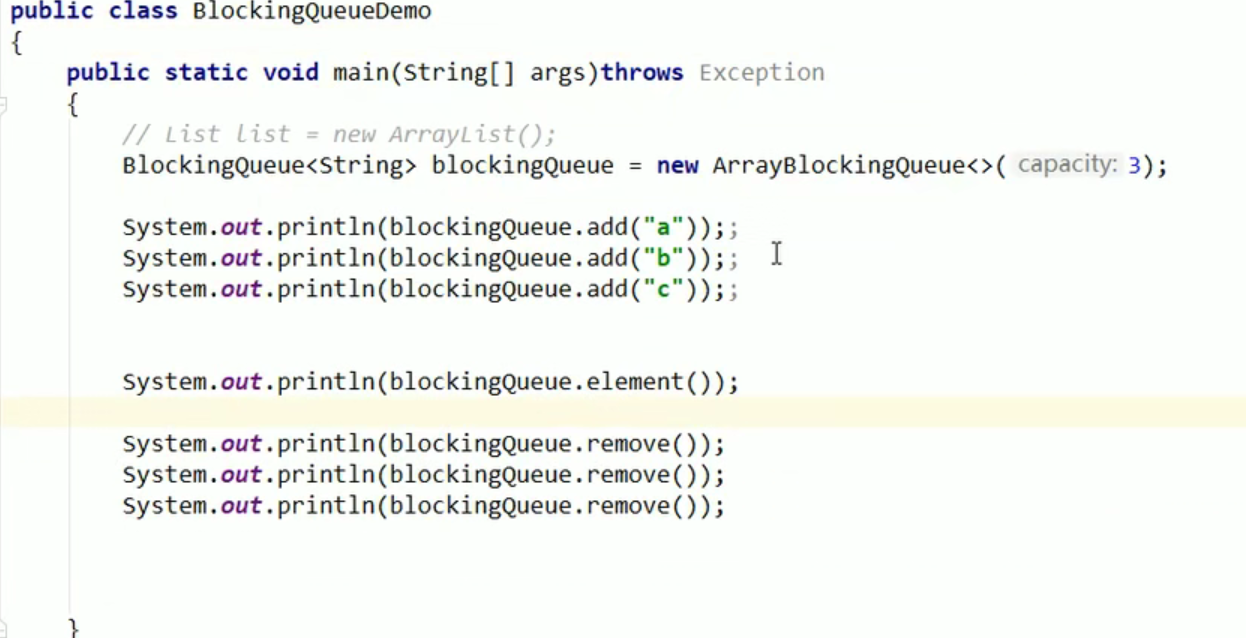
- 常用情况(超时):
不要那么猛,折中的一种做法嗷!!!我可以等,但是过时不候,如果超时了我线程就自己退出了嗷!!!

SynchronousQueue:
- 本质上是一个不存储元素的BlockingQueue,每一个put都要等待一个take嗷!!!
1 | |
用在哪里?
生产者消费者模式(老版)
ProdConsumer_TraditionDemoProdConsumer_BlockQueueDemo传统版:

老版sync向新版lock的转换:
- 代码:
1 | |
- 多线程判断都要用while,不要用if,if就有可能出现问题嗷!!!
1 | |
synchronized和lock的区别
- 原始构成
- synchronized是Java关键字,lock是java5以后出现的一个类。
- synchronized是属于JVM层面的,monitorenter和monitorexit,底层是通过monitor对象来完成的,其实wait / notify等方法也是依赖于monitor对象,只有在同步块或同步方法中才能调用wait / notify等方法。
- Lock是具体类,JUC中,是api层面的锁嗷!!!
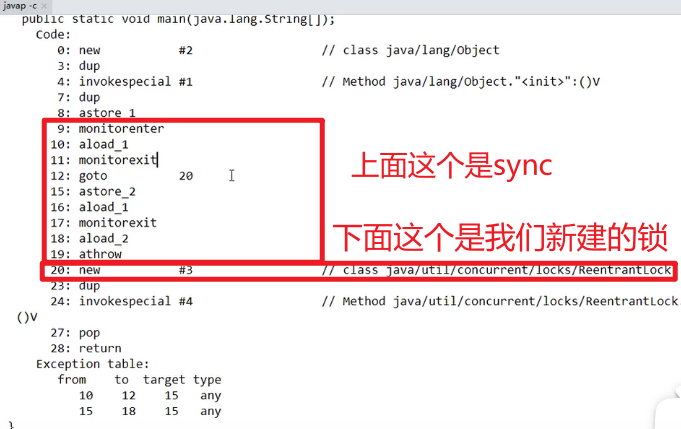
- 使用方法
- synchronized不需要用户去手动释放锁,当synchronized代码执行完成后系统会自动让线程释放对于锁的占用嗷!!!
- ReentrantLock需要用户手动释放锁,如果用户没有主动释放锁,那么就有可能会出现死锁现象嗷!!!需要lock , unlock方法配合try / finally语句块来完成嗷!!!
- 判断是否可以中断
- 等待是否可以中断,synchronized不可中断,除非抛出异常或者正常运行完成。ReentrantLock可中断:
- 设置超时方法 trylock(long timeout , TimeUnit unit)
- LockInterruptibly()放代码块中,调用interrupt方法可以中断
- 加锁是否公平
- synchronized非公平锁
- ReentrantLock两者都可以,默认非公平锁,构造方法可以传入boolean值,true为公平锁,false为非公平锁。
- 锁绑定多个条件的Condition
ReentrantLock可以实现分组唤醒需要唤醒的线程们,可以精确唤醒,而不是像synchronized要么随机唤醒一个要么唤醒全部线程嗷!!!
- 例如A唤醒B,B唤醒C:

1 | |
生产者消费者模式(阻塞队列)
1 | |
- main代码块中的一些代码:
Callable接口(第三种多线程方式):
- 两个接口:

区别:
- Runnable没有返回值,Callable有返回值
- Callable会抛出异常
- 接口需要实现的接口不一样嗷!!!
中间层同时适配了Callable和Runnable接口嗷!!FutureTask这个类同时实现了Callable接口和Runnable接口,是按了适配嗷!!!!
背景?为什么会出现呢?
并发,异步导致。高并发最牛逼的控制嗷!!!初衷就是:麻烦的事儿交给别的线程去处理,实现高并发需要使用的嗷!!!
兔兔想法:实现更高程度的并行嗷!!!(分支合并操作嗷!!!)
- 小建议:
- 把get方法放在最后哦!!!get如果没有获取到值的话,会阻塞在这里嗷!!!
- 等它算完了再去取就会比较方便嗷!!!所以我们尽量放在后面取。
- 当然如果某一步就要结果,又不想阻塞的话,我们就可以类似于自旋锁,通过
futureTask.isDone()来实现哦!!!
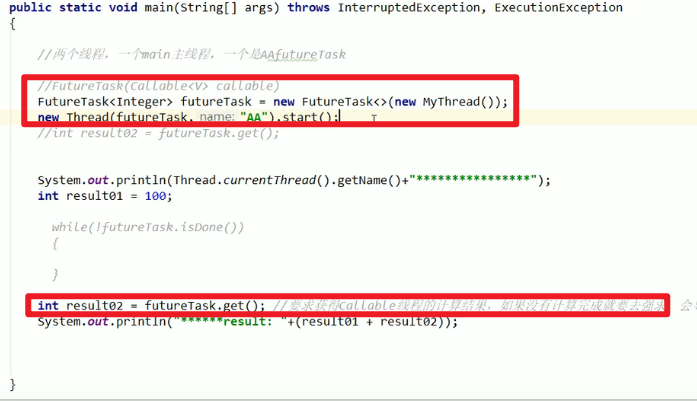
提高了并行性嗷!!!
- 如果启动了多个线程来抢着执行同一个任务呢?
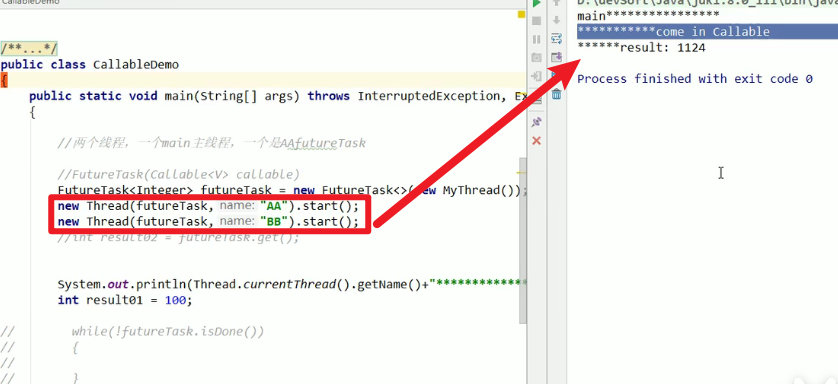
- 不好意思,只执行了一次嗷!!!同样的动作就应该复用嗷!!!如果你真的想走两遍的话,再自己多去做一个FutureTask嗷!!!
线程池使用以及优势(第四种多线程方式):
概念:
- 查看电脑CPU核数量:
Runtime.getRuntime().availableProcessors()可以获得硬件中可用的CPU的核数嗷!!!
- 从new对象到IoC的反转,依赖注入 -> 全都给你准备好,你直接复用我准备好的就成嗷!!!
- 底层就是阻塞队列嗷!!!
- 底层是
ThreadPoolExecutor ThreadPoolExecutor ThreadPoolExecutor这个类嗷!!!Executor这个接口就对应了Executors这个工具类嗷!!!(和Array,Arrays一样的嗷!!!)
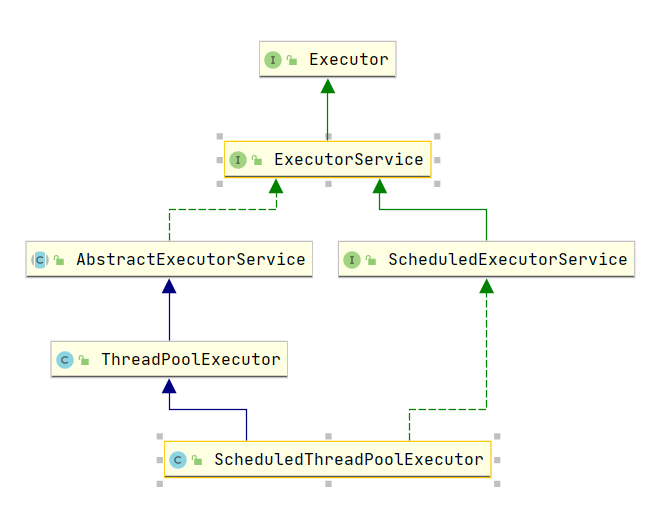
- 了解:
Executors.newScheduledThreadPool()时间参数用于调度的Executors.newWorkStealingPool(int)可用的处理器作为它的并行级别
- 重点:
Executors.newFixedThreadPool(int)Executors.newSingleThreadPool()Executors.newCachedThreadPool(int)
代码:
newFixedThreadPool:
固定数目线程池,处理线程数目固定哦!!!
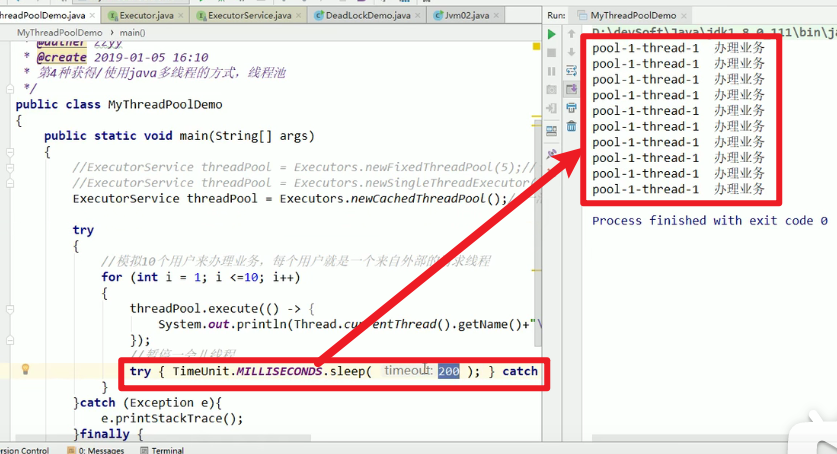
模拟十个用户用五个请求来进行处理嗷!!!
处理结果:

- 关闭比使用更加重要嗷!!!
newSingleThreadExecutor:
- 固定单个数目线程池
newCachedThreadPool:
- 线程池数目不固定,够用就好嗷!!!如果线程不够的话,还会自动扩容嗷!!!
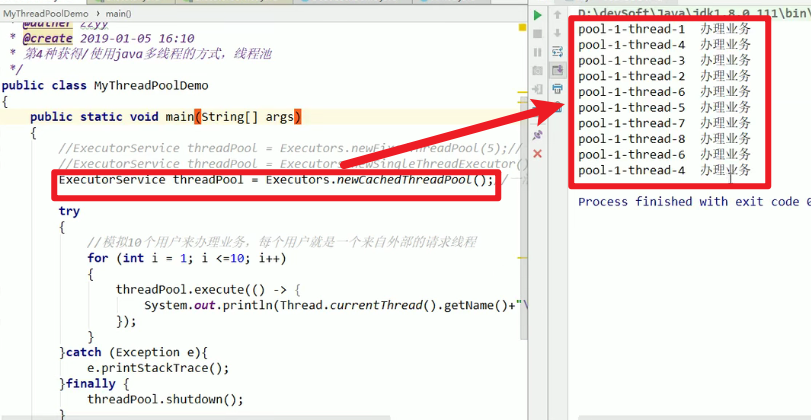
- 核心思想:
我尽力办,我办的完的话,就ok。我要是办不完,我就摇人了嗷!!!
总结:
- 发现上面这三个玩意儿,底层都是
return new ThreadPoolExecutor(...)!!!所以ThreadPoolExecutor如此重要嗷!!!

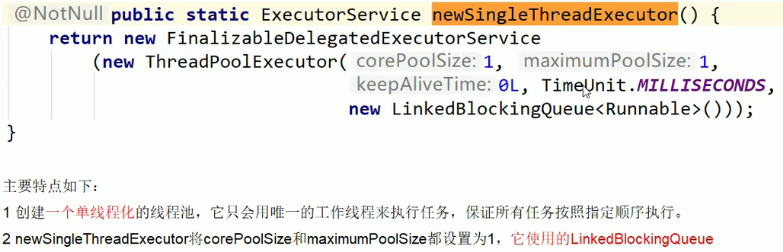

底层源码重点:
- ThreadPoolExecutor这个类很重要!!!
- 底层的阻塞队列也很重要嗷!!!!
使用方法:

七大参数简介:
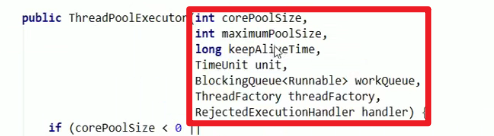
- corePoolSize:常驻核心线程数

- maximumPoolSize:
物理上线程池能够容纳的同时执行的最大线程数,此值必须大于等于1嗷!!!
- keepAliveTime:
多余的空闲线程的存活时间,当线程池数量超过CorePoolSize的时候,空闲时间达到keepAliveTime的值的时候,多余的空闲线程会被销毁直到只剩下corePoolSize个线程为止嗷!!!
没有业务了,“加班”的人会慢慢回退嗷!!!
unit:keepAliveTime的单位
workQueue:任务队列,被提交了,但是由于核心线程都被占用而无法执行,处于等待状态的任务嗷!!!
类似于银行中的候客区
threadFactory:生成线程池中线程的线程工厂,用于创建线程,一般用默认的就可以了嗷!!!
handler:拒绝策略,如果线程池满了,阻塞队列都满了,那就……只能够采取一些操作了orz
类似于银行网点,上班的人都在服务(但是还有多的空位),等待的人爆了,银行紧急通知其他休假的人赶紧赶回来上班嗷!!!
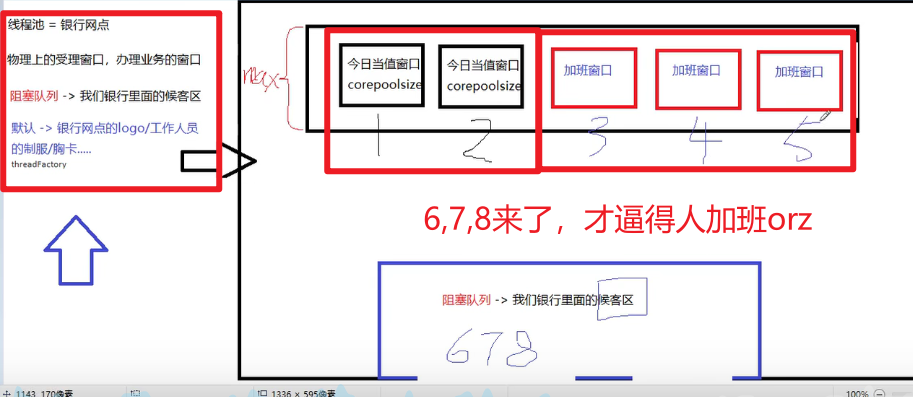
当所有人都在上班了(物理线程池被占满了),候客区也满了,不好意思。我银行已经尽力的,多来的请求我就不收了。
底层工作原理:
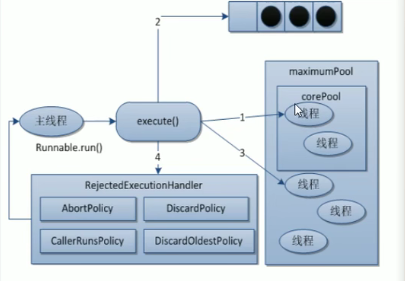
这幅图就是上面的银行网点那幅图嗷!!!
- 主要处理流程:
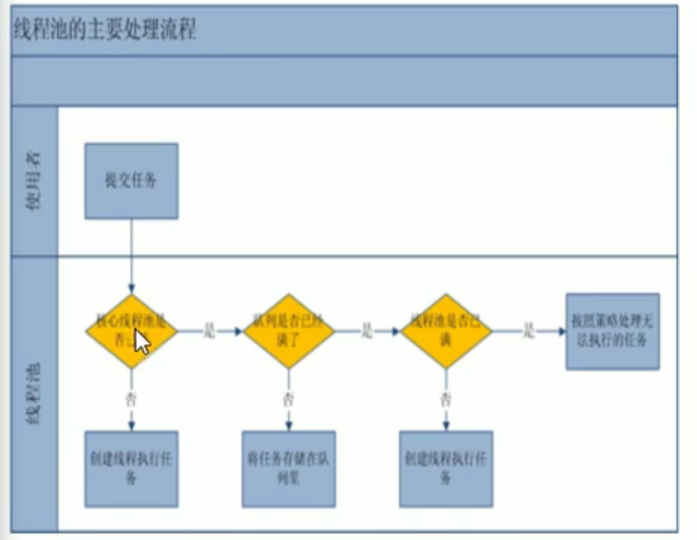

四种拒绝理论:
大坑:
- 上面学的三种,实际开发中,一个都不用嗷!!!(超级大坑!!!)
- 阿里开发手册:

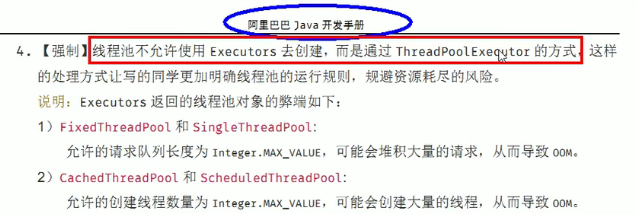
就是这里说的,由于底层是链表,没有最大长度,默认是Integer.MAX_VALUE。这就一个非常大的问题,就是如果我一直往阻塞队列里面加请求,加满了,你的Linux也就爆了orz。
自定义线程池:
ExecutorService threadPool = new ThreadPoolExecutor(2,5,1L,TimeUnit.SECONDS,new LinkedBlockingQueue<Runnable>(3),Executors.defaultThreadFactory(),new ThreadExecutor.AbortPolicy());
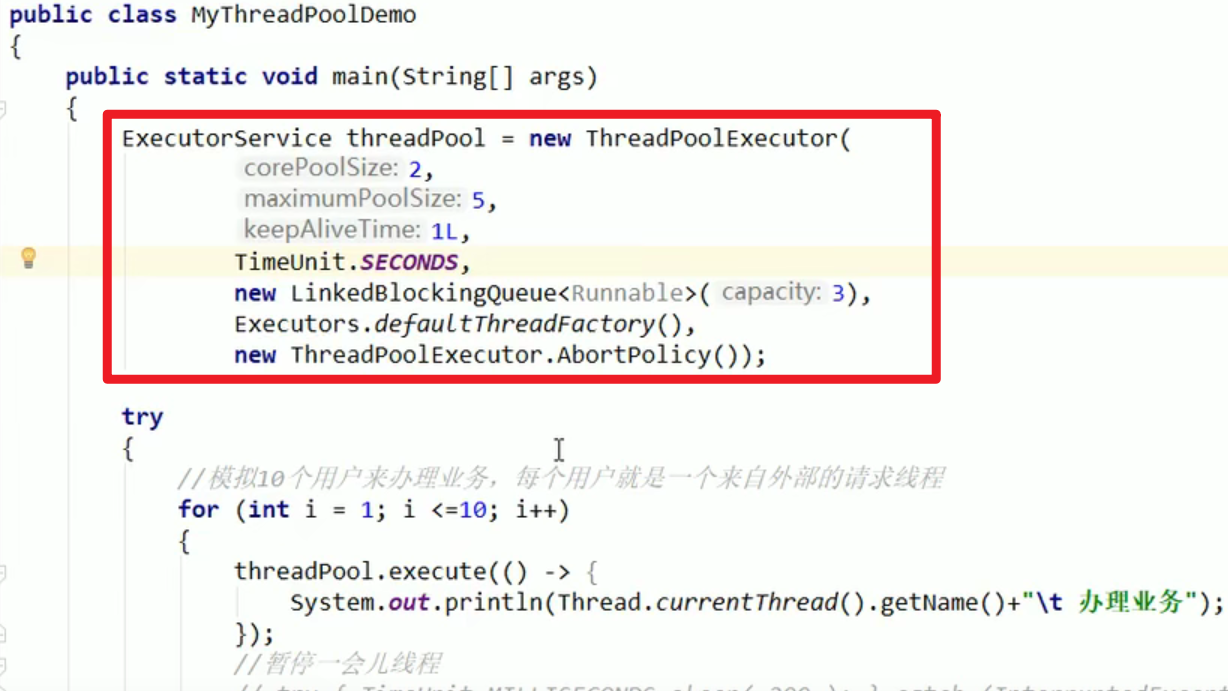
- 测试什么时候出问题呢?
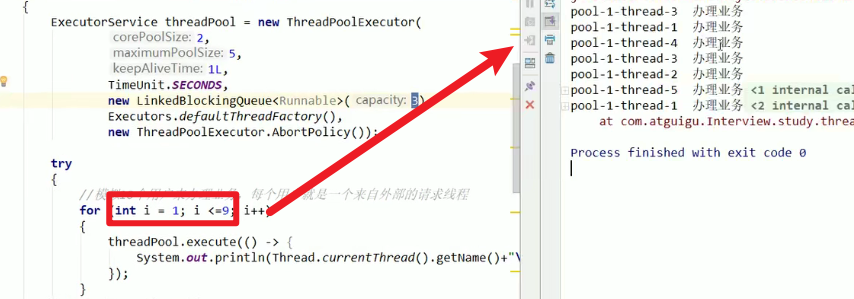
最大承载量 = maximumPoolSize + 阻塞队列最大长度,因此来9个时候可能出现这个问题嗷!!!
AbortPolicy:
- 概念:

- 种类:

- 如上图所示,出了问题直接报错嗷,程序运行终止。
CallerRunsPolicy:
- 调用者运行的一种调节机制,不会抛弃任务也不会抛出异常,而是将一些任务回退给调用者进行处理,从而降低流量嗷!!!
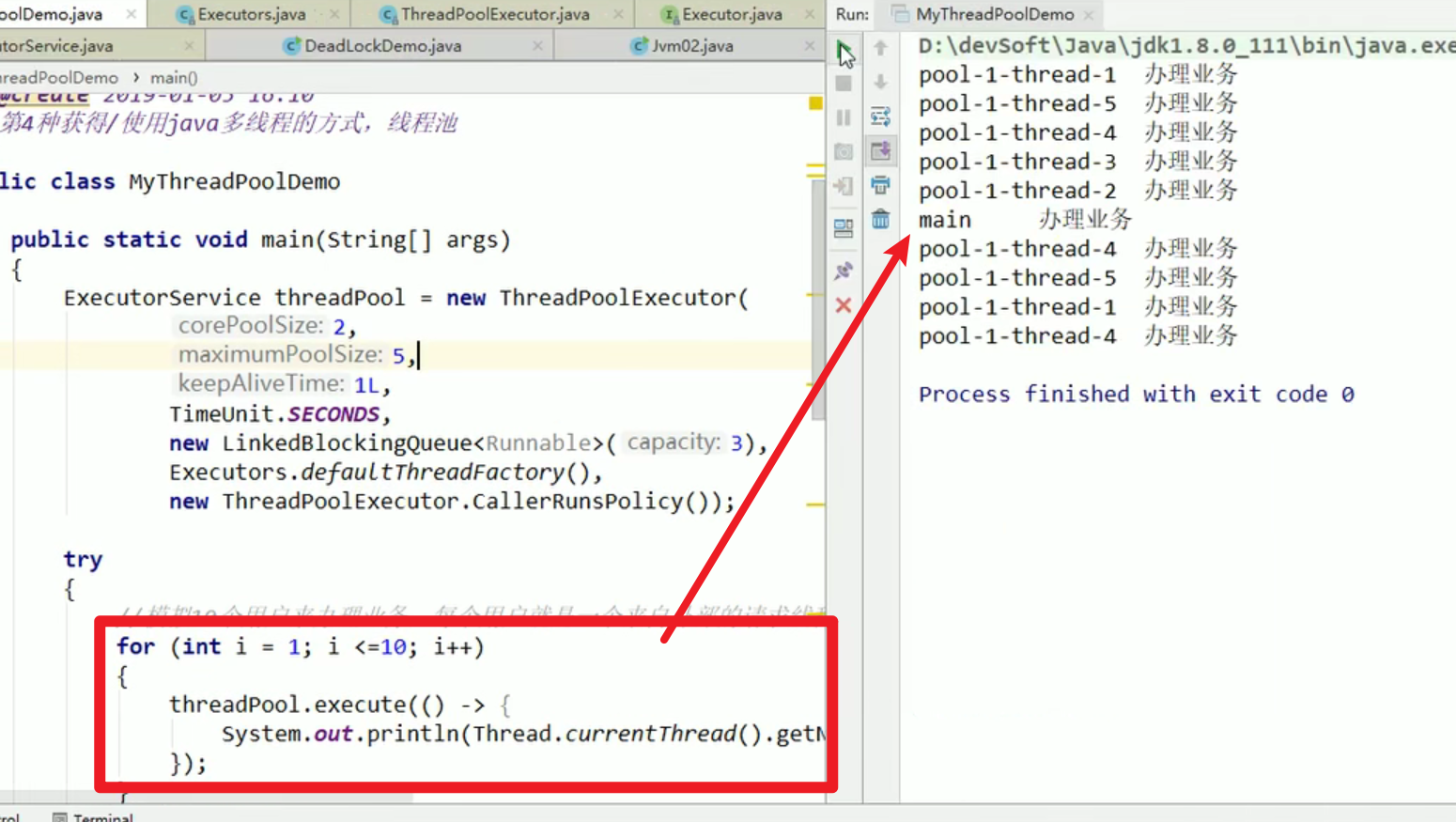
这里就会退给main来处理了嗷!!!
DiscardOldestPolicy:
- 抛弃等待最久的,将最新的加入到队列中再次尝试提交嗷!!!
DiscardPolicy:
- 多来的直接就给了扔掉了嗷!!!
配置合理线程数:
熟悉硬件:
- CPU密集型

- IO密集型
- I/O密集型任务线程并不是一直在执行任务,配置尽可能多的线程,如CPU核数*2

死锁编码及定位分析:
- 两个火柴人拿枪指着对方orz,好家伙orz。
写个死锁呗:
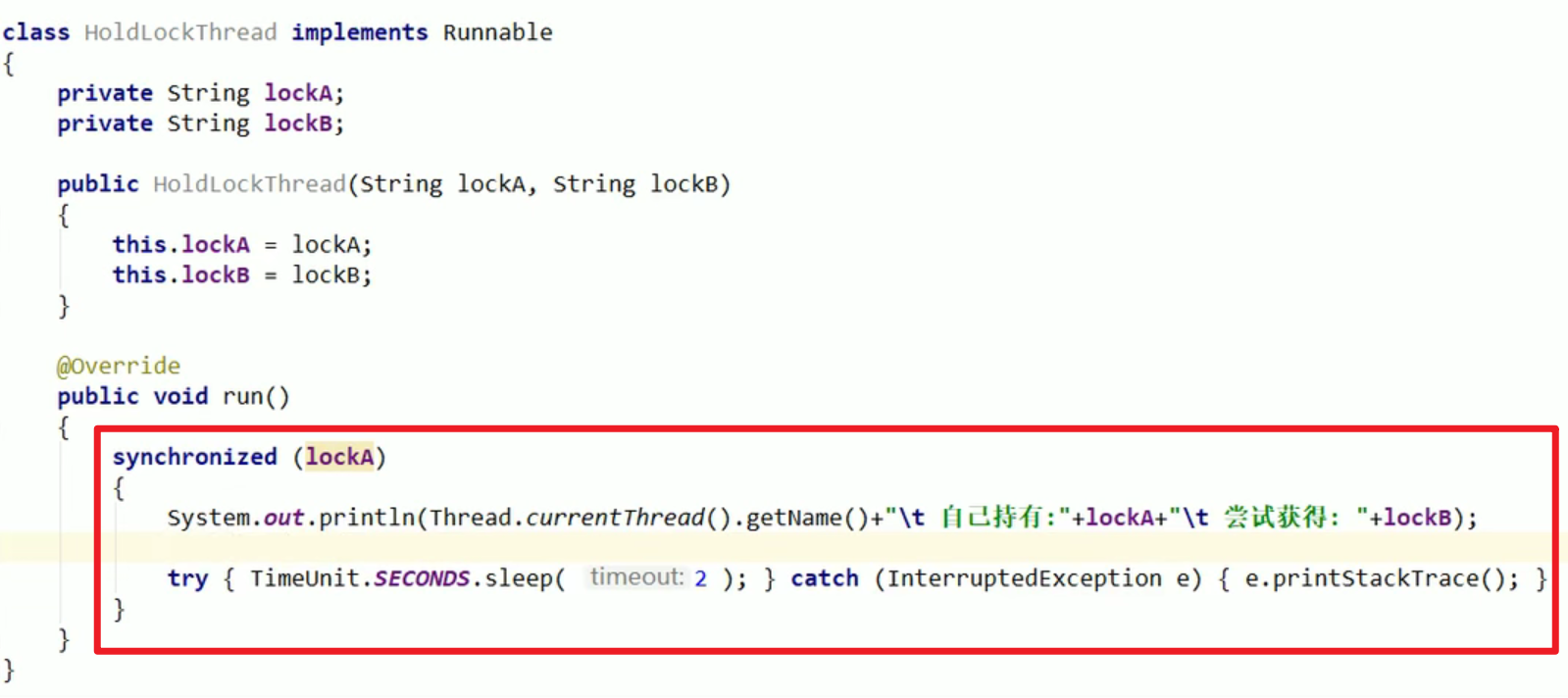
run没有写全,写全的版本在下面嗷!!!

- main函数:

小介绍:
- jps
linux中ps -ef | grep xxx
windows下的java运行程序捏?也有类似于ps查看进程的命令,但是目前我们需要查看的只是java的程序嗷!!
jps = java ps嗷!!!
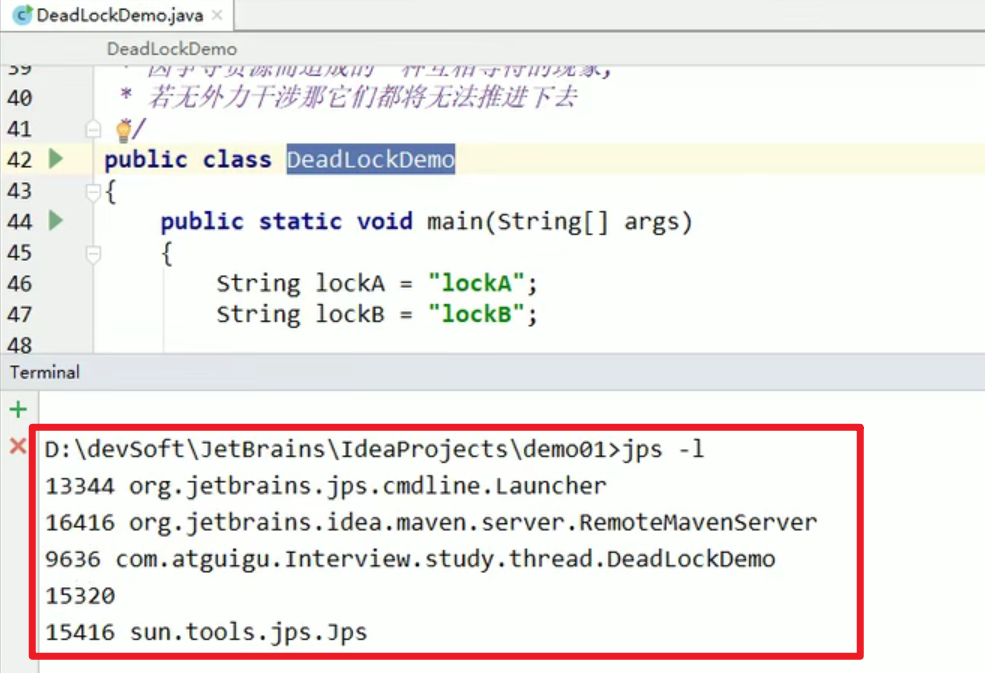
- jstack
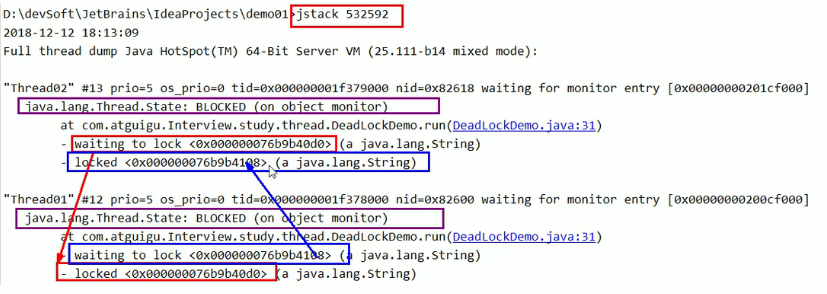
jstack + 进程号
结合上面的jps一起使用,找到对应的线程编号,再查看线程的错误信息嗷!!!
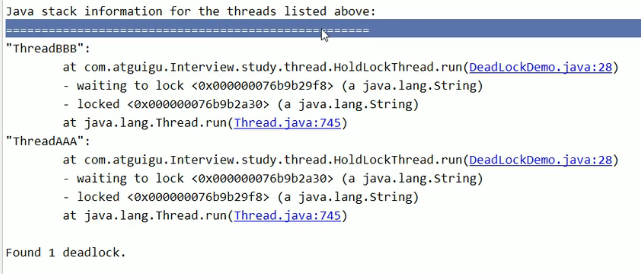
- summary:
- jsp命令定位进程号
- jstack找到死锁查看
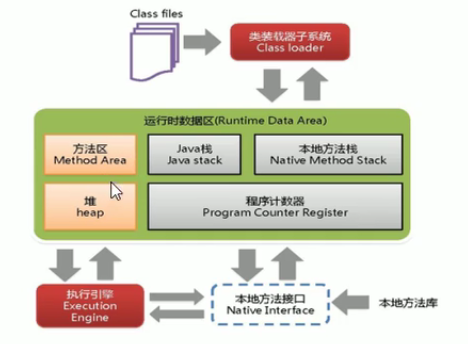
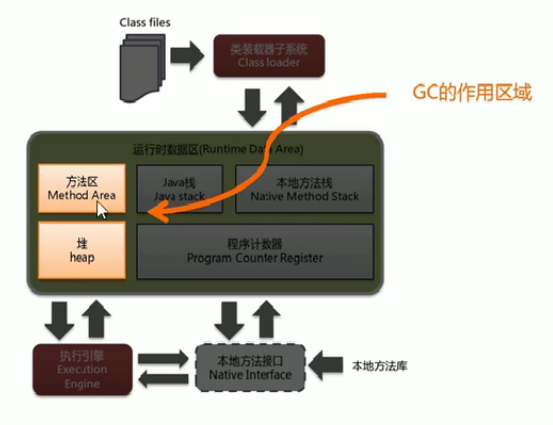
11. JVM+GC
复习串讲:
- JVM内存结构:
- GC作用域:
常见垃圾回收算法:
- 引用计数:
有对象应用+1,没对象-1,到0就回收。较难解决循环引用问题,因此JVM不采用这种方式。
- 复制算法:
复制算法在年轻代中用
名言:复制之后有交换,谁空谁是To

缺点就是复制大对象耗时,浪费空间嗷!!!
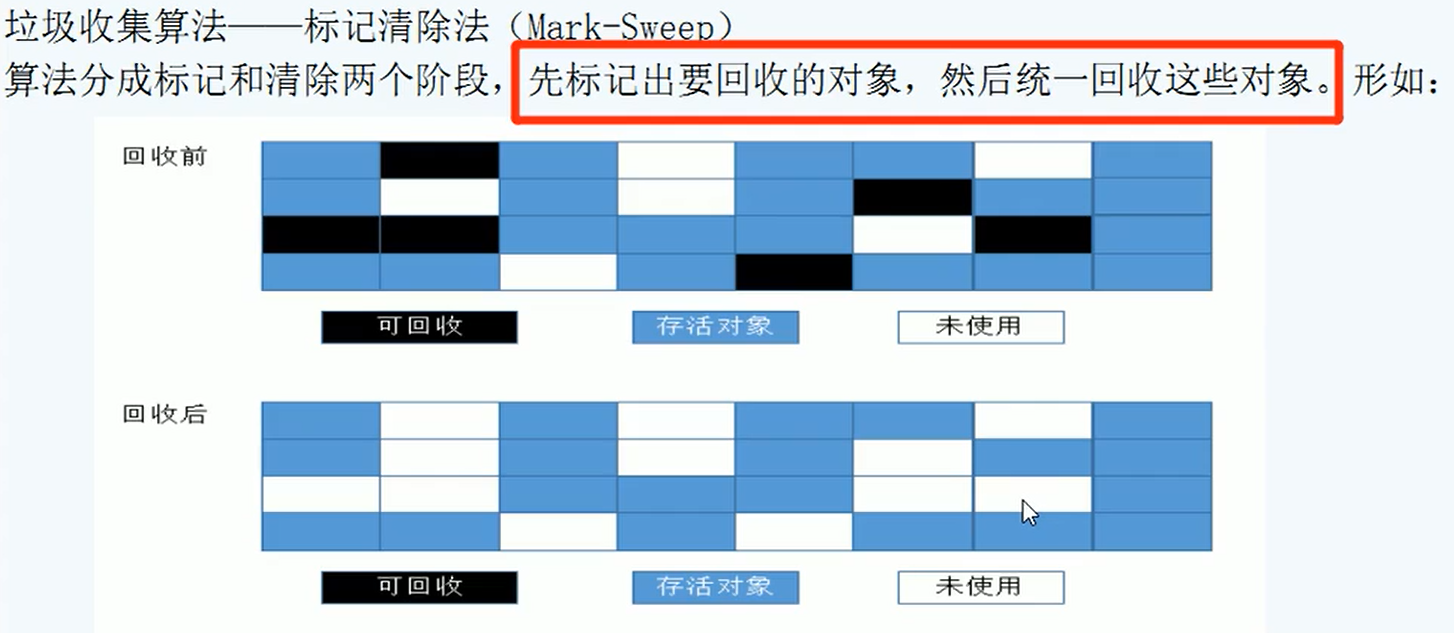
- 标记清除:
Mark-Sweep,分为标记清除两个阶段。先标记出要回收的对象,然后统一回收这些对象。
好处:不用复制,耗时少了。
坏处:出现了内存碎片
- 标记清除整理:
Mark-Compact
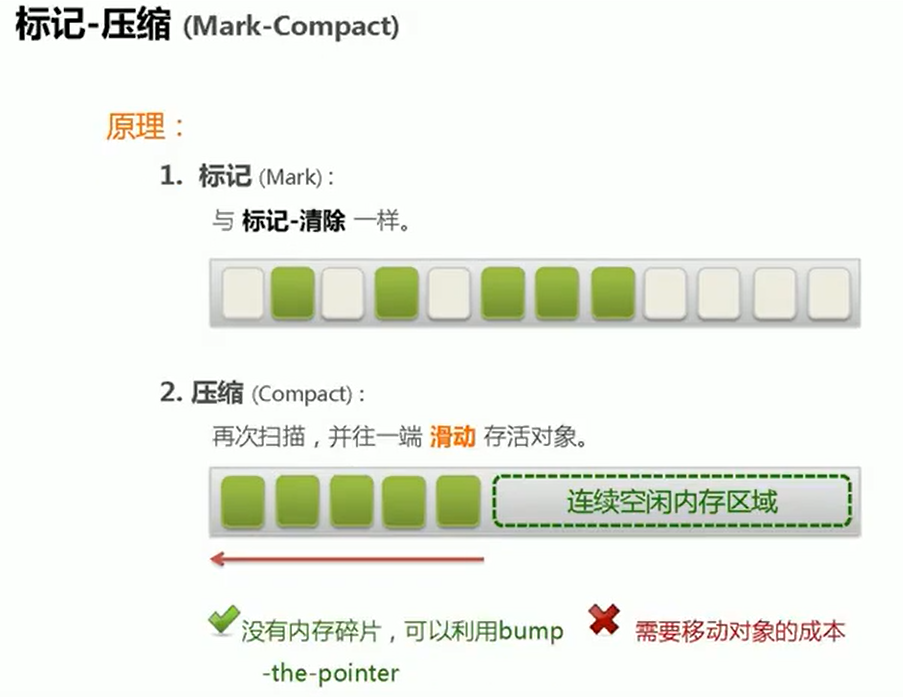
移动过程中,耗时比较多嗷!!!
如何确定垃圾+GCRoot:
内存中不再被使用的空间就是垃圾
如何判断一个对象是否是垃圾?
- 引用计数法:简单,但是循环引用解决不了
- 枚举根结点做可达性分析:
复制,标记清除,标记压缩都要用GCRoots来判断哪些是垃圾嗷!!!
GCRoots:

从GC对象进行扫描,看是否可达。
- 哪些对象可以作为GC Roots对象:
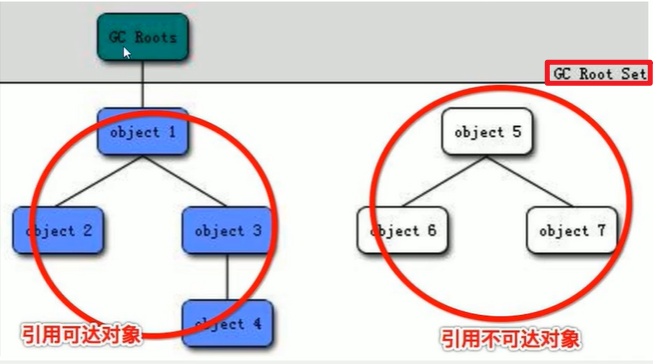
- 可以作为GCRoot的根呢?
JVM的参数介绍和调整:
查看参数:

-Xms和-Xmx尽量调成一致,防止GC频繁收集,忽高忽低。参数类型:
标配参数:
- 随着java变更,基本不会动的参数,没有大的变化。
X参数:
XX参数:
Boolean类型:
- 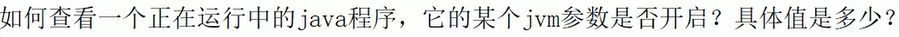
- 先让一个程序空转,比如
sleep(Integer.MAX_VALUE):查看线程情况:
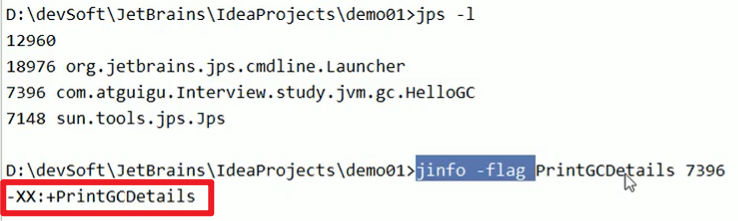
jps -l和jinfo,这个jinfo是显示当前正在运行的线程的信息嗷!!!- 查看某个线程的情况:
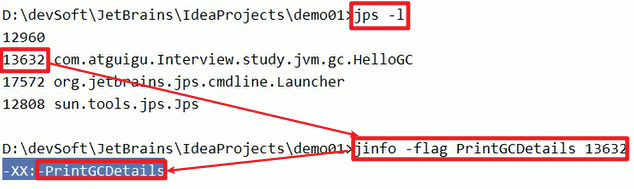
- 编辑参数:
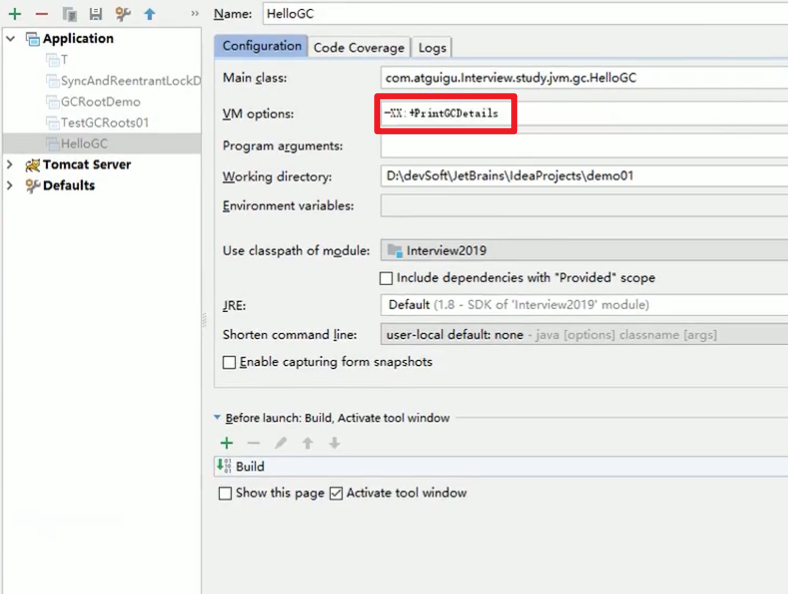
开启参数之后再测试:
- 先让一个程序空转,比如
KV设值类型:




查出某个进程的Metaspace的默认设置:

设置对应的值:
例如这个MaxTenuringThreshold就是young区的对象进入老年区所需要的年纪嗷!!!

所以这里就可以看出来默认的一些配置嗷!!!
- jinfo的配置使用:

-flags:
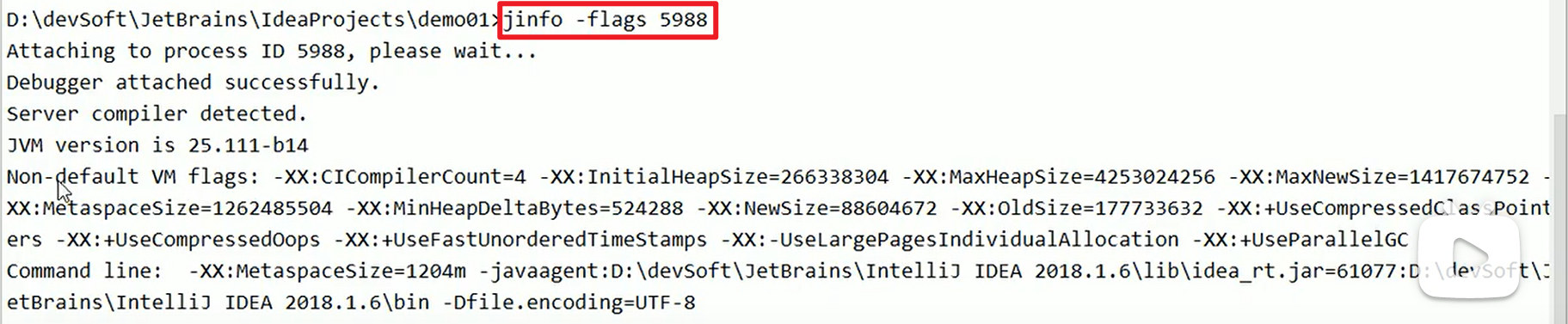
这个东西是要求得到运行中的线程的id,再去flags才能看得到的嗷!!!
Non-default是系统干的,帮我们自动配置好的。
Command line是我们自己配置的嗷!!!
- 题外话,坑题(-Xms和-Xmx如何解释?)

这两个参数也是一样样的,本质上就是-XX参数,用的多。这两个不属于X参数哈,还是属于XX参数嗷!!!只是用到多,单独提出来方便使用而已嗷!!!这两个值一般都是配置成一样的嗷!!!这样才能保证GC尽可能少哦!!!
查看参数二:

- 方式:
-XX:+PrintFlagsInitial查看初始参数值

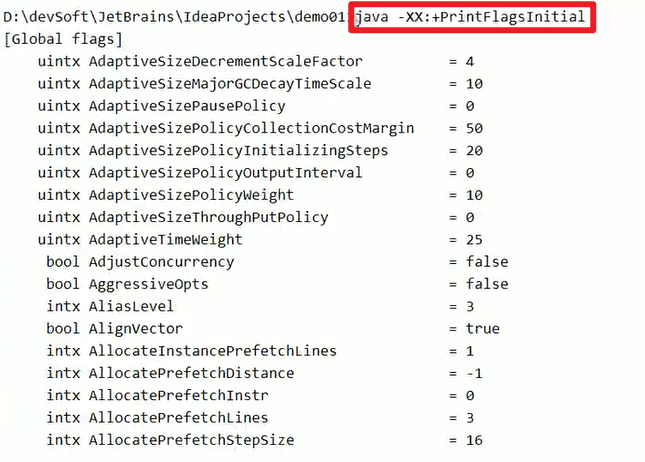
-XX:+PrintFlagsFinal查看修改更新的参数值
=和:=- 等于是没有被改过的初始值
:=是我们人为改过的或者是JVM加载的时候修改过的参数值嗷!!!
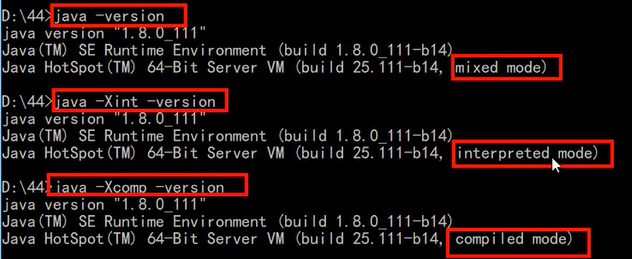
- -version的话,只是在最后多打出了JVM的版本号而已嗷!!!
- 命令行修改:

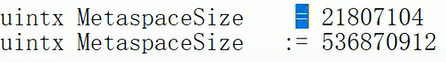
修改之后,运行T之后,可以看出来元空间的值发生了变化嗷!!!
-XX:+PrintCommandLineFlags打印命令行参数

这个命令最方便就是看最后一个参数!!!垃圾回收器的种类和默认参数嗷!!!
JVM基本配置:
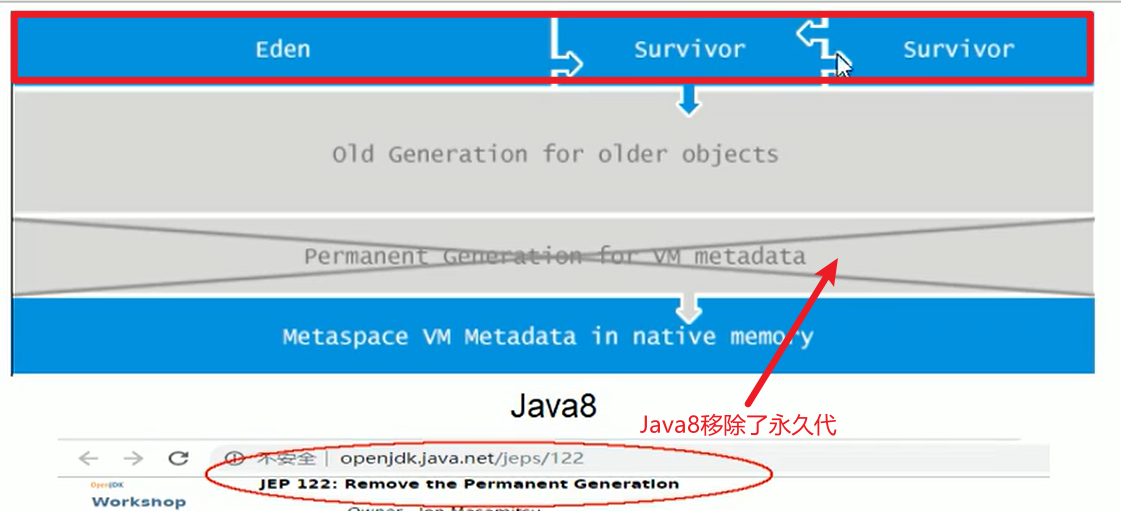
Java8调整:
- Java的MetaSpace:
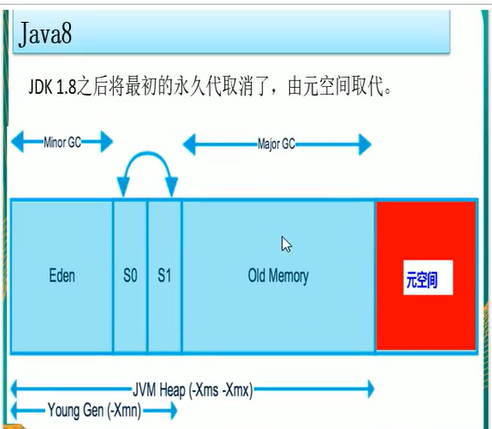

- 通过程序获得初始内存大小和最大的堆内存大小:

通用参数:


- 如何配置:
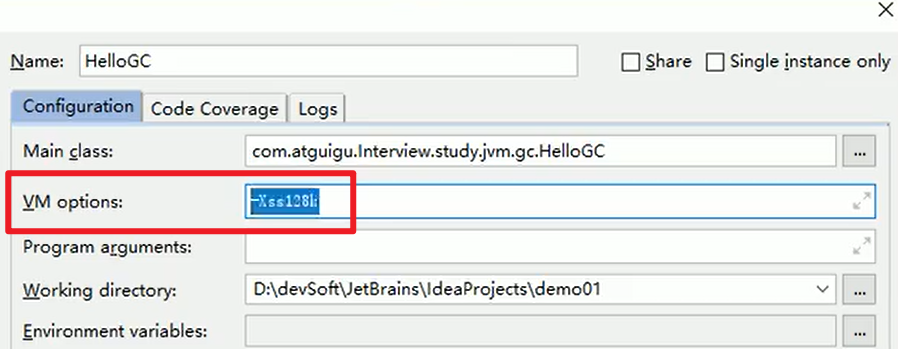
注意:栈管运行,堆管存储嗷!!!!这个栈是线程运行的时候所拥有的栈的大小
当我们不配置-Xss参数的时候,出现了神奇的问题:

它默认值为0
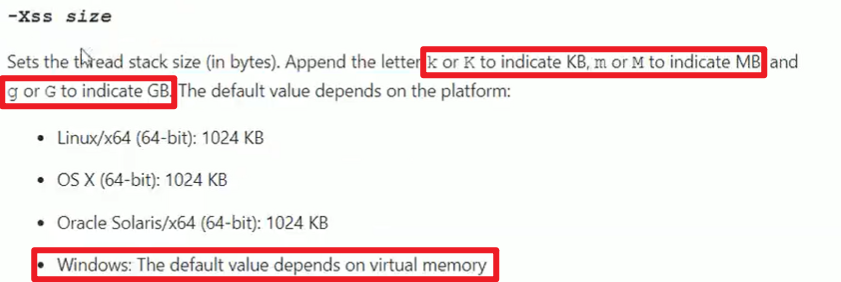
这里为0其实上表示采用系统的默认值,默认值又是多少呢?上图实际上告诉我们了嗷!!!(这个东西在Java的官方文档中都有嗷!!!)
-Xmn:设置年轻代的大小嗷!!!
- 一般自己不用调,采用系统默认的

-XX:MetaspaceSize
典型参数设置案例:
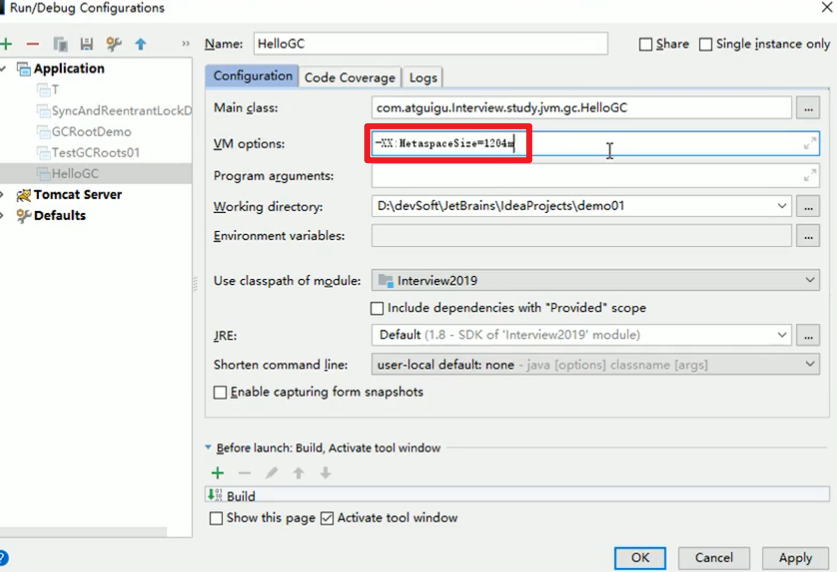
- 设置元空间大小:

- 坑:
虽然说着元空间有这么多可以用,但是元空间自己取的少啊orz,就有可能报OOM:Metaspace

这里默认值就20多M而已啊orz,我内存16个G呢orz。
- 为了保证不会出现OOM:
参数配置实例:
下面是我们要手动配置的参数:
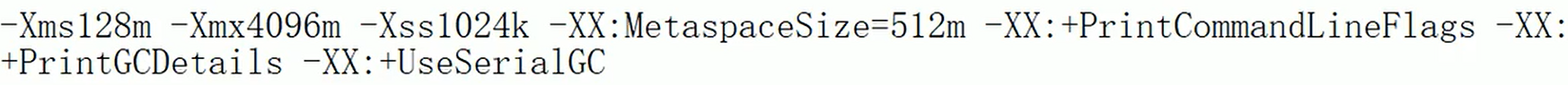
-XX:+UserSerialGC是串行垃圾回收器嗷!!!
默认设置也可以瞅一眼哦:
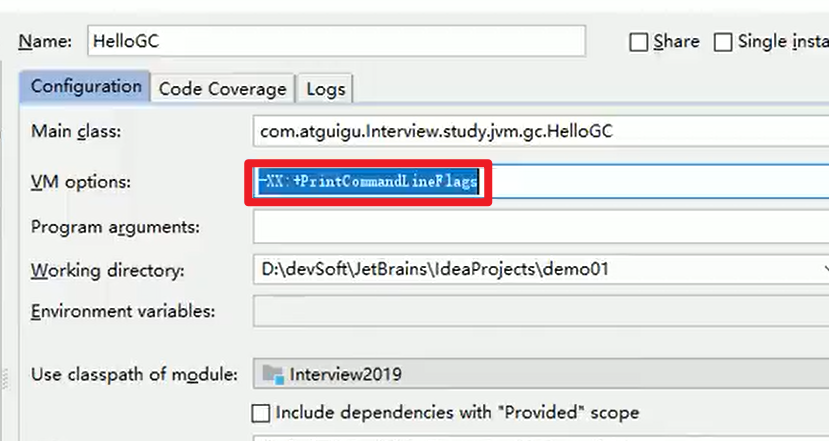
运行结果:
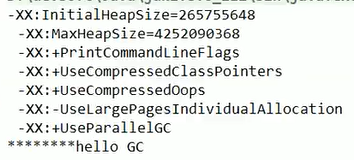
查看默认参数:
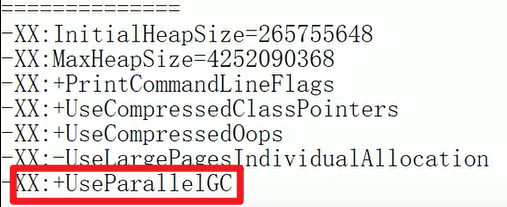
可以看到默认是这些,我们修改之后再康康嗷!!!
我们配置一下上面最开始提到的参数:
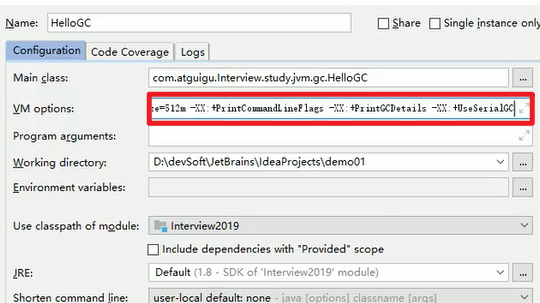
参数设置后的结果:

完全按照我们的配置来启动了嗷!!!
-XX:+PrintGCDetails
- 输出GC的详细收集日志信息
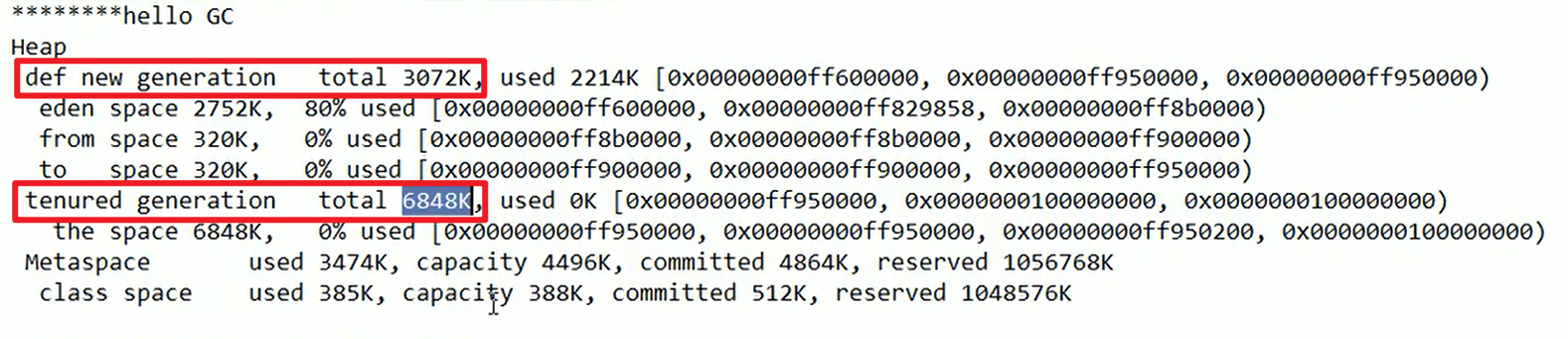
- 可以通过限定堆的大小,然后人为new一个贼大的对象来构造GC的错误嗷,这个过程中会产生GC嗷!!!
上下是对应的嗷!!!
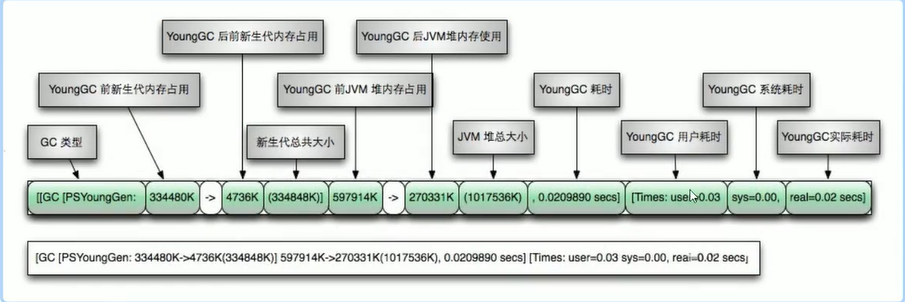

规律:[名称: GC前内存占用 -> GC后内存占用(该区总内存大小)]
SurvivorRatio
- 设置新生代中eden区和S0/S1空间的比例。
- 默认:

- 查看默认参数:

改了之后再打印就是我们修改之后的值了嗷!!!
-XX:NewRatio

设置老年代占比,剩下1给新生代
默认就是1:2嗷!!!
-XX:MaxTenuringThreshold
- 设置垃圾的最大年龄,超过这个年龄就从年轻代进入老年代嗷!!!

通过这个参数就可以设置垃圾的最大年龄嗷!!!
四种引用:
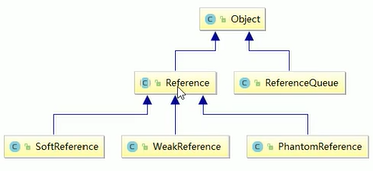
- 强引用(默认支持模式)
Book book = new Book("兔子姐姐的小窝")
- 当内存不足,JVM开始垃圾回收,对于强引用的对象,就算是出现了OOM也不会对于这个对象进行回收嗷!!!死都不收!!!
- 软引用
- 内存足够的前提下我不收(就算手动GC也不回收哦,我够用嘛!!!),内存不够的情况收了你,来保证尽量不要出现OOM嗷!!!
- 软引用是相对强引用弱化了一些的引用,需要用
java.lang.ref.SoftReference类来实现,可以让对象豁免一些垃圾回收。 - 通常用到对于内存敏感的程序中,高速缓存中就有用到嗷!!!


注意上面这里哈,实际上告诉了我们获得软引用的方式嗷!!!
- 故意整活:
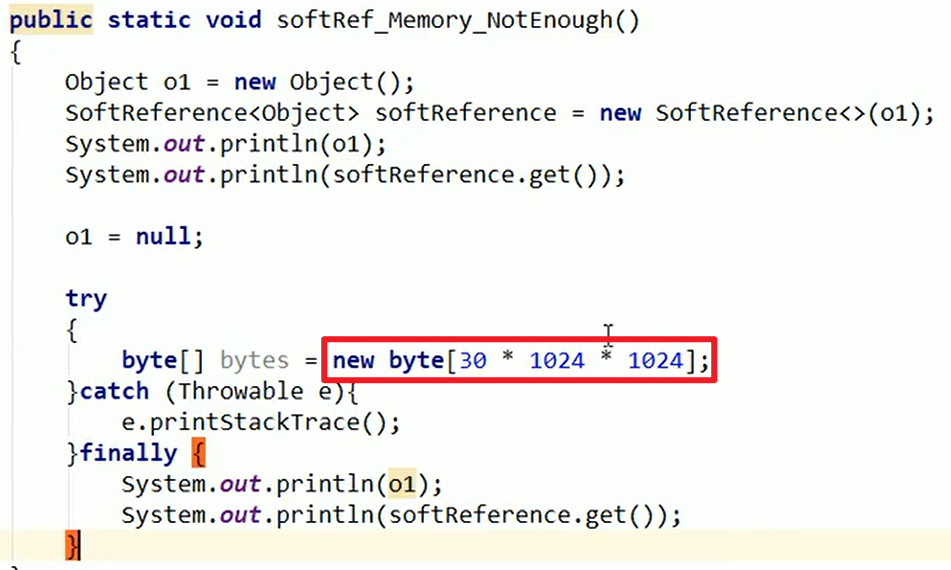
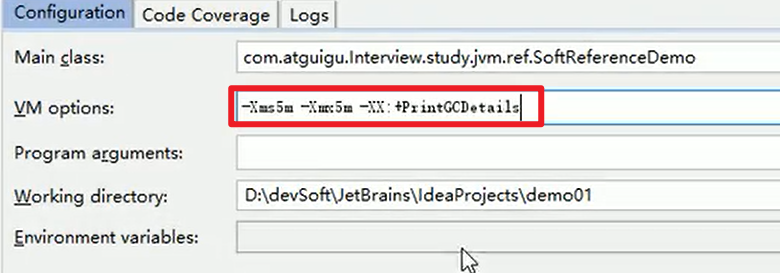
5M的小内存,分配了30M的对象,必垃圾回收嗷!!!
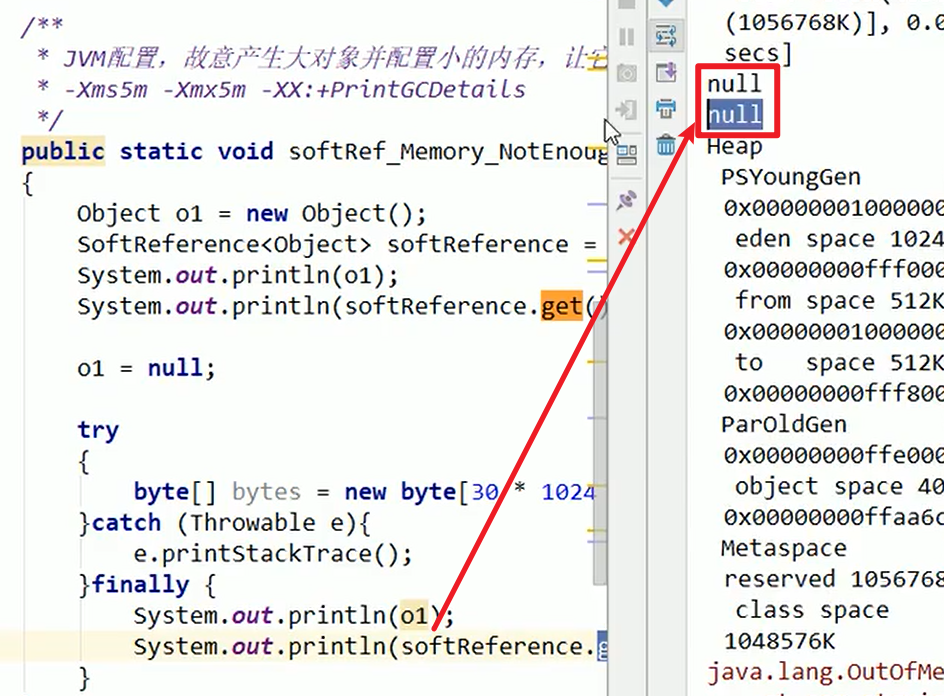
- 使用场景:

Map<String,SoftReference<Bitmap>> imageCache = new Hashmap<String,SoftReference<Bitmap>>();
在保证我程序正常运行的情况下,把空间给你多存一点照片,提高你的效率,这是好事儿。但是如果我都不够用了,那我就不客气了,把你收了嗷,保证不OOM最重要嗷!!!
- 弱应用
- 不管够不够用,垃圾回收一律都收掉嗷!!!不管啥情况,回收我就收了你!!!
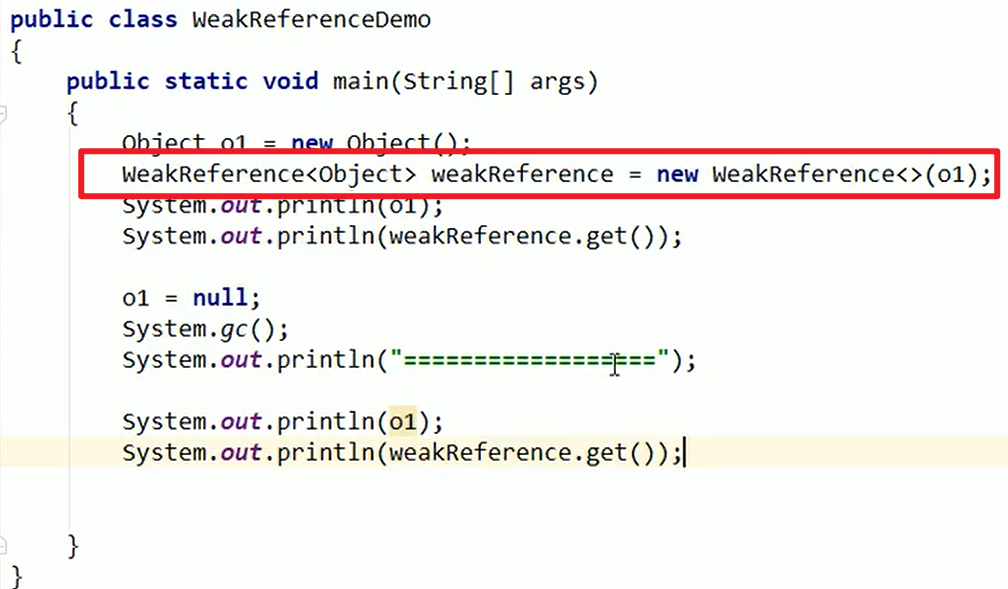
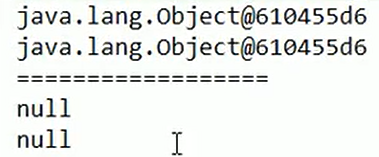
- 使用场景:
WeakHashMap
key是弱key,如果被垃圾回收了的话,这个entry就会被自动移除嗷!!!
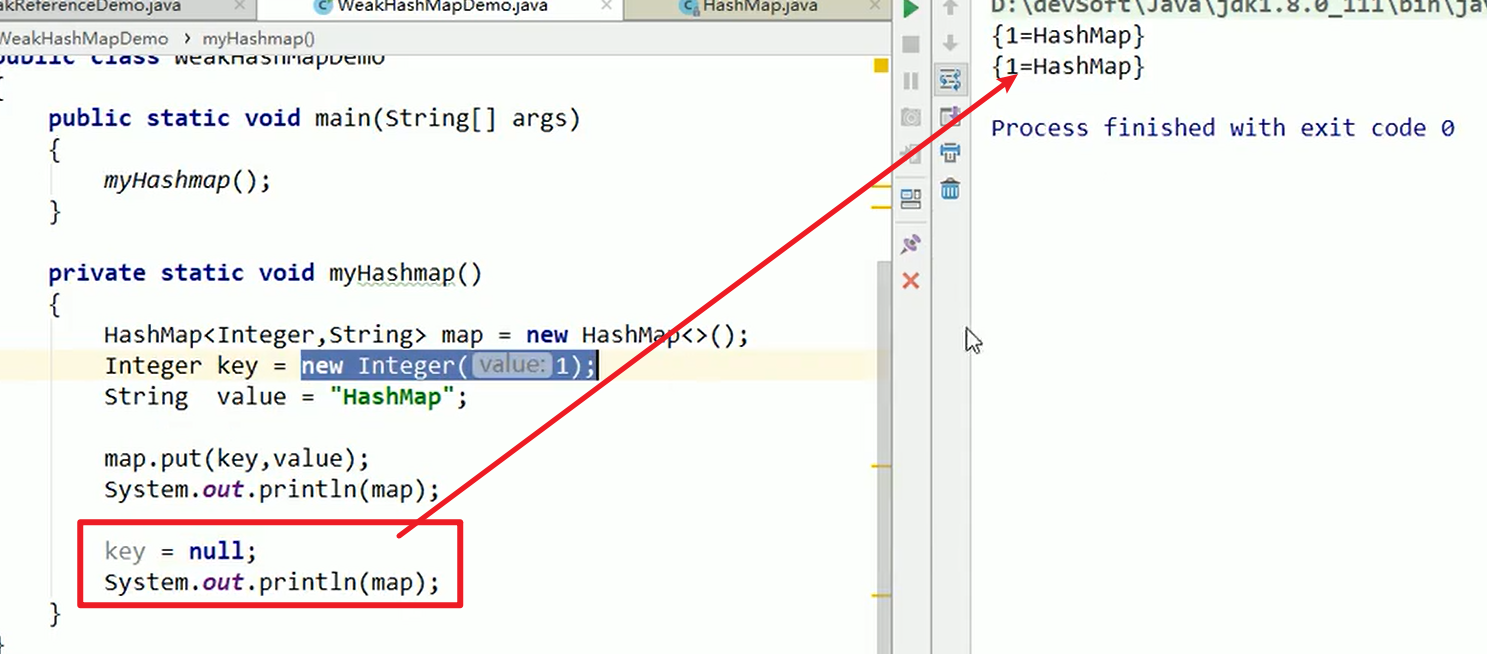
1 | |
底层本质是一个Node的数据结构,实现了Map的Entry,比如上面,本质上put的时候,map底层新建立了一个Node,Node中的key的引用就是传入的Integer的应用,因此如果你修改的是key的话,实际上对于对应位置的引用没有任何的改变,因此这个打印出来的结果还是上面那个结果嗷!!!
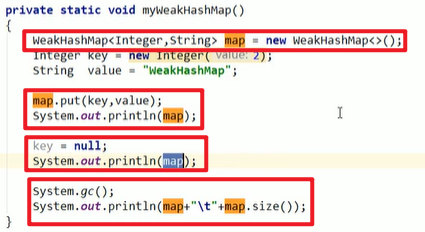
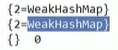
这个key不会阻止垃圾回收嗷,如果key失效了,就会被remove嗷!!!
适用于对于内存敏感的使用嗷!!!
- 虚引用:
- 又被称为幽灵引用



- 回收之前需要被引用队列保存一下嗷!!!
- 弱引用队列的例子:

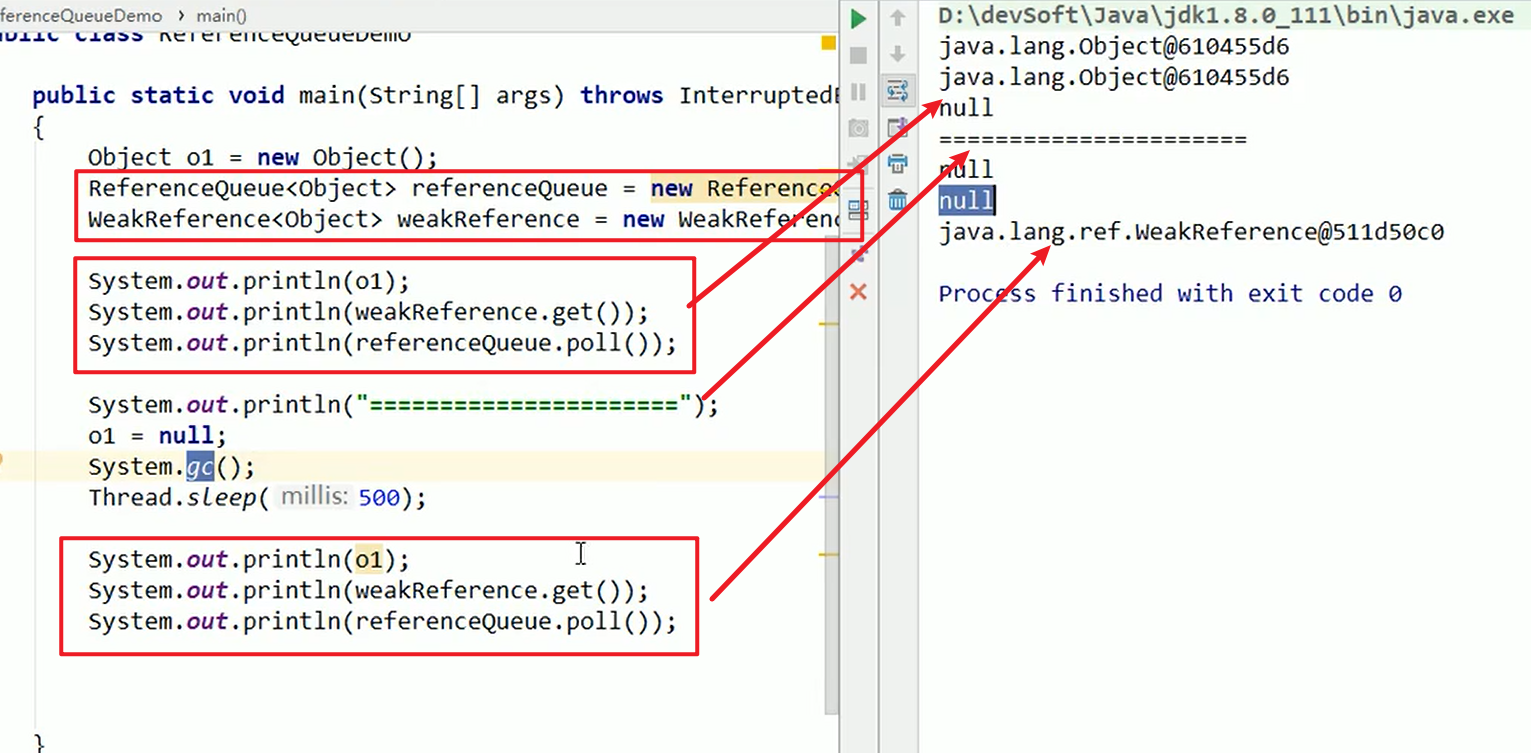
- 虚引用队列的例子:

重点就是后续操作,可以做一些通知之类的嗷!!!
GCRoots + 四大引用小总结:
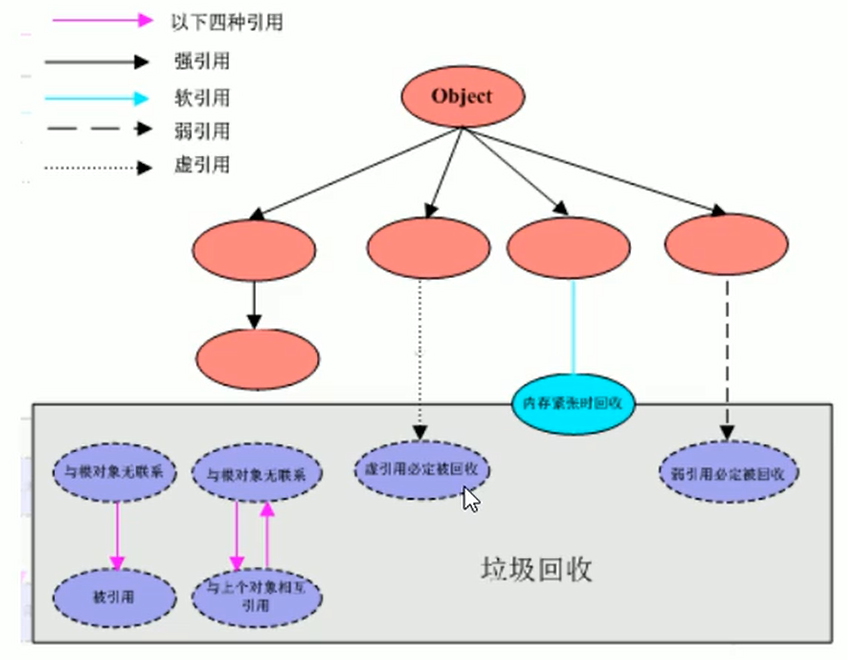
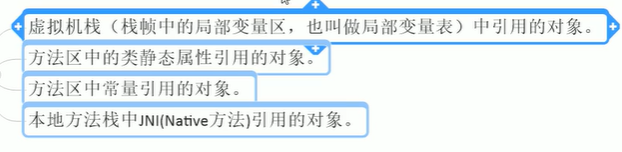
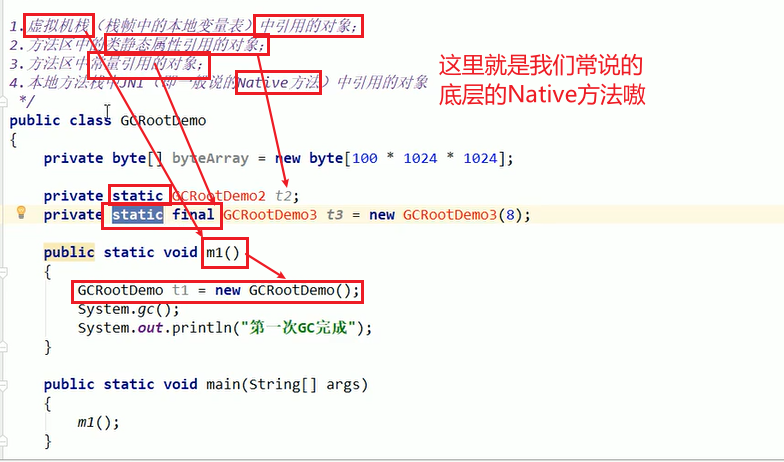
- Java中可以作为GC Roots的对象:
- 虚拟机栈(栈帧中的局部变量区,也叫做局部变量表)。
- 方法区中的类静态属性引用的对象。
- 方法区中常量引用的对象。
- 本地方法栈中JNI(Native方法)引用的对象
12. SOFE
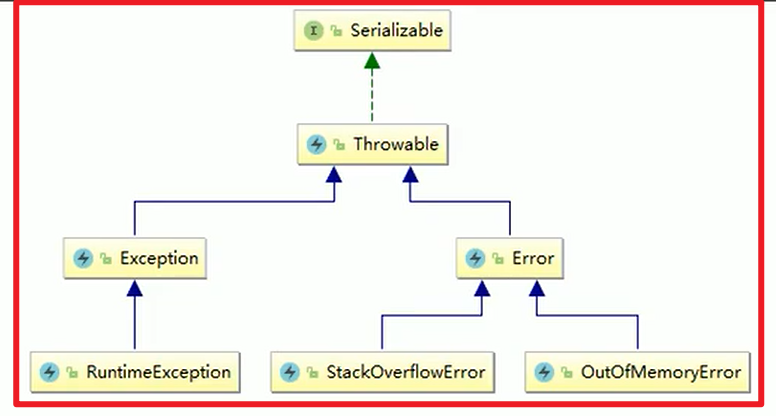
各种异常分类:
栈管运行,堆管存储。
- StackOverflowError
这里的栈就是程序运行时对应的栈,由于内存不大,在调用方法的时候就会压栈,我们可以人为构造循环调用方法来制造SOFE:
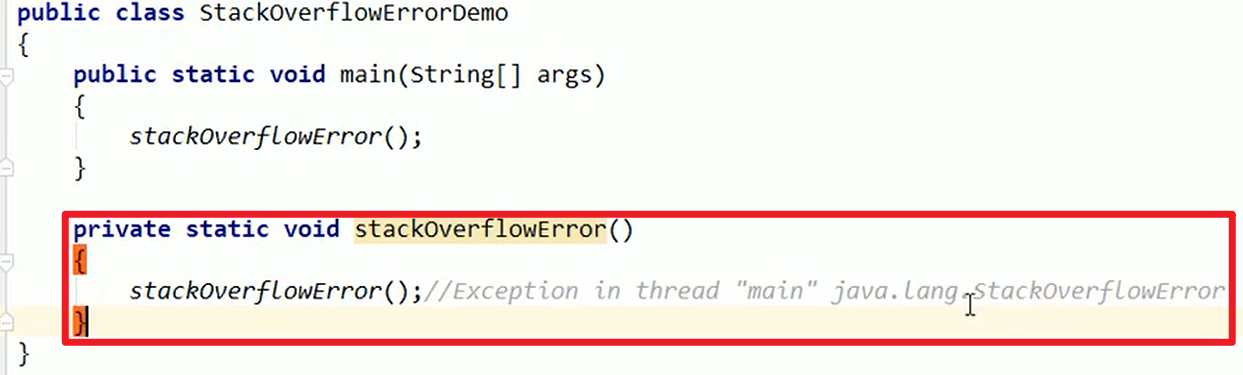
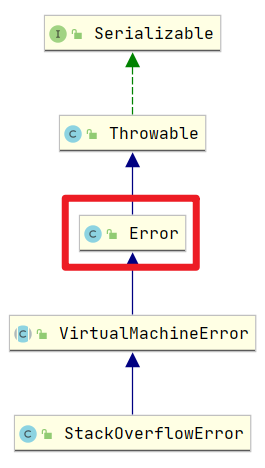
这个是错误,不是异常嗷!!!异常是Exception,错误是Error:
栈爆了。
- OOM:java heap space
先把heap的大小调小:
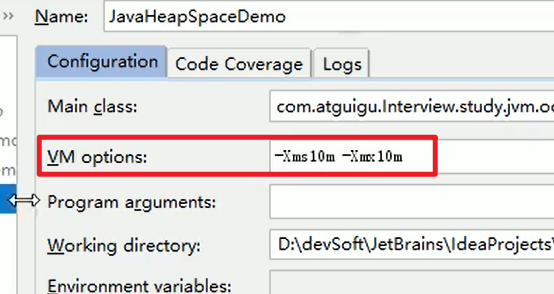
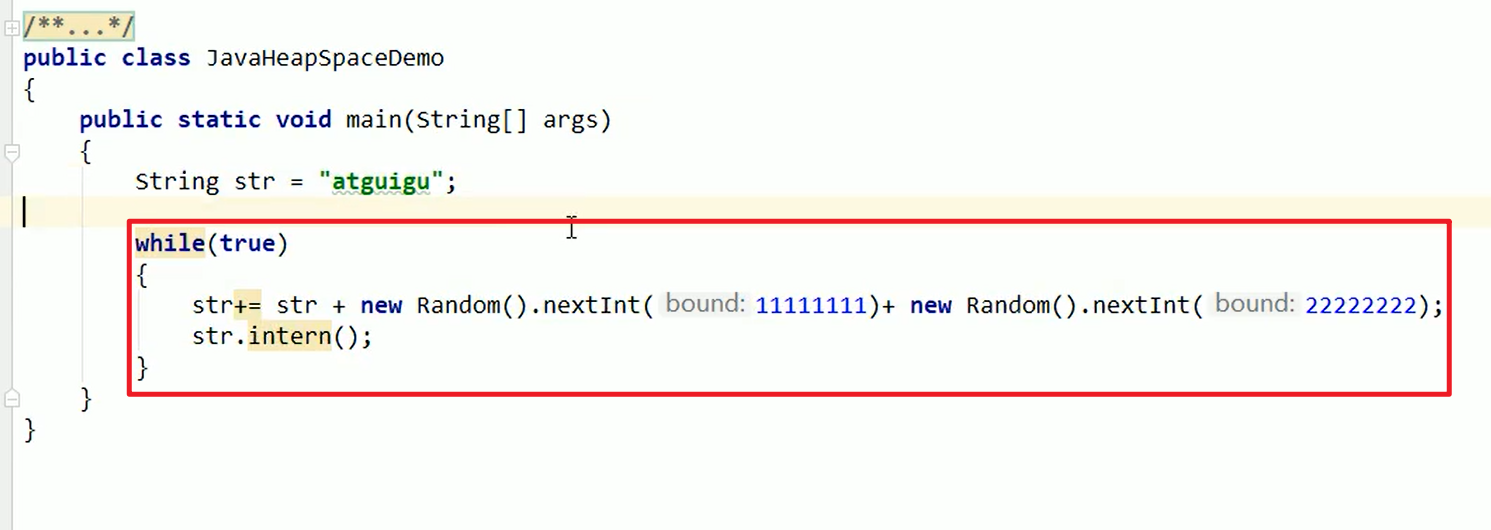 不断新建对象,这样就可以了嗷!!!
不断新建对象,这样就可以了嗷!!!
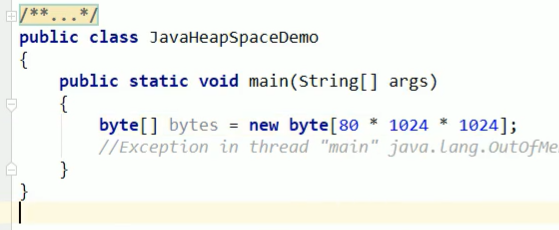
上面这样也行,直接new一个80M的数组,上面调过堆内存只有10M,这个对象远远大于10M。

这个也是个Error嗷!!!堆爆了。
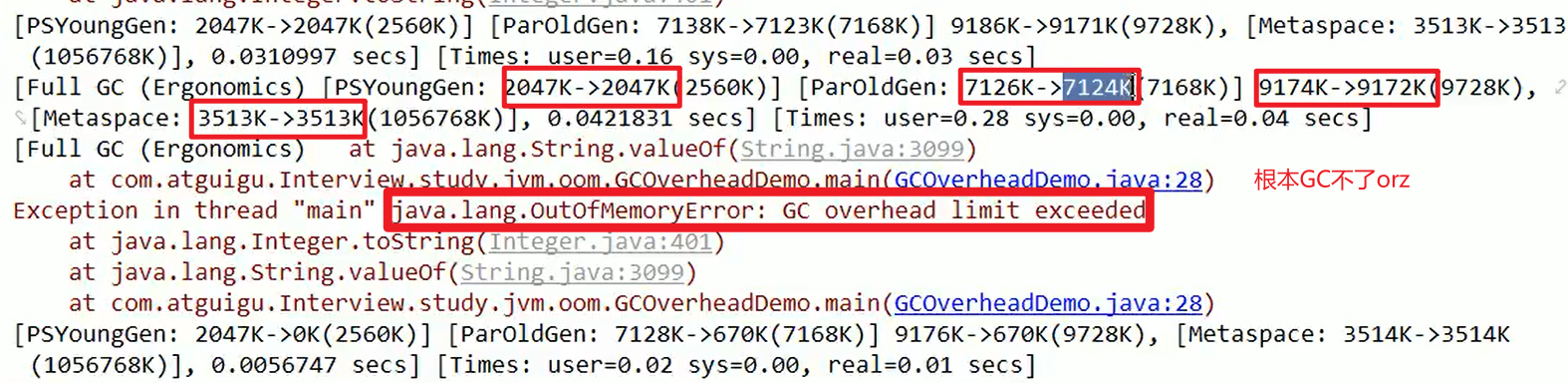
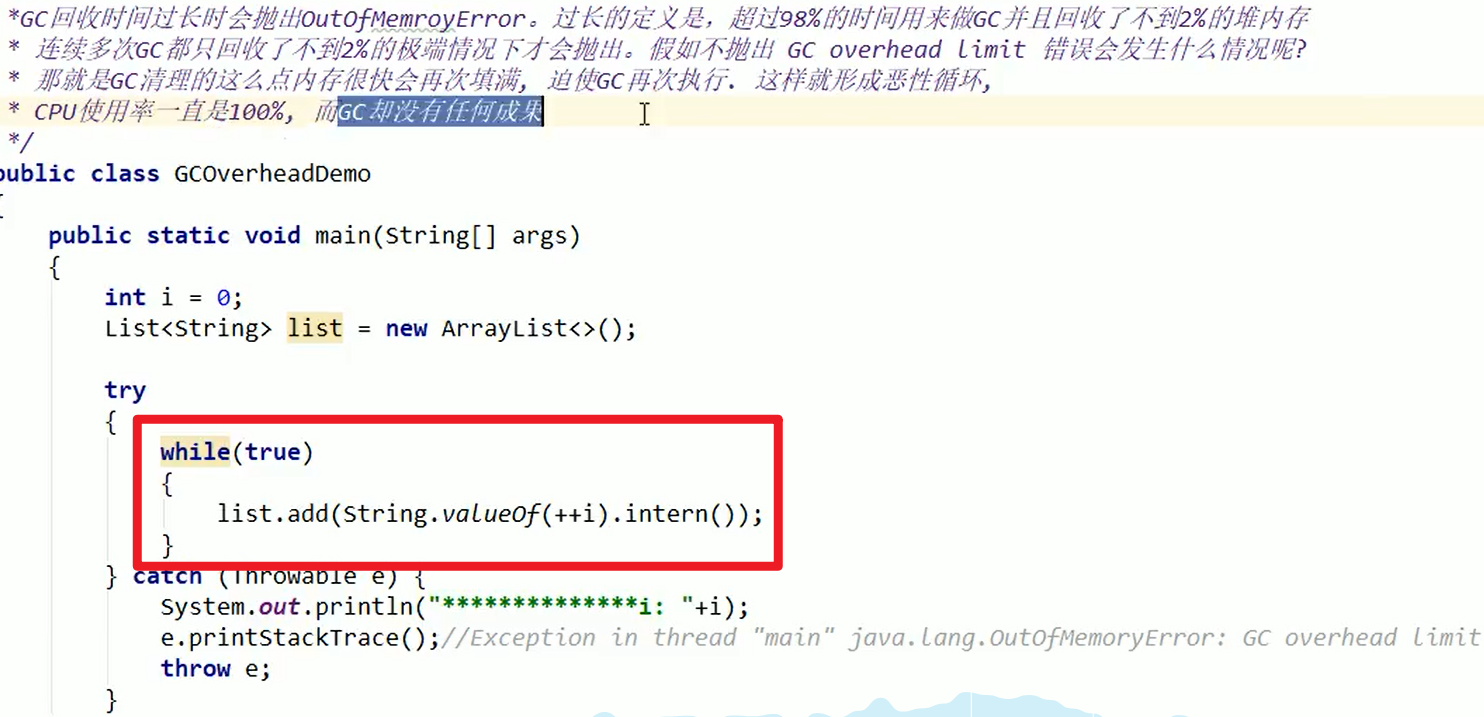
- OOM:GC overhead limit exceeded
- 程序特别诡异,Java内存急剧上升,大量对象被装载被创建出来。启动GC之后,超过最高警戒了。

- GC反复执行,恶行循环,执行存在非常大的问题嗷!!!
- 实例:

- OOM:Direct buffer memory
- 是由于底层NIO引起的嗷!!!

里面够用,外面用满了orz。默认堆外可用内存是总内存的1/4嗷!!!
- 示例代码:
查看本地可用的JVM内存:
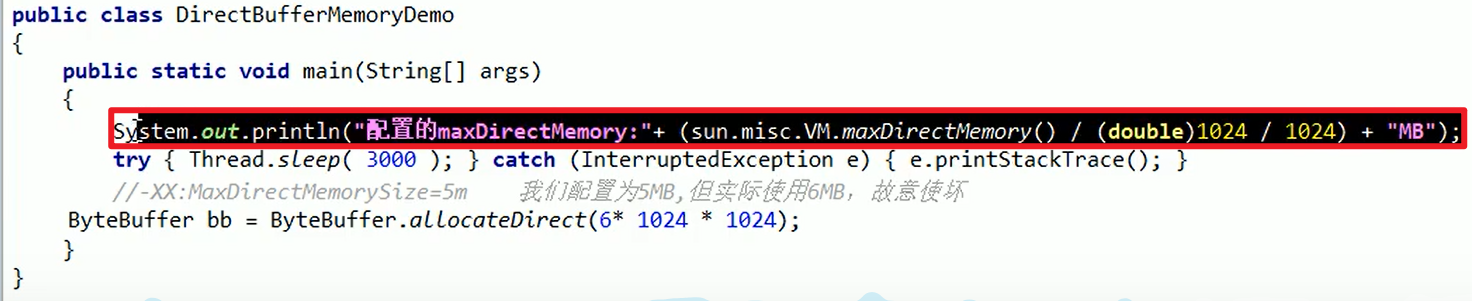
内存的图:

内存:

- 下面是示例哈,把外部内存的可用参数调成5M之后,在内存中new一个6M的对象,就会出现上面的问题嗷!!!
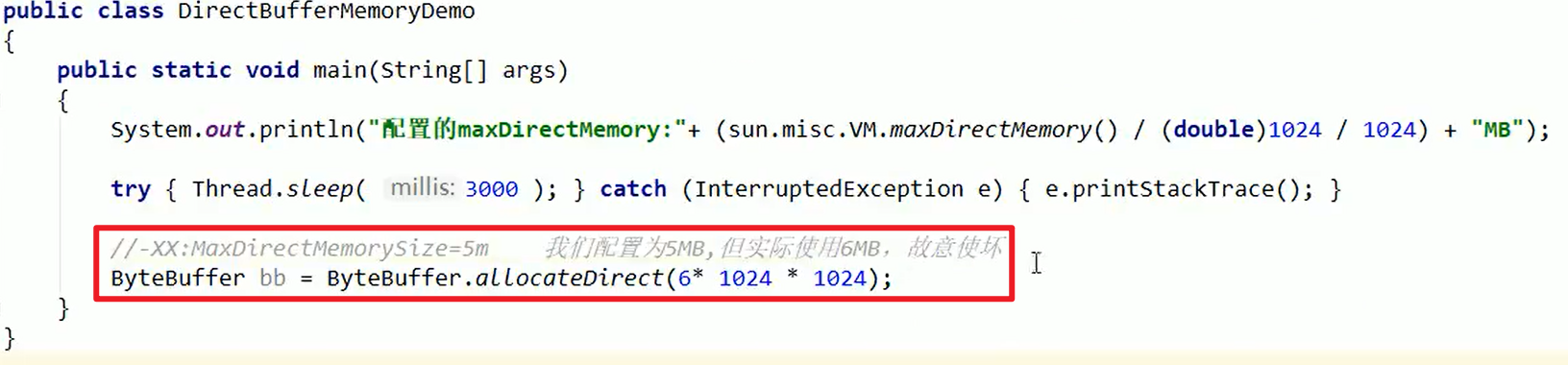

这个问题就是由于NIO所引出的哦,面试的时候就有可能问你这个Direct buffer memory的问题,来刺探你是否使用过NIO嗷!!!
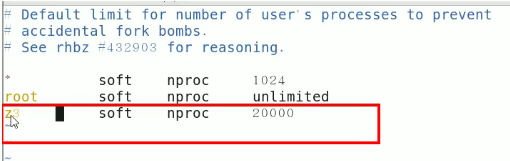
- OOM:unable to create new native thread

- 准确的讲,该native thread异常与对应的平台有关。说白了就是:创建的线程的数量超过了系统允许的最大值嗷,导致出现了这个异常嗷!!!!!
- 示例:

Linux中默认允许单个进程可以创建的线程数是1024嗷!!!

解决方案:
- 减少跑起来的线程数
- 扩大底层机器允许的最大线程数


注意,linux下的root用户对于线程是没有上限的,其他用户默认一个进程最多创建的线程数就是1024,修改:
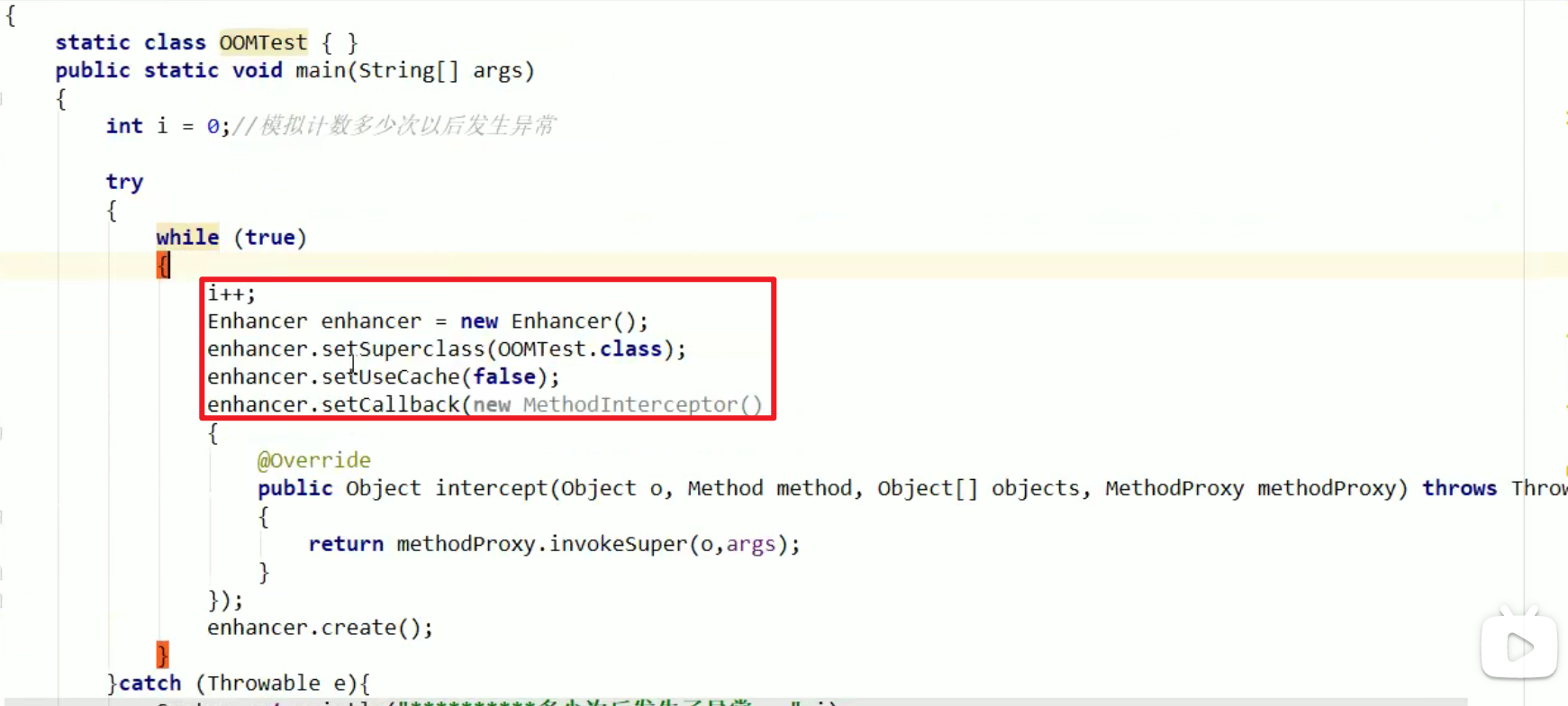
- OOM:Metaspace
- 元空间是方法区,方法区装类的模板,常量池啊之类的东东。

- 元空间与持久代的最大区别:Metaspace并不在虚拟机内存中,而是使用本地内存。

- 示例:
设置元空间的大小为8M:

GC垃圾回收器的理解:
- GC有四种垃圾回收算法(引用计数/复制/标记清除/标记整理),垃圾收集器本质上就是这些算法的落地实现。
- 没有完美的垃圾收集器,都有具体的使用场景嗷!!!
- 四种垃圾收集器
垃圾收集器策略:
Serial
- 串行
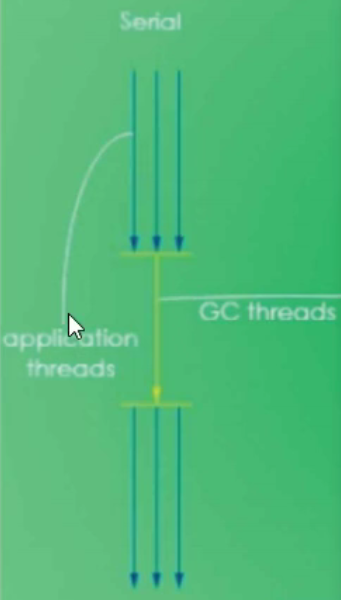
- 为单线程环境设计,只使用一个线程进行回收,并且会暂停全部的用户线程,不适用于服务器环境。(中间业务线程被打断了orz)
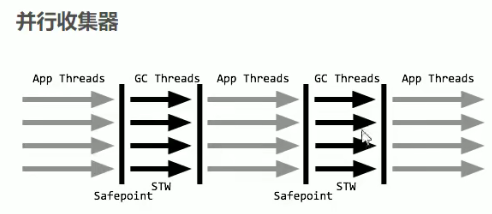
Parallel
- 并行
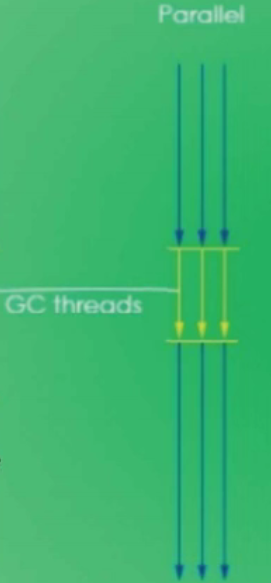
- 多个垃圾收集线程并行工作,此时用户线程是暂停的,适用于科学计算 / 大数据处理等弱前台交互系统。
- 停顿回收垃圾的时间回比串行少,但是仍然和前面一样的,需要把所有的用户线程停下来!!!
CMS
- 并发垃圾回收器(并发标记垃圾清除)
- 用户线程和垃圾回收线程同时执行(不一定是并行,有可能交替执行),不需要停顿用户线程。互联网公司大多都用CMS,它适用于对于响应时间有要求的场景。

小总结:
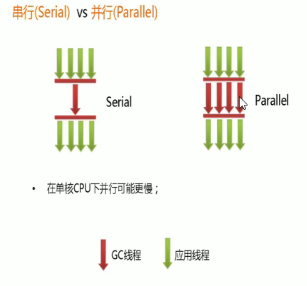
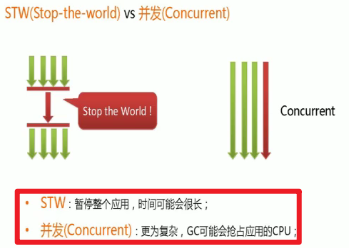
G1
- 将堆内存分割为不同的区域,然后并发对于不同的区域进行垃圾回收嗷!!!
ZGC
G1的升级版本
比较新,Java12之后才出现的,需要自己下去看看嗷!
服务器默认垃圾收集器查看:
- GC深透明细,思想:四大垃圾回收算法 —>>> 落地实现

- 打印出垃圾收集器:

默认使用的是并行垃圾回收器
- 设置垃圾收集器:
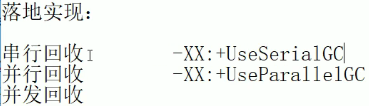
默认垃圾收集器有哪些?
- CMS(ConcMarkSystem)
- 总共理论上有七种的,UseSerialOldGC和引用计数一样,已经被这个时代废除了,源码中也看不到了,但是它曾经存在过嗷!!!
- 查看某个运行中的进程的垃圾回收器:

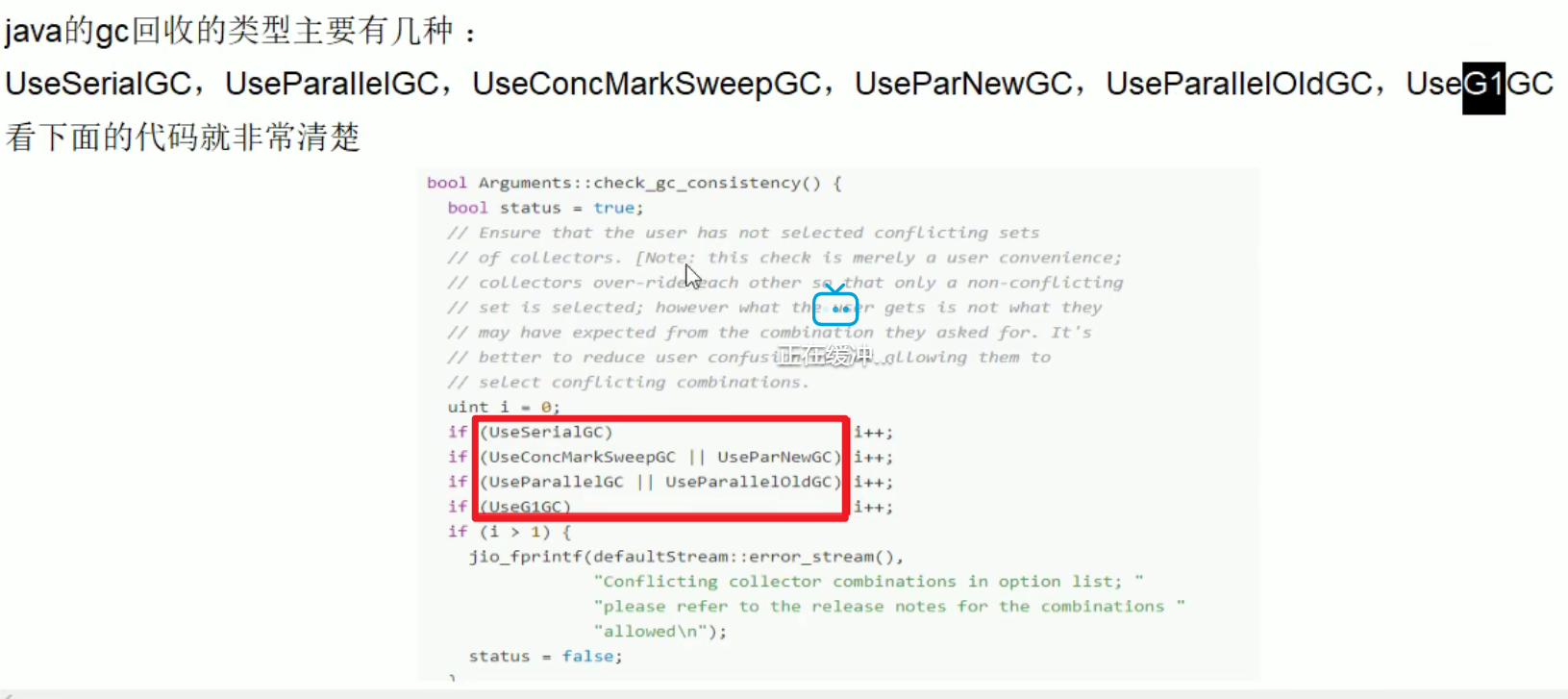
七种垃圾收集器:
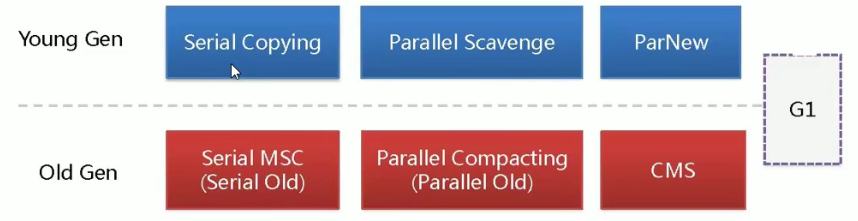
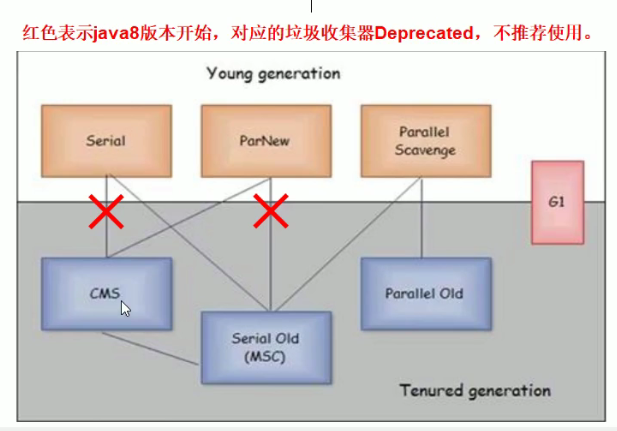
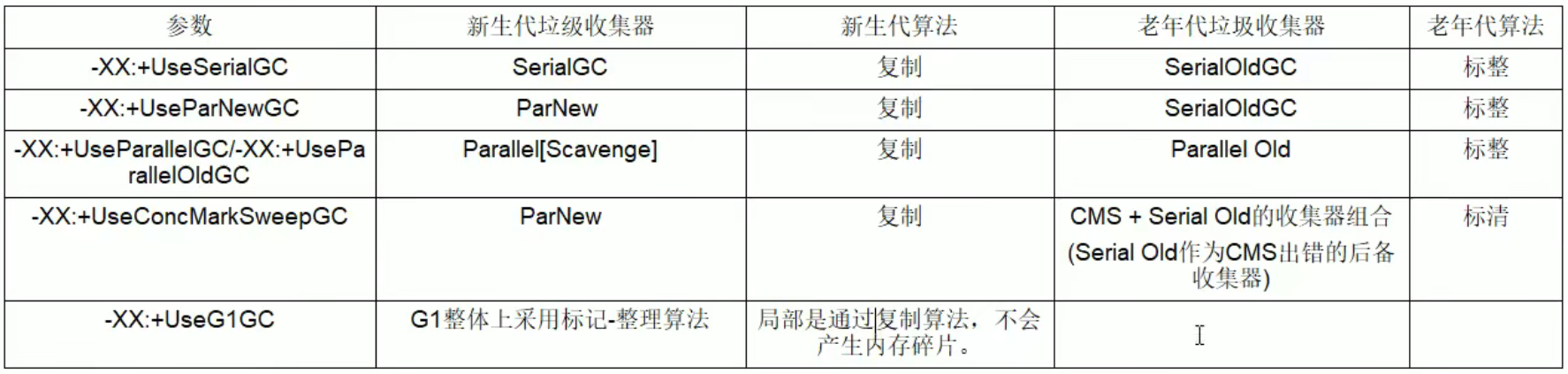
- 年轻代更多使用复制算法,老年代我们更多使用标记清除或者标记整理算法。
部分参数说明 / C/S模式有什么区别
参数:
- DefNew - Default New Generation
- Tenured - Old
- ParNew - Parallel New Generation
- PSYoungGen - Parallel Scanvenge Young Generation
- ParOldGen - Parallel Old Generation
C/S模式:
- 只需要掌握Server模式即可,Client模式基本不会用
- 操作系统:

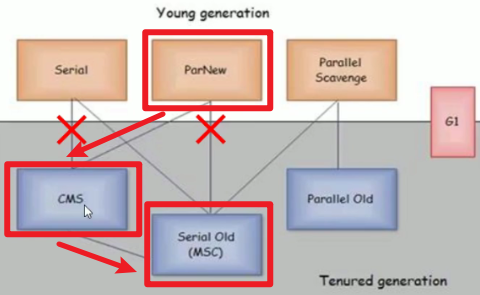
新生代:
- Young和Old的垃圾收集器是搭配使用的嗷,注意上面那张图图捏!!!新生代的指定了,老年代的基本上就确定了嗷!!!
Serial / Serial Copying:
- 串行+串行
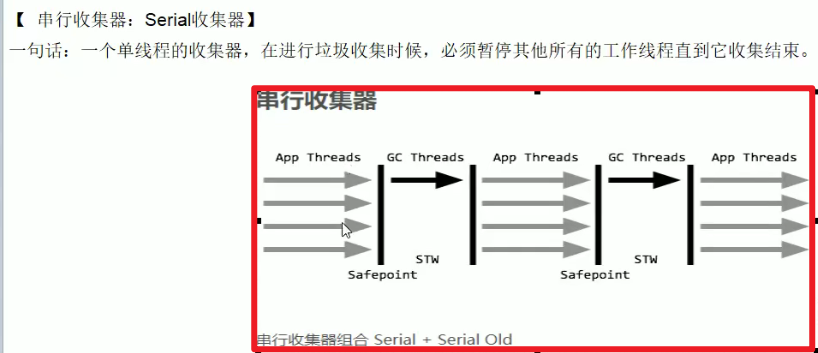
简单高效,没有线程交互的开销,可以获得最高的单线程垃圾收集效率,因此Serial垃圾收集器依然是Java虚拟机运行在Clinet模式下默认的垃圾收集器

- Y和O都是Serial回收,只是回收过程中,采取的回收算法不一样而已嗷!!!
ParNew:
- 并行+串行
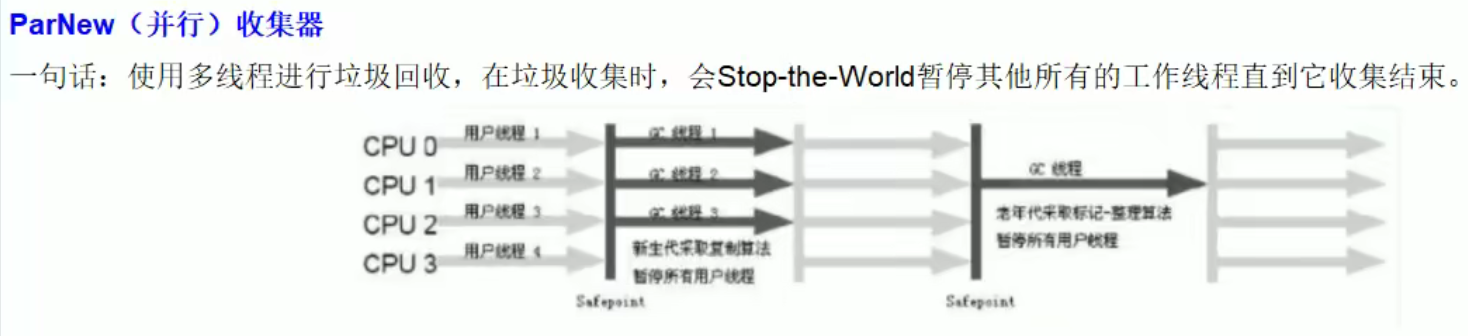
- 年轻代的ParNew是搭配老年代的CMS使用的嗷!!!

ParallelScanvenge:
- 并行+并行
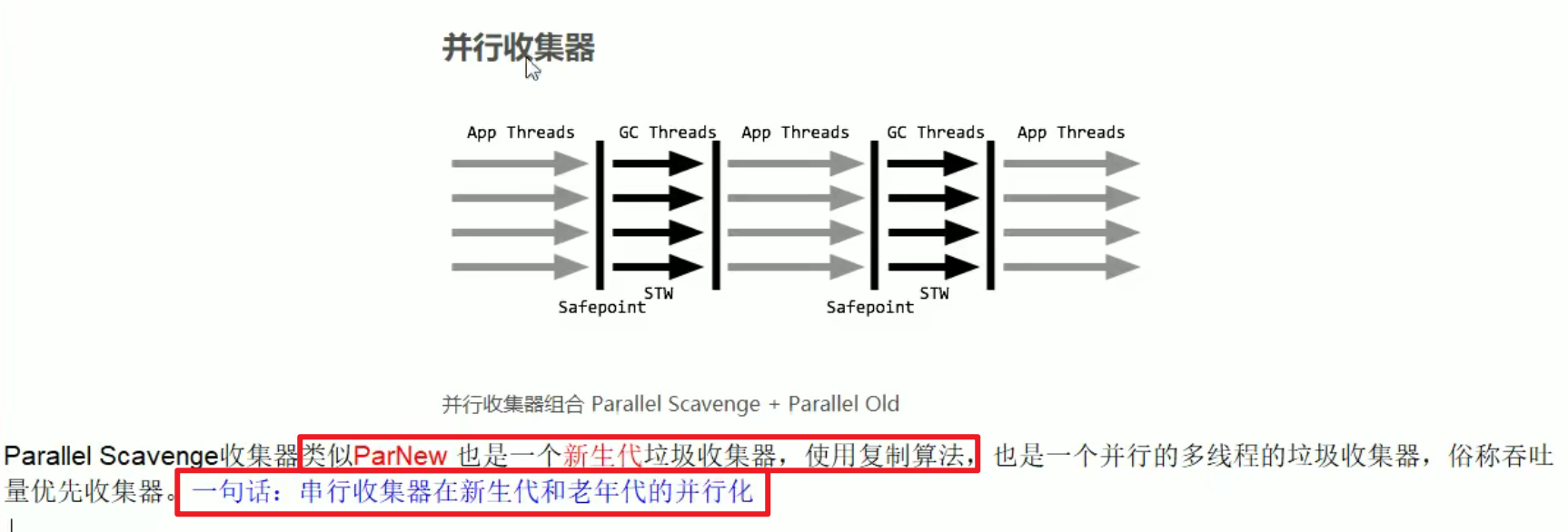
串行收集器在新生代和老年代的并行化

- 配置这个模式:


老年代:
Serial Old / Serial MSC:
- 老年代的串行收集器
- 单线程+标记整理算法,这个收集器也是主要运行在Client默认的java虚拟机默认的老年代垃圾收集器。


- 已经优化掉了,都不用了都orz
Parallel Old:
并行+并行
Parallel Scavenge的老年代版本,使用多线程的标记-整理算法,Parallel Old收集器在1.6才开始使用嗷!!!

- 不加的话默认使用的是
UseParrellelGC,就在上面,所以老年代默认的也是使用Parallel Old嗷!!!
CMS:
- 并发标记清除GC(CMS)
- 好处:解决空间和时间,坏处:内存碎片
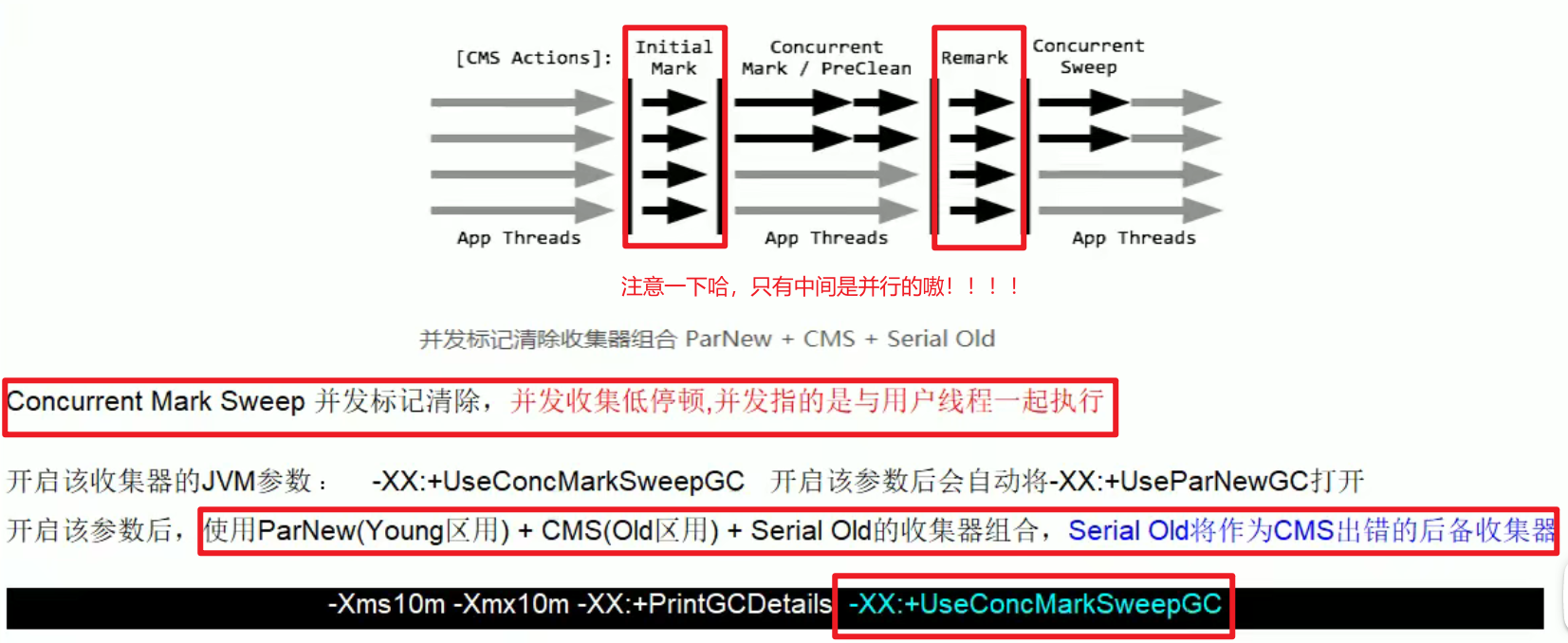
- 过程:

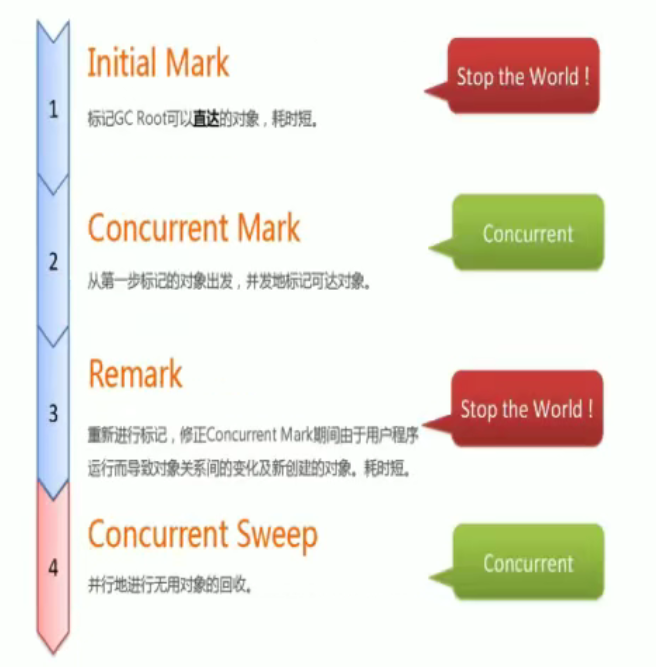
1,3要停,2,4不要停:
重新标记:

并发清除:

标记和清除这两个最耗时的操作,可以并发执行嗷!!!
- 优缺点:
- 优点:并发收集低停顿
- 缺点:并发执行,CMS在收集与应用线程会同时增减对于堆内存的占用,CPU的压力比较大!!!CMS必须在老年代堆内存用尽之前完成垃圾回收,否则就会回收失败,触发担保机制。串行老年代收集器将会以STW的方式进行一次GC,从而造成较大停顿时间。此外,标记清除算法会导致大量碎片嗷!!!

- 同时配置多个垃圾收集器:

关联激活,完全没有必要这么去写嗷!!!
选择合适的垃圾收集器:
- 适用场景:
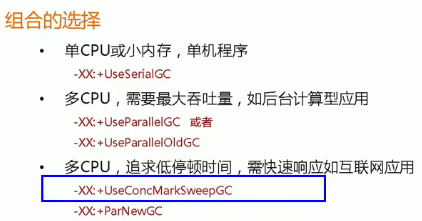
- 对应关系:
G1垃圾回收器:
- G1又被称为
Garbage-First嗷!!!
- 打印结果显示:

别的都有两个区哦这里,G1只有一个garbage-first heap,这就是上面所提到过的,G1横跨两个区哦!!!

G1是一种服务端的垃圾收集器,应用在多处理器和大容量内存环境中,实现高吞吐量的同时,尽可能满足垃圾收集暂停时间的要求。
特性:
- 像CMS一样,能与应用程序并发执行
- 整理空闲时间空间更快
- 需要更多的时间来预测GC停顿时间
- 不希望牺牲大量的吞吐性能
- 不需要更大的Java Heap
G1就是为了取代CMS而被设计的,不会产生很多内存碎片,而且添加了预测机制,用户可以指定期望停顿时间嗷!!!
Eden和Survivor和Tenured等区域不再是连续的,而是变成了一个个大小一样的region。

Java9开始就作为默认的垃圾收集器了嗷!!!
- 特点:

底层原理:
Region区域化垃圾收集器,化整为零,避免全内存扫描,只需要按照区域进行内存扫描嗷!!!

G1的改变:
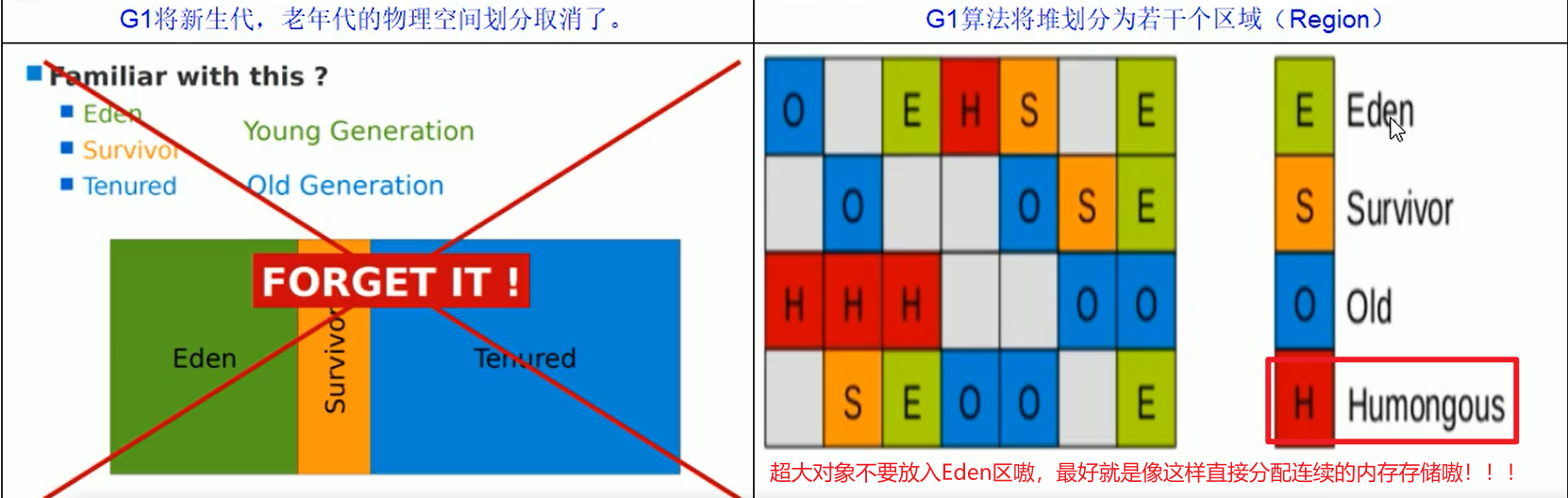
化整为零,避免了全内存扫描嗷!!!相当于把垃圾回收的基本单位变小了orz,粒度小了,并发度就高了嗷!!!

大的对象,也可以通过紧凑的方法来腾出空间,边清理,边内存整理,当然效率高哇!!!
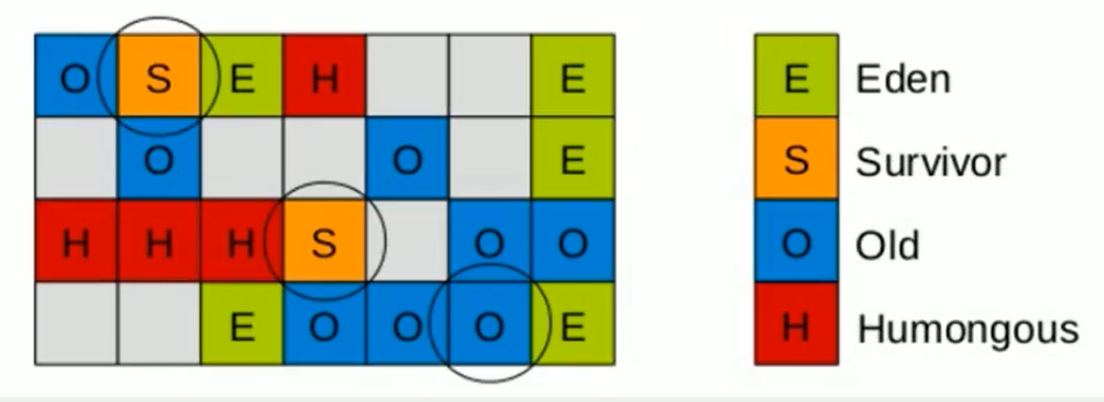
G1分为了四个区嗷:
- Eden区
- Survivor区
- Old区
- Humongou大对象区
垃圾回收流程:
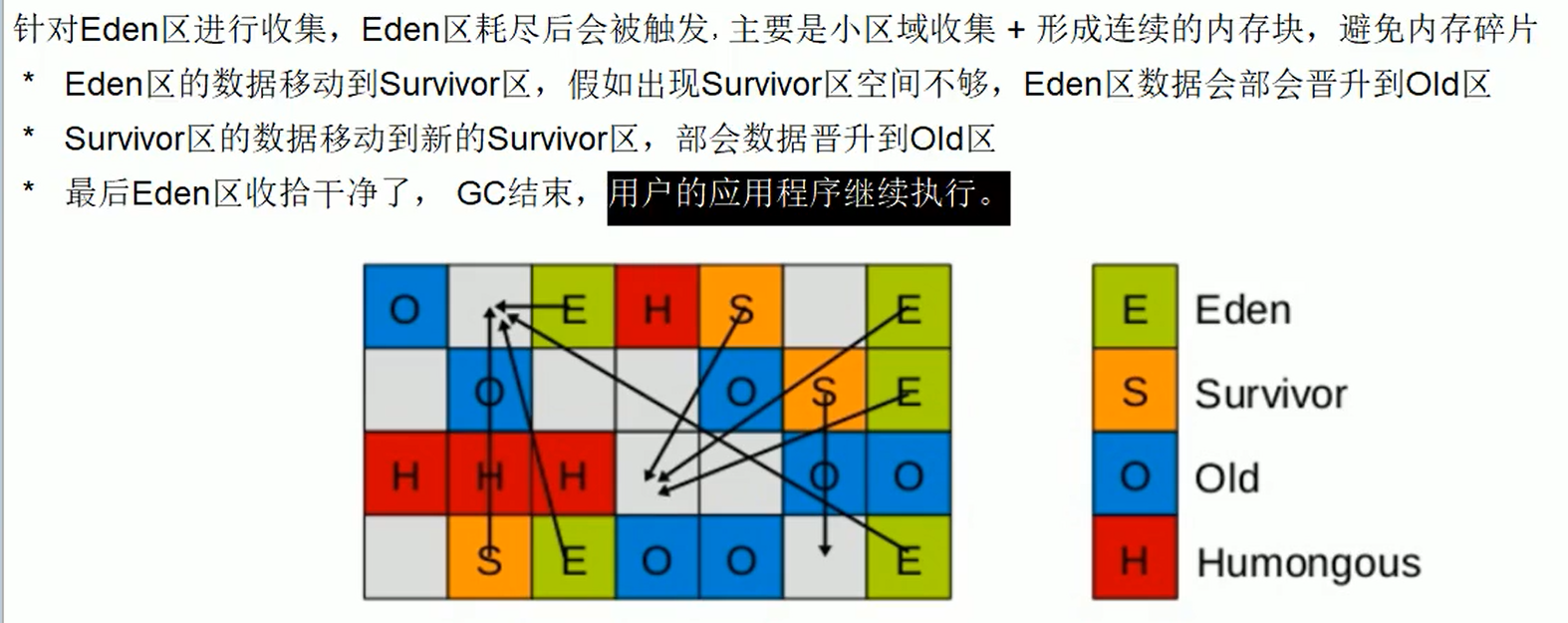
G1中的内存处于一个动态变化的过程中嗷!!!有点像分页算法???????这种熟悉的感觉,emmmmmm
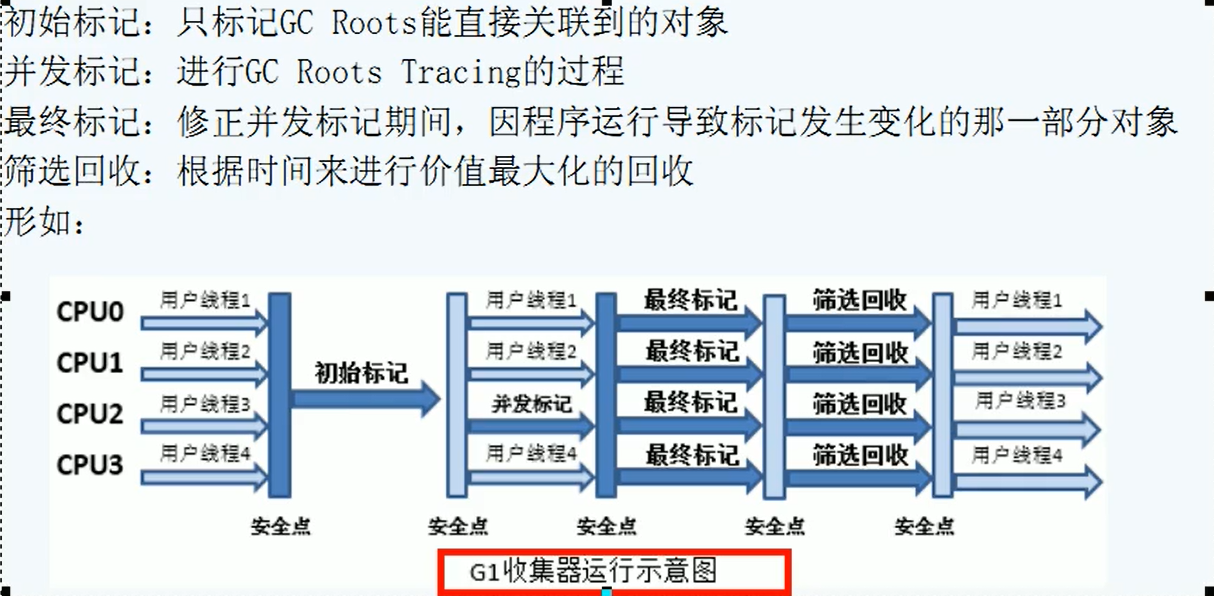
回收步骤倒是和CMS一模一样,这不就和HashTable和ConcurrentHashMap一样嘛orz,对于每一个小块,采用的都是同样的CMS算法嗷!!!
- 好多参数嗷!!!

这些都可以尝试着看一下哈!!!一般都是用默认值的嗷!!!
G1和CMS相比的优势
- G1没有内存碎片嗷!!!
- G1可以精确控制停顿嗷!!!
JVMGC + SpringBoot微服务部署
JVMGC –> 调优 –> 应用于微服务
步骤:
- IDEA开发完成微服务工程
- maven进行clean和package
- 微服务启动的时候,同时配置我们JVM / GC的调优参数:
- 内
- 外 => 中带你
- 公式:
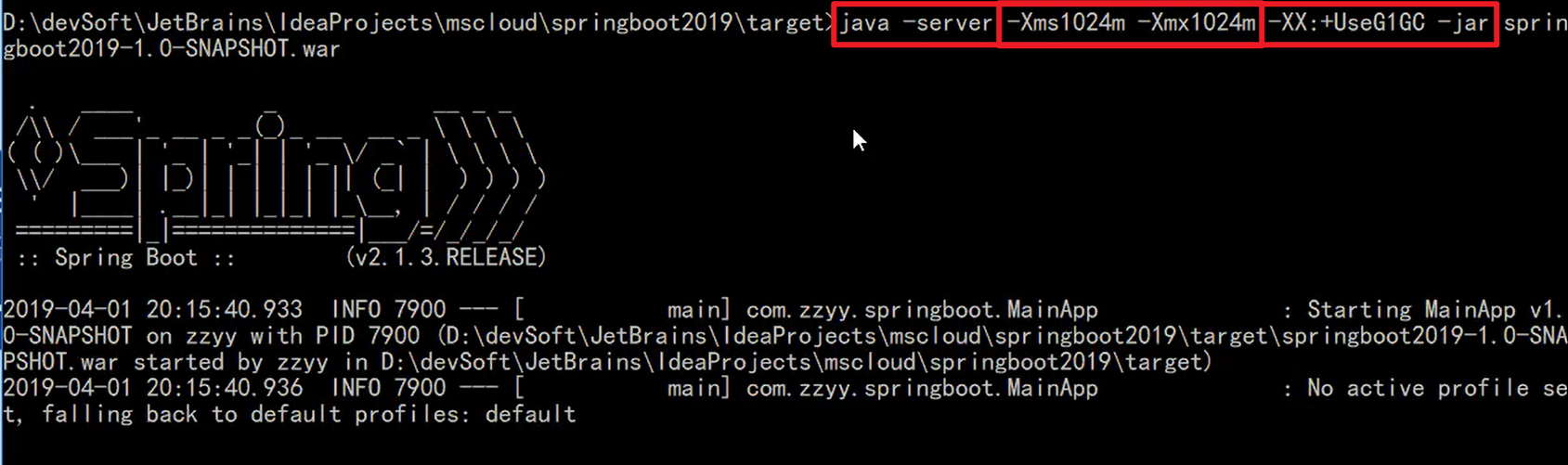
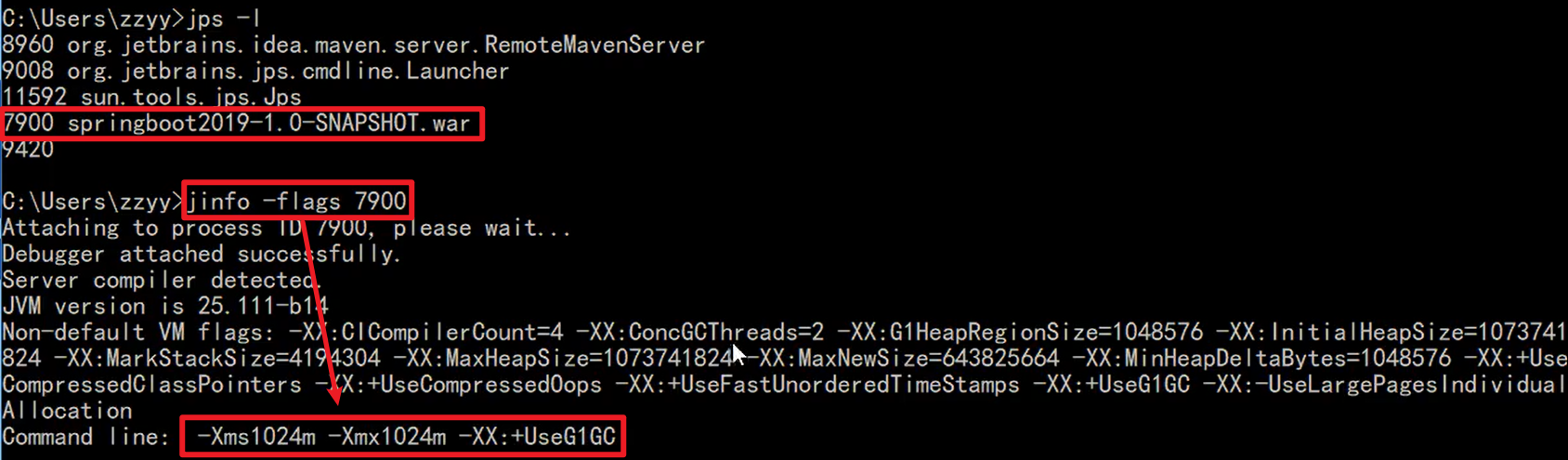
java -server jvm的各种参数 -jar jar/war包的名字
示例:
13. Linux相关
生产环境服务器变慢了
top:
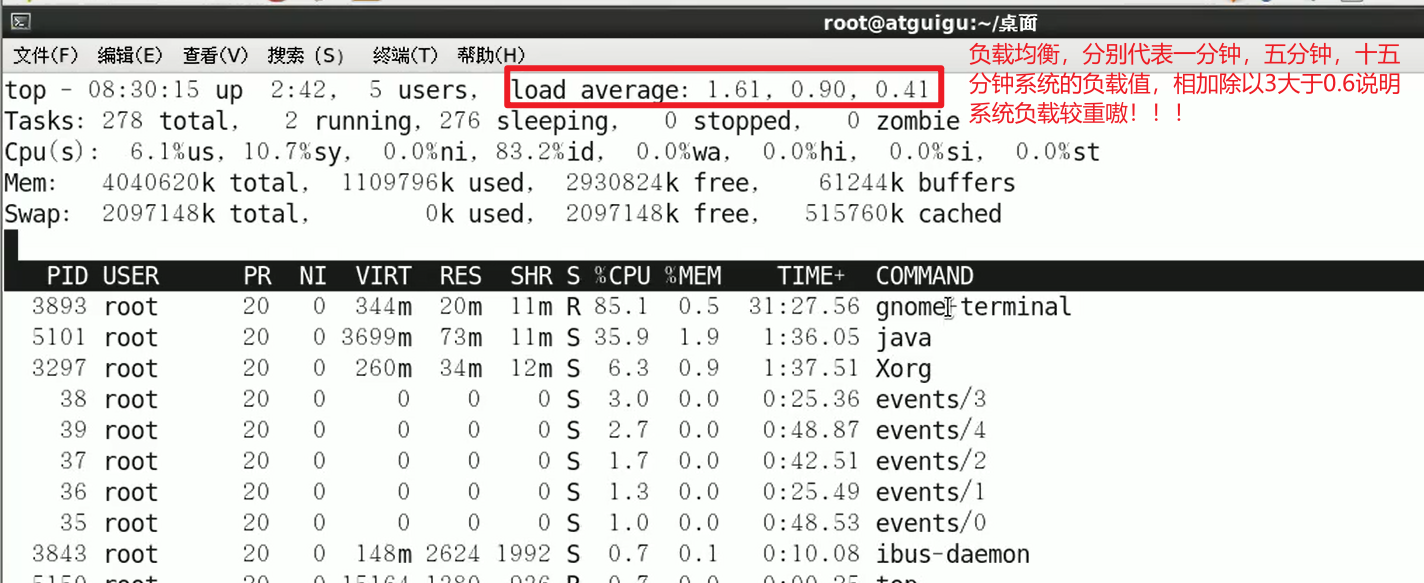
- 在top的情况下,按下
1,就会显示所有的CPU的占用情况嗷!!!
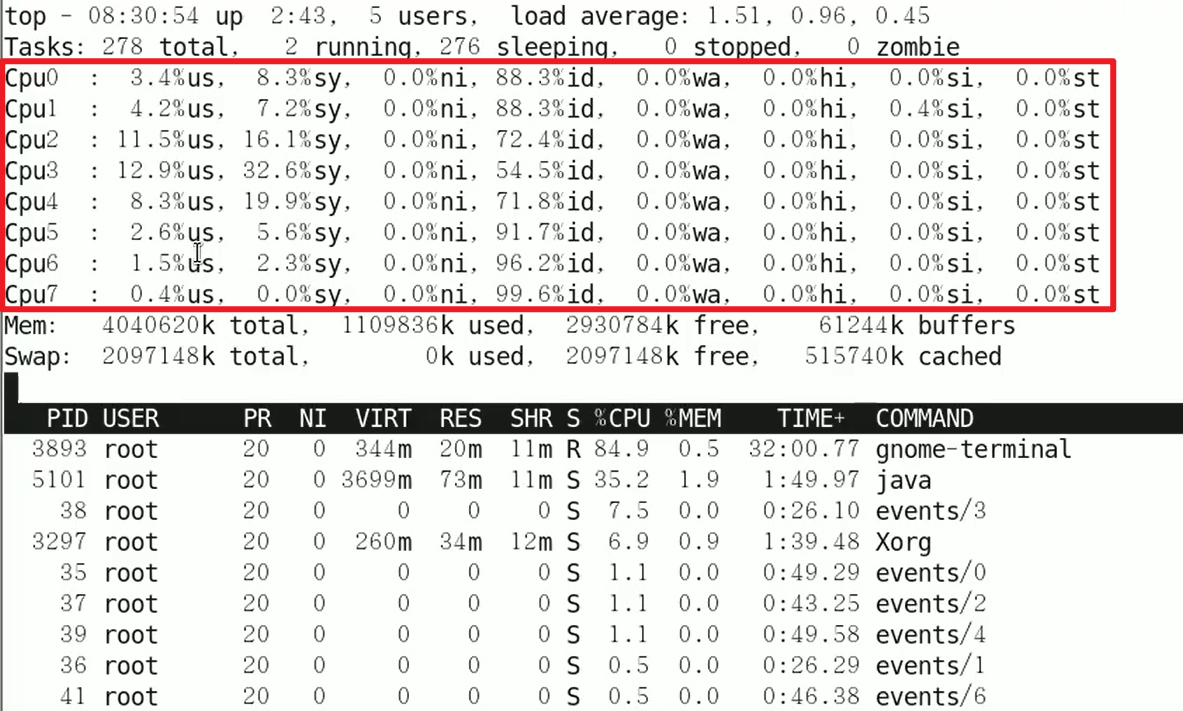
可以看到每个CPU的各种参数的使用情况嗷!!!
uptime:

精简版的ps,uptime你值得拥有
vmstat:
vmstat -n 2 3
- 主要用于查看CPU,但是包含不限于嗷!!!
- 每2秒采样一次,共计采样3次
1 | |
- 头和尾的两个比较重要嗷!!!
- r是run , b是block。

mpstat:
mpstat -P ALL 2
每两秒采样一次,查看所有CPU的核信息:
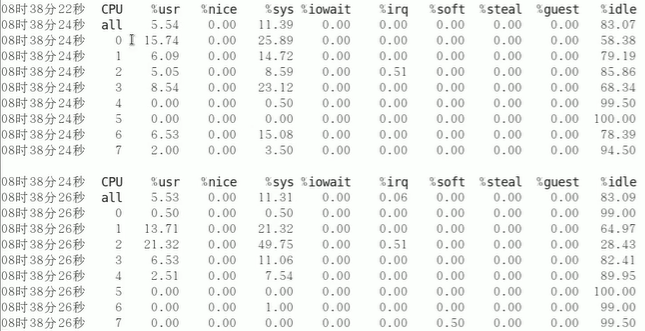
查看每个进程使用CPU的用量分解信息:
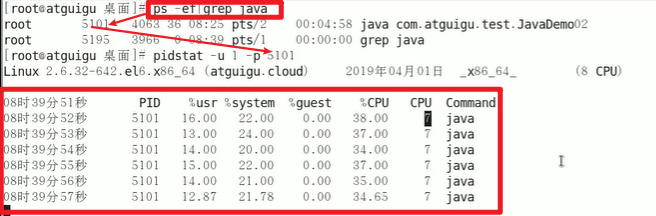
pidstat -u 1 -p 进程编号
free:
查看程序可用内存数
free -m按照M来看,系统内存的可用数量

pidstat -p 进程号 -r 采样间隔秒数
df:
disk free,查看磁盘剩余空间数
df -h用人类看得懂的方式来告诉我们,可用的磁盘空间大小
ioStat:
iostat,查看磁盘IO,磁盘I/O性能评估iostat -xdk 2 3

pidstat -d 时间间隔 -p 进程号
ifstat:
- 默认本地没有,要下载的嗷!!!
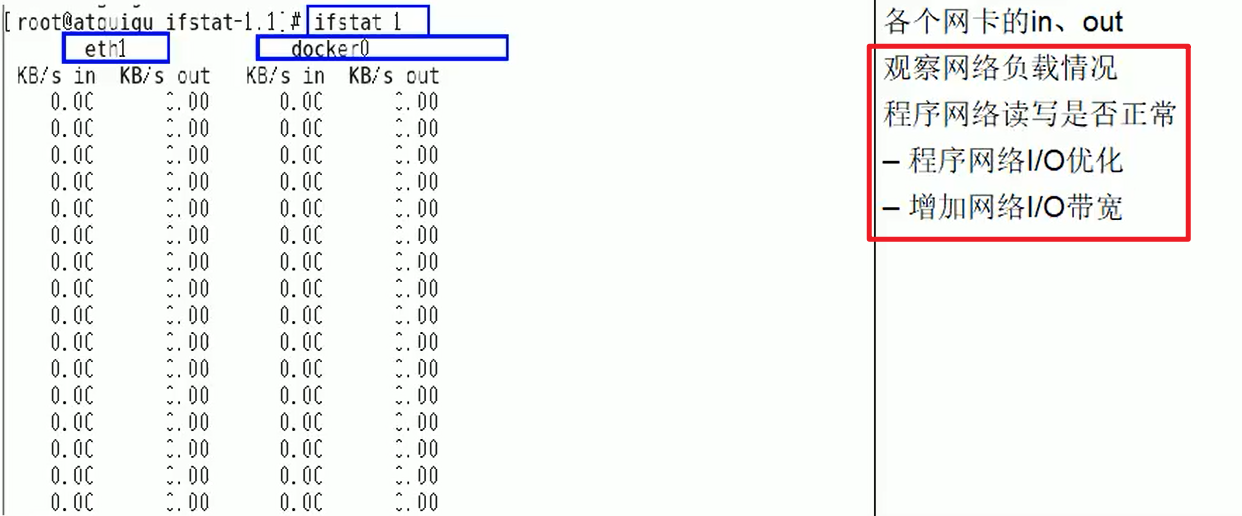
CPU占用过高,分析+定位?
Linux加上JDK共同分析
步骤:
- top命令找出惹事儿的Java程序,记录它的id
- ps -ef | grep 进程号或者 jps 进一步定位,得知怎样的后台程序在惹事儿
- 定位到具体的线程或者代码:
ps -mp 进程 -o THREAD,tid,timetid是哪一个线程,time是某个线程已经耗费的时间
参数解释:
- -m显示所有的线程
- -p pid进程使用cpu的时间
- -o 该参数后面是用户自定义格式
- 将需要的线程ID转换为16进制格式(英文小写格式)

或者手动算或用计算机算也成嗷!!!
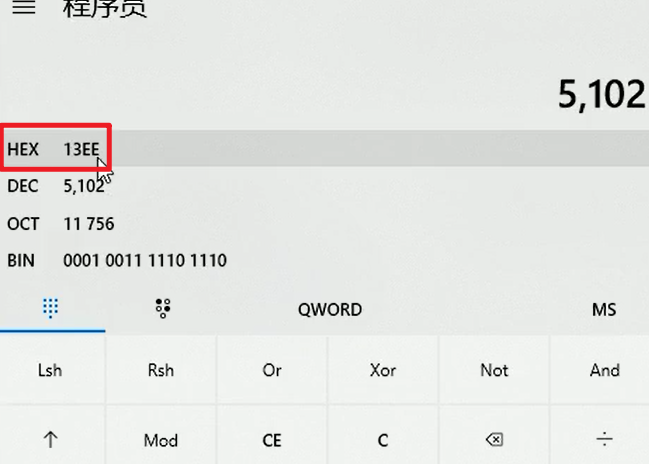
注意哈,机器内存里面全是小写嗷!!!
jstack 进程ID | grep tid(16进制线程id小写英文)-A60
-A60是打印出前60行嗷!!!
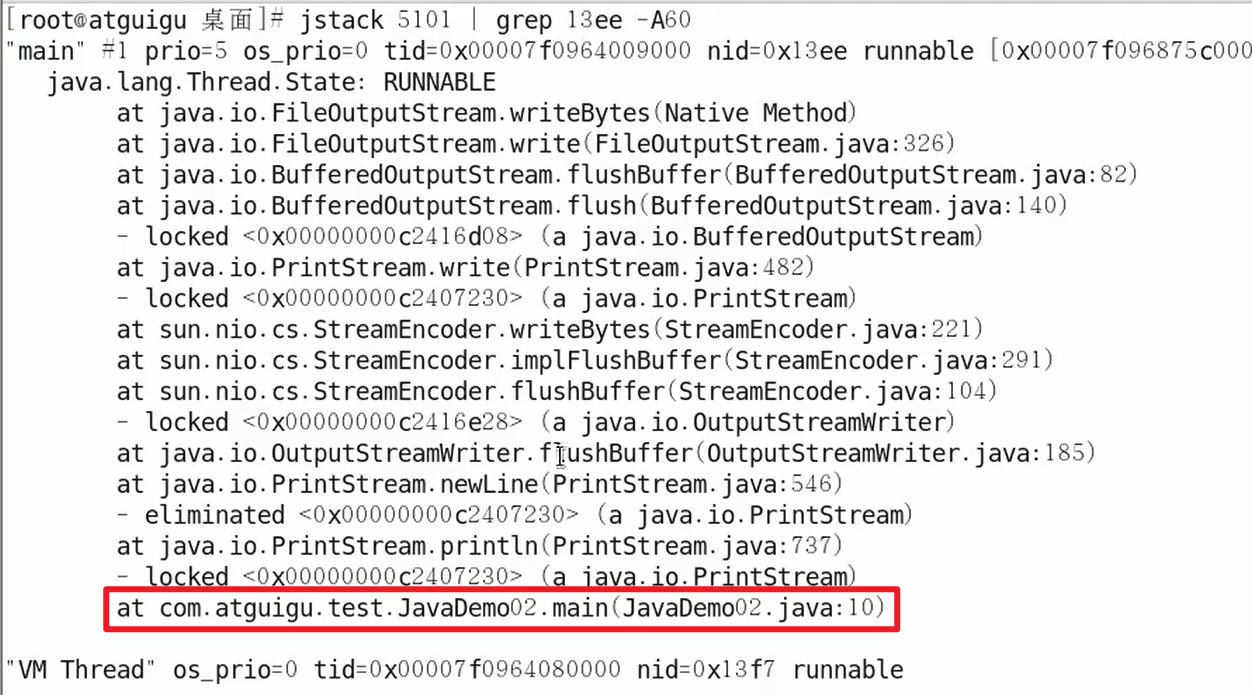
14. Github骚操作
常用词:
- watch:持续获得某个项目更新的通知嗷
- fork:复制某个项目到自己的仓库中
- star:项目点赞数
- clone:把项目下载到你本地
- follow:关注感兴趣的作者,会收到他们的动态
具体骚操作:
In关键词限制搜索范围:
公式:
xxx关键词 in:name 或 description 或 readme例如
seckill in:name,项目的名字中必须有seckill这个关键字嗷!!!组合使用:
seckill in:name,description
stars或fork项目查找项目:
- 公式:
xxx关键字 stars 通配符- 例如
:> 或者 :>= - 区间范围数字:
数字1...数字2
- 例如
- 例如:
springboot stars:>=5000 - 例如:
springboot forks:>=500 - 组合使用:
springboot forks:100..200 stars:2000..4000
awesome加强搜索:
- awesome系列一般是用来收集
- 查找官方收集的学习,工具,书籍类相关的项目
- 公式:
awesome 项目名字 - 例如:
awesome redis
高亮显示代码:
给别人指出关键代码的行数或者行号
公式:
项目对应代码的URL + #L + 数字例如:
https://github.com/coding/.../killDao.java#L13范围高亮:
项目对应代码的URL + #L + 数字 + - + L + 数字例如:
https://github.com/coding/.../killDao.java#L13-L23
T搜索:
- 项目内搜索
- 在项目主页按下小写字母t,这个快捷键就是项目中搜索嗷!!!
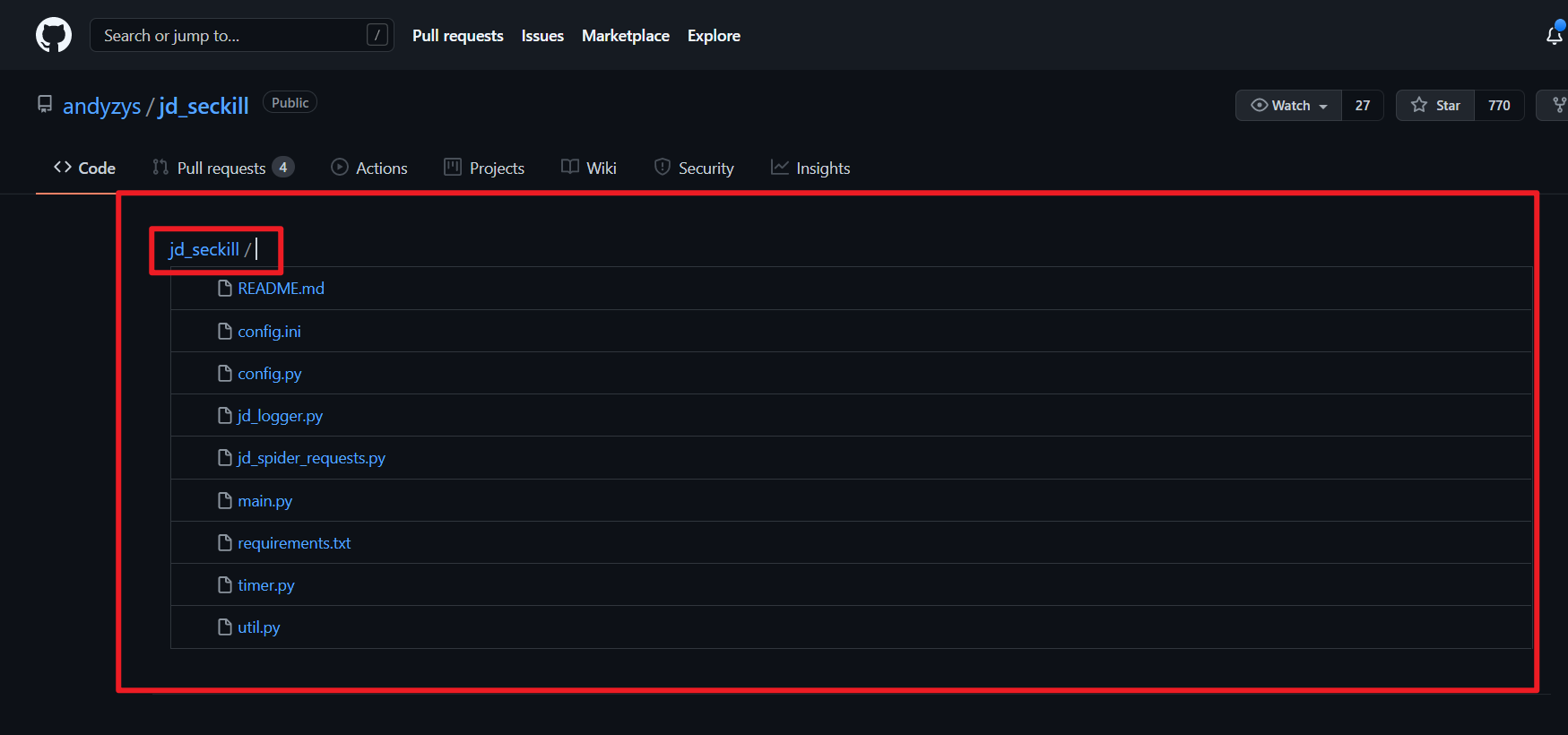
- 进入列表显示和搜索栏,可以列出项目中全部的文件,方便我们查找和检索阅读嗷!!!
- 还有好多好多快捷键嗷!!!
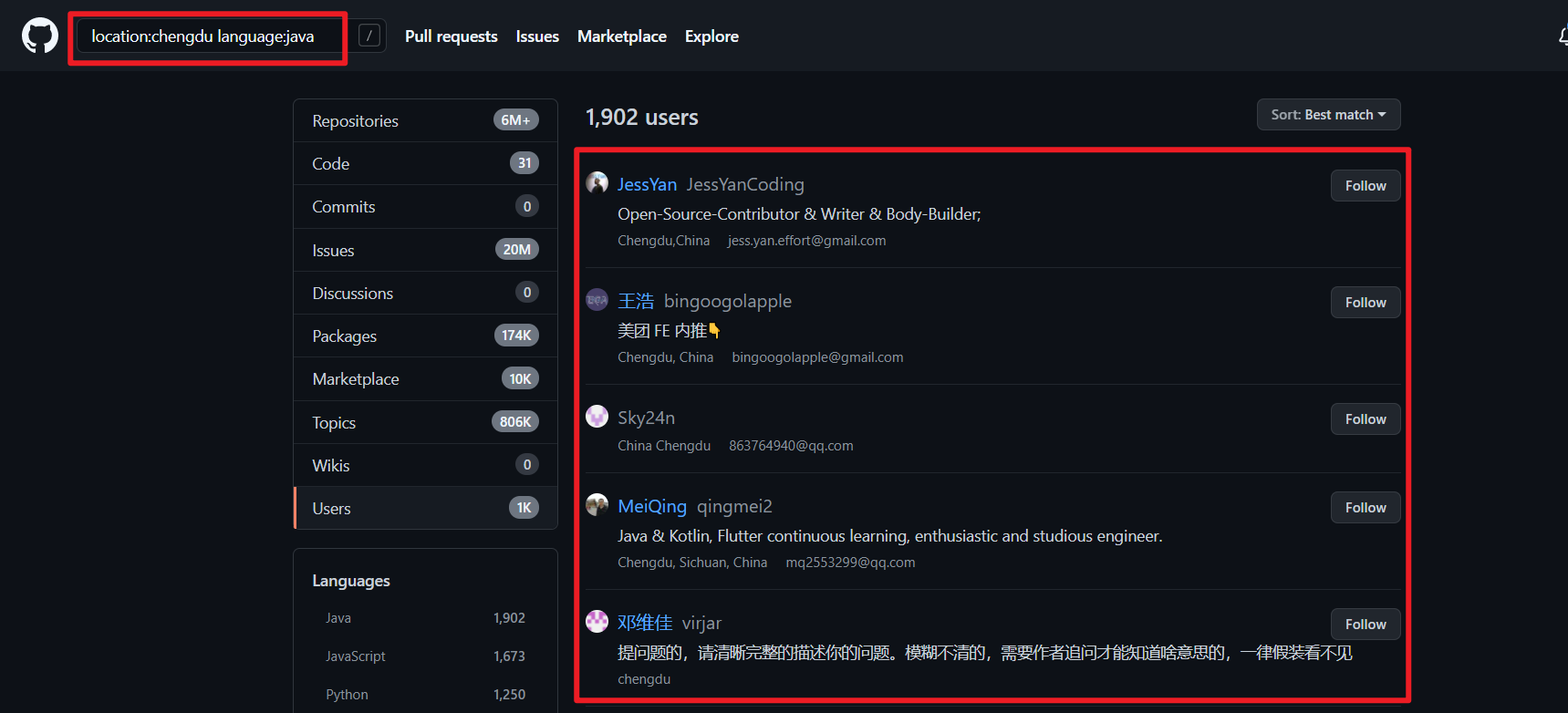
搜索某个地区的大佬:
- 公式:搜索栏中
location:beijing language:java